
- 1大数据与财会行业未来机遇与挑战下的领域——大数据资产的估值_与会计专业有关的数据图片
- 2【全开源】JAVA同城搬家系统源码小程序APP源码
- 3mysql 锁表确认及解除锁表_mysql锁表如何解锁
- 4CDH | Spark升级_cdh spark2和3 区别 cdh spark升级
- 5AI编程篇-python基础篇_python ai编程
- 6java学习资源分享_javaweb学习资源百度云
- 7清华大学范玉顺互联网与大数据_清华大学范玉顺:大数据、人工智能与工业互联网...
- 8vue router 参数_让构建单页面应用变得易如反掌 Vue3中的router
- 9安卓程序的开机动画详解(Animation 一)_app的开机动画
- 10Vue2+Echarts+koa2+websocket电商平台数据可视化实时检测系统(一)_vue 调佣echarts 和 websocket 时需要分开写js文件吗
什么是数据中台
赞
踩
一、数据中台的前世今生
在正式进入数据中台建设实践之前,我想花点时间先聊一聊大数据的发展史,这样更能理解数据中台诞生的原因。不管是学习一项知识,还是讨论一个问题,最好的方法都不应该是一头扎进细节里,而是应该先从时空的维度了解其来龙去脉,当你了解了一件事物的前因后果后,更能透过现象,洞察背后的本质。理解了大数据的发展历史,更能体会数据中台诞生的必然性和数据中台建设方法论。
1.1、数据仓库诞生
1996年,美国加特纳集团第一次提出商业智能的概念,它是指通过一系列的技术和方法,将企业已有的数据转化为有用的信息,帮助企业制定经营分析决策。比如,对于零售企业的库存管理,如何保证不大面积断货影响产品销量的同时,避免库存大量积压导致的成本增加,我们要分析每个商品的销售量趋势、库存情况和未来销量预测,制定合理的采购计划,对滞销商品采取降价促销,对畅销品、爆品要提前下生产订单,供应链部门根据商品订单,提前采购、生产。这些需求的实现,依赖于聚合多个业务系统数据进行分析,如供应链系统、仓储系统等。同时也要保存历史数据,支持销量预测。然而,传统数据库是面向单一业务系统,主要实现面向事务的增删改查,不能满足复杂的数据分析场景,此时,数据仓库的概念应运而生了。
数据仓库之父比尔·恩门在 1991 年出版的《Building the Data Warehouse》中首次给出了数据仓库的完整定义:数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的、不可修改的数据集合。举个例子让大家更好的理解,比如在电商场景中,订单数据、会员数据、库存数据存放在三个不同的数据仓库中,构建数据仓库,首先要把不同业务系统的数据同步到一个统一的数据仓库中,然后按照划分主题域的方式组织数据。
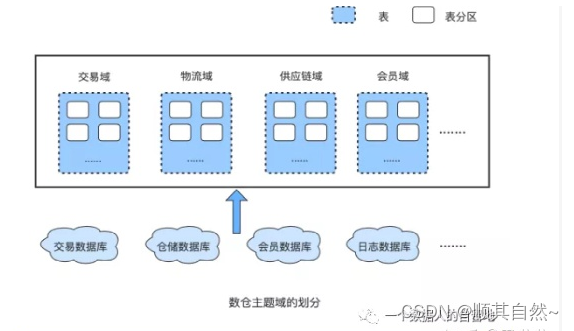
主题域是对业务过程的高度抽象,像商品、交易、用户、供应链都能作为一个主题域,可以把它理解为数据仓库的一个目录。数据仓库中的数据一般是按照时间进行分区存放,一般会保留 5 年以上,每个时间分区内的数据都是追加写的方式,对于某条记录是不可更新的。
数据仓库的出现,明确了复杂场景的数据分析解决方案,让数据分析场景不再依赖业务数据库,也为商业智能的发展奠定了技术基础。
1.2、Hadoop出现
进入互联网时代后,有两个比较明显的变化,一个是数据规模的增长前所未有,一个是数据异构化普遍存在。传统数据库难于扩展、数据在导入前必须事先定义好模型的特性,决定了传统数据仓库根本无法承载互联网时代海量数据存储和计算。
2004年前后,当大多数公司还在研究如何扩展单机性能,寻找更贵更好的服务器时,互联网巨头谷歌发表的 3 篇论文让业界为之一振,也就是我们经常听到的“三驾马车”,分别是分布式文件系统 GFS、大数据分布式计算框架 MapReduce 和 NoSQL 数据库系统 BigTable。论文思路是部署一个大规模的服务器集群,通过分布式的方式将海量数据存储在这个集群上,然后利用集群上的所有机器进行数据计算。这样一来,Google 其实不需要买很多很贵的服务器,它只要把这些普通的机器组织到一起,就能实现大量的数据的存储和计算。
当时的天才程序员Doug Cutting 受Google 的论文影响,开始基于论文原理实现GFS和MapReduce的功能,两年后,Google的理论被变成现实,Hadoop正式诞生。和传统数仓相比,Hadoop有以下两点优势:
1)完全分布式,易于扩展,可以使用价格低廉的机器堆出一个计算、存储能力很强的集群,满足海量数据的处理要求;
2)弱化数据格式,数据被集成到 Hadoop 之后,可以不保留任何数据格式,数据模型与数据存储分离,数据在被使用的时候,可以按照不同的模型读取,满足异构数据灵活分析的需求。
1.3、大数据平台兴起
一个商用Hadoop支持几十种计算引擎,数据研发流程复杂,通常涉及数据集成、数据开发、数据测试、数据发布、任务运维等。繁杂的工作流程使得数据研发的门槛高、效率低下。为解决数据研发低效率、高门槛的问题,大数据平台应运而生,自此,数据实现了“流水线”式的快速加工。
这里简单介绍下大数据平台。
大数据平台是面向数据研发场景的数据研发全链路的工作平台。可以实现数据流水线化快速加工。

大数据平台由下至上大致可分为三部分,分别是数据采集、数据处理、数据展示。
1)数据采集
由于数据源不同,所以数据同步系统相当于多个组件的集合,业务数据库同步一般用Sqoop,日志同步可以选Flume,埋点数据经过格式转换后通过kafka消息队列进行传输。
2)数据处理
数据处理是大数据计算的核心,数据同步系统导入的数据会存储到HDFS,Hive、Mapreduce、Spark等计算任务读取HDFS的数据计算后再将计算结果写入HDFS。
3)数据展示
大数据计算产生的结果被写入了HDFS,但应用程序不能直接到HDFS中读取数据,所以需要数据同步系统将计算结果导出到数据库,应用程序就可以直接访问数据库中的数据,展示给用户。
那各种数据什么时候开始同步,各种计算引擎任务如何合理调度才能使资源利用最合理、等待的时间又不至于太久,同时临时的重要任务还能够尽快执行,这就需要任务调度管理系统来对上述三个部分进行整合完成,大数据平台上的其他系统一般都有开源的可供选择,但任务调度管理系统一般涉及很多个性化的需求,通常需要自己开发,开源的大数据调度系统有 Oozie,也可以在此基础进行扩展。
1.4、数据中台时代
2016年左右,随着互联网的高速发展,业务场景的不断增加,数据应用的需求越来越多,为快速响应业务的需求,很多企业都不同程度的存在烟囱式的开发模式,这种烟囱式的开发导致企业不同业务线的数据是割裂的,这就造成了数据的重复加工,导致研发效率、数据存储和计算资源的浪费,使大数据的应用成本越来越高,也带来指标口径不一致的问题。产生这些问题的根源在于数据无法共享,为解决这一问题,2016年,阿里率先提出“数据中台”的口号。数据中台的核心是:避免数据的重复加工,通过数据服务化,提高数据的共享能力,赋能数据应用。
总的来说,数据中台具备异构数据统一计算、存储的能力,同时让分散杂乱的数据通过规范化的方式管理起来。数据中台借鉴了传统数仓面向主题域的数据组织方式,基于维度建模理论,构建统一的数据公共层和应用层。数据中台依赖于大数据平台完成数据研发全流程,同时增加了数据治理和数据服务化以及数据资产内容。
二、什么是数据中台
说完了数据中台诞生的历史背景,现在,我们应该对数据中台有了一定的了解,那我们现在给数据中台下个定义。
自2016年,数据中台被提出以来,不同的人对数据中台有不同的理解,就像一千个读者心中有一千个哈姆雷特,因此也有许多不同的定义,以下是我从一些文章、书籍中搜集到的关于数据中台的定义:

我的理解:数据中台是DT时代的大背景下,为实现数据快(快速)、准(准确)、省(低成本)赋能业务发展的目标,将企业的数据统一整合起来,基于Onedata方法论借助大数据平台完成数据的统一加工处理,对外提供数据服务的一套机制。
举个例子:如果把数据比如新时代的水电煤,那数据中台就是煤业公司、水厂,煤如果深埋地下,不被挖掘加工,就没法发挥应有价值。所以,建设好基础,数据价值才能最大化被挖掘。
三、数据中台的价值
1、数据中台是企业数据化建设的基础设施
数据中台解决了企业全域数据汇聚的问题,打通以往的数据孤岛,沉淀数据资产,实现数据之间的价值共通,可基于数据中台满足复杂的数据应用场景。
2、提升数据质量
数据中台基于Onedata方法论构建统一的公共层,保证了源头数据的一致性,且实现数据按照统一口径只加工一次,实现全局指标、标签的统一,大大提高数据质量。
3、节约企业数据应用成本
基于数据中台的元数据管理的数据血缘,可以实现数据投入产出比的评估,及时发现并下线低ROI的数据,也避免数据重复加工。由此降低数据的研发、存储和计算成本,降低企业数据应用成本。
比如,对于一些超过3个月未使用的报表,可以做下线处理,评估表的ROI,对于低ROI的报表及时下线处理。
4、健全各部门协作机制
利用系统化的解决方案配合一定的管理机制,实现业务人员、数据研发、产品经理、数据分析师等角色的高效协同,提升各角色之间的协作效率。

