
- 1stc5 采集adc值越来越小_FPGA高速数据采集设计JESD204B接口的应用场景
- 2【深度学习】数据归一化/标准化 Normalization/Standardization_深度学习 归一化计算
- 3PCB设计中,铜箔的厚度,PCB线宽和电流的关系
- 4实战 | YOLOv10 自定义数据集训练实现车牌检测 (数据集+训练+预测 保姆级教程)
- 5union all和union的区别以及怎么使用_union all和union的区别用法
- 6使用 Docker 设置 PySpark Notebook_docker 执行 pyspark
- 7OpenNLP入门实验_opennlp ner 地址
- 8Spring Boot 3.0 新书出炉!
- 9OrangePi KunPengPro | 开发板开箱测评之学习与使用
- 10Merge还是Rebase?这次终于懂了_rebase 和 merge
【论文解读】SAHI:针对小目标检测的切片辅助超推理库
赞
踩
★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
SAHI:针对小目标检测的切片辅助超推理库
当数据集中大部分目标均极小的情况下,使用SAHI可以进一步提高检测精度,并且它可以应用在任何现有的目标检测网络上。特别地,由于无人机航拍获得的图像中,其目标尺寸较小,本项目在最后会介绍PaddleDetection的SAHI(Slicing Aided Hyper Inference)工具切图和拼图的方案,并展示基于PP-YOLOE-SOD小目标检测模型对无人机航拍图像的推理效果。·
参考资料:
- Fatih Cagatay Akyon, Sinan Onur Altinuc, & Alptekin Temizel (2023). Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection
- 基于PP-YOLOE-SOD的无人机航拍图像检测案例全流程实操 by 飞桨PaddleDet
- 小目标检测研究进展
一、小目标检测主流解决方案
小目标检测中的小目标目前有两大类的定义,分别是基于相对尺度定义(即与同一类别中所有目标实例的相对面积相比)和基于绝对尺度定义(即从目标绝对像素大小这一角度考虑来对小目标进行定义)。目前最为通用的定义来自于目标检测领域的通用数据集——MS COCO数据集,将小目标定义为分辨率小于32像素×32像素的目标。
在做小目标检测时,由于待检测物体在图像中的像素占比较少,缺乏足够的细节,因此难以使用传统目标检测方法进行检测,但是目前也有一些方法在尝试解决小目标检测的难点。
1.数据增强
在提升模型性能的方法中,数据增强是最简单、最有效的方法,通过不同的数据增强策略可以扩充训练数据集的规模,从而在一定程度上增强模型的鲁棒性和泛化能力。常用的增强策略有:
- 复制增强:通过对图像中的小目标的复制与粘贴操作进行数据增强
- 自适应采样:考虑上下文信息进行复制,避免出现尺度不匹配和背景不匹配的问题
- 尺度匹配:通过尺度匹配策略对图像进行尺度变换,用作额外的数据补充
- 放与拼接:通过缩放拼接操作增加中、小尺寸目标的数量
数据增强这一策略虽然在一定程度上解决了小目标信息量少、有效提高了网络的泛化能力,在最终检测性能上获得了较好的效果,但同时带来了计算成本的增加。而且在实际应用中,怎么选择数据增强策略也是一个问题,设计不当的数据增强策略可能会引入新的噪声,损害特征提取的性能,这也给算法的设计带来了挑战。
SAHI算法就属于数据增强的方法,为了处理小对象检测问题,SAHI算法在fine-tuning和推理阶段提出了一种基于切片的通用框架。将输入图像分割成重叠的块,这样小目标物体的像素区域相对较大一些。注:因为
SAHI算法只是将输入图像分成若干子图,所以它输入图像的分辨率很高,适用于遥感图像、4k无人机航拍图像等高质量图像,而不适用于分辨率很低的图像!换句话说,该算法解决的是基于相对尺度定义的小目标检测,而对于在基于绝对尺度定义的小目标检测收效甚微。
2.多尺度学习
小目标与常规目标相比可利用的像素较少,难以提取到较好的特征,而且随着网络层数的增加,小目标的特征信息与位置信息也逐渐丢失,难以被网络检测。这些特性导致小目标同时需要深层语义信息与浅层表征信息,而多尺度学习将这两种相结合,是一种提升小目标检测性能的有效策略。常用的多尺度学习模型框架如下图所示:
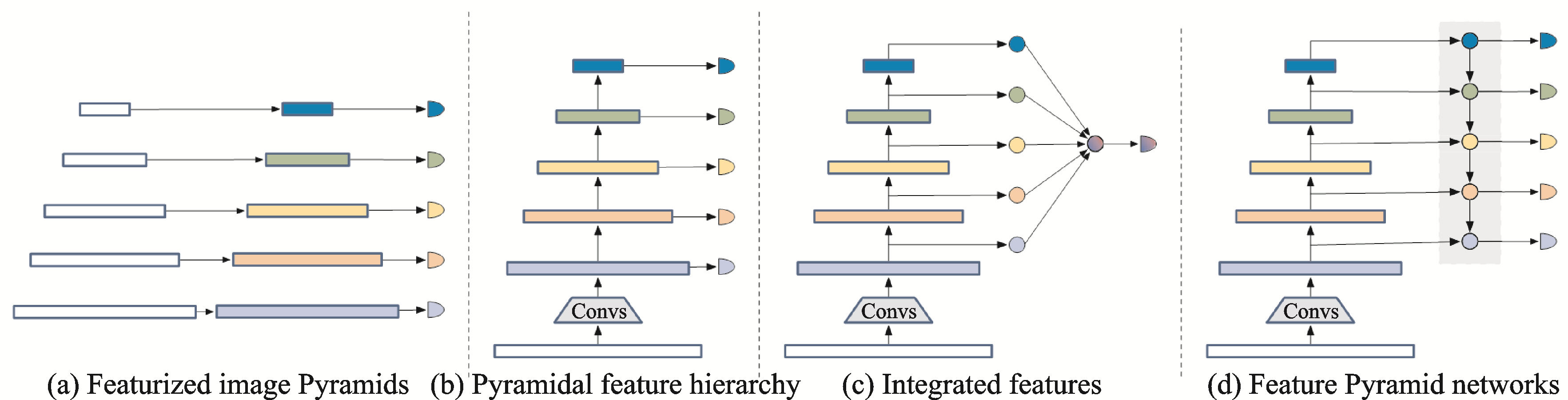
注:上图源于高新波,莫梦竟成,汪海涛等.小目标检测研究进展[J].数据采集与处理,2021,36(03):391-417.
多尺度特征融合同时考虑了浅层的表征信息和深层的语义信息,有利于小目标的特征提取,能够有效地提升小目标检测性能。然而,现有多尺度学习方法在提高检测性能的同时也增加了额外的计算量,并且在特征融合过程中难以避免干扰噪声的影响,这些问题导致了基于多尺度学习的小目标检测性能难以得到进一步提升。
3.上下文学习
在真实世界中,“目标与场景”和“目标与目标”之间通常存在一种共存关系,通过利用这种关系将有助于提升小目标的检测性能。将目标周围的上下文集成到深度神经网络中的方法有:基于隐式上下文特征学习的目标检测和显式上下文推理的目标检测。
4.生成对抗学习
生成对抗学习的方法旨在通过将低分辨率小目标的特征映射成与高分辨率目标等价的特征,从而达到与尺寸较大目标同等的检测性能。前文所提到的数据增强、特征融合和上下文学习等方法虽然可以有效地提升小目标检测性能,但是这些方法带来的性能增益往往受限于计算成本。
二、算法框架
为了处理小目标检测问题,SAHI算法在fine-tuning和推理阶段提出了一种基于切片的通用框架。将输入图像分割成重叠的块,这样小目标物体的像素区域相对较大一些。
1.fine-tuning阶段的切片框架
fine-tuning阶段通过从图像中提取patch并将其调整为更大的大小来增强数据集,fine-tuning阶段的切片框架如下图所示:

注:上图源于Fatih Cagatay Akyon, Sinan Onur Altinuc, & Alptekin Temizel (2023). Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection
具体地,SAHI算法在微调阶段通过从数据集中提取patch来增强数据集。每个图像
I
1
F
,
I
2
F
,
…
,
I
j
F
I_{1}^{F}, I_{2}^{F}, \ldots, I_{j}^{F}
I1F,I2F,…,IjF将被切片为重叠的patch
P
1
F
,
P
2
F
,
…
P
k
F
P_{1}^{F}, P_{2}^{F}, \ldots P_{k}^{F}
P1F,P2F,…PkF 。
然后在微调期间,通过保持纵横比来调整patch的大小,使得图像宽度在800到1333像素之间,以获得增强图像 I 1 ′ , I 2 ′ , … , I k ′ I_{1}^{\prime}, I_{2}^{\prime}, \ldots, I_{k}^{\prime} I1′,I2′,…,Ik′,因此相对对象大小与原始图像相比更大。在微调期间将会使用增强图像 I 1 ′ , I 2 ′ , … , I k ′ I_{1}^{\prime}, I_{2}^{\prime}, \ldots, I_{k}^{\prime} I1′,I2′,…,Ik′以及原始图像 I 1 F , I 2 F , … , I j F I_{1}^{F}, I_{2}^{F}, \ldots, I_{j}^{F} I1F,I2F,…,IjF(以便于检测大物体)。
必须注意的是,随着patch大小的减小,较大的对象可能不适合切片和相交区域,这可能导致较大对象的检测性能较差。
2.推理阶段的切片框架
在推理过程中,图像被划分为许多较小的子图,并对这些子图进行resize后送入模型进行预测。然后,预测结果会在NMS之后转换回原始图像坐标。特别地,还可以添加来自原图的预测结果。推理阶段的切片框架如下图所示:
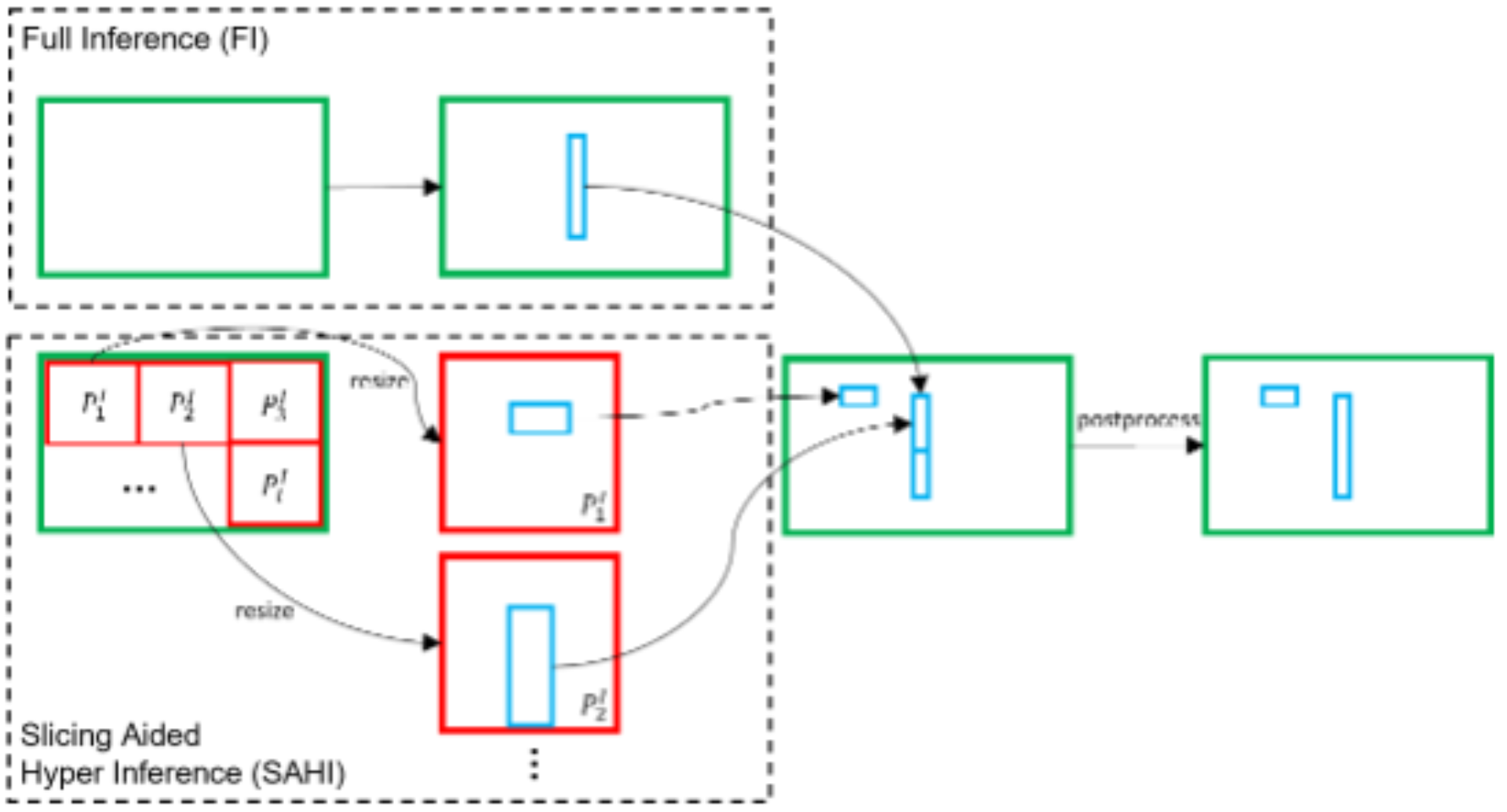
注:上图源于Fatih Cagatay Akyon, Sinan Onur Altinuc, & Alptekin Temizel (2023). Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection
在推理的时候中也采用切片方法。首先,将原始图像 I I I分成 l l l个 M × N M \times N M×N个重叠的patch P 1 I , P 2 I , … P l I P_{1}^{I}, P_{2}^{I}, \ldots P_{l}^{I} P1I,P2I,…PlI。
然后,在保留纵横比的同时调整每个patch的大小,并且对每个patch分别进行预测。特别地,加上对原始图像的推理结果可用于检测更大的物体。
最后,使用NMS将重叠的预测结果和对原始图像的推理结果合并,并转换到原始大小。
总的来说,SAHI算法非常巧妙地避开了模型设计,只在模型的输入做改进,也正因如此,SAHI算法可以应用在现有的任意目标检测算法中。但是缺点也很明显,就是用速度换精度,对于实时检测的场景,可能不是那么地适合,除非检测模型非常小、推理速度非常快…
三、基于SAHI的无人机航拍图像检测
这里我们在PP-YOLOE模型的基础上,使用SAHI算法完成无人机航拍图像检测。
飞桨PaddleDetection团队已经提供了训练好的PP-YOLOE模型,并且配置了SAHI算法,可供我们快速体验。
PaddleDetection是一个基于PaddlePaddle的目标检测端到端开发套件,在提供丰富的模型组件和测试基准的同时,注重端到端的产业落地应用,通过打造产业级特色模型|工具、建设产业应用范例等手段,帮助开发者实现数据准备、模型选型、模型训练、模型部署的全流程打通,快速进行落地应用。
1.安装必要的资源库
# 下载PaddleDetection
%cd /home/aistudio/
# gitee 国内下载比较快
!git clone https://gitee.com/paddlepaddle/PaddleDetection.git -b develop
- 1
- 2
- 3
- 4
/home/aistudio
正克隆到 'PaddleDetection'...
remote: Enumerating objects: 255205, done.[K
remote: Counting objects: 100% (202/202), done.[K
remote: Compressing objects: 100% (152/152), done.[K
remote: Total 255205 (delta 74), reused 156 (delta 50), pack-reused 255003[K
接收对象中: 100% (255205/255205), 412.30 MiB | 5.01 MiB/s, 完成.
处理 delta 中: 100% (209102/209102), 完成.
检查连接... 完成。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
# 安装PaddleDetection
%cd /home/aistudio/PaddleDetection/
!pip install -r requirements.txt
!python setup.py install
- 1
- 2
- 3
- 4
2.准备PP-YOLOE模型
导出基于VisDrone-DET数据集训练的PP-YOLOE模型
# 导出模型
%cd /home/aistudio/PaddleDetection/
!python tools/export_model.py -c configs/smalldet/ppyoloe_crn_l_80e_sliced_visdrone_640_025.yml \
-o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_80e_sliced_visdrone_640_025.pdparams
- 1
- 2
- 3
- 4
[01/11 21:20:41] ppdet.utils.download INFO: Downloading ppyoloe_crn_l_80e_sliced_visdrone_640_025.pdparams from https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_80e_sliced_visdrone_640_025.pdparams
100%|████████████████████████████████| 208285/208285 [00:08<00:00, 24169.58KB/s]
[01/11 21:20:51] ppdet.utils.checkpoint INFO: Finish loading model weights: /home/aistudio/.cache/paddle/weights/ppyoloe_crn_l_80e_sliced_visdrone_640_025.pdparams
[01/11 21:20:52] ppdet.data.source.category WARNING: anno_file 'dataset/visdrone_sliced/val_640_025.json' is None or not set or not exist, please recheck TrainDataset/EvalDataset/TestDataset.anno_path, otherwise the default categories will be used by metric_type.
[01/11 21:20:52] ppdet.data.source.category WARNING: metric_type: COCO, load default categories of COCO.
[01/11 21:20:52] ppdet.engine INFO: Export inference config file to output_inference/ppyoloe_crn_l_80e_sliced_visdrone_640_025/infer_cfg.yml
[01/11 21:21:01] ppdet.engine INFO: Export model and saved in output_inference/ppyoloe_crn_l_80e_sliced_visdrone_640_025
- 1
- 2
- 3
- 4
- 5
- 6
- 7
导出的模型将保存在/home/aistudio/PaddleDetection/output_inference/ppyoloe_crn_l_80e_sliced_visdrone_640_025。
3.单图预测
使用PaddleDetection/deploy/python/infer.py进行预测,其中有以下参数可以配置:
- slice_infer表示切图预测并拼装重组结果,如果不使用则不写;
- slice_size表示切图的子图尺寸大小
- overlap_ratio表示子图间重叠率;
- combine_method表示子图结果重组去重的方式,默认是nms;
- match_threshold表示子图结果重组去重的阈值,默认是0.6;
- match_metric表示子图结果重组去重的度量标准,默认是ios表示交小比(两个框交集面积除以更小框的面积),也可以选择交并比iou(两个框交集面积除以并集面积),精度效果因数据集而而异,但选择ios预测速度会更快一点;
# 使用单张子图预测
%cd /home/aistudio/PaddleDetection/
!python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_80e_sliced_visdrone_640_025 \
--image_file=/home/aistudio/drone_demo.jpg \
--output_dir=/home/aistudio/work/demo/deploy_output \
--threshold=0.30 \
--slice_infer
--device=GPU
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
为了做对比,这里展示基于SAHI算法以及不基于SAHI算法的预测结果,如图所示:
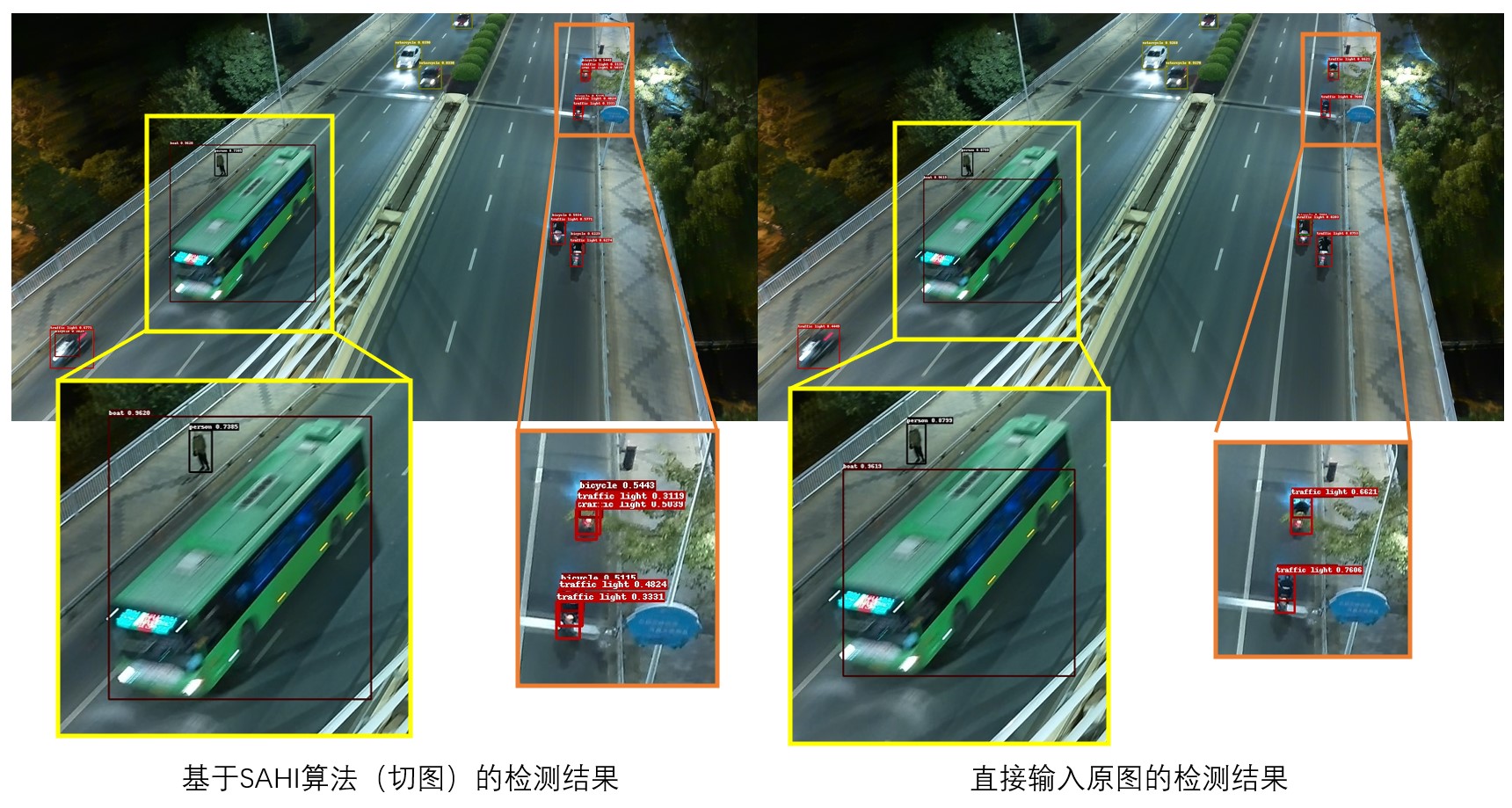
这张图是我精心挑选的,因为图像中不仅有小目标(非机动车、行人等),还有尺寸相对较大的目标(公交车)。从上图的对比中不难发现:
- 直接输入原图对于面积占比较大的物体的检测效果更好;但是在检测小物体时,检测框有重叠,效果会差一些
- 使用
SAHI算法时,可以发现大物体的检测效果变差了,公交车的检测框并没有完全框住公交车;但是在检测非机动车时,可以发现重叠框变少了,比直接输入原图的效果要好一些。
4.视频预测
对多个航拍视频逐帧拆解成图像,并进行推理,推理结束后,将推理结果可视化并合成视频。
视频拆帧
将/home/aistudio/drone_video文件夹下的所有视频逐帧拆解,这里放了5个示例视频:
drone_video
├── Video_20230104_203458_0002_AA 00_00_04-00_00_15.mp4
├── Video_20230104_204350_0011_AA 00_00_05-00_00_30.mp4
├── Video_20230104_204741_0013_AA 00_00_08-00_00_21.mp4
├── Video_20230104_205948_0006_AA 00_00_00-00_00_03.mp4
└── Video_20230104_210422_0010_AA 00_00_15-00_00_34.mp4
- 1
- 2
- 3
- 4
- 5
- 6
视频拍摄设备为哈博森Zino Mini Pro无人机。
视频拆解成图片后,其图片会保存到/home/aistudio/drone_video2img文件夹中,并且在该文件夹下,每个视频文件会生成一个文件夹,对应视频拆出来的图片会放到对应名称的文件夹中:
drone_video2img
├── Video_20230104_203458_0002_AA 00_00_04-00_00_15
├── Video_20230104_204350_0011_AA 00_00_05-00_00_30
├── Video_20230104_204741_0013_AA 00_00_08-00_00_21
├── Video_20230104_205948_0006_AA 00_00_00-00_00_03
└── Video_20230104_210422_0010_AA 00_00_15-00_00_34
- 1
- 2
- 3
- 4
- 5
- 6
# 对文件夹下的所有视频进行批量拆帧
!python /home/aistudio/video2image.py
- 1
- 2
批量预测
对/home/aistudio/drone_video2img文件夹下的所有图片进行基于SAHI算法(切图)的预测,并保存可视化预测结果.
对文件夹下的图片进行批量检测时,infer.py中--image_file需要改为--image_dir,并在--image_dir后面输入文件夹路径。
# 对某个文件夹下的图片进行批量预测 import os import threading from threading import Lock, Thread folder_path = "/home/aistudio/drone_video2img" folderlist = os.listdir(folder_path) def folder_detect(foldername): os.system('cd /home/aistudio/PaddleDetection/ && \ python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_80e_sliced_visdrone_640_025 \ --image_dir=/home/aistudio/drone_video2img/{}/ \ --output_dir=/home/aistudio/drone_videoimg_output/{}/ \ --threshold=0.30 \ --slice_infer \ --device=GPU'.format(foldername, foldername)) for foldername in folderlist: print(foldername) if(foldername == '.ipynb_checkpo'): continue folder_detect(foldername)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
注:输出的图像有缺失是正常的,可能某一张图像中没有目标物体,就不会输出检测结果
合成视频
最后将可视化的检测结果(单张图片)按顺序合成为视频即可。
!python /home/aistudio/image2video.py
- 1
视频展示:
b站视频链接:https://www.bilibili.com/video/BV1GD4y1W7Hf/
四、总结与升华
SAHI算法在一定程度上可以提高小目标检测模型的性能,但是对于大目标来说,可能性能会有所降低,因此,在推理时可以增加原图推理的结果,但是,这样一来会导致推理时间的延长,并且,SAHI算法的切图操作本身就会带来性能上的损耗,不过SAHI算法也会小目标检测的优化打开了思路,这样一个通用的、可以应用在任何现有的目标检测网络上的算法给我的感觉更像是一种可以在比赛中刷榜的trick。
作者简介
郑博培,百度飞桨开发者技术专家,AI Studio精选项目审稿人,前任百度飞桨北京领航团团长、百度飞桨领航团技术面试官,多次参与各大竞赛基线系统的开发、多次担任课程讲师及助教。
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378

