
- 1git如何远程推送到gitlab_初次使用gitlab,本地代码push到远程指定的分支
- 2git:git用户push后无法弹出输入指定gitee的用户及密码的窗口_git push 指定用户
- 3数据结构与算法导论---通讯录的实现_数据结构与算法实训通讯录代码总结
- 4Vscode-Git graph怎么看?
- 5微信小程序开发系列(三十二)·如何通过小程序的API实现页面的上拉加载(onReachBottom事件)和下拉刷新(onPullDownRefresh事件)_微信小程序 onreachbottom
- 6git 克隆出问题remote: Access denied fatal: unable to access ‘<url>‘ The requested URL returned error: 403_git clone remote: [session-e84593b6] access denied
- 7【开发工具篇】git 常用命令合集_git镜像地址
- 8DES算法的介绍和实现_des实现类
- 9Mistral AI 推出最新Mistral Large模型,性能仅次于GPT 4_mistral-large
- 10微信小程序web-view使用说明,及链接打不开问题
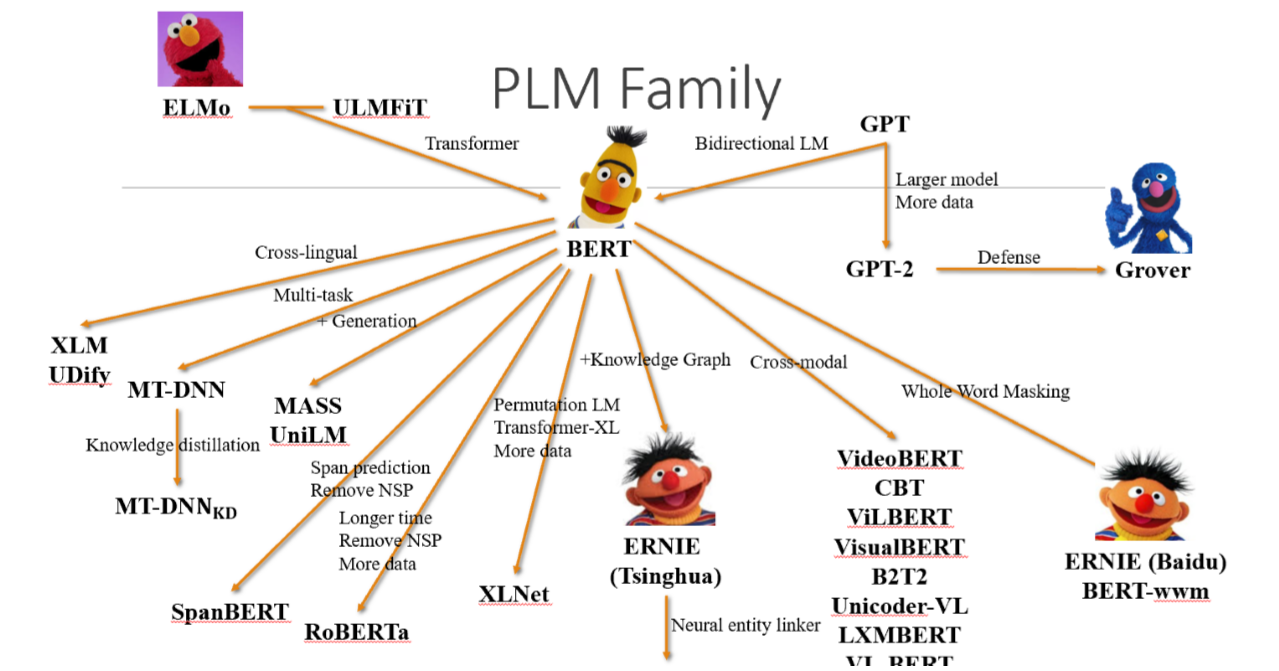
深入浅出语言模型(四)——BERT的后浪们(RoBERTa、MASS、XLNet、UniLM、ALBERT、TinyBERT、Electra)_roberta tiny
赞
踩
引言
上一节我们讲到了BERT,如果要用一句时下正流行的话来形容 BERT 的出现,这句话大概再恰当不过: 一切过往, 皆为序章。 Bert出现之后,研究者们开始不断对其进行探索研究,提出来各式的改进版,再各类任务上不断超越Bert。针对Bert的改进,主要体现在增加训练语料、增添预训练任务、改进mask方式、调整模型结构、调整超参数、模型蒸馏等。下面对近年来Bert的改进版本的关键点做叙述。
深入浅出语言模型(一)——语言模型及其有趣的应用
深入浅出语言模型(二)——静态语言模型(独热编码、Tf-idf、word2vec、FastText、glove、Gussian Embedding、Pointcare Embedding )
深入浅出语言模型(三)——语境化词向量表示(CoVe、ELMo、ULMFit、GPT、BERT)
深入浅出语言模型(四)——BERT的后浪们(RoBERTa、MASS、XLNet、UniLM、ALBERT、TinyBERT、Electra)
RoBERTa
Facebook提出了RoBERTa(a Robustly Optimized BERT Pretraining Approach)。再度在多个任务上达到SOTA。那么它到底改进了什么?它在模型层面没有改变Google的Bert,改变的只是预训练的方法。
- 训练时间更长,batch size更大,训练数据更多。借鉴XLNet用了比Bert多10倍的数据,RoBERTa也用了更多的数据。性能确实再次彪升。当然,也需要配合更长时间的训练。
- 移除了next predict loss,发现NSP任务对训练语言模型帮助并不大
- 训练序列更长。RoBERTa去除了NSP,而是每次输入连续的多个句子,直到最大长度512(可以跨文章)。
- 动态调整Masking机制。 BERT中是准备训练数据时,每个样本只会进行一次随机mask(因此每个epoch都是重复),后续的每个训练步都采用相同的mask,这是原始静态mask,这是原始 BERT 的做法。作者先提出了修改版静态mask,在预处理的时候将数据集拷贝 10 次,每次拷贝采用不同的 mask;然后又提出了动态mask,并没有在预处理的时候执行 mask,而是在每次向模型提供输入时动态生成 mask,所以是时刻变化的。
- 在Text Encoding方面采用的是BPE。原始BERT的Wordpiece是于基于 char-level实现的,是基于概率生成新的subword。在本文中,他和GPT-2采用的方式一样,基于下一最高频字节对进行合并,用 bytes 而不是 unicode 字符作为 sub-word 的基本单位。关于BPE的一些讲解推荐一些资料:NLP subword算法,
该论文中的BPE。
MASS
Mass是微软亚洲研究院的研究员在ICML 2019上提出了一个全新的通用预训练方法,在序列到序列的自然语言生成任务中全面超越BERT和GPT。屏蔽序列到序列预训练(MASS: Masked Sequence to Sequence Pre-training)。MASS对句子随机屏蔽一个长度为k的连续片段,然后通过编码器-注意力-解码器模型预测生成该片段。如下图所示,编码器端的第3-6个词被屏蔽掉,然后解码器端只预测这几个连续的词,而屏蔽掉其它词,图中“_”代表被屏蔽的词。类似Transformer版的Cove。

MASS预训练有以下几大优势:
- 解码器端其它词(在编码器端未被屏蔽掉的词)都被屏蔽掉,以鼓励解码器从编码器端提取信息来帮助连续片段的预测,这样能促进编码器-注意力-解码器结构的联合训练。
- 为了给解码器提供更有用的信息,编码器被强制去抽取未被屏蔽掉词的语义,以提升编码器理解源序列文本的能力。
- 让解码器预测连续的序列片段,以提升解码器的语言建模能力。
其实MASS的本质思想相当于BERT和GPT的融合,可以通过MASK片段的长度 k k k来控制。当 k = 1 k=1 k=1时,根据MASS的设定,编码器端屏蔽一个单词,解码器端预测一个单词,这时MASS和BERT中的屏蔽语言模型的预训练方法等价;当 k = m k=m k=m( m m m为序列长度)时,根据MASS的设定,编码器屏蔽所有的单词,解码器预测所有单词,如下图所示,由于编码器端所有词都被屏蔽掉,解码器的注意力机制相当于没有获取到信息,在这种情况下MASS等价于GPT中的标准语言模型。
XLNet
上一个博客说了AR和AE模型存在一些缺点,这里再简单说一下AR方式所带来的自回归性在预测时学习了被预测 token 之间的依赖,这是 AE的BERT 所没有的;而 BERT的AE方式带来的对深层次双向信息的学习,却又是像ELMo还有GPT这种AR单向语言模型所没有的。通常来说以BERT为代表的AE模型做生成任务是不如AR的。于是,人们自然就会想,如何将自回归模型和自编莫模型两者的优点统一起来? 这时就到了XLNet登场的时间。
XLNet在文中指出的,第一个预训练阶段因为采取引入[Mask]标记来Mask掉部分单词的训练模式,而Fine-tuning阶段是看不到这种被强行加入的Mask标记的,所以两个阶段存在使用模式不一致的情形,这可能会带来一定的性能损失;另外一个是,Bert在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的,XLNet则考虑了这种关系。
XLNet的核心思想是Permutation Language Model,具体实现方式是,通过随机取一句话排列的一种,然后将末尾一定量的词给“遮掩”(和 BERT 里的直接替换 “[MASK]” 有些不同)掉,最后用 AR 的方式来按照这种排列方式依此预测被“遮掩”掉的词,论文中 Permutation 具体的实现方式是通过直接对 Transformer 的 Attention Mask 进行操作。
Two-Stream Self-Attention
首先我们会发现,打乱顺序后位置信息非常重要,同时对每个位置来说,需要预测的是内容信息(对应位置的词),于是输入就不能包含内容信息,不然模型学不到东西,只需要直接从输入 copy 到输出就好了。于是这里就造成了位置信息与内容信息的割裂,因此在 BERT 这样的位置信息+内容信息输入 Self-Attention (自注意力) 的流(Stream)之外,作者们还增加了另一个只有位置信息作为 Self-Attention 中 query 输入的流。文中将前者称为 Content Stream,而后者称为 Query Stream。这样子就能利用 Query Stream 在对需要预测位置进行预测的同时,又不会泄露当前位置的内容信息。具体操作就是用两组隐状态(hidden states),g 和 h,其中 g 只有位置信息,作为 Self-Attention 里的 Q,h 包含内容信息,则作为 K 和 V;对于Content Stream ,h 同时作为 Q K V。
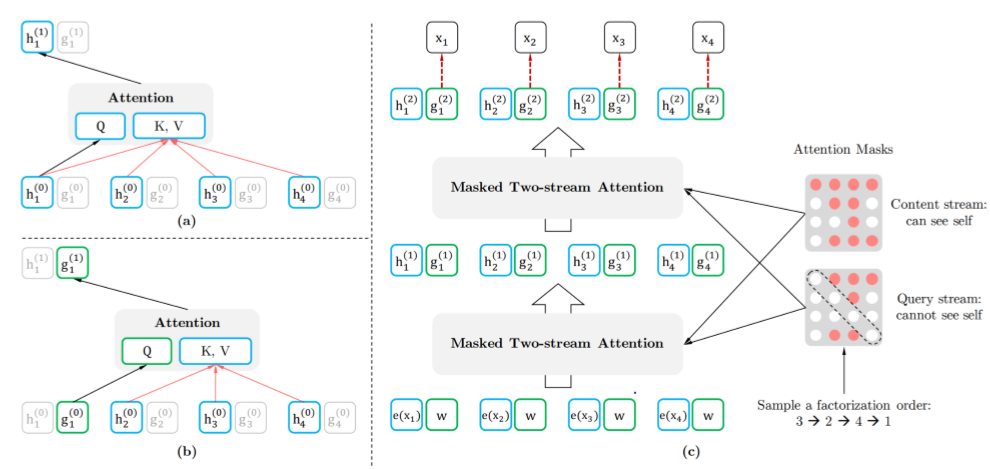
- context stream 就和普通的self-attention一样编码的是内容信息,但是是基于lookahead的mask 策略,即只能看到自己以及之前位置的内容信息。
- query stream 编码的是位置信息,可以看到自己的位置信息,还有之前的内容信息但是不能看到自己的内容信息。
Transformer-XL
Transformer-XL和Vanilla Transformer都是用来解决Transformer无法建模超过固定长度的依赖关系,对长文本编码效果差的问题,从而更好的建模长距离依赖。在本文中,引入了Transformer-XL的主要思路:相对位置编码以及分段RNN机制。实践已经证明这两点对于长文档任务是很有帮助的。
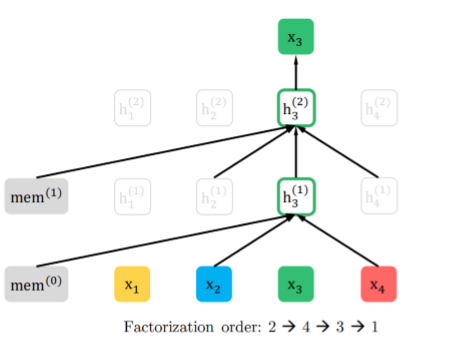
Segment Recurrence Mechanism
Segment Recurrence Mechanism 想做的就是,能不能在前一段计算完后,将它计算出的隐状态(hidden states)都保存下来,放入一个 Memory 中去,之后在当前分段计算时,将之前存下来的隐状态和当前段的隐状态拼起来作为 Attention 机制的 K 和 V,从而获得更长的上下文信息。下图的 mem 的身份也就很明显了,就是 Segment Recurrence Mechanism 中用到的 memory,一面存放着之前 segment 的隐状态。
Relative Positional Encoding
相对位置编码,不再关心句中词的绝对信息,而是相对的,比如说两个词之间隔了多少个词这样的相对信息Transformer-XL 给出的改进方案是这样:

Relative Segment Encodings
但当这个遇上 Segment Recurrence Mechanism 时,和位置向量一样,也出问题了。万一出现了明明不是一句,但是相同了怎么办,于是我们就需要最后一块补丁,同样准备两个向量, s + s+ s+ 和 s − s- s− 分别表示在一句话内和不在一句话内。具体实现是在计算 attention 的时候加入一项:
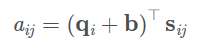
s i j s_{ij} sij也是来自于两个可训练的向量 s + s_+ s+和 s − s_- s−,当 i i i和 j j j来自用一个segment时, s i j = s 1 s_{ij}=s1 sij=s1;否则 s i j = s 0 s_{ij}=s_0 sij=s0。
UniLM
参考BERT提出了新的Seq2Seq任务的预训练方法,接下来要讲的是另一个BERT-based生成模型-UNILM,也是微软出的,他和MASS、XLNet一样都是为生成任务而成的。作者很巧妙的抓住了MASK这个点,认为不管是什么LM,本质都是在训练时能获取到什么信息,在实现层面其实就是mask什么输入的问题。所以完全可以把Seq2Seq LM整合到BERT里,在 S1 [SEP] S2 [SEP] 中,S1用encoder编码,S2中的token只能获取S1和自己之前的token信息,如图最下面那个mask矩阵。

Input representation:这里和BERT一样使用了三个Embedding,但是参考WordPiece把token都处理成了subword,增强了生成模型的表现能力。另外,作者强调了segment embedding可以帮助区分不同的LM。
Bidirectional LM:对于双向的LM,只对padding进行mask。
Unidirectional LM:对于MASK的预测,只能使用t自己以前的字符以及自己位置能够被使用,使用的就是一个对角矩阵的。同理从右到左的LM也类似。
Seq2Seq LM:输入两句。第一句采用BiLM的编码方式,第二句采用单向LM的方式。同时训练encoder(BiLM)和decoder(Uni-LM)。处理输入时同样也是随机mask掉一些token。
训练:在一个batch里,优化目标的分配是1/3的时间采用BiLM和Next sentence,1/3的时间采用Seq2Seq LM,1/6的时间分别给从左到右和从右到左的LM。
Mask:对于加Mask,80%的时间随机mask一个,20%时间会mask一个bigram或trigram,增加模型的预测能力。
UniLM vs MASS
UNILM和MASS的目标一样,都是想统一BERT和生成式模型,但我个人认为UNILM更加优雅。首先UNILM的统一方法更加简洁,从mask矩阵的角度出发改进,而MASS还是把BERT往Seq2Seq的结构改了,再做其他任务时只会用到encoder,不像UNILM一个结构做所有事情。
ALBERT
这个论文和前面的论文出发点不太一样,这篇论文是基于模型压缩去做的。在BERT之后出现的一些预训练模型,都以BERT作为baseline,并且声称模型效果超越了BERT。但是我们必须注意到,大部分这些模型的规模,都是超过BERT的。这种类似军备竞赛的研究方法,在工业界的意义是不大的,因为即使模型的效果再好,也无法部署上线,只能跑跑离线任务。所以模型压缩十分重要。
该模型是如何改造BERT的呢?
对Embedding进行因式分解
在BERT中,词embedding维度 ( E ) (E) (E)与encoder输出的维度 ( H ) (H) (H)是一样的都是768。但是ALBERT认为,词级别的embedding是没有上下文依赖的信息的,而隐藏层的输出值不仅包含了词本身的意思还包括一些上下文依赖信息,因此理论上来说隐藏层的表述包含的信息应该更多一些,所以应该让 H > > E H>>E H>>E才比较合理。
另外在NLP任务中,通常词典都会很大,embedding matrix的大小是 E × V E×V E×V,如果和BERT一样让 H = E H=E H=E,那么embedding matrix的参数量会很大,并且反向传播的过程中,更新的内容也比较稀疏,造成模型空间的浪费。
针对上述的两个点,ALBERT采用了一种因式分解的方法来降低参数量,简单来说就是在输入与Embedding输出之间加了个线性映射。首先把one-hot向量映射到一个低维度的空间,大小为E,然后再映射到一个高维度的空间,说白了就是先经过一个维度很低的embedding matrix,然后再经过一个高维度matrix把维度变到隐藏层的空间内,从而把参数量从 O ( V × H ) O(V×H) O(V×H)降低到了 O ( V × E + E × H ) O(V×E+E×H) O(V×E+E×H),当 E < < H E<<H E<<H时参数量减少的很明显。
跨层的参数共享
传统的BERT有12层,每层有FFN和attention两个子层,模型训练好后,它们的参数是不一样的。作者发现很多参数都是相似的,如下图所示。在“层间参数共享”方法里,部分层(子层)的参数可以是共享的,这样就节约了存储参数的空间。经过炼丹实践,得出以下经验:
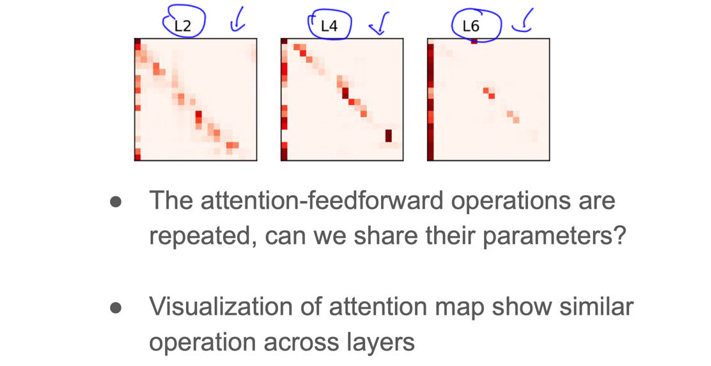
(1)共享FFN层的参数,会导致模型效果下降。
(2)共享attention层的参数,模型效果不会下降(词向量维度E=128时)或者轻微下降(词向量维度E=768时)。
(3)我们可以将L层模型分为N组,每组包含M层,进行组内参数的共享。
参数量最大从
O
(
12
×
L
×
H
×
H
)
O(12×L×H×H)
O(12×L×H×H)降低到了
O
(
12
×
H
×
H
)
O(12×H×H)
O(12×H×H)
移去NSP任务,使用SOP任务
BERT的NSP任务实际上是一个二分类,训练数据的正样本是通过采样同一个文档中的两个连续的句子,而负样本是通过采用两个不同的文档的句子。NSP的设计思路实际上是将主题预测和连贯性预测这两个任务混杂在同一个任务里。主题预测任务比连贯性预测任务更容易学习训练,并且在MASK语言模型的训练过程中已经学到了不少主题预测的信息。
ALBERT中,为了只保留一致性任务去除主题识别的影响,提出了一个新的任务—句子连贯性预测 sentence-order prediction(SOP),SOP的正样本和NSP的获取方式是一样的,负样本把正样本的顺序反转即可。这样做的目的是:通过调整正负样本的获取方式去除主题识别的影响,使预训练更关注于句子关系一致性预测。
移除dropout
ALBERT的作者还发现一个很有意思的点,ALBERT在训练了100w步之后,模型依旧没有过拟合,于是乎作者果断移除了dropout,没想到对下游任务的效果竟然有一定的提升。
TinyBERT
BERT 的效果好,但是模型太大且速度慢,因此需要有一些模型压缩的方法。TinyBERT 是一种对 BERT 压缩后的模型,由华中科技和华为的研究人员提出。TinyBERT 主要用来模型蒸馏的方法进行压缩,在 GLUE 实验中可以保留 BERT-base 96% 的性能,但体积比 BERT 小了 7 倍,速度快了 9 倍。
模型蒸馏 Distillation 是一种常用的模型压缩方法,首先训练一个大的 teacher 模型,然后使用 teacher 模型输出的预测值训练小的 student 模型。student 模型学习 teacher 模型的预测结果 (概率值) 从而学习到 teacher 模型的泛化能力。
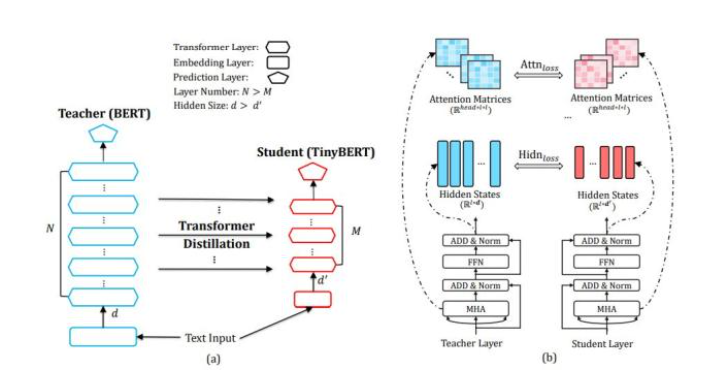
模型创新点
(1)TinyBERT模型提出了一个用于transformer模型的知识蒸馏方法。
(2)TinyBERT模型提出了一个两阶段的学习框架:通用知识蒸馏阶段,基于特定任务的蒸馏阶段。
基于transformer的知识蒸馏方法
(1)在两个方面对模型进行了简化:层数,向量维度。
(2)设计了三种损失函数:embd层的输出,每个transform层的隐藏状态和注意力矩阵,最后一层的logits输出
(3)BERT学习到的注意力权重包含了潜在的语言信息,在从教师网络BERT到学生网络TinyBERT的转换中,语义信息也被传递了。
两阶段的蒸馏框架
(1)在通用知识蒸馏阶段,缩减层数和维度,会导致模型效果的下降。
(2)模型在fine-tune蒸馏阶段使用了数据增强。
数据增强
(1)先mask文本中的一个字词,使用语言模型BERT预测出这个位置最有可能的M个字词,作为候选集。
(2)使用一个门限p去决定,是否将这个被mask的字词随机替换为备选集中的一个字词。如果词语由多个字组成,那么使用GloVe的固定词向量进行替换,而不使用BERT模型输出的候选集中的字词。
(3)对文本中的每个词,重复地执行以上步骤,这样能得到一个新的文本
Electra
ELECTRA对Bert的改进最主要的体现在是提出了新的预训练任务和框架,把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。模型总体结构如下:使用一个MLM的Generator-BERT(生成器)来对输入句子进行更改,然后传给Discriminator-BERT(判别器)去判断哪个词被改过。
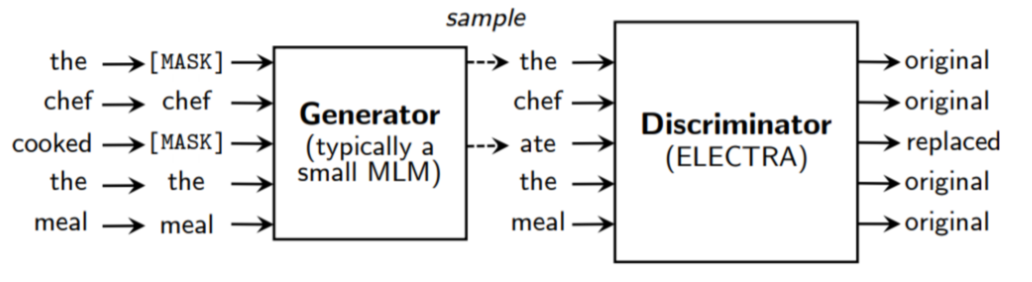
generator:就是一个小的 masked language model(通常是 1/4 的discriminator的size),该模块的具体作用是他采用了经典的bert的MLM方式;iscriminator:discriminator的接收被generator corrupt之后的输入,discriminator的作用是分辨输入的每一个token是original的还是replaced,注意:如果generator生成的token和原始token一致,那么这个token仍然是original的。
该模型采用了minimize the combined loss的方式进行训练:
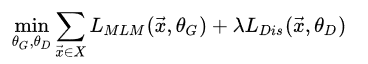
为什么要联合训练?
我们可以分析,为什么共同训练会使得模型得到好的效果?其实我们形象地理解,就是我们把generator当作是出题人,discriminator当作是答题者。模型在训练过程中,出题人出的题越来越有水平,答题者也随着积累,越来越厉害。而不是刚开始出题人出的题目就非常复杂,答题人根本没办法学习。

