
- 1Git教程-搭建服务器上GitBlit代码仓库(超详细)_搭建gitblit服务
- 2已解决java.nio.file.FileSystemException文件系统异常的正确解决方法,亲测有效!!!
- 3[网络安全自学篇] 二十五.Web安全学习路线及木马、病毒和防御初探_网络安全文字教程
- 4HTML静态网页作业(HTML+CSS)——外卖平台主题网页设计制作(8个页面)_html加css外卖静态网站
- 5第一篇【传奇开心果系列】Python的PyTorch库技术点案例示例:深度解读PyTorch深度学习在医学领域应用
- 6物联网学习之二:ESP8266 MQTT连接服务器_mqttx链接esp8266
- 7RTL硬件实现 | 定点化_rtl 四舍五入
- 8ImageButton去边框的问题_mfc 设置了背景图片后 按钮有白边
- 9Midjourney角色一致性功能使用方法教程(附今日提示词)_一致性角色 paper
- 10在Node.js中,什么是模块(module)?如何导入和导出模块?_nodejs module
数据结构之堆的详解_数据结构 堆
赞
踩
一.堆的概念
1.1 堆的基本概念
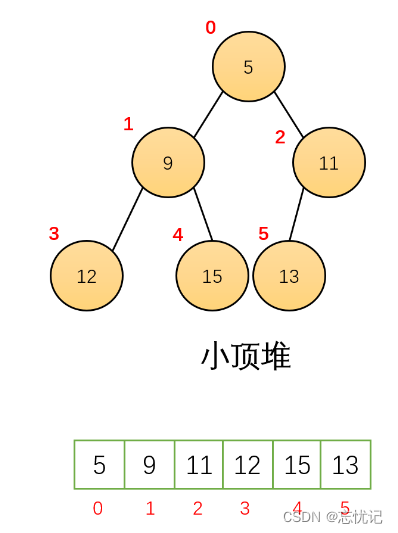
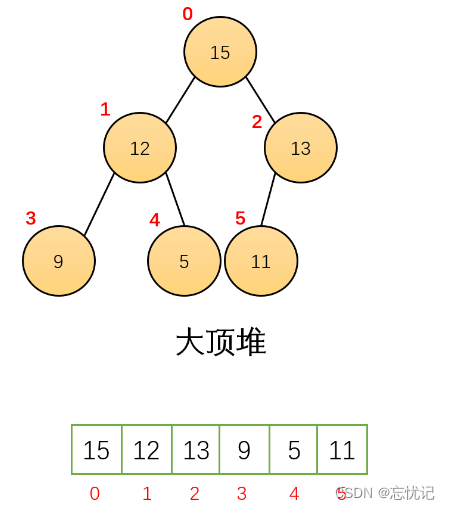
- 堆中某个节点的值总是不大于或不小于其父节点的值;
1.2 堆的存储方式
从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储.

二.堆的操作和实现
基本框架
我们采用数组的方式实现一课完全二叉树,下述就是基本描述代码.
public class TestHeap { public int[] elem; public int usedSize; public TestHeap() { this.elem = new int[10]; } public void initElem(int[] array) { for (int i = 0; i < array.length; i++) { elem[i] = array[i]; usedSize++; } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
建堆
当然,在我们构建了完全插树之后,我们要进行一系列的操作,接下来的第一个操作就是建堆操作.
我这里给出一个建堆操作的过程,我们以建立最大堆为例子.
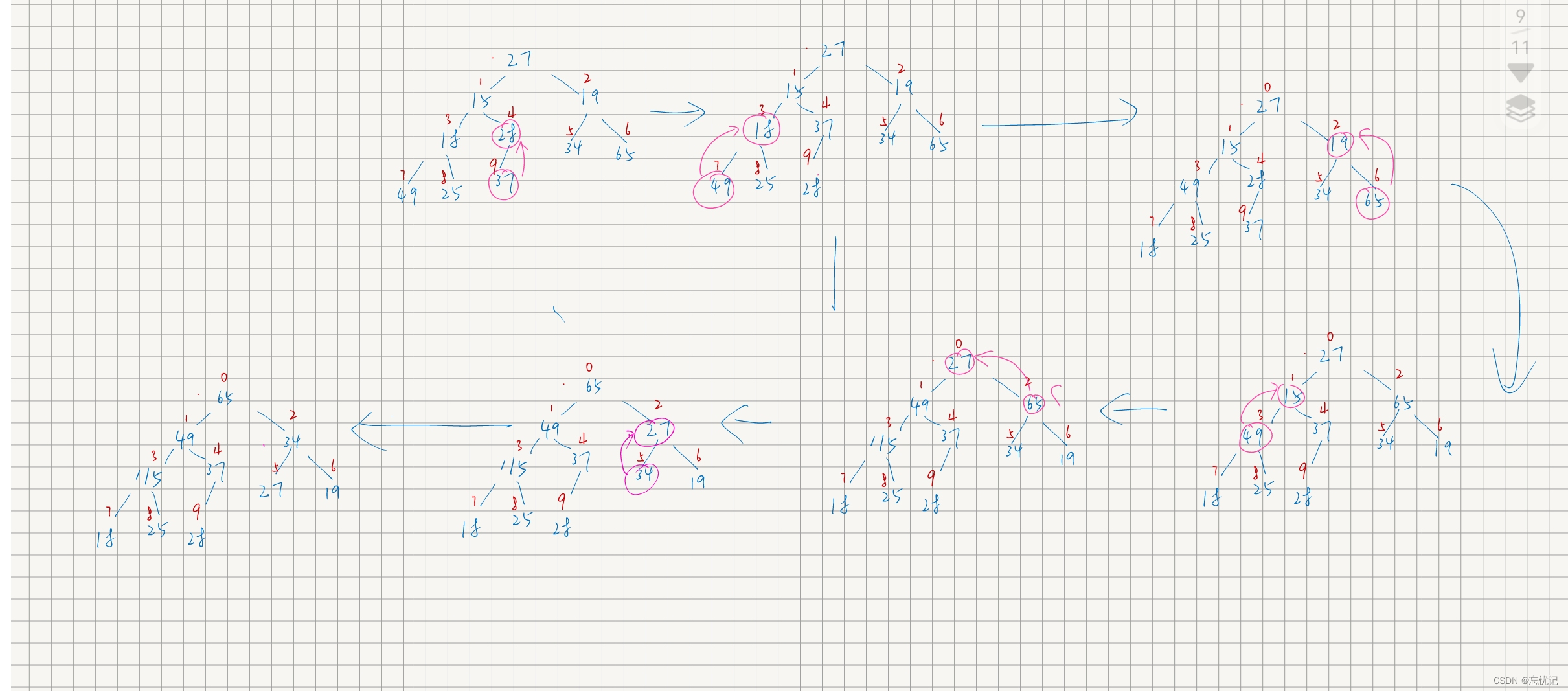
以下方法的思路如下:
大家可以参考一下.
shiftDown 方法的思路如下:
- 首先找到当前节点的左子节点,作为当前比较的子节点。
- 如果有右子节点,并且右子节点的值大于左子节点,则将右子节点作为比较的子节点。
- 如果比较的子节点的值大于父节点的值,则交换父节点和子节点的值,并继续比较交换后的子节点。
- 重复步骤 2-3,直到父节点的值大于子节点的值,则结束下沉。
createHeap 方法的思路:
- 从最后一个非叶子节点开始,逐层下沉。
- 对每个非叶子节点调用 shiftDown 方法进行下沉操作。
- 重复步骤 1-2 直到根节点,则整个数组形成一个大顶堆。
public void createHeap() { for (int parent = (usedSize-1-1)/2; parent >= 0 ; parent--) { shiftDown(parent,usedSize); } } /** * 父亲下标 * 每 * 棵树的结束下标 * @param parent * @param len */ private void shiftDown(int parent,int len) { int child = 2*parent + 1; //最起码 要有左孩子 while (child < len)( { //一定是有右孩子的情况下 if(child+1 < len && elem[child] < elem[child+1]) { child++; } //child下标 一定是左右孩子 最大值的下标 if(elem[child] > elem[parent]) { int tmp = elem[child]; elem[child] = elem[parent]; elem[parent] = tmp; parent = child; child = 2*parent+1; }else { break; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
下面是时间复杂度的分析过程.
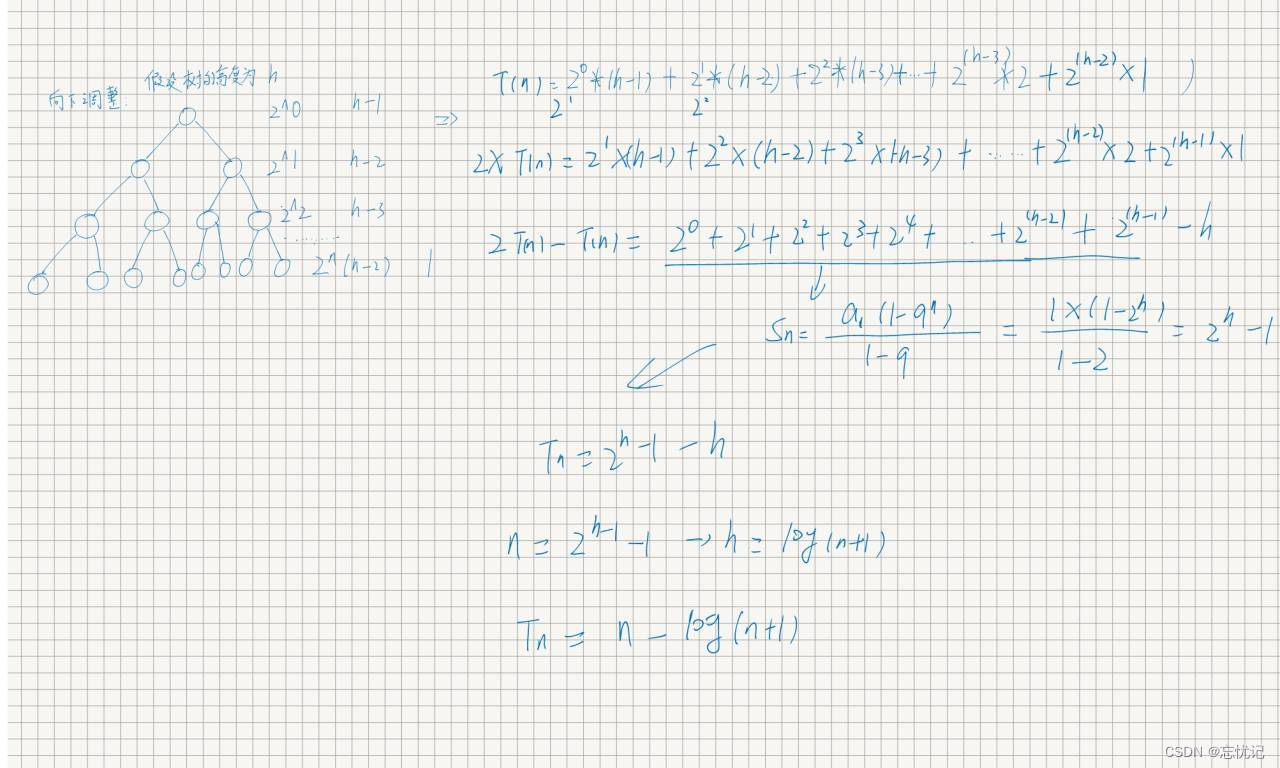
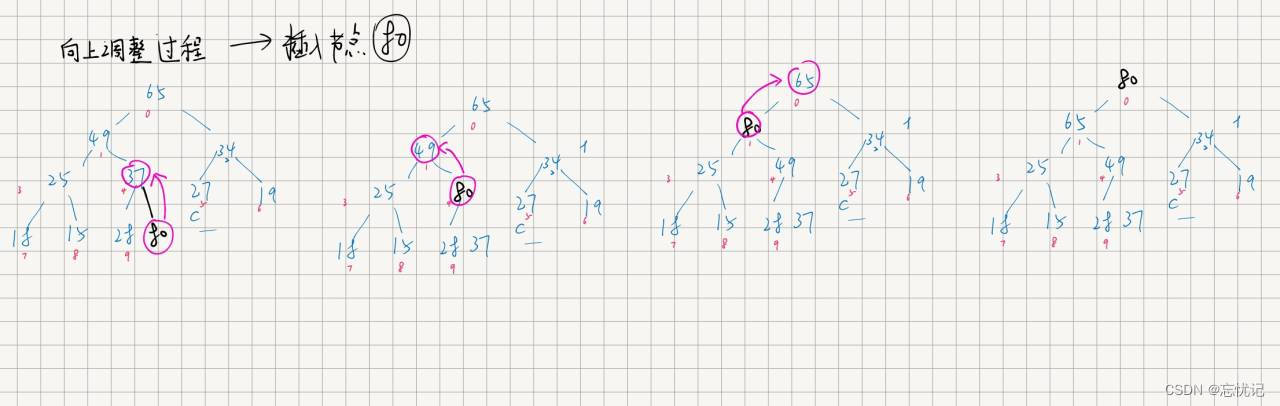
插入
数据的插入
向上调整的具体过程
下面的代码思路如下:
shiftUp 方法的思路如下:
- 首先找到当前新增元素的父节点。
- 如果当前元素的值大于父节点的值,则交换两者的值。
- 交换后,当前元素的父节点变为原先的祖父节点。
- 重复步骤 2-3,直到当前元素的值不大于父节点的值,上浮结束。
offer 方法的思路:
- 首先判断堆是否已满,如果满了则扩容。
- 将新增元素添加到数组尾部。
- 调用 shiftUp 方法,对新增元素进行上浮操作。
- 重复上浮,直到上浮结束,则新增元素添加完成。
该实现的时间复杂度是 O(logn),空间复杂度是 O(n)。
//向上调整建堆的时间复杂度:N*logN public void offer(int val) { if(isFull()) { //扩容 elem = Arrays.copyOf(elem,2*elem.length); } elem[usedSize++] = val;//11 //向上调整 shiftUp(usedSize-1);//10 } private void shiftUp(int child) { int parent = (child-1)/2; while (child > 0) { if(elem[child] > elem[parent]) { int tmp = elem[child]; elem[child] = elem[parent]; elem[parent] = tmp; child = parent; parent = (child-1)/2; }else { break; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
具体的向上调整时间复杂度分析

删除
删除过程如下:
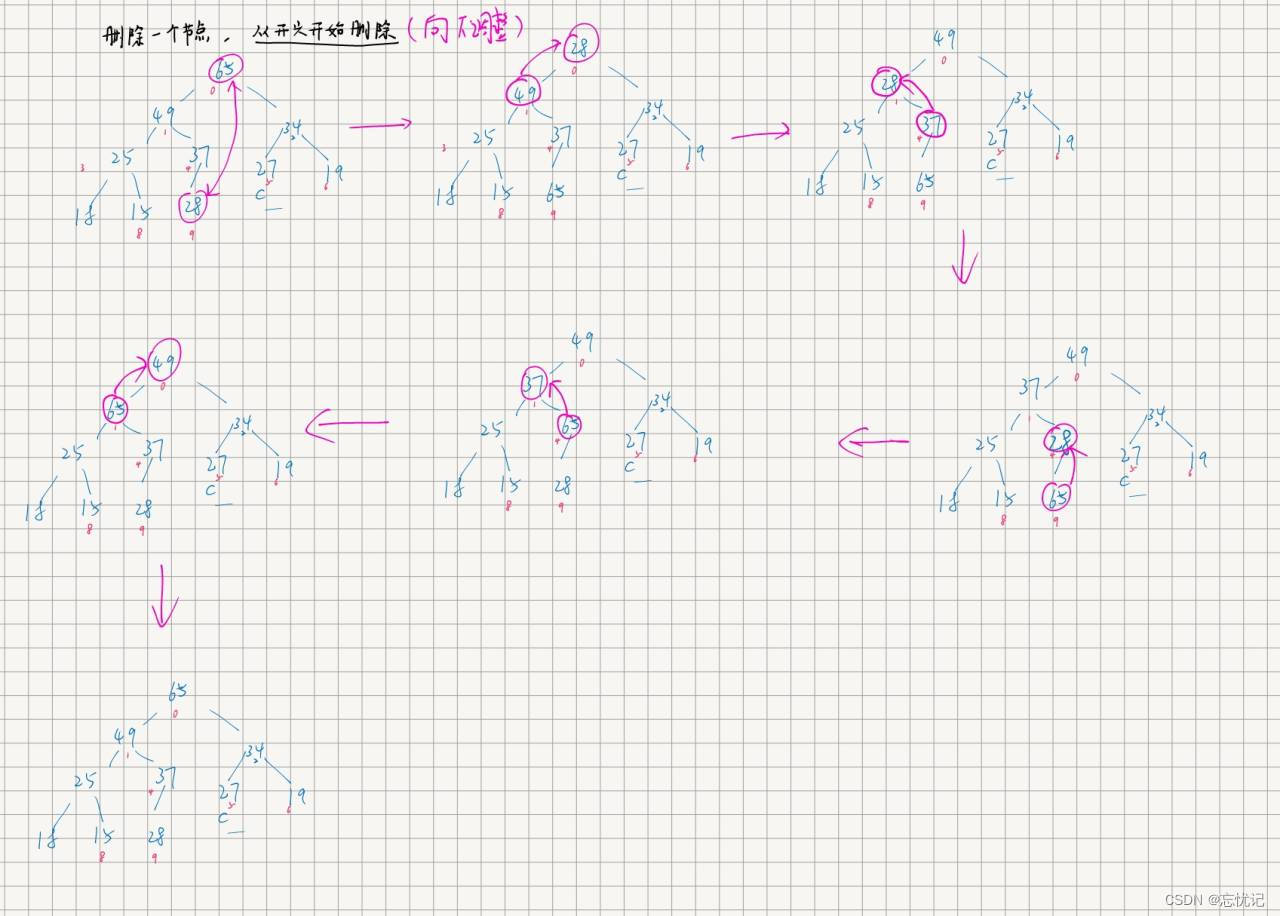
具体思路如下:
pop 方法的思路:
- 首先判断堆是否为空,如果为空则返回。
- 交换根节点和最后一个元素。
- 减小 usedSize,表示元素数量减一。
- 调用 shiftDown 方法,对根节点进行下沉操作。
- 重复下沉,直到下沉结束,则弹出根节点元素完成。
- 该实现的时间复杂度是 O(logn),空间复杂度是 O(1)。
public void pop() { if(isEmpty()) { return; } swap(elem,0,usedSize-1); usedSize--; shiftDown(0,usedSize); } private void shiftDown(int parent,int len) { int child = 2*parent + 1; //最起码 要有左孩子 while (child < len) { //一定是有右孩子的情况下 if(child+1 < len && elem[child] < elem[child+1]) { child++; } //child下标 一定是左右孩子 最大值的下标 if(elem[child] > elem[parent]) { int tmp = elem[child]; elem[child] = elem[parent]; elem[parent] = tmp; parent = child; child = 2*parent+1; }else { break; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
三.堆的应用
优先队列
再开始堆的拓展之前,我们先来看一个概念,就是java里面优先队列api的概念
概念
队列是一种先进先出(FIFO)的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列
数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)
PriorityQueue的特性
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的,这里主要是介绍的是PriorityQueue.
PriorityQueue的构造方法解释
第一种
构造方法没有比较器,直接传入参数.

第二种

指定初始化容量
第三种
这一种就是指定比较器,也是我们实现最大堆的关键因素.

看了上面的构造方法,我们,我们发现这个优先队列是可以指定比较器的,这样我们就可以实现堆的大小,可以定义大根堆,还可以定义小根堆.
具体先来看看,为什么一开始,我们说优先队列构建的是小根堆.
看代码构建.
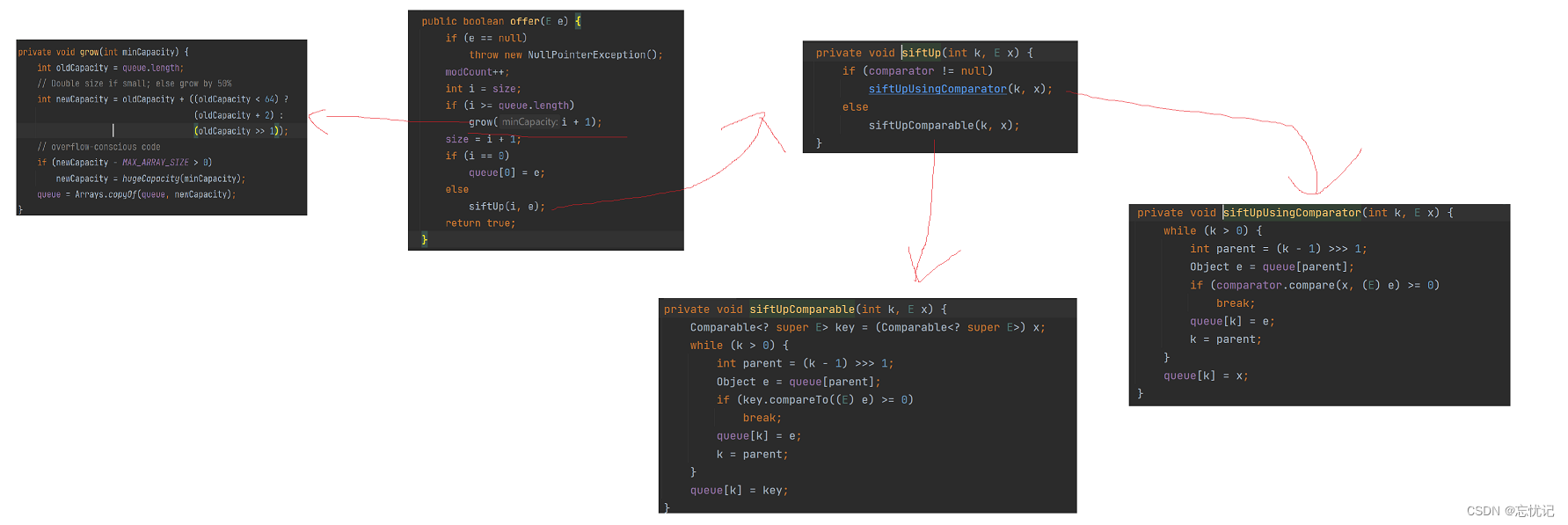
接下来我会一一解释这些方法,你尽量代入我们上面实现的思想,你就能一下子明白了.
grow方法的解释

siftUpComparable和siftUpUsingComparator

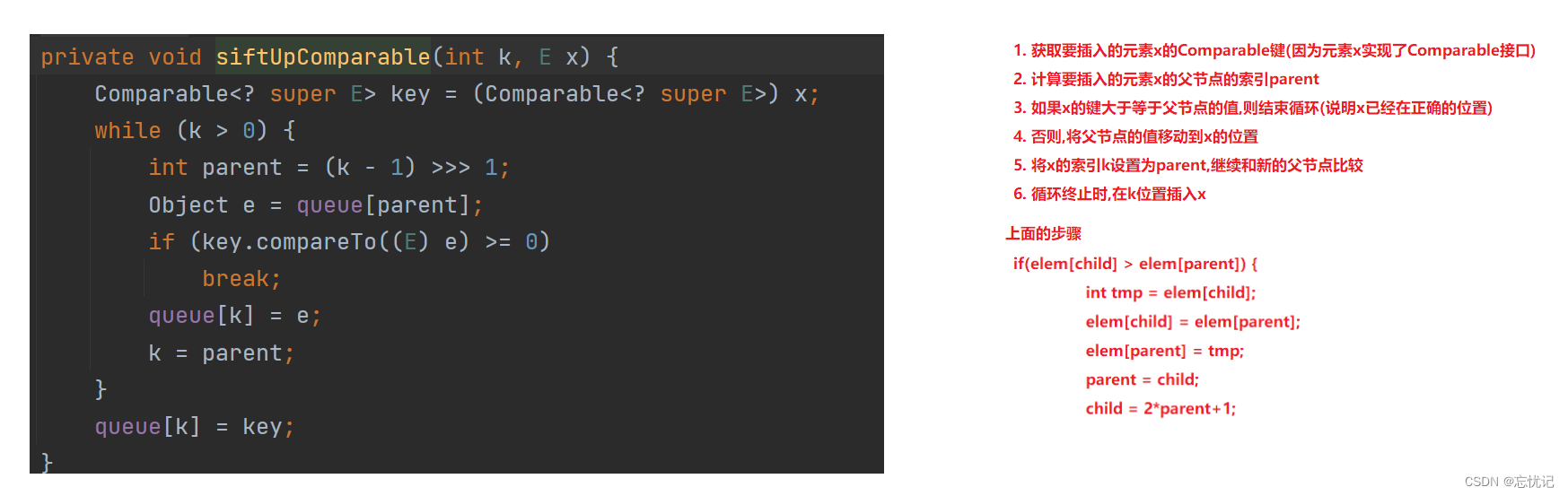
整个offer的逻辑:
- 检查要插入的元素e是否为null,如果是则抛出NullPointerException
- 修改modCount,这个字段主要用于并发修改检测
- 计算优先队列当前大小i,如果超过容量则调用grow方法扩容
- size增加1,表示插入1个新元素
- 如果优先队列是空的(i==0),直接将新元素插入根节点
- 否则调用siftUp方法,将新元素插入尾部,然后执行向上筛选操作,使新元素上浮到正确位置
- 返回true表示插入成功
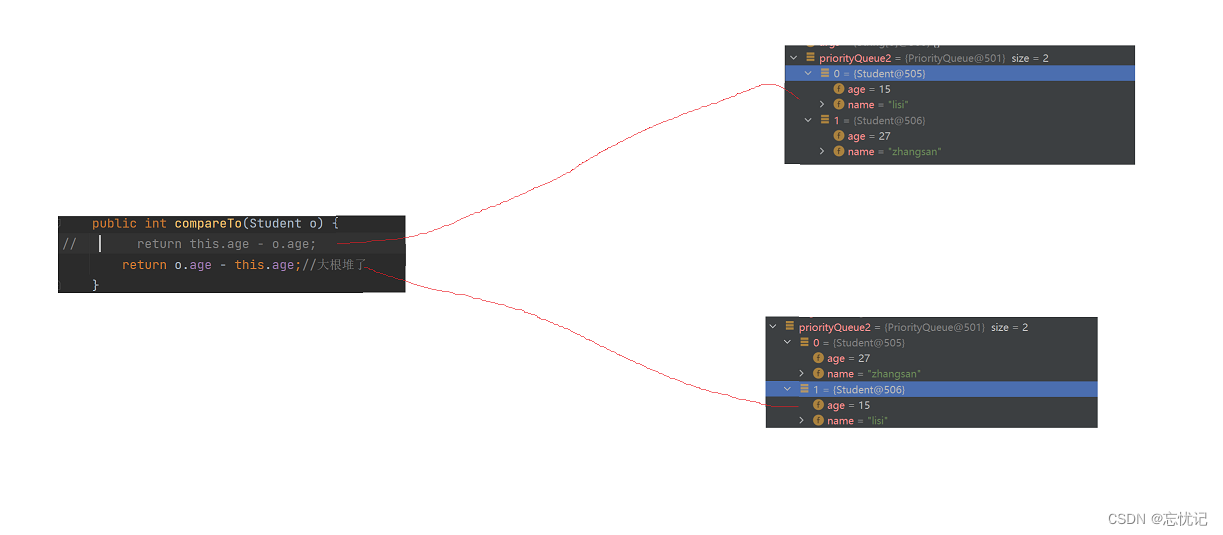
看了上面的例子之后,我们发现在我们没有指定具体的比较器或者说实现compareto接口的时候,他调用自己的比较器,进行比较,所以默认是小根堆,这里我们可以利用比较器的知识,
我用下面的例子来说明一下,怎么构建大根堆,代码如下:
class Student implements Comparable<Student>{ public int age; public String name; public Student(String name,int age) { this.name = name; this.age = age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(age, name); } @Override public int compareTo(Student o) { return this.age - o.age; //return o.age - this.age;//大根堆了 } } public class Test { public static void main(String[] args) { Queue<Student> priorityQueue2 = new PriorityQueue<>(); priorityQueue2.offer(new Student("zhangsan",27)); priorityQueue2.offer(new Student("lisi",15)); System.out.println(2111); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
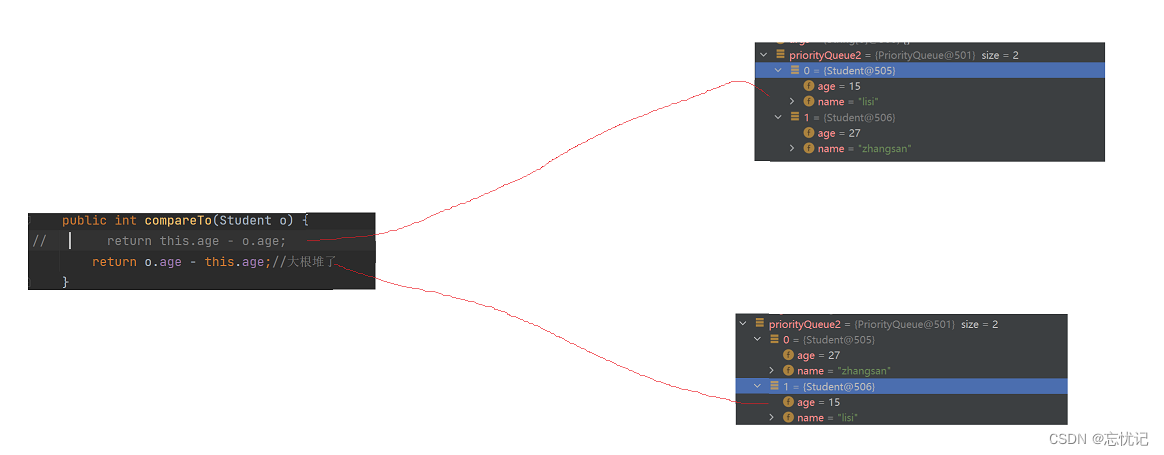
当然我们还有另外一种方式,就是传入比较器
class Student{ public int age; public String name; public Student(String name,int age) { this.name = name; this.age = age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(age, name); } class AgeComparator implements Comparator<Student> { @Override public int compare(Student o1, Student o2) { return o2.age-o1.age; } } } public static void main(String[] args) { AgeComparator ageComparator = new AgeComparator(); Queue<Student> priorityQueue2 = new PriorityQueue<>(ageComparator); priorityQueue2.offer(new Student("zhangsan",27)); priorityQueue2.offer(new Student("lisi",15));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
具体图示如下:
使用的注意事项
1.使用时必须导入PriorityQueue所在的包,即:
2. PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出
ClassCastException异常
3. 不能插入null对象,否则会抛出NullPointerException
4. 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
5. 插入和删除元素的时间复杂度为
6. PriorityQueue底层使用了堆数据结构
7. PriorityQueue默认情况下是小堆—即每次获取到的元素都是最小的元素
top-k问题:最小的K个数或者最大k个数
我这里以最大的k个元素为例子
第一种思路:
通过维持一个大小为N的最小堆,并从中弹出K个元素,从而找到数组中最大的K个元素。
代码如下:
public int[] smallestK(int[] arr, int k) { int[] ret = new int[k]; if(arr == null || k == 0) { return ret; } //O(N*logN) Queue<Integer> minHeap = new PriorityQueue<>(arr.length); for (int x: arr) { minHeap.offer(x); } //K * LOGN for (int i = 0; i < k; i++) { ret[i] = minHeap.poll(); } return ret; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
第二种思路:
- 用数据集合中前K个元素来建堆 前k个最大的元素,则建小堆 ,前k个最小的元素,则建大堆
- 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素\
具体过程

代码如下:
/** * 前K个最大的元素 * N*logK */ public static int[] maxK(int[] arr, int k) { int[] ret = new int[k]; if(arr == null || k == 0) { return ret; } Queue<Integer> minHeap = new PriorityQueue<>(k); //1、遍历数组的前K个 放到堆当中 K * logK for (int i = 0; i < k; i++) { minHeap.offer(arr[i]); } //2、遍历剩下的K-1个,每次和堆顶元素进行比较 // 堆顶元素 小的时候,就出堆。 (N-K) * Logk for (int i = k; i < arr.length; i++) { int val = minHeap.peek(); if(val < arr[i]) { minHeap.poll(); minHeap.offer(arr[i]); } } for (int i = 0; i < k; i++) { ret[i] = minHeap.poll(); } return ret; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
堆排序
具体步骤
分为两步:
- 建堆
升序:建大堆
降序:建小堆 - 利用堆删除思想来进行排序
private void swap(int[] array,int i,int j) { int tmp = array[i]; array[i] = array[j]; array[j] = tmp; } /** * 时间复杂度:n*logn * 空间复杂度:O(1) */ public void heapSort() { int end = usedSize-1;//9 while (end > 0) { swap(elem,0,end); shiftDown(0,end); end--; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 首先调用shiftDown方法构建一个最大堆或最小堆。这个步骤时间复杂度为O(n)。
- 初始化end为最后一个元素的索引。
- 然后从end到0进行循环,在每次循环中:
- 交换堆顶元素(索引0)和end位置的元素
- 调用shiftDown方法对索引0的位置进行堆化(向下调整),使得索引0的位置上有最大值或最小值
- end减1,用于下一轮循环
- 循环结束后,排序完成。

