
- 1ArcGIS Engine10.0轻松入门级教程(4)——基本功能开发_arcengine movelinefeedbackclass
- 2java分布式事务——最终一致性,最大努力通知总结!_分布式事务中的最大努力通知思想
- 3python tokenizer是什么_Python tokenizer包_程序模块 - PyPI - Python中文网
- 4wordpress开源代码的一次白盒审计_开源代码安全审计
- 5大厂偏爱的Agent技术究竟是个啥_azure agent 是通过什么技术和后端通讯
- 6【gpt】免费部署个人gpt平台(无需tz)_gpt免费
- 7白天研究生系列:炼丹专题第三集《本地部署大语言模型保姆级教程——以ChatGLM-6B为例》_chatglm4-6b
- 8在Atlas 200 DK(Soc=Ascend 310)快速上手自定义模型训练、部署与推理_aclliteresource
- 9Python 零基础学习指南_momodel
- 10Python和人工智能的关系_人工智能程序是关联独立
【C++】哈希的应用——布隆过滤器_哈希应用之布隆 csdn
赞
踩
哈希的应用——布隆过滤器

一、布隆过滤器的概念与性质
1.布隆过滤器的引出
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。但我们可以使用一些哈希算法把字符串类型转换成整型,比如BKDR哈希算法,但是这里还存在一个问题。字符串的组合方式太多了,一个字符的取值有256种,一个数字只有10种,所以不可避免会出现哈希冲突
上述法二将哈希与位图结合的方法,即布隆过滤器
2.布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。相比于传统的 List、Set、Map 等数据结构,此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
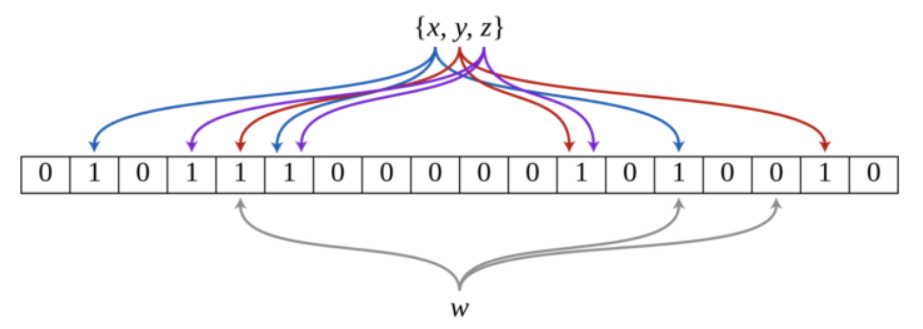
3.布隆过滤器的误判
布隆过滤器是**一个大型位图(bit数组或向量) + 多个无偏哈希函数**
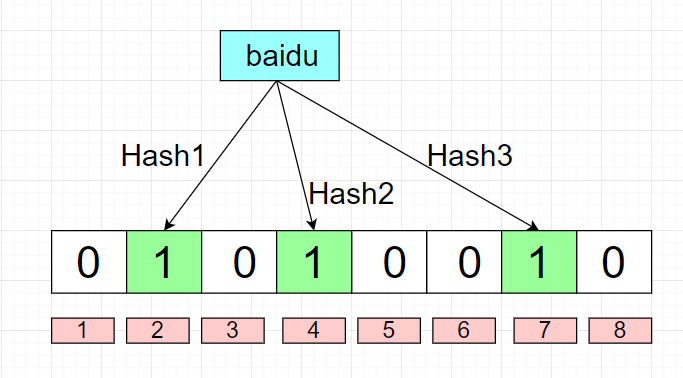
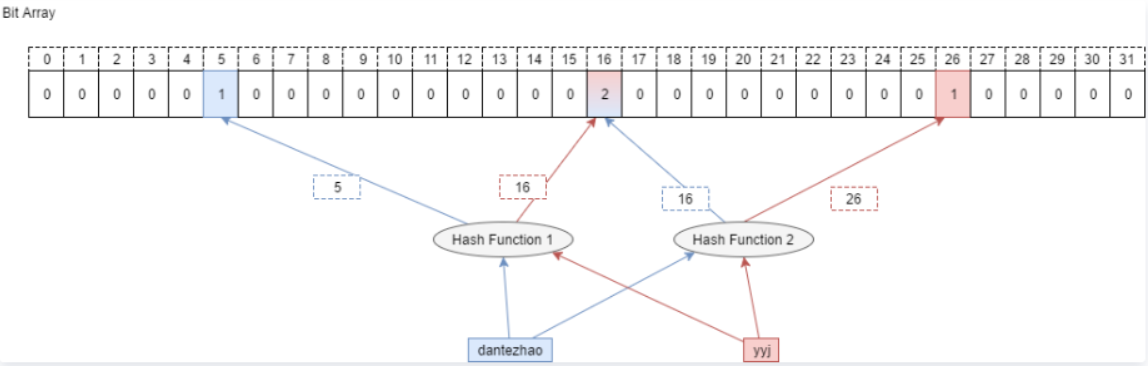
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值**,**并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 2、4、7,则上图转变为:
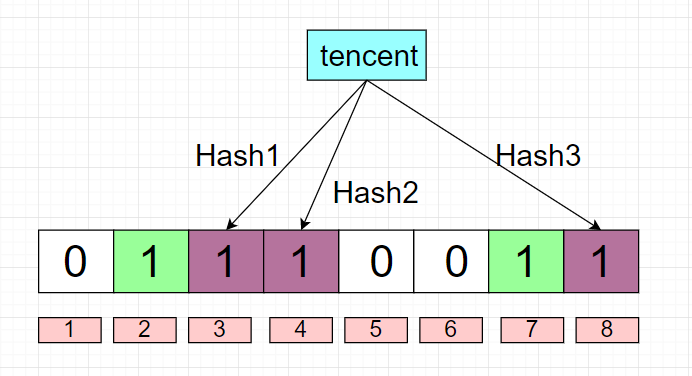
现在,如果我们要查询"baidu"这个字符串是否存在,就要判断位图中下标2,4,7对应的值是否均为1,若是,则说明此字符串“可能”存在。注意这里就可能出现误判了,至于为什么我们先再存一个字符串"tencent",假设哈希函数返回3,4,8,则对应的图如下:
- 值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “alibaba” 这个值是否存在,哈希函数返回了 2、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “alibaba” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 2、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在(发生了误判)。
- 这是为什么呢?答案很简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。像上面的字符串baidu,哈希函数返回的是2,4,7,可是先前的字符串baidu,哈希函数返回的是3,4,8,你怎么知道比特位4的值对应的是字符串baidu呢?我说它是字符串baidu的也没毛病吧,因此“baidu”可能存在。这就是误判出现的典型现象。
**总结:**布隆过滤器是无法解决误判的问题的,一个key通过多种哈希函数映射多个比特位只能说是降低误判的概率,但无法去除。

4.布隆过滤器的应用场景
根据布隆过滤器的概念,我们得知,只要数据允许误判,并且不会对业务造成影响,就允许使用布隆过滤器,有如下场景。
1、注册的时候,快速判断一个昵称是否使用过
- 如果一个不在布隆过滤器里头,表示没有用过;如果在,就需要再去数据库确认查找一遍
2、黑名单
- 如果一个人不在布隆过滤器里头,表示可同行;如果在,需要再去系统确认
3、过滤层,提高查找数据效率
- 如果一个数据在布隆过滤器里头,接着去数据系统中查找具体的那个;如果不在,直接返回,可以不用进行后续昂贵的查询请求。
4、对爬虫网址进行过滤,爬过的不用再爬;
……
5.布隆过滤器优缺点
优点:
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有着很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
缺点:
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
6.如何选择哈希函数个数和布隆过滤器长度
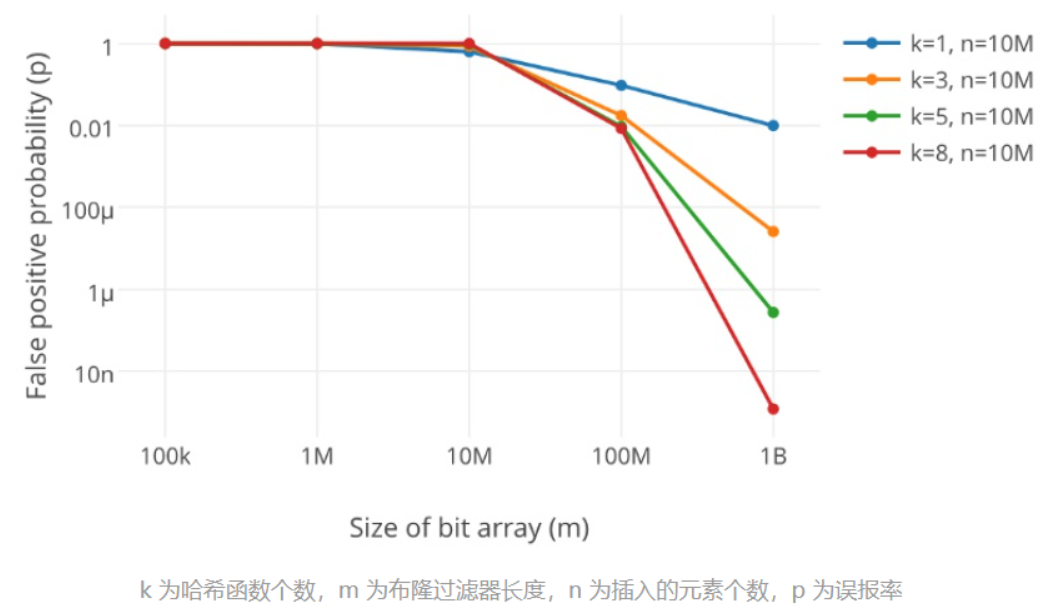
- 很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
- 另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
这是一位大佬绘制出来的一幅图,详细的说明了误判率和哈希函数个数及布隆过滤器长度之间的关系:
如何选择适合业务的哈希函数的个数和布隆过滤器长度呢,一大佬给出的一个公式:
其中k为哈希函数个数,m为布隆过滤器长度,n为插入的元素个数,p为误判率。
我们可以大概估算一下如果使用3个哈希函数,k = 3,ln2≈0.7,k = m/n * 0.7
通过计算得知m和n的关系大概是m = 4.3n,也就是布隆过滤器的长度应该是插入元素个数的4倍。
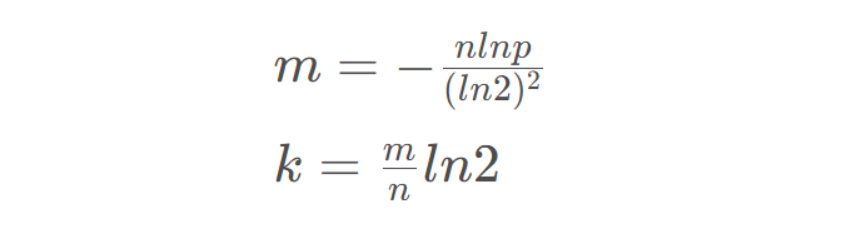
二、布隆过滤器的实现
1.布隆过滤器基本框架
- 这里布隆过滤器要实现成一个模板类,因为布隆过滤器插入的元素类型不固定(整型、字符串……),正因为元素类型不固定,所以要通过哈希函数把数据类型转换为整型。但一般情况下布隆过滤器都是用来处理字符串的,所以这里可以将模板参数K的缺省类型设置为string。这里我们假定传入3个哈希函数,通过上述计算,布隆过滤器的长度大概是插入元素个数的四倍。
- 布隆过滤器的成员也是一个位图,我们可以在布隆过滤器设置一个非类型模板参数M,用于调用者指定位图的长度。
template<size_t N, size_t X = 5, class K = string, class HashFunc1 = BKDRHash, class HashFunc2 = APHash, class HashFunc3 = DJBHash, class HashFunc4 = JSHash>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
布隆过滤器的三个哈希函数的作用是把数据转换成三个不同的整型,便于后续建立映射关系,这里我们使用BKDRHash、APHash和DJBHash这三种算法:
struct BKDRHash { size_t operator()(const string& key) { size_t hash = 0; for (auto ch : key) { hash *= 131; hash += ch; } return hash; } }; struct APHash { size_t operator()(const string& key) { unsigned int hash = 0; int i = 0; for (auto ch : key) { if ((i & 1) == 0) { hash ^= ((hash << 7) ^ (ch) ^ (hash >> 3)); } else { hash ^= (~((hash << 11) ^ (ch) ^ (hash >> 5))); } ++i; } return hash; } }; struct DJBHash { size_t operator()(const string& key) { unsigned int hash = 5381; for (auto ch : key) { hash += (hash << 5) + ch; } return hash; } }; struct JSHash { size_t operator()(const string& s) { size_t hash = 1315423911; for (auto ch : s) { hash ^= ((hash << 5) + ch + (hash >> 2)); } return hash; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
其它哈希算法的链接:各种字符串Hash函数算法

2.布隆过滤器的Set插入
布隆过滤器的插入就是提供一个Set接口,核心思想就是把插入的元素通过三个哈希函数获取对应的整型并%比特位数从而获得对应的3个映射位置,再把这三个位置置为1即可。
//set插入 void set(const K& key) { size_t hash1 = HashFunc1()(key) % (N * X); size_t hash2 = HashFunc2()(key) % (N * X); size_t hash3 = HashFunc3()(key) % (N * X); size_t hash4 = HashFunc4()(key) % (N * X); _bs.set(hash1); _bs.set(hash2); _bs.set(hash3); _bs.set(hash4); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.布隆过滤器的Test查找
布隆过滤器的查找就是提供一个Test接口,实现规则如下:
- 把测试数据通过三个哈希函数获取对应的整型并%比特位数从而获得对应的3个映射位置
- 如果三个位置中有任何一个位置不是1,直接返回false,说明查找的值不可能存在
- 只有三个位置全部为1,才可返回true,但是可能会存在误判(上面已经讲过)
//test查找 bool test(const K& key) { size_t hash1 = HashFunc1()(key) % (N * X); size_t hash2 = HashFunc2()(key) % (N * X); size_t hash3 = HashFunc3()(key) % (N * X); size_t hash4 = HashFunc4()(key) % (N * X); if (!_bs.test(hash1)) { return false; } if (!_bs.test(hash2)) { return false; } if (!_bs.test(hash3)) { return false; } if (!_bs.test(hash4)) { return false; } // 前面判断不在都是准确,不存在误判 return true; // 可能存在误判,映射几个位置都冲突,就会误判 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4.布隆过滤器的删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
- 比如:删除上图中"create"元素,如果直接将该元素所对应的二进制比特位置0,“source”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法(计数法删除):
- 将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计器减一,通过多占用几倍存储空间的代价来增加删除操作。
缺陷:
- 无法确认元素是否真正在布隆过滤器中
- 存在计数回绕
总结:
- 布隆过滤器不支持直接删除归根结底在于其主要就是用来节省空间和提高效率的,在计数法删除时需要遍历文件或磁盘中确认待删除元素确实存在,而文件IO和磁盘IO的速度相对内存来说是很慢的,并且为位图中的每个比特位额外设置一个计数器,就需要多用原位图几倍的存储空间,这个代价也是不小的。若支持删除就不那么节省空间了,也就违背了布隆过滤器的本质需求。
相关参考文献链接:布隆过滤器的原理,使用场景和注意事项

