
- 1高效数据存储格式Parquet_to_parquet
- 2IDEA连接SqlServer数据库_idea导入sqljdbc后如何与sqlserver连接
- 3【大模型实践】ChatGLM3微调输入-输出模型(六)_chatglm3 prompt
- 4【Git-Git克隆代码与提交代码】使用Git命令方式拉取代码至本地以及上传代码到云端
- 5文件上传漏洞靶场搭建(upload-labs)_upload-labs搭建
- 6Debian/Linux 配置网络教程(包括配置IP)_debian 配置网络
- 7移动通信网络频段大全_n66频段
- 8前端安全——最新:lodash原型漏洞从发现到修复全过程_lodash 漏洞复现
- 9React native拆包之 原生加载多bundle(iOS&Android)_react native加载bundle
- 10华为鸿蒙4谷歌GMS安装教学_华为鸿蒙os安装谷歌gms套件的最便捷方法教程
一、NLP中的文本分类_nlp文本分类模型
赞
踩
目录
NLP学习笔记系列,欢迎收藏交流:
1.0 文本分类的应用场景
(1)情感分析:中性,正向评论,负向评论,黄色言论,暴力言论,反政言论等;
(2)主题、话题分类:法律、经济类话题等;
(3)垃圾邮件识别;
(4)意图识别:开关车门,开关车灯,闲聊等类别。
1.1 文本分类流程
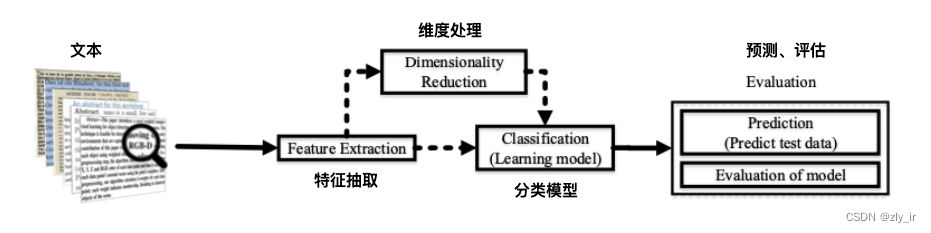
(0)数据预处理:将本文中的停用词、空格、大小写等进行去除和归一。
(1)特征提取:将本文字符转换成数学模型能够识别的向量或者token,也就是第零章节中讲到的部分。
(2)维度处理:传统机器学习模型在处理分类任务前,通常会对输入的特征进行降维处理,以避免资源爆炸及训练时间过长,常用的维度处理方法有:主成分分析PCA(无监督、降维后的方差diff最大)、线性判别分析LDA(有监督)等。对于深度学习模型,由于大部分进行了词嵌入处理,因此一般不需要对维度进行特殊处理。
PCA的具体推导和实现:主成分分析法(PCA)-CSDN博客
LDA的具体推导和实现:线性判别分析LDA
其他降维方法:机器学习降维算法汇总!
(3)分类模型:处理好特征后,就可以利用机器学习或者深度学习模型对数据进行分类,常用的分类模型分为判别式模型和生成式模型,将在下面两节着重介绍。
1.2 判别式模型
人为设定好模型框架,通过数据的不断训练修正模型参数,最后输入数据,直接判断数据所属类别的概率。要确定一个羊是山羊还是绵羊,用判别式模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
LR:Logistic Regression逻辑回归,最常用及最简单的一种分类模型。曾经写的LR的博客
KNN:k-最近邻,一种有监督的模型,对于一个未知类别的数据,去计算得到K个与之距离最近的有标签的数据,最后通过投票的方式得到未知数据的类别。
SVM:支持向量机,通过计算得到一个超平面将数据进行分类。曾经写的关于SVM的博客
决策树:一种基于树结构进行决策判断的模型,它通过多个条件判别过程将数据集分类,最终获取需要的结果。(根据计算熵增方式的不同,分为ID3决策树、C4.5决策树、CART决策树)
集成分类器:XGBoost, GBDT。
MLP:多层感知器 ,通常由一个输入层、多个隐藏层和一个输出层组成,能够通过学习给出输入数据的类别概率。曾经写的关于MLP的博客

RNN:循环神经网络,在MLP的隐藏层中加入上一次计算得到的结果同时作为当前隐藏层的输入,来保存时序性数据的信息。曾经写的RNN的博客

LSTM:类似电路设计,会有输入门、遗忘门、输出门,遗忘门会有选择的遗忘低概率的数据。
BERT、ERNIE
1.3 生成式模型
通过数据学习得到数据的联合概率分布,基于条件概率P(X|Y)和先验概率P(Y)来作为预测模型的预测基础,预测联合概率分布P(Y,X)。是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,再放到绵羊模型中看概率是多少,哪个大就是哪个。
贝叶斯网络:一种生成式模型,给定一些先验知识(例如,每个类别的先验概率以及每个特征在不同类别下的条件概率),我们可以计算出某个数据点属于每个类别的后验概率,然后选择具有最高后验概率的类别作为预测结果。

马尔科夫随机场:MRF
隐马尔科夫模型:HMM
不管是生成式模型还是判别式模型,它们最终的判断依据都是条件概率P(y|x),但是生成式模型先计算了联合概率P(x,y),再由贝叶斯公式计算得到条件概率。因此,生成式模型可以体现更多数据本身的分布信息,其普适性更广。由生成式模型可以得到判别式模型,但反过来不行。
1.4 评估
NLP分类任务中,常用的评价指标有准确率、精准率、召回率、F1值,宏平均、微平均等。这些评价指标常依赖于混淆矩阵的计算,混淆矩阵主要包括其中包括真阳性(TP),假阳性(FP),假阴性(FN)和真阴性(TN),一般来说,他们的计算方式如下:
TP:预测为正例的,且标签值也为正例的;
FP:预测为正例的,但标签值为负例的;
TN:预测为负例的,且标签值也为负例的;
FN:预测为负例的,但标签值为正例的;
(1)准确率:
![]()
(2)精准率:
![]()
(3)召回率:
![]()
(4)F1值:
![]()
(5)宏F1值:
求取每一类的F值之后求平均值,对于类别分布不均的数据集,数据量大的类别对总体影响大:
![]()
(6)微F1值
求取每一类的TP/FP/TN/FN,然后按照P、R的计算公式计算微平均P、微平均R,最后计算得到微平均F1。
(7)ROC曲线
根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测(例如第一个样本的值为分界线,小于的为负例,大于的为正例),每次计算出两个重要量的值(TPR真阳率、FPR假阳率),分别以它们为横、纵坐标作图。
TPR = 召回率
FPR = FP / (TP + FP)
(8)AUC:
ROC曲线下的面积,介于0.1和1之间,作为数值可以直观的评价分类器的好坏,值越大越好。

