
Spark从入门到精通_spark学习
赞
踩
Spark学习(一)
1. 对Spark的认识
Apache Spark 是用于大规模数据处理的统一分析引擎,是一个实现快速通用的集群计算平台,用来构建大型的、低延迟的数据分析应用程序,它扩展了广泛使用的MapReduce计算模型,高效的支撑更多计算模式,包括交互式查询和流处理。spark的一个主要特点是能够在内存中进行计算,及时依赖磁盘进行复杂的运算,Spark依然比MapReduce更加高效。
2.Spark的四大特性
- 高效性:Apache Spark使用最先进的DAG调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。
- 易用性:Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
- 通用性:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
- 兼容性:Spark可以非常方便地与其他的开源产品进行融合。
3.Spark的组成
Spark组成(BDAS):全称伯克利数据分析栈,通过大规模集成算法、机器、人之间展现大数据应用的一个平台。也是处理大数据、云计算、通信的技术解决方案。
它的主要组件有:
SparkCore:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
SparkSQL:Spark Sql 是Spark来操作结构化数据的程序包,可以让我使用SQL语句的方式来查询数据,Spark支持 多种数据源,包含Hive表,parquest以及JSON等内容。
SparkStreaming: 是Spark提供的实时数据进行流式计算的组件。
MLlib:提供常用机器学习算法的实现库。
GraphX:提供一个分布式图计算框架,能高效进行图计算。
BlinkDB:用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:以内存为中心高容错的的分布式文件系统。
4.Spark安装
-
创建安装目录
mkdir /opt/soft cd /opt/soft- 1
- 2
-
下载Scala
wget https://downloads.lightbend.com/scala/2.13.10/scala-2.13.10.tgz -P /opt/soft- 1
-
解压Scala
tar -zxvf scala-2.13.10.tgz- 1
-
修改Scala目录名字
mv scala-2.13.10 scala-2- 1
-
下载Spark
wget https://dlcdn.apache.org/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3-scala2.13.tgz -P /opt/soft- 1
-
解压spark
tar -zxvf spark-3.4.0-bin-hadoop3-scala2.13.tgz- 1
-
修改spark目录
mv spark-3.4.0-bin-hadoop3-scala2.13 spark3- 1
-
修改环境变量
vim /etc/profile- 1
export JAVA_HOME=/opt/soft/jdk8 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export ZOOKEEPER_HOME=/opt/soft/zookeeper export HADOOP_HOME=/opt/soft/hadoop3 export HADOOP_INSTALL=${HADOOP_HOME} export HADOOP_MAPRED_HOME=${HADOOP_HOME} export HADOOP_COMMON_HOME=${HADOOP_HOME} export HADOOP_HDFS_HOME=${HADOOP_HOME} export YARN_HOME=${HADOOP_HOME} export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export HIVE_HOME=/opt/soft/hive3 export HCAT_HOME=/opt/soft/hive3/hcatalog export SQOOP_HOME=/opt/soft/sqoop-1 export FLUME_HOME=/opt/soft/flume export HBASE_HOME=/opt/soft/hbase2 export PHOENIX_HOME=/opt/soft/phoenix export SCALA_HOME=/opt/soft/scala-2 export SPARK_HOME=/opt/soft/spark3 export SPARKPYTHON=/opt/soft/spark3/python export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HCAT_HOME/bin:$SQOOP_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin:$PHOENIX_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$SPARKPYTHON
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
source /etc/profile- 1
-
Local模式启动
spark-shell 页面访问 http://spark01:4040- 1
- 2
-
退出
:quit- 1
5.HA模式
-
编写核心配置文件
cd /opt/soft/spark3/conf- 1
cp spark-env.sh.template spark-env.sh- 1
vim spark-env.sh- 1
export JAVA_HOME=/opt/soft/jdk8 export HADOOP_HOME=/opt/soft/hadoop3 export HADOOP_CONF_DIR=/opt/soft/hadoop3/etc/hadoop export JAVA_LIBRAY_PATH=/opt/soft/hadoop3/lib/native SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=spark01:2181,spark02:2181,spark03:2181 -Dspark.deploy.zookeeper.dir=/spark3" export SPARK_WORKER_MEMORY=4g export SPARK_WORKER_CORES=4 export SPARK_MASTER_WEBUI_PORT=6633- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
hdfs dfs -mkdir /spark3- 1
-
编辑slaves
cp workers.template workers- 1
vim workers spark01 spark02 spark03- 1
- 2
- 3
- 4
-
配置历史日志
cp spark-defaults.conf.template spark-defaults.conf- 1
vim spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://lihaozhe/spark-log- 1
- 2
- 3
hdfs dfs -mkdir /spark-log- 1
vim spark-env.sh export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://lihaozhe/spark-log"- 1
- 2
- 3
- 4
- 5
-
修改启动文件名称
mv sbin/start-all.sh sbin/start-spark.sh mv sbin/stop-all.sh sbin/stop-spark.sh- 1
- 2
-
分发搭配其他节点
scp -r /opt/soft/spark3 root@spark02:/opt/soft scp -r /opt/soft/spark3 root@spark03:/opt/soft scp -r /etc/profile root@spark02:/etc scp -r /etc/profile root@spark03:/etc- 1
- 2
- 3
- 4
source /etc/profile- 1
-
启动
start-spark.sh start-history-server.sh- 1
- 2
-
网页访问
http://spark01:6633 http://spark01:18080- 1
- 2
6.Spark-RDD
-
RDD概念
-
什么是RDD
RDD称为弹性分布式数据集,是spark中最基本的数据抽象,它代表一个不可变、可分区、里边元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在多个查询时显示地将工作集缓存在内存中,后续的查询能够重用工作集,极大限度的提升查询效率。
-
RDD的属性
- 一组分片,即数据集的基本组成单位。每个分片都会被一个计算任务处理,并决定并行计算的粒度。
- 一个计算每个分区的函数。spark中RDD的计算是以分片为单位的。
- RDD之间的依赖关系。RDD的每次转换都会形成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系,在部分分区数据丢失时,spark可以通过这个依赖关系重新计算丢失的分区数据。
- 一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片parent RDD Shuffle输出时的分片数量。
- 一个列表,存储存取每个Partition的优先位置。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在块的位置。
-
图解RDD
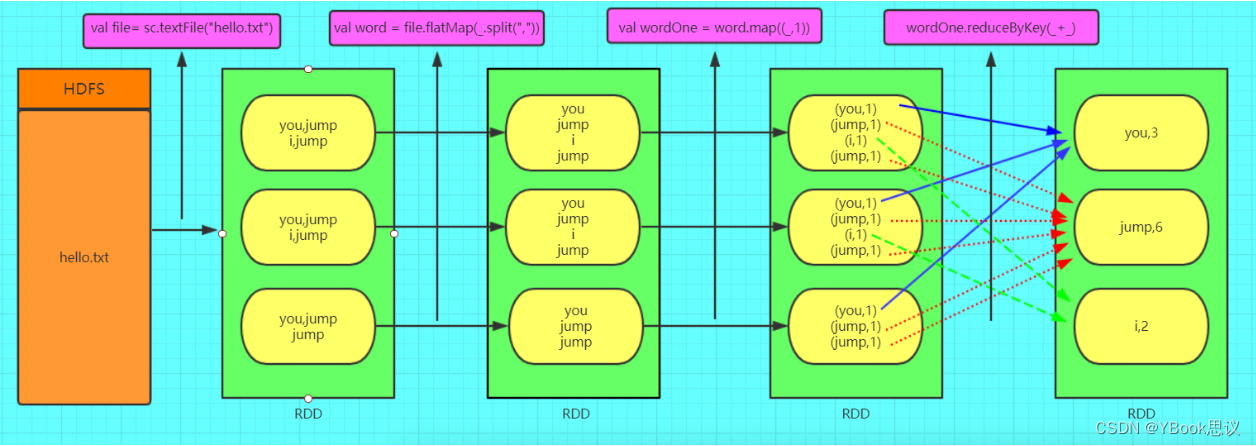
-
-
RDD创建
-
数据集方式构建RDD
package com.lihaozhe.course01 import org.apache.spark.{SparkConf, SparkContext} object ScalaDemo01 { def main(args: Array[String]): Unit = { val appName = "rdd" // spark基础配置 // val conf = new SparkConf().setAppName(appName).setMaster("local") val conf = new SparkConf().setAppName(appName) // 本地运行 conf.setMaster("local") // 构建 SparkContext spark 上下文 val sc = new SparkContext(conf) // 数据集 val data = Array(1, 2, 3, 4, 5) // 从集合中创建 RDD // Parallelized Collections val distData = sc.parallelize(data) distData.foreach(println) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
本地文件构建RDD
package com.lihaozhe.course01 import org.apache.spark.{SparkConf, SparkContext} object ScalaDemo02 { def main(args: Array[String]): Unit = { val appName = "rdd" // spark基础配置 // val conf = new SparkConf().setAppName(appName).setMaster("local") val conf = new SparkConf().setAppName(appName) // 本地运行 conf.setMaster("local") // 构建 SparkContext spark 上下文 val sc = new SparkContext(conf) // 从外部中创建 RDD // External Datasets // 使用本地文件系统 val distFile = sc.textFile("file:///home/lsl/IdeaProjects/spark-code/words.txt") distFile.foreach(println) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
-
HDFS文件构建RDD
package com.lihaozhe.course01 import org.apache.spark.{SparkConf, SparkContext} object ScalaDemo03 { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME", "root") val appName = "rdd" // spark基础配置 // val conf = new SparkConf().setAppName(appName).setMaster("local") val conf = new SparkConf().setAppName(appName) // 本地运行 conf.setMaster("local") // 构建 SparkContext spark 上下文 val sc = new SparkContext(conf) // 从外部中创建 RDD // External Datasets // 使用HDFS文件系统 // val distFile = sc.textFile("hdfs://spark01:8020/data/words.txt") val distFile = sc.textFile("/data/words.txt") distFile.foreach(println) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
-
-
RDD算子
Spark支持两个类型(算子)操作:Transformation和Action
- 常用的Transformation

- 常用的Action
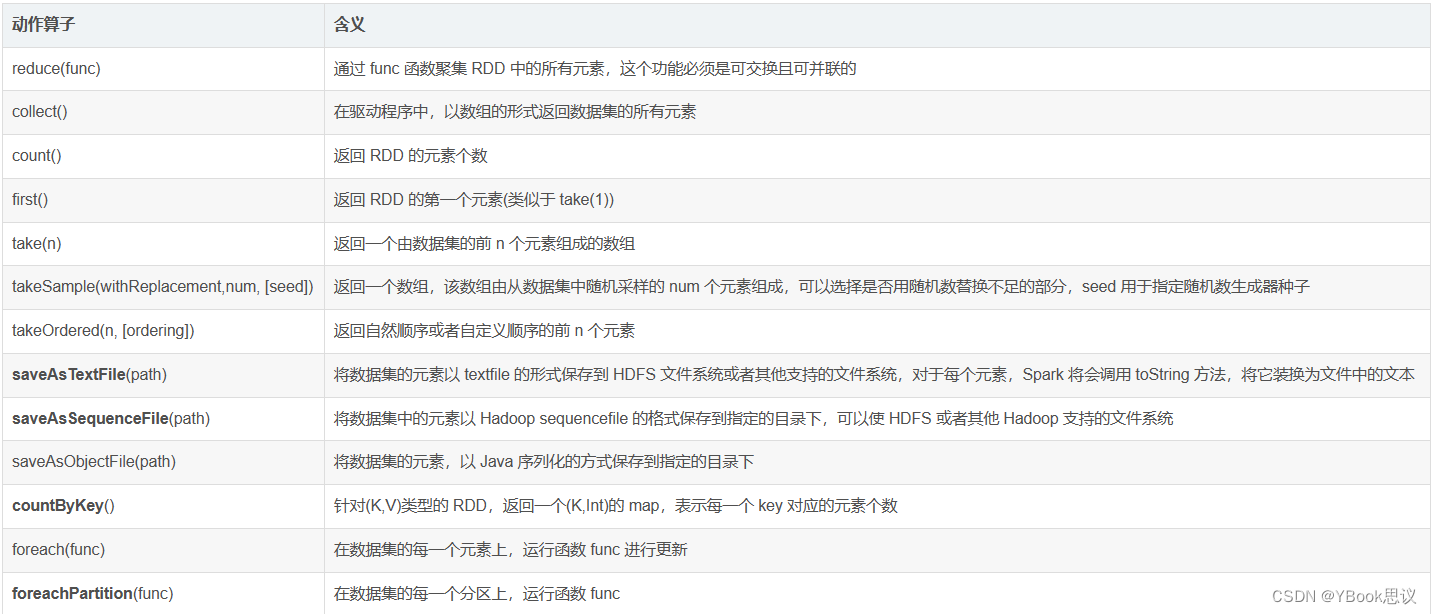
- 常用的Transformation
-
词频统计
-
JavaWordCount
package com.lihaozhe.course03; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; import java.util.Arrays; public class JavaWordCount { public static void main(String[] args) { System.setProperty("HADOOP_USER_NAME", "root"); String appName = "WordCount"; // SparkConf conf = new SparkConf().setAppName(appName).setMaster("local"); SparkConf conf = new SparkConf().setAppName(appName); // 本地运行 // conf.setMaster("local"); try (JavaSparkContext sc = new JavaSparkContext(conf)) { JavaRDD<String> javaRDD = sc.textFile("/data/words.txt"); JavaRDD<String> wordsRdd = javaRDD.flatMap((FlatMapFunction<String, String>) line -> Arrays.asList(line.split(" ")).listIterator()); JavaPairRDD<String, Integer> javaPairRDD = wordsRdd.mapToPair((PairFunction<String, String, Integer>) word -> new Tuple2<>(word, 1)); JavaPairRDD<String, Integer> rs = javaPairRDD.reduceByKey((Function2<Integer, Integer, Integer>) Integer::sum); rs.saveAsTextFile("/data/result"); sc.stop(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
1. ScalaWordCount- 1
package com.lihaozhe.course03 import org.apache.spark.{SparkConf, SparkContext} object ScalaWordCount01 { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME", "root") // val conf = new SparkConf().setAppName("WordCount").setMaster("local") val conf = new SparkConf().setAppName("WordCount") // conf.setMaster("local") val sc = new SparkContext(conf) val content = sc.textFile("/data/words.txt") // content.foreach(println) val words = content.flatMap(_.split(" ")) // words.foreach(println) // (love,Seq(love, love, love, love, love)) val wordGroup = words.groupBy(word => word) // wordGroup.foreach(println) // (love,5) val wordCount = wordGroup.mapValues(_.size) // wordCount.foreach(println) wordCount.saveAsTextFile("/data/result"); sc.stop() } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
package com.lihaozhe.course03 import org.apache.spark.{SparkConf, SparkContext} object ScalaWordCount02 { def main(args: Array[String]): Unit = { System.setProperty("HADOOP_USER_NAME", "root") // val conf = new SparkConf().setAppName("WordCount").setMaster("local") val conf = new SparkConf().setAppName("WordCount") // conf.setMaster("local") val sc = new SparkContext(conf) val content = sc.textFile("/data/words.txt") // content.foreach(println) val words = content.flatMap(_.split(" ")) // words.foreach(println) // (love,Seq(love, love, love, love, love)) val wordMap = words.map((_, 1)) // wordGroup.foreach(println) // (love,5) val wordCount = wordMap.reduceByKey(_ + _) //wordCount.foreach(println) wordCount.saveAsTextFile("/data/result"); sc.stop() } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
-
-
RDD宽依赖和窄依赖
-
RDD依赖关系的本质
由于RDD是粗粒度的操作数据集,每个Transformation操作都会生成一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系;RDD和它依赖的父RDD的关系有两种不同类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。如图所示显示了RDD之间的依赖关系。
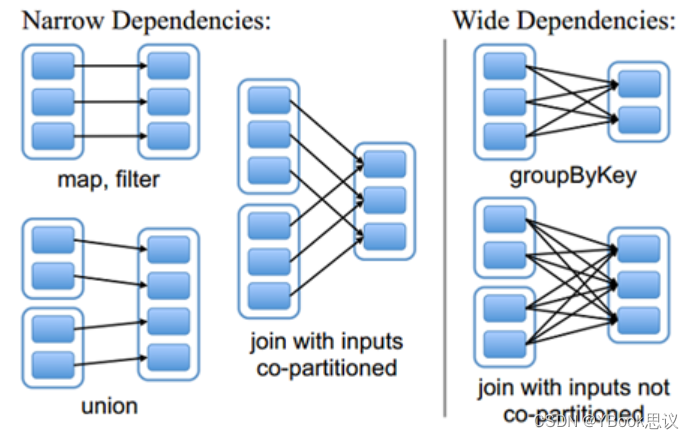
窄依赖:是指每个父RDD的一个Patition最多会被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)。 宽依赖:是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)- 1
- 2
- 3
特别说明:join操作有两种情况:
-
图中左半部分join:如果两个RDD在进行join操作时,一个RDD的Partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖
-
图中右半部分join:其它情况的join操作就是宽依赖,例如图1中右半部分的join操作,由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
总结: > 在这里我们是从父RDD的partition被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。因为是确定的partition数量的依赖关系,所以RDD之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。 > > 一对固定个数的窄依赖的理解:即子RDD的partition对父RDD依赖的Partition的数量不会随着RDD数据规模的改变而改变;换句话说,无论是有100T的数据量还是1P的数据量,在窄依赖中,子RDD所依赖的父RDD的partition的个数是确定的,而宽依赖是shuffle级别的,数据量越大,那么子RDD所依赖的父RDD的个数就越多,从而子RDD所依赖的父RDD的partition的个数也会变得越来越多。- 1
- 2
- 3
- 4
- 5
- 依赖关系下的数据流试图
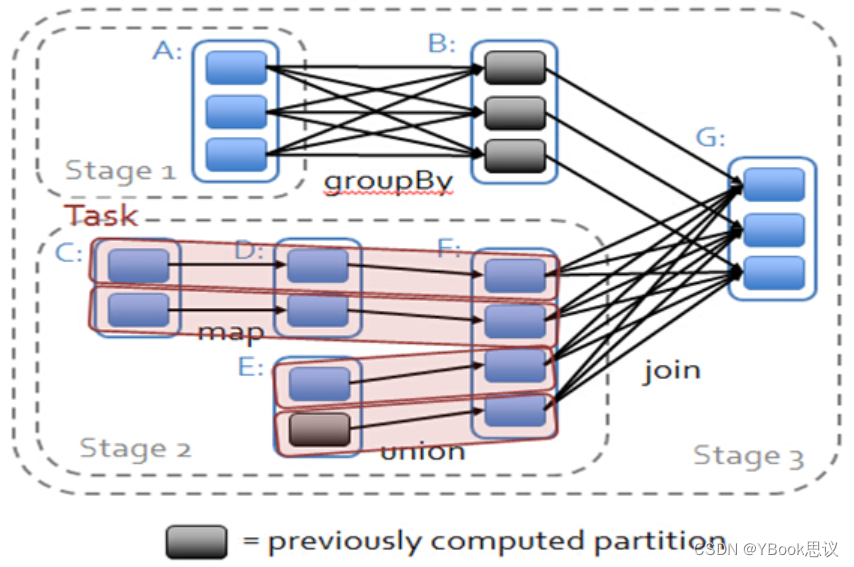
在spark中,会根据RDD之间的依赖关系将DAG图(有向无环图)划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。 因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在图2中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。 在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask; 简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说上图中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。 在之前动手操作了一个wordcount程序,因此可知,Hadoop中MapReduce操作中的Mapper和Reducer在spark中的基本等量算子是map和reduceByKey;不过区别在于:Hadoop中的MapReduce天生就是排序的;而reduceByKey只是根据Key进行reduce,但spark除了这两个算子还有其他的算子;因此从这个意义上来说,Spark比Hadoop的计算算子更为丰富。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7.广播变量broadcast variable
-
背景
在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
-
图解
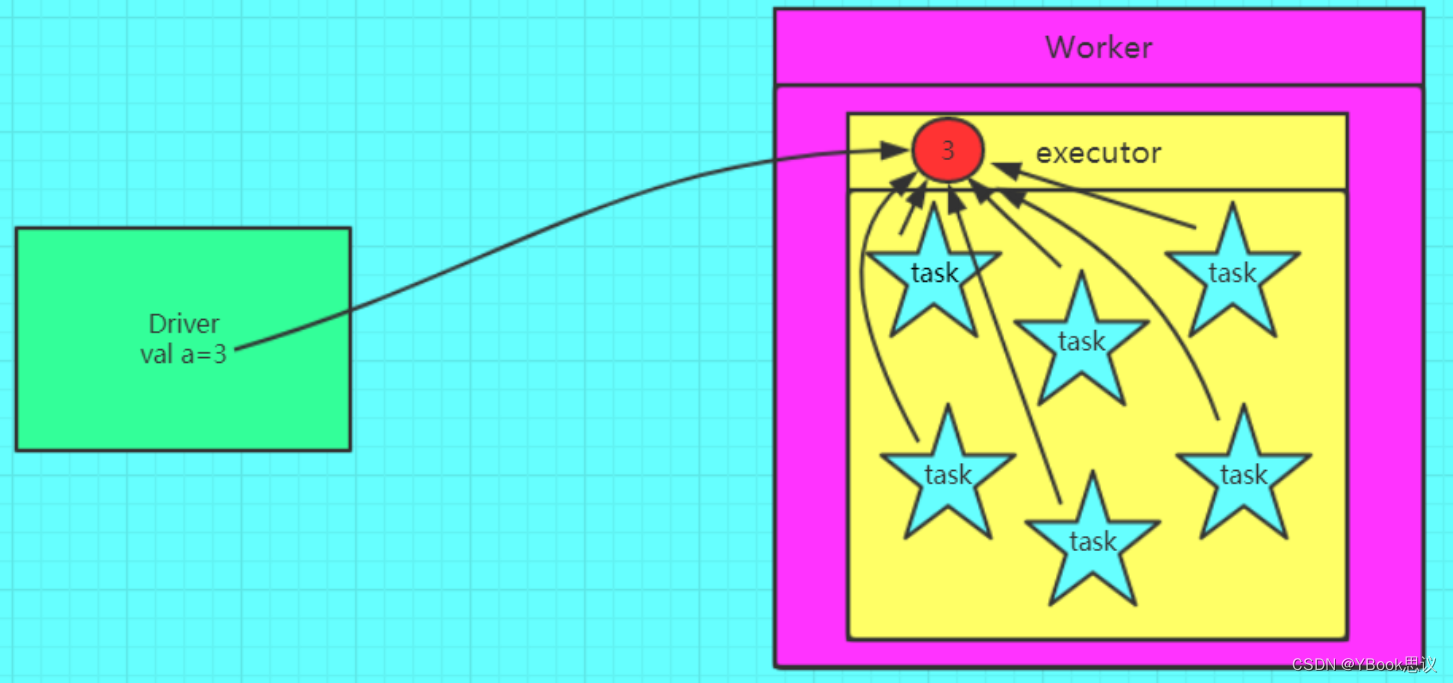
-
定义一个广播变量
val a = 3; val broadcast = sc.broadcast(a);- 1
- 2
-
还原一个广播变量
val c = broadcast.value;- 1
-
注意事项:
-
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
-
注意:
1、能不能将一个RDD使用广播变量广播出去? 不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
-
-
8.累加器
-
背景
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
-
图解
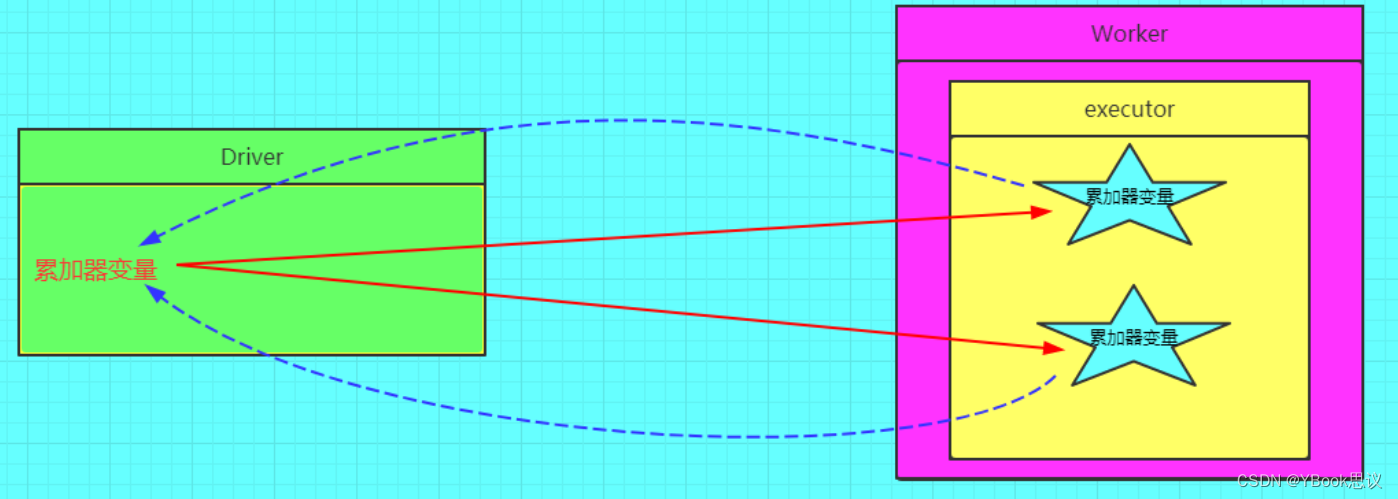
-
定义一个累加器
val a = sc.accumulator(0)- 1
-
还原一个累加器
val b = a.value- 1
-
注意事项
1、 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
2、累加器不是一个调优的操作,因为如果不这样做,结果是错的

