
- 1踩坑记--Your connection to this site is not secure
- 2RK3568-ANDROID11-4G-EC20-驱动篇(移远模块)_移远4g模块驱动下载
- 3灰狼算法Grey Wolf Optimizer跑23个经典测试函数|含源码
- 4Xilinx 7 Series FPGAs Integrated Block for PCI Express v3.3(持续更新。。。)_7series integrated block pcie
- 5redis 去中心化集群 搭建流程_redis无中心化集群搭建
- 6鸿蒙Harmony应用开发—ArkTS声明式开发(通用属性:颜色渐变)_鸿蒙渐变背景裁剪api
- 7【论文精读】ECCV2020 - 带有圆平滑标签的定向目标检测_circular smooth label
- 8Qt 对话框无边框,背景透明,不在任务栏显示,当点击对话框之外区域对话框关闭_qt点击其他区域关闭dialog
- 9大数据与网络安全哪个的就业前景更好?该如何抉择?_云计算和网络安全哪个有前景
- 10STM32CubeMX配置ADC采样(轮询、中断、DMA)_stm32cubemx adc
爬虫实例二:爬取拉勾网招聘信息_拉勾招聘网爬虫
赞
踩
爬虫实例二:爬取拉勾网招聘信息
如果是第一次看本教程的同学,可以先从一开始:
爬虫实例一:爬取豆瓣影评
欢迎关注微信公众号:极简XksA
微信账号:xksnh888
转载请先联系微信号:zs820553471
交流学习
一、学习开始前需安装模块
pip install requests
pip install pandas
pip install numpy
pip install jieba
pip install re
pip install pyecharts
pip install os- 1
- 2
- 3
- 4
- 5
- 6
- 7
二、讲解概要
为什么要爬取拉勾网?
哈哈哈,当然是因为简单,啪,原因如下:
(1)动态网页,爬起来难度更大,讲起来更有内容;
(2)与一般情况不同,我们所需内容通过get请求获取不了,需进行页面分析。
- 1.爬取拉勾网求职信息
(1)requests 请求,获取单页面
(2)分析页面加载,找到数据
(3)添加headers 信息,模仿浏览器请求
(4)解析页面,实现翻页爬取
(5)爬取数据存入csv文件 - 2.数据分析与可视化
(1)分析数据
(2)pyecharts实现数据可视化
三、正式开始,竖起你的小眼睛
爬取拉勾网求职信息
(1)requests 请求,获取单页面
# 我们最常用的流程:网页上复制url->发送get请求—>打印页面内容->分析抓取数据
# 1.获取拉钩网url
req_url = 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput='
# 2.发送get请求
req_result = requests.get(req_url)
# 3.打印请求结果
print(req_result.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
由上面的流程,打印输出结果如下:
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta name="renderer" content="webkit">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
</head>
<script type="text/javascript" src="https://www.lagou.com/utrack/trackMid.js?version=1.0.0.3&t=1529144464"></script>
<body>
<input type="hidden" id="KEY" value="VAfyhYrvroX6vLr5S9WNrP16ruYI6aYOZIwLSgdqTWc"/>
<script type="text/javascript">HZRxWevI();</script>
é?μé?¢?? è????-...
<script type="text/javascript" src="https://www.lagou.com/upload/oss.js"></script>
</body>
</html>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
看的出来,与我们想象的还是差别很大。
为什么会出现这种情况,很简单,因为它并不是简单的静态页面,我们知道请求方式有get和post请求两种基本区别如下:
(1)Get是向服务器发索取数据的一种请求;而Post是向服务器提交数据的一种请求,要提交的数据位
于信息头后面的实体中。GET和POST只是发送机制不同,并不是一个取一个发.
(2)GET请求时其发送的信息是以url明文发送的,其参数会被保存在浏览器历史或web服务器中,
而post则不会某(这也是后面我们翻页的时候发现拉勾网翻页时 浏览器 url栏地址没有变化的原因。)- 1
- 2
- 3
- 4
(2)分析页面加载,找到数据
1.请求分析
在拉钩网首页,按F12进入开发者模式,然后在查询框中输入python,点击搜索,经过我的查找,终于找到了页面上职位信息所在的页面,的确是一个post请求,而且页面返回内容为一个json格式的字典。2.返回数据内容分析
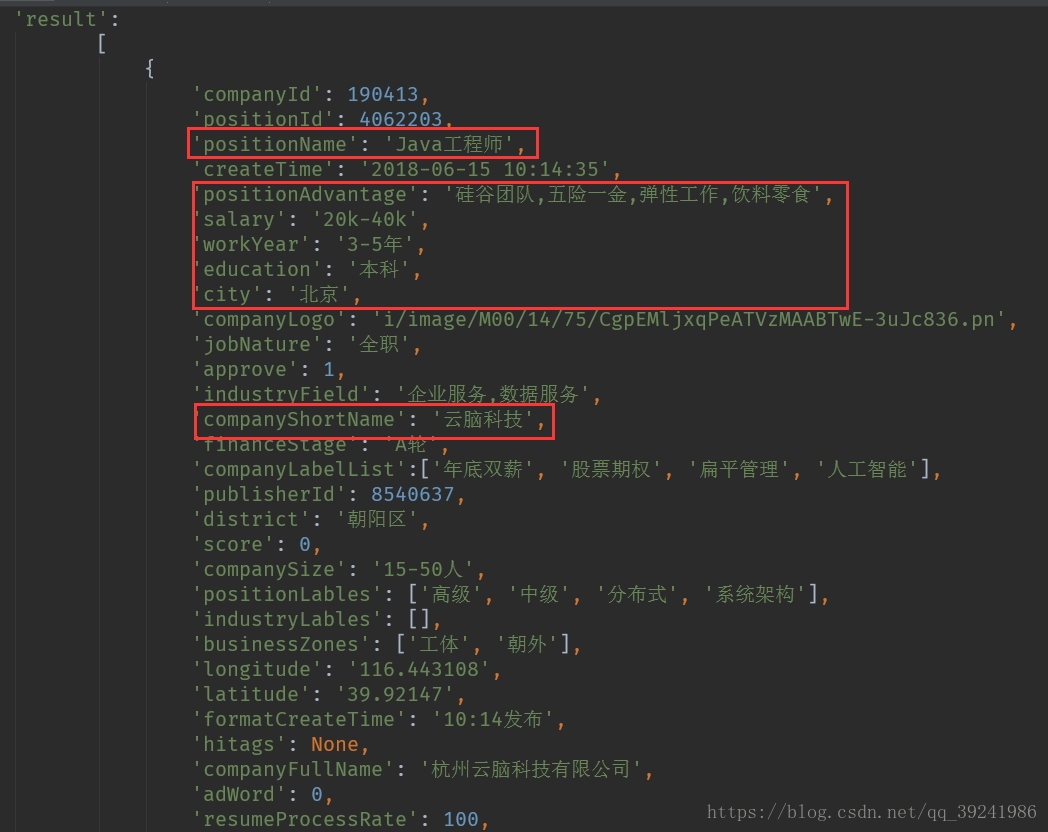
页面上:我们主要获取7个数据(公司 | 城市 | 职位 | 薪资 | 学历要求 | 工作经验 | 职位优点)
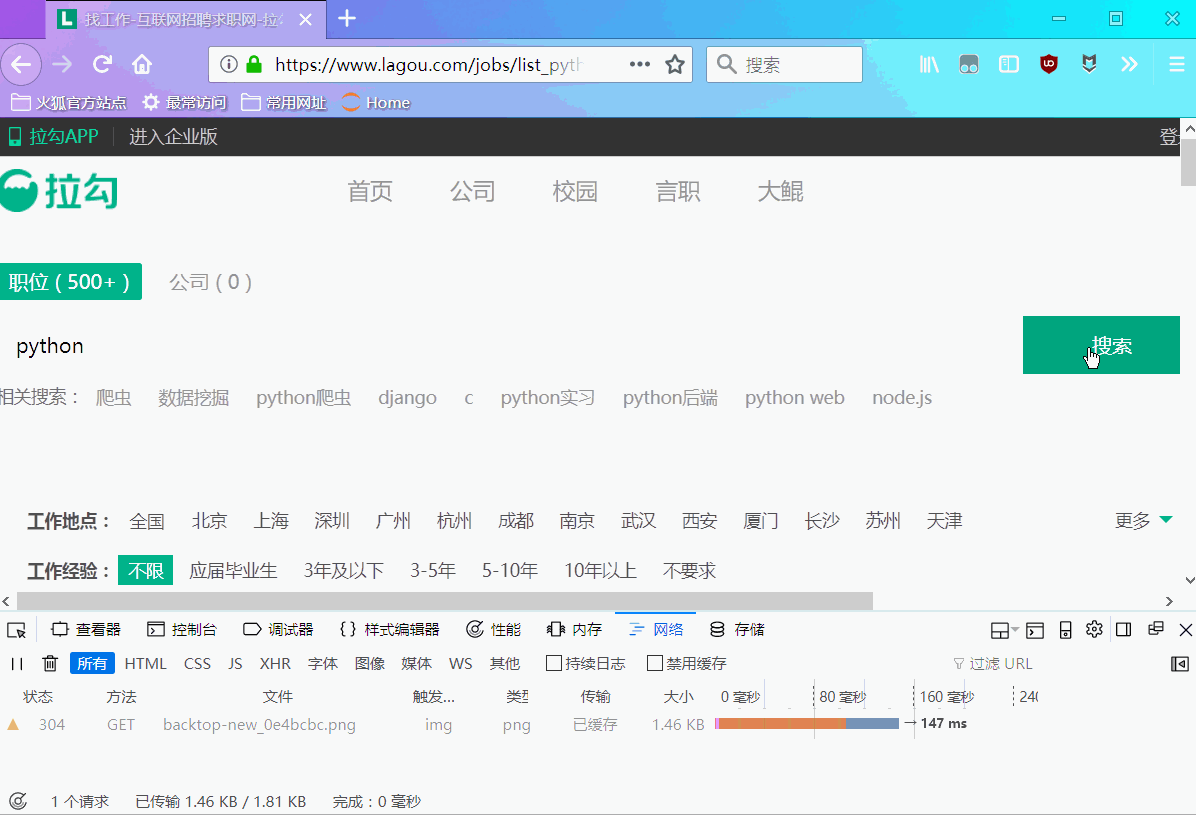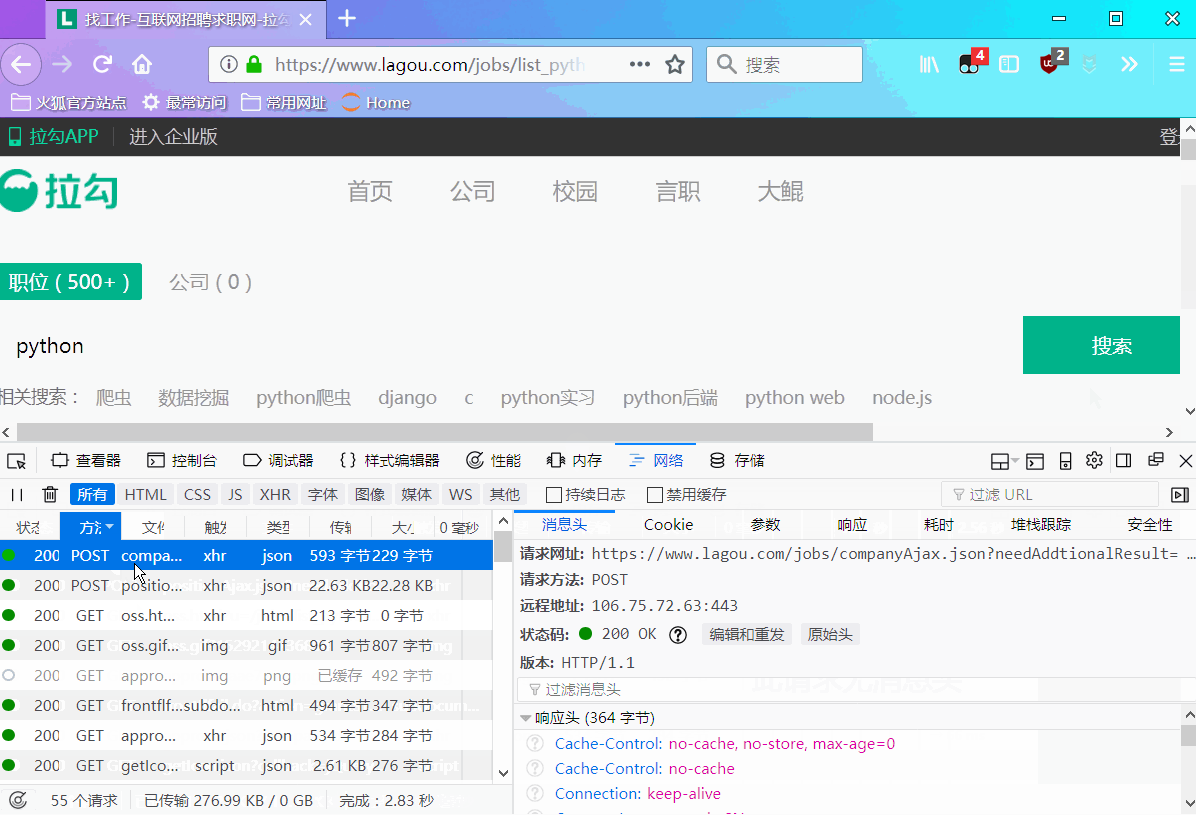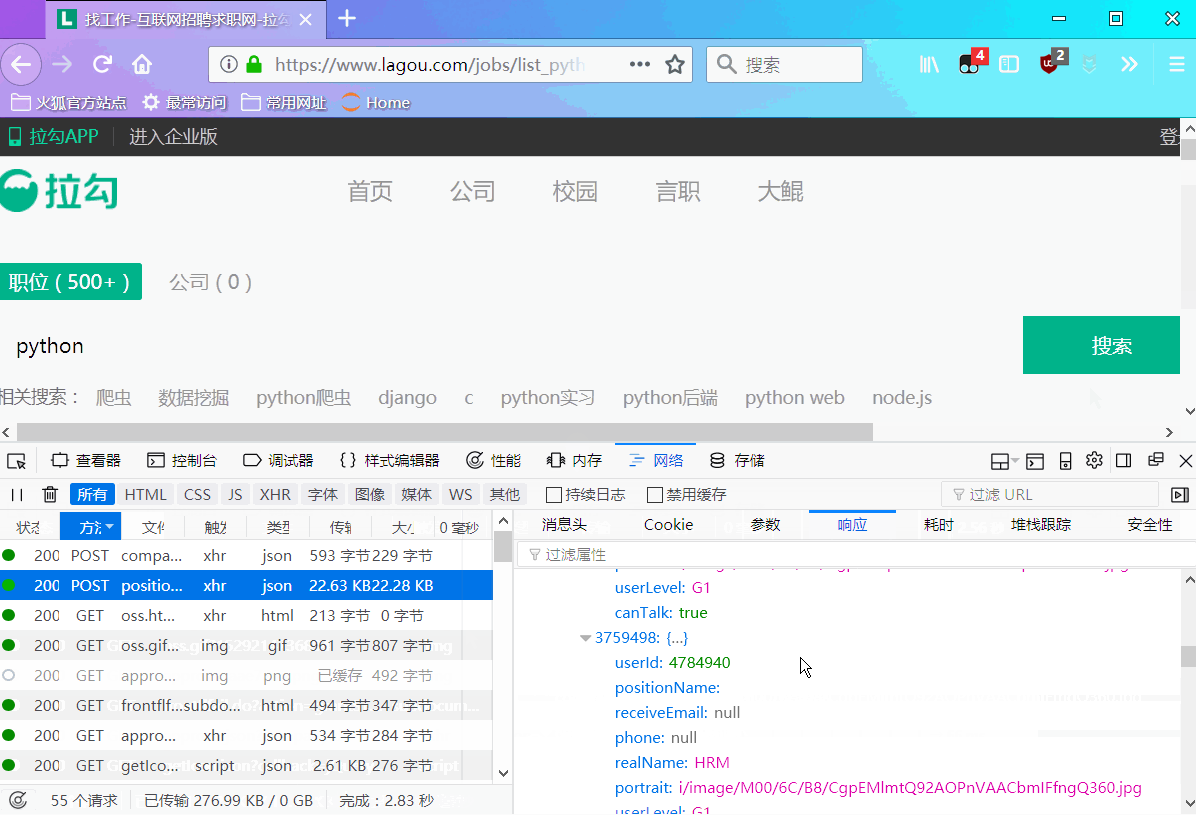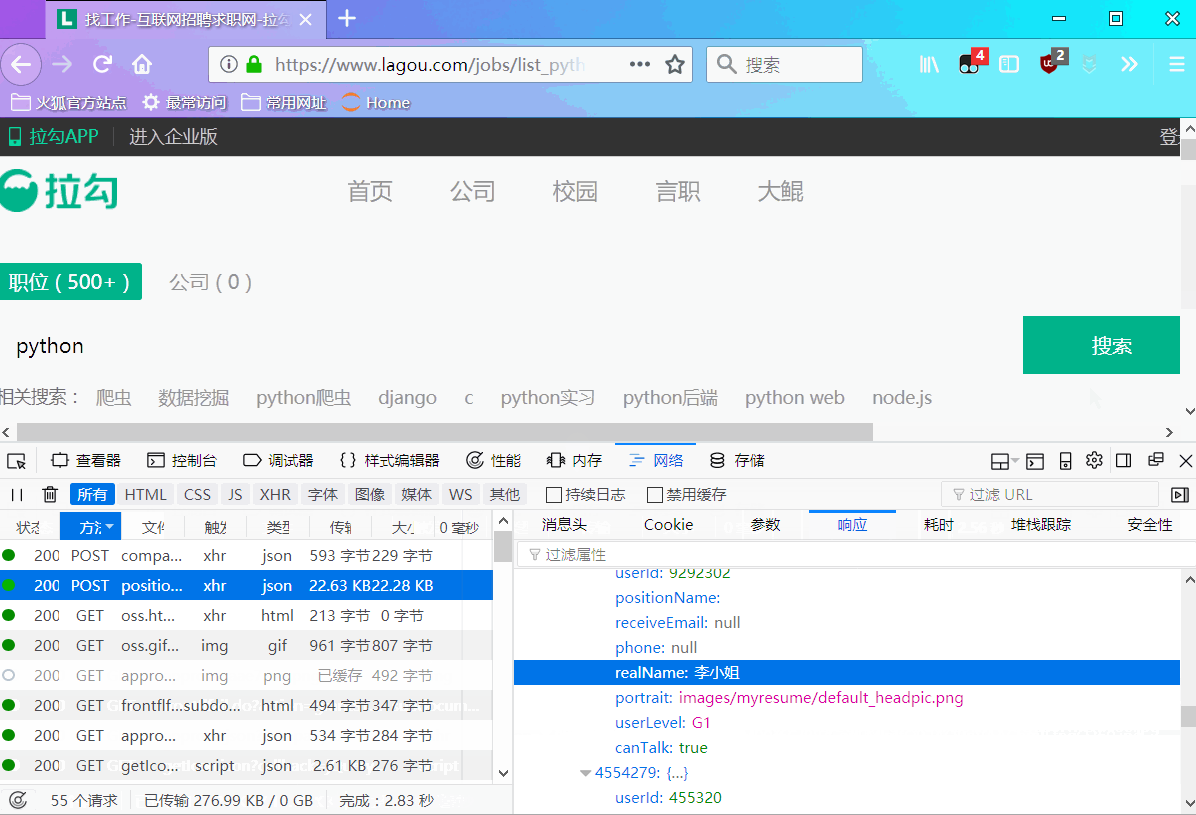

json数据中:我把爬下来的json数据整理了一下,如下图:
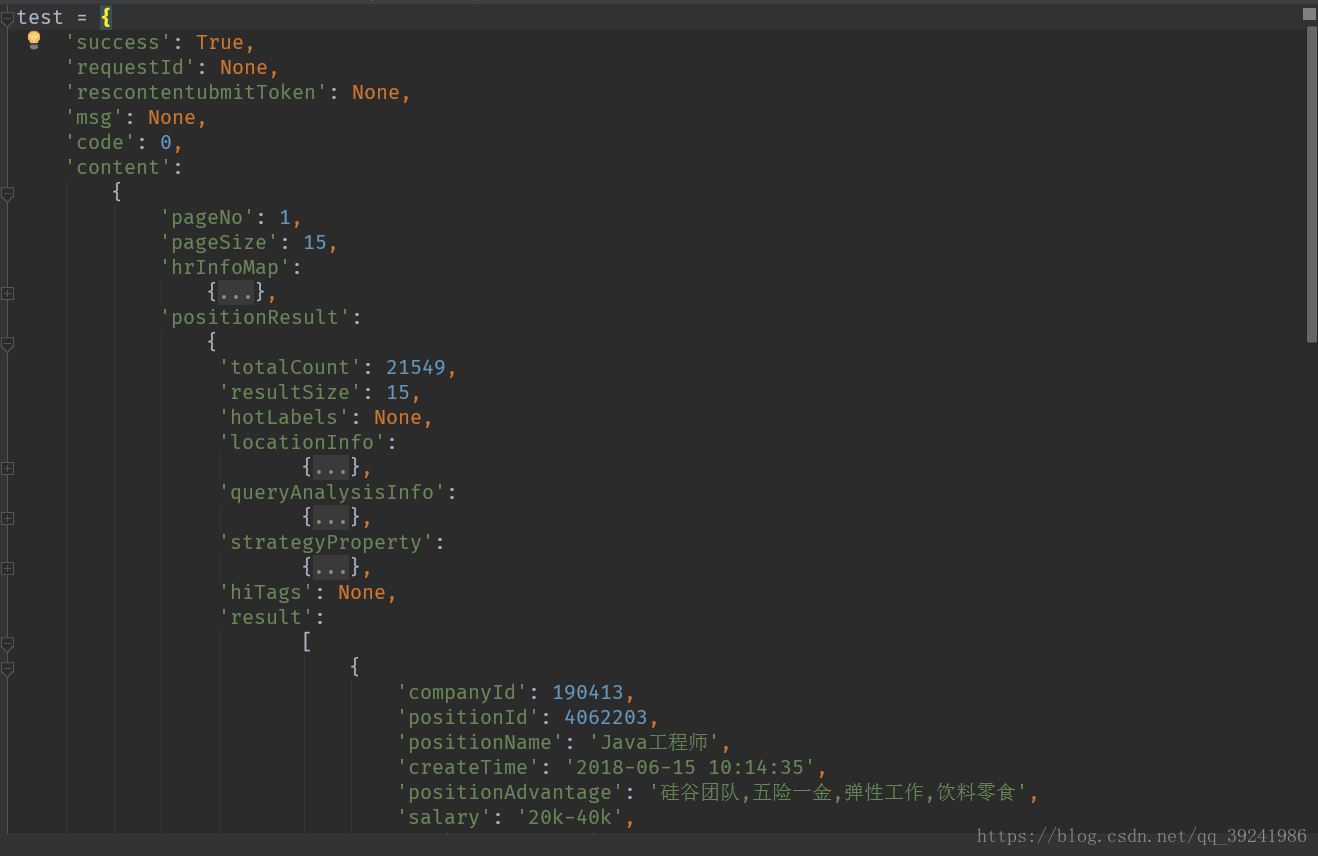
我们会发现,我们需要的数据全在:req_info['content']['positionResult']['result']里面,为一个列表,而且还包含许多其他的信息,本次我们不关心其他数据。我们所需要数据如下图框:
(3)添加headers 信息,模仿浏览器请求
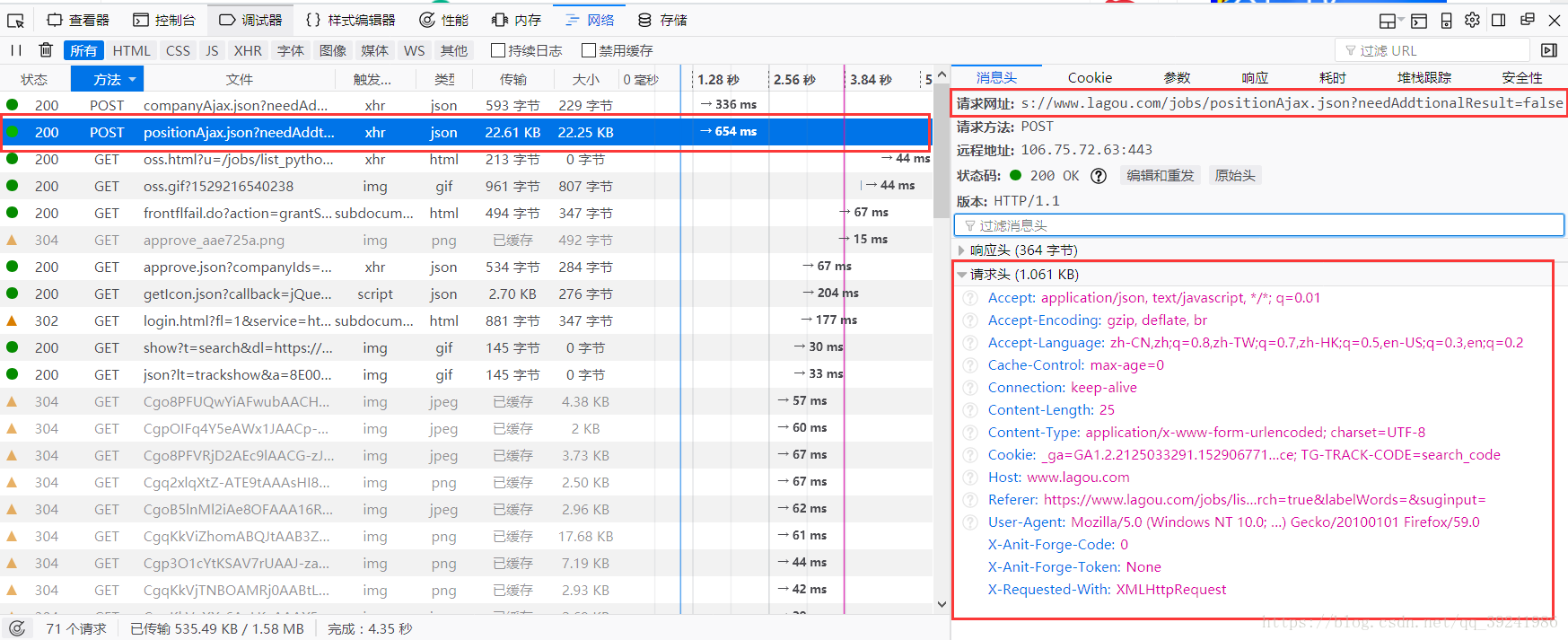
通过上面的请求分析我们可以找到post请求的网址为:https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false,如果此时我们直接发送post请求,会提示如下代码:
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '122.xxx.xxx.xxx'}- 1
出现这种提示的原因是,我们直接post访问url,服务器会把我们误认为‘机器人’,这也是一种反爬,解决方法很简单,加一个请求头即可完全模拟浏览器请求,请求头获取见下图:
(4)解析页面,实现翻页爬取
- 怎么实现翻页呢?
一般,我们实现翻页的方法就是自己手动的在浏览器翻页,然后观察网址的变化,找出规律,可是翻拉钩网的时候我们会发现,在浏览器里翻页的时候,url框内的网址并没有变化。 - 再次页面分析?
还得继续分析页面求,我们必须要相信,肯定是有变化的,不然,页面内容怎么可能自己变化呢?
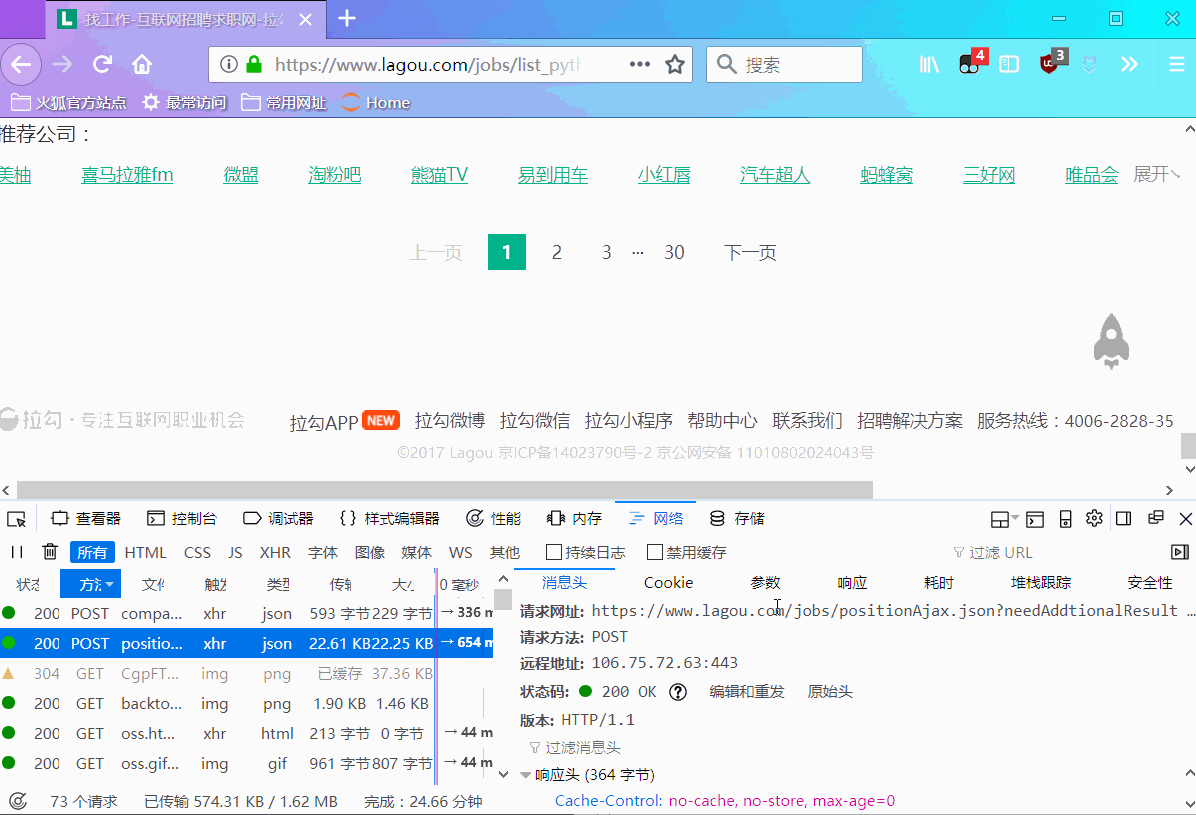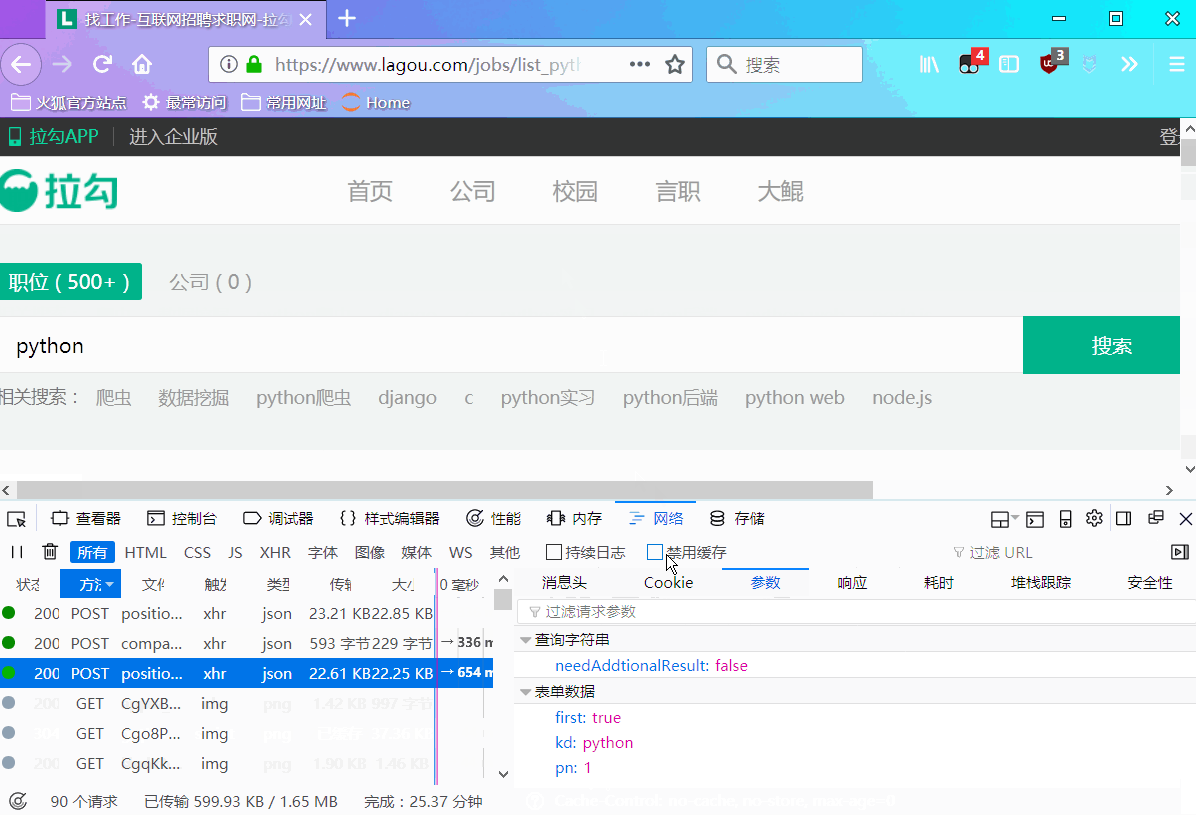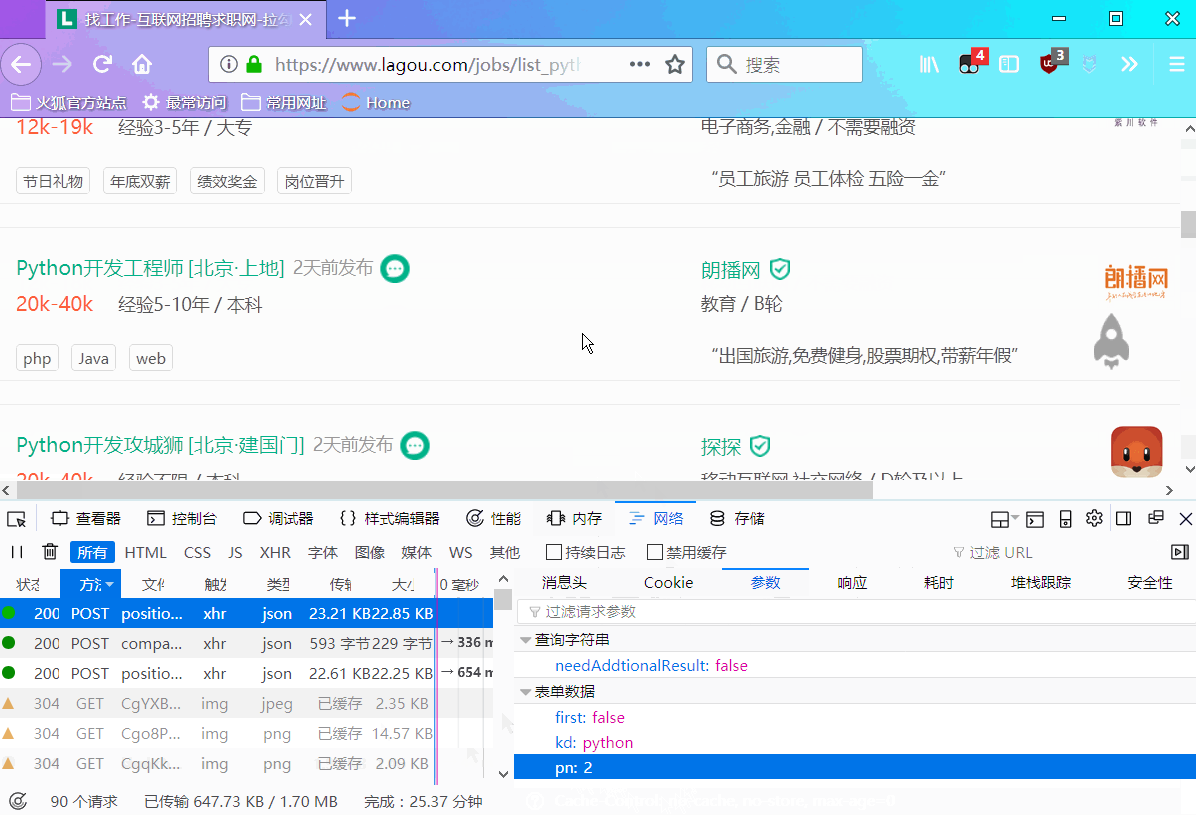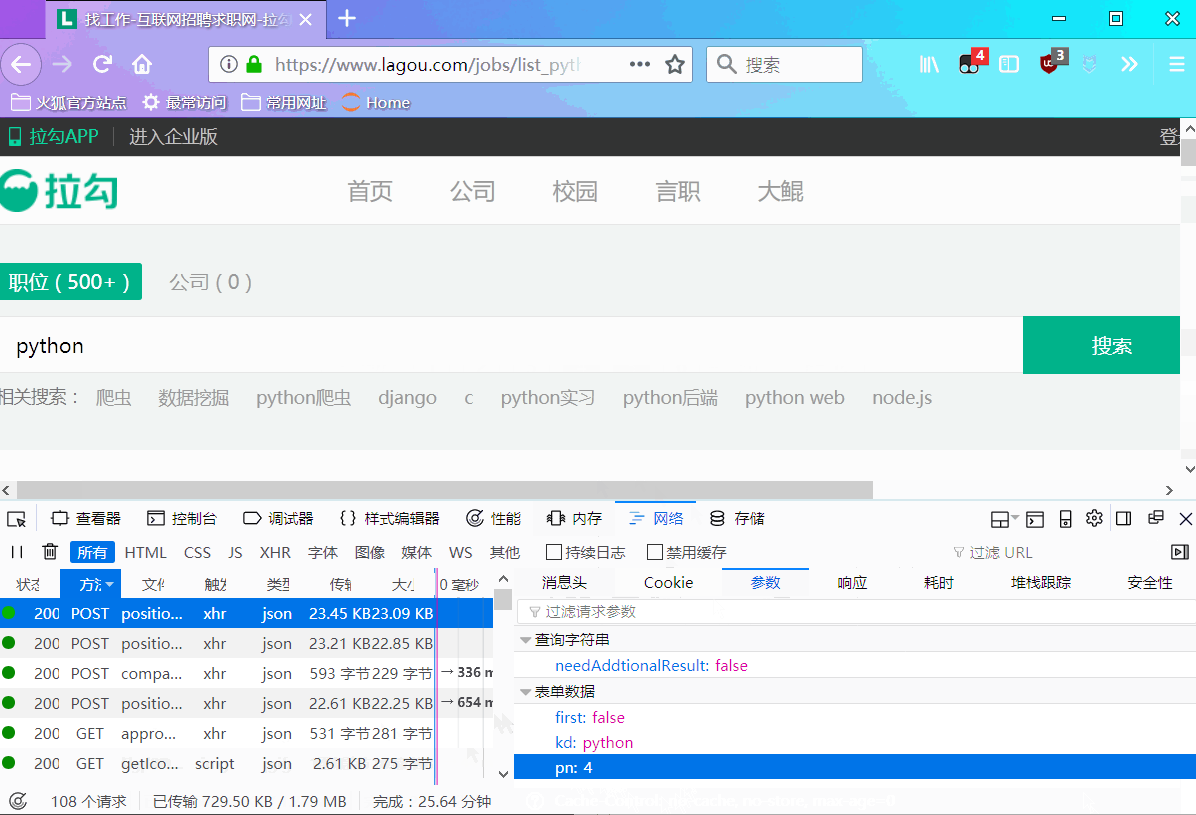
分析发现下面规律:
在post请求中,有个请求参数->表单数据,包含三个参数first、kd、pn,通过动图演示,我们不难猜出其含义:
data = {
'first':'true', # 是不是第一页,false表示不是,true 表示是
'kd':'Python', # 搜索关键字
'pn':1 # 页码
}- 1
- 2
- 3
- 4
- 5
现阶段代码:
import requests
# 1. post 请求的 url
req_url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 2. 请求头 headers
headers = {'你的请求头'}
# 3. for 循环请求
for i in range(1,31):
data = {
'first':'false',
'kd':'Python',
'pn':i
}
# 3.1 requests 发送请求
req_result = requests.post(req_url,headers = headers,data = data)
req_result.encoding = 'utf-8'
# 3.2 获取数据
req_info = req_result.json()
# 打印出获取到的数据
print(req_info)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(5)爬取数据存入csv文件
def file_do(list_info):
# 获取文件大小
file_size = os.path.getsize(r'G:\lagou_test.csv')
if file_size == 0:
# 表头
name = ['公司','城市','职位','薪资','学历要求','工作经验','职位优点']
# 建立DataFrame对象
file_test = pd.DataFrame(columns=name, data=list_info)
# 数据写入
file_test.to_csv(r'G:\lagou_test.csv', encoding='gbk',index=False)
else:
with open(r'G:\lagou_test.csv','a+',newline='') as file_test :
# 追加到文件后面
writer = csv.writer(file_test)
# 写入文件
writer.writerows(list_info)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
简单展示一下爬取到的数据:
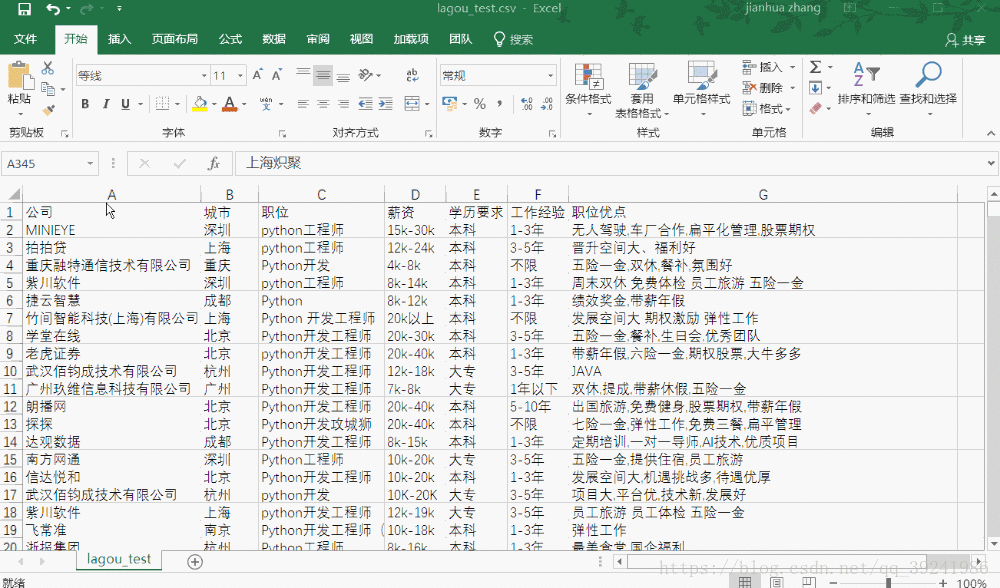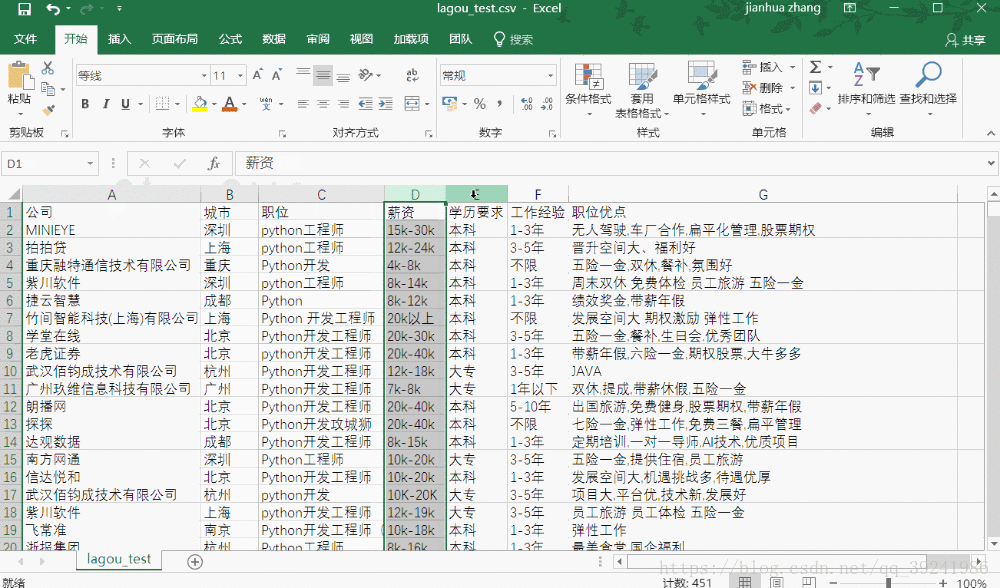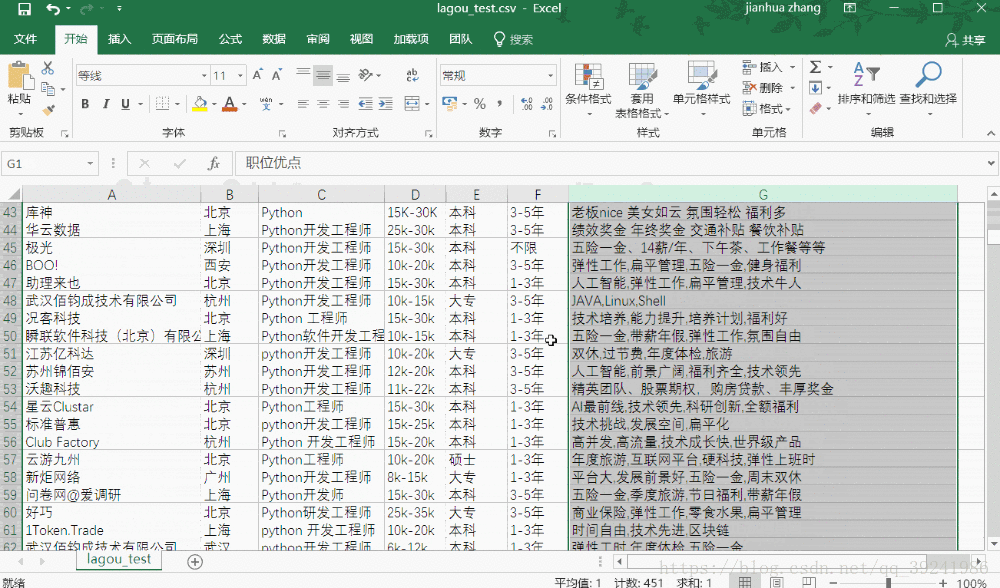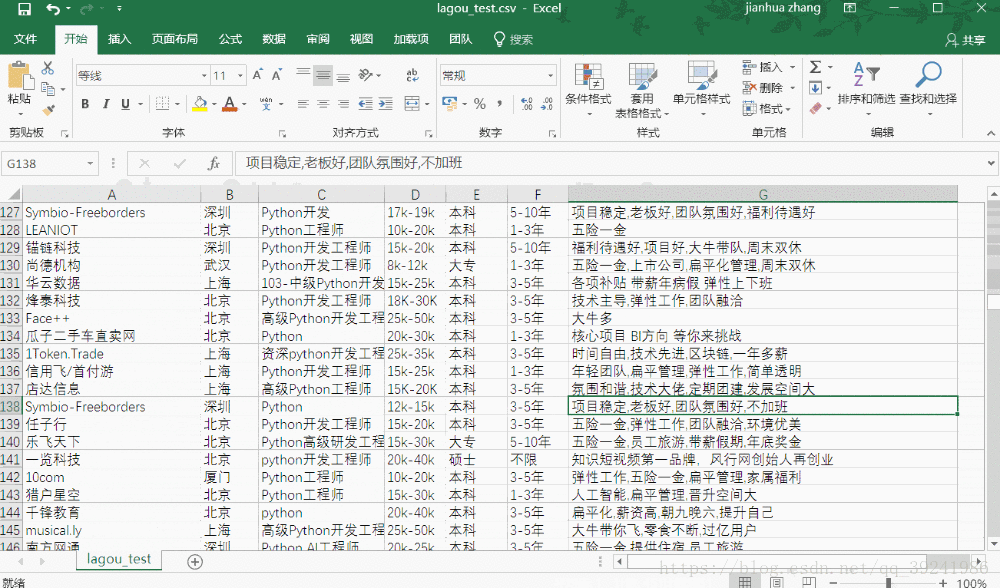
四、来点进阶的(和爬虫无关)
数据分析+pyechart数据可视化
- 1.薪资分布分析
# 薪资分析,下面的几个都是柱状图,和这个地方分析一样
# 统计各个城市出现次数
salary_lists = {}
for x in city:
salary_lists[x] = salary.count(x)
key = []
values = []
for k,v in salary_lists.items():
key.append(k)
values.append(v)
bar2 = Bar('求职信息数据化','需求量',page_title='薪资分布')
# 图表其他主题:vintage,macarons,infographic,shine,roma
bar2.use_theme('vintage')
bar2.add('薪资',key,values,is_more_utils = True,is_datazoom_show = True,xaxis_interval=0, xaxis_rotate=30, yaxis_rotate=30)
bar2.render()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
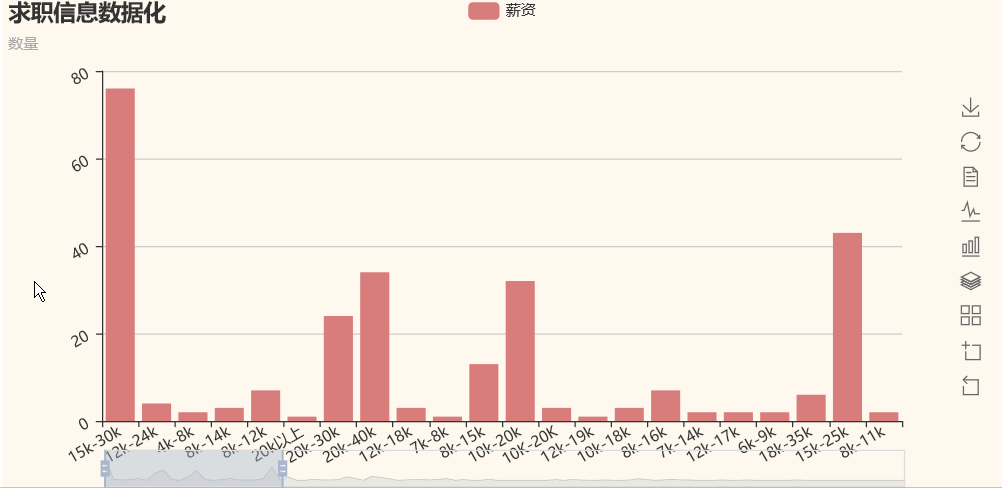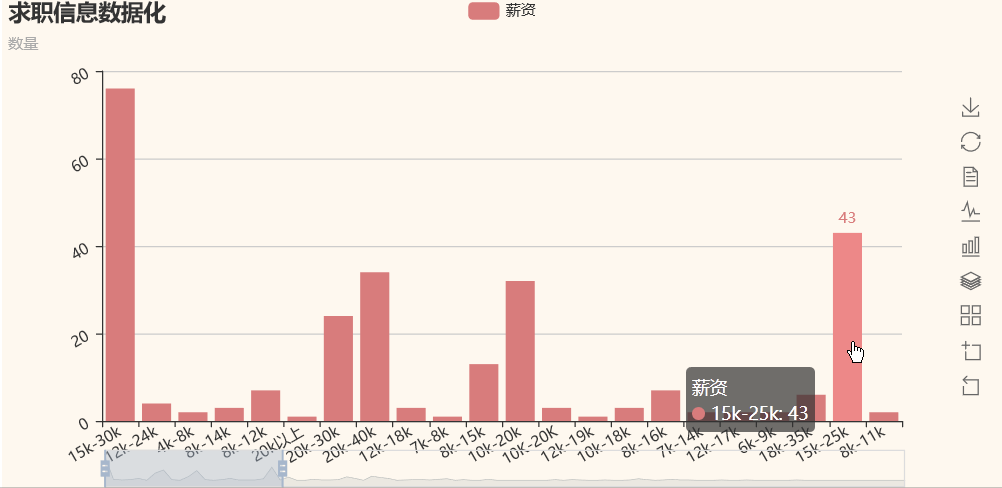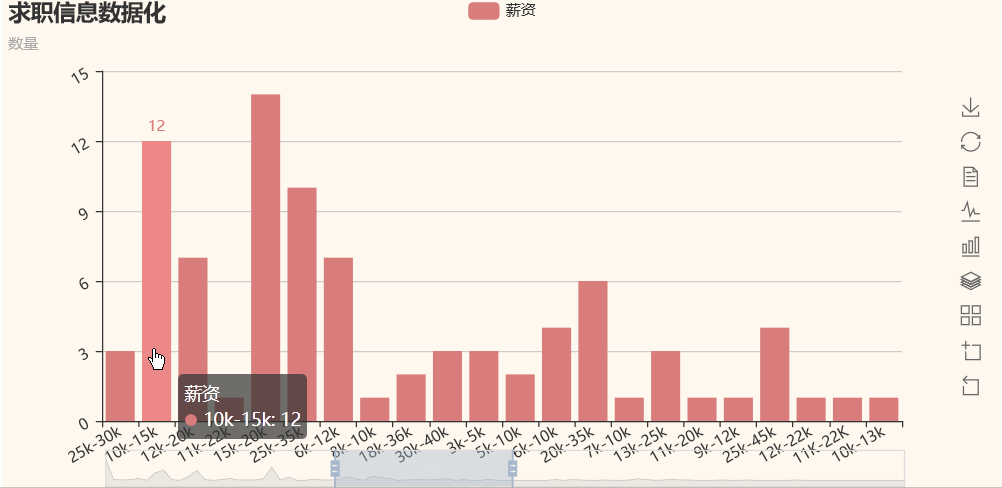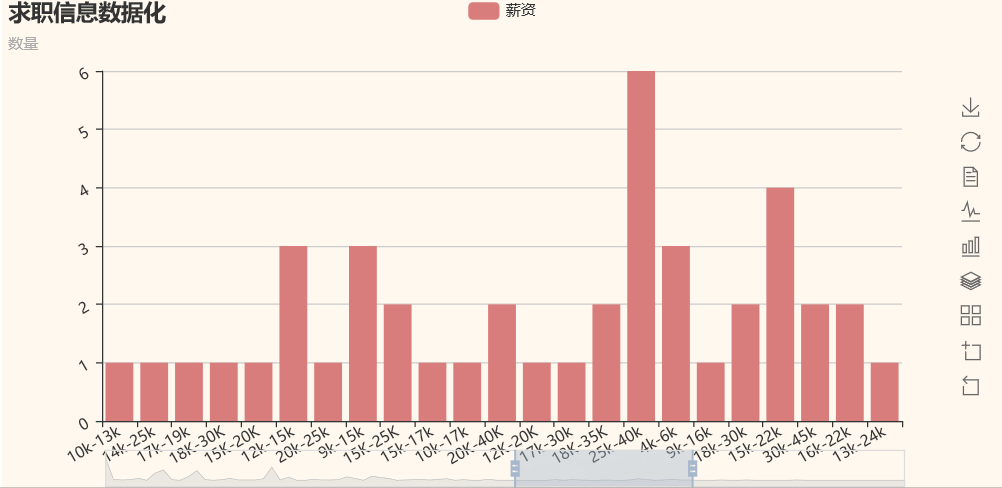
我们可以看到,python的薪资基本都是10k起步,大部分公司给出薪资在10k-40k之间,所以,不要怕学python吃不到饭。
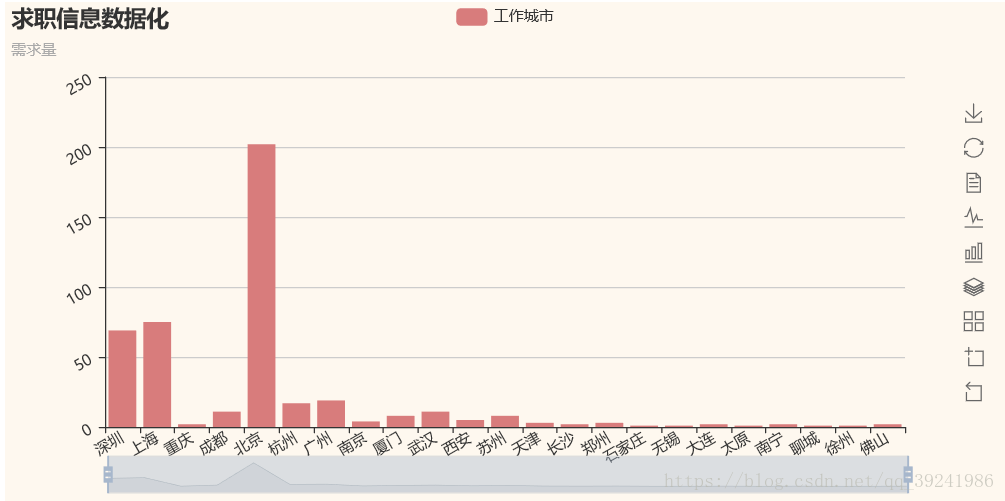
2.工作地点分析
通过图表,我们很容易看出,需要python程序员的公司大多分布在北京、上海、深圳,再后面就是广州了,所以,学python的同学千万不要去错城市哦。3.职位学历要求
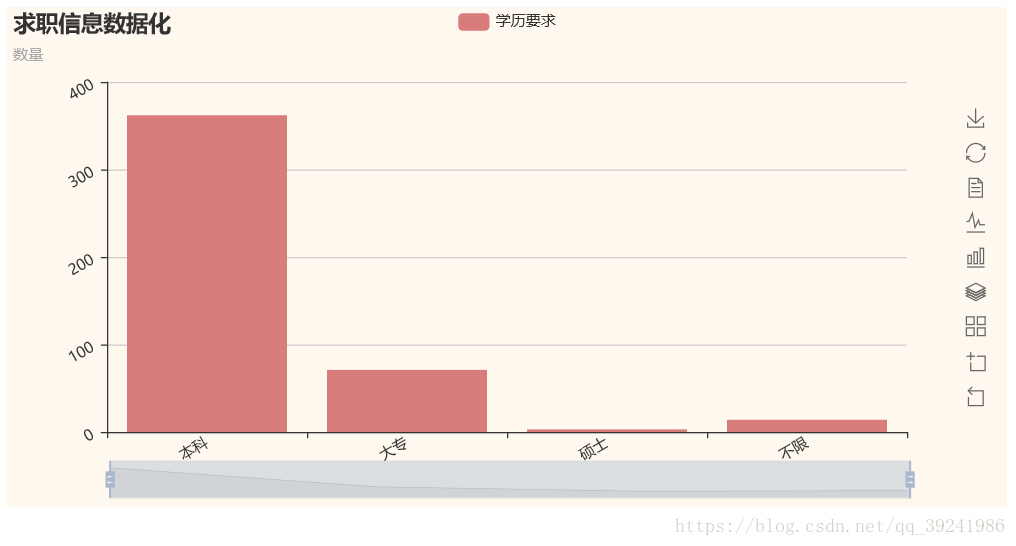
根据图表显示,python程序员的学历要求并不高,主要是本科,虽然学历要求不高,但一定要有思辨能力哦。4.工作经验要求
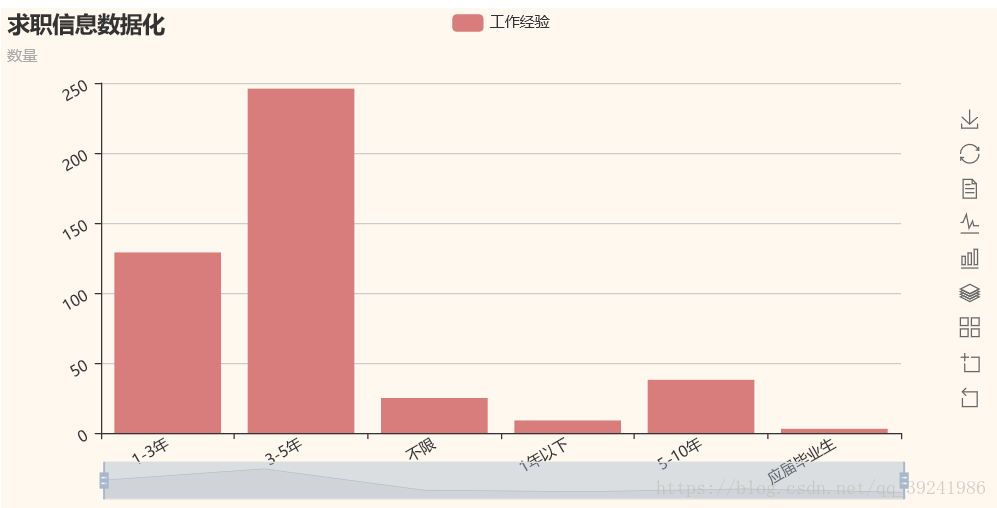
主要是需要3-5年工作经验的同学,不老也不年轻,成熟稳重,又能学新东西的年龄,招聘公司真聪明。5.工作职位研究方向分析
# 和下面福利关键词的分析差不多,大家可以自己试着写写。- 1

开发,没错是开发,至于具体什么开发,公司面谈吧。哈哈哈~
- 6.工作福利优点分析
# 福利关键词分析
content = ''
# 连接所有公司福利介绍
for x in positionAdvantage:
content = content + x
# 去除多余字符
content = re.sub('[,、(),1234567890;;&%$#@!~_=+]', '', content)
# jieba 切词,pandas、numpy计数
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment': segment})
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"计数": numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False)
test = words_stat.head(1000).values
# 制作词云图
codes = [test[i][0] for i in range(0,len(test))]
counts = [test[i][1] for i in range(0,len(test))]
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("福利关键词", codes, counts, word_size_range=[20, 100])
wordcloud.render()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

很明显,大家都关心的五险一金、团队、氛围、年终奖···都有哈。

