
- 1萌新的51之旅——AD转换(2)_逐次比较型ad转换器与双积分,转换速度慢
- 2在python中,删除列表中不含“1,2,3,4,5,6,7,8,9,0”字符的元素
- 3Pandas进行数据分析
- 4LVGL_V8.3入门四---圆形表盘UI设计(字体、图片、时间显示设计)_lvgl计时器设计
- 5Git 多账号配置_git多账号配置
- 6kali监听win2008;反弹shell;msf生成木马;留后门;权限维持;_payload=什么kali可以监听
- 7如何从零到有开始进行git仓库的建立上传,以及所遇到的问题及解决方法_git创建本地仓库并上传
- 8若依分离版的文件上传_若依文件上传
- 9使用easyexcel模板导出的两个坑(Map空数据列错乱和不支持嵌套对象)_easyexcel 导出数据移位
- 10uni-app开发微信小程序 vue3写法添加pinia_uni-app 自动注入所有pinia模块 写法
11.JAVAEE之网络原理1
赞
踩
1.应用层(和程序员接触最密切)
应用程序
在应用层这里,很多时候, 都是程序员"自定义"应用层协议的,(当然,也是有一些现成的应用层协议)(这里的自定义协议,其实是非常简单的~~协议 =>约定,程序员在代码中规定好,数据如何进行传输)
1.根据需求, 明确要传输的信息
2.约定好信息按照什么格式来组织
1.1 几种开发中常见的格式
1.xml(叉 ml)
上古时期的组织数据的格式.现在很少用于网络通信了.但是在后面还会有一些地方遇到
通过标签来组织数据。
xml 的优势:
让数据的可读性变的更好了
xml 的劣势:
标签写起来非常繁琐,传输的时候也占用更多网络带宽,

HTML 也是这种标签格式的数据HTML 属于是 xml 的变种,
xml是一个通用的数据格式, 这里有啥标签, 标签有啥含义都是程序员自定义的
html则是一个专属的数据格式.有啥标签, 标签是啥含义都是有一个标准委员会,规定好的.
2. json(当下最流行的一种数据组织格式)
键值对结构.
{}把所有的键值对给包裹起来
键值对之间,使用""来分割
键和值之间, 使用":"来分割键固定就是 string 类型值的话,可以是数字,可以是字符串, 也可以是 json,还可以是数组....由于 json 的 key 固定就是字符串类型,很多时候也是可以把 key 的引号给省略的

json 的优势:
可读性比较好的; 比 xml 更简洁.json 的劣势:
同样也是会在网络传输中,消耗额外的带宽(需要把 key 也进行传输的)虽然如此,ison 在网络通信中仍然非常流行,除非是一些对于性能要求非常高的场景,不使用 json 之外,其余的很多地方都可以使用json.
3.protobuffer
相比于json 和 xml 来说,protobuffer(简称为 pb)使用二进制的方式来组织数据可以保证带宽占用最低(相当于把要传递的信息按照二进制形式压缩了)
pb 的优势:
占用带宽最低,传输效率最高.非常适合于对于性能要求比较高的场景.pb 的劣势:
可读性不好(二进制结构,肉眼无法直接阅读)定程度的影响开发效率
- 应用层中也有一些"现成"的应用层协议,其中最知名的,最广泛使用的, 就是 HTTP 协议了(超文本传输协议)
- "超文本"不仅仅是文本,图片,视频,音频,字体.....
2.传输层 (重点)
UDP
无连接,不可靠,面向数据报,全双工
TCP
有连接,可靠传输,面向字节流,全双工
端口号
写一个服务器,必须手动指定一个端口号,通过端口来区分当前这个主机上的不同的应用程序写一个客户端,客户端在通信的时候也会有一个端口号 (代码中感受不到),系统自动分配的.
端口号, 固定就是占 2 个字节
表示的数据范围 0->65535
一般来说,0 是不用的。
2.1 UDP协议
学习一个协议,其中最主要的工作,就是去理解协议报文格式
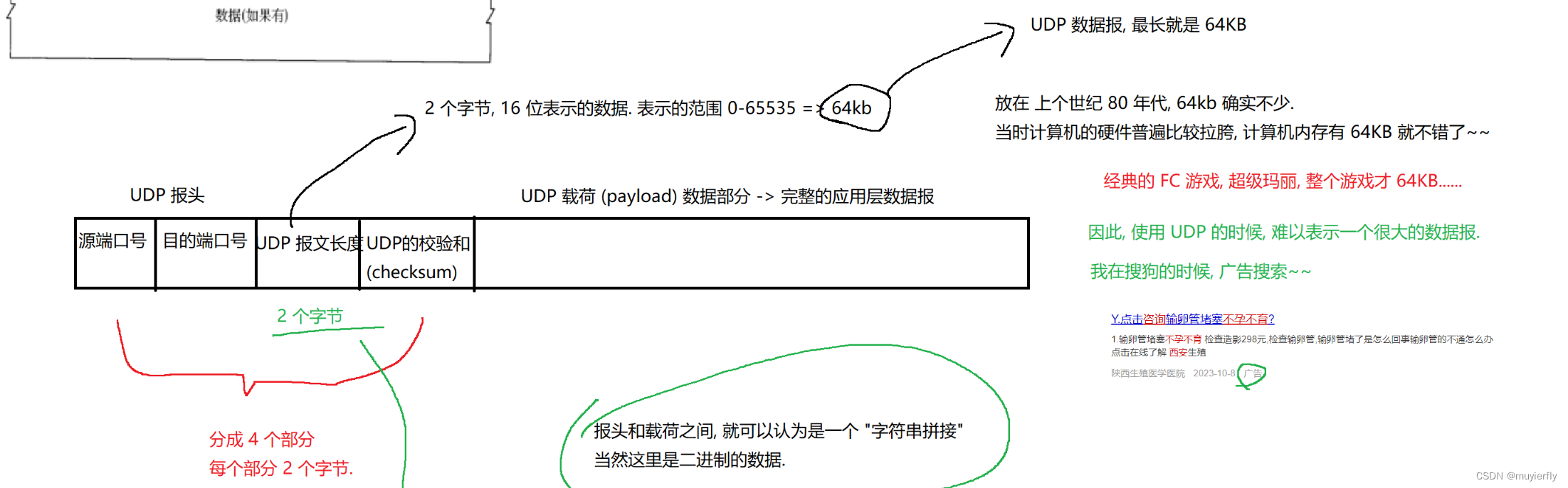
报头和载荷之间,就可以认为是一个"字符串拼接当然这里是二进制的数据.
像 UDP TCP 这样的报文格式,是谁规定的呢??
有一些组织(一群大佬们,最初设计约定的)约定出来的内容,被整理成了一份 标准文档,称为 RFC 标准文档.
源 ip, 目的 ip 在哪里??
不在传输层, 而是在网络层(IP 协议里)
UDP报文长度超过64K怎么解决???
1.把数据拆分成多个包, 使用多个 UDP 数据报进行传输
这个方案,不合理~~(开发成本,比较大)拆包,如何组包(很大的开发成本和测试成本)
2.直接使用 TCP .TCP 没有包大小的限制.
校验和
检测UDP数据报在传输中是否有错,有错则丢弃。
前提: 网络传输中,由于一些外部干扰,就可能会出现数据传输出错的情况。光信号/电信号
磁场,电场, 高能离子... 某个地方本来是传输低电平,在干扰下就成了高电平了翻转
因此,就需要有办法,能够识别出出错的数据校验和,其实本质上也是一个字符串,体积比原始的数据更小, 又是通过原始的数据生成的.
原始数据相同,得到的校验和就一定相同.
反之, 校验和相同, 原始数据大概率相同 (理论上会存在不同的情况, 实际的概率非常低,可以忽略不计)
如何基于校验和来完成数据校验呢?
1.发送方,把要发送的数据整理好(称为 data1),通过一定的算法,计算出校验和 checksum1
2.发送方把 data1 和 checksum1 一起通过网络发送出去,
3.接收方收到数据,收到的数据称为 data2(数据可能和 data1 就不一样了),收到数据 cHecksum1
4.接收方再根据 data2 重新计算校验和 (按照相同的算法),得到 checksum2
5.对比 checksum1 和 checksum2 是否相同. 如果不同, 则认为 data2 和 data1 一定不相同.
如果 checksum1 和 checksum2 相同,则认为 data1 和 data2 大概率是相同的 (理论上存在不同的可能性,概率比较低,工程上忽略不计)
校验和是怎么算的??
计算校验和,有很多种算法.
此处 UDP 中使用的是:CRC 算法(循环冗余算法)
把当前要计算校验和的数据,每个字节,都进行累加,把结果保存到这个 两个字节的 变量中.累加过程中如果溢出,也没关系
如果中间某个数据,出现传输错误,第二次计算的校验和就会和第一次不同~~
CRC这个算法其实不是特别的靠谱,导致两个不同的数据,得到相同的 crc 校验和的概率比较大前一个字节恰好 少 1,后一个字节恰好 多 1. (这种情况概率确实不大,但是确实也还是有这方面的风险)md5/sha1 算法 (就只介绍 md5)
1.定长.
无论你原始数据多长,计算得到的 md5,都是固定长度校验和本身就不应该很长,要不然不方便网络传输
2.分散.给定两个原始数据,哪怕绝大部分内容都一样,只要其中-个字节不同,得到的 md5 值都会差异很大
md5 也非常适合作为 hash 算法
【哈希表
哈希表是要把一个 key 通过 hash 函数,转换成 数组 下标希望 hash 函数能够做到尽量分散,产生 hash 冲突的概率才会比较低】
3.不可逆
给你一个原始数据,计算 md5,非常容易给你 md5,还原出原始数据,计算量非常庞大,以至于超出了现有计算机的算力极限,理论上是不可行的,
md5 也可以应用在一些密码学场景中
有一些应用层协议,基于 UDP 来实现的,其实并不算很多相比于 UDP 来说, TCP 在更多的情况下,是具有优势的,很多时候,都是优先考虑使用 TCP

2.2 TCP协议 (最大的特点是可靠传输)
可靠传输是TCP的初心
2.2.1 TCP的相关特性

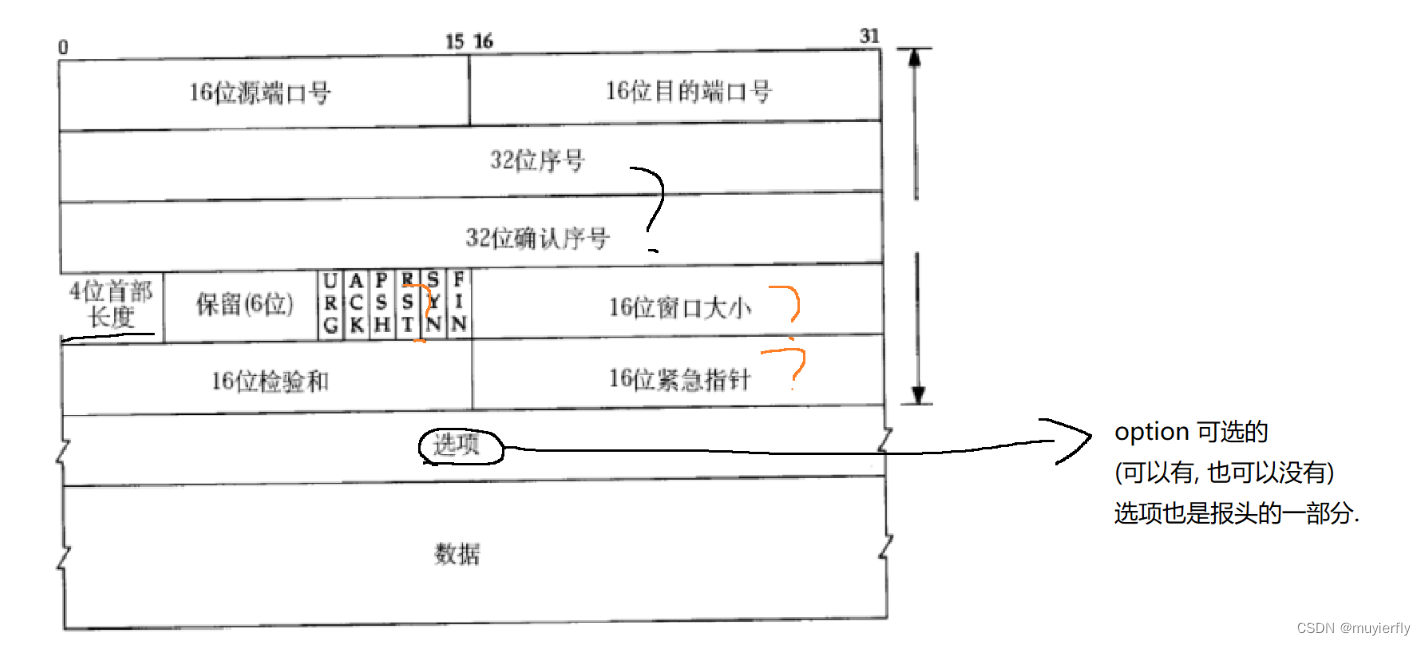

可靠传输,不是说, 发送方把数据能够 100% 的传输给接收方~~(要求太高了)
退而求其次~~
1)发送方发出去数据之后, 能够知道接收方是否收到数据.2)一旦发现对方没收到,就可以通过一系列的手段来"补救”
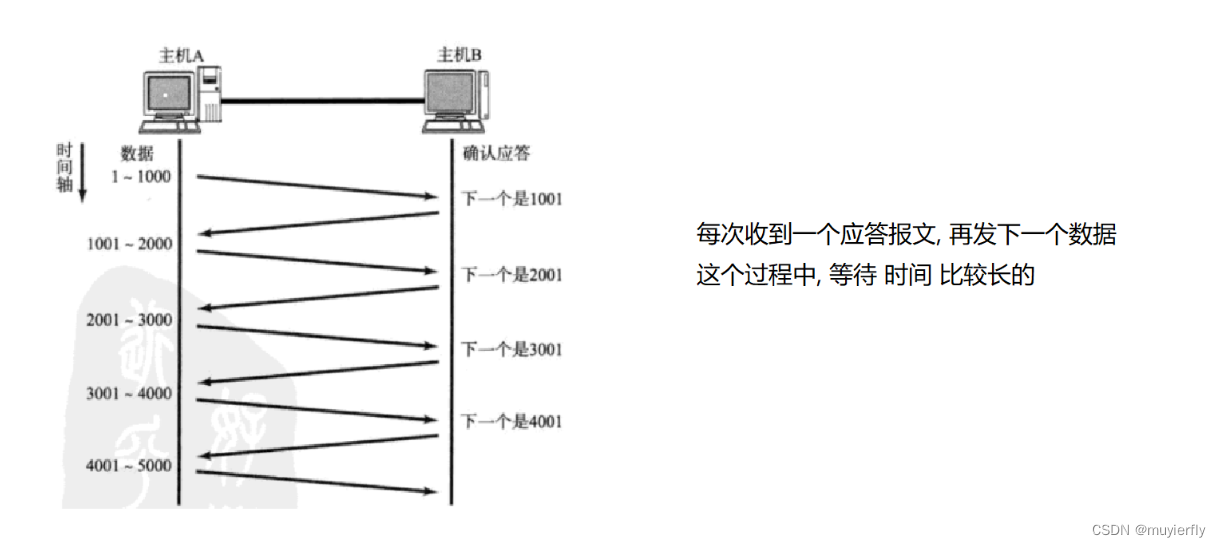
1.确认应答
发送方,把数据发给接收方之后,接收方收到数据就会给发送方返回一个 应答报文(acknowledge, ack)发送方,如果收到这个应答报文了,就知道自己的数据是否发送成功了
【网络传输还有可能收到后发先至的情况】
一个数据包在进行传输的过程中走的路径可能是非常复杂的,不同的数据包,可能走不同的路线。
TCP 在此处要完成两个工作:
1.确保应答报文和发出去的数据, 能对上号,不要出现歧义,
2.确保在出现后发先至的现象时,能够让应用程序这边仍然按照正确的顺序来理解数据【引入序号,序号就是一个整数.大小关系,就描述了数据的先后顺序!】【更准确的说,序号不是按照"一条两条"方式来进行编号的,而是按照字节来编号的!!】
通过特殊的 ack 数据包,里面携带的"确认序号"告诉发送方, 哪些数据已经被确认收到了此时发送方,就心中有数了,就知道了自己刚发的数据是到了还是没到.=>可靠传输
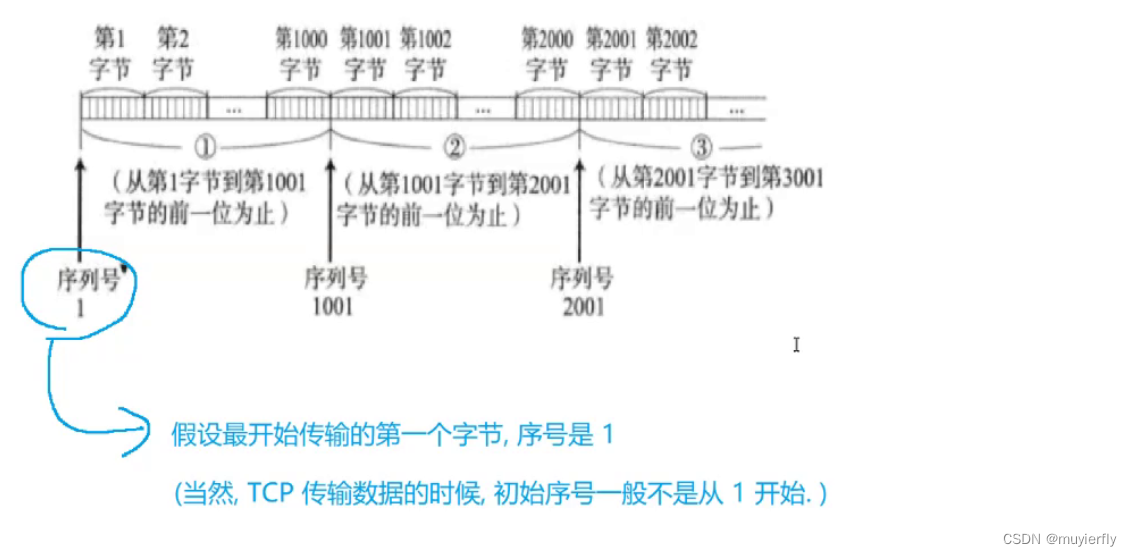
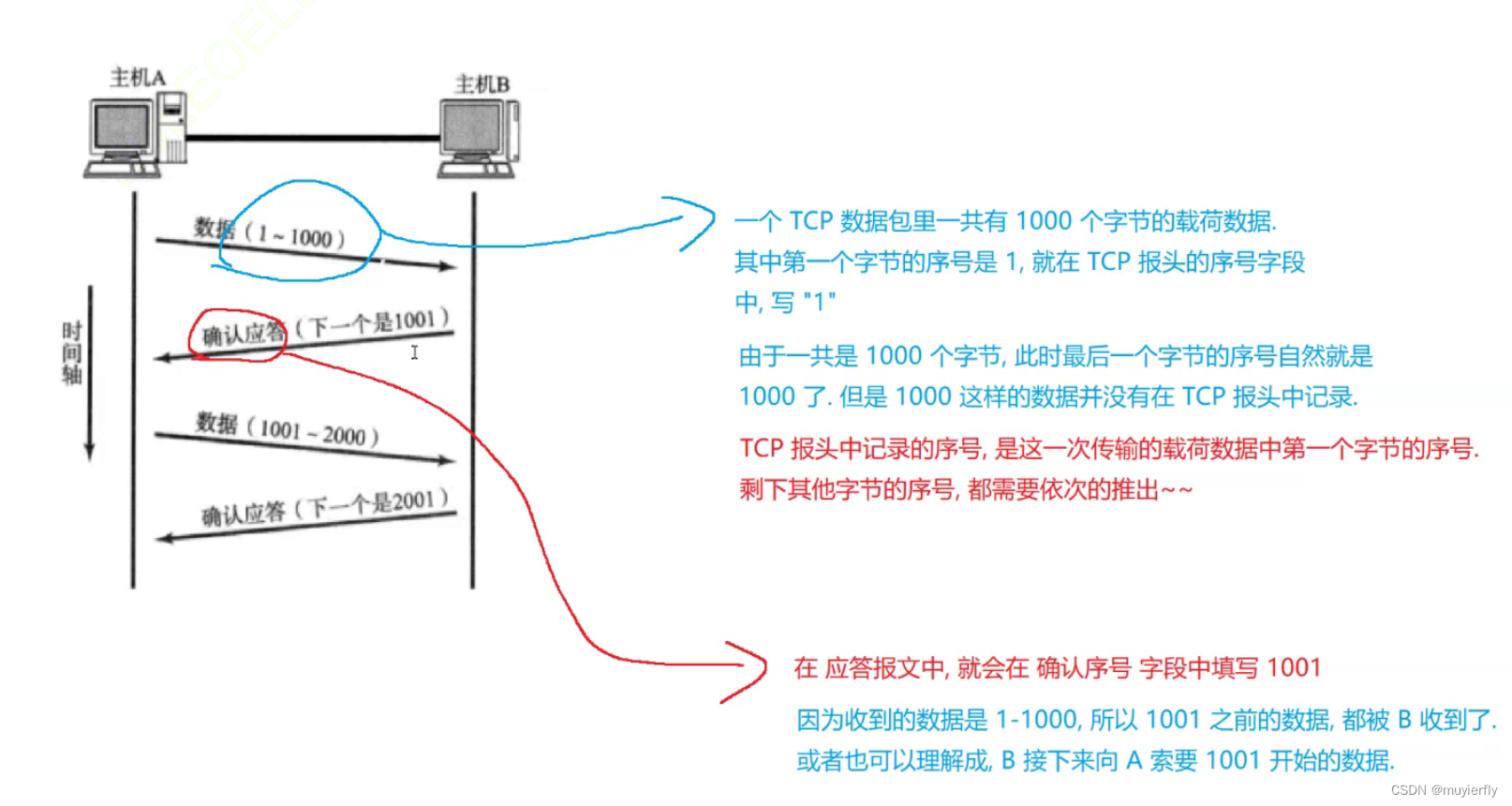

TCP 的初心,是为了实现可靠传输 =>达成可靠传输的最核心的机制, 就是 确认应答
常见面试题:TCP 是如何保证可靠传输的??
正确答案: 通过确认应答为核心,借助其他机制辅助最终完成可靠传输
2.超时重传
确认应答,描述的是一个比较理想的情况(出现丢包了,咋办??
如果网络传输过程中发送方,势必就无法收到 ACK 了~
使用超时重传机制,针对确认应答,进行补充
站在发送方来说,无法区分这两种情况
无论出现上述哪种情况,发送方都会进行"重新传输第一次是丢了,重传一下试试,很大概率就能传过去~~(重传就是一个很好的丢包下的补救措施了)
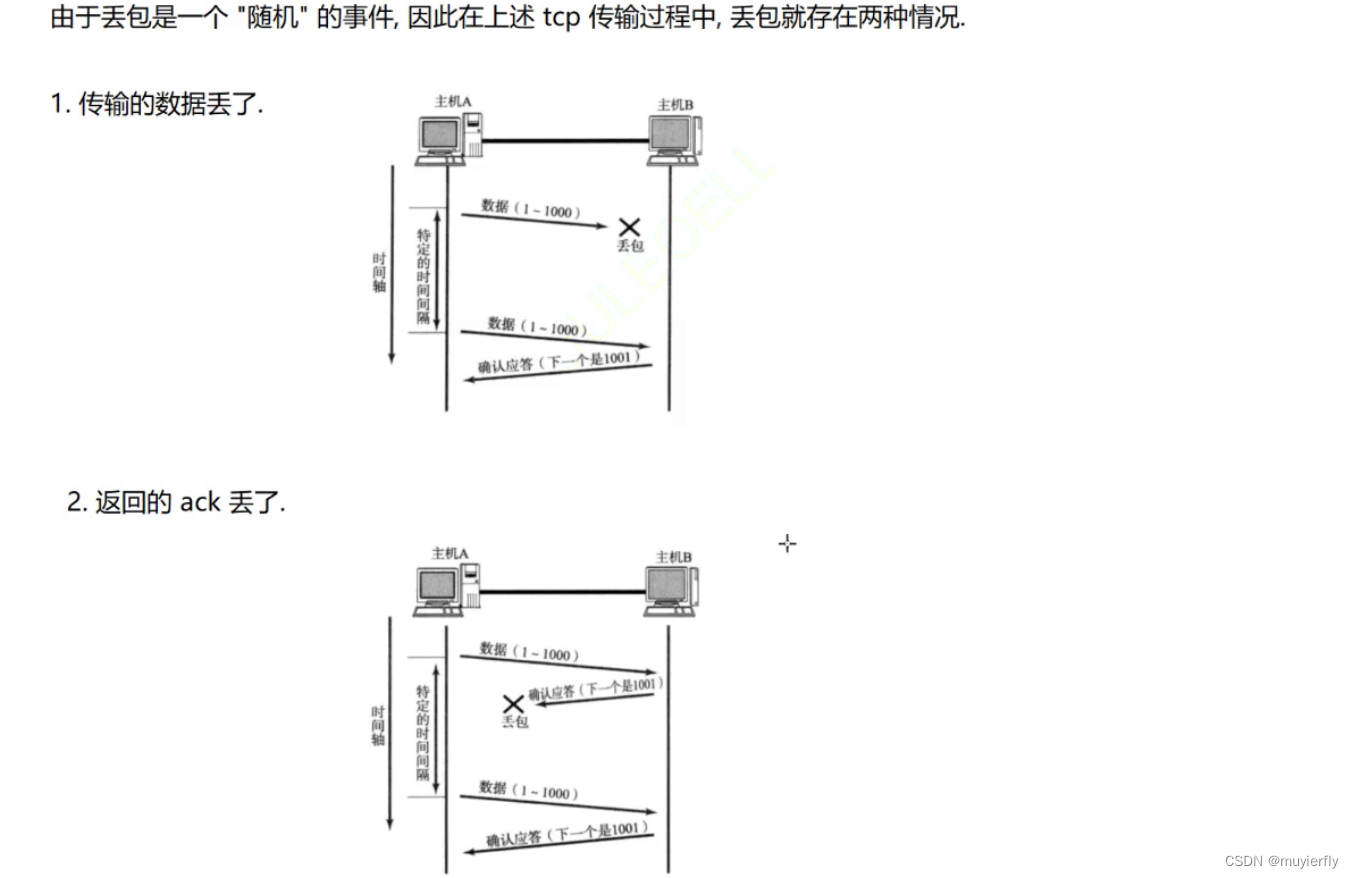
发送方,何时进行重传?等待时间~~
发送方,发出去数据之后,会等待一段时间.如果这个时间之内, ack 来了,此时就自然视为数据到达如果达到这个时间之后,数据还没到,就会出发重传机制~~ (超过了等待时间再重传)
1.初始的等待时间,是可配置的,不同的系统上都不一定一样.
也可以通过修改一些内核参数来引起这里的时间变化.
2.等待的时间,也会动态变化.
每多经历一次超时,等待时间都条变长(变长, 隐含的含义,就是对能够正确传输数据这件事非常悲观~~)A ->B发了一条数据,
第一次, A 等待 ACK 的时间,假设是 50ms
此时如果达到 50ms, 还没有 ack, A 就重传
当 A 重传的数据,还是没有收到 ack,第二次等待的时间就会比第一次更长
拉长也不是无限拉长,重传若干此时, 时间拉长到一定程度,认为数据再怎么重传也没用了,就放弃 tcp 连接 (准确的说是会触发 tcp 的重置连接操作)
站在 B的视角,收到了两条一样的数据:收到重复数据,是否会给程序带来一些bug??
比如发的是一条数据,收的时候收到两条数据了(inputStream.read,读出来的是两条一样的数据)会!!!!!
其实 TCP 已经非常贴心的帮我们把这个问题解决了TCP 会有一个"接收缓冲区"就是一个内存空间,会保存当前已经收到的数据,以及数据的序号
接收方如果发现,当前发送方发来的数据,是已经在接收缓冲区中存在的 (收到过的重复数据了),接收方就会直接把这个后来的数据给丢弃掉,确保应用程序进行 read 的时候读到的是只有一条数据.
接受缓冲区,不仅仅是能进行去重,还能进行重新排序,确保发送的顺序,和应用程序读取的顺序是一致的
3.连接管理
建立连接 + 断开连接
面试中,最经典的问题:三次握手(建立连接)和 四次挥手(断开连接) ~~
握手 => handshake(打个招呼)(打招呼的内容,没有实际意义,也比较简短,只是为了唤起对方的注意~~)【tcp 这里的握手,也是类似,也就是给对方传输一个简短的,没有业务数据的数据包,通过这个数据包,来唤起对方的注意,从而触发后续的操作.】
【握手这个操作,不是 TCP 独有的,甚至不是网络通信独有的.计算机中的很多操作,都会涉及到“握手”】
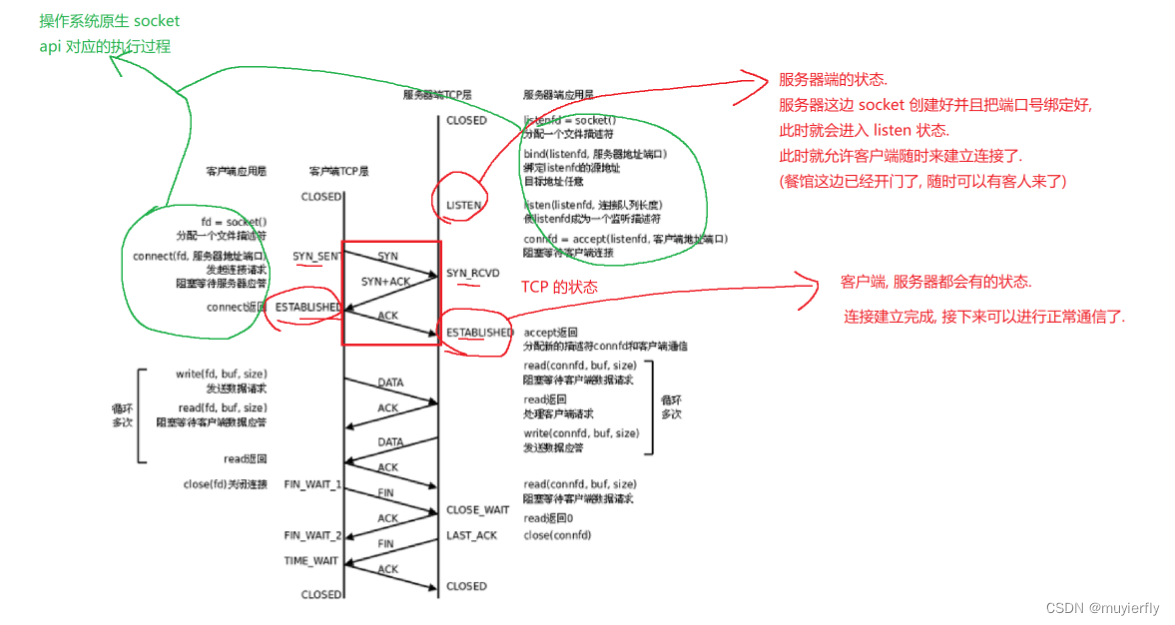
TCP 的三次握手.
TCP 在建立连接的过程中,需要通信双方一共"打三次招呼" 才能够完成连接建立的 (ack和syn合并为一次)
【question】三次握手是要解决什么问题??通过四次握手,是否可行? 通过两次握手,是否可行呢??
TCP 初心,是为了实现"可靠传输
进行确认应答 和 超时重传有个大前提,当前的网络环境是基本可用的,通畅的.
如果当前网络已经存在重大故障了,此时,可靠传输,无从谈起。

三次握手核心作用一:投石问路,确认当前网络是否是畅通的
三次握手核心作用二:要让发送方和接收方都能确认自己的发送能力和接收能力均正常
三次握手核心作用三让通信双方,在握手过程中,针对一些重要的参数,进行协商(syn,ack都是数据报文)
断开连接 四次挥手
建立连接,一般都是客户端主动发起
断开连接,客户端和服务器都可以主动发起
和 三次握手 不同,此处的四次挥手,能否把中间的两次交互合二为一?
不一定!!
不能合并的原因, ACK 和 第二个 FIN 的触发时机是不同的,
ACK 是内核响应的.B 收到 FIN,就会立即返回 ACK第二个 FIN 是应用程序的代码触发,B 这边调用了 close 方法才会触发 FIN 。【从服务器收到 FIN(同时返回 ACK),再到执行到 close发起 FIN, 这中间要经历多少时间,经历多少代码,是不确定的!!】像前面的三次握手, ACK 和 第二个 syn 都是内核触发的.
同一个时机.可以合并这里的四次挥手,ACK 是内核触发的,第二个 FIN 是应用程序执行 close 触发的. 时机不相同,不能合并
是否意味着,如果我这边代码 close 没写/没执行到,是不是第二个 FIN 就一直发不出去??(有可能的)
如果是正常的四次挥手,"好聚好散”,正常的流程断开的连接.如果是不正常的挥手 (没有挥完四次),异常的流程断开连接(也是存在的)
但是,TCP 中还有一个机制,延时应答,能够拖延 ACK 的回应时间一旦 ACK 滞后了,就有机会和下一个 FIN 合并在一起了
A 这边使用 TIME WAIT 状态进行等待,等待的这个时间, 就是为了处理后续 B 重传的 FIN
TIME WAIT 等待多久呢?
假设网络上两个节点通信消耗的最大时间为 MSL【可配置的参数.(数值也是拍脑门出来了)】此时 TIME WAIT 的时间就是 2 MSL【已经是上限了,绝大部分的数据包不会达到这个时间的,都会比这个时间短很多】


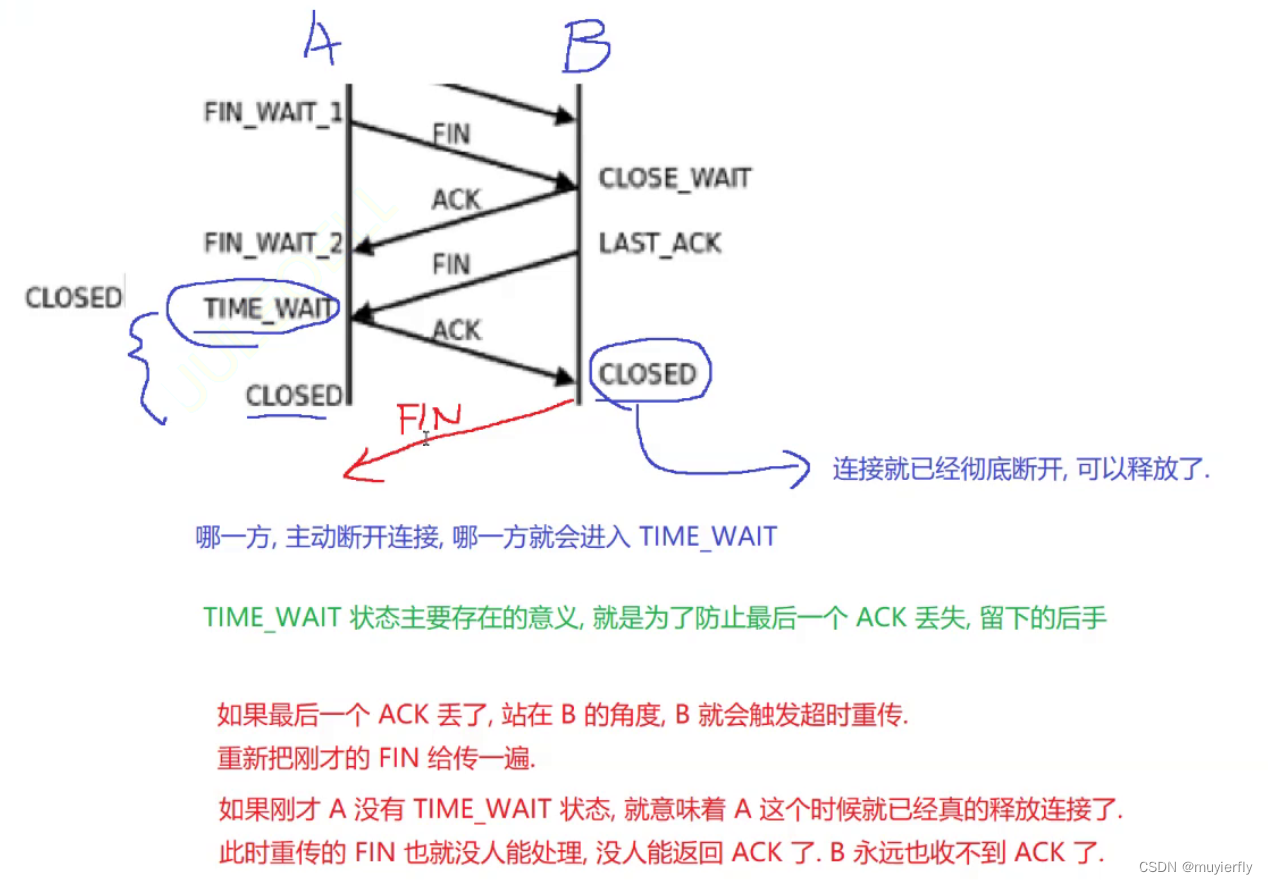
前三个机制,都是在保证 tcp 的可靠性
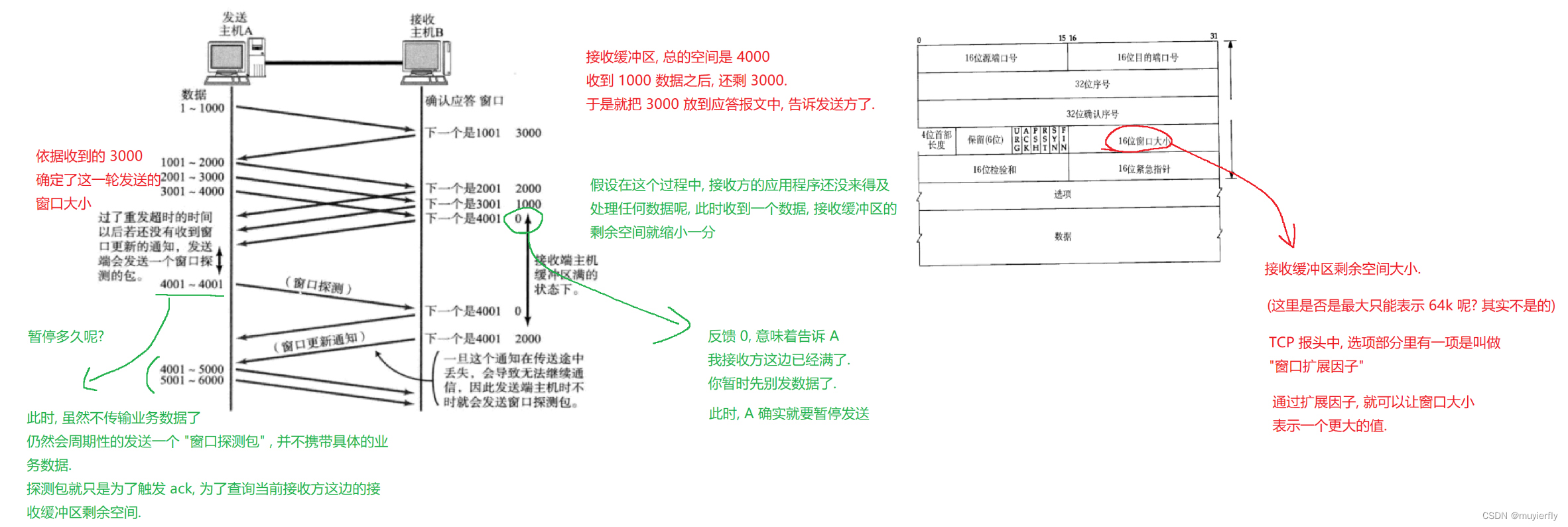
4.滑动窗口
提高效率.=>亡羊补牢
TCP 的可靠传输,是会影响传输的效率的(多出了一些等待 ack 的时间. 单位时间内能传输的数据就少了)
滑动窗口,就让可靠传输对性能的影响,更少一些
TCP 只要引入了可靠性,传输效率是不可能超过 没有可靠性的 UDP 的
TCP 这里的"效率机制"都是为了让 影响更小,缩短和 UDP 的差距,
缩短确认应答的的等待时间
【滑动的过程】
TCP 初心是"可靠传输”上述滑动窗口中,确认应答是可以正常工作的,但是,如果出现丢包了咋办??
这里的重传,相比于前面的超时重传,又有变化~
如果通信双方,传输数据的量比较小,也不频繁,就仍然是普通的确认应答和普通的超时重传,。如果通信双方,传输数据量更大,也比较频繁,就会进入到滑动窗口模式,按照快速重传的方式处理

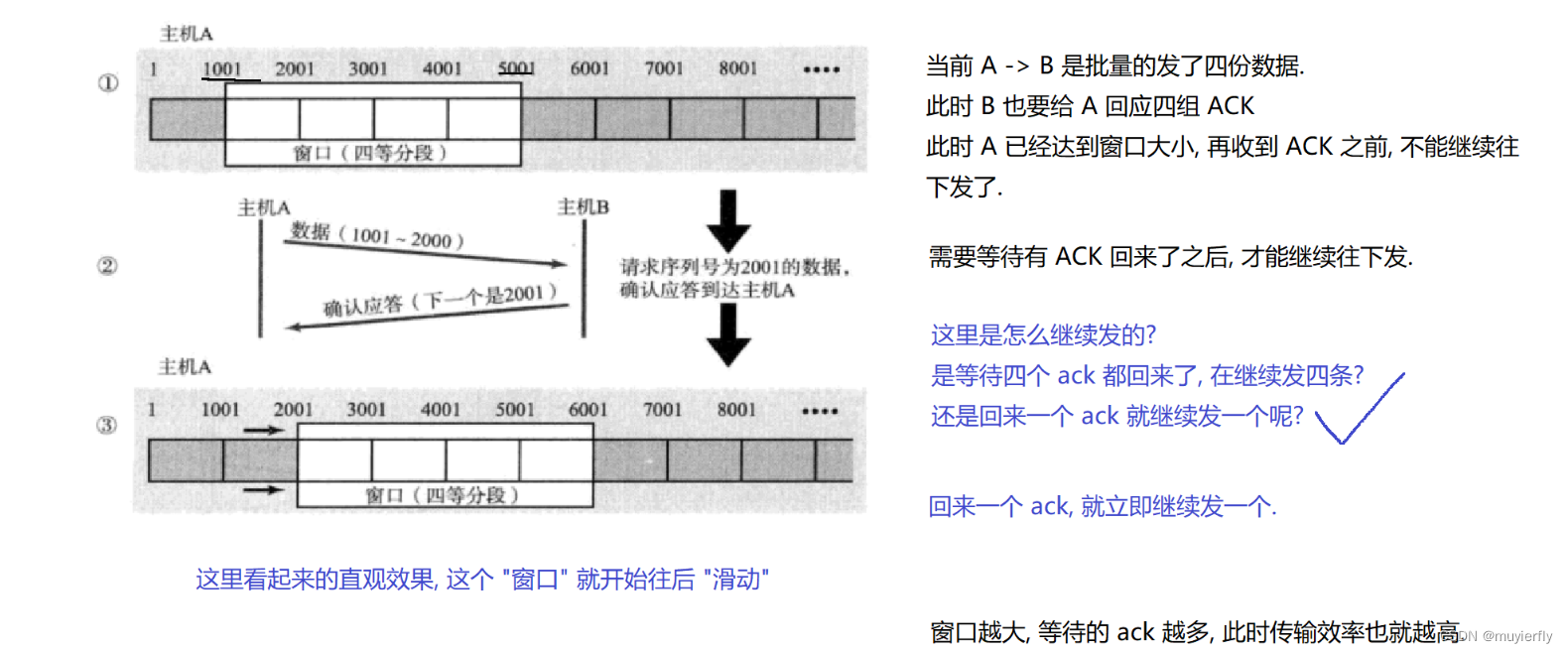
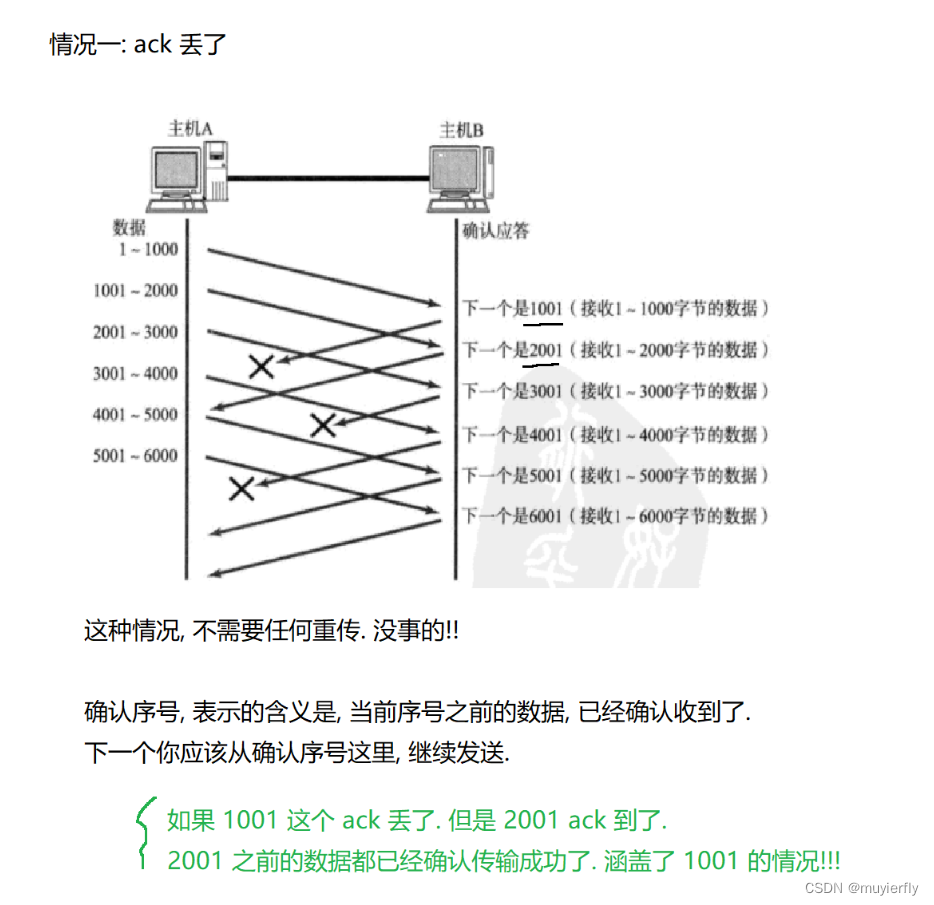
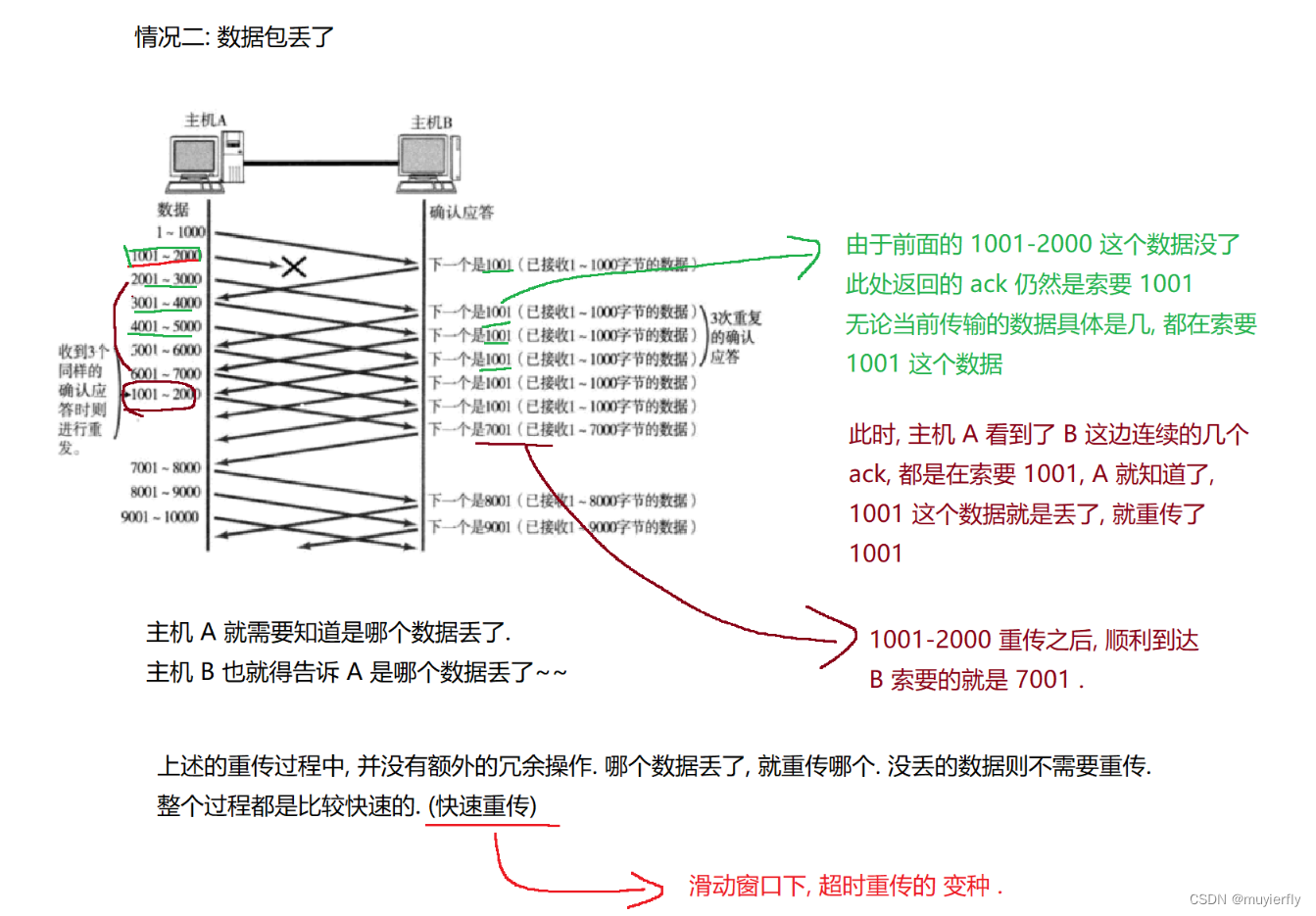
通过滑动窗口的方式传输数据,效率是会提升的,
窗口越大,传输效率就越大.(一份时间, 等待 的 ack 更多了,总的等待时间更少了)
滑动窗口,设置的越大,越好嘛??
如果传输的速度太快, 就可能会使接收方,处理不过来了.此时,接收方也会出现丢包.发送方还得重传......
TCP 前提是可靠性,可靠性的基础上,再提高传输效率,
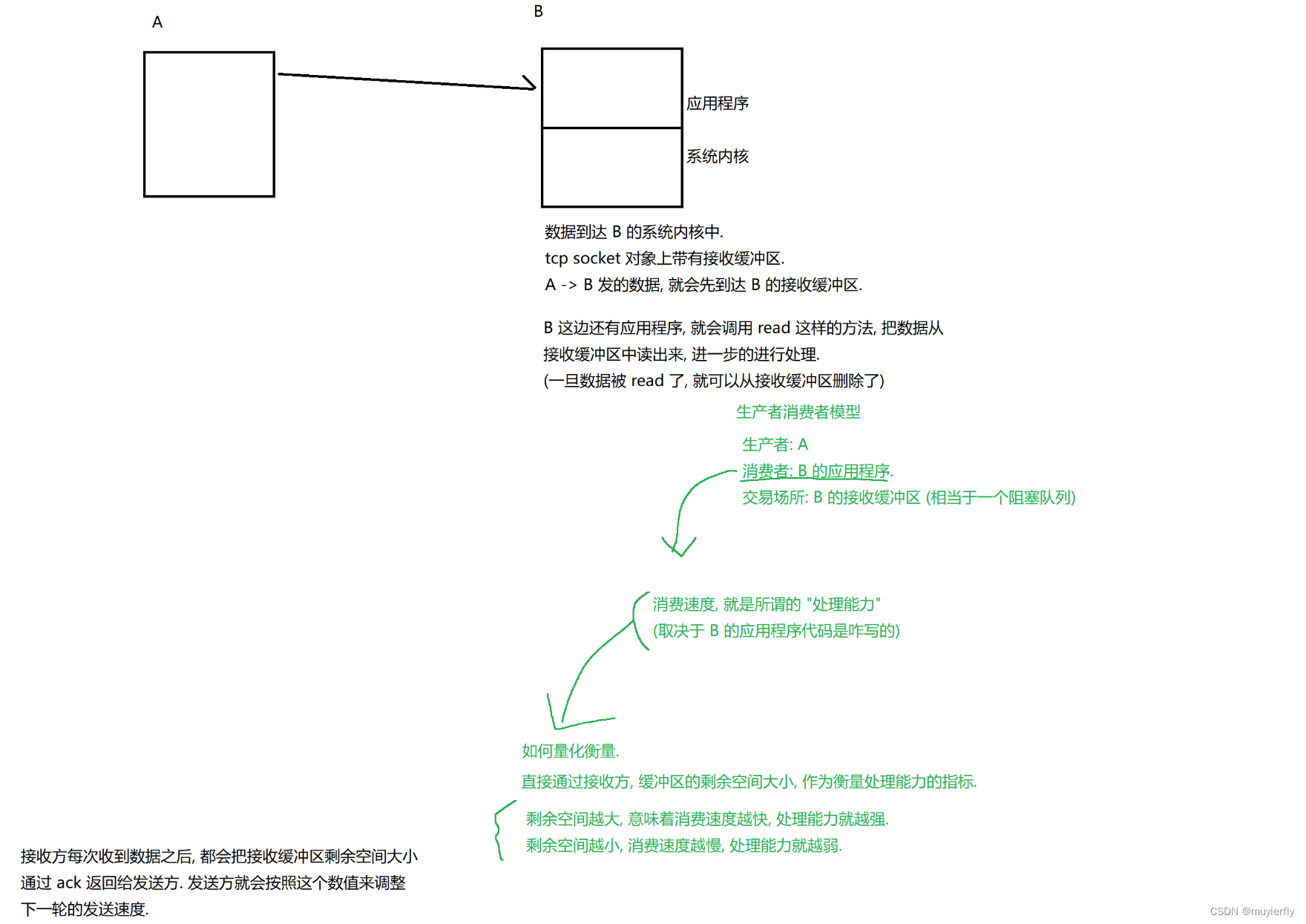
5.流量控制
站在接收方的角度,反向制约发送方的传输速率
发送方发送的速率,不应该超过接收方的处理能力,
6.拥塞控制(se)
流量控制,是考虑的接收方的处理能力,
不仅仅是接收方,还有你整个通信的路径
【question】关键问题:
接收方的处理能力,很方便进行量化,
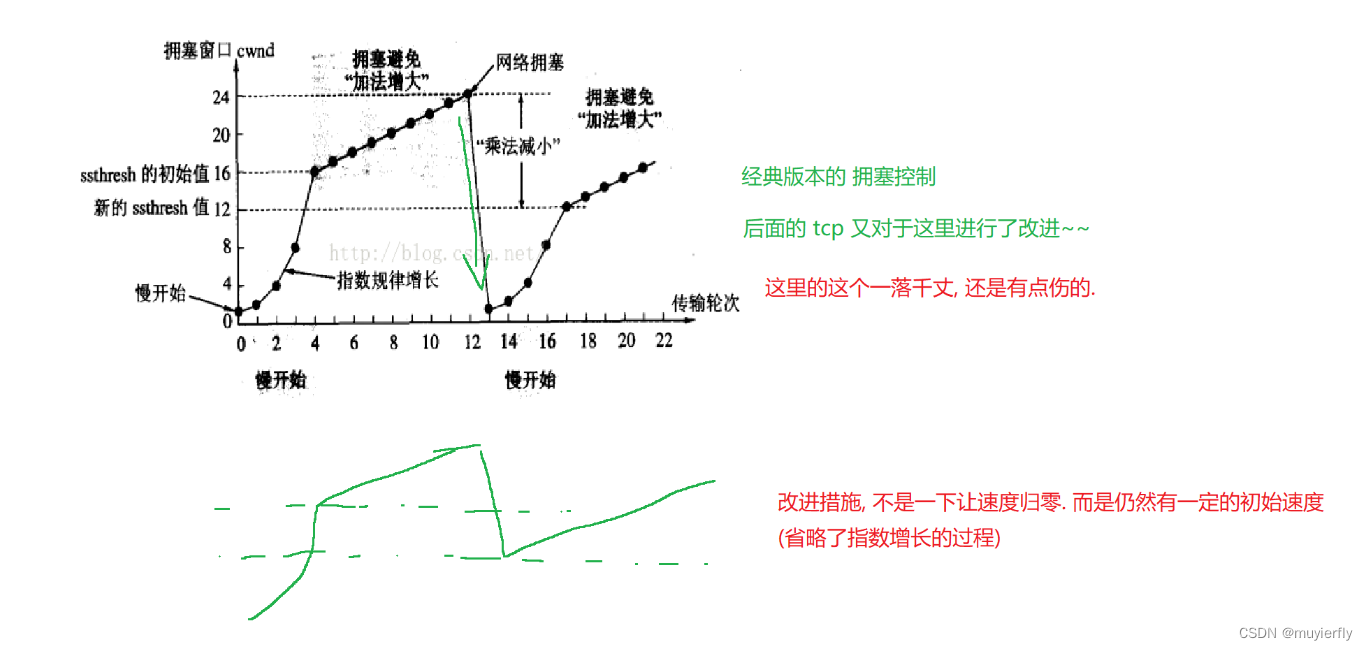
由于中间节点,结构更复杂,更难以直接的进行量化因此就可以使用"实验"的方式,来找到个合适的值。让 A 先按照比较低的速度先发送数据(小的窗口)
如果数据传输过程非常顺利,没有丢包,
再尝试使用更大的窗口,更高的速度进行发送(一点一点变化)
随着窗口大小不停的增大,达到一定程度,可能中间节点就会出现问题了.此时这个节点就可能会出现丢包发送方发现丢包了,就把窗口大小调整小,此时如果发现还是继续丢包,继续缩小,如果不丢包了,就继续尝试变大
再这个过程中,发送方不停的调整窗口大小,逐渐达成"动态平衡"
这种做法,就相当于把中间节点,都视为"整体",通过实验的方式,来找到中间节点的瓶颈在哪里。
【改进】


流量控制、拥塞控制都是在限制发送方的发送窗口的大小,
最终时机发送的窗口大小,是取 流量控制 和 拥塞控制 中的窗口的较小值.
7.延时应答
A 把数据传给 B, B 就会立即返回 ack 给 A【正常】
也有的时候,A 传输给 B, 此时 B 等一会再返回 ack 给 A【延时应答】
本质上也是为了提升传输效率
发送方的窗口大小,就是传输效率的关键
流量控制这里,就是根据接收缓冲区的剩余空间,来决定发送速率的如果能够有办法,让这个流量控制得到的窗口更大点,发送速率就更快点(大点的前提,能够让接收方还是能处理过来的)延时返回 ack,给接收方更多的时间, 来读取接收缓冲区的数据此时接收方读了这个数据之后,缓冲区剩余空间,变大了~~
返回的窗口大小也就更大了
初始情况下,接收缓冲区剩余空间是 10kb,如果立即返回 ack,返回了 10kb 这么大的窗口如果延时个 200ms 再返回,这 200ms 的过程中,接收方的应用程序的, 又读了 2kb,此时, 返回的 ack, 就可以返回 12kb 的窗口了
8.捎带响应

9.面向字节流
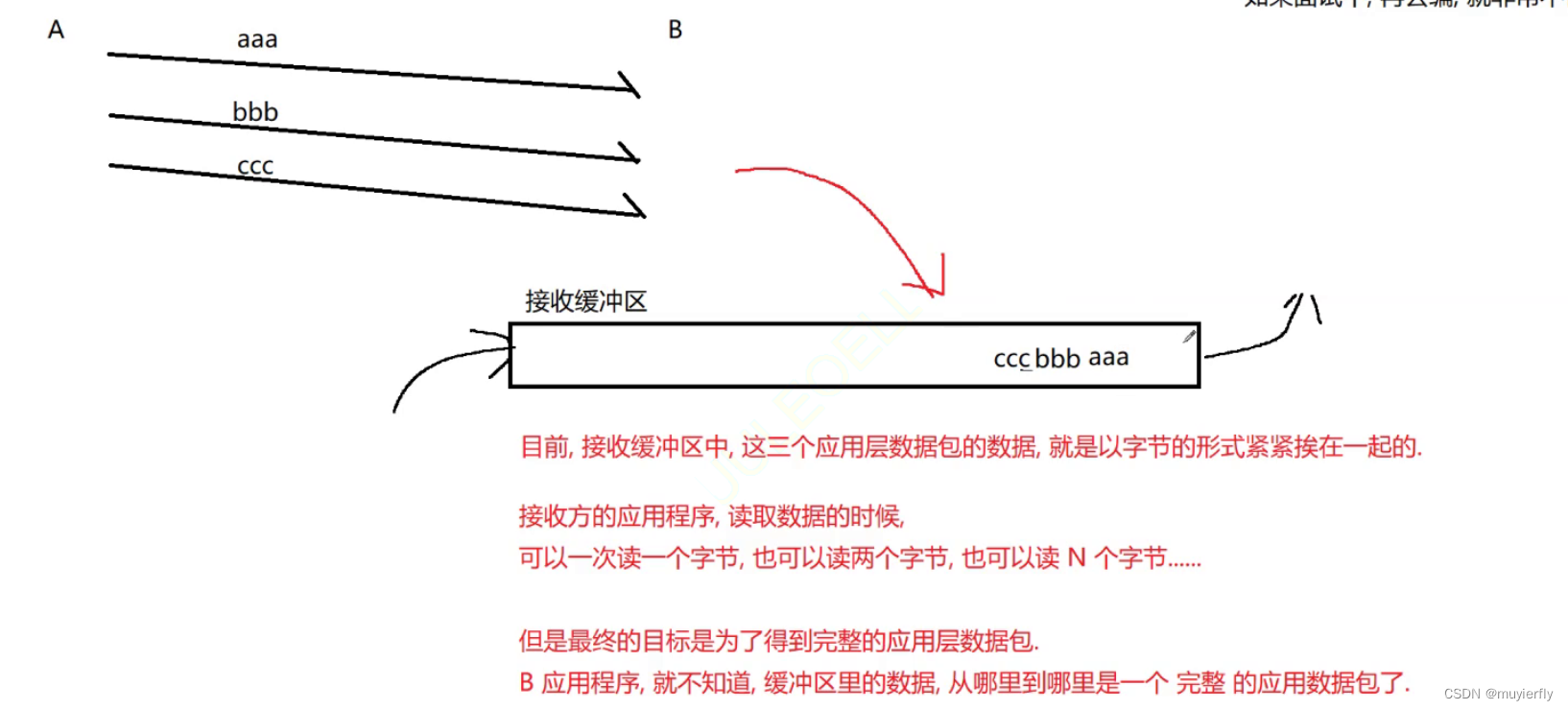
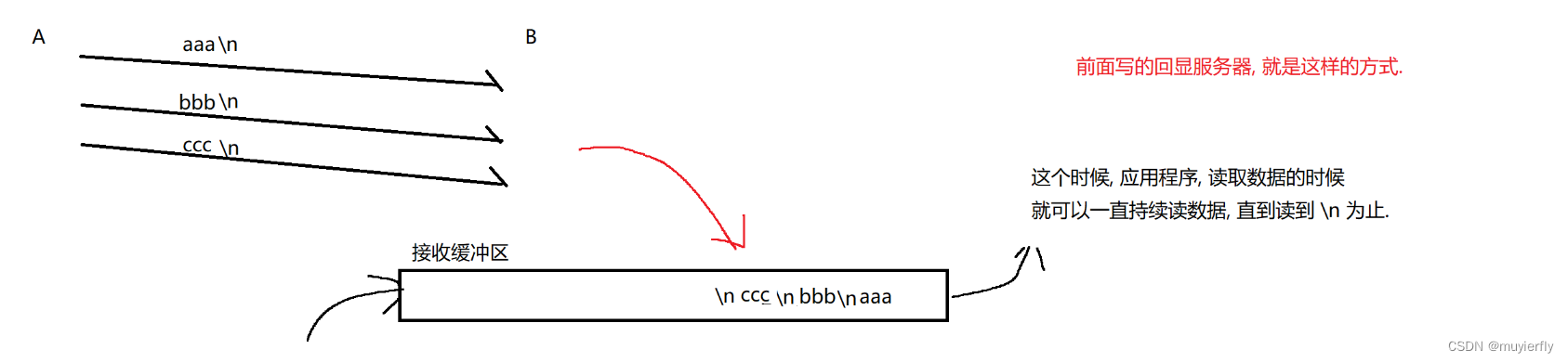
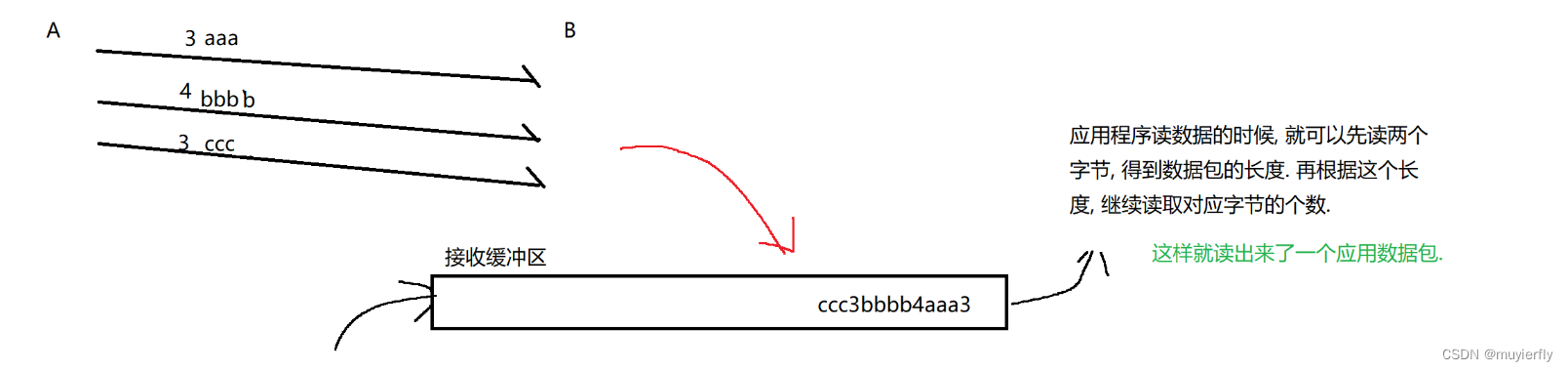
这里有一个最重要的问题,粘包问题 (不是 tcp 独有的,而是面向字节流的机制都有类似的情况)
此处"包"应用层数据包. 如果同时有多个应用层数据包被传输过去,此时就容易出现粘包问题
如何解决粘包问题?
核心思路: 通过定义好应用层协议,明确应用层数据包之间的边界.
1.引入分隔符
2.引入长度.
一个简单的例子, 使用 \n 作为分隔符!
自定义应用层协议的格式,
xml, ison, protobuffer,本身都是明确了包的边界的.

10.异常情况的处理
如果在使用 tcp 的过程中,出现意外,会如何处理?
1)进程崩溃,
进程没了,异常终止了.
文件描述符表,也就释放了.
相当于调用 socket.close()此时就会触发 FIN,对方收到之后,自然就会返回 FIN 和 ACK,这边再进行 ACK(正常的四次挥手断开连接的流程)
TCP 的连接,可以独立于进程存在,(进程没了,TCP 连接不一定没)
2)主机关机(正常流程)
在进行关机的时候,就是会先触发强制终止进程操作.(相当于 1)
此时就会触发 FIN, 对方收到之后,自然就会返回 FIN 和 ACK.
不仅仅是进程没了,整个系统也可能关闭了,如果在系统关闭之前,对端返回的 ACK 和 FIN 到了,此时系统还是可以返回 ACK,进行正常的四次挥手的,如果系统已经关闭了,ACK 和 FIN 迟到了,无法进行后续ACK 的响应.站在对端的角度,对端以为是自己的 FIN 丢包了,重传 FIN.重传几次都没有响应,自然就会放弃连接:(把持有的对端的信息就删了)3)主机掉电 (非正常)
此时,是一瞬间的事情, 来不及杀进程,也来不及发送 FIN,主机直接就停机了
站在对端的角度,对端不一定知道这个事情咋搞~~
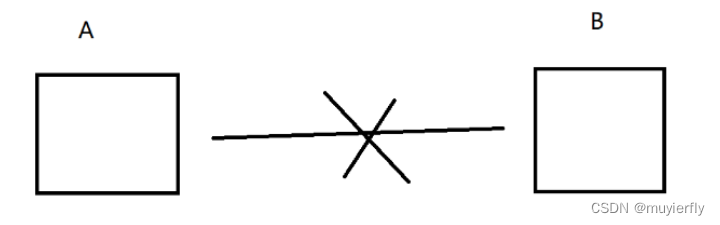
4)网线断开
网线断开,和刚才的主机掉电非常类似的.
当前假设,是 A 正在给 B 发送数据,一旦网线断开,
A 就相当于就会触发超时重传 ->连接重置 ->单方面释放连接B 就会触发心跳包->发现对端没响应->单方面释放连接


3.TCP和UDP的对比
TCP 优势 可靠传输,TCP 适用于绝大部分场景.
UDP 优势 更高效率,UDP 更适合于,对于"可靠性不敏感”,“性能敏感"场景
如果要传输比较大的数据包,TCP 更优先(UDP 有 64KB 的限制)
如果要进行"广播传输",优先考虑 UDP. UDP 天然支持广播,TCP 不支持 (应用程序额外写代码实现)【有一种特殊的场景,需要把数据发给局域网的所有的机器这个情况就是广播】【投屏功能
(手机和电视得在同一个局域网下,手机这边触发投屏功能, 就会往局域网发起广播数据包,询问一下, 你们谁是电视??谁能够接受投屏??电视此时就会回应了: 俺是电视, 并且把自己的 ip 端口啥的都告诉了手机,手机就可以完成后续的投屏了】

