
- 1黑马程序员---微服务笔记【实用篇】_黑马程序员微服务命名空间
- 2tensorflow-gpu1.14.0安装全过程_tensorflow1.14安装
- 3中国电子学会2022年12月份青少年软件编程Scratch图形化等级考试试卷四级真题(含答案)_运行下列程序,变量“结果”的值为?
- 42023年快要结束了,今年哪些计算机书值得推荐?
- 5Stable Diffusion 图生图-蒙版重绘,Controlnet未生效的一个场景_stablediffusion局部重绘没反应
- 6赵旭计算机论文,上海交通大学赵旭教授团队在计算机视觉顶级期刊上发表最新研究成果...
- 7N1盒子刷Armbian安装CUPS共享惠普1020为网络打印机【更新】_how to install brother printer in armbian
- 8全面整理!机器学习常用的回归预测模型
- 9npm之报错:npm WARN deprecated @npmcli/move-file@2.0.1(一百五十九)_npm warn deprecated @npmcli/move-file@2.0.1: this
- 10程序员为什么不喜欢关电脑:揭秘背后的原因_程序员们似乎从不关电脑
9种常用排序算法总结(超详细)_排名存储算法
赞
踩
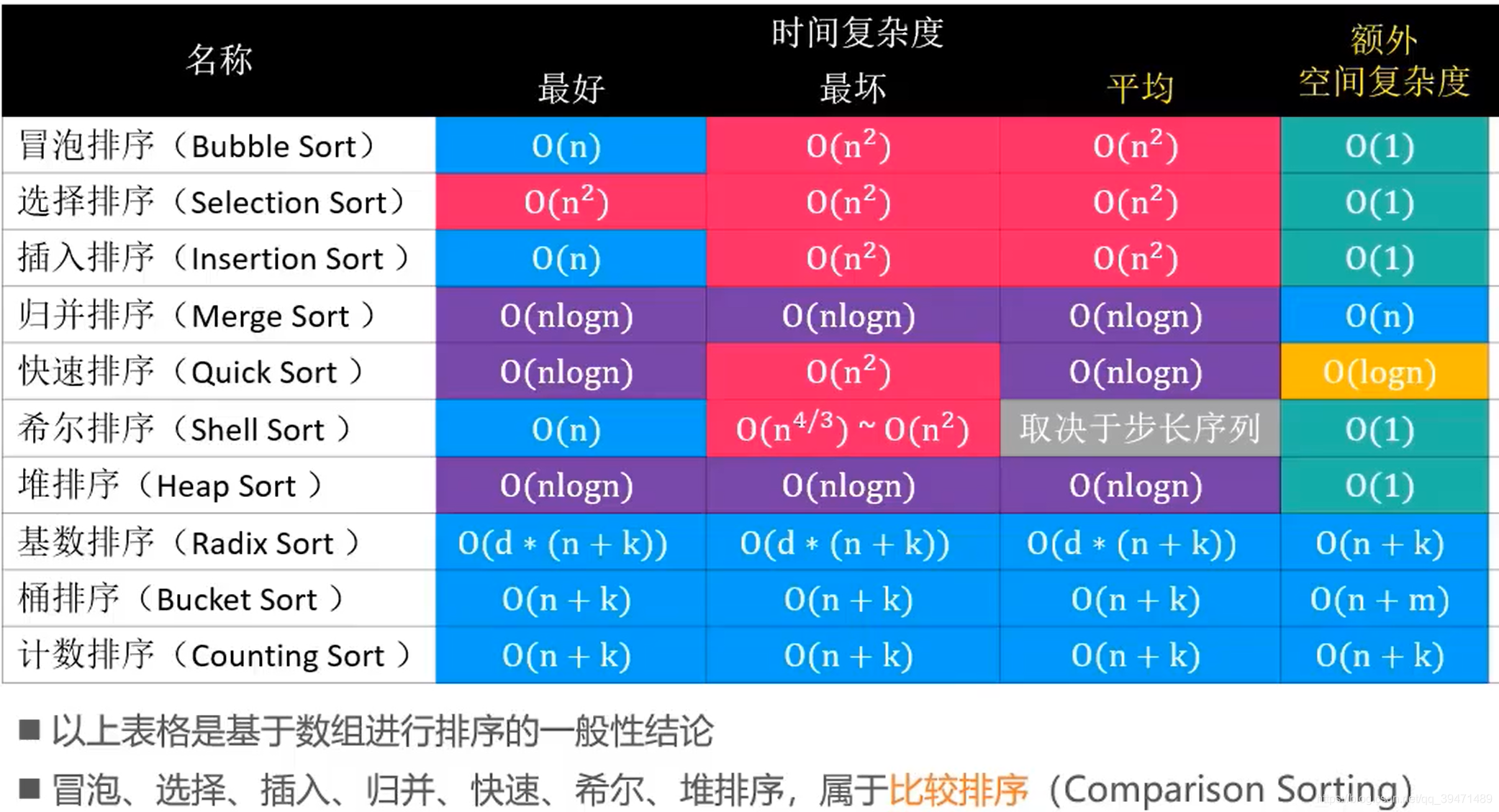
以int型数据为例,且0号下标数组用来做为交换辅助空间,数据从1号下标开始存储
一、插入排序
基本思想:每一趟将一个待排序的记录,按其关键字的大小插入到已经排好序的一组记录的适当位置上,直到全部待排序记录全部插入为止。
直接插入排序
排序过程:
1、将待排序数组arr[1…n]看作两个集合,arr[1]为有序集合中元素,arr[2…n]为无序集合中元素,a[0]用来临时存放当前待排序记录
2、外层循环每次从无序集合中选择一个待插入元素(n-1次),每次使用顺序查找法,内层循环查找arr[i]在有序集合中的位置(将有序集合中大于待插入元素的记录后移一位)
//直接插入排序
void Insert_Sort(int *arr,int n){
int j = 0;
for(int i = 2; i <= n; ++i){
if(arr[i] < arr[i-1]){
arr[0] = arr[i];
arr[i] = arr[i-1];
for(j = i-2; arr[0] < arr[j];--j)//a[0]既可以存放当前待排序记录,也可当作哨兵防止越界
arr[j+1] = arr[j];
arr[j+1] = arr[0];
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
时间复杂度:
最好情况下(待排序记录递增有序),总的比较次数为n-1次,记录不需要移动。
最坏情况下(待排序记录递减有序),总的比较次数和移动次数均为n^2 / 2 。
平均情况下,比较次数和移动次数都为n^2 / 4
空间复杂度:
只需要一个辅助空间arr[0],因此空间复杂度为O(1)
算法特点:
1、稳定排序
2、适用于顺序存储结构和链式存储结构
3、适用于初始记录基本有序的情况,当初始记录无序,n较大时,此算法时间复杂度较高,不宜采用
折半插入排序
基本思想同直接插入排序,不同点在于,在有序集合中搜索插入位置时折半插入采用二分搜索,可以有效的减少比较次数。
//折半直接插入排序 void BInsert_Sort(int arr[],int n){ int high , low , mid , j; for(int i = 2; i <= n; ++i){ arr[0] = arr[i]; low = 1 ; high = i-1; while(low <= high){ //一定是low <= high ,搜索结束high指向的位置后一位即为插入位置 mid = (low + high) / 2 ; if(arr[0] < arr[mid]) high = mid - 1; else low = mid + 1; } for(j = i - 1; j >= high + 1; --j) arr[j+1] = arr[j]; arr[high + 1] = arr[0]; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
时间复杂度:
折半插入排序所需的关键字比较次数比直接插入排序要少,平均性能要优于直接插入排序,时间复杂度为O(n^2)
折半插入排序关键字比较次数与待排序列初始排列无关,依赖于有序序列的元素个数,插入第i个元素时比较次数为
l
o
g
2
i
log_2i
log2i
折半插入排序的对象移动次数与直接排序相同,依赖于对象的初始排列。
空间复杂度:
只需要一个辅助空间arr[0],因此空间复杂度为O(1)
算法特点:
1、稳定排序
2、只能适用于顺序结构,不用于链式结构
3、适合初始记录无序,n较大的情况
希尔排序
通过分析直接插入排序可以得出,待排序记录个数越少、待排序记录中逆序对越少,直接插入排序算法的效率越高。希尔排序正时通过将待待排序记录分组来减少记录数量,通过对分组后的每个小组进行直接插入排序来减少逆序对的数量。
//希尔排序 //例程步长序列计算公式 n/2^k n为排序规模 k取1,2,3,4 ... 当步长为1时为止 void shell_insert(int arr[],int n,int d){ int j; for(int i = d+1; i <= n; i++){ arr[0] = arr[i]; for(j = i; j > d && arr[0] < arr[j-d]; j -= d){ arr[j] = arr[j-d]; } arr[j] = arr[0]; } } void shell_sort(int arr[],int n){ for(int gap = n / 2; gap > 0; gap /= 2){ shell_insert(arr,n,gap); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
时间复杂度:
最坏情况,步长序列由 n/2^k 计算得出,为O(n^2)
最好情况,步长序列由下列公式计算得出,为O(n^(4/3))
9
(
2
k
−
2
k
/
2
)
+
1
(
K
取
偶
数
)
9(2^k-2^{k/2})+1(K取偶数)
9(2k−2k/2)+1(K取偶数)
8 ∗ 2 k − 6 ∗ 2 k + 1 / 2 + 1 ( K 取 奇 数 ) 8*2^k - 6*2^{k+1/2} +1(K取奇数) 8∗2k−6∗2k+1/2+1(K取奇数)
空间复杂度:
仅用arr[0]作为辅助空间,因此时间复杂度为O(1)
算法特点:
1、不稳定排序
2、只能用于顺序结构,不能用于链式结构
3、增量可以有各种取法,但应该使增量序列中的值没有除1之外的公因子,并且最后一个增量值必须是1
4、总的比较次数和移动次数比直接插入排序要少,n越大,效果越明显,适用于初始记录无序、n较大的情况
二、交换排序
基本思想:两两比较待排序记录关键字,当两个关键字不满足次序要求时进行交换,直到整个序列满足要求为止。
冒泡排序
两两比较关键字,如逆序则交换顺序,较大关键字逐渐一端移动,直到序列有序。
//冒泡排序
void bubble_sort(int arr[],int n){
int flag = 1 , len = n;
int m = n;
while((m > 0) && (flag == 1)){
flag = 0;
for(int j = 1; j <= m; j++){
if(arr[j] > arr[j+1]){
flag = 1;
arr[0] = arr[j];arr[j] = arr[j+1]; arr[j+1] = arr[0];
}
}
m--;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
时间复杂度:
最好情况(初始序列正序),只需进行一次排序,在排序过程中进行n-1次关键字的比较,不移动记录
最坏情况(初始序列逆序),进行n-1次排序,总的关键字比较次数为 n^2 / 2 ,记录移动次数为 (3n^2 )/ 2
平均情况,比较次数和记录移动次数分别为 n^2 / 2 ,3n^2 / 4, 时间复杂度为O(n^2)
空间复杂度:
仅需arr[0]作为交换辅助空间,故空间复杂度为O(1)
算法特点:
1、稳定排序
2、可用于链式存储结构
3、记录移动次数较多,算法平均性能比直接插入排序差,当初始记录无序时,n较大时,不宜采用
快速排序
由冒泡排序改进得到,冒泡排序只对相邻两个记录进行比较,因此每次只能消除一个逆序,而快速排序一次交换可消除多个逆序,从而提高排序性能。
//快速排序 //一趟排序,返回中枢位置 int partition(int arr[],int low,int high){ arr[0] = arr[low]; while(low < high){ while((low < high) && arr[high] >= arr[0]) high--; arr[low] = arr[high]; while((low < high) && arr[low] <= arr[0]) low++; arr[high] = arr[low]; } arr[low] = arr[0]; return low; } //递归进行排序 void QSort(int arr[],int low,int high){ int pivotloc; if(low < high){ pivotloc = partition(arr,low,high); QSort(arr,low,pivotloc-1); QSort(arr,pivotloc+1,high); } } void quick_sort(int arr[],int n){ QSort(arr,1,n); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
时间复杂度:
快速排序的趟数取决于递归树的深度
最好情况(每次排序后序列被分成两个大小大致相等的子表),定位枢轴所需的时间为O(n),总的排序时间为O(nlog2 n)
最坏情况(待排序列有序),递归树成为单支树,关键字的比较次数为n^2 / 2 ,这种情况下快速排序的速度已经退化为简单排序的水平。枢轴记录的合理选择可以避免最坏情况的出现,例如,可在待排序列中随机选择枢轴,并将枢轴交换到第一个位置。
平均情况,时间复杂度为O(nlog2 n)
空间复杂度:
快速排序时递归的,最大递归调用次数与递归树的深度一致,因此最好情况为O(log2 n),最坏情况为O(n)
算法特点:
1、不稳定排序
2、适用于顺序结构,很难用于链式结构
3、当n较大时,在平均情况下时所有内部排序方法中最快的一种,适用于初始记录无序,n较大的情况
三、选择排序
基本思想:每一趟排序从待排序的记录中选出关键字最小的记录,按顺序放在已排序的记录中,直到全部排完为止。
简单选择排序
//简单选择排序
void select_sort(int arr[],int n){
int k;
for(int i = 1; i < n; i++){
k = i;
for(int j = i+1; j <= n; j++){
if(arr[k] > arr[j])
k = j;
}
if(k != i){
arr[0] = arr[i]; arr[i] = arr[k]; arr[k] = arr[0];
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
时间复杂度:
最好情况(正序),记录不需要移动。
最坏情况(逆序),移动3(n-1)次
无论记录的初始状态如何,所进行的关键字之间的比较次数相同,均为n^2 / 2 ,因此时间复杂度为O(n^2)
空间复杂度:
仅用arr[0]作为交换辅助空间,因此空间复杂度为O(1)
算法特点:
1、算法本身是稳定排序,也可以变成是不稳定排序
2、可以用于链式存储结构
3、移动次数少,当每一个记录占用的空间较多时,此方法比直接插入排序快。
堆排序
每次将堆顶元素取出,与末尾元素交换,调整前n-1个元素,使其仍然成堆,重复上述过程,直到剩余元素为1时为止,即可得到非递减序列
//调整堆 void heapify(int arr[],int low,int high){ arr[0] = arr[low]; for(int i = 2*low; i <= high; i *= 2){ if(i<high && arr[i] < arr[i+1]) i++; if(arr[0] >= arr[i]) break; arr[low] = arr[i];low = i; } arr[low] = arr[0]; } //初建堆 void creat_heap(int arr[],int n){ for(int i = n / 2; i > 0; i--){ heapify(arr,i,n); } } //堆排序 void heap_sort(int arr[],int n){ creat_heap(arr,n); for(int i = n; i > 1; i--){ arr[0] = arr[1]; arr[1] = arr[i]; arr[i] = arr[0]; heapify(arr,1,i-1); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
时间复杂度:
堆排序平均性能接近于最坏性能,时间复杂度为O(nlog2 n)
空间复杂度:
仅用arr[0]作为交换辅助空间,空间复杂度为O(1)
算法特点:
1、不稳定排序
2、只能用于顺序结构,不能用于链式结构
3、初始建堆所需要的比较次数比较多,记录较少时不宜采用,堆排序在最坏情况下的时间复杂度为O(nlog2 n),相对于快速排序最坏情况下的O(n^2)而言是个优点,当记录较多时较为高效。
四、归并排序
基本思想:假设初始序列含有n个记录,则可看成时n个有序的子序列,每个子序列的长度为1,然后两两并归,得到n/2个长度为2或1的有序子序列;如此重复,直至得到一个长度为n的有序序列为止。
//合并相邻位置上的有序表 void Merge(int arr1[],int arr2[],int low,int mid,int high){ int i = low, j = mid+1, k = low; while(i <= mid && j <= high){ if(arr1[i] <= arr1[j]) arr2[k++] = arr1[i++]; else arr2[k++] = arr1[j++]; } while(i <= mid) arr2[k++] = arr1[i++]; while(j <= high) arr2[k++] = arr1[j++]; } void Msort(int arr1[],int arr2[],int low,int high){ int mid; int arr3[high]; if(low == high) arr2[low] = arr1[low]; else{ mid = (low + high) / 2; Msort(arr1,arr3,low,mid); Msort(arr1,arr3,mid+1,high); Merge(arr3,arr2,low,mid,high); } } //归并排序 void Merge_sort(int arr[],int n){ Msort(arr,arr,1,n); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
时间复杂度:
n个记录需要进行log2 n趟归并排序,每一趟归并,其关键字比较次数不超过n,元素移动次数都是n,因此时间复杂度为O(nlog2 n)
空间复杂度:
用顺序表实现递归时,需要和待排序记录相等的辅助存储空间,所以空间复杂度为O(n)
算法特点:
1、稳定排序
2、可用于链式结构,且不需要附加存储空间,但递归实现仍需要开辟相应的递归工作栈
五、基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。排序过程是将所有待比较数值统一为同样的数位长度,数位较短的数前面补零,然后从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
//获取最大值 int getMax(int arr[],int n){ int mx = arr[1]; for(int i = 2;i <= n; i++){ if(arr[i] > mx) mx = arr[i]; } return mx; } void countSort(int arr[],int n,int base){ int output[n]; int i,bucketCount[10] = {0}; //统计各个桶中元素个数 for(i = 1; i <= n;i++){ bucketCount[(arr[i]/base)%10] ++; } //计算分配后 数组下标 for(i = 1;i < 10; i++){ bucketCount[i] += bucketCount[i-1]; } //将本次排序的结果过暂时存放在output中 for(i = n;i >= 1; i--){ output[bucketCount[(arr[i]/base)%10]] = arr[i]; bucketCount[(arr[i]/base)%10]--; } //将排序的结果存入原数组 for(i = 1;i <= n; i++){ arr[i] = output[i]; } } //基数排序 void radix_sort(int arr[],int n){ int m = getMax(arr,n); for(int base = 1; m / base > 0; base *= 10) countSort(arr,n,base); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
时间复杂度
该算法所花的时间基本是在把元素分配到桶里和把元素从桶里串起来;把元素分配到桶里:循环 length 次;
把元素从桶里串起来:这个计算有点麻烦,看似两个循环,其实第二循环是根据桶里面的元素而定的,可以表示为:k×buckerCount;其中 k 表示某个桶中的元素个数,buckerCount 则表示存放元素的桶个数;
有几种特殊情况:
第一、所有的元素都存放在一个桶内:k = length,buckerCount = 1;
第二、所有的元素平均分配到每个桶中:k = length/ bukerCount,buckerCount = 10;(这里已经固定了10个桶)
所以平均情况下收集部分所花的时间为:length (也就是元素长度 n)
综上所述:
时间复杂度为:posCount * (length + length) ;其中 posCount 为数组中最大元素的最高位数;简化下得:O( k*n ) ;其中k为常数,n为元素个数;
空间复杂度
该算法的空间复杂度就是在分配元素时,使用的桶空间;所以空间复杂度为:O(10 × length)= O (length)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

