
热门标签
当前位置: article > 正文
Spark性能调优-总结分享_sparkthriftserver并发调优
作者:Monodyee | 2024-05-30 23:25:46
赞
踩
sparkthriftserver并发调优
1、Spark调优背景
目前Zeppelin已经上线一段时间,Spark作为底层SQL执行引擎,需要进行整体性能调优,来提高SQL查询效率。本文主要给出调优的结论,因为涉及参数很多,故没有很细粒度调优,但整体调优方向是可以得出的。
环境:服务器600+,spark 2.0.2,Hadoop 2.6.0
2、调优结果
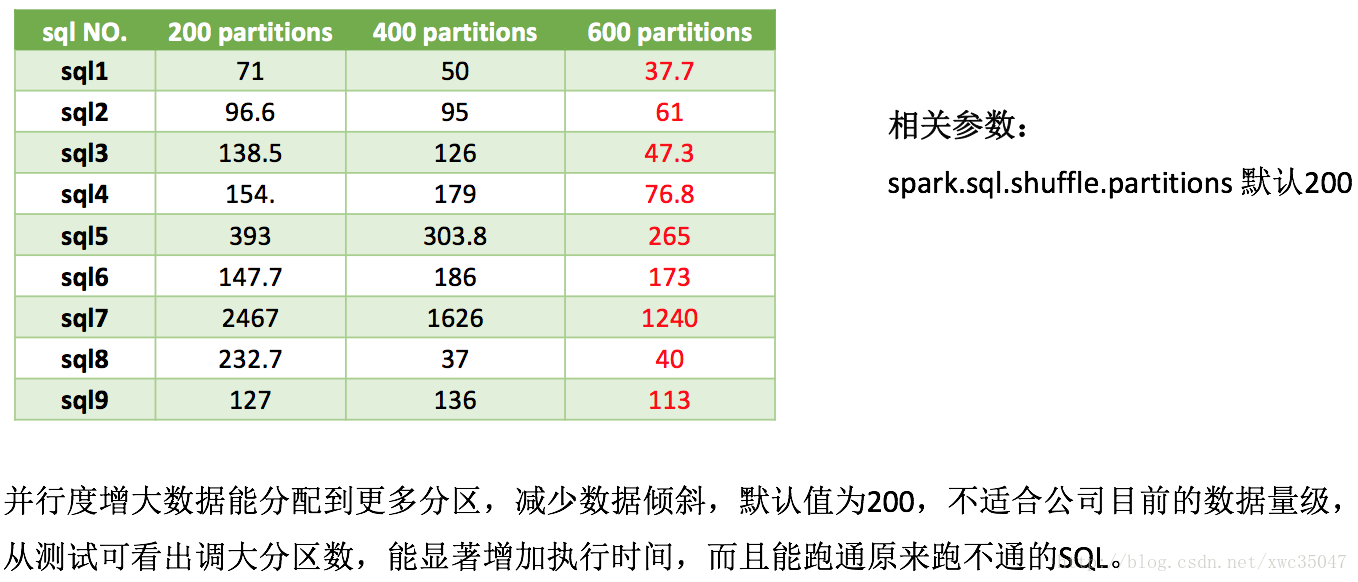
调优随机选取线上9条SQL,表横轴是调优测试项目,测试在集群空闲情况下进行,后一个的测试都是叠加前面测试参数。从数据可参数经过调优,理想环境下性能可提高50%到300%
3、 下面为调优分享PPT
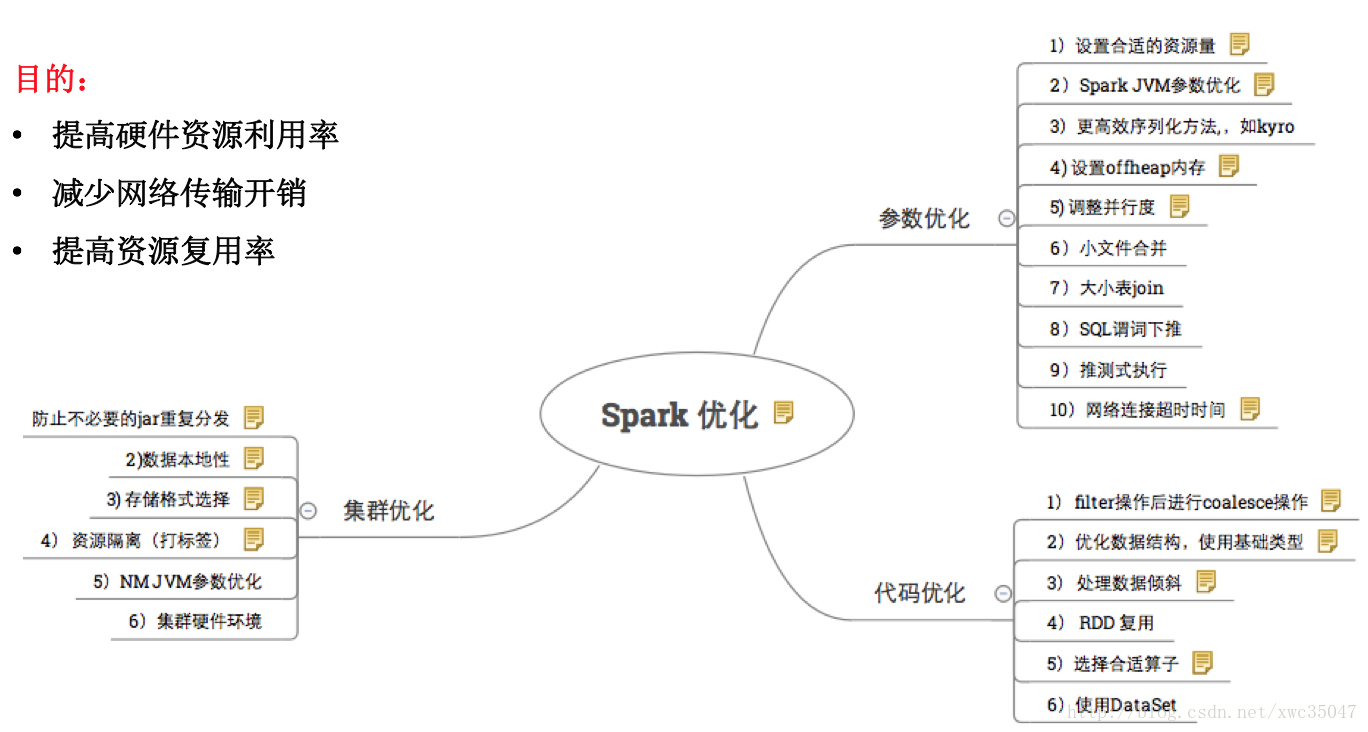
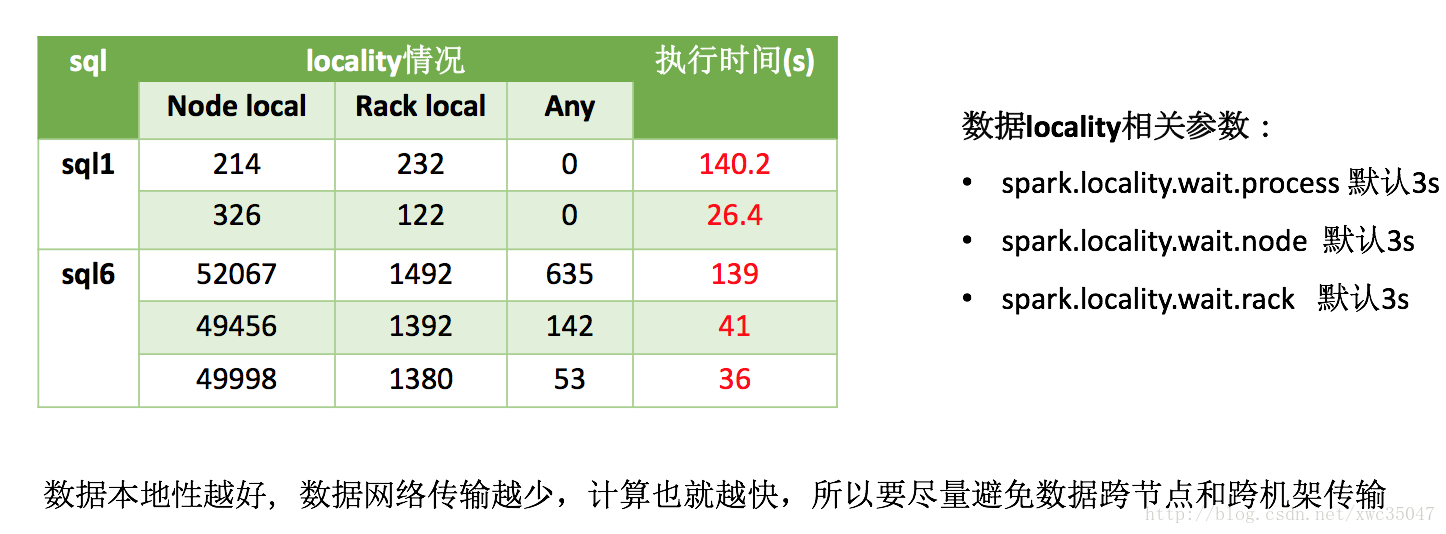
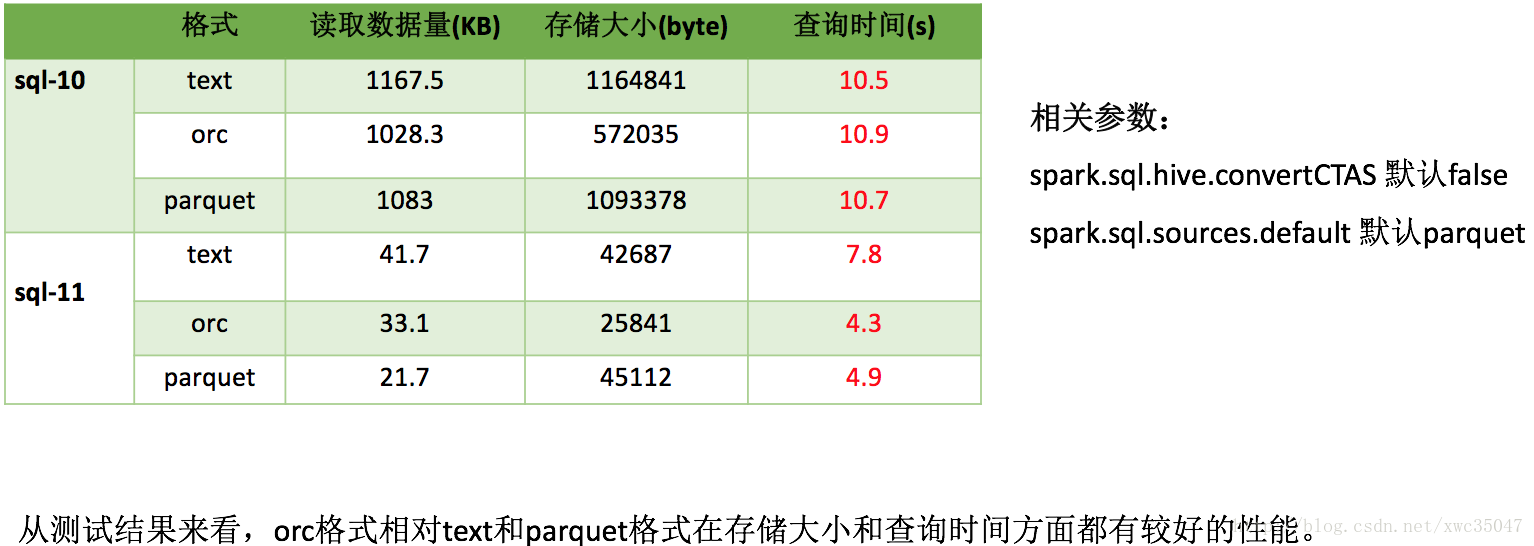
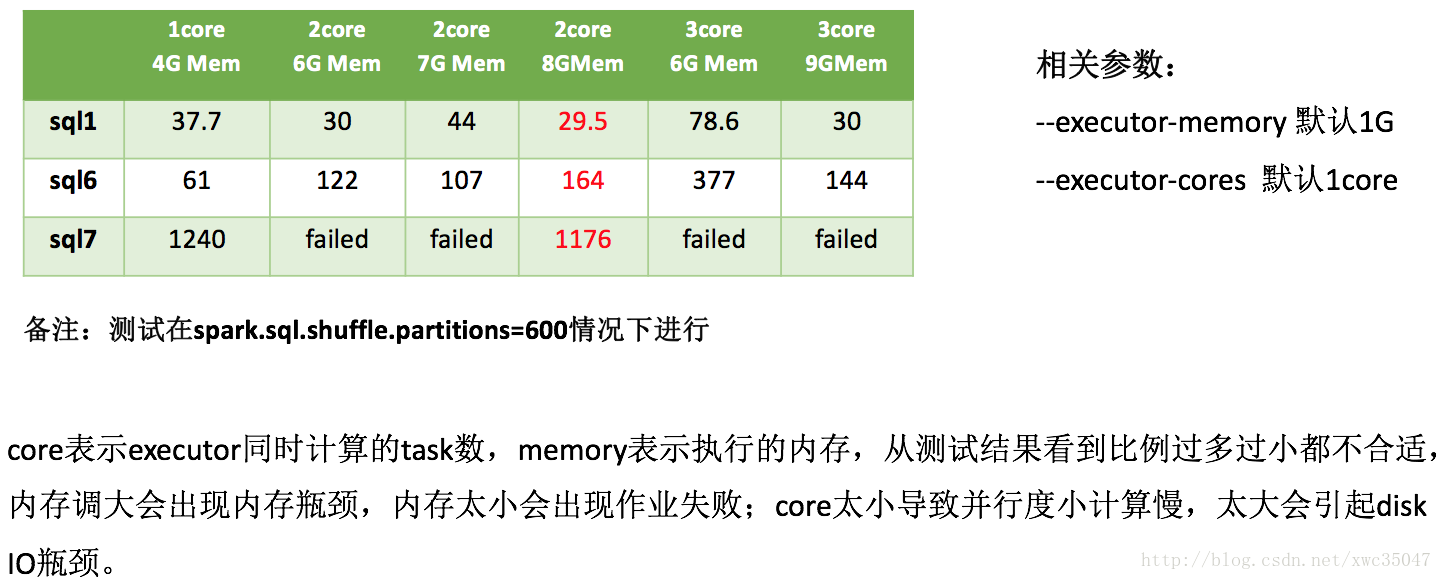



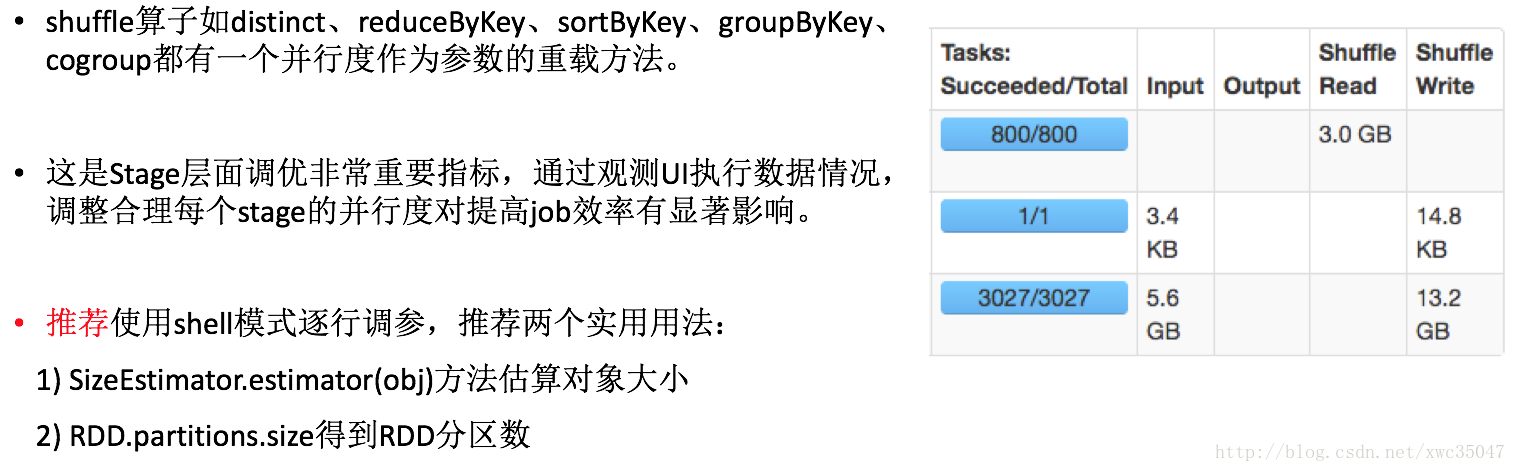


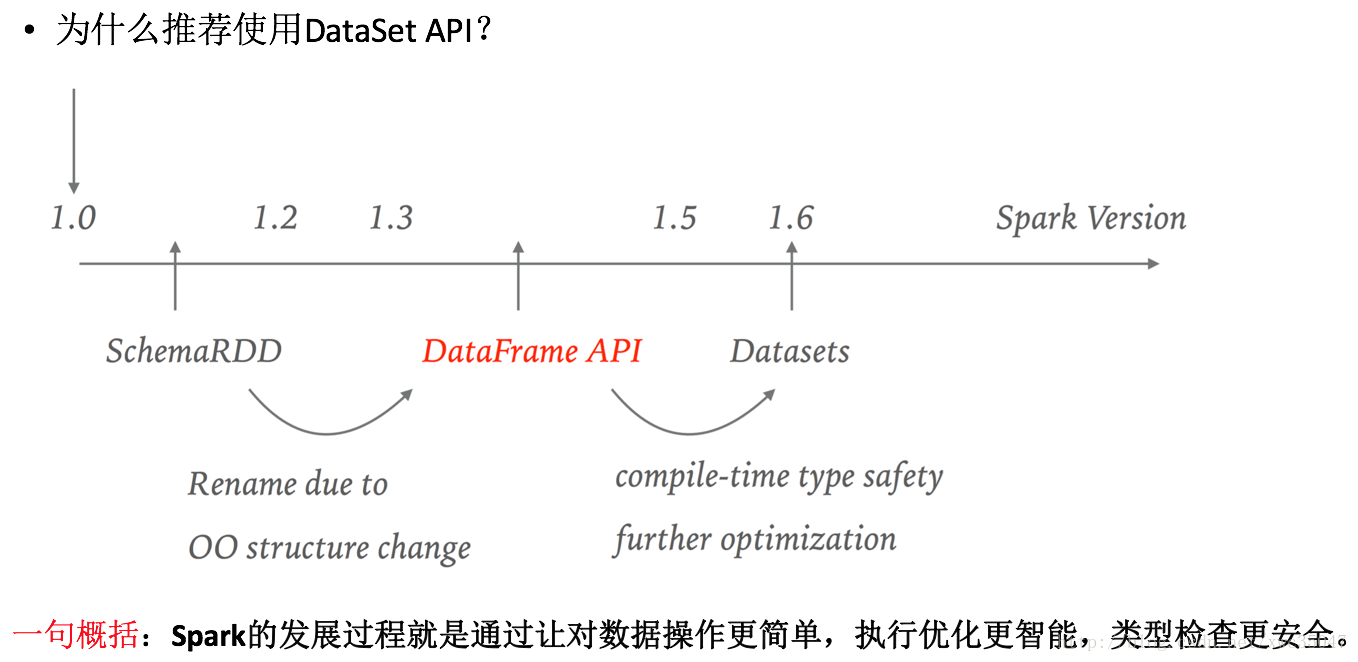
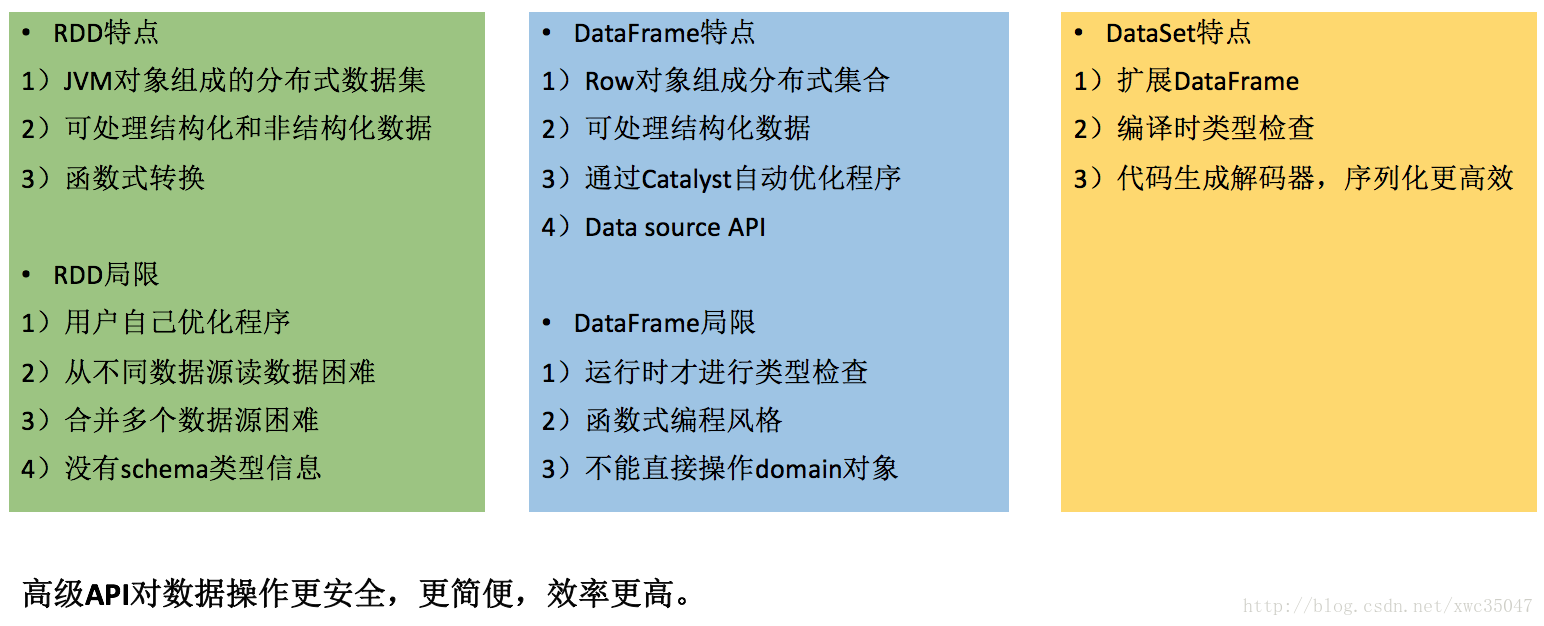


3、总结
调优参数虽名目多样,但最终目的是提高CPU利用率,降低带宽IO,提高缓存命中率,减少数据落盘。
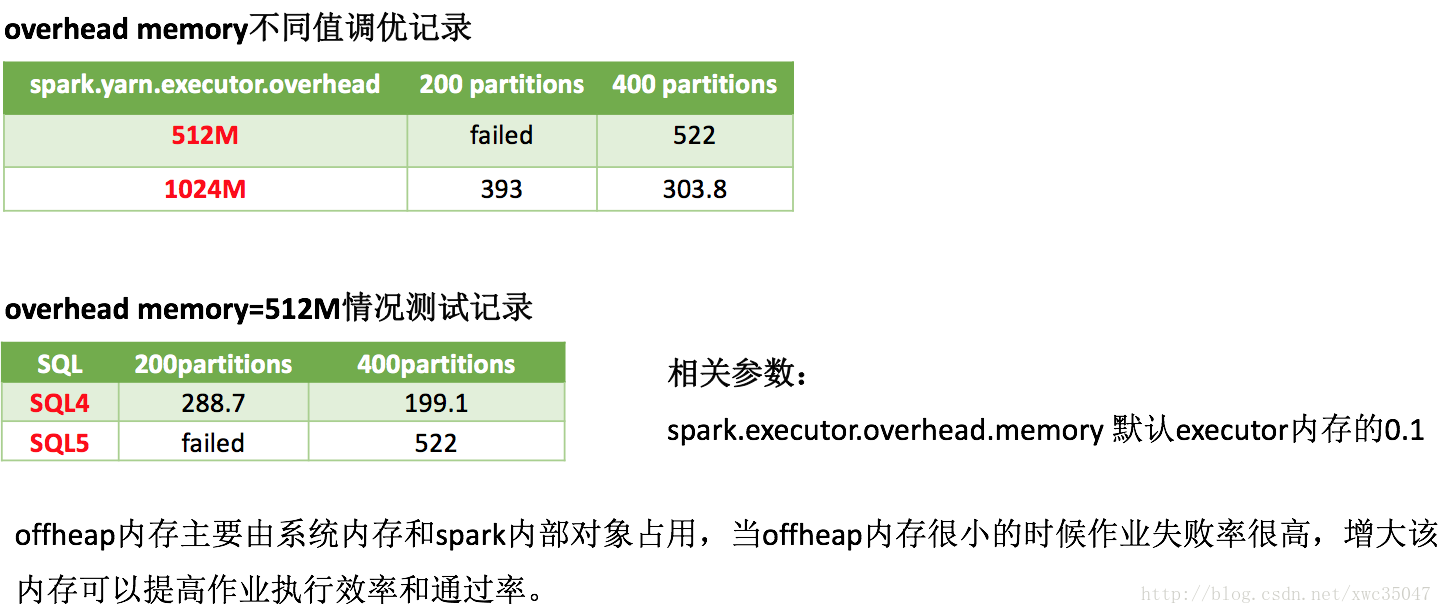
不同数据量的最优参数都不相同,调优目的是让参数适应数据的量级以最大程度利用资源,经调优发现并不是所有参数有效,有的参数的效果也不明显,最后折中推荐如下调优参数以适应绝大多数SQL情况,个别SQL需要用户单独调参优化。(以下参数主要用于Spark Thriftserver,仅供参考)
| 参数 | 含义 | 默认值 | 调优值 |
|---|---|---|---|
| spark.sql.shuffle.partitions | 并发度 | 200 | 800 |
| spark.executor.overhead.memory | executor堆外内存 | 512m | 1.5g |
| spark.executor.memory | executor堆内存 | 1g | 9g |
| spark.executor.cores | executor拥有的core数 | 1 | 3 |
| spark.locality.wait.process | 进程内等待时间 | 3 | 3 |
| spark.locality.wait.node | 节点内等待时间 | 3 | 8 |
| spark.locality.wait.rack | 机架内等待时间 | 3 | 5 |
| spark.rpc.askTimeout | rpc超时时间 | 10 | 1000 |
| spark.sql.autoBroadcastJoinThreshold | 小表需要broadcast的大小阈值 | 10485760 | 33554432 |
| spark.sql.hive.convertCTAS | 创建表是否使用默认格式 | false | true |
| spark.sql.sources.default | 默认数据源格式 | parquet | orc |
| spark.sql.files.openCostInBytes | 小文件合并阈值 | 4194304 | 6291456 |
| spark.sql.orc.filterPushdown | orc格式表是否谓词下推 | false | true |
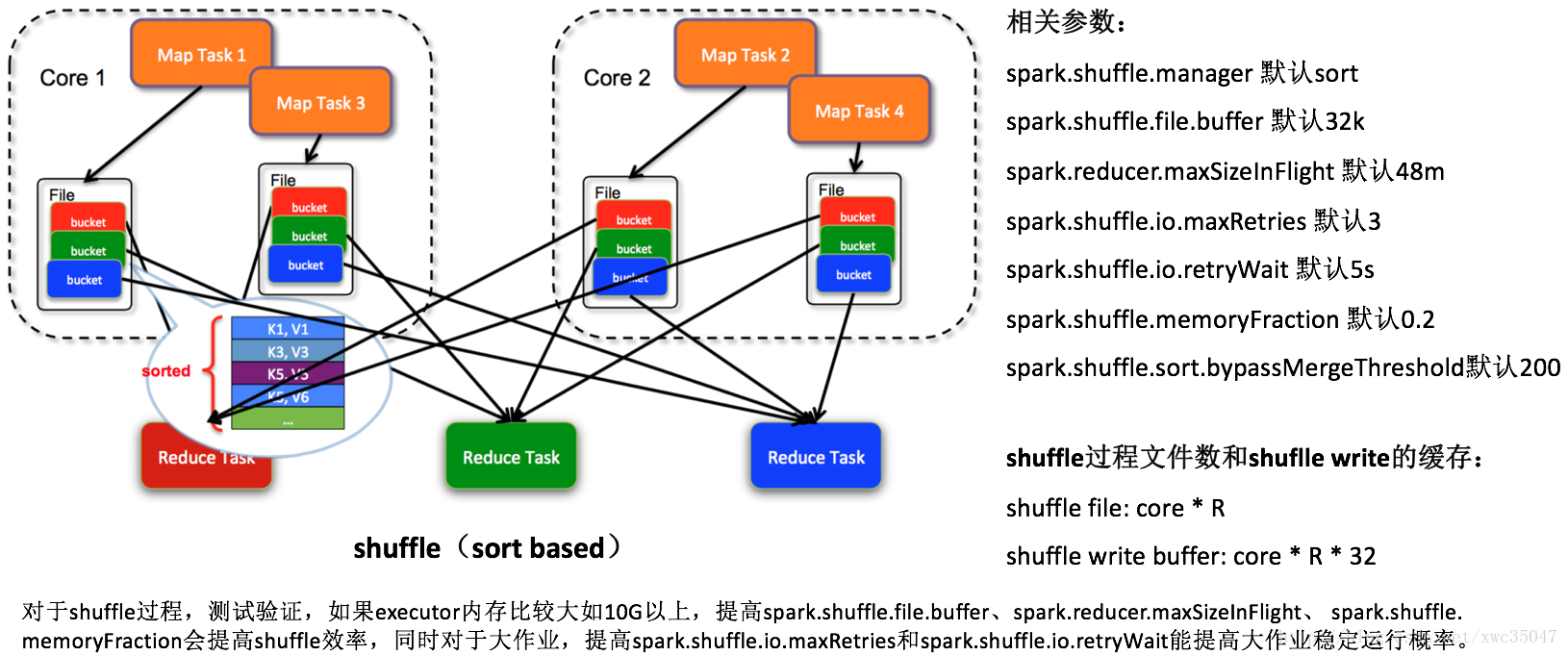
| spark.shuffle.sort.bypassMergeThreshold | shuffle read task阈值,小于该值则shuffle write过程不进行排序 | 200 | 600 |
| spark.shuffle.io.retryWait | 每次重试拉取数据的等待间隔 | 5 | 30 |
| spark.shuffle.io.maxRetries | 拉取数据重试次数 | 3 | 10 |
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/649179
推荐阅读
相关标签

