
- 1【Git】切换分支【2024年2月19日】
- 2Unity导出工程到Android Studio(export project to android studio)_unity3d导出安卓工程到android studio
- 3【面试必读(编程基础)】OpenGL ES 2.0渲染管线_open gl 面试 常用问题
- 4UnityUI相机的创建_unity怎么制作uicamera
- 5怎样选中行复制_Axure 教程 | 列表选中项求合计值
- 6IDEA教程之Changelist_idea changelist
- 710-OpenFeign-实现异步调用
- 8Atlassian系列产品及插件注册方法[JIRA8.19.0+]_atlassian-agent.jar
- 9基于Springboot高校学校教室实验室房间预约系统设计与实现 开题报告参考
- 102402com,com管理引用计数的规则
CNN(卷积神经网络)工作原理详解_卷积神经网络的视觉识别运作机制
赞
踩
CNN(卷积神经网络)
前言、
用夹逼定理说,前馈神经网络(也称为神经元的多层网络)可以作为强大的逼近来学习输入和输出之间的非线性关系。但是前馈神经网络的问题在于,由于网络中存在许多要学习的参数,因此网络易于过度拟合。
我们是否可以拥有另一种类型的神经网络,它可以学习复杂的非线性关系但参数较少,因此容易出现过度拟合的情况?卷积神经网络(CNN)是另一种神经网络,可用于使机器可视化事物并执行诸如图像分类,图像识别,对象检测,实例分割等任务……这是CNN最常见的领域用过的。
2D卷积运算

如上图所示,我将图像视为只有一个颜色通道的灰度图像。想象一下上面图像中的每个像素都是相机拍摄的读数。如果我们要重新估计任何像素的值,则可以取其相邻像素的值并计算这些相邻像素的加权平均值,以获得重新估计的值。此操作的数学公式由下式给出:
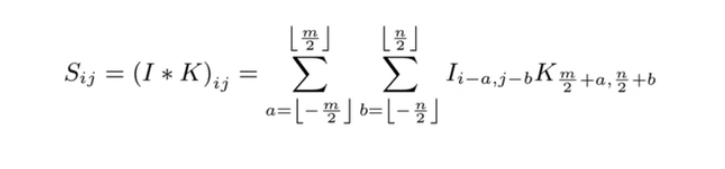
其中,
K —代表分配给像素值的权重的矩阵。它具有两个索引a,b-a表示行,b表示列。
I —包含输入像素值的矩阵。
Sᵢⱼ—某个位置像素的重新估计值。
举例
我们有一个泰姬陵的图片和3x3的矩阵(过滤器)。在卷积运算中,我们将过滤器加在图像上,使图片的像素将与过滤器的中心对齐,然后我们将计算所有邻域像素的加权平均值。然后,我们将过滤器从左向右滑动,直到它经过整个宽度,然后再从上到下,以计算图像中所有像素的加权平均值。
影像模糊
考虑到我们将使用3x3矩阵(过滤器)重新估计图像中的像素值。我们这样做的方法是系统地检查图像中存在的每个像素,然后将过滤器放置在该像素位于图片中心的位置。然后,将该像素的值重新估计为其所有邻居的加权总和。

在此操作中,我们平均取9个邻居,包括像素本身。因此,结果图像将变得模糊或变平滑。
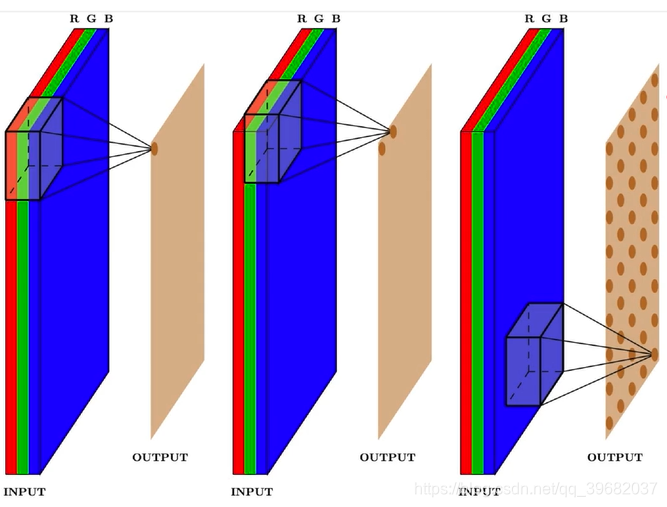
3通道(RGB)的2D卷积
在3通道输入的情况下如何进行卷积运算?
到目前为止,由于3个输入通道(红色,绿色和蓝色(RGB)),我们看到的任何图像都是3通道图像。在3通道图像中,每个像素将具有3个值,分别具有红色,绿色和蓝色颜色值的通道。在3通道输入中,我们将使用3个过滤器,这意味着图像的通道数和过滤器相同。

与2D卷积操作类似,我们将在水平方向上滑动过滤器。每次移动过滤器时,我们都将获取整个图片三个通道的加权平均值,即RGB值的加权邻域。由于我们仅在两个维度上滑动内核-从左到右,从上到下,此操作的输出将是2D输出。
我们可以对同一张图片应用多个过滤器吗?
实际上,代替应用一个过滤器,我们可以在同一张图像上一个接一个地应用具有不同值的多个过滤器,以便获得多个输出。

所有这些输出可以堆叠在一起,形成一个体积。如果在输入上应用三个过滤器,我们将得到3个通道的输出。
如何计算输出尺寸?
假设我们有大小为7x7的2D输入,并且正在从图像的左上角开始在图像上应用3x3的滤镜。当我们从左到右,从上到下在图像上滑动内核时,很明显,输出小于输入,即5x5。

为什么输出较小?
由于我们不能将过滤器放在角落,因为它会越过输入边界。图像外的那些像素的值是不确定的,因此我们不知道如何计算该区域中像素的加权平均值。
对于输入中的每个像素,我们不会计算加权平均值并重新估计像素值。对于图像中存在的所有阴影像素(至少使用3x3矩阵)都是如此,因此输出的大小将减小。此操作称为有效填充。

如果我们希望输出与输入大小相同怎么办?
如果原始输入的大小为7x7,我们也希望输出大小为7x7。因此,在那种情况下,我们可以做的是在输入周围均匀添加一个人工填充点(零),这样我们就可以将过滤器K(3x3)放置在图像像素点上,并计算邻居的加权平均值。
通过在输入周围添加一圈(零)这种人工填充,我们可以将输出的形状与输入保持相同。如果我们有一个更大的过滤器K(5x5),那么我们需要应用零填充的数量也会增加,这样我们就可以保持相同的输出大小。在此过程中,输出的大小与输出的大小相同,因此命名为Same Padding。
计算输出尺寸
我们以一定的间隔从左向右滑动内核(过滤器),直到它通过图像的宽度为止。然后,我们从上到下滑动,直到整个图像横向。步幅 (S)定义了应用过滤器的间隔。通过选择大于1的步幅(间隔),当我们计算邻居的加权平均值时,我们跳过了几个像素。跨度越高,输出图像的尺寸越小。
公式:

卷积神经网络
我们如何到达卷积神经网络?
过去我们进行图像分类的任务,我们需要将给定图像分类为一个类。实现此目的的较早方法是将图像展平,即…将30x30x3的图像平展为2700的向量,并将该向量输入到任何机器学习分类器(如SVM,Naive Bayes等)中……该方法的主要要点是正在将原始像素作为机器学习算法的输入,并为图像分类学习分类器的参数。

之后,人们开始意识到并非图像中存在的所有信息对于图像分类都是重要的。在这种方法中,不是通过将原始像素传递到分类器中,而是通过应用一些预定义或手工制作的过滤器(例如,在图像上应用边缘检测器滤镜)对图像进行预处理,然后将预处理的表示传递给分类器。
一旦特征工程(对图像进行预处理)开始提供更好的结果,就会开发出改进的算法,例如SIFT / HOG,以生成图像的精确表示。这些方法生成的特征表示是静态的,即使生成表示不涉及任何学习,所有学习都推送到了分类器。

而不是手动生成图像的特征表示。为什么不将图像展平为2700x1的矢量,然后将其传递到前馈神经网络或神经元多层网络(MLN),以便该网络也可以学习特征表示?
与诸如SIFT / HOG,边缘检测器之类的静态方法不同,我们并未确定权重,但允许网络通过反向传播进行学习,从而降低了网络的总体损耗。前馈神经网络可以学习图像的单个特征表示,但是在复杂图像的情况下,神经网络将无法给出更好的预测,因为它无法学习图像中存在的像素依存关系。

卷积神经网络可以通过应用不同的过滤器变换来学习图像的多层特征表示,从而可以保留图像中存在的时空像素依存性。在CNN中,由于稀疏的连接性和网络中的权重共享使CNN的传输速度更快,网络要学习的参数数量大大低于MLN。
稀疏连接和权重共享

考虑到我们正在执行数字识别的任务,我们的输入是16像素。在前馈神经网络的情况下,存在于输入/隐藏层中的每个神经元都连接到前一层的所有输出,即……它取与该神经元相连的所有输入的加权平均值。

在卷积神经网络中,通过将内核叠加在图像上,我们一次只考虑几个输入来计算所选像素输入的加权平均值。输出h 1是使用稀疏连接而不是考虑所有连接来计算的。

请记住,当我们尝试计算输出h 11时,我们仅考虑了4个输入,并且类似地考虑了输出h similar 2。需要注意的重要一点是,我们使用相同的2x2内核来计算h 1和h 12,即…使用相同的权重来计算输出。与前馈神经网络不同,在前馈神经网络中,存在于隐藏层中的每个神经元将为其自身分配不同的权重。这种在输入端利用相同权重来计算加权平均值的现象称为权重共享。
池化层

考虑我们有一个长度,宽度和深度为3个通道的输入体积。当我们将相同深度的过滤器应用于输入时,我们将获得2D输出,也称为输入的特征图。一旦获得了特征图,通常我们将执行一个称为Pooling operation的操作。由于学习图像中存在的复杂关系所需的隐藏层数将很大。我们应用池化操作来减少输入特征的表示,从而降低网络所需的计算能力。
一旦获得输入的特征图,我们将在特征图上应用确定形状的过滤器,以从特征图的该部分获得最大值。这称为最大池化。这也称为子采样,因为从内核覆盖的特征图的整个部分中,我们正在对一个最大值进行采样。
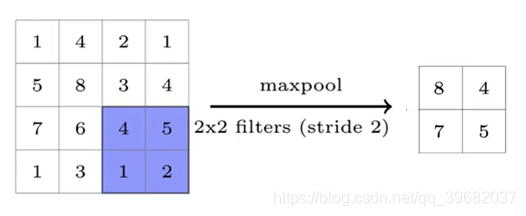
与“最大池化”相似,“ 平均池化”计算内核覆盖的特征图的平均值。
全连接层
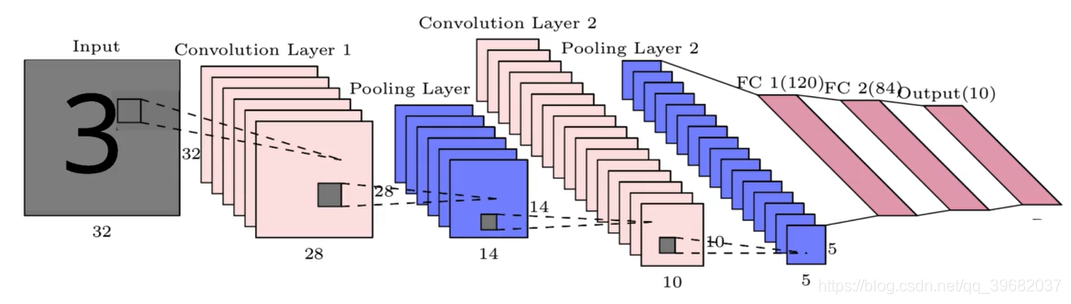
一旦我们对图像的特征表示进行了一系列的卷积和合并操作(最大合并或平均合并)。我们将最终池化层的输出展平为一个向量,并将其通过具有不同数量隐藏层的全连接层(前馈神经网络)传递,以了解特征表示所存在的非线性复杂性。
最后,完全连接层的输出将通过所需大小的Softmax层。Softmax层输出概率分布的向量,这有助于执行图像分类任务。在数字识别器问题(如上所示)中,输出softmax层具有10个神经元,可将输入分类为10个类别之一(0–9个数字)。

