Hadoop 简介
赞
踩
一、Hadoop 是什么
Hadoop 是一个提供分布式存储和计算的开源软件框架,它具有无共享、高可用(HA)、弹性可扩展的特点,非常适合处理海量数量。
- Hadoop 是一个开源软件框架
- Hadoop 适合处理大规模数据
- Hadoop 被部署在一个可扩展的集群服务器上
二、Hadoop 三大核心组件
- HDFS(分布式文件系统) -—— 实现将文件分布式存储在集群服务器上
- MAPREDUCE(分布式运算编程框架) —— 实现在集群服务器上分布式并行运算
- YARN(分布式资源调度系统) —— 帮用户调度大量的 MapReduce 程序,并合理分配运算资源(CPU和内存)
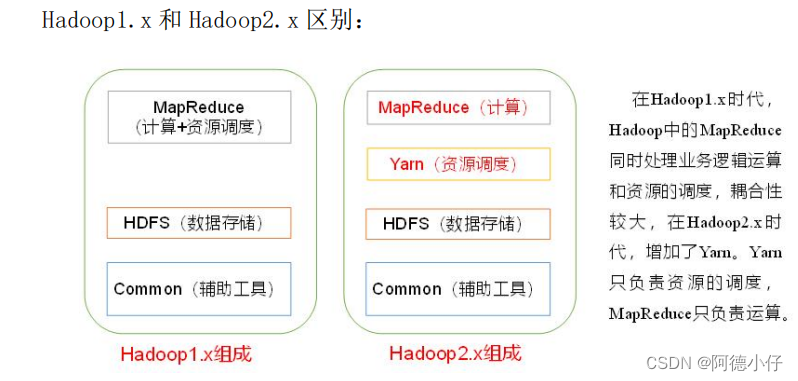
1.X和2.X版本的区别
1、HDFS
定义
优缺点
优点:
核心思想
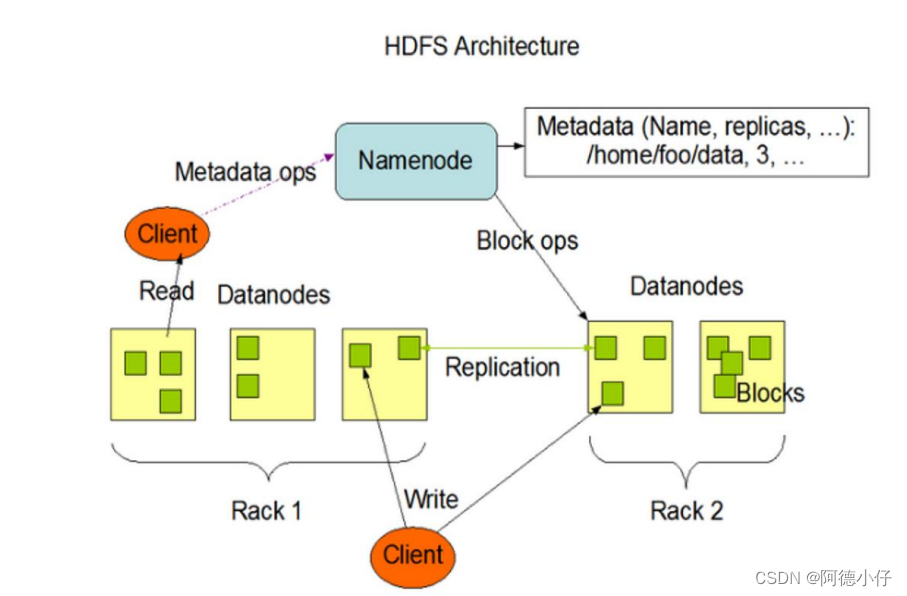
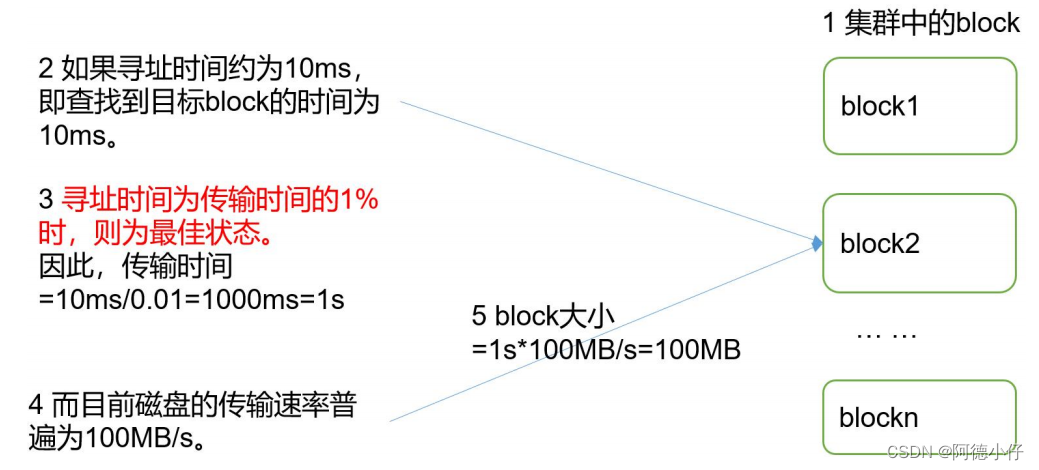
重点
2、MapReduce
定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完的分布式运算程序,并发运行在一个Hadoop集群上
优缺点
优点:
(1)MapReduce易于编程它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
(2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
(3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
(4)适合PB级以上海量数据的离线处理可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点:
(1)不擅长实时计算MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果
(2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的不擅长DAG(有向图)计算
(3)多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下
核心思想
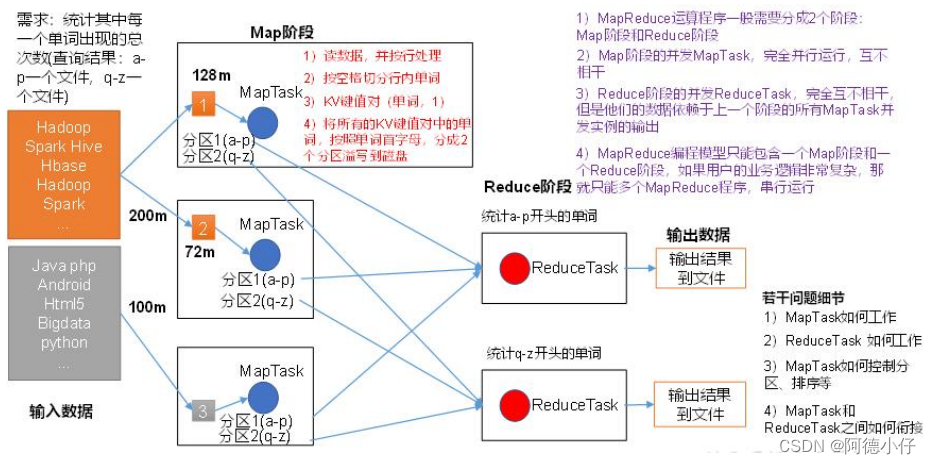
MapReduce进程

执行流程
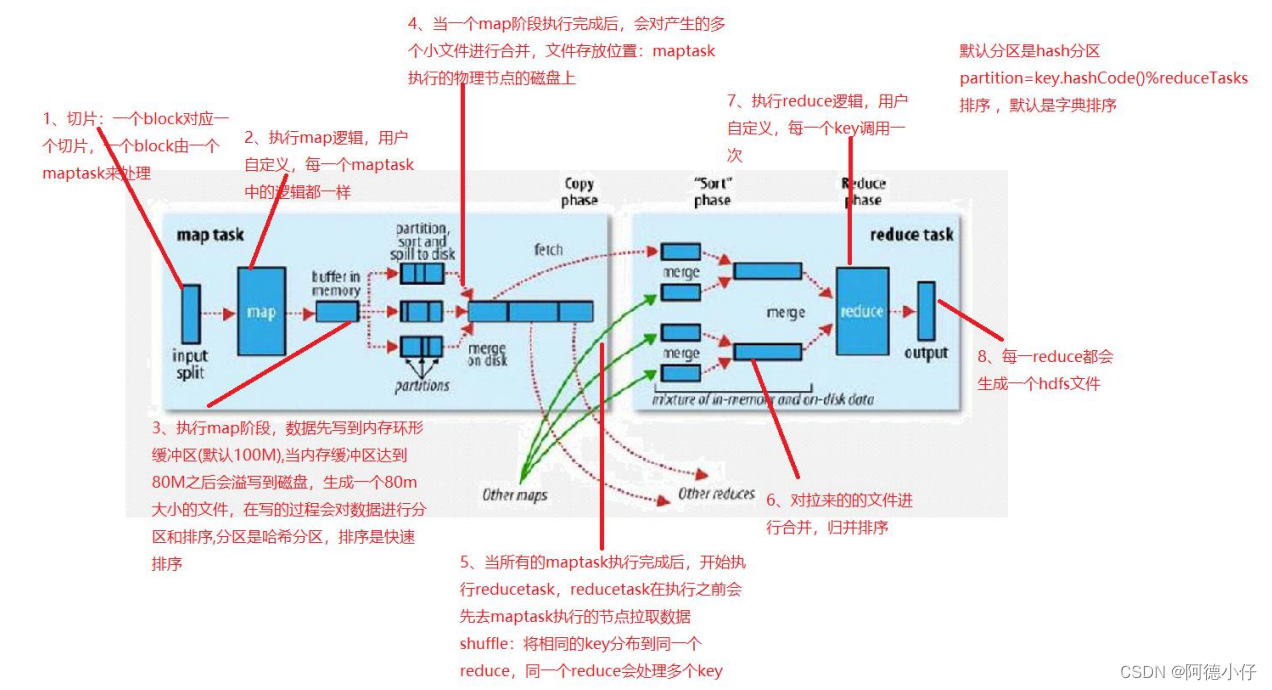 3、Yarn
3、Yarn
定义
yarn是一种通用的资源管理系统和调度平台。
资源管理系统 :管理集群内的硬件资源,和程序运行相关,比如内存,CPU等。
调度平台:多个程序同时申请计算资源时提供分配,调度的规则(算法)。
通用:不仅仅支持MapReduce程序,理论上支持各种计算程序如spark,flink。yarn不关系程序的计算内容,只关心程序所需的资源,在程序申请资源的时候根据调度算法分配资源,计算结束之后回收计算资源。使用yarn作为资源调度平台的计算框架自身需要提供ApplicationMaster来负责计算任务的调度。
优缺点
优点
(1)将资源管理和作业控制分离,减小JobTracker压力
(2)YARN的设计大大减小了 JobTracker(也就是现在的 ResourceManager)的资源消耗,并且让监测每一个 Job 子任务 (tasks) 状态的程序分布式化了,更安全、更优美。
(3)老的框架中,JobTracker一个很大的负担就是监控job下的tasks的运行状况,现在,这个部分就扔给ApplicationMaster做了而ResourceManager中有一个模块叫做ApplicationsManager(ASM),它负责监测ApplicationMaster的运行状况。
(4)能够支持不同的计算框架
(5)资源管理更加合理
(6)使用Container对资源进行抽象,Container不同于MRv1中的slot,它是一个动态资源划分单位,是根据应用程序的需求动态生成的,比之前以slot数目更合理。
(7)且使用了轻量级资源隔离机制Cgroups进行资源隔离。
(8)Container的设计避免了之前的map slot/reduce slot分开造成集群资源闲置的尴尬情况。
缺点:
(1)各个应用无法感知集群整体资源的使用情况,只能等待上层调度推送信息。
(2)资源分配采用轮询、ResourceOffer机制(mesos),在分配过程中使用悲观锁,并发粒度小。
(3)缺乏一种有效的竞争或优先抢占的机制。
(4)简化了双层调度器中的全局资源管理器,改为由一个Cell State来记录集群内的资源使用情况,这些使用情况都是共享的数据,以此来达到与全局资源管理器相同的效果。
(5)所有任务访问共享数据时,采用乐观并发控制方法。
核心思想
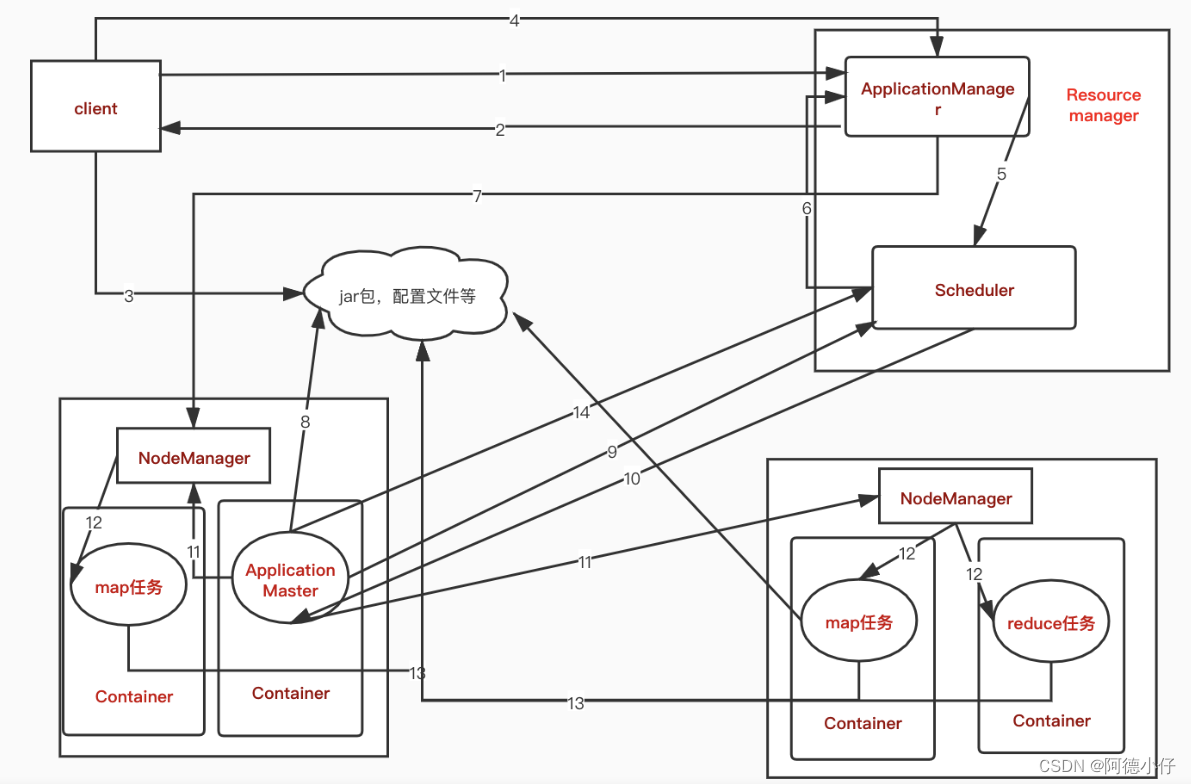
步骤说明:
1,客户端向ResourceManager中的ApplicationManager提交作业申请,申请jobID。
2,ApplicationManager 返回一个jobID,以及运行的hdfs临时路径(hdfs://… jobID)。
3,客户端将作业的jar包,配置信息等上传到分配的hdfs临时路径(hdfs://… jobID)中。
4,客户端上传文件成功后,向ApplicationManager发送执行作业请求。
5,ApplicationManager将请求转发给Scheduler,申请执行所需资源。
6,调度器将作业放置到相关队列中,当执行到该作业时,开始让ApplicationManager分配Containers。
7,ApplicationManager命令NodeManager使用分配的container资源启动ApplicationMaster。
8,ApplicationMaster启动后去分配的hdfs临时路径(hdfs://… jobID)中读取作业的具体信息,根据分片信息创建map任务,reduce任务。
9,ApplicationMaster向Scheduler请求资源来执行map任务,reduce任务。
10,Scheduler返回申请结果。
11,AppMaster通知NodeManager,启动map,reduce任务。
12,NodeManager启动map,reduce任务。
13,map,reduce任务读取数据,进行逻辑计算。计算过程中如果有map,reduce任务执行失败了,AppMaster负责重启任务。
14,程序执行成功后,AppMaster向Scheduler发送请求,释放资源。
摘抄部分原文链接:https://blog.csdn.net/weixin_43172032/article/details/117759068
调度策略
Yarn中有三种资源调度器:FIFO调度器(FIFO Scheduler)、容量调度器(Capacity Scheduler)、公平调度器(Fair Scheduler)。
(1)FIFO调度器
简介:顾名思义,FIFO调度器把应用放在队列里,按照先进先出的提交顺序执行应用。
优点:简单,不需要额外配置。
缺点:不适合共享集群。大应用会占满整个集群的资源,导致小应用长时间等待。
(2)容量调度器
简介:容量调度器设有一个专门的队列给小作业使用。
优点:大作业不会占满全部资源,小作业不需要长时间等待大作业完成。
缺点:整个集群的资源利用率降低了,大作业需要更长的时间来执行。
(3)公平调度器
简介:公平调度器旨在为所有运行的应用公平地分配资源。
优点:同时解决了FIFO大作业占满整个集群资源的问题和Capacity小作业队列空闲导致集群资源利用率降低的问题。
缺点:存在延迟问题,后面的作业需要等待前面的作业让出资源。
具体策略介绍请看:https://blog.csdn.net/m0_37795099/article/details/124211350
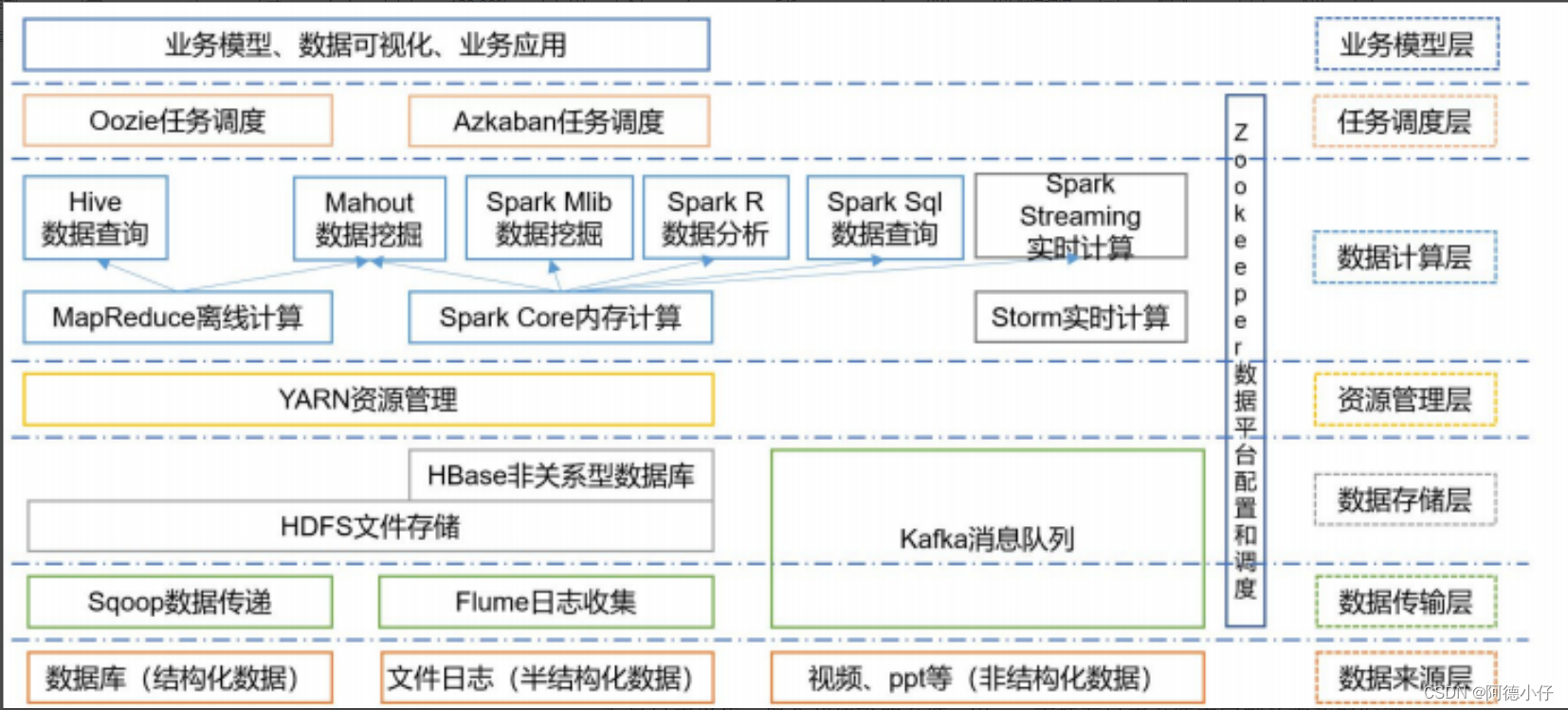
三、Hadoop 生态圈
Hadoop 生态圈是指围绕 Hadoop 软件框架为核心而出现的越来越多的相关软件框架,这些软件框架和 Hadoop 框架一起构成了一个生机勃勃的 Hadoop 生态圈。在特定场景下,Hadoop 有时也指代 Hadoop 生态圈。
Hadoop 生态圈的架构图