
- 1成为一名合格的自动化测试工程师所要知道的学习步骤及学习误区_测试工程师学习流程
- 2Git【实践 01】使用Git工具托管本地代码到GitHub简单易懂的图文教程(含Git+第三方工具TortoiseGit+中文语言包百度云盘资源)_tortoisegit包百度云
- 3【ChatGLM】学习ChatGLM3-6B模型部署_chatgml3怎么加载chatgml3-6b模型
- 4保研之路——哈深计算机预推免_哈工深预推免机试真题
- 5php养老院管理系统 毕业设计-附源码202026_养老院管理系统er图
- 6Redis设置有效时间_设置redis有效时间
- 7CSDN超级实习生 | 除了高薪,你学习Java的理由是……_选择成为java实习生的理由
- 8openssl 如何从pfx格式证书 获取证书序列号信息
- 9WIN32中GetCommandLine函数_win32 getcommandline()
- 10数据结构——顺序栈的初始化、入栈、出栈、返回栈顶元素、十进制转换为n进制
论文笔记--ERNIE: Enhanced Language Representation with Informative Entities_zhang 2, han x, liu 2, et al. ernie: enhanced lang
赞
踩
论文笔记--ERNIE: Enhanced Language Representation with Informative Entities
1. 文章简介
- 标题:ERNIE: Enhanced Language Representation with Informative Entities
- 作者:Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, Qun Liu
- 日期:2019
- 期刊:ACL
2. 文章概括
文章提出了ERNIE(Enhanced Language Representation with Informative Entities),一种可以将外部知识融合进入预训练模型的方法。数值实验表明,ERNIE可以提升一些知识驱动的下游任务的表现,且在其它NLP任务上效果基本持平SOTA。
3 文章重点技术
3.1 模型框架
给定token序列
{
w
1
,
…
,
w
n
}
\{w_1, \dots, w_n\}
{w1,…,wn},其中
n
n
n为序列长度,令
{
e
1
,
…
,
e
m
}
\{e_1, \dots, e_m\}
{e1,…,em}表示对应的实体序列,其中
m
m
m为实体数。一般来说
m
<
n
m<n
m<n,这是因为不是每个token都可以映射为知识图谱(KG)中的实体(entity),且一个实体可能对应多个token,比如"bob dylan"两个token对应一个实体"Bob Dylan"。记所有token的词表为
V
\mathcal{V}
V,KG中所有实体的集合为
E
\mathcal{E}
E。如果对
v
∈
V
v\in\mathcal{V}
v∈V,存在与其对应的实体
e
∈
E
e\in\mathcal{E}
e∈E,则我们用
f
(
v
)
=
e
f(v)=e
f(v)=e表示这种对齐关系。特别地,针对上述多个token对应单个实体的情况,我们将实体对齐给第一个token,例如句子中出现"bob dylan…"时,
f
(
"bob"
)
=
"Bob Dylan"
f(\text{"bob"}) = \text{"Bob Dylan"}
f("bob")="Bob Dylan"。
如下图所示,ERNIE的整体框架分为两部分:1) T-Encoder(Textual encoder),用于捕捉基本的词义和句法信息;2) K-Encoder(Knowledgeable encoder),用于将外部知识融合进入模型。记T-Encoder的层数为
N
N
N,K-Encoder的层数为
M
M
M。
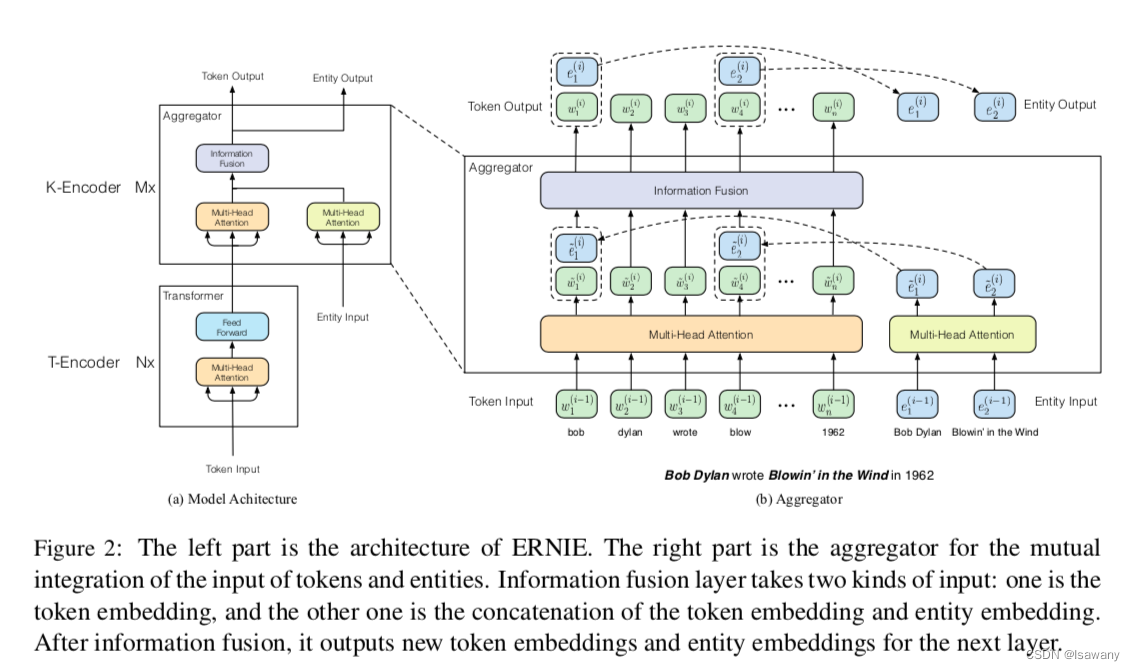
具体来说,给定输入序列
{
w
1
,
…
,
w
n
}
\{w_1, \dots, w_n\}
{w1,…,wn}和对应的实体序列
{
e
1
,
…
,
e
m
}
\{e_1, \dots, e_m\}
{e1,…,em},T-encoder层首先将token序列、segment序列和位置序列输入得到词汇和句法层面的特征
{
w
1
,
…
,
w
n
}
=
T-Encoder
(
{
w
1
,
…
,
w
n
}
)
\{\bold{w}_1, \dots, \bold{w}_n\} = \text{T-Encoder}(\{w_1, \dots, w_n\})
{w1,…,wn}=T-Encoder({w1,…,wn}),其中T-Encoder结构和BERT[1]相同,基本架构为Transformer的Encoder层。
然后将上述特征传入到K-Encoder层。K-Encoder还会接受外部知识信息,首先我们会通过TransE生成
{
e
1
,
…
,
e
m
}
\{e_1, \dots, e_m\}
{e1,…,em}对应的预训练实体嵌入
{
e
1
,
…
,
e
m
}
\{\bold{e}_1, \dots, \bold{e}_m\}
{e1,…,em},然后将该嵌入同上述特征
{
w
1
,
…
,
w
n
}
\{\bold{w}_1, \dots, \bold{w}_n\}
{w1,…,wn}一起输入K-Encoder层从而得到融合外部知识的输出嵌入:
{
w
1
o
,
…
,
w
n
o
}
,
{
e
1
o
,
…
,
e
m
o
}
=
K-Encoder
(
{
w
1
,
…
,
w
n
}
,
{
e
1
,
…
,
e
m
}
)
\{\bold{w}_1^o, \dots, \bold{w}_n^o\},\{\bold{e}_1^o, \dots, \bold{e}_m^o\} = \text{K-Encoder}(\{\bold{w}_1, \dots, \bold{w}_n\},\{\bold{e}_1, \dots, \bold{e}_m\})
{w1o,…,wno},{e1o,…,emo}=K-Encoder({w1,…,wn},{e1,…,em}),上述输出嵌入后续可用来作为特征参与下游任务。
3.2 K-Encoder(Knowledgeable Encoder)
如上图所示,K-Encoder包含堆叠的聚合器,每个聚合器包含token和实体两部分输入。在第
i
i
i个聚合器中,输入为来自上层聚合器的嵌入
{
w
1
(
i
−
1
)
,
…
,
w
n
(
i
−
1
)
}
\{\bold{w}_1^{(i-1)}, \dots, \bold{w}_n^{(i-1)}\}
{w1(i−1),…,wn(i−1)}和实体嵌入
{
e
1
(
i
−
1
)
,
…
,
e
m
(
i
−
1
)
}
\{\bold{e}_1^{(i-1)}, \dots, \bold{e}_m^{(i-1)}\}
{e1(i−1),…,em(i−1)},然后将token和实体嵌入分别传入到两个多头自注意力机制MH-ATTs得到各自的输出:
{
{
w
~
1
(
i
)
,
…
,
w
~
n
(
i
)
}
=
MH-ATT
(
{
w
1
(
i
−
1
)
,
…
,
w
n
(
i
−
1
)
}
)
{
e
~
1
(
i
)
,
…
,
e
~
m
(
i
)
}
=
MH-ATT
(
{
e
1
(
i
−
1
)
,
…
,
e
m
(
i
−
1
)
}
)
3.3 预训练任务
为了将知识融合进入语言表达,文章提出了一种新的预训练任务:dEA(denoising entity auto-encoder):随机掩码一些token-entity的对齐,然后让模型给予对齐的tokens来预测被掩码的实体。具体来说,给定输入序列
{
w
1
,
…
,
w
n
}
\{w_1, \dots, w_n\}
{w1,…,wn}和对应的实体序列
{
e
1
,
…
,
e
m
}
\{e_1, \dots, e_m\}
{e1,…,em},通过下述公示预测token
w
i
w_i
wi对应的实体分布:
p
(
e
j
∣
w
i
)
=
exp
(
linear
(
w
i
o
)
⋅
e
j
)
∑
k
=
1
m
exp
(
linear
(
w
i
o
)
⋅
e
k
)
p(e_j|w_i) = \frac {\exp (\text{linear}(\bold{w}_i^o) \cdot \bold{e}_j)}{\sum_{k=1}^m \exp (\text{linear}(\bold{w}_i^o) \cdot \bold{e}_k)}
p(ej∣wi)=∑k=1mexp(linear(wio)⋅ek)exp(linear(wio)⋅ej)。
考虑到实际对齐过程中可能存在一些错误,我们增加如下策略:1)5%的时间用随机的实体替代当前实体,使得模型纠正token-实体对齐错误的情况 2)15%的时间将token-实体对齐进行掩码,使得模型可以纠正当实体对齐为被识别到的情况 3)其余时间保持token-实体对齐不变,从而使得模型学习到token和实体之间的对齐方法。
最终,ERNIE使用MLM、NSP和上述dEA三种训练目标。
3.4 微调
类似于BERT,我们使用[CLS]的嵌入作为句子的最终嵌入表示来进行分类。针对关系分类任务,我们增加[HD]和[TL]表示head/tail实体的开头和结尾;针对实体抽取任务,我们增加[ENT]表示实体位置。
4. 文章亮点
文章提出了一种可以将外部信息融合至预训练的ERNIE模型。实验表明,ERNIE可以有效地将KG中的信息注入到预训练模型,从而使得模型在处理实体提取、关系分类等需要外部知识的任务时更加出色,且实验证明外部知识可以帮助模型充分利用少量的训练集。
5. 原文传送门
ERNIE: Enhanced Language Representation with Informative Entities
6. References
[1] 论文笔记–BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[2] 百度ERNIE论文笔记–ERNIE: Enhanced Representation through Knowledge Integration

