
- 1如何发布Android库到Maven中心仓库_repository oss.sonatype.org
- 2docker-compose安装部署kafka_docker-compose安装kafka
- 3c++ string类的常用方法_OpenCV常用图像拼接方法(四):基于Stitcher类拼接
- 4layer mobile使用方法_layui mobile
- 5体验了下科大讯飞星火模型的新功能,被惊艳到了!
- 6Vision Transformer鸟类图像分类:数据和代码分享_python鸟类图像分类
- 7Unity-Timeline制作动画(快来制作属于你的动画吧)_unity timeline 怎么启动动画
- 8全国职业技能大赛云计算赛项---Linux系统调优案例_oslo.messaging._drivers.impl_rabbit oserror: [errn
- 9无伤理解阻抗控制:机械臂的阻抗、导纳控制(间接力控):第一篇 思想源泉_机械臂阻抗
- 10UX与UI设计的区别及编程实践_uxjuc
数据结构——堆(C语言实现)_c语言堆
赞
踩
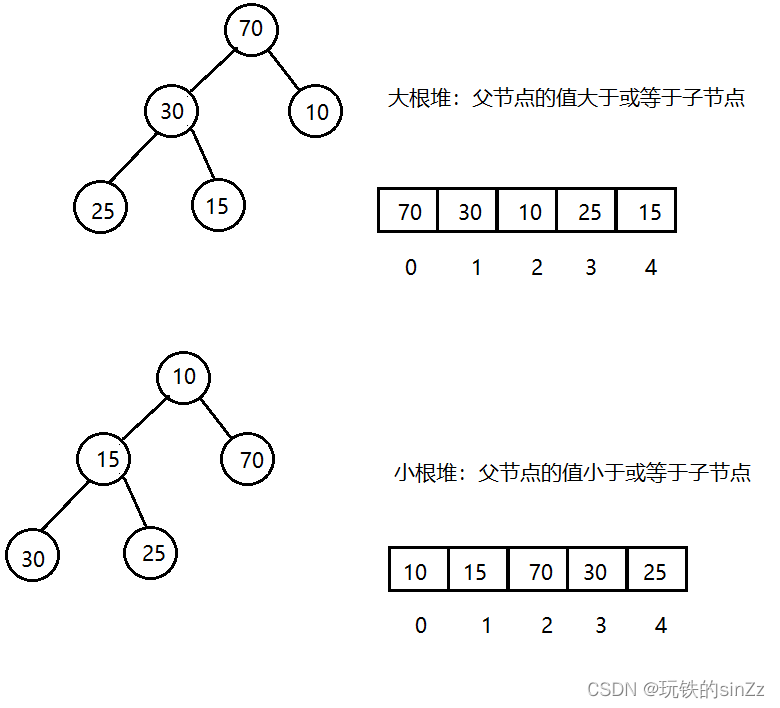
什么是堆
堆是一种特殊的数据结构,它是一棵完全二叉树,同时满足堆属性,即父节点的值总是大于或小于其子节点的值。如果父节点的值总是大于子节点的值,那么我们称之为大根堆;反之,如果父节点的值总是小于子节点的值,那么我们称之为小根堆。在堆中,根节点的值最大(大根堆)或最小(小根堆),因此它也被称为堆顶。堆经常用于排序、topK问题等场景。
堆的实现
本篇文章使用c语言实现并以头文件和源文件分离的形式,也会逐步介绍各个接口的实现思路以及提供参考代码。
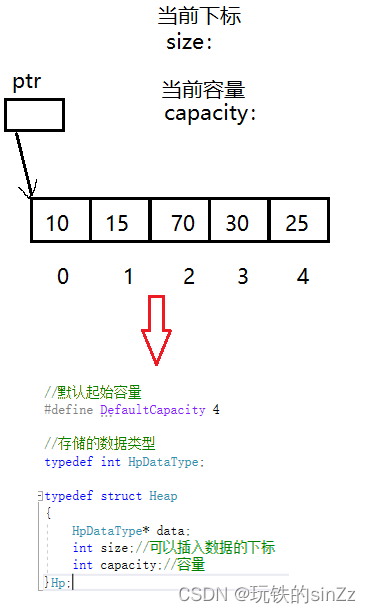
堆的结构定义
堆的结构定义其实是一个特殊的顺序表,这点和栈类似。所以,需要用一个指针指向动态开辟的内存,需要一个指向当前下标位置的变量,以及需要一个记录当前动态内存的容量。
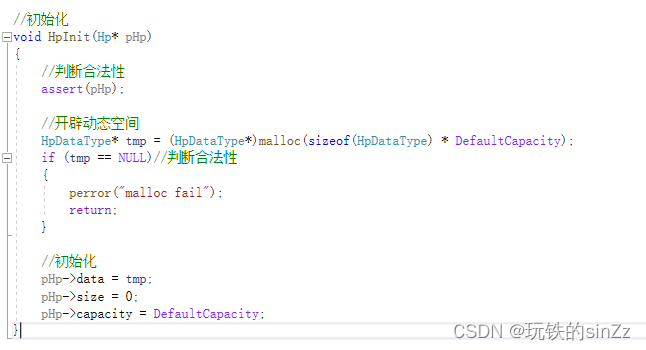
堆的初始化接口
堆初始化接口实现思路如下,首先,改变一个堆,我们需要传它的地址。所以参数部分需要写成Hp*。在接口的一开始先判断指针的合法性。然后开辟动态内存,判断一下动态内存的有效性。最后,初始化结构体成员即可。
堆的销毁接口
释放动态申请的空间,free后及时置空的好习惯是我们应该要养成的。最后将size和capacity置零即可。

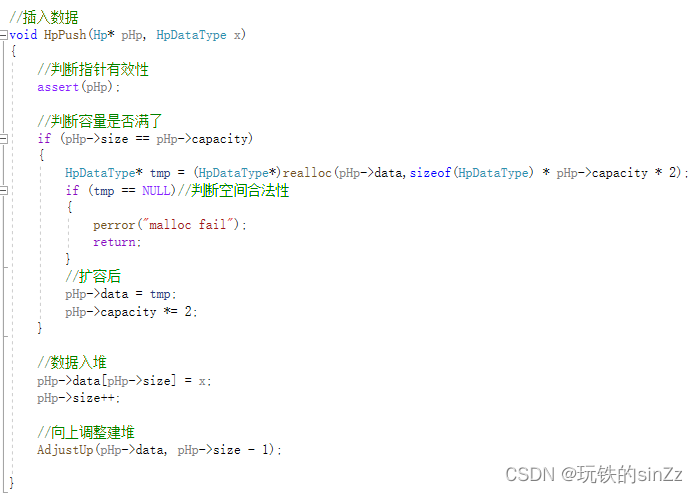
堆的插入数据接口
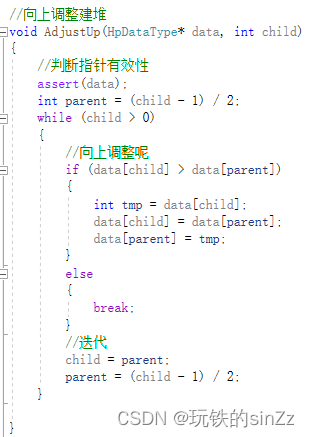
堆的插入接口实现思路如下,assert判断指针有效性,这是一个好的编程习惯,建议大家平时也养成这种习惯。首先判断容量是否满了,满了的话就扩容。然后直接下面的插入数据逻辑,其实就是类似于顺序表。直接将数据插入size下标的位置,++size即可。最后调用向上调整建堆接口,使堆的结构不变。
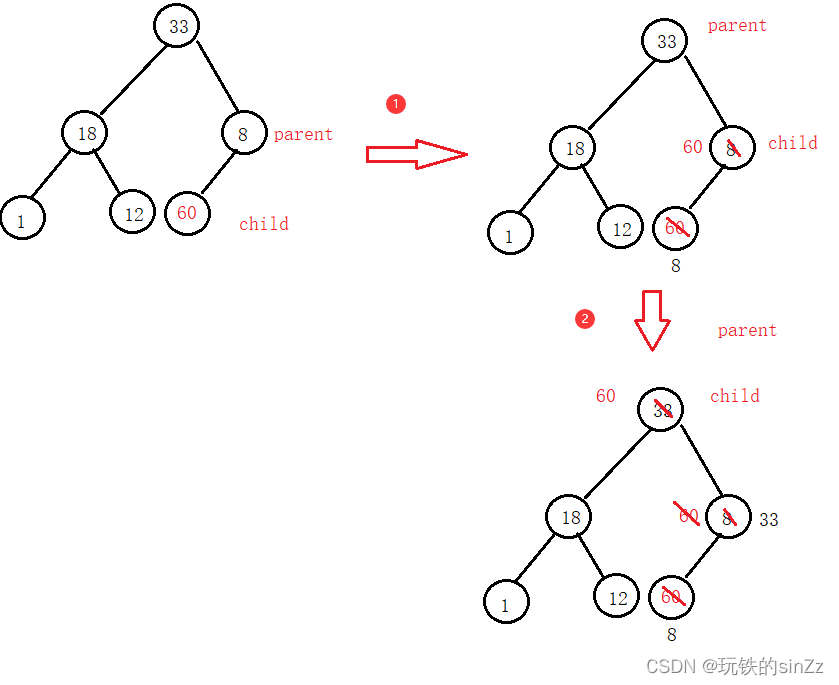
向上调整建堆接口
首先要根据孩子的下标位置,推断出父节点的下标位置。然后开始向上调整,向上调整的过程是一个循环的过程,循环的迭代条件就是当child大于根节点下标就继续支持循环。当子节点小于父节点循环终止。若父节点小于子节点那么进行对应下标的数据交换,然后迭代子节点下标和父节点下标即可。
判断堆是否为空
判断堆是否为空接口思路相对简单,类似于顺序表的判空思路,当下一个可以插入数据的下标为0时,表示为空堆。

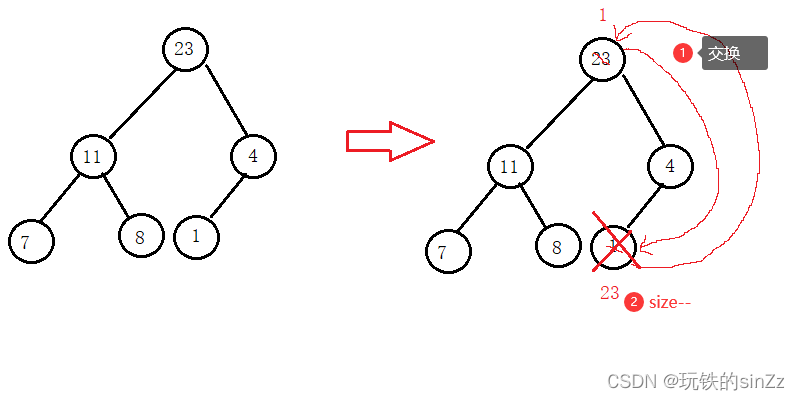
堆的删除数据接口
要删除堆的数据,是删除堆的堆顶数据还是堆底数据呢?答案是删除堆顶的数据,因为删除堆底的数据没有什么价值。而删除堆顶可以产生一些价值,如排序或者对一些前排名K个的数据进行收集等。举个例子,当我们在购物app想选一个电脑,我们可以按照销量进行排序这也是堆应用的一个场景。回到正题,删除堆顶的实现思路如下,我们让堆顶数据和最后一个数据交换,然后让size–,达到删除堆顶数据的效果,并且大大提升了效率。最后向下调整建堆即可。

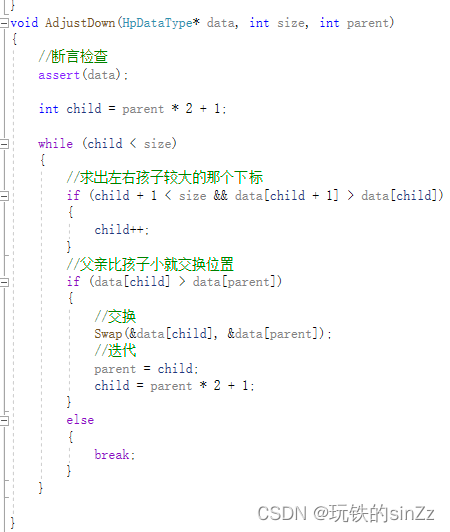
向下调整建堆接口
向下调整建堆实现思路如下,首先,向下调整的过程是一个循环,它的终止条件为parent > size。循环体内部就是向下调整的核心思路,parent跟左右孩子较大的(较小的)比,本文以实现大堆为例。这里要介绍一个比较重要的概念,由于堆的底层使用顺序表存储,所以同一个父亲的左孩子右孩子是相邻存储的。即左孩子下标+1就是右孩子下标。让父亲和左右孩子较大的那一个比较,如果父亲小于孩子就交换位置,然后迭代。注意:向下调整的条件是左右子树必须是堆。
获取堆顶数据
其实,就是访问顺序表的第一个元素。但是,这样提供一个接口是非常符合接口的一致性以及对于代码的可读性有极大的提升的。

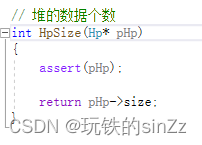
获取堆的有效数据个数
由于我们的size是从0开始,所以直接return size即可。
完整实现代码
//Heap.h文件 #include<stdio.h> #include<stdlib.h> #include<assert.h> #include<stdbool.h> //默认起始容量 #define DefaultCapacity 4 //存储的数据类型 typedef int HpDataType; typedef struct Heap { HpDataType* data; int size;//可以插入数据的下标 int capacity;//容量 }Hp; //初始化 void HpInit(Hp* pHp); //堆的销毁 void HpDestroy(Hp* pHp); //插入数据 void HpPush(Hp* pHp, HpDataType x); //向上调整建堆 void AdjustUp(HpDataType* data, int child); //判断是否为空 bool HpEmpty(Hp* pHp); //删除数据 void HpPop(Hp* pHp); //向下调整建堆 void AdjustDown(HpDataType* data,int size, int parent); // 取堆顶的数据 HpDataType HpTop(Hp* pHp); // 堆的数据个数 int HpSize(Hp* pHp);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
// Heap.c文件 #include"Heap.h" //初始化 void HpInit(Hp* pHp) { //判断合法性 assert(pHp); //开辟动态空间 HpDataType* tmp = (HpDataType*)malloc(sizeof(HpDataType) * DefaultCapacity); if (tmp == NULL)//判断合法性 { perror("malloc fail"); return; } //初始化 pHp->data = tmp; pHp->size = 0; pHp->capacity = DefaultCapacity; } //堆的销毁 void HpDestroy(Hp* pHp) { //判断合法性 assert(pHp); //释放内存和清理 free(pHp->data); pHp->data = NULL; pHp->size = pHp->capacity = 0; } void Swap(HpDataType* p1, HpDataType* p2) { HpDataType tmp = *p1; *p1 = *p2; *p2 = tmp; } //向上调整建堆 void AdjustUp(HpDataType* data, int child) { //判断指针有效性 assert(data); int parent = (child - 1) / 2; while (child > 0) { //向上调整呢 if (data[child] > data[parent]) { Swap(&data[child], &data[parent]); } else { break; } //迭代 child = parent; parent = (child - 1) / 2; } } //插入数据 void HpPush(Hp* pHp, HpDataType x) { //判断指针有效性 assert(pHp); //判断容量是否满了 if (pHp->size == pHp->capacity) { HpDataType* tmp = (HpDataType*)realloc(pHp->data,sizeof(HpDataType) * pHp->capacity * 2); if (tmp == NULL)//判断空间合法性 { perror("malloc fail"); return; } //扩容后 pHp->data = tmp; pHp->capacity *= 2; } //数据入堆 pHp->data[pHp->size] = x; pHp->size++; //向上调整建堆 AdjustUp(pHp->data, pHp->size - 1); } void AdjustDown(HpDataType* data, int size, int parent) { //断言检查 assert(data); int child = parent * 2 + 1; while (child < size) { //求出左右孩子较大的那个下标 if (child + 1 < size && data[child + 1] > data[child]) { child++; } //父亲比孩子小就交换位置 if (data[child] > data[parent]) { //交换 Swap(&data[child], &data[parent]); //迭代 parent = child; child = parent * 2 + 1; } else { break; } } } void HpPop(Hp* pHp) { //断言检查 assert(pHp); //删除数据 Swap(&pHp->data[0], &pHp->data[pHp->size-1]); pHp->size--; //向下调整建堆 AdjustDown(pHp->data,pHp->size-1,0); } //判断是否为空 bool HpEmpty(Hp* pHp) { assert(pHp); return pHp->size == 0; } // 取堆顶的数据 HpDataType HpTop(Hp* pHp) { assert(pHp); return pHp->data[0]; } // 堆的数据个数 int HpSize(Hp* pHp) { assert(pHp); return pHp->size; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
小结
操作堆这种数据结构就像吃老婆饼,你吃的是香甜的饼,至于是不是你老婆做的那就不一定了。但是,你在吃的时候想像成你老婆做的饼吃起来也别有一番风味。堆在逻辑结构上你操作的是一颗树,在底层的存储上又是一个顺序表。这就比较抽象的地方,需要考验我们画图以及走读代码调试的能力。
堆排序
堆排序其实就是堆这个数据结构的一种常见的使用方式。堆排序的核心思想就是利用堆删除的思想来进行排序操作。堆排序是一种时间复杂度O(N*logN)的不稳定排序。至于排序的稳定性的讲解在后面的博客会给大家介绍。
堆排序的实现
堆排序的实现思路如下,首先确定排序的顺序并将数据建成堆,升序建大堆,降序建小堆。建堆的话建议使用向下调整建堆。因为时间复杂度为O(logN),若使用向上调整建堆,那么时间复杂度为O(N*logN)。这样的时间复杂度对于找出堆顶数据的损耗太大,还不如直接遍历一遍(时间复杂度)。

接着是利用堆删除的思想进行排序。下面就以排升序为例。
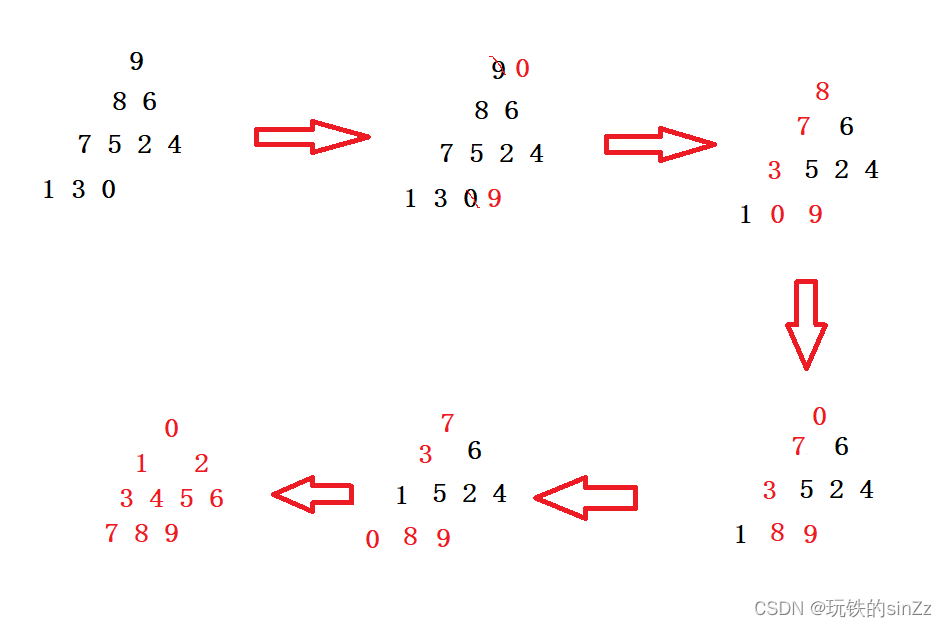
//堆排序--排升序建大堆 void HeapSort(int* arr, int n) { //向下建堆,效率更高 for (int i = (n - 1 - 1) / 2; i >= 0; --i) { AdjustDown(arr,n-1,i); } //排序 //利用堆删除的思想进行排序 int end = n - 1; while (end > 0) { //交换 int tmp = arr[0]; arr[0] = arr[end]; arr[end] = tmp; //调整堆 AdjustDown(arr, end-1, 0); end--; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
关于建堆和堆排序时间复杂度的分析
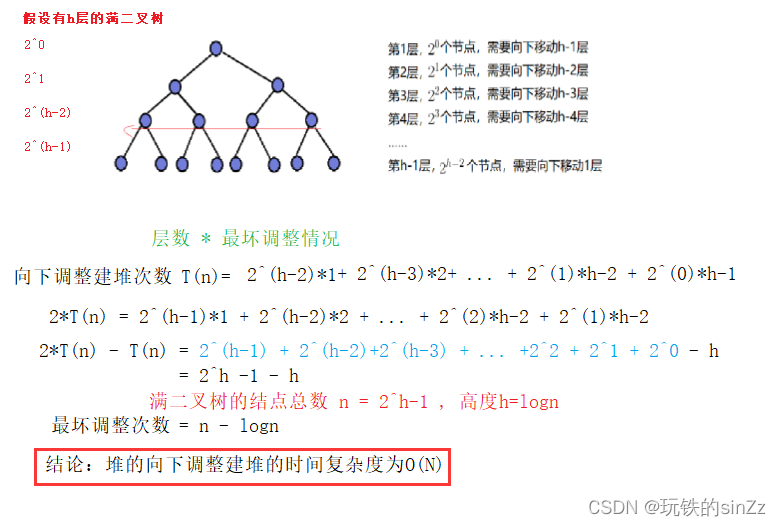
向下调整建堆
在前面的堆排序实现中,提到向下调整建堆的效率更高,这是因为向下调整建堆的时间复杂度是O(N)。下面我就带领大家简单分析一下向下调整建堆的时间复杂度。
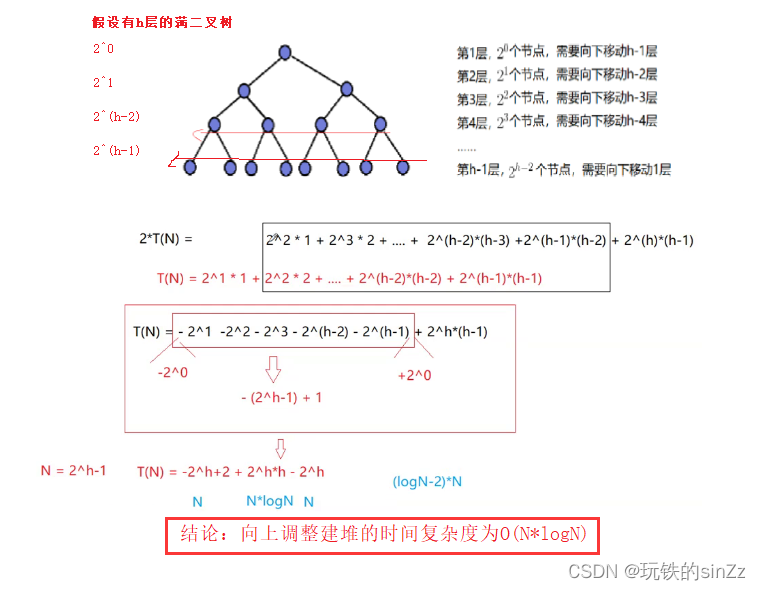
向上调整建堆
向上调整建堆的时间复杂度为O(N*logN)。下面请看向上调整的时间复杂度问题。
堆排序
堆排序的时间复杂度为O(NlogN)。向下调整建堆的复杂度为O(N),要排序的个数为N-1趟,可以算作O(N),交换完后的向下调整建堆的时间复杂度为O(LogN),所以对排序的时间复杂度为O(2NLogN)。

小结
上面介绍的建堆时间复杂度和堆排序复杂度,记个结论其实就可以了。当然,从实现的角度上也不难分析出向上调整建堆和向下调整建堆的大致效率上的差距。因为向下调整从第一个非叶子结点开始调整,最坏的情况下也要比向上调整少调整一半的结点。这在效率上已经胜出不少了。
TOPK问题的介绍
TOPK问题是指在一组数据中,找出前K个最大或最小的数据的问题,常见的解决方法包括堆排序、快速排序、归并排序等。该问题在数据分析、机器学习等领域中经常出现。当然有一种特殊场景下用堆进行TOK的筛选非常的妙。假设现在有100亿个整数,要求出前50个数,我们可以建一个小堆,只要遍历的数据比堆顶数据大就替代它进堆(向下调整),最终就可以得到最大的前五十个数。下面用一个样例简单感受一下。
void AdjustDownSH(HpDataType* data, int size, int parent) { //断言检查 assert(data); int child = parent * 2 + 1; while (child < size) { //求出左右孩子较大的那个下标 if (child + 1 < size && data[child + 1] < data[child]) { child++; } //父亲比孩子小就交换位置 if (data[child] < data[parent]) { //交换 Swap(&data[child], &data[parent]); //迭代 parent = child; child = parent * 2 + 1; } else { break; } } } void PrintTopK(const char* file, int k) { // 1. 建堆--用a中前k个元素建小堆 int* topk = (int*)malloc(sizeof(int) * k); assert(topk); FILE* fout = fopen(file, "r"); if (fout == NULL) { perror("fopen error"); return; } // 读出前k个数据建小堆 for (int i = 0; i < k; ++i) { fscanf(fout, "%d", &topk[i]); } for (int i = (k - 2) / 2; i >= 0; --i) { AdjustDownSH(topk, k, i); } // 2. 将剩余n-k个元素依次与堆顶元素交换,不满则则替换 int val = 0; int ret = fscanf(fout, "%d", &val); while (ret != EOF) { if (val > topk[0]) { topk[0] = val; AdjustDownSH(topk, k, 0); } ret = fscanf(fout, "%d", &val); } for (int i = 0; i < k; i++) { printf("%d ", topk[i]); } printf("\n"); free(topk); fclose(fout); } void CreateNDate() { // 造数据 int n = 10000; srand(time(0)); const char* file = "data.txt"; FILE* fin = fopen(file, "w"); if (fin == NULL) { perror("fopen error"); return; } for (size_t i = 0; i < n; ++i) { int x = rand() % 10000; fprintf(fin, "%d\n", x); } fclose(fin); } int main() { CreateNDate(); PrintTopK("data.txt", 10); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108

