
- 1mssql stuff 使用
- 2AGI:走向通用人工智能的【生命学&哲学&科学】第一篇——生命、意识、五行、易经、量子
- 3[力扣Hot 100------第2题--148.排序链表]_给定两个排序列表l1和l2,计算l1 l2的最快算法具有时间复杂性(nlogn)。
- 4Flask之强大的first_or_404_flask raise 404
- 52024年JAVA招聘行情如何?_2024 java 行情
- 6python爬虫爬取链家二手房信息_爬取链家北京二手房
- 7ElasticSearch教程入门到精通——第二部分(基于ELK技术栈elasticsearch 7.x+8.x新特性)
- 8LangChain(0.0.340)官方文档六:Output parsers_pydanticoutputparser
- 9Android 14 权限_android14 radio.te权限
- 10NLP step by step -- 了解Transformer
MySQL怎么运行的系列(二)Innodb缓冲池 buffer pool 和 改良版LRU算法_log buffer在buffer pool中吗
赞
踩
InnoDB存储结构
下图是官方提供的InnoDB总体结构:分为内存结构(下图左侧)和磁盘结构(右侧)两部分。
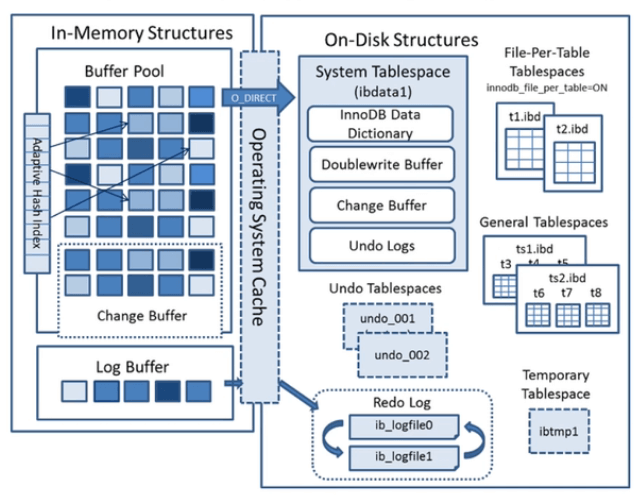
内存部分由多个缓冲区构成,分为 缓冲池(Buffer Pool,检测BP) 和 日志缓冲(Log Buffer),缓冲区的最小逻辑单位是页(page)。
页是数据库的最小操作单位,无论是在磁盘还是内存中数据库的操作单位都是页,一页等于文件系统的一个或者多个块,mysql默认页大小为16K。
磁盘部分包括各种表空间,主要有以下5种:系统表空间(System Tablespace,又称共享表空间)、独立表空间(File-Per-Table Tablespaces)、undo表空间(undo Tablespaces)、通用表空间(General Tablespaces)、临时表空间。
innodb可以选择使用系统表空间还是独立表空间存储表,如果选择前者,则所有innodb表都保存在 ibdata1 这个表文件中,选择后者则一个innodb表占据一个表文件,拥有自己独立的表文件。
缓冲池 Buffer Pool
缓冲池是mysql向操作系统申请的一片连续内存空间(实际上缓存池实例中的块(chunk)内部是连续的,但chunk之间是离散的),存储单位是页,称为缓冲页或缓存页,缓存页的大小和磁盘页一样为16K。
每一个缓存页都会有对应的控制块记录其控制信息(例如页所属的表空间号、页号、页在缓存中的地址、下一页的指针等)。

缓冲池包括:数据页(data Page)、索引页(index Page)、undo页、写缓冲区(change page,简称 CB)、自适应哈希索引(adaptive hash index)和其他信息(如锁信息,数据字典信息)等。
- Buffer Pool 的预读特性
磁盘IO按页读取,查询某条记录不是只读取这条记录,而是读取这条记录所在的整个页并缓存。
根据局部性原理,短期内数据读取是集中在某个小的范围之内的,所以本次读取的数据大概率和上次读取的数据在一个页内。
假设把这个页放到内存缓存,那么这个页下次被命中的可能性比较高,从而避免重复的磁盘IO。所以缓存整个页具有预读的作用,预读也是缓冲池一大作用。
例如 本次查询 id = 5 的行,系统缓存了页号为1001的页,下次查询id = 6的行(假设这两行放在同一页中),就会命中1001号页的缓存,无需进行磁盘IO。
InnoDB怎么在不查询磁盘的情况下知道 id = 6的记录也位于 1001号页呢?很简单,因为该表的索引页缓存了起来,系统查询缓存中的索引页就能得知id=6的数据页页号。
Innodb的预读不仅只读取本次所需的一个页面,还可能读取和该页面相邻近的其他页面。
预读分为两种:线性预读 和 随机预读。
线性预读是指当某个区(extend,1 extend 包含 64 page)内被顺序访问的页面(即离散分布)超过56个时,innodb会把下一个区的全部页面异步载入buffer pool。
随机预读是指当某个区的13个连续页面在buffer pool中,而且这13个页面都在lru热区域的前 1/4 位置内时,innodb都会把本区内的所有页异步载入buffer pool。
- Buffer Pool 的页分类
free page :空闲page,未被使用过的页;
clean page:正在被使用的干净页,即没有被修改过的页;
dirty page:脏页,用户做出DML操作修改数据且这些数据刚好在缓冲池的页就是脏页,这样的页与磁盘中对应的页数据不一致。
针对这3种页,InnoDB使用3种链表维护:
free list:空闲页链表,管理 free page;
flush list:脏页链表,管理 dirty page 并在某个时刻对该链表的脏页进行刷盘,按脏页的修改时间排序,更新操作早的脏页先被刷盘;
lru list:正在使用的内存页链表,里面包含 clean page 和 dirty page,也就是说 lru list 中的页包含 flush list 中的所有脏页。
实际上链表中的节点不是缓存页本身,而是页对应的控制块:
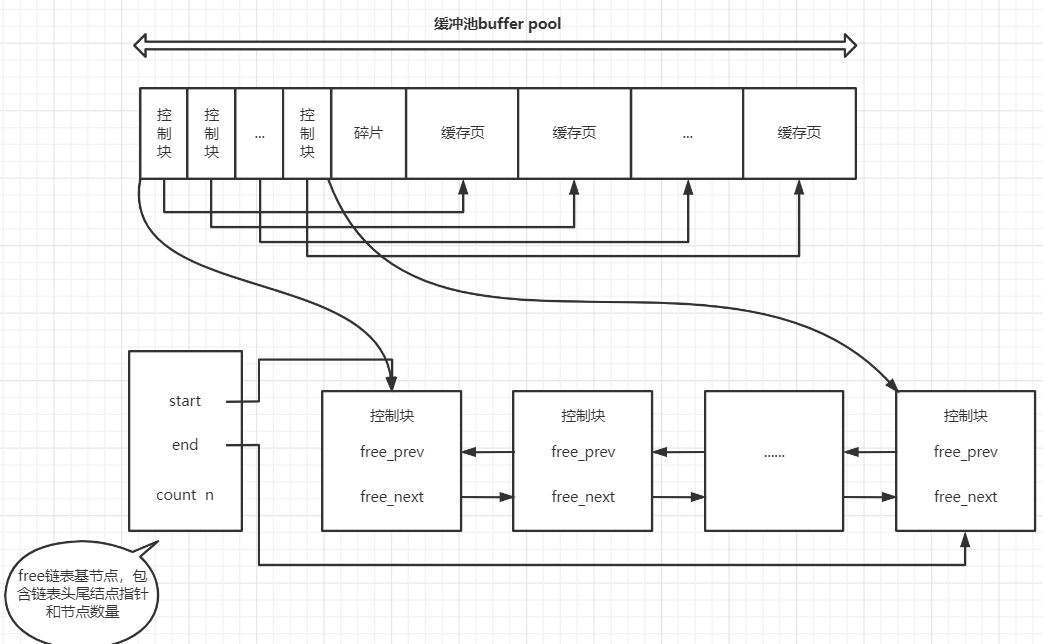
链表的基节点(记录链表首尾节点地址的空间)占用的内存空间并不包含在为 Buffer Pool 申请的一大片连续内存空间之 内,而是一块单独申请的内存空间。
除了这3个列表之外,innodb的buffer pool还管理了很多其他链表如管理压缩页的链表等。
- 改良版lru算法
Innodb的buffer pool中,lru链表遵循LRU算法管理缓存页。
刚开始lru列表是空的,所有的内存页都放在 free 列表;当数据从磁盘读到内存,系统先从free列表查找是否有可用的空闲页,有则从free 列表移除放到lru列表,没有则按照lru算法释放旧的缓存页。
注意:free list + lru list 不一定等于 Buffer Pool 的大小,因为 Buffer Pool 还存放 写缓冲区、自适应哈希索引和其他信息。
整个mysql使用的内存区可以划分为多个Buffer Pool ,一个Buffer Pool 可以分为多个块(chunk),每个chunk包含有多个page。
实际上,innodb使用的是一种改良版的LRU算法来管理缓存页,它相比于正常的LRU算法有以下优化。
优化点1:midpoint
普通LRU遵循新数据从链头加入,链表满了需要释放时从末尾弹出。改良LRU设置了一个 midpoint 点,新页(刚从磁盘读到的页或者刚进入lru list没多久的页)不放在LRU首部,而是放在 midpoint 后的第一个位置,链表满了则从末尾弹出节点。
midpoint 前的页是 热数据 列表区(new list),midpoint 后的页是 冷数据 列表区(old list)。midpoint 默认位于距离 lru 的链头的 5/8 的位置。
使用改良LRU是为了防止某些不常用的数据占用buffer pool空间,比如预读了不常用的页,或者 扫描操作(如全表扫描、索引扫描、大范围查询)查到大量数据,导致缓冲池的热数据被(部分或全部)刷走,这种情况称为缓冲池污染。使用了midpoint之后,被刷走的也只是midpoint后的cold数据。
优化点2:old_blocks_time
InnoDB规定 页读到cold区域之后 需要隔一段时间T才有资格进入到LRU列表的热端(在这段时间T内该cold页再次被访问也不会进入热端列表),这是为了防止某些不常用的页(如全表扫描的页)在短时间(如1秒内)内被多次访问,让系统误以为它是热数据从而将其放入了热端区域。
优化点3:减少热页在链表移动
我们知道热数据页会被频繁的访问,如果一个热数据页每被访问一次就被移动到 lru链表 首部,那么操作内存的开销也不小。Innodb规定热区域的前 1/4 的页被访问后不会移动位置,后 3/4 的页被访问就需要移动到头部,这样可以减少链表的指针操作。
LRU链表还有很多的优化点,这里不一一介绍。
- 缓冲页的哈希处理
我们知道InnoDb访问某页时,不是直接从磁盘读取,而是先从缓冲池(的lru链表)读取页;如果没命中缓存,就从磁盘读取页到缓冲池缓存,下次读到相同的页则直接从缓冲池读取,从而减少磁盘IO。
问题是怎么知道我要查询的页是否在buffer pool呢,难道要对lru链表一个个页遍历?遍历是不可能遍历的,这辈子都不可能遍历的。
其实学过lru算法的小伙伴们都知道,lru算法的实现需要 链表 和 哈希表两个结构。
innodb是通过 页所在表空间号 + 页号 来定位一个页的,所以缓存一个页时,系统除了将该页的控制块链入lru链表之外,还会将 该页的表空间号 + 页号 作为key,页的控制块地址作为value写入到哈希表中。
所以当要访问某个页时,根据该 表空间号+页号 即可得知页在不在buffer pool,在buffer pool的哪个地方。
- 脏页刷盘
后台有专门的线程负责每隔一段时间就把脏页刷新到磁盘,这样可以不影响用户线程正常处理用户请求。
刷新方式主要有下面几种:
1、从LRU 链表的冷数据区刷新部分页面到磁盘
后台线程会定时从 LRU 链表尾部开始扫描指定数量的页面(比如每次只扫描最靠近末尾的1000个页),发现脏页(控制块的某个属性记录了一个页是不是脏页)则刷新到磁盘,这种刷 新页面的方式称为BUF_FLUSH_LRU。
热数据的脏页会随着它不被访问而进入到冷数据区,从而被检测到并刷盘。如果热数据的脏页一直都在使用,不会进入到冷数据区,也可以通过第二种方式保证热数据的脏页在一定时间内刷盘。
优先刷盘冷数据而不优先刷盘热数据是因为,热数据在短时间可能被多次修改,如果优先刷盘热数据页,这个页很快又会被修改,又需要再刷盘,不如等它变成冷数据再刷盘。
2、从 flush 链表中刷新一部分页面到磁盘
这种刷新页面的方式称为 BUF_FLUSH_LIST。flush链表包括 lru链表热数据页 和 冷数据页的脏页。
3、主动刷盘内存池中被淘汰的脏页
如果在buffer pool已满的情况下,用户线程从磁盘读取某个页要链入lru链表,lru链表会释放尾部的一个页。
假设这个释放的页是一个脏页,那么用户线程就不得不亲自把这个脏页刷盘,因而降低用户请求的速度。这种方式称为 BUF_FLUSH_SINGLE_PAGE。
之所以需要后台线程定时刷盘脏页就是为了尽可能避免发生 BUF_FLUSH_SINGLE_PAGE。
- 多个Buffer Pool
一个mysql实例中,缓冲池不只一个,而是有多个,所有缓存页根据哈希值平均分配到不同缓冲池实例。将内存空间分为多个缓冲池是为了增加临界资源,减少多个线程对buffer pool的竞争(毕竟访问buffer pool的各种链表都需要加锁处理),提高并发。
每个 buffer pool有自己独立的内存空间,独立的lru、free、flush链表。buffer pool的个数不是越多越好,因为管理每一个buffer pool也需要开销。
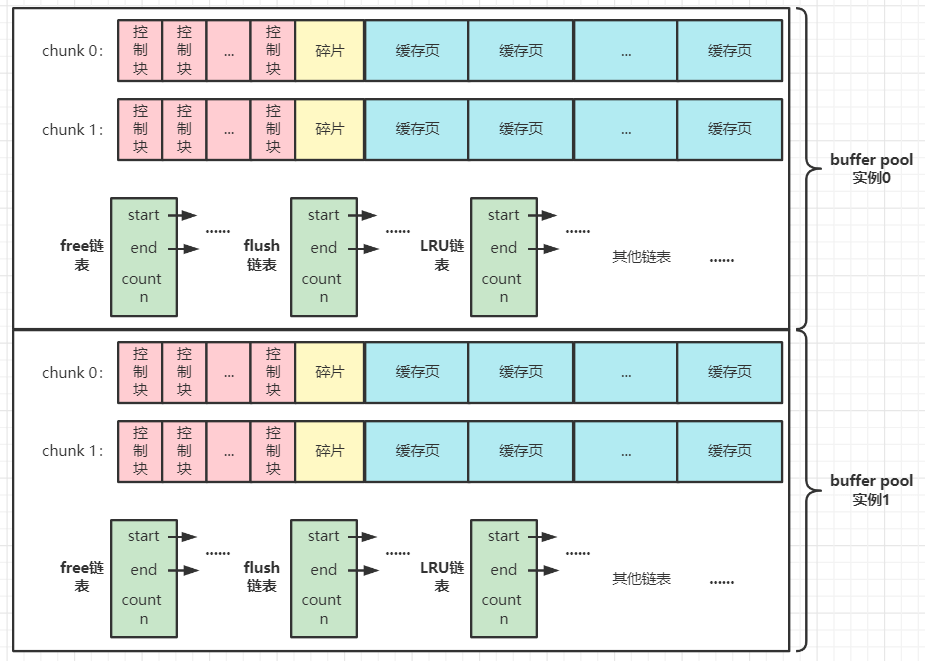
- Buffer Pool分块
Buffer Pool 分块(chunk)是mysql 5.7.5之后的特性,该特性是指一个buffer pool实例是由多个块组成,每个块的块内空间是连续的,块与块之间是离散的。
在 mysql 5.7.5之前,为buffer pool申请内存空间是整个buffer pool 实例都是连续的。
buffer pool分块是为了方便用户可以在mysql运行期间能够调整buffer pool的大小(innodb_buffer_pool_size)。
假设,整个buffer pool都是连续的,如果用户增大buffer pool的大小,系统必须分配一个比原来 buffer pool 更大的连续空间,再将原来buffer pool的数据拷贝到新空间,这个CPU时间开销无疑是巨大的。
但是使用了 分块 存储的方式,当想要增大 buffer pool 的大小时,系统只需多申请一个块或者多个块的空间,并将这些块链入这个buffer pool实例中即可。
一个块的大小由参数innodb_buffer_pool_chunk_size控制,默认一个chunk为128M。
- Buffer Pool 预热
Mysql重启时,BP中的热数据会清空,为此mysql提供了缓冲池预热功能,当关机时会把内存中的热数据写入到 ib_buffer_pool 文件中,保存的数据占 lru 的比例可由参数控制,mysql启动时会自动加载热数据到缓冲池。预热功能默认开启。
- Buffer Pool配置参数
innodb_page_size
BP缓冲区大小(单位是页),建议将其设为总内存的 60% ~ 80%。
innodb_old_blocks_pct
midpoint离链尾的百分比,默认37.5%。
innodb_old_blocks_time
新页需要隔多长时间才能进入lru链表的热端。
innodb_buffer_pool_instances
Buffer Pool的个数,建议设为多个。
innodb_buffer_pool_dump_at_shutdown
关闭服务时保存热数据.
innodb_buffer_pool_dump_pct
保存热数据的比例。
innodb_buffer_pool_load_at_startup
开机时载入热数据
可以通过 show variables like '%...%' 查看以上配置项;
注意:Innodb的缓冲池 和 查询缓存 是不同的两个东西,前者属于存储引擎层,后者属于服务层,前者是缓存已经读取过的页,后者是缓存查询语句和查询结果的映射关系,后者想要命中缓存必须要做到下一次用相同的sql语句查询。
- 写缓冲 Change Buffer
在进行DML操作时,系统不会直接将变更刷新到磁盘中,而是会先将变更的页写入到缓冲区,经过一系列策略同步到磁盘。
此时分为两种情况:
1、当更改的页存在于 Buffer Pool 的 lru 链表,则直接在缓冲池中修改这个页,这个页会变成脏页,链入到 flush list中,但并不马上刷盘;此时不涉及 change buffer 操作。
2、当更改的页不存在于 Buffer Pool 的 lru 链表,就要先从磁盘读取要修改的数据页到Buffer Pool后再修改(数据不可能在磁盘中直接更改,肯定要读到内存,在内存中修改)。
但为了避免修改操作引发的磁盘读IO,系统会将DML操作记录到 change buffer中,并不马上刷盘。
等下次对这些修改的页进行查询时,由于lru链表不存在该页,会从磁盘读取(磁盘页是更改前的数据),为了避免读到脏数据,该磁盘页会和 change buffer中的更改合并后才链入到 lru链表。
如果未来一段时间都不会查询到这个修改了的页,也会有 insert buffer thread 定时将change buffer 的数据合并到磁盘页中。
使用change buffer可以避免数据更改时因为隐式查询数据带来的磁盘IO,这是change buffer提升性能的地方。
如果做出的更改是对唯一键索引的值的修改,innodb要做唯一性校验,必须查询磁盘,再在lru链表上的页修改,不会在change buffer 中操作。
change buffer 默认占 Buffer Pool 的 25%,最大允许占50%。可以根据写业务的量调整,写操作越频繁,change buffer 带来的性能提升越明显。
日志缓冲区 Log Buffer
log buffer 用来缓存要写入log文件的数据(redo和undo)。
这里的log文件是指Innodb引擎的日志,所以不包括什么binlog日志、慢查询日志之类的其他日志,日志缓冲区会定期刷新到磁盘的log文件中。
从日志缓冲区 log buffer 刷盘到 log文件需要经过 操作系统内核的缓冲区 os cahce(见本文第一张图中的 Operation System Cache),因为IO操作需要委托操作系统来完成。
innodb_flush_log_at_trx_commit参数控制日志刷新的行为和周期,默认为1。log日志刷盘有3种策略:
1、每隔1秒从 log buffer 写入OS cache,并马上刷盘,mysql服务故障或者主机宕机则丢失1秒数据。
2、事务提交时,立刻从 log buffer 写入 os cache, 并马上刷盘,mysql服务故障或者主机宕机不会丢失数据,但会频繁发生磁盘IO。
3、事务提交时,立刻从 log buffer 写入 os cache,每隔1秒刷盘,mysql服务故障不会丢失数据,因为数据已经进入操作系统缓存,与mysql进程无关了,主机宕机则丢失1秒数据。
除此之外,当redo/undo日志缓冲区满了之后,也会触发刷盘。
上面所说的刷盘是指日志数据刷盘到log文件,而不是表数据刷盘到表文件,数据刷盘到表文件是发生在redo日志刷盘到redo log文件之后才发生的,而且是从buffer pool刷盘到表文件的。
刷盘操作是异步IO,由专门的线程完成这件事,不会阻塞用户请求的处理。
- InnoDb的线程模型
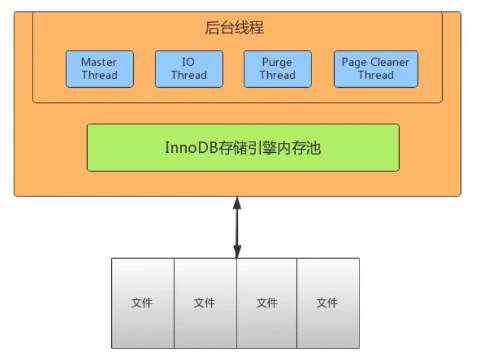
Innodb的这些线程负责的是数据在Innodb的内存和磁盘间的传输。
IO Thread
负责读写操作,使用AIO读写(异步IO),InnoDB 1.0 版本之前一共有4个IO线程,分别是 write、read、insert buffer 和 log thread,后来将read thread 和 write thread增大到4个,一共10个IO线程。
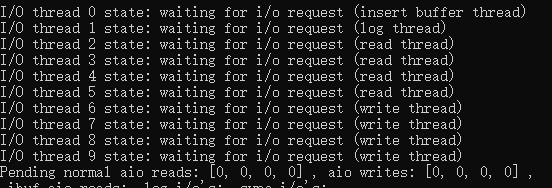
read thread:将数据从磁盘加载到缓存page页;
write thread:将缓存脏页刷新到磁盘;
log thread:将日志缓冲区刷盘到log文件;
insert buffer thread:将写缓冲change buffer的更改内容刷新到磁盘;
Purge Thread
事务提交之后,该事务相关的undo日志不再需要,Purge Thread负责回收已分配的undo页。默认有4个purge thread。
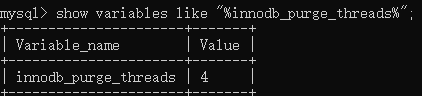
Page Cleaner Thread
将脏数据刷新到磁盘(会调用 write thread 线程),脏数据刷盘后对应的redo log也就没用了,可以释放掉这部分 redo log,达到redo log 循环使用的目的。默认有1个Page Cleaner thread。
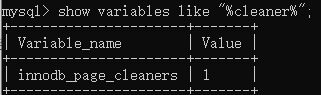
Master Thread 主线程
负责调度其他线程,优先级最高。主要职能:脏页刷盘(调用page cleaner thread)、undo页回收(purge thread)、redo日志刷新(log thread)、合并写缓冲(insert buffer thread)。如果这些子线程通过配置关闭了,那么关闭的子线程的任务就会由master thread来做。
主线程是由多个无限循环构成的,主要有2个主处理,分别是每隔1秒和10秒的处理:
每1秒的操作(有条件的做):
·刷盘日志缓冲区
·合并change buffer数据到磁盘的B+树中,根据IO读写压力决定是否操作
·刷盘脏页到磁盘(条件是脏页比例达到75%才操作(innodb_max_dirty_pages_pct),而且不是一次性刷盘所有脏页,而是默认每次刷盘200页(innodb_io_capacity))。
每10秒操作(无条件的做):
·刷盘脏页到磁盘
·合并change buffer数据
·刷盘日志缓冲区
·删除无用的undo页



