Multimodal Foundation Models:From Specialists to General-Purpose Assistants(Chapter 4)
赞
踩
Multimodal Foundation Models:From Specialists to General-Purpose Assistants
Chapter 4 Unified Vision Models
4.1 Overview
Challenges:
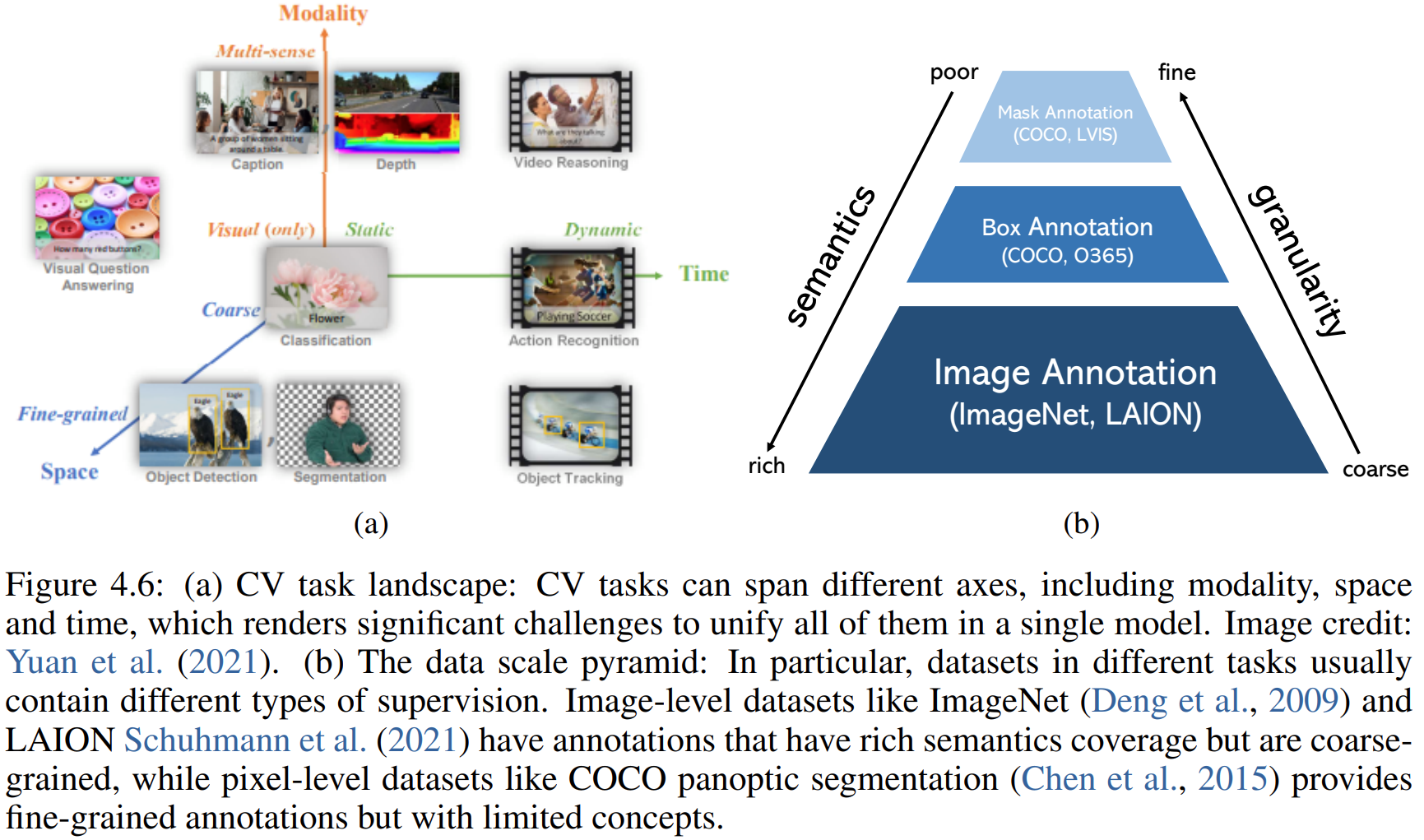
输入类型很多:图片、视频,纯视觉输入、多模态输入;
不同任务粒度不同:图片级别的分类、描述,区域级别的检测、grounding,像素级别的分割,超分辨率。
输出的形式也不同:空间信息如边缘、框、掩码,语义信息如单类别标签、多类别标签、细节描述。
数据集:标注类型差别非常大,相比文本数据,视觉数据很难获得,所以一般视觉数据集比文本数据集小一些。
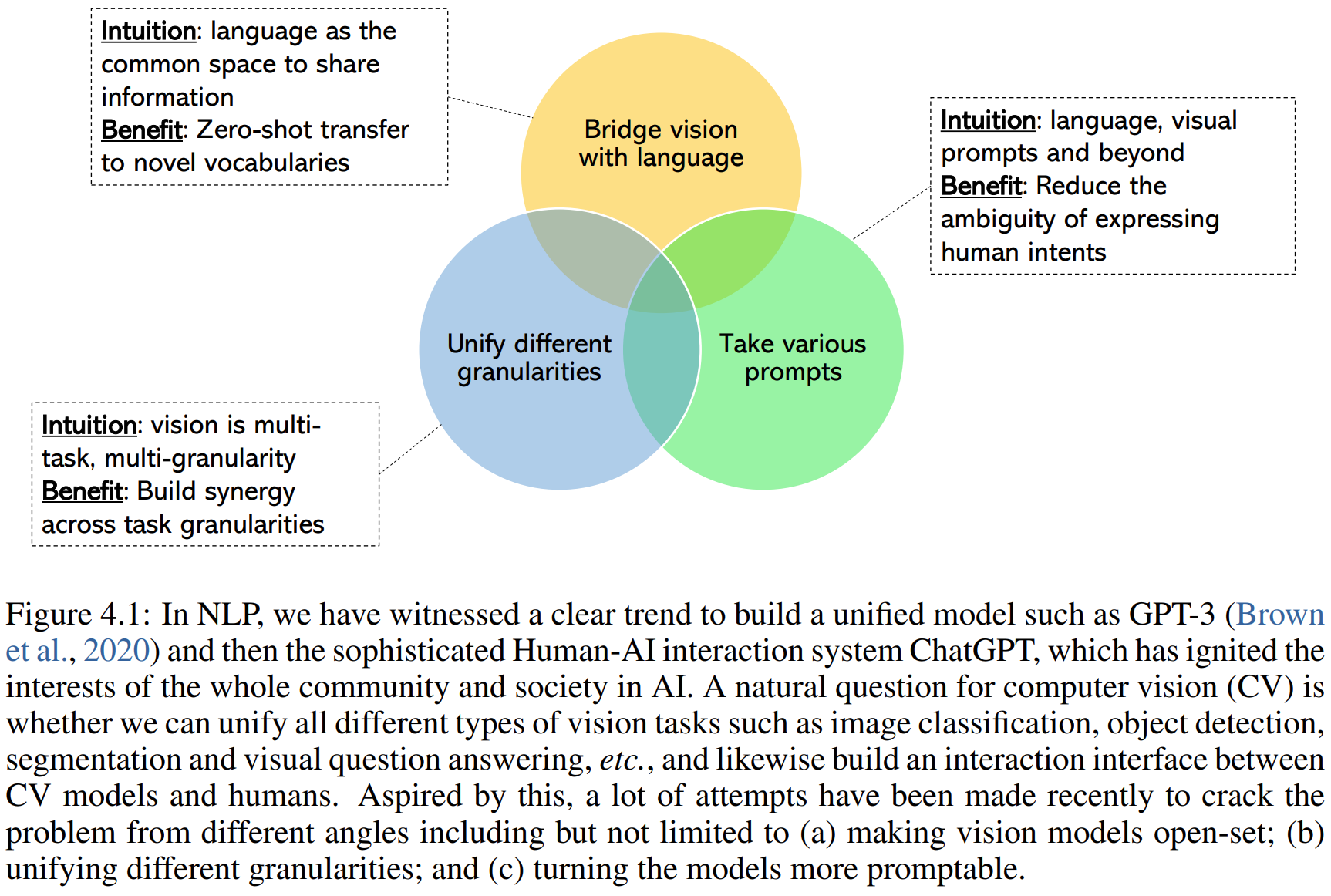
Towards a unified vision model:Bridging vision and language:CLIP,Unified multi-task modeling,LLM-like promptable interface
4.2 From Closed-Set to Open-Set Models
Model initialization:CLIP initialized,CLIP augmented。
Model design:Two-stage models:解耦了位置和分割,End-to-end models如GLIP。
Model pre-training:Supervised learning,Semi-supervised learning,Weakly-supervised learning
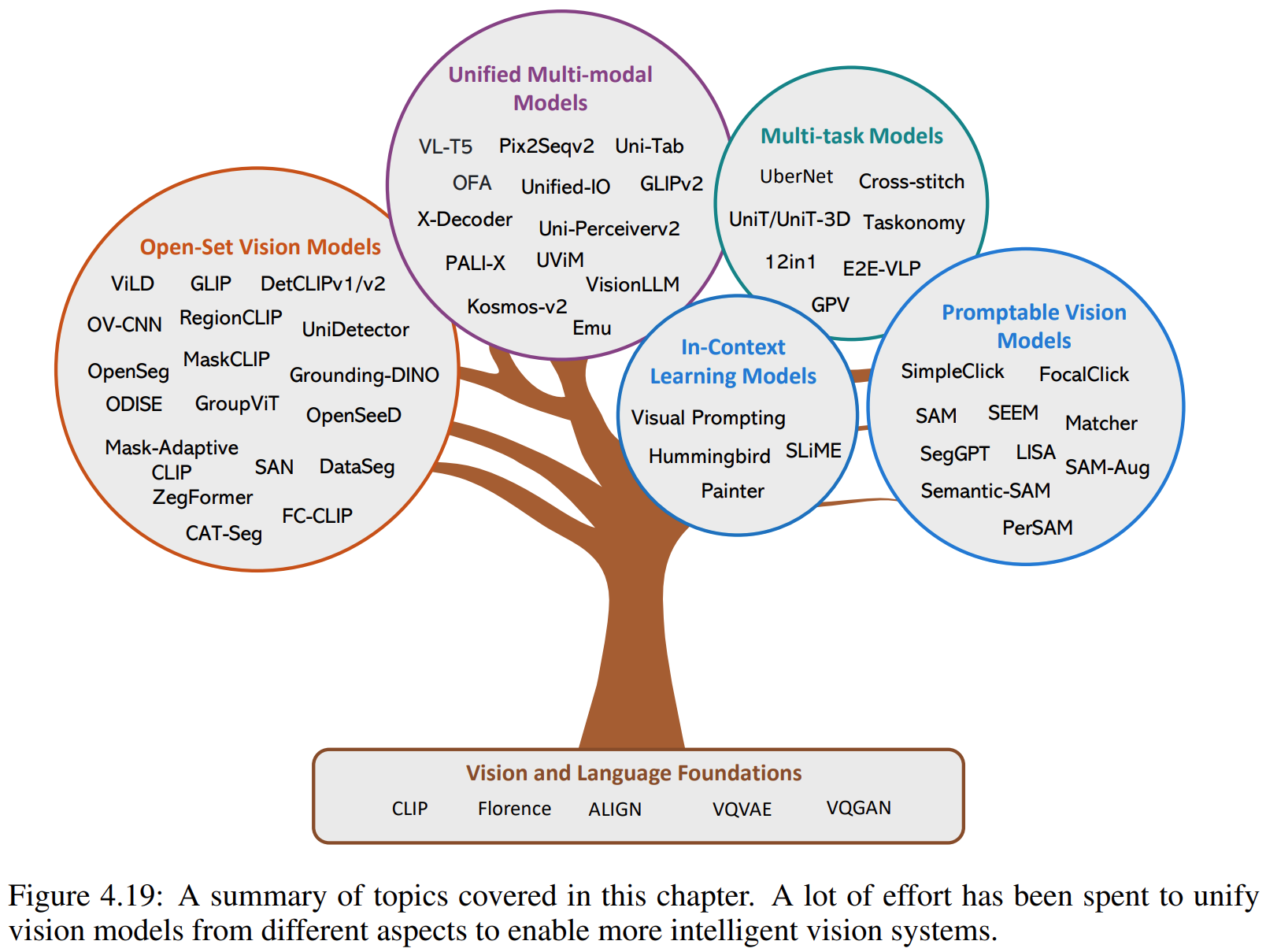
4.3 From Task-Specific Models to Generic Models
I/O Unification:将许多视觉任务重新表述为一个序列到序列的问题
Functionality Unification:需要复杂的模型设计来适应各种任务
这两种统一方法都努力利用不同粒度级别任务之间的协同作用。例如,粗粒度数据有望有助于细粒度任务所需的丰富语义支持,而经过精细训练的数据则可以增强粗粒度任务的基础能力。

4.3.1 I/O Unification
Sparse and discrete outputs

LLM-augmented
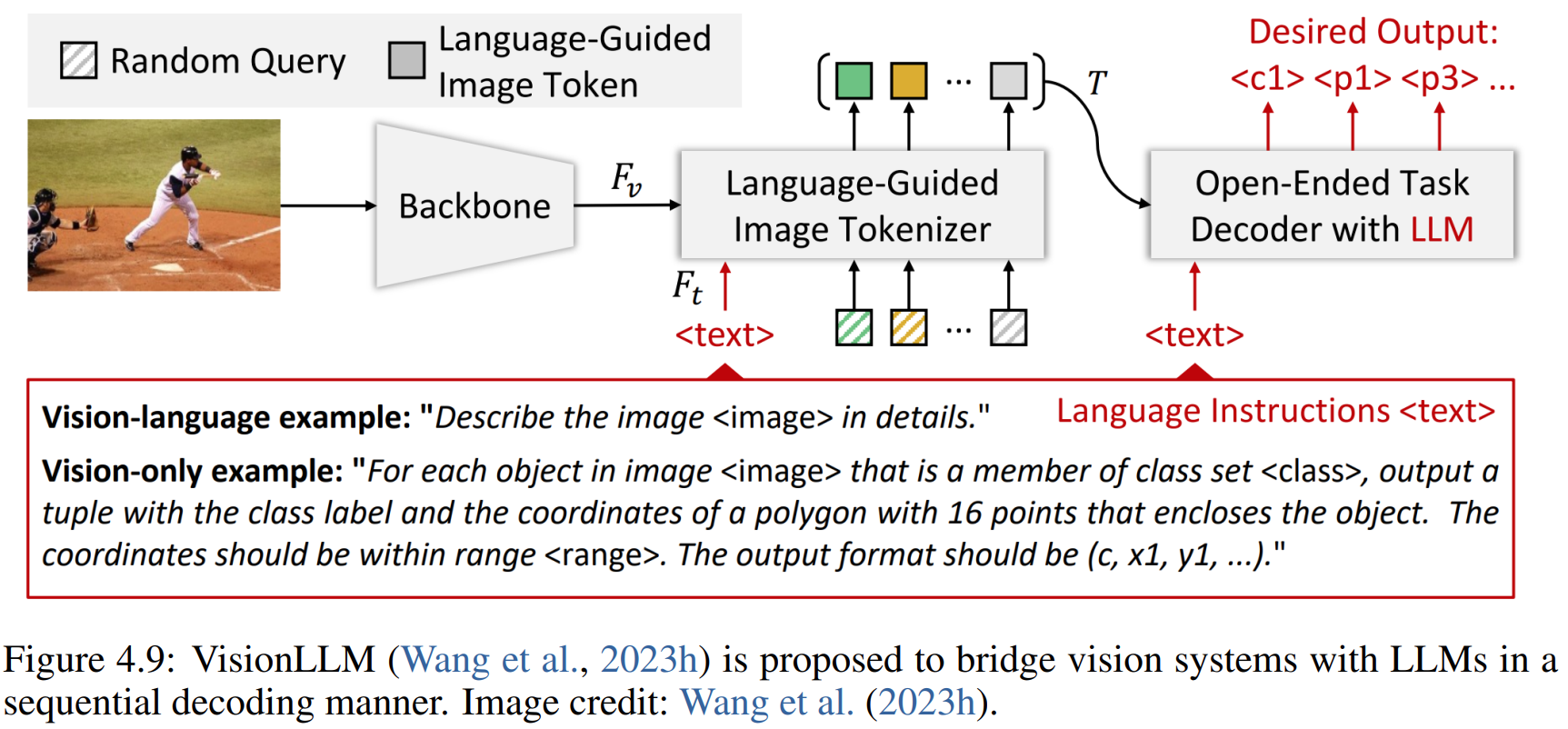
Dense and continuous outputs
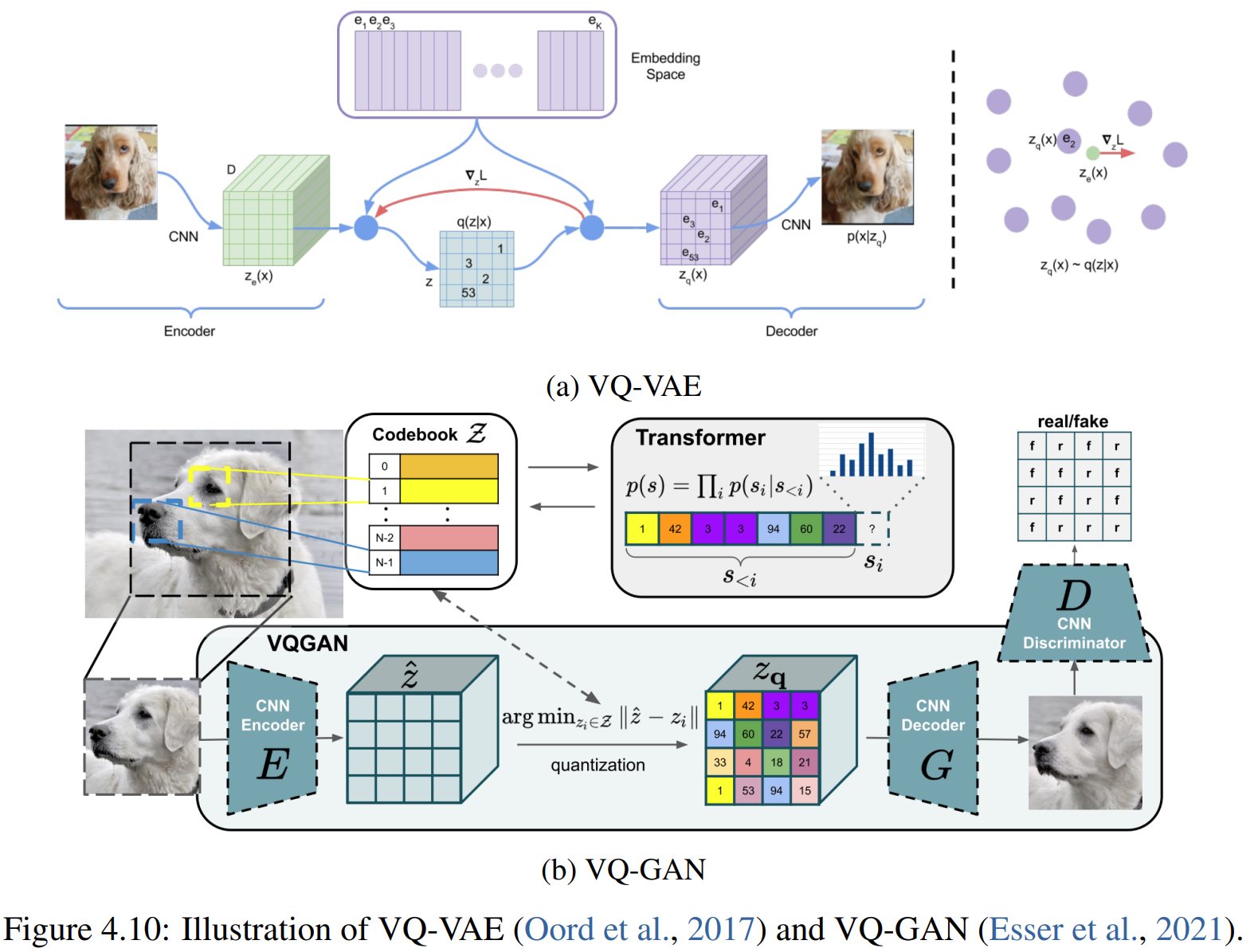

Diffusion-augmented:Prompt Diffusion,ControlNet,InstructDiffusion
4.3.2 Functionality Unification
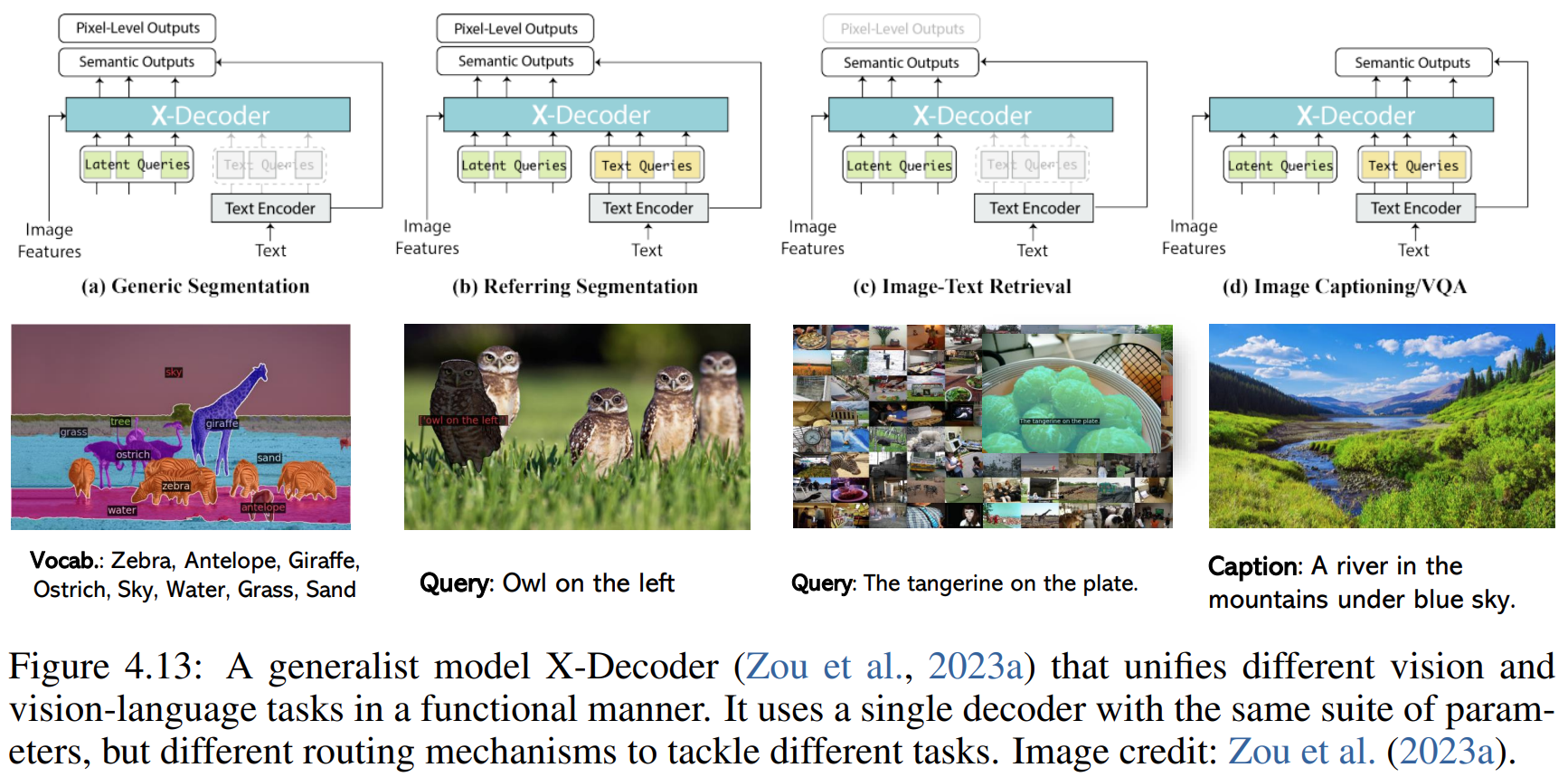
涉及几个模型:GLIPv2,X-Decoder,Uni-Perceiver-v2
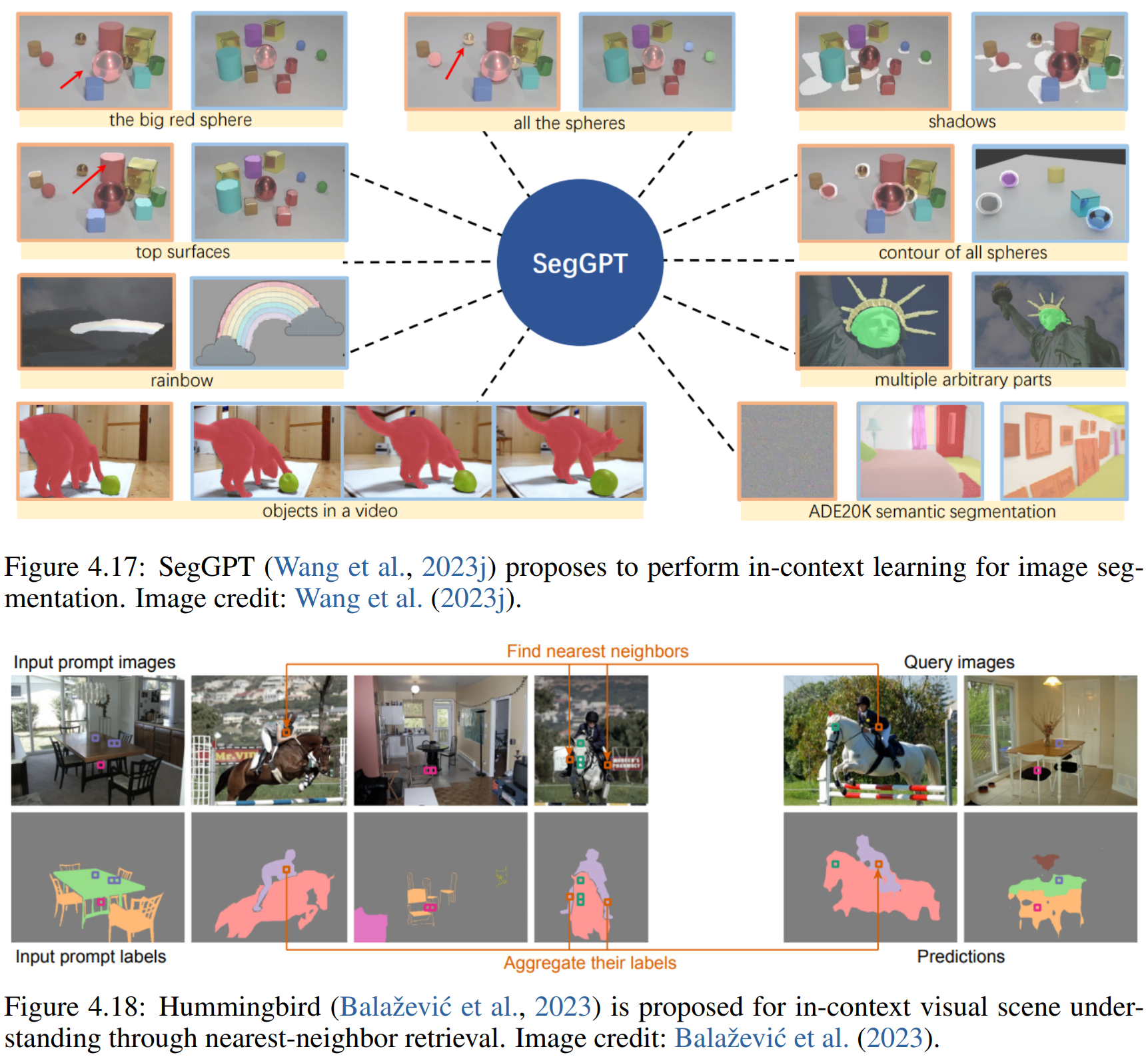
4.4 From Static to Promptable Models

涉及的模型:PerSAM,SEEM,ImageBind,Prismer等