
- 1C语言第十七弹---指针(一)
- 2uview组件得到回调的参数_uview 展开阅读更多用法
- 3子序列个数_子序列的定义:对于一个序列a=a[1]a[2]......a[n]。则非空序列a'=a[p1]a[p
- 4linux 给用户授予目录权限_linux chmod username
- 5一键迁移接口,即刻搭建企业接口开放平台 - YesApi接口大师v3.15
- 6神经网络基础以及BP算法_bp算法每一轮迭代中的更新步长是由( )控制的
- 73、使用三层交换机实现跨VLAN通信_三层交换机跨vlan通信
- 8c#-OpenCvSharp-SURF/SIFT特征匹配(附源码)_opencvsharp surf
- 9Codeforces Round 700(Div.2)--Problem C
- 10208.【2023年华为OD机试真题(C卷)】停车场车辆统计(贪心算法实现-Java&Python&C++&JS实现)_华为机试 停车场车辆统计
【LLM】低成本进行半天的训练可产生与主流大型模型、开源且无商业的特定领域 LLM 解决方案类似的结果_llm 训练成本
赞
踩

LLaMA-1 和 LLaMA-2 之间最显着的区别在于纳入了更高质量的语料库,这是导致 LLaMA-2 性能显着增强的关键因素。这与其商业可用性相结合,扩展了开源社区内大型模型的创造性应用的潜力。
然而,人们普遍认为,从头开始预训练大型模型的成本过高,通常被幽默地称为只有“5000万美元”闲置的人才能进入的领域。这让很多公司和开发者望而却步,那么如何才能以更低的成本构建自己的大型模型呢?
Colossal-AI团队处于大型模型降低成本和效率提升的前沿,最大限度地发挥了 LLaMA-2 的核心功能。通过创新的训练技术,Colossal-AI 仅利用了约0.0085 万亿代币的数据,投入了 15 个小时,花费了数百美元的训练成本,就取得了显着的效果。这一策略产生了高性能的中国 LLaMA-2 模型,该模型在多个评估基准上始终优于竞争对手。
与原始的LLaMA-2相比,Colossal-AI的模型不仅增强了中文能力,还进一步提高了其英语水平。值得注意的是,它所表现出的性能水平可以与开源社区中类似规模的最先进 (SOTA) 模型相媲美。
Colossal-AI 方法的基础是坚定的开源原则。因此,该模型的访问不受任何商业限制,并且整个训练过程、代码和模型权重完全透明。与此同时,Colossal-AI 提供了综合评估框架 ColossalEval,促进了经济高效的可重复性。
此外,Colossal-AI 开发的方法可以轻松应用于各个领域,有助于经济地构建从头开始预训练的大型模型。
开源代码和权重可在以下位置获得:
GitHub - hpcaitech/ColossalAI: Making large AI models cheaper, faster and more accessible

表现如下
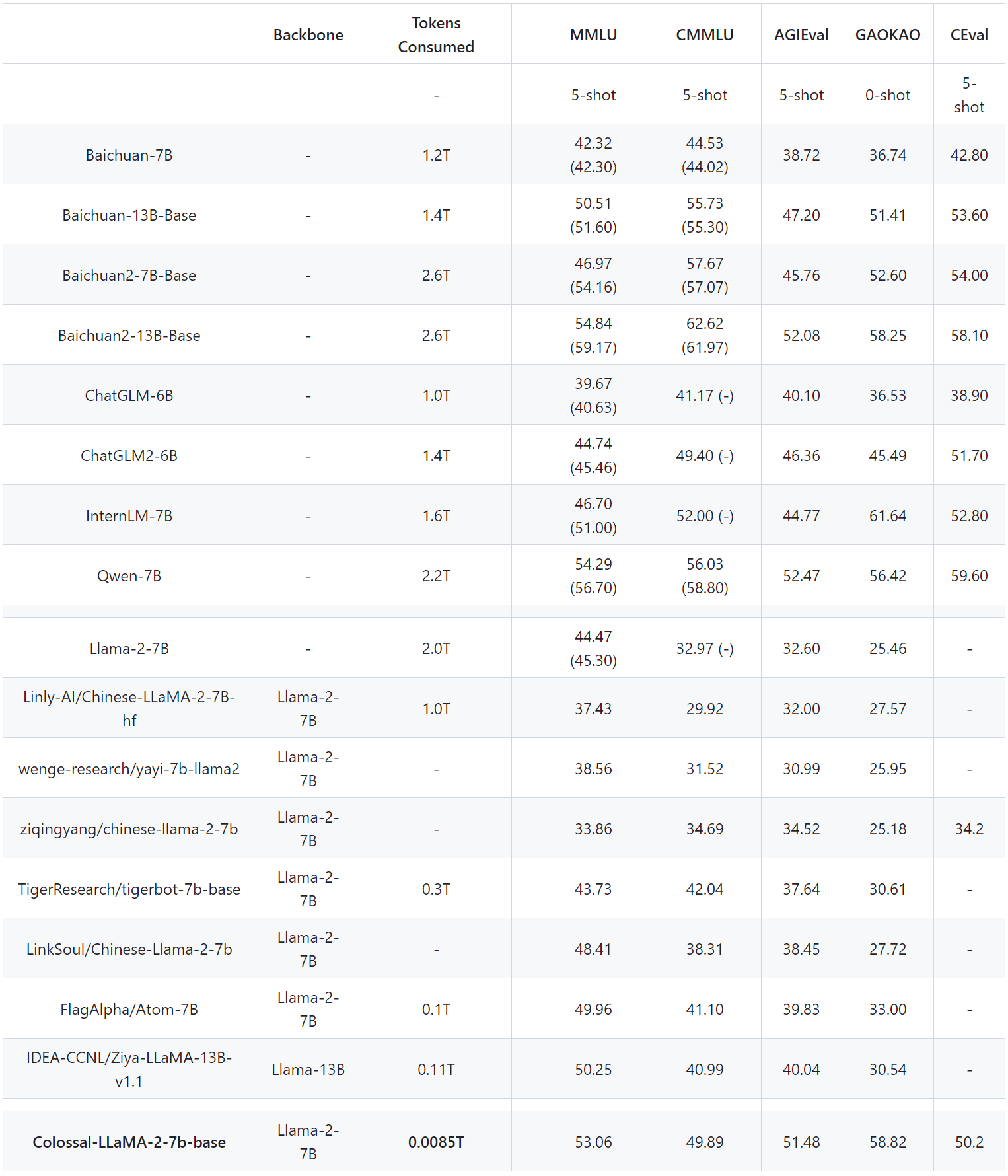
注:基于ColossalEval分数,括号内的分数来自相应模型的官方排行榜分数,C-Eval分数来自官方排行榜。
在常见的英语评测排名中可以观察到,在MMLU排名中,Colossal-LLaMA-2-7B-base在低成本持续预训练的支持下,克服了灾难性遗忘的问题。其性能稳步提升(44.47 -> 53.06),在所有7B级型号中展现出优异的性能。
中文排名中,主要与CMMLU、AGIEVAL、GAOKAO、C-Eval进行比较。Colossal-LLaMA-2 的性能明显优于其他基于 LLaMA-2 的中文本地化模型。即使与其他使用中文语料库并可能花费数百万美元从头开始训练的知名模型相比,Colossal-LLaMA-2 在同等规模下仍然脱颖而出。值得注意的是,与原来的LLaMA-2相比,它在汉语水平上取得了显着的飞跃(CMMLU:32.97 -> 49.89)。
此外,通过SFT和LoRA等方法进行微调在有效地从基础模型中注入知识和能力方面存在局限性。它不能很好地满足构建高质量的特定领域知识或专门模型应用的要求。
为了更好地评估模型的性能,Colossal-AI团队不仅依靠定量指标,还对模型的不同方面进行人工评估。以下是一些示例:

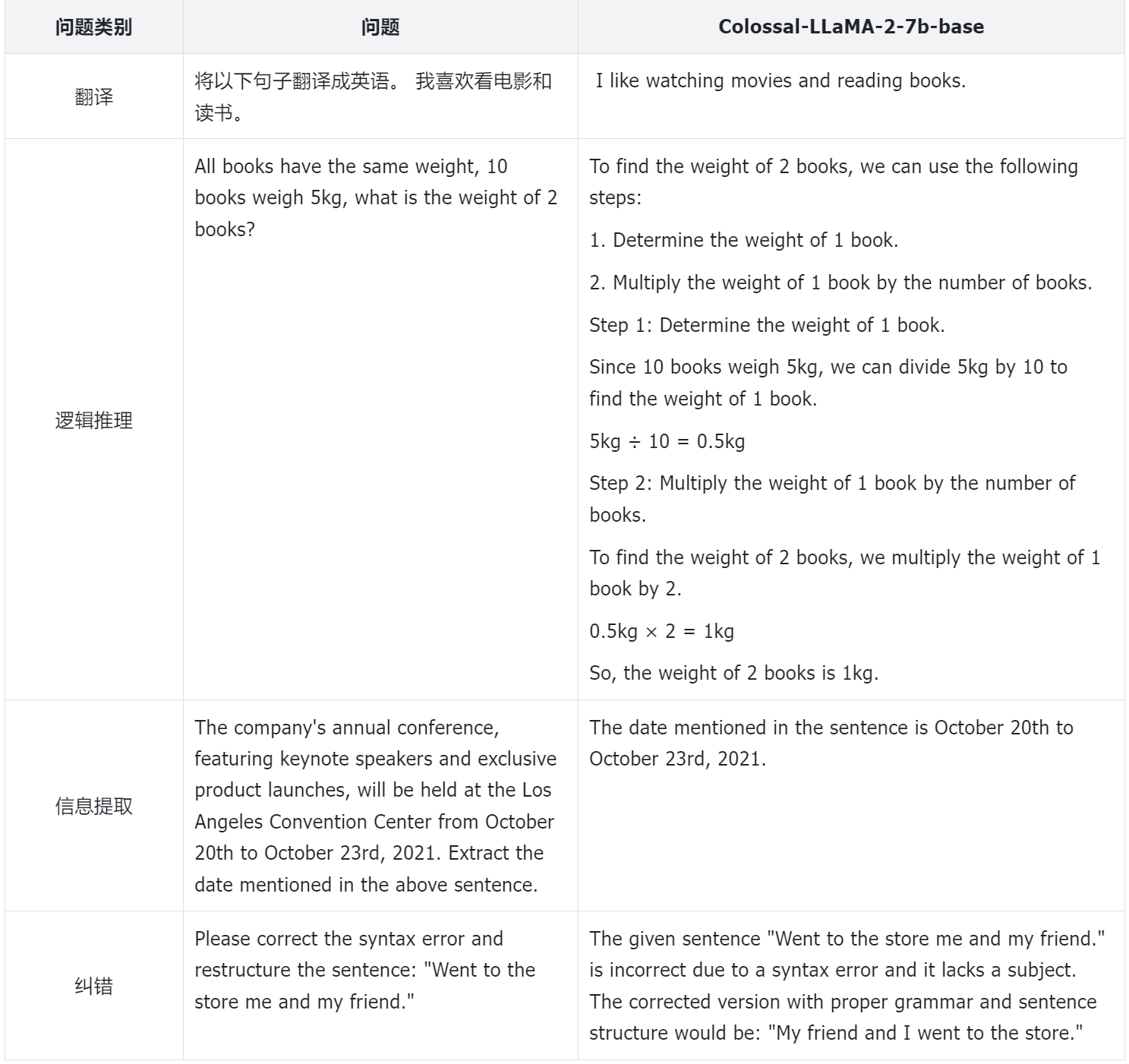
纵观整个训练损失记录,很明显,在利用 Colossal-AI 系统的成本效益功能的同时,模型的收敛性也得到了很好的保留。该模型在训练数据集仅为约85 亿个 token 和数百美元的计算成本的情况下取得了如此显着的成绩。相比之下,市场上许多大规模模型需要数万亿代币进行训练才能保证有效性,成本明显较高。
那么,Colossal-AI团队是如何降低培训成本并取得如此骄人成绩的呢?
词汇扩展和模型初始化
LLaMA-2的原始词汇没有专门针对中文进行优化,中文词汇有限,导致对中文数据的理解不足。因此,第一步涉及扩大 LLaMA-2 的词汇量。
Colossal-AI 团队发现:
- 词汇扩展不仅显着提高了字符串序列的编码效率,而且丰富了编码序列的更有意义的信息。事实证明,这对于文档级编码和理解非常有益。
- 然而,由于连续预训练数据量有限,词汇量的广泛扩展可能会导致某些单词或组合缺乏实际意义,从而使得从连续预训练数据集中有效学习它们变得困难并影响最终性能。
- 词汇量过大会增加嵌入相关参数的数量,影响训练效率。
因此,在兼顾训练质量和效率的情况下,经过大量实验,Colossal-AI团队决定将LLaMA-2的词汇量从原来的32,000个单词扩大到69,104个。
扩展词汇表到位后,下一步涉及根据新词汇表的原始 LLaMA-2 初始化嵌入。为了促进从原始 LLaMA-2 到中文 LLaMA-2 的功能无缝过渡,同时确保英语水平在初始状态下不受影响,Colossal-AI 团队使用原始嵌入的权重对新嵌入进行平均初始化LLaMA-2。这种方法不仅保留了英语语言能力,而且有利于这些能力顺利转移到中文语言模型。
数据建设
要进一步降低训练成本,高质量的数据起着关键作用,特别是持续的预训练对数据的质量和分布都有严格的要求。为了更好地筛选高质量数据,Colossal-AI团队构建了完整的数据清洗系统和工具包,用于选择更高质量的数据进行持续的预训练。
下图展示了Colossal-AI团队完整的数据治理流程:
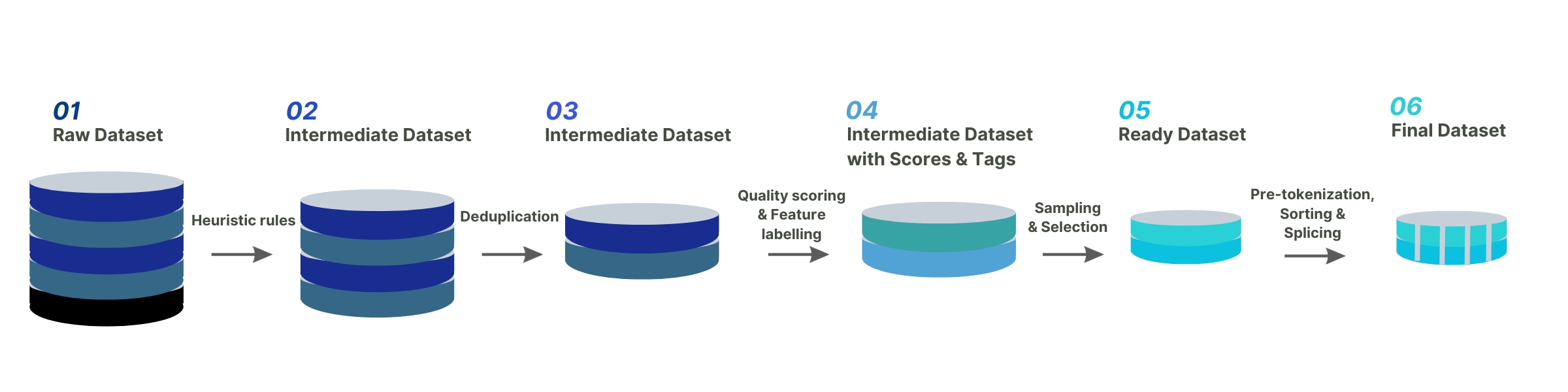
除了对数据进行启发式选择和去重之外,还对关键数据进行评分和分类过滤。合适的数据对于激发 LLaMA-2 的中文能力发挥着至关重要的作用,同时克服了英文的灾难性遗忘问题。
最后,为了提高同一主题数据的训练效率,Colossal-AI团队对数据进行了长度排序,并按照最大长度4096进行拼接。
培训策略
多阶段训练
训练方面,针对持续预训练的特点,Colossal-AI团队设计了多阶段、分层的持续预训练方案,将训练过程分为三个阶段:

- 大规模预训练阶段:该阶段的目标是通过大量语料的训练,使模型能够产生相对流畅的文本。这一阶段由 LLaMA-2 完成。经过这个阶段,模型已经掌握了大量的英语知识,并且可以基于 Next Token Prediction 产生平滑的结果。
- 中文知识注入阶段:该阶段依赖于高质量的中文知识。一方面增强了模型对中文知识的掌握,另一方面提高了模型对中文词汇中新增词语的理解。
- 相关知识重播阶段:该阶段致力于增强模型对知识的理解和泛化能力,缓解灾难性遗忘问题。
多阶段方法相辅相成,最终确保模型在中文和英语能力上平等进步。
Bucket Training
持续预训练对数据分布极为敏感,因此平衡尤为重要。为了保证数据的均衡分布,Colossal-AI团队设计了数据分桶策略,将同一类型的数据分为10个不同的分桶。在训练过程中,每个数据桶包含每种类型的数据一个bin,从而保证每种类型的数据都能被模型均匀地利用。
评价体系
为了更好地评估模型的性能,Colossal-AI团队构建了一套完整的评估系统——ColossalEval,从多个维度评估大型语言模型。流程框架和代码完全开源,支持结果复现,也允许用户根据应用场景定制数据集和评估方法。评估框架的特点总结如下:
- 包含评估大型语言模型知识储备能力的常用数据集,如MMLU、CMMLU等。对于选择题、ABCD概率比较等格式,增加了更全面的计算方法,如绝对匹配、单选等困惑度等。目的是更彻底地衡量模型对知识的掌握程度。
- 支持多项选择题和长文本评估的评估。
- 支持多轮对话、角色扮演、信息提取、内容生成等不同应用场景的评估方式,用户可以根据自己的具体需求选择性地评估模型不同方面的能力。此外,系统还支持自定义提示和评估方法的扩展,以满足个人喜好和要求。
从通用大型模型到特定领域大型模型的桥梁
从Colossal-AI团队的经验来看,构建中国版LLaMA-2可以概括为以下流程:
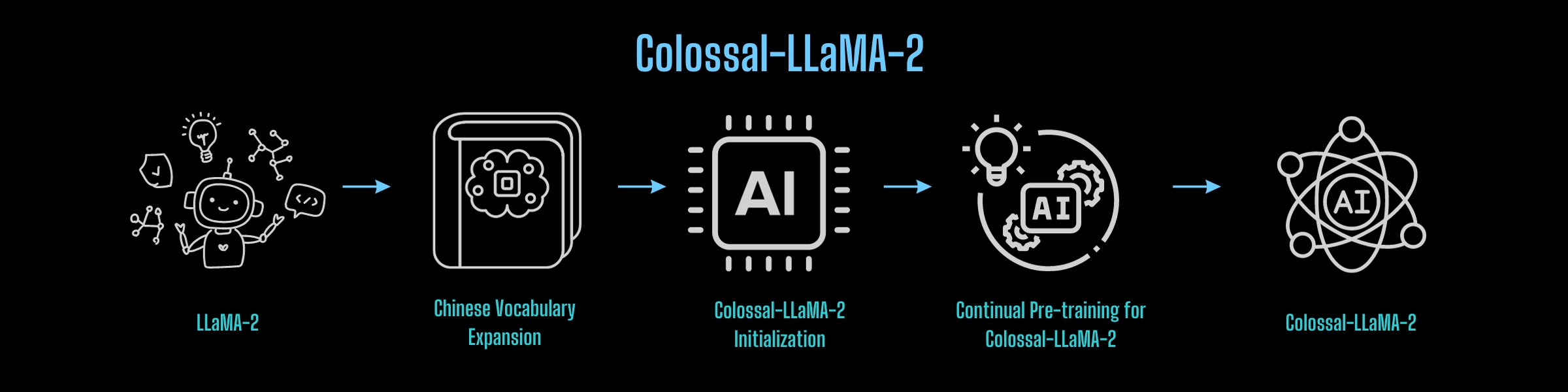
那么,这个流程可以重用吗?
答案是肯定的,并且在实际实施场景中具有重要意义。
随着ChatGPT带动的人工智能浪潮兴起,各大互联网巨头、人工智能公司、初创公司、大学、研究机构等都在积极参与大型通用模型的竞赛。然而,这些大型模型的通用性背后往往缺乏特定领域的知识。因此,实际应用的问题变得尤为严重。虽然针对特定应用程序的微调可以带来一些好处,但缺乏特定于领域的大型模型会在应用程序部署中造成性能瓶颈。
如果能够快速且经济高效地构建特定领域的大型模型,然后针对特定业务需求进行微调,无疑将推进应用程序的部署,提供竞争优势。
应用上述过程在任何领域执行知识转移,可以经济高效地构建轻量级特定领域基础大型模型:
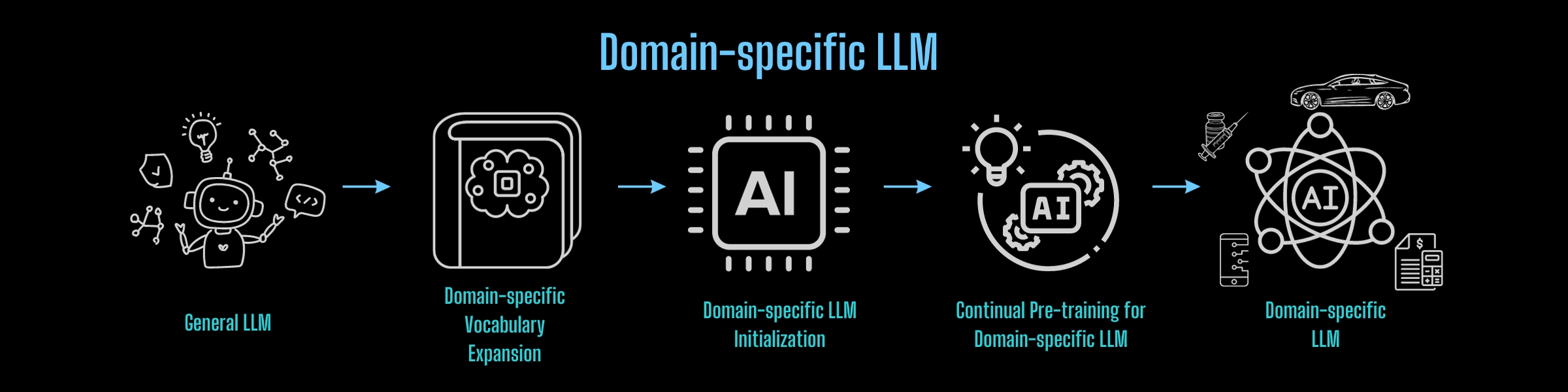
从头开始构建基础大模型,也可以从上述经验和Colossal-AI的降本增效能力中得到启发,以最小的成本高效地实现这一目标。
系统优化
Colossal-LLaMA-2令人印象深刻的性能和成本优势建立在低成本AI大模型开发系统Colossal-AI的基础上。
Colossal-AI基于PyTorch,利用高效的多维并行、异构内存等技术,降低AI大模型训练、微调和推理的开发和部署成本。它增强了模型任务性能,降低了 GPU 要求等等。在短短一年多的时间里,它在开源社区中获得了超过 30,000 名 GitHub star。在大型模型开发工具和社区领域排名全球第一,与众多世界500强等知名企业合作,开发/优化千亿、百亿参数模型,创建特定领域的模型楷模。
庞大的AI云平台
为了进一步提升大模型开发和部署的效率,Colossal-AI已升级为Colossal-AI云平台。该平台允许用户通过低代码/无代码的方法在云端低成本地训练、微调和部署大型模型,同时快速集成模型以实现个性化应用。
 目前,Colossal-AI云平台预装了Stable扩散、LLaMA-2等主流模型和解决方案。用户只需要上传自己的数据进行微调,并且可以将微调后的模型以API的形式部署。
目前,Colossal-AI云平台预装了Stable扩散、LLaMA-2等主流模型和解决方案。用户只需要上传自己的数据进行微调,并且可以将微调后的模型以API的形式部署。

