
- 1anaconda安装python 3.11_anaconda配置python3.11
- 2百度世界大会2021:AI链接社会价值
- 3CNCC 技术论坛 | 知识图谱赋能数字经济
- 4SQL注入原理讲解,很不错!
- 5使用avrdude下载arduino程序到Atgema328pb中_mega328pb
- 6如何一次取消全部WORD文档里的所有超链接?_怎么一键移除文章的超链接
- 76框开源代码搜索引擎_搜索引擎框代码
- 8Windows子系统WSL2 (ubuntu安装 docker、nvidia-docker)_windows docker nvidia
- 9docker(基础命令,实践(mysql,redis集群,tomcat), 网络)_docker mysql tomcat
- 10python+UIAutomation简介_python uiautomation
16款Stable Diffusion插件推荐,让SD小白快速上手_stable diffuison 插件推荐
赞
踩
随着 Stable Diffusion 的不断进化,越来越多的开发者加入到插件开发的行列中。大家都知道网上虽然教程多,但非常碎片,一个个学习和查阅真的非常耗时,感觉每天都在烧脑。如果你是SD小白或者是小懒猫,又想快速上手使用 Stable Diffusion 插件,那么这篇文章就非常适合你了!因为这是以设计师日常应用的角度出发,从推荐指数、易上手程度、使用频率三个维度来测评。下面会附赠下载地址!
希望这篇文章能够帮助大家更好地了解 Stable Diffusion 插件。
SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。

1.prompt-all-in-one提示词翻译补全(自动翻译)
**推荐指数:**⭐️⭐️⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️⭐️⭐️⭐️
能做什么:prompt-all-in-one提示词翻译补全可以帮助英文不好的用户,快速弥补英文短板。其中包含,中文输入自动转英文、自动保存使用描述词、描述词历史记录、快速修改权重、收藏常用描述词、翻译接口可以多种选择、一键粘贴删除描述词等。

扩展地址:https://github.com/Physton/sd-webui-prompt-all-in-one
**2.**SixGod提示词插件
**推荐指数:**⭐️⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️⭐️⭐️
能做什么:SixGod提示词插件可以帮助用户快速生成逼真、有创意的图像。其中包含,清空正向提示词”和“清空负向提示词、提示词起手式包含人物、服饰、人物发型等各个维度的提示词、一键清除正面提示词与负面提示词、随机灵感关键词、提示词分类组合随机、动态随机语法等。

扩展地址:https://github.com/thisjam/sd-webui-oldsix-prompt
**3.**After Detailer人脸及手部修复插件
**推荐指数:**⭐️⭐️⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️⭐️⭐️
能做什么:After Detailer 是一款强大的图像编辑工具,可用于修复和编辑图像。自动修复图像中的瑕疵 ,无论是2D还是真实的人脸及手部都可以通过识别面部/人物/手部并自动对其进行mask和重绘的工具,可以通过调整参数去改变识别的对象和识别区域的大小及位置等。
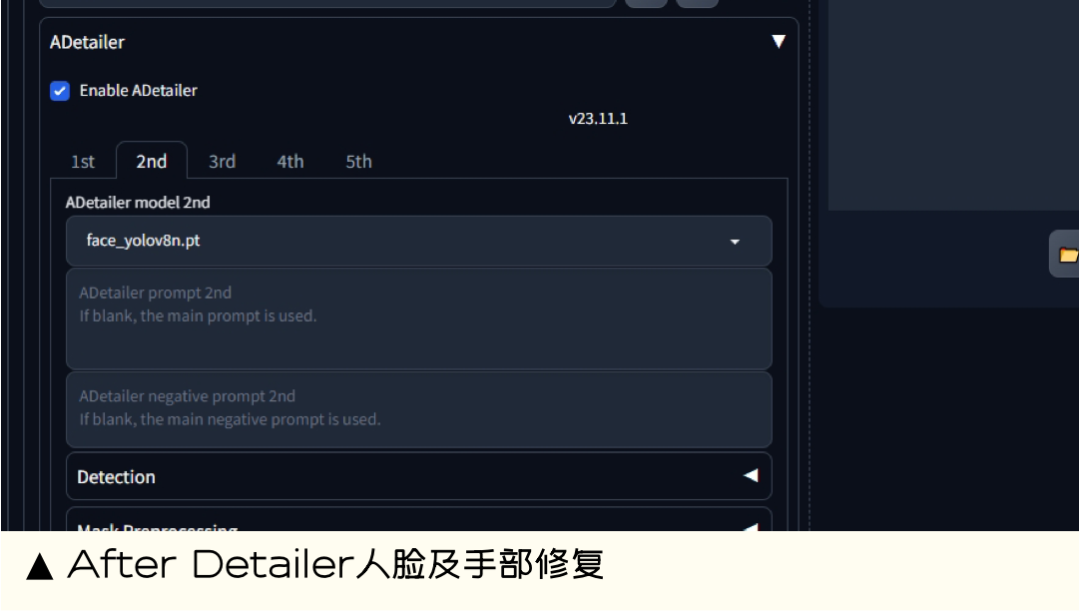
扩展地址:https://github.com/Bing-su/adetailer
**4.**Tagger提示词反推
**推荐指数:**⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️
能做什么:Tagger 提示词反推可以从任意图片中提取。帮助理解图像的内容、创建创意图像、分析图像数据。

扩展地址:https://github.com/pythongosssComfyUI-WD14-Tagger?tab=readme-ov-file
**5.**Inpaint Anything蒙版换装换脸
**推荐指数:**⭐️⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️
**使用频率:**⭐️⭐️
能做什么:Inpaint Anything 是一款强大的图像编辑工具,可用于删除和替换图像中的任何内容。它使用人工智能来自动识别和修复图像中的缺陷,无需使用遮罩。删除图像中的不需要的对象或瑕疵、修复图像中的损坏或损坏、替换图像中的对象或背景、创建创意图像效果。

扩展地址:https://github.com/Uminosachi/sd-webui-inpaint-anything
**6.**Segment Anything识别分割图片中的物体
**推荐指数:**⭐️⭐️⭐️
**易上手程度:**⭐️⭐️
**使用频率:**⭐️
能做什么:Segment Anything 是一款强大的图像分割工具,可用于自动识别和分割图像中的不同对象。类似于controlnet中的SEG语义分割,但Segment Anything是功能更强大、准确性更高、易用性也更高的图像分割工具。但学习成本更高。

扩展地址:https://github.com/facebookresearch/segment-anything.git
**7.**ultimate SD upscale图片放大
**推荐指数:**⭐️⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️⭐️⭐️
能做什么:Ultimate SD Upscale 是一款强大的图像超分辨率工具,可用于将低分辨率图像提升到高分辨率、减少噪声和模糊。Ultimate SD Upscale 使用的超分辨率模型是基于深度学习的,因此具有较高的准确性。

扩展地址:https://github.com/Coyote-A/ultimate-upscale-for-automatic1111.git
**8.**Tiled Diffusion
**推荐指数:**⭐️⭐️⭐️
**易上手程度:**⭐️⭐️
**使用频率:**⭐️⭐️⭐️
能做什么:Tiled Diffusion同样是图像超分辨率、修复图像瑕疵的工具。Tiled Diffusion适合小显存,速度更快,细节添加更可控,也不容易崩坏。

扩展地址:https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
**9.**4x-UltraSharp高清修复放大算法
**推荐指数:**⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️
能做什么:4x-UltraSharp 也是一款图像超分辨率工具,可用于将低分辨率图像提升到高分辨率。纯放大,无细节添加,最大可达 4 倍。
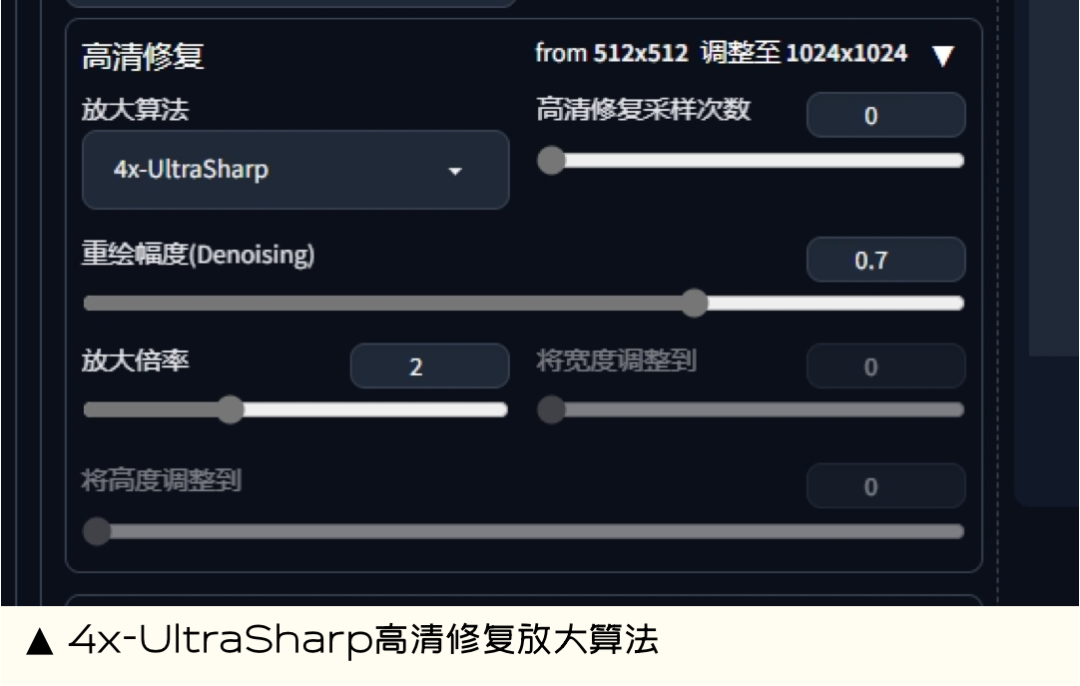
扩展地址:https://pan.baidu.com/s/1WcrZGjLZVOmCNjvy850IPw?pwd=7899 提取码:7899
Q:上面三款同样都是放大工具,三者的区别,哪款更好?
A:本人用Ultimate SD Upscale最多,因为它相对更有发挥空间。而Tiled Diffusion是可以让图片看起来更逼真。4x-UltraSharp简单方便。可以结合自身需求来选择使用。
**10.**Additional Networks
**推荐指数:**⭐️⭐️
**易上手程度:**⭐️
**使用频率:**⭐️
能做什么:Additional Networks 是一个由 Google AI 开发的插件,可用于模型中添加额外的LoRA,也可帮我们控制多个LoRA模型生成混合风格的图像,从而提升图片的独创性。
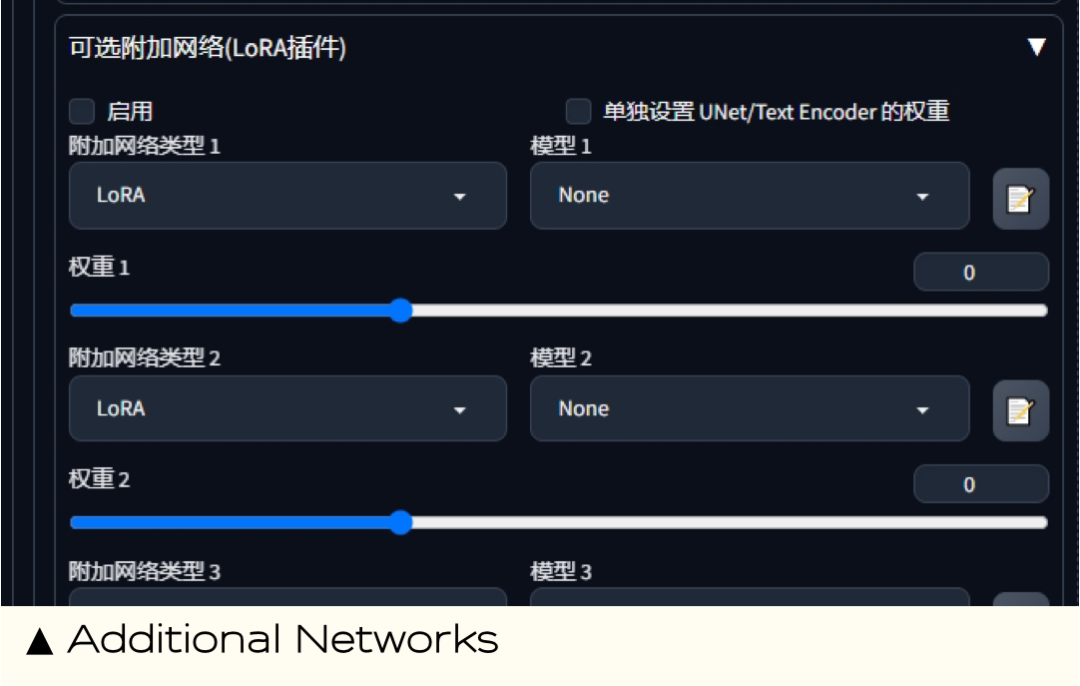
扩展地址:https://github.com/kohya-ss/sd-webui-additional-networks.git
**11.**Image-recognition图片信息识别
**推荐指数:**⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️⭐️⭐️
能做什么:sd-webui-图片信息识别是一个由 Google AI 开发的开源插件,可基于图片识别模型、图片中的物体、场景、人物等信息,并将其输出为文本。

扩展地址:https://github.com/google/sd-webui-image-recognition
**12.**Openpose Editor姿态编辑
**推荐指数:**⭐️⭐️⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️⭐️⭐️⭐️
能做什么:识别图片中的人物姿态,可以根据需求随意调整人物的姿势,例如武术、手托腮、人物复杂姿态。
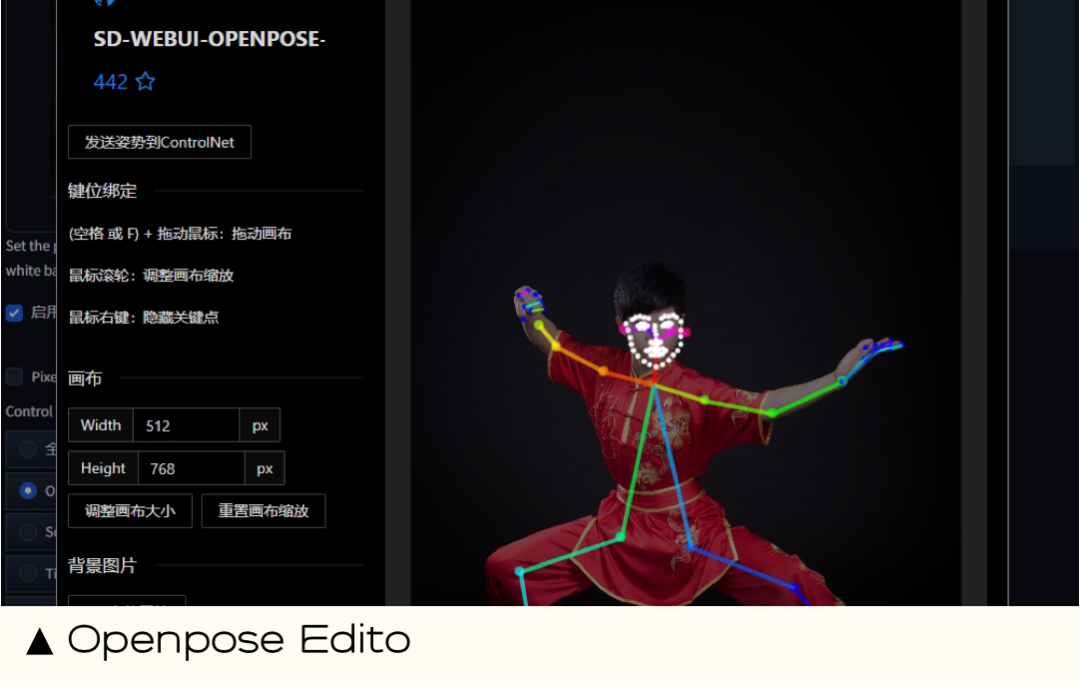
**13.**DWpose手部修复
**推荐指数:**⭐️⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️⭐️⭐️
能做什么:普通OpenPose模型的强化版,对手部动态识别有更好的理解能力,对复杂的穿插关系的姿态识别表现出众。

扩展地址:https://github.com/IDEA-Research/DWPose
**14.**IP-Adaper
**推荐指数:**⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️⭐️
能做什么:IP-Adapter 是腾讯的另一个实验室 Tencent AI Lab 研发的控图模型。名称中的 IP 指的是 Image Prompt 图像提示,它和 T2I-Adapter 一样是一款小型模型,用于风格迁移、可理解为垫图。
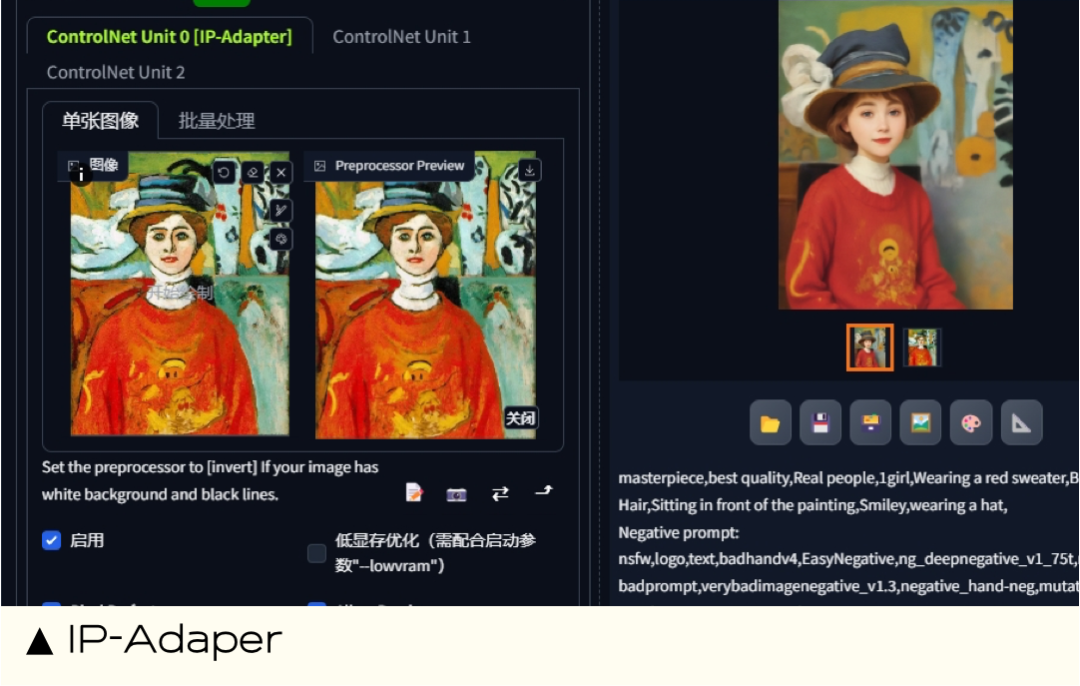
扩展地址:https://github.com/tencent-ailab/IP-Adapter https://ip-adapter.github.io/
**15.**Recolor重新上色
**推荐指数:**⭐️⭐️⭐️⭐️
**易上手程度:**⭐️⭐️⭐️⭐️⭐️
**使用频率:**⭐️
能做什么:Recolor 是给图片填充颜色,非常适合修复一些黑白老旧照片和去过色的图片。

**16.**T2I-Adapter 文生图适配器
**推荐指数:**⭐️⭐️⭐️⭐️
**易上手程度:**⭐️
**使用频率:**⭐️⭐️
能做什么:T2I-Adapter 由腾讯 ARC 实验室和北大视觉信息智能学习实验室联合研发的一款小型模型,它的作用是为各类文生图模型提供额外的控制引导,同时又不会影响原有模型的拓展和生成能力。T2I-Adapter 的特点是体积小,参数级只有 77M,但对图像的控制效果不错。

扩展地址:https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
总体而言,Stable Diffusion功能非常强大、也逐渐变得易于使用了。如果你还没有尝试过SD,我强烈建议你试试看。它一定会给你带来惊喜!需要SD安装包的小伙伴也可以在文末扫码,我给大家免费安排!
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

