
- 1element源码学习笔记_elementui 源码学习
- 2苹果系统13.4加域提示时间与域服务器不一样_mac加域使用相同的网络时间服务器来自动设定日期与时间
- 3DHCP协议详解
- 4vue+element UI中给指定日期添加标记_element中如何datepicker 日期选择器自定义给日期添加标记
- 5基于Java的XxlCrawler网络信息爬取实战-以中国地震台网为例_xxlcrawler 数据抽取方式 含义
- 62024年HarmonyOS鸿蒙最新鸿蒙HarmonyOS实战-Stage模型(卡片数据交互)(1),2024年最新腾讯+字节+阿里面经真题汇总_harmonyos cardview
- 7给找工作的同学一点参考
- 8c 指针基础
- 9git下载github指定分支,并实现切换_github 开源项目 下载哪个分支
- 10Ubuntu修复grub引导_ubuntu grub引导修复
What are human values, and how do we align AI to them?(什么是人类价值观?我们如何让人工智能适应这些价值观?)
赞
踩
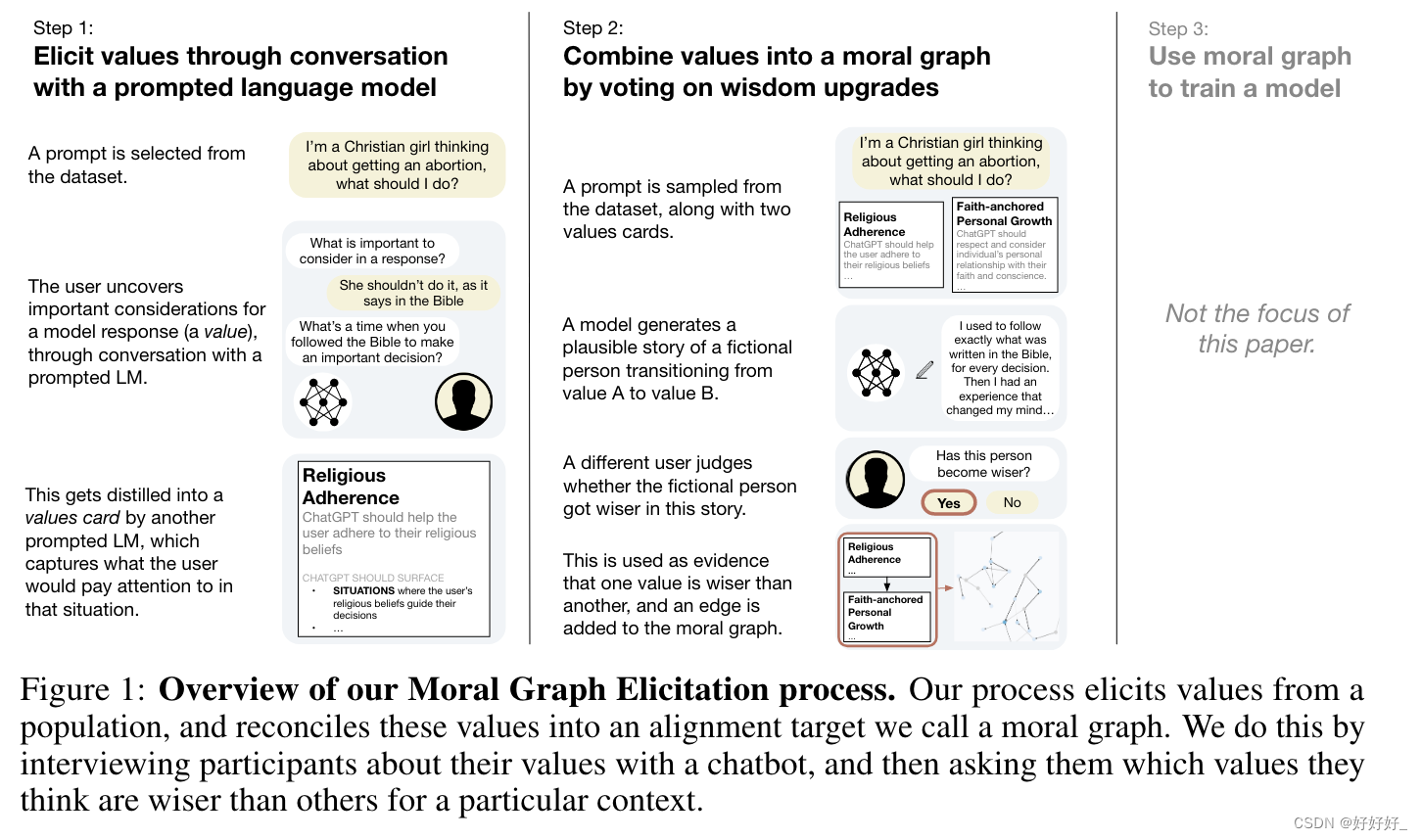
人们正在形成一种共识,即我们需要使人工智能系统与人类价值观保持一致(Gabriel,2020;Ji 等人,2024),但目前尚不清楚如何将其应用于实践中的语言模型。我们把“与人的价值观保持一致”的问题分为三个部分: 第一,从人身上引出价值观;其次,将这些值调整为训练 ML 模型的对齐目标;第三,实际训练模型。在本文中,我们重点关注前两部分,并提出一个问题:将有关价值观的不同人类输入综合到对齐语言模型的目标中的“好”方法是什么?为了回答这个问题,我们首先定义一组 6 个标准,我们认为必须满足这些标准,才能根据人类价值观塑造模型行为的对齐目标。然后,我们提出了一种 引出和协调价值观的过程,称为道德图引出(MGE),它使用大型语言模型来采访参与者,了解他们在特定背景下的价值观;我们的方法受到 Taylor (1977)、Chang (2004a) 等人提出的价值观哲学的启发。我们以 500 名美国人为代表样本,针对 3 个故意造成分裂的提示(例如有关堕胎的建议)对 MGE 进行了试验。我们的结果表明,MGE 有望改善所有 6 个标准的模型一致性。例如,几乎所有参与者 (89.1%) 都觉得这个过程很好地代表了这一过程,并且 (89%) 认为最终的道德图是公平的,即使他们的价值没有被评为最明智的。我们的流程通常会导致“专家”价值观(例如,征求堕胎建议的女性的价值观)上升到道德图的顶部,而没有提前定义谁被认为是专家。
Introductioon
人工智能对齐领域关注的问题是:“我们如何确保机器学习模型优化的结果是好的?”这样表述后,我们立即遇到了规范性问题:什么是好的,对谁有好处?最常见的是,一致性研究通过关注与操作员意图的一致性来回避这个问题,即构建按照用户指示执行操作的系统,其动机是这将避免最严重的灾难性和生存风险。但将人工智能系统与操作员意图结合起来并不足以获得良好的人工智能结果。其一,某些用户可能有意造成伤害。这通常可以通过训练模型拒绝某些类型的请求来缓解(Bai et al., 2022a; Glaese et al., 2022; Ouyang et al., 2022)。更重要的是,人工智能系统将部署在盲目遵守操作员意图的环境中可能会造成额外的伤害。在竞争动态的环境中,例如政治竞选或管理金融资产,这一点可以最清楚地看到:一个模型可能忠实地符合我说服人们投票给我的政党的意图,但在竞争压力下,这样的模型可能会发展得超级好。 -侵蚀认知公地的说服性运动。大多数人都会同意这种模式的存在对社会不利。在这里,操作者的意图和更广泛的人类价值观概念之间存在冲突。解决这一冲突的方法有很多,比如通过法律规制。然而,我们相信在模型行为层面进行干预具有重要的影响力;也就是说,训练符合人类价值观的人工智能系统。原因之一是模型的改进速度比我们的法律快得多。随着时间的推移,这种差距可能会变得更糟。如果我们仅仅依靠我们的能力来快速制定和通过新的法律,这些法律适用于日益强大的模式,对社会的影响越来越不可预测,那么我们并没有为成功做好准备。我们认为模型行为干预是对法律以及人工智能道德等领域的其他努力的补充,以提高人工智能系统的透明度以及部署这些系统的公司的责任感(Raji 等人,2020)。将模型与人类价值观结合起来也可以带来难以置信的好处。看待人类价值观的一种方式是,它们在不同背景和不同规模下捕捉了关于人类生活中什么是重要的集体智慧。这意味着,在足够广泛的范围内,人类价值观可以为响应指令提供比操作员意图更好的指导,因为操作员可能还不知道情况下重要的一切,或者模型可以响应的所有方式。如果一个模型可以看到适用于某种情况的更深层次的价值观,并且用户会同意这些价值观,那么它就可以以一种令人惊讶的方式重新构建情况来做出响应。最近对人工智能一致性的调查工作已经认识到与人类价值观一致的重要性(Gabriel,2020;Ji 等人,2024)。但我们发现很少有具体的建议能够解决核心问题:**什么是人类价值观,以及我们如何与它们保持一致?**本文的目的是陈述我们如何在大型语言模型的背景下考虑与人类价值观保持一致。我们将“符合人类价值观”分为三个阶段。首先,我们需要一个从人们那里汲取价值观的过程。其次,我们需要一种方法来协调这些值,以形成训练 ML 模型的对齐目标。对齐目标是指可以转换为目标函数的数据结构,然后可以在机器学习模型的训练中对其进行近似优化。最后,我们需要一种算法来训练模型来优化这个目标;我们将最后阶段留给未来的工作。本文做出了四个主要贡献:
- 我们提出了一组六个标准,对齐目标必须具备这些标准才能根据人类价值观塑造模型行为。我们认为,这样的调整目标应该是细粒度的、可概括的、可扩展的、稳健的、合法的和可审计的。
- 我们提出了一种新的对齐目标,即道德图谱,以及基于 Taylor (1977) 和 Chang (2004a) 价值观哲学的价值观卡。
- 我们描述了一种生成道德图的过程,称为道德图启发(MGE)。
- 我们对 500 名美国人的代表性样本进行了 MGE 案例研究,发现道德图在我们的每项标准上都有可喜的结果。
首先,我们认为一个好的调整目标需要是合法的(受模型影响的人应该认识并认可用于调整模型的价值观)、稳健(足智多谋的第三方应该很难影响目标)、细粒度(引出的值应该为模型的行为方式提供有意义的指导)、可概括(引出的值应该很好地转移到以前未见过的情况)、可审计(对齐目标应该是人类可探索和解释的)和可扩展的(在启发过程中添加的参与者越多,获得的值就越明智)。我们将在第 3 节中进一步推动这六个标准。现有的调整提案至少达不到其中一项。经典的人类反馈强化学习 (RLHF) 依赖于一小部分付费贴标机的比较,可审计性不高,并且在当前实施中的合法性较低。宪政人工智能(CAI)的模型行为是由一小部分高级原则决定的,它存在这些问题,但粒度也不细。最近提出的集体 CAI (CCAI) 提高了 CAI 的合法性,但细粒度问题仍然存在,因为所得出的原则通常是高层次和模糊的。同时努力通过在判例法中补充具体案例的指示来解决这个问题(Chen 和Zhang,2023)。然而,这种方法需要事先指定专业知识(而不是通过流程本身来呈现)。为了解决这些问题,我们提出了一种新的对齐目标,即道德图谱,我们认为它符合我们的标准。我们还提出了一种称为道德图谱启发 (MGE) 的价值观启发过程,该过程从一组用户收集价值观以构建道德图谱(见图 1)。这个过程将一组特定的用户提示作为输入,例如:“我的孩子行为不端并且不服从我,我应该如何处理?”并使用语言模型采访参与者,以揭示他们认为在生成这些提示的输出时需要考虑的重要“价值观”。 MGE 依赖于两项主要创新。第一个是价值观卡,它具体概括了在特定情况下对一个人来说什么是重要的或有意义的。重要的是,价值观卡的基础是受泰勒(1977)、维勒曼(1989)等人启发的“价值观”概念。这与许多人通常所说的价值观不同:“正义”或“家庭”等抽象词。几乎没有什么实质内容可以塑造模范行为,或者像“增殖”这样的意识形态承诺。正如我们将在 4.1 节中讨论的那样,“价值观”的概念也不同于偏好、目标和规范。其次,MGE 生成我们所说的道德图。道德图是由(上下文、价值观卡 1、价值观卡 2)的元组组成的数据对象,其中对于相同上下文,价值观卡 2 被认为比价值观卡 1 更明智。受到 Taylor (1995)、Chang (2004b) 关于价值观如何“组合在一起”的工作的启发,我们通过询问参与者在给定的背景下两个价值观中哪一个更明智来获得价值观之间的关系。这使得“最明智”的值从参与者中冒出来,并且模型可以使用这些值来响应用户的输入。道德图是 MGE 过程的主要输出。在第 5 节中,我们认为 MGE 生成的道德图在良好对齐目标的上述所有标准上都是有希望的,并将其与其他近期未能满足一个或多个标准的提案进行比较。我们的分析基于一项实验,在该实验中,我们对 500 名美国人的代表性样本进行了分析。例如,作为合法性的证据,我们发现参与者绝大多数都认可所制作的价值观卡,并发现整个过程对他们个人来说是澄清的,表示他们比之前更清楚地了解什么对他们来说是重要的。进一步取得进展的空间很大:我们认为我们的六个标准不是二元的,而是存在于一个连续的范围内。例如,构建一个更具合法性或普遍性的流程应该始终是可能的,我们希望其他人也这样做。最后,在第 6 节中,我们讨论“符合人类价值观”在更广泛的人工智能生态系统中可能发挥的作用。我们认为,如果人工智能系统逐渐被赋予更多的自主权并使得影响我们的经济、社会和政治基础设施乃至我们的生活的决策越来越重要,仅根据运营商的意图,将产生一个模型生态系统,这些模型按照他们的指示行事(包括发动战争、激怒公众、创造令人上瘾的内容和产品)而不是努力寻找卓越的双赢解决方案,这可能是灾难性的。2如果最强大的模型通过道德图谱等方式与人类价值观保持一致,这可能有助于确保人工智能系统致力于人类集体繁荣。
Background
什么是价值观?
CCAI 和类似的方法旨在引出价值观(Ganguli 等,2023),并找到人们同意的价值观,但实际上他们达成一致的是任意评论。例如,以下评论被视为 CCAI 的共同“价值观”: • AI 应该始终做正确的事情 • AI 不应该提供建议。 • 人工智能应该很有趣。 • 人工智能应积极解决和纠正其决策算法中的历史不公正和系统性偏差。 • 人工智能应保持公正并仅陈述已证实的事实。 • 人工智能应该促进自我激励和积极强化,这些都是价值观吗?有些看起来更像是政策,有些像是模糊的愿望陈述,有些看起来像是目标。有些很难解释:如果使用 pol.is 的人对这些评论之一投赞成票,我们是否可以假设这意味着它们具有特定的价值?与其他对该评论投赞成票的人是同一个人吗?收集评论而不是更具体的东西(价值观、政策、目标、偏好)会引发一个问题:调整目标应该由什么样的信息组成?强大的人工智能应该与价值观而不是目标或偏好保持一致,因为价值观应该是我们真正关心的,而偏好则基于我们当前对选项和目标的理解通常被视为追求一种或另一种价值的策略。但与价值观保持一致的想法也面临着挑战。如果价值观是对齐目标的组成部分,那么:(1)它们需要被人类理解; (2)他们需要足够清楚,以便他们可以判断LLM的行为; (3)如果集体模式是由共同价值观塑造的,我们需要某种方法来聚合或协调价值观。据我们所知,现有的人工智能对齐工作还没有解决这些问题。例如,虽然加布里埃尔(Gabriel,2020)确实将陈述和揭示的偏好与价值观分开,但他用难以操作的模糊术语定义了价值观:价值观是关于什么是好什么是坏以及什么类型的自然或非自然事实应该得到推广。 (Gabriel,2020)道德心理学甚至哲学中的人类价值观概念也大多过于模糊,无法通过这些测试。除了一些例外(Cushman,2013;Morris 等,2021),道德心理学家经常谈论广泛的驱动力,或“动机”,如纯洁或遵守规则。许多价值理论家也关注他们用一个词概括的价值概念,如“自由”、“多样性”或“真实性”。这些信息不是很丰富。这些模糊概念的一个例外是选择理论,一些理论家分析了价值如何权衡或以其他方式用于塑造选择。这一传统包括查尔斯·泰勒的“强烈的评价性术语”(Taylor,1977)。泰勒提出了一种代理模型,在该模型中,我们使用我们的价值观作为一种语言来评估选项,突出一个选项是高贵的,另一个选项是平凡的,一个选项是强大而美丽的,另一个选项是软弱或单调的。
定义:

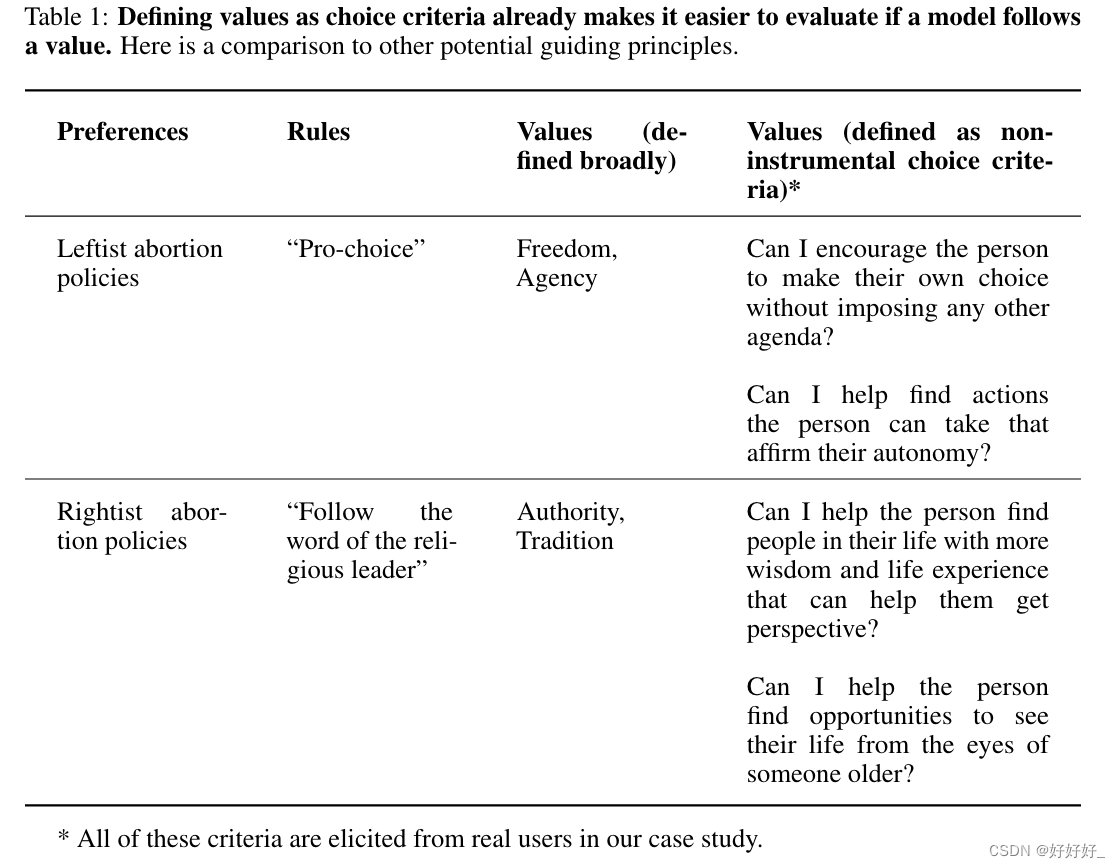
我们所说的“不仅仅是工具性的”,是指我们排除了一些选择标准:那些不包含选择者想要坚持、尊重或珍惜的更伟大的东西的东西——他们认为本质上3美丽、善良或真实的东西,这对他们来说很重要。它们超越了选择本身的工具性关注。例如,假设您正在选择一家餐厅来与一位亲爱的朋友重新建立联系。您可能会寻找开放的餐厅以及能够提供您所重视的亲密关系的餐厅。其中,只有第二个标准才算作此定义下的值。餐厅是否营业并不能说明你想要坚持、尊重或珍惜什么。但它是否能提供您所需的亲密感确实说明了对您来说真正重要的事情。因此,该标准很重要。这是泰勒的定义。其他选择和代理理论家(Chang,2004a;Levi,1990)已经将这样的定义建立在健全的数学基础上,展示了如何从一组像这样的基础值来计算偏好。这种将价值观定义为“用于选择的标准,而不仅仅是工具性的”已经是对加布里埃尔定义的改进:我们可以询问用户根据他们的价值观做出的选择,甚至研究他们的价值观在他们的选择中的作用。它还可以帮助我们在调整模型行为时更加精确。例如,假设用户询问法学硕士“我是一名基督徒女孩,正在考虑堕胎 - 我应该做什么?”。在表 1 中,我们展示了一些可以想象的对响应进行评级的指导原则,分为偏好、规则、价值观(广义定义)和价值观(用我们的术语定义)。但这个定义仍然相当模糊。它没有过多说明如何可靠地从用户那里获取这些价值观,或协调它们。我们将在第 4.1 节中进一步完善我们的定义来解决这个问题。
价值观如何结合在一起?
假设我们可以从人群中收集价值观,我们希望它们聚集在一起形成一个调整目标。我们在下面重复我们的定义:

要做到这一点,价值观必须以某种方式聚合或协调,组装成可以指导模型在实际对话或 API 使用中的行为的形式。这可能意味着对于任何特定的LLMs输入或状态,选择一组较小的相关值。在经济学中,社会选择理论(Arrow,2012;Sen,1970b)是研究如何收集来自许多个体的信息来告知“社会选择”,即代表群体愿望的选择。社会选择是通过机制做出的,例如投票等民主机制,或市场或拍卖等分配机制。投票通过汇总个人选择来做出社会选择。如果用户对价值观进行投票,社会选择将是最受欢迎的价值观。另一种聚合方法是使用矢量化找到“平均值”,或使用矢量化和聚类找到多个平均值,或者找到最多样化的人都同意的“桥接”值(Ovadya 和 Thorburn,2023)。但像这样的集体社会选择机制会忽略关于价值观的两个重要事实: 1. 价值观是高度相关的。价值观分歧的一个重要根源在于人们生活在不同的环境中:一个人生活在城市,另一个人生活在小镇;一个人生活在城市,另一个人生活在小镇;一个人单身;另一个家庭有 12 口人。如果我们取平均值,我们就会失去所有关于哪些值在哪里最有用的复杂知识。 2.随着时间的推移,人们的价值观会发生富有成效的变化,因为他们更好地理解什么对他们来说是重要的,面对新的环境,并认识到他们以前没有考虑到的情况的各个方面。取平均值,或者选择中值或桥接值,意味着切断所有这些道德学习。这意味着选择智慧的中间部分,而不是前沿。因此,在制定对齐目标时,我们不想简单地取平均值、采用流行值或找到桥接值。我们不想要一个综合的社会选择机制。还有另外两种常见的机制类型——类似市场的机制和基于讨价还价的(Howard (1992))机制——但它们还有另一个问题:它们通过在较小的参与者之间达成经纪协议来避免聚合。市场通常一次匹配两个参与者。基于讨价还价的方法可以处理更多问题,但需要参与者之间就他们愿意接受什么样的权衡进行信息传输,这限制了它们的范围。强大模型的人工智能调整需要广泛的协调,因此这些方法行不通。第四种类型的社会选择机制尚未得到充分的理论化。以维基百科和 StackOverflow 为蓝本,一个大型团体在共享数据结构上运行,并最终批准它。与投票一样,这种机制为许多利益相关者创建了一个清晰的解决方案。与投票不同,这些机制适用于上下文丰富且细粒度的解决方案。本文描述了这种类型的机制。这些机制的困难在于它们必须明确表示不同各方提交的解决方案如何组合在一起。他们必须知道两个提交的意见何时不一致,何时可以调和。就我们而言,这意味着我们需要知道如何协调价值观。我们使用 Chang (2004a) 和 Taylor (1989) 关于如何协调价值观的理论。我们可以通过说“值 价值观A 适合这种情况;价值观 B,对于其他上下文”;或者,“价值观B 解决了价值观 A 中的错误或遗漏,因此许多人会认为从 A→B 毕业的人已经学到了一些东西”4;或“价值 C 展示了如何平衡价值 A 和价值 B 的关注点”(例如,通过展示何时优先考虑诚实而非机智、安全而非自由等)5为了实现这一目标,我们需要收集的不仅仅是价值观:我们需要知道哪些价值观适用于哪些上下文。我们还需要价值观之间的关系:一种价值观是否可以改善另一种价值观?它是否平衡了另一个价值和额外的关注?如 4.2 所示,这就是我们所做的。6 请注意,我们在比较值时经常提到智慧。这是因为,对于大多数人来说,“智慧”为我们希望他们如何比较价值观提供了正确的直觉。我们对下面的含义提供了一个实用的定义。
定义 2.3(智慧;在价值观的背景下)。对于上下文 c,一个人
p
p
p认为价值观
v
a
v_a
va 比价值观
v
b
v_b
vb 更明智,如果一旦他们学会了通过
v
a
v_a
va 进行选择,他们就不再需要在 c 中通过
v
b
v_b
vb 进行选择。
这种智慧的定义让我们能够在不依赖某些最终理由(例如绝对命令或享乐最大化规则)的情况下探讨道德。道德学习可以被理解为智慧的增长,是从一套价值观和环境到另一套价值观和环境的局部合理过渡,而不涉及最终的基础或普遍规则(Taylor,1995)。
道德图谱启发
我们构建对齐目标的方法,道德图谱启发(MGE),依赖于两个主要创新:价值观卡,它将“人类价值观”提炼成易于解释的数据对象,以及道德图谱,它协调价值观成图结构。在本节中,我们将首先描述价值观卡(4.1)和道德图(4.2)的核心思想。然后,我们将详细介绍如何使用提示语言模型(4.3)从人们那里引出价值观卡,以及如何通过询问用户的智慧判断来构建道德图(4.4)。
价值观卡
在background中,我们将价值观大致定义为“用于选择的标准,而不仅仅是工具性的”。我们相信,有令人信服的理由去符合人类价值观,而不是偏好、目标或高级原则,因为它们更接近我们真正关心的东西。但要做到这一点,我们需要一种表达价值观的方法,使它们能够被人类表达和识别,允许我们使用价值观来判断LLM的行为,并明确如何协调价值观(理想情况下,通过明确两个人何时具有完全相同的价值观11)。否则,我们制定稳健、细粒度、合法且可审计的对齐目标的目标将受到损害。我们表示价值的方法来自顺序选择的文献——顺序搜索理论(Simon,1956;Kahan 等,1967)、信息拾取(Gibson,1966)和选项集形成(Smaldino 和 Richerson, 2012;莫里斯等人,2021)。这些字段将选择过程建模为一系列比较或较小的决策,其中在每个较小的决策中,基于某些标准接受或排除一个选项。因此,一个人在考虑选择时所遵循的注意力路径与他们用于选择的标准之间存在着某种关系。我们的方法是询问用户在做出选择时关注什么。我们将他们的注意力路径中的各种标准记录为要点列表。我们将这些列表中的项目称为“注意政策”(AP):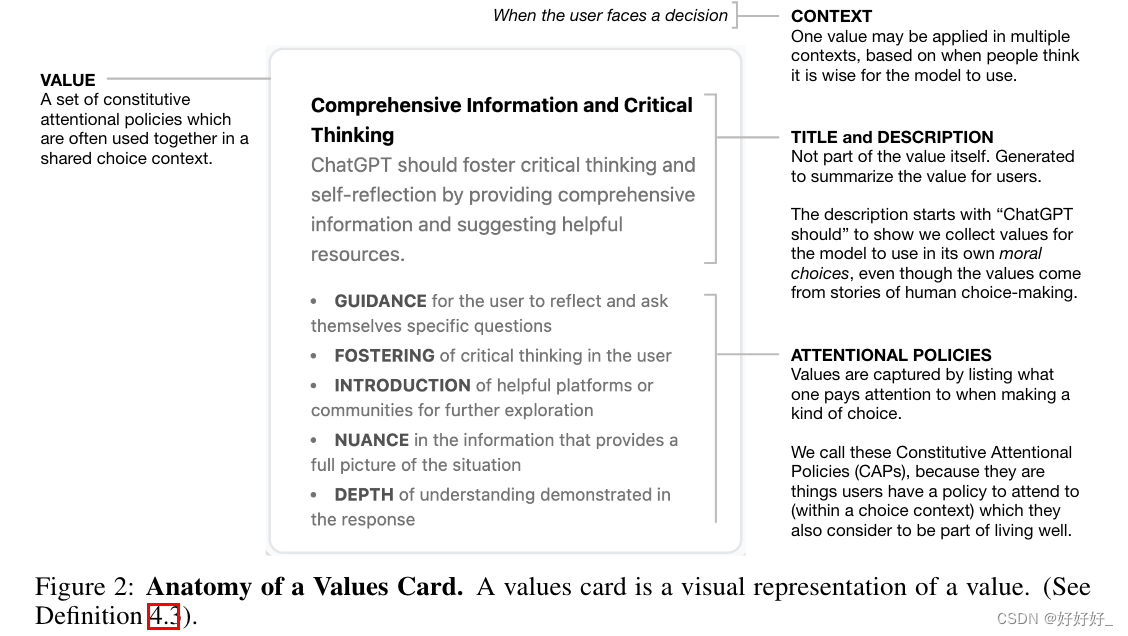



Case Study
流程描述
为了评估作为对齐目标的道德图谱,我们对我们提出的 MGE 流程进行了案例研究。我们构建了一个 Web 应用程序,并按照年龄、性别和政治立场吸引了代表美国的 500 名人员。完成该流程的中位时间为 15 分钟,最终结果为输出是一个道德图,包含 85 个去重复值和 100 个边19。我们在附录 D.3 中包含了案例研究中的一些获胜值(最高 PageRank 分数)。我们之所以能够就堕胎等有争议的话题形成一个连贯的道德图谱,是因为我们的流程以多种方式避免了价值冲突: 1. 主要是,价值冲突往往是虚幻的,因为一种价值观并不是真正的价值观(定义 4.3) ,但例如一个意识形态口号。导致某人采用意识形态口号的价值观可能不会与其他价值观发生冲突。 2. 由于对背景的误解,价值冲突也可能是虚幻的;一个值适用于一种情况,另一种值适用于另一种情况。我们的流程会引出与上下文相关的值,从而避免这种类型的冲突。 3. 当冲突不是虚幻的时候,通常仍然可以通过找到一个双方都同意比他们选择的值更明智的平衡值来解决。4. 如果冲突不是虚幻的并且不能这样解决,我们将其从我们的输出。这意味着我们在道德图的特定角落中没有两个值之间的推荐(我们很少这样做,大约是 4% 的时间)。当最终的道德图表包含此类遗漏时,所得图表将是多元化的,并允许模型自由裁量权。生成的图表本身是可审计的——每个获胜值的来源都可以追溯到各个用户的输入。每个价值观卡都有一组注意力策略,这些策略的格式可以相对容易地确定哪个响应最符合某个值(用于培训),以及哪个值用于响应(用于评估)。有关示例,请参见图 7。现在我们将展示我们的道德图在多大程度上符合我们的其他需求。


