
- 1mysql 节点查根_(三)B数、B+树及在数据库索引中应用
- 22023年黑龙江省职业院校技能大赛:移动应用与开发赛项规程
- 3STM32 HAL库 CubeMX配置 定时器学习 F103C8T6_stm3f103 定时器 hal库
- 4人工智能算法工程师面试题——之OpenCV必背汇总(二)_opencv 图像金字塔
- 5使用Chrome://inspect调试 Android 设备上Webview
- 6HTTP 请求头安全方案_permissions-policy
- 7解决Error: git clone of oh-my-zsh repo failed
- 8情感分析:几乎包括你需要知道的所有(二)_情感分析组合有哪些
- 9网页上做笔记--Diigo
- 10flutter 自定义TabBar 【top 0 级别】_flutter tabbar
Few-Shot Representation Learning for Out-Of-Vocabulary Words 论文笔记
赞
踩
《Few-Shot Representation Learning for Out-Of-Vocabulary Words》
这篇文章是发表在2019年NAACL上的,主要是针对out of vocabulary问题提出的想法。
这里感觉和bert,elmo的想法类似,提炼的都是词向量,只不过这篇文章是将提炼词向量去解决out of Vocabulary这一个小问题上,切入点比较好;而且这篇文章自己提出了一个模型去进行词向量的学习。而之前的语言模型是,从大规模语料当中学习到语言学的一些通用知识,从而去进行下游任务。
这篇文章提炼词向量的方法是通过层级context encoder+Model Agnostic Meta-Learning (MAML)学习算法。在Rare-NER和词性标注的下游任务中取得了显著的改善。
分以下四部分介绍:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
在真实世界当中,out of vocabulary, 不会频繁的出现在训练语料里,对这部分的表示进行学习是一个challenge。论文提出了一种层级注意力结构对有限的observations进行词向量表示。
用一个词的上下文信息去进行编码,并且只使用K个observations去训练模型(目的就是希望模型能够准确对出现频率较少的词进行表示)。
为了使模型对新的语料有着更好的鲁棒性,提出了一种新的训练方法ModelAgnostic Meta-Learning (MAML)
2、Model
2.1 The Few-Shot Regression Framework
Problem formulation
首先在训练集上,我们使用训练方法产生词向量。这些词向量作为我们训练的一个目标标签,Oracle embedding。训练方法(MAML)如下:首先从大规模语料当中选出n个词,对于每一个词,我们可以用St表式所有包含这个词的句子。为了训练我们的模型,解决out of vocabulary的问题,我们随机的采样所有词的k(2, 4, 6)个句子,形成一个episode,该episode为一个小样本。在这个语料当中去训练我们的模型,然后用新的测试语料Dn微调。如此反复进行训练。同时加入字符特征。最后我们选择余弦距离作为我们的评价指标,目标是想让模型生成的词向量和oracle embedding 尽可能的接近。
2.2 Hierarchical Context Encoding (HiCE)
模型结构如下:
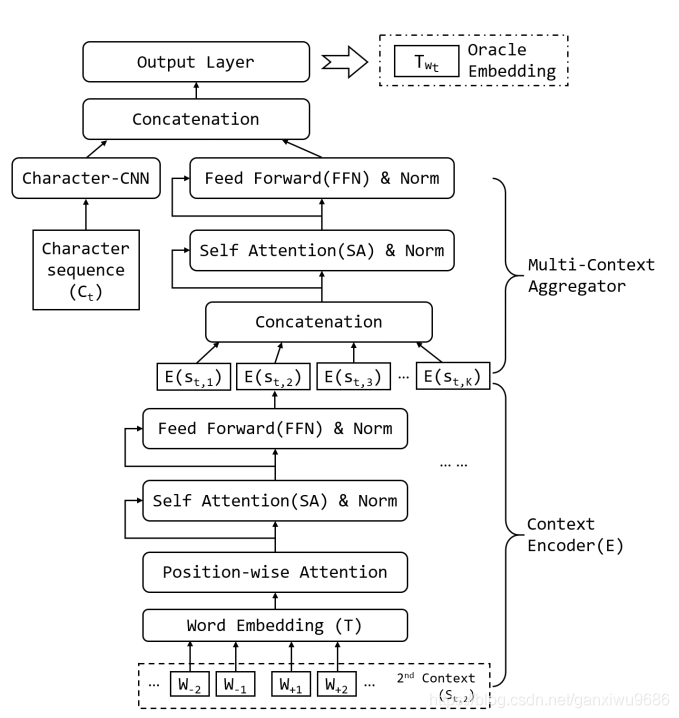
该模型也是训练一个语言模型,
输入:包含
w
t
w_t
wt 的
k
k
k 个句子
s
t
,
k
s_{t, k}
st,k ,其中
w
t
w_t
wt 被mask
输出:
w
t
w_t
wt 的词向量表示
模型结构主要分为两部分,第1部分是context encoder,第2部分是,Multi context Aggregator。
第1部分主要是对输入去进行一个transformer encoder的编码,得到每一个句子的表示,第2部分将这每一个句子的表示进行连接,再经过一个transformer encoder,并和字符特征去进行concatenation最后输出层得到词向量。模型结构比较简单,通过此模型结构能够去补获上下文的信息以及整体的全局信息。
都是标准的transformer,模型参数和计算过程就不赘述了。
3、Experiment
Present two types of experiments to evaluate the effectiveness of the proposed HiCE model.
- intrinsic evaluation–WikiText-103 (Merity et al., 2017)[1] WikiText-103 which used as Dt contains 103 million words extracted from a selected set of articles
- extrinsic evaluation
3.1 Intrinsic Evaluation: Evaluate OOV Embeddings on the Chimera Benchmark
Evaluate HiCE on Chimera (Lazaridou et al., 2017)[2], a widely used benchmark dataset for evaluating word embedding for OOV words,对于每一个OOV的单词,只有几个句子会出现,用Spearman correlation去评估结果的好坏。结果如下:
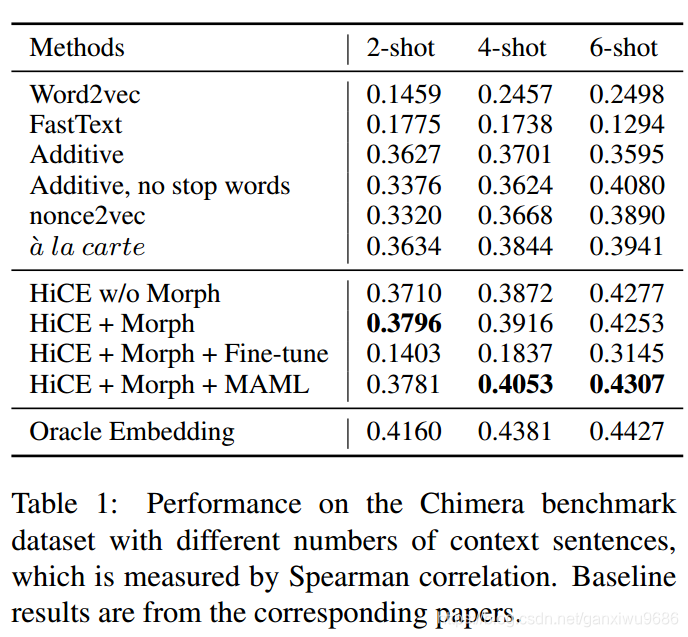
1、We can see that adapting with MAML can improve
the performance when the number of context sentences is relatively large (i.e., 4 and 6 shot), as it can mitigate the semantic gap between source corpus
D
T
D_T
DT and target corpus DN
3.2 Extrinsic Evaluation: Evaluate OOV Embeddings on Downstream Tasks
Named Entity Recognition
- Rare-NER: focus on unusual, previouslyunseen entities in the context of emerging discussions
- Bio-NER: focuses on technical terms in the biology domain
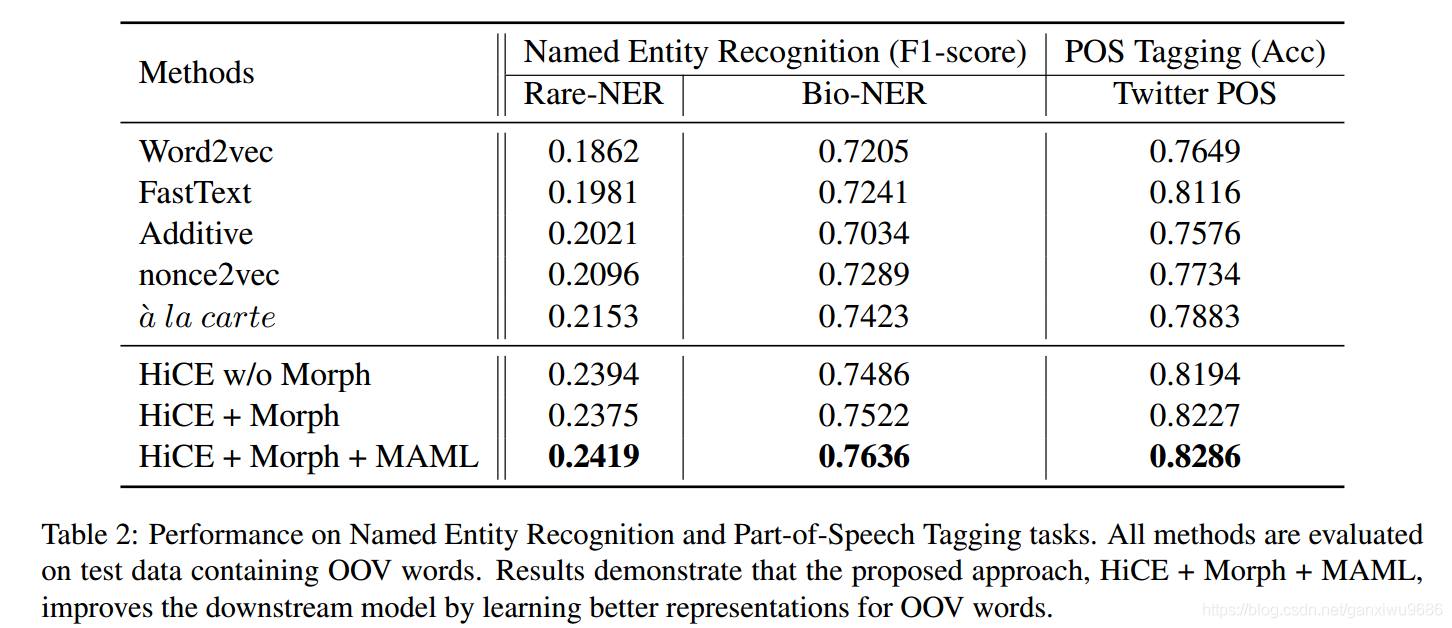
2、 The experiment demonstrates that HiCE trained on DT is already able to leverage the general language knowledge which can be transferred through different domains, and adaptation with MAML can further reduce the domain gap and enhance the performance
模型结构还是挺强的,上面说道HICE已经可以学习到跨领域的通用知识,并且通过MAML能够更好地减少领域鸿沟
4、Discussion
1、首先文章的切入点比较好,针对NLP领域的一个小问题,即OOV问题提出自己的解决方法。
2、从大规模语料库中提取词向量,并且使用一种新的结构作为语言模型提炼语言学中的一些通用知识。
3、为了减少领域之间的gap问题,使用MAML的学习方法,加强模型的鲁棒性。
4、实验中应该加入HICE+MAML的对比试验,因为MAML的微调既会对Morph产生影响,又会对结构产生影响。
5、如果直接用bert在这几个任务上实验,效果如何。
Reference
[1]Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2017. Pointer sentinel mixture models. In ICLR’17
[2]Angeliki Lazaridou, Marco Marelli, and Marco Baroni.2017. Multimodal word meaning induction from minimal exposure to natural text. Cognitive Science.

