
- 1笔记-软考高项-错题笔记汇总3
- 2鸿蒙Harmony-列表组件(List)详解_鸿蒙精简列表
- 3神经网络可以用来分类吗,神经网络用什么软件做_spss神经网络可以用来干什么
- 4python最全画地图,可视化数据
- 5pb90代码如何连接sql2008r2_如何创建Raspberry Pi灯光秀
- 6【毕业设计】疲劳驾驶行为检测系统 - python opencv cnn 深度学习_基于python和opencv的疲劳驾驶检测系统源码+全部数据(毕业设计).zip
- 7深蓝激光slam理论与实践-第一节笔记_slam的静态环境的这个静态环境到底是啥意思
- 8android自动计时器,Android中定时器Timer的使用
- 9【分享】免费的AI绘画网站(5个)_免费ai绘画网站入口
- 10VFF复现_voxel field fusion for 3d object detection
目标检测YOLO算法系列学习笔记第二、三、四章-YOLOv1、v2、v3算法思想与架构_简述以下 一步法的v1,v2,v3的核心思想
赞
踩
神经网络算法关注:网络结构输出值+损失函数。
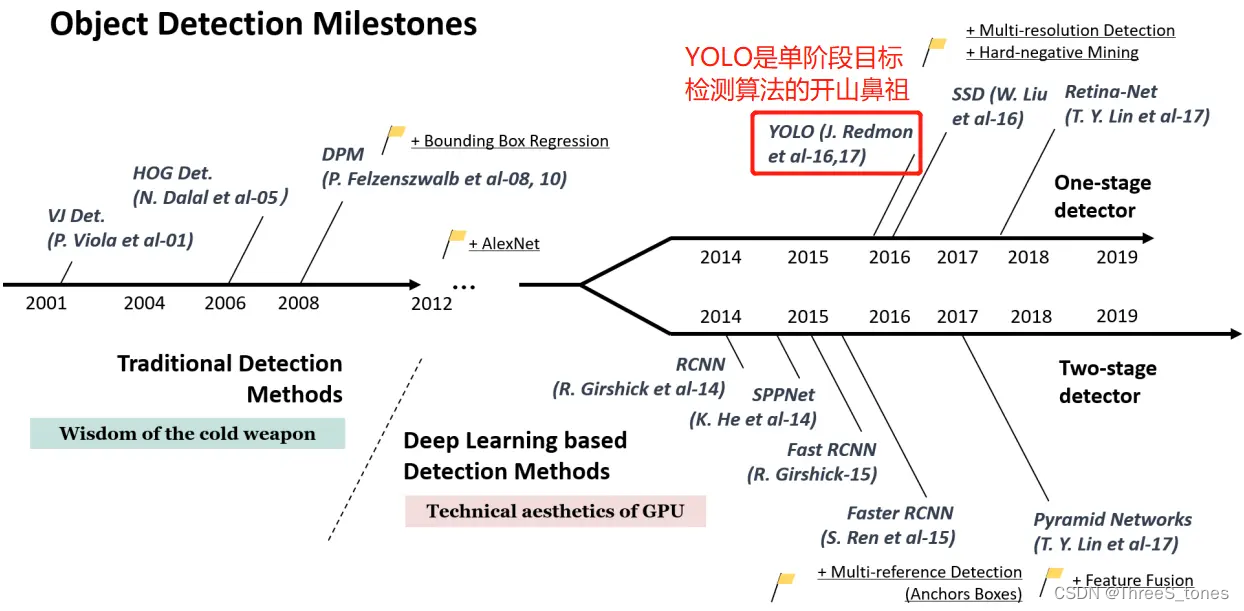
各版本发表时间、作者和论文
YOLO(You Only Look Once),2015.6.8,Joseph Redmon
YOLOv2(YOLO9000),2016.12.25,Joseph Redmon
YOLOv3,2018.4.8,Joseph Redmon
YOLOv4,2020.4.23,Alexey Bochkovskiy
YOLOv5,2020.6.10,Ultralytics
YOLOX,2021.7.20,旷世
YOLOv6,2022.6.23,美团
YOLOv7,2022.7.7,Alexey Bochkovskiy
YOLOv8,2023.1,Ultralytics
参考:https://blog.csdn.net/qq_34451909/article/details/128779602
YOLOv1:2015,paper:https://arxiv.org/pdf/1506.02640.pdf
YOLOv2:2017,paper:https://arxiv.org/pdf/1612.08242.pdf
YOLOv3:2018,paper:https://arxiv.org/pdf/1804.02767.pdf
YOLOv4:2020,paper:https://arxiv.org/pdf/2004.10934.pdf
YOLOv5:2020,paper:https://arxiv.org/pdf/2108.11539.pdf
YOLOv6:2022,paper:https://arxiv.org/pdf/2209.02976.pdf
YOLOv7:2022,paper:https://arxiv.org/pdf/2207.02696.pdf
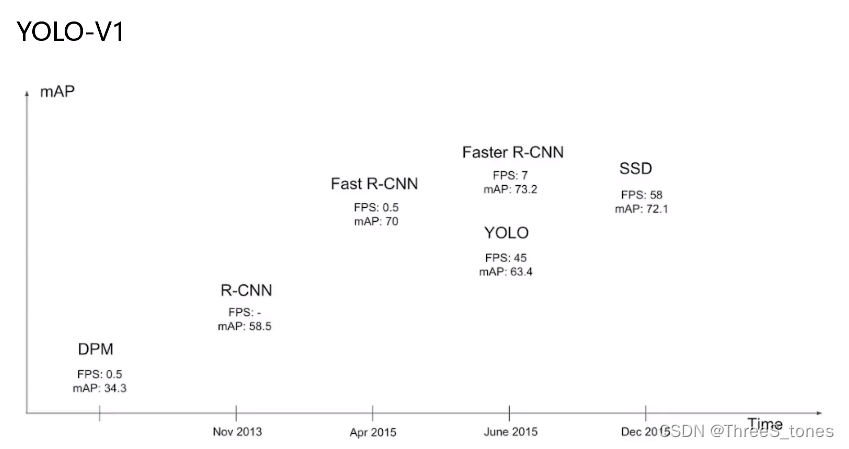
yolo-v1(2015年提出)
整体思想
其核心思想是:把目标检测当做一个单一的回归任务。它首先将图像划分为SxS个网格,物体真实框中心落在哪个网格上,就由该网格对应的锚框负责检测该物体。
经典的one-stage方法,把检测问题转换为回归问题,一个CNN搞定,可输出x,y,h,w。
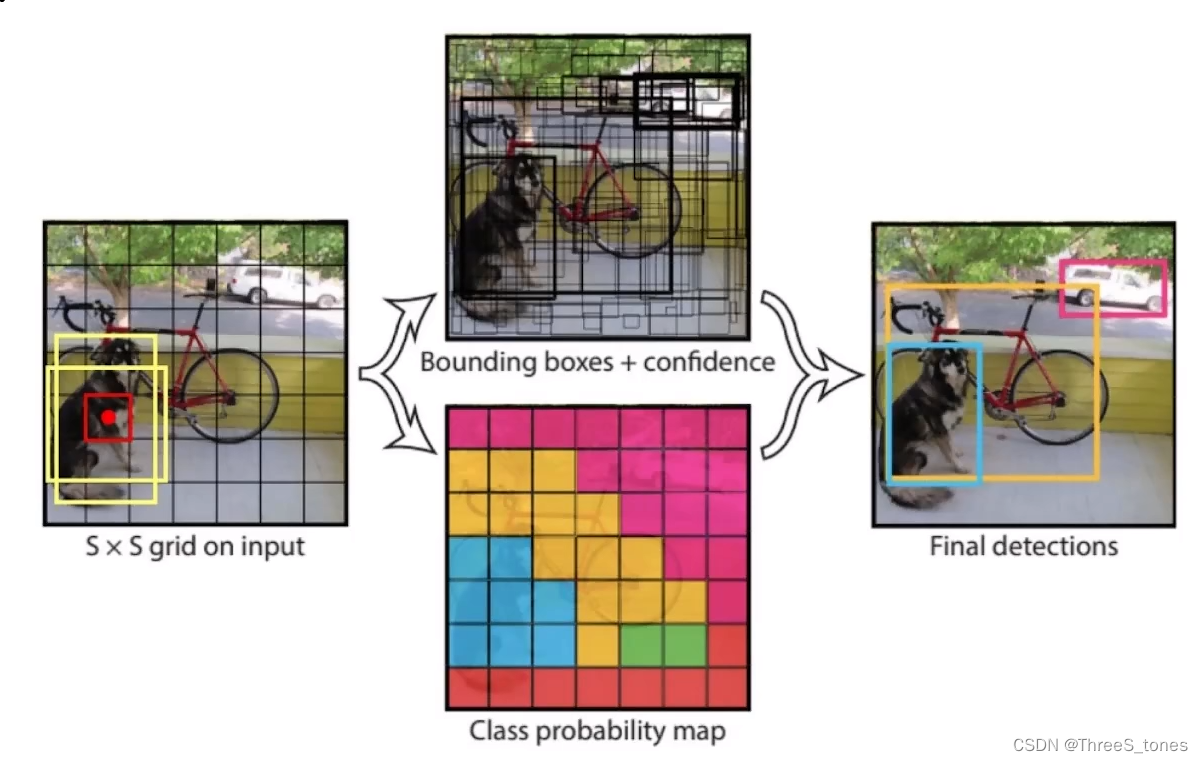
将输入数据分成S*S的小格子**(v1中输出是7×7)**。
判断物体在哪个格子看他的中心点。
先基于经验给出两种候选框的H和W,与真实的框计算IoU,哪个高就用哪个作为预测框,再进行微调(回归任务),对每一个格子,都生成预测框,最终输出x,y,h,w(bounding box,边界框)和confidence(置信度),然后对生成的许多框进行过滤,得到置信度较高的框,对置信度较高的框再进行微调。
网络架构解读
对于全连接层,因为其权重和偏置的大小在每次回归中是不变的,必须限制输入特征的大小,否则就没办法做,所以YOLO-v1中给定了输入图像大小为448×448×3。
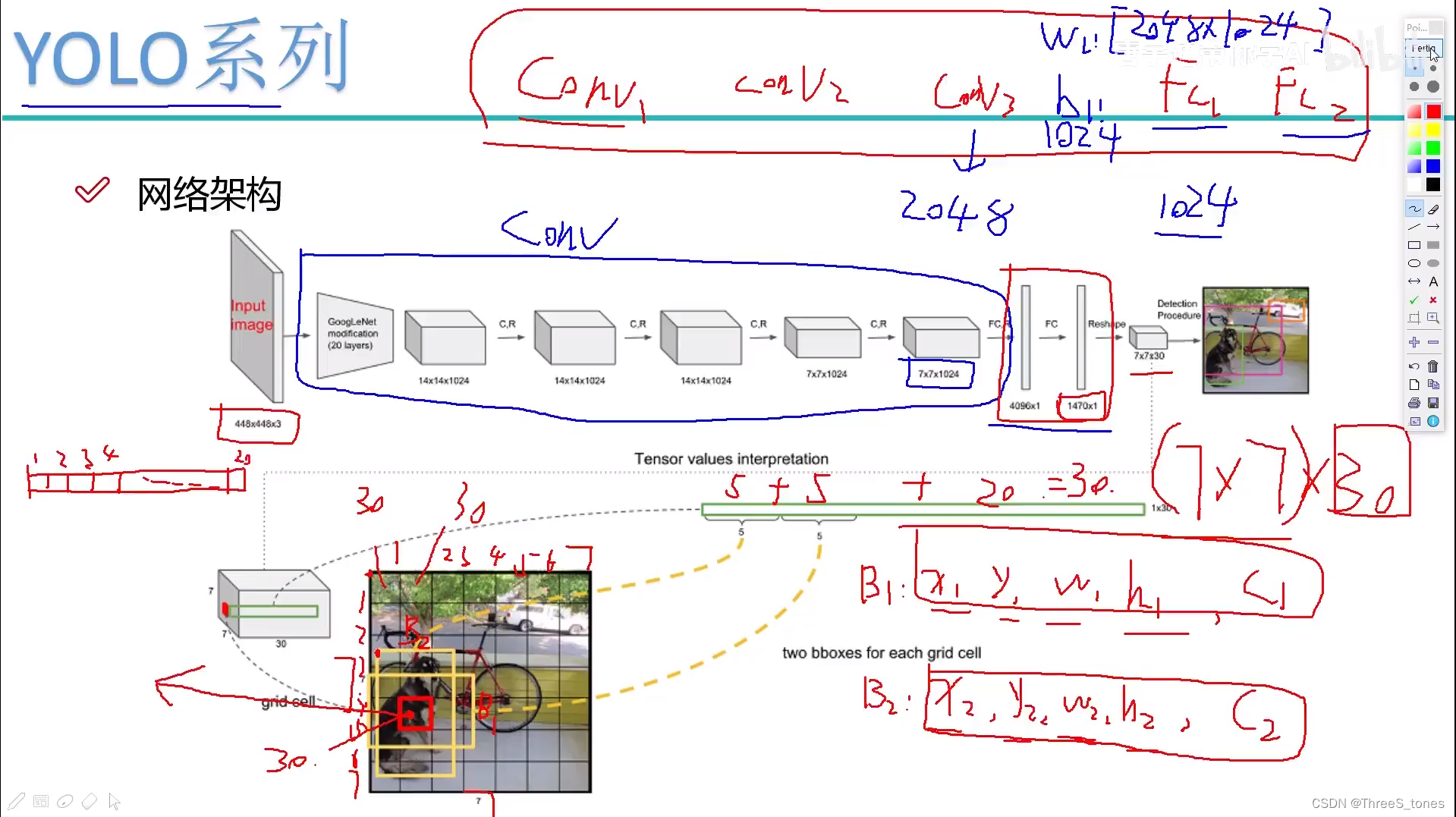
全连接层前面的部分可以看成进行卷积过程,因为GoogLeNet网络现在用的很少了,所以就不细讲,v3的时候会细讲用的网络模型。
主要看后面输出的7×7×30的含义:
7×7表示把图像分成7×7的格子。
30=10+20:表示两种候选框(bounding box)的位置、大小和置信度,加上20个类别。
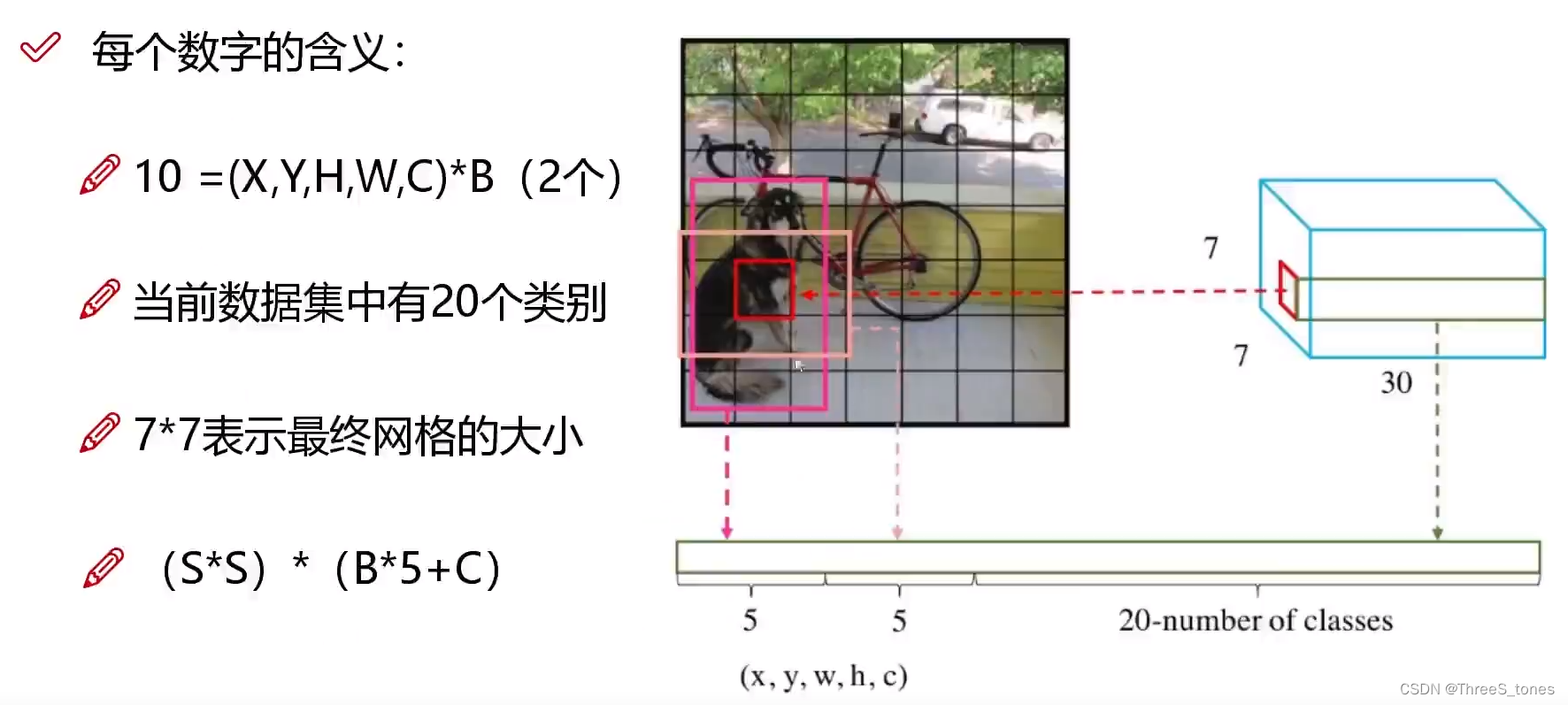
最终预测结果的维度为S×S×(B*5+C)
损失函数
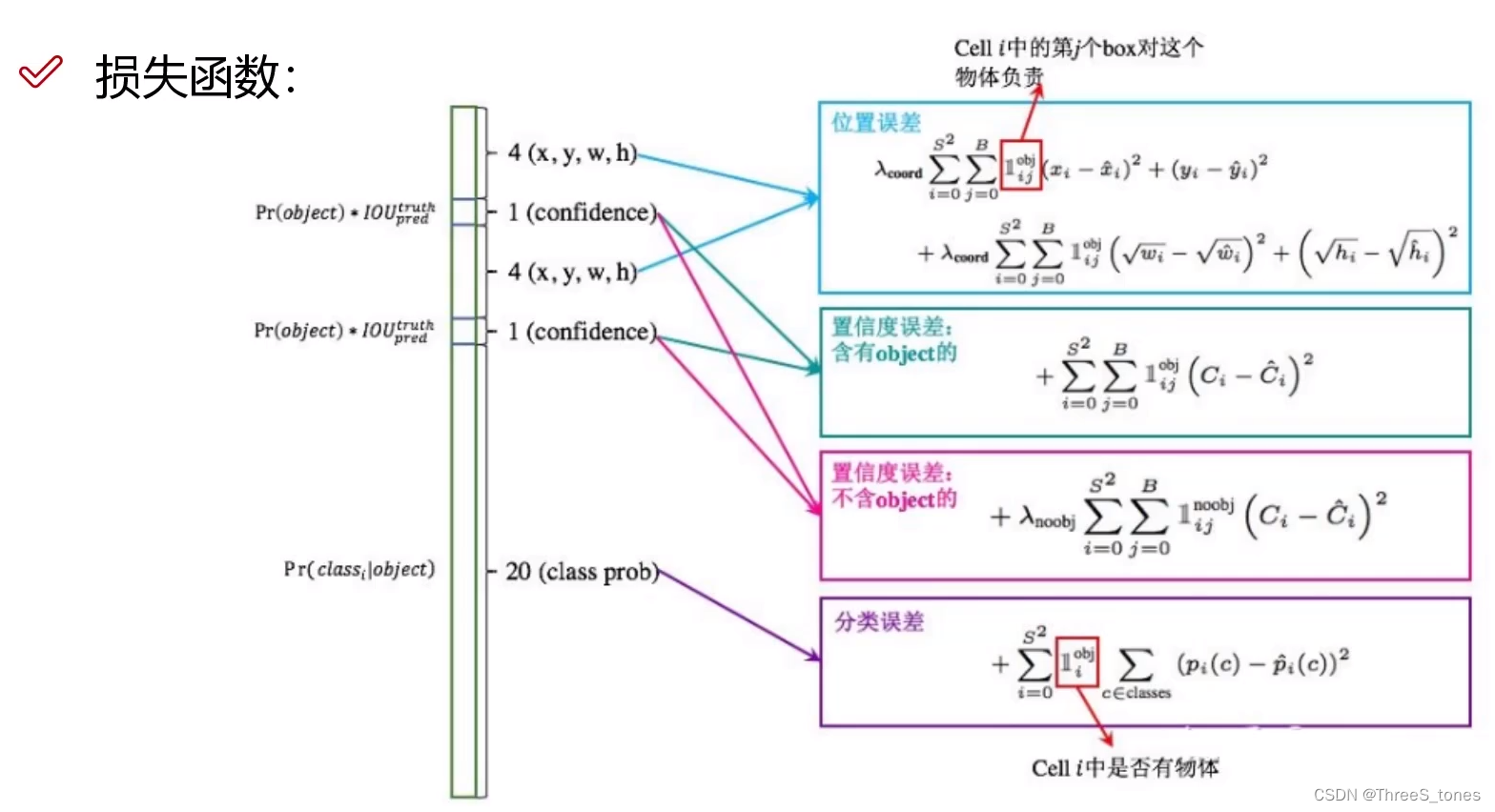
位置误差
i表示对于不同的格子,一共有S的平方个,j表示对不同的候选框,共有B个,选择IoU最大的那个框,计算真实值和预测值的差异。
对w和h加上根号是为了应对物体大小不同的情况,对小物体来说框的大小变一个单位可能就框不住了。
y=根号x函数在数值较小的时候会比较敏感,数值较大的时候没那么敏感。对于小物体来说偏移量比较小的时候可能不敏感,现在让它敏感一些。
前面的系数就相当于权重项。
置信度误差
分为前景(即含目标)和背景(不含目标)
当某一个框与真实框的IoU大于阈值,比如0.5,那么当前这个框的置信度越接近IoU越合适,但是可能有许多框与真实框多有重叠的部分,那么就计算IoU大的那个框。
在实际图像中前景和背景的比例多少不同,所以在背景的计算中有一个权重项,让背景对损失的影响小一点。
分类误差
计算交叉熵损失。
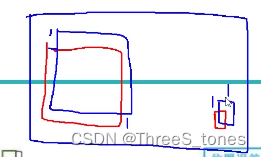
NMS(非极大值抑制)
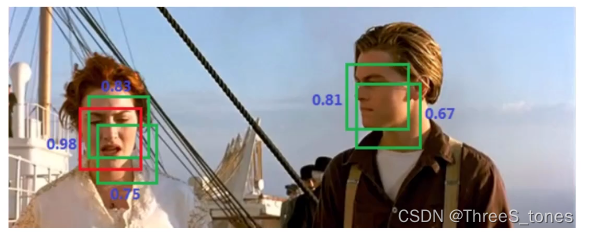
在预测时,对于IoU比较大的框(预测的是同一个物体),比较他们的置信度,保留极大值,把其他的都去掉。
yolo-v1的特点
优点
快速简单。
缺点
- 重合在一起的东西很难都检测出来。
- 小物体检测效果一般,长宽比可选但单一。
- 同一个目标具有多个标签的问题很难做,比如一个物体的标签是狗和哈士奇。
yolo-v2(2017年)
改进细节

v2没有全连接层。

BN现在用的非常多,conv-bn可以说是标配了。

v1的时候计算机性能可能比较差,训练448×448×3的图像会比较慢,所以训练跟测试用的图像像素点数量不同。
v2的时候不考虑时间了,额外进行了10次的微调。
网络架构解读

借鉴了VGG(2014)和Resnet网络结构。
-
就是为了提取特征,所以没有了全连接层。
全连接层容易过拟合,而且由于参数非常多,训练的比较慢。
右边的output只是举了个例子,实际情况不是这样。 -
5次降采样,每次降采样降低为原来的一半,输出特征图上的一个点相当于原始图像的1/32。
实际输入为416×416,输出13×13(比v2更精细),这是实际的网络结构Darknet 19,有19层,层数可以根据自己的需求改,层数多,可能mAP就高,FPS就低。输出是个奇数,这样特征图有个中心点。 -
网络中有两种卷积核:3×3和1×1,前者是借鉴了VGG网络那篇论文的思想,选择比较小的卷积核时参数比较小,感受野比较大。1×1卷积是只改变了特征图的个数(channel通道数),都是想要达到特征浓缩的一个过程,用1比用3参数少,计算的快。
基于聚类选择先验框尺寸
- YOLOv1用了2种。
- fasterRCNN用了9种。3个scale,三种不同的大小,每个大小中有三个形状的。faster-rcnn系列选择的先验比例都是常规的,但是不一定完全适合数据集。
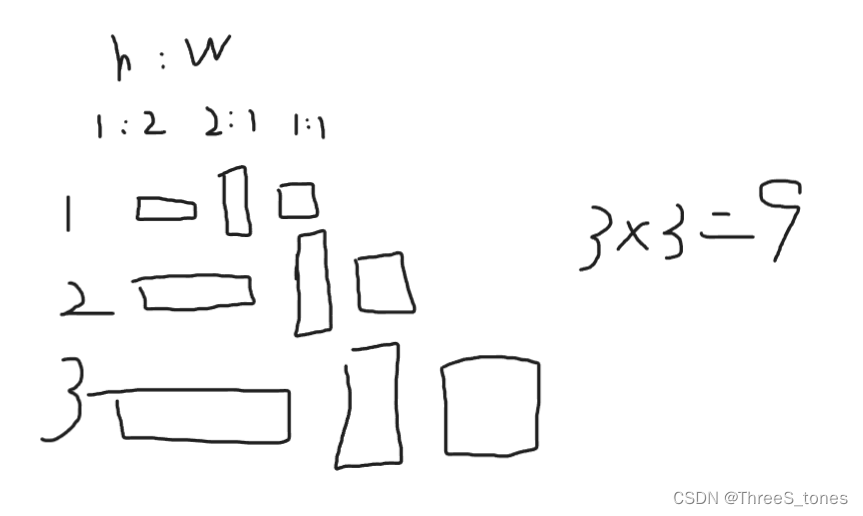
- YOLOv2:基于K-means聚类选择先验框尺寸。从实际例子中聚类出5类(k=5),每一类的中心作为代表拿出来作为先验框的h和w,特征图中的每个格子都出来5中先验框。如果都使用欧氏距离的话可能大的框产生的误差就大,小的框误差小。提出了一种距离的定义,用1-IoU作为距离。
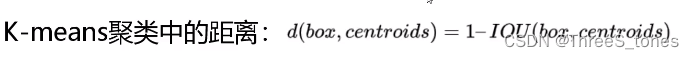
他们做了一个实验,取了一个折中的值k=5。此时平均IoU比较大,再增加k值提升就很慢了(斜率)。选出五种先验框(anchors)。
- 结果
mAP略有降低,recall明显提高。
候选框多了,但是不是每个候选框都能做得好,所以mAP值略有降低(打个比方,本来找了两个学习好的,发挥都很好,但是如果找了五个,能发挥的没那么好),但是查全率提升较明显,查全率就是图中有目标,能够检测出来的目标多了。

偏移量计算方法,坐标映射与还原
- YOLOv1当中直接预测偏移量。
- v2中预测一个相对位置,防止加上偏移量之后,边界框移出格子。

坐标映射与还原
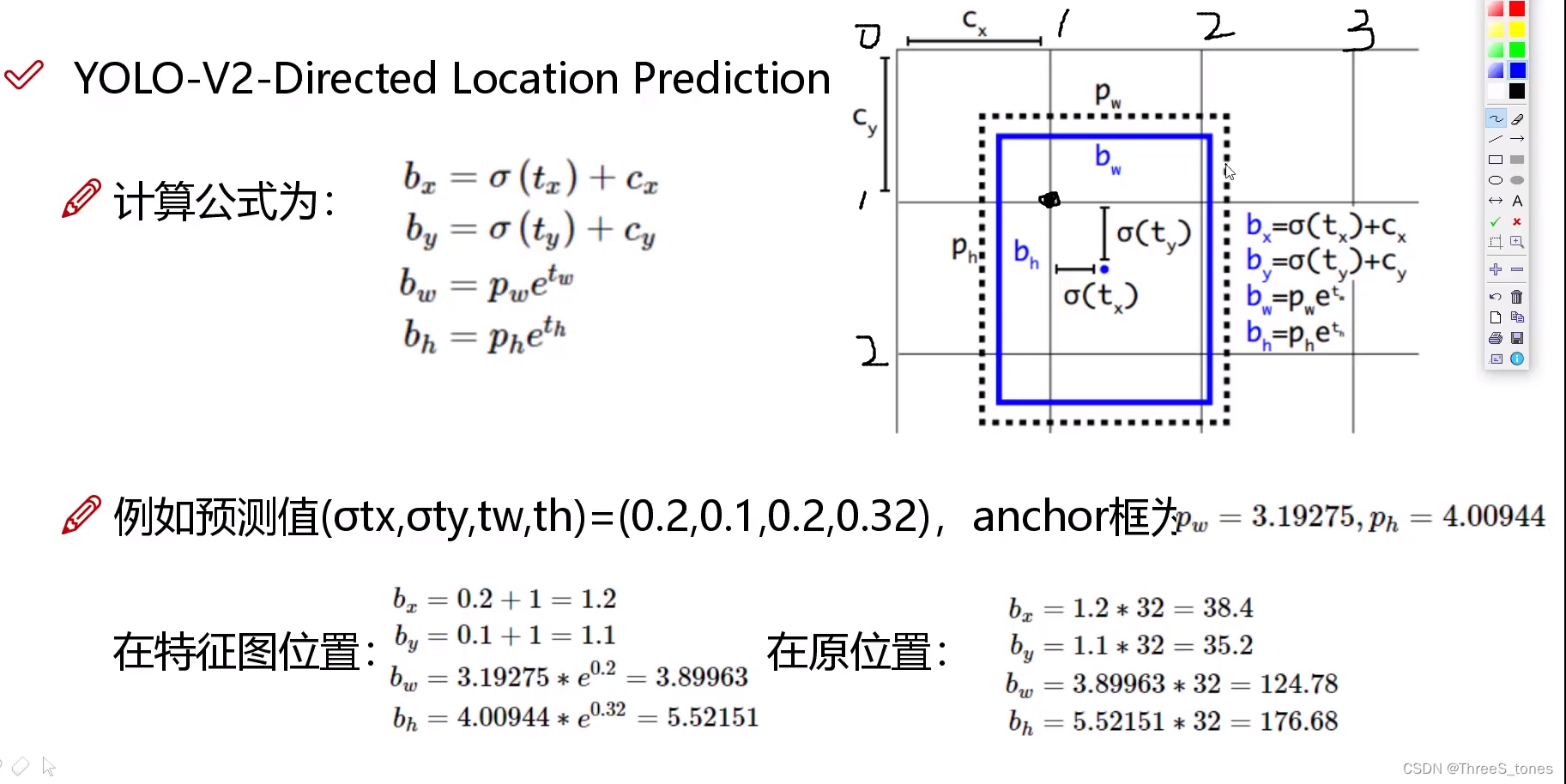
- tx,ty是预测的偏移量,sigmoid函数,值域是0到1,预测的偏移量输入到sigmoid函数中得到一个0-1之间的数,加上格子左上角的坐标,得到bx,by,最终预测值bx,by,bw,bh是映射到了特征图上。
- tw,th也是预测值,其中经过了一个对数变换,所以到bw,bh时又变回来。最终预测值bx,by,bw,bh是实际特征图上的位置。
- pw,ph是通过聚类得到的先验框,是在特征图中框的大小,原始图像经过了映射(除以32)。
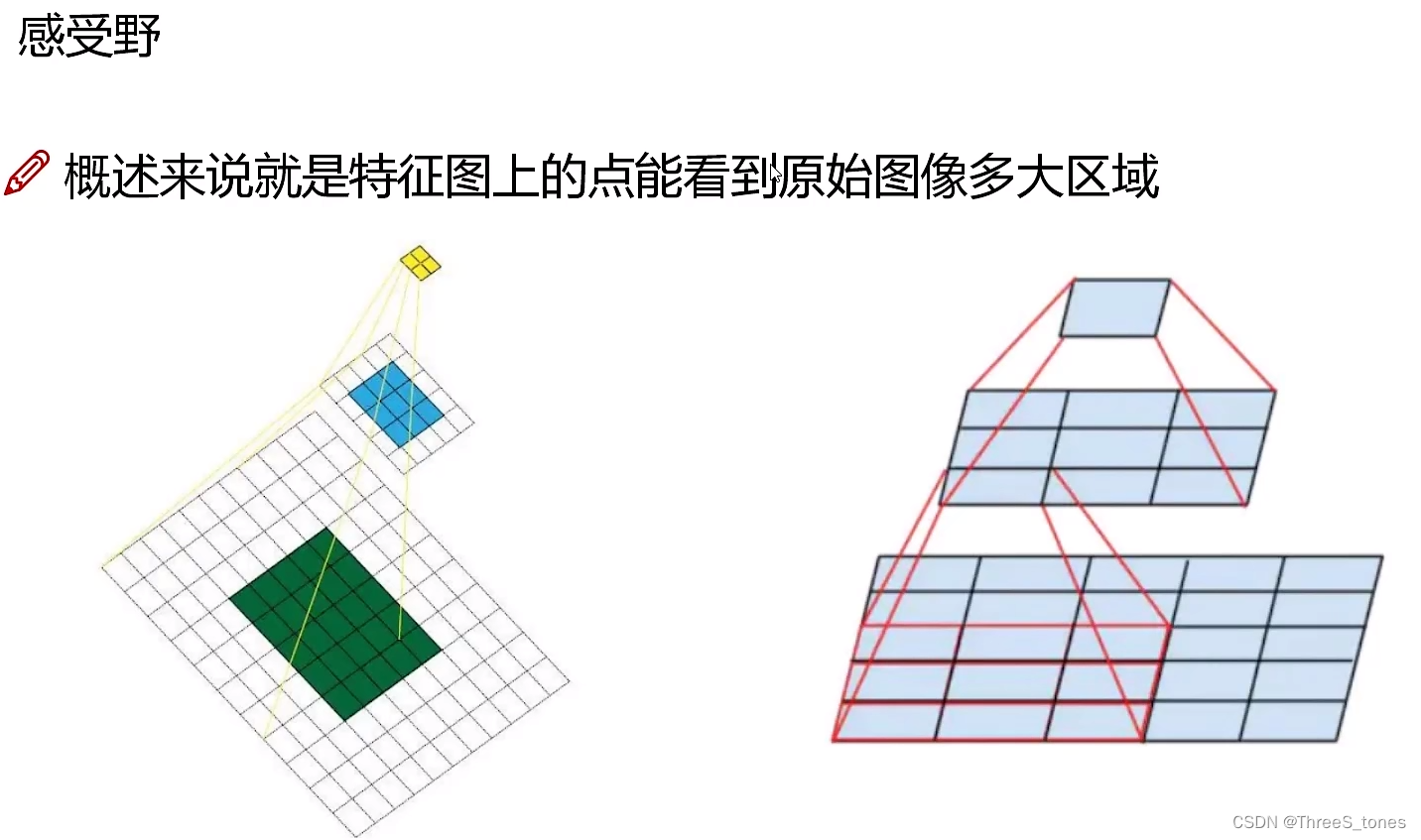
感受野的作用
越大的感受野相当于它看原始图像当中的信息就更多了,方便识别出更大的物体。
感受野的计算公式:

如果有空洞卷积:
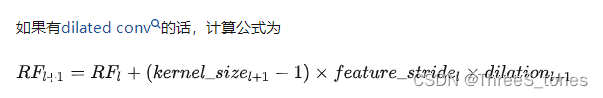
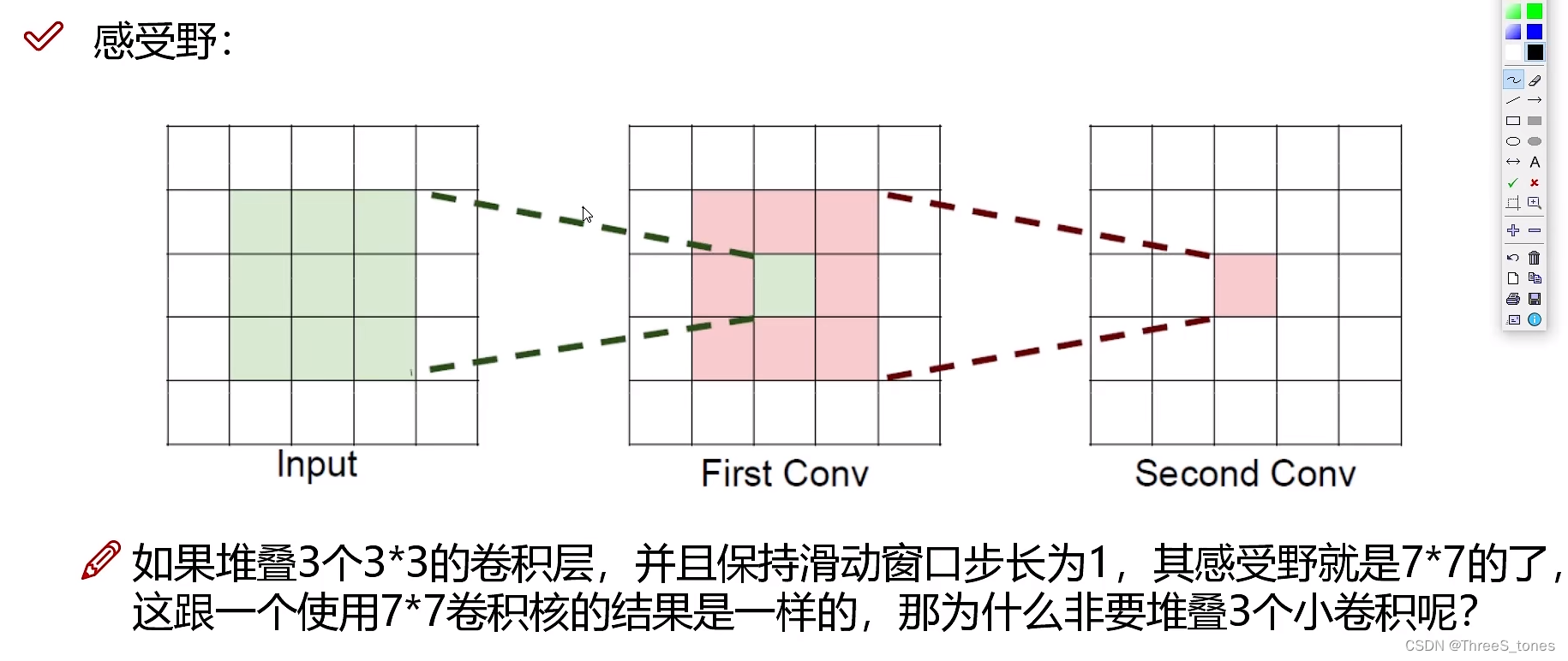
第一层卷积感受野为3,第二层卷积后感受野5,第三层:5+(3-1)×1=7

特征融合改进
越大的感受野适合捕捉大的目标,小的特征就可能丢失。
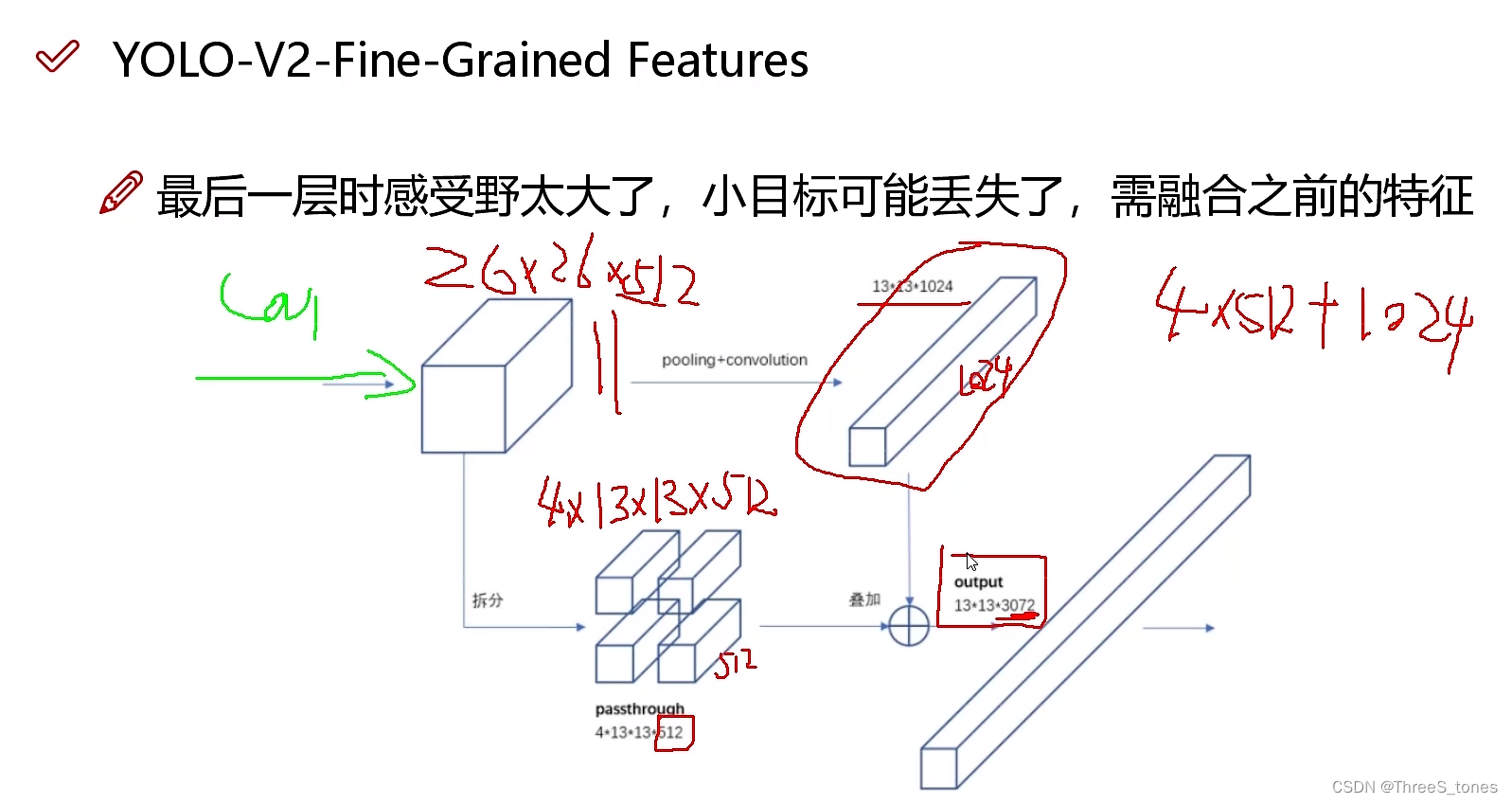
既要大的又要小的感受野,就把这两层的叠加起来。
多尺度

v2中图像的尺寸都得能被32整除。
经过几次迭代,改变图像的尺寸,让网络有个适应能力,既能在小的图像当中检测到,又能在大的图像当中检测到,让它的能力更全面一点。
yolo-v3(2018年)
改进概述
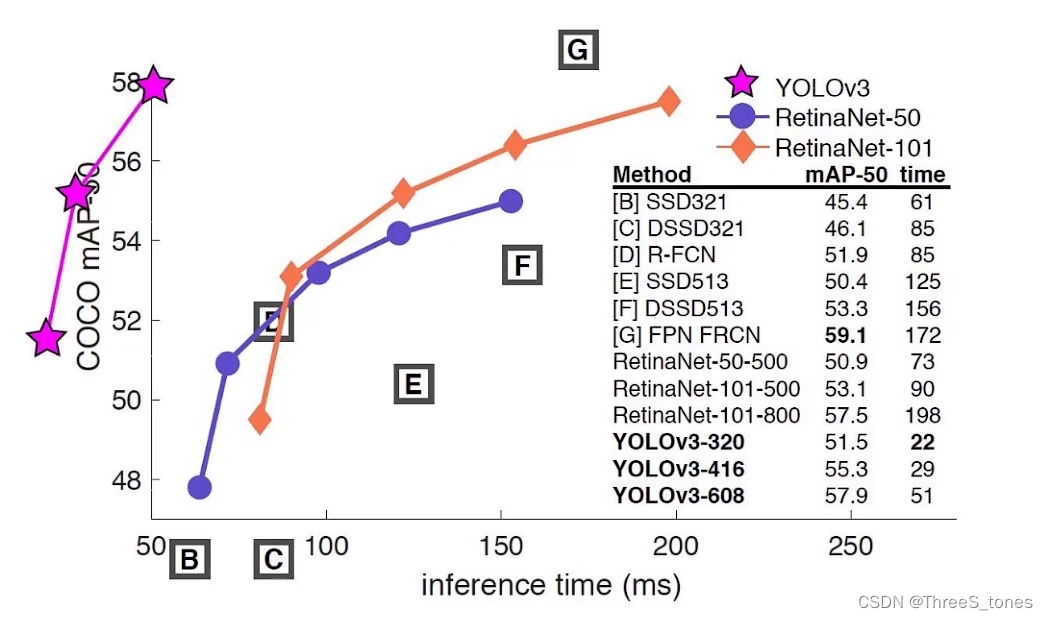
v3是非常实用的,它被用在了军事和隐私领域。2020年YOLO原作者发表了一个推特,说自己要退出计算机视觉领域的研究了。
v3之后的版本都不是原作者开发的。

特征图网格大小:
v1:7×7
v2:13×13
v3:13×13、26×26、52×52.
多scale方法改进与特征融合
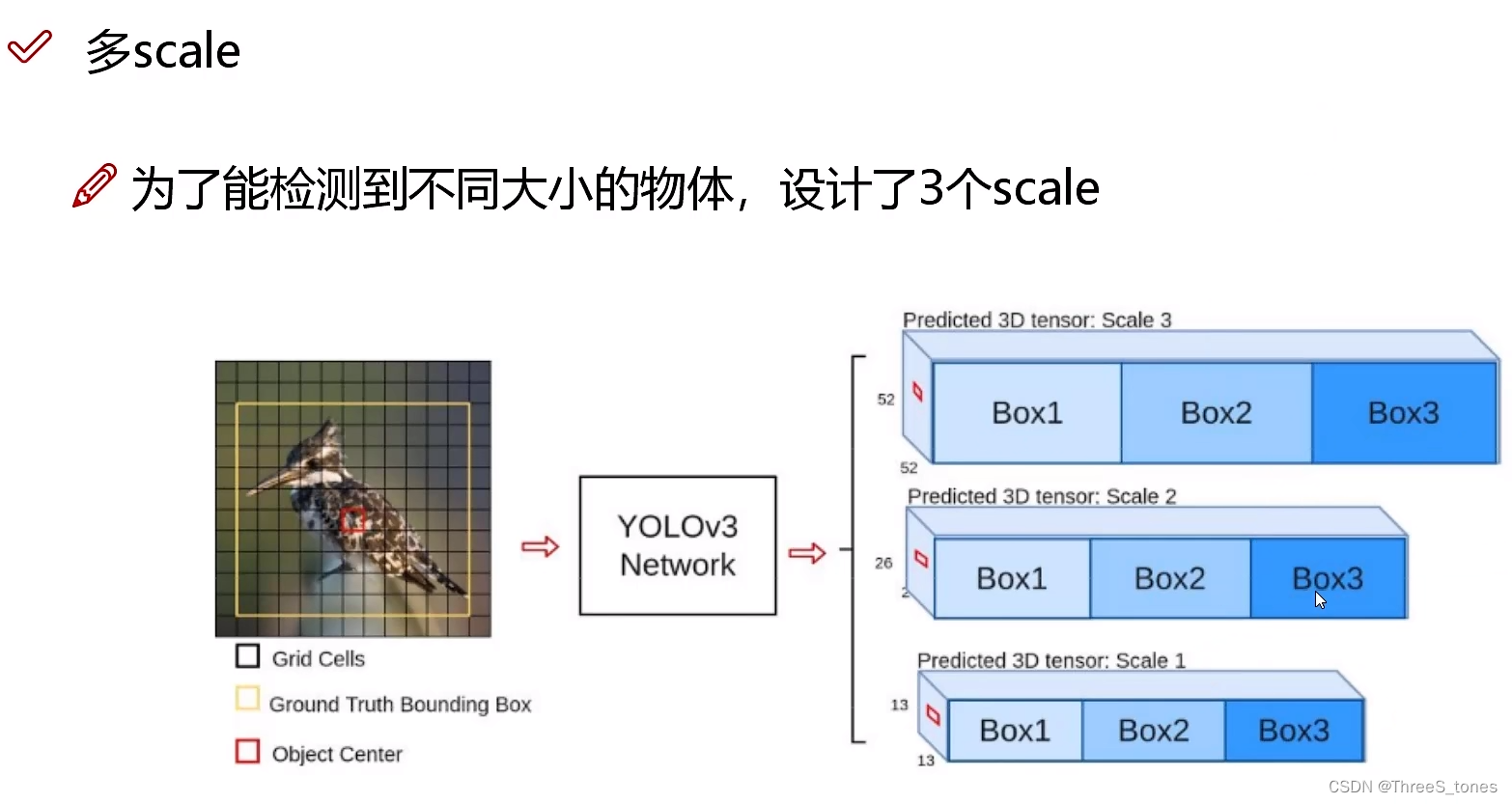
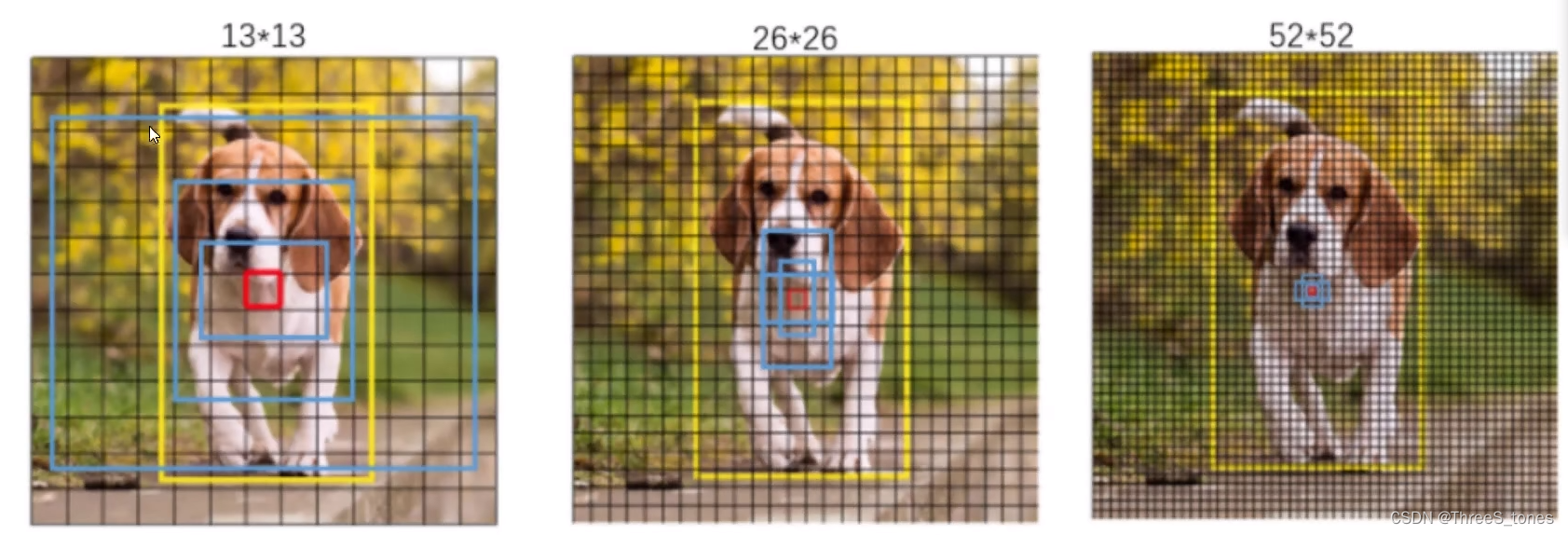
- 3种scale:52×52擅长预测小目标,26×26擅长预测中等大小的目标,13×13擅长预测大目标。不是擅长做什么就让他做什么(不是各做各的),也不是直接将前面和后面的特征融合。
- 每一种特征图上产生三种候选框。
- 不是直接让52×52预测小目标,26×26预测中等大小的目标,13×13预测大目标,而是做了一个特征融合,13×13的已经知道了全局的信息,所以使用26×26预测中等大小的目标时也要使用13×13的经验。预测中目标的从预测大目标的特征图中借鉴一些思想,预测小目标的借鉴预测中目标的特征。
scale变换经典方法对比分析
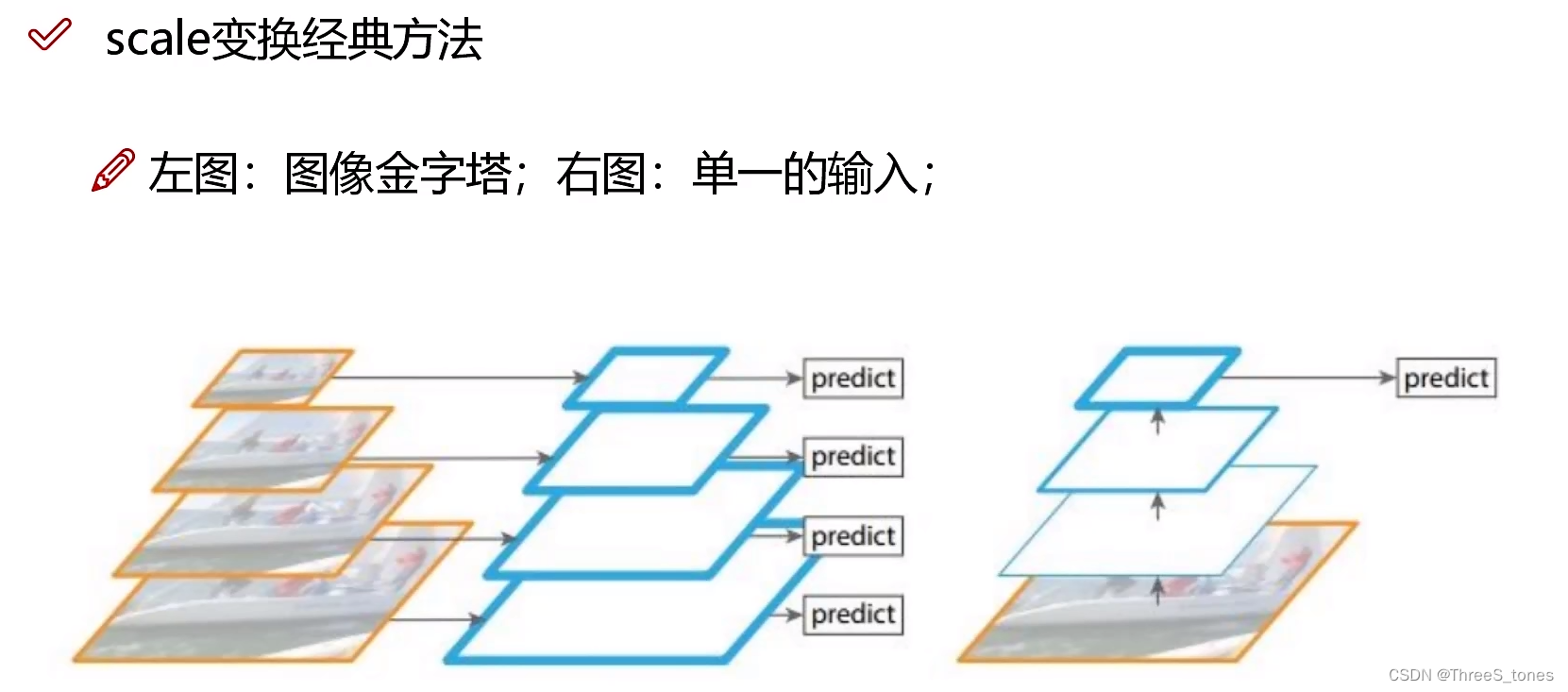
左图:图像金字塔,将输入图像做一个resize,分别输入进网络,产生三种特征图大小:52×52,26×26,13×13,但是这种速度太慢。
右图:其实就是YOLOv1,单一的预测结果,一张图像做一个CNN。
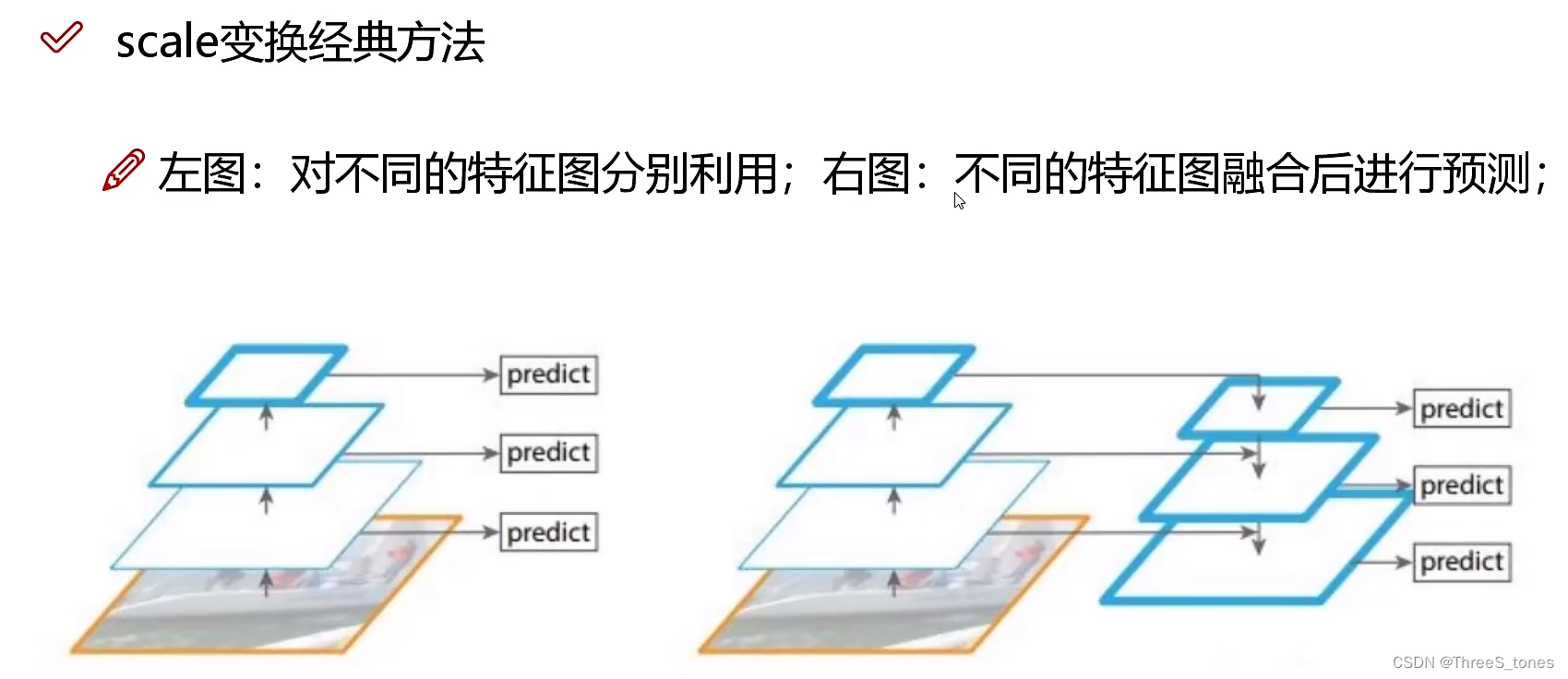
左图是各做各的。
v3中用右图,使用上采样,用线性插值去做。
13×13的特征图经过上采样变成26×26,然后与26×26的进行融合,去预测中等大小的目标,26×26的经过上采样之后与13×13的进行融合,预测小目标。
残差连接方法解读
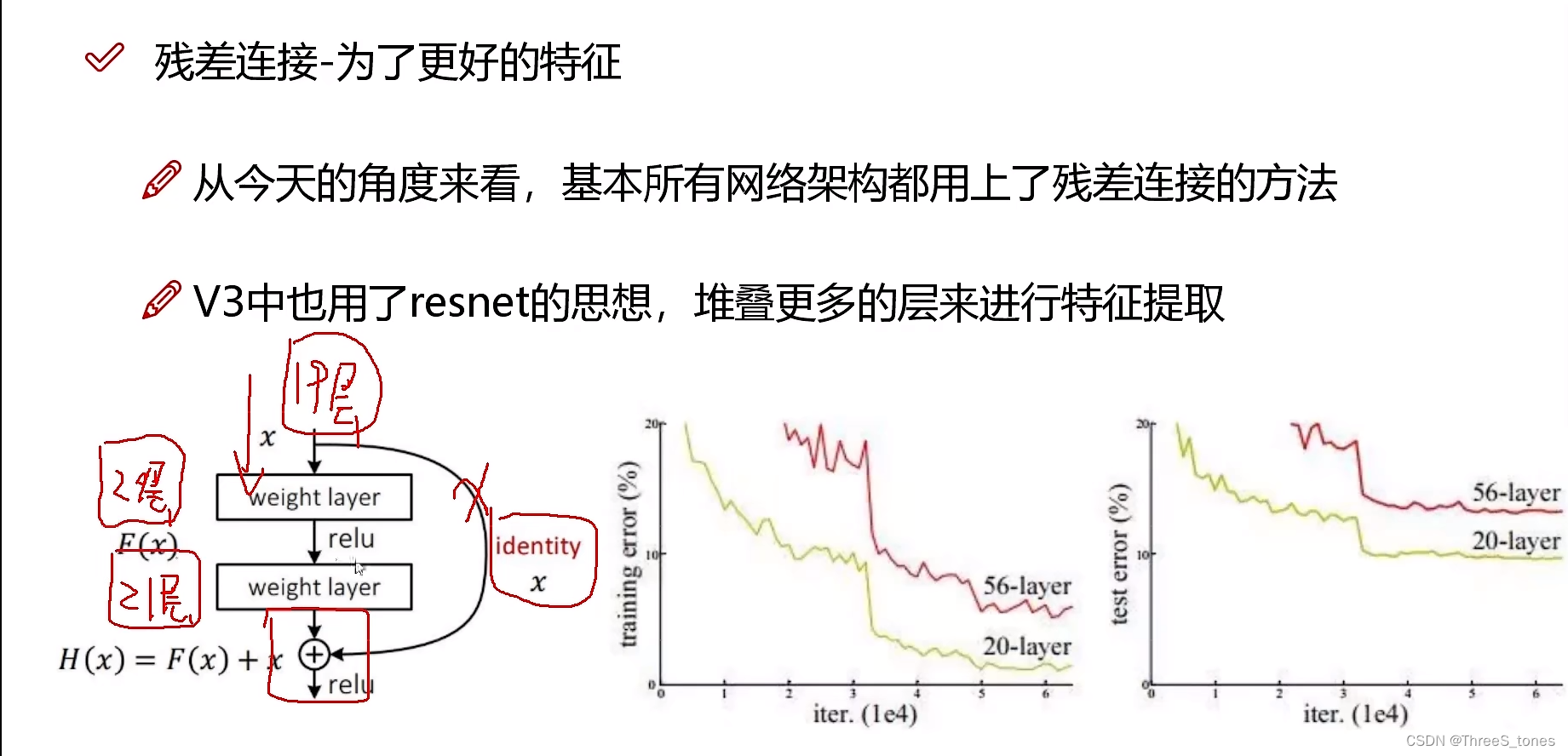
YOLOv3把resnet(2016)论文中的思想融合进去了。
2014年VGG只做了19层,因为有时层数增加,预测效果反而不好了,梯度消失。
resnet解决了梯度消失的问题,因为有同等映射x,所以网络性能可以达到至少不比原来差。
左下角是个残差块儿。
整体网路模型架构分析
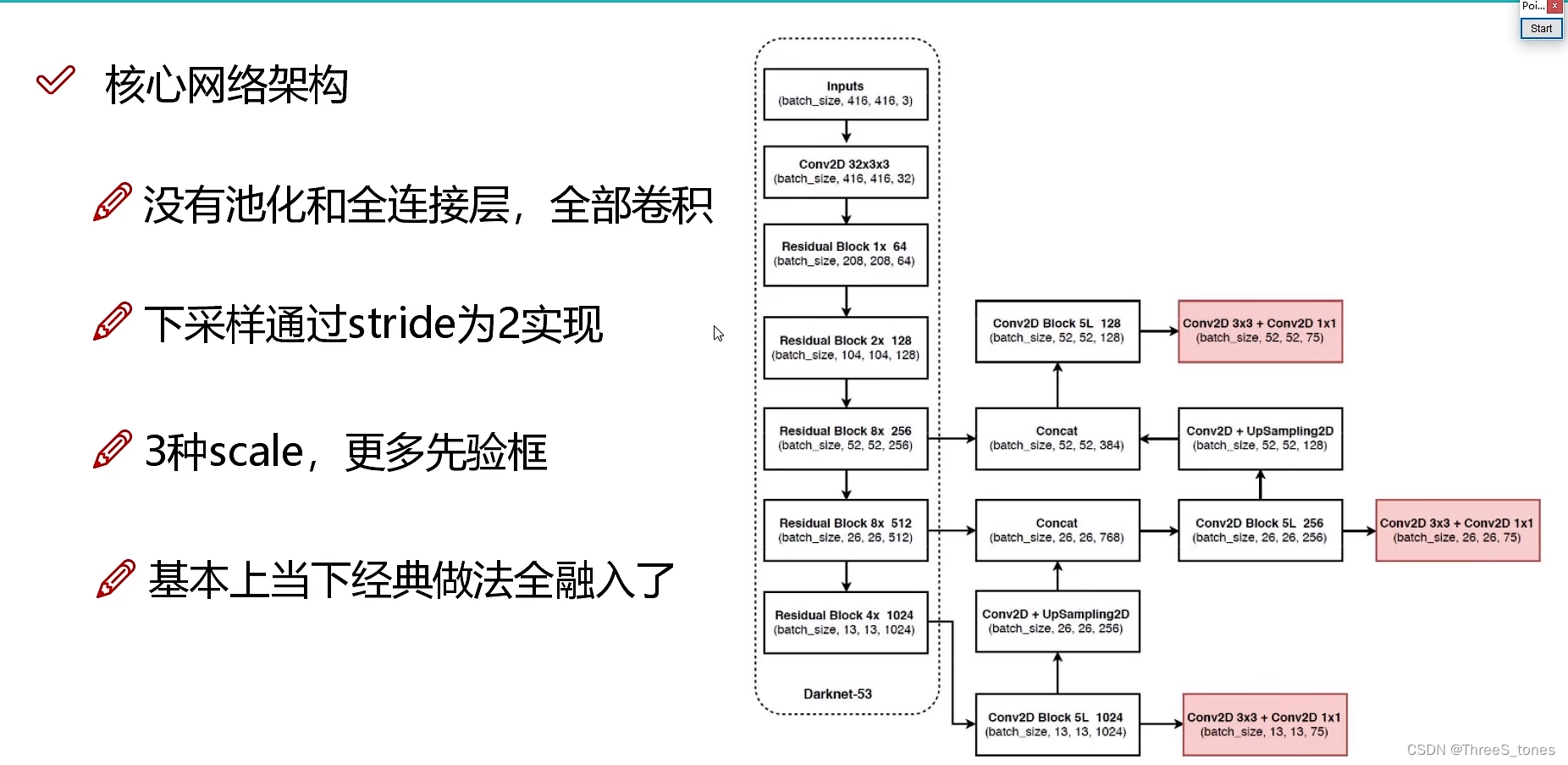
1x, 2x, 8x指的是堆叠的次数。
YOLO v3把模型叫做DarkNet 53,其实可以把它当做resnet。
池化会把特征压缩,可能效果反而不好。卷积省时省力速度快效果好。
先验框设计改进
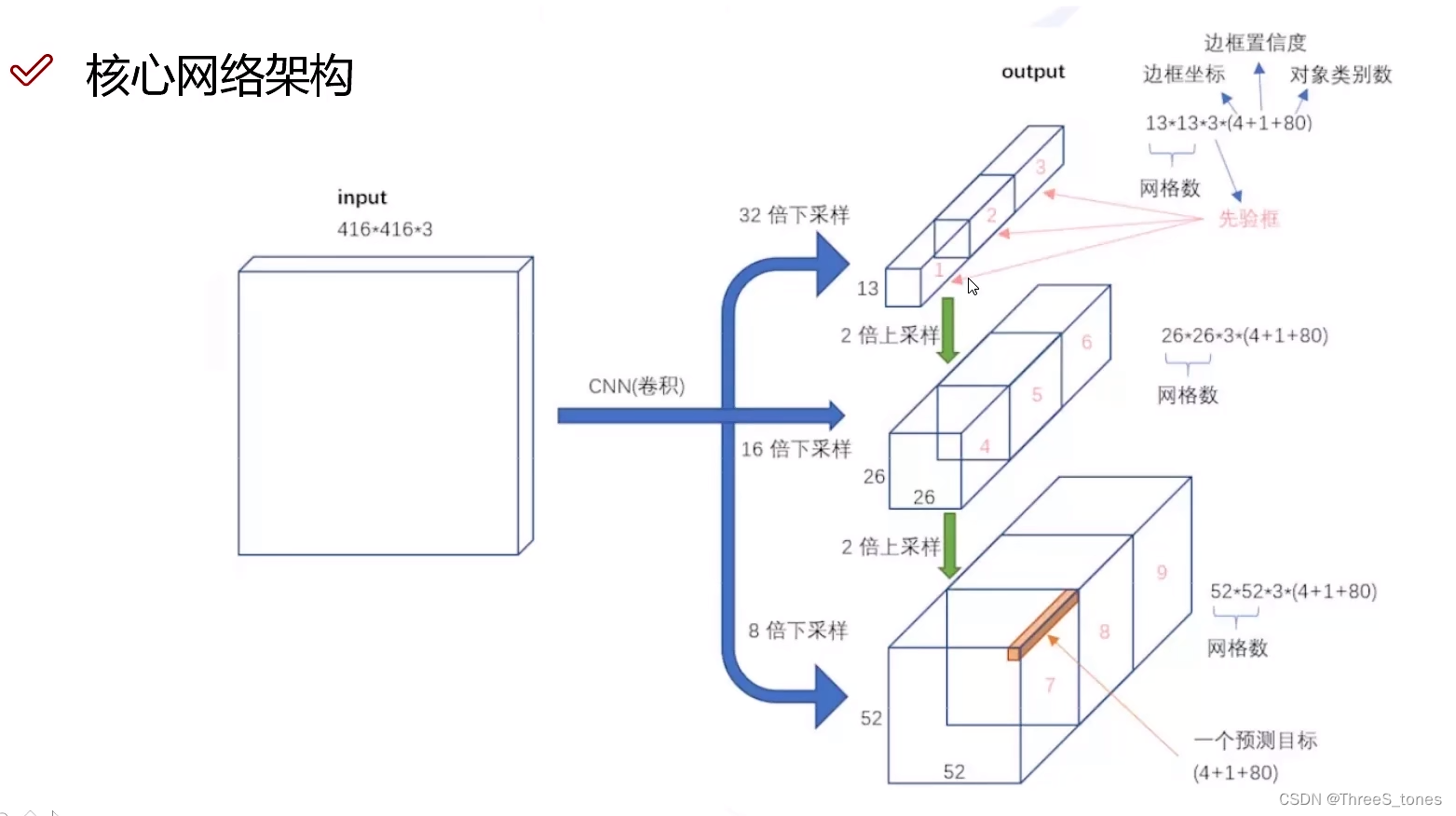
输出值:13×13×3×85(13网格数×3种先验框比例×4边框坐标×1置信度×80类别)
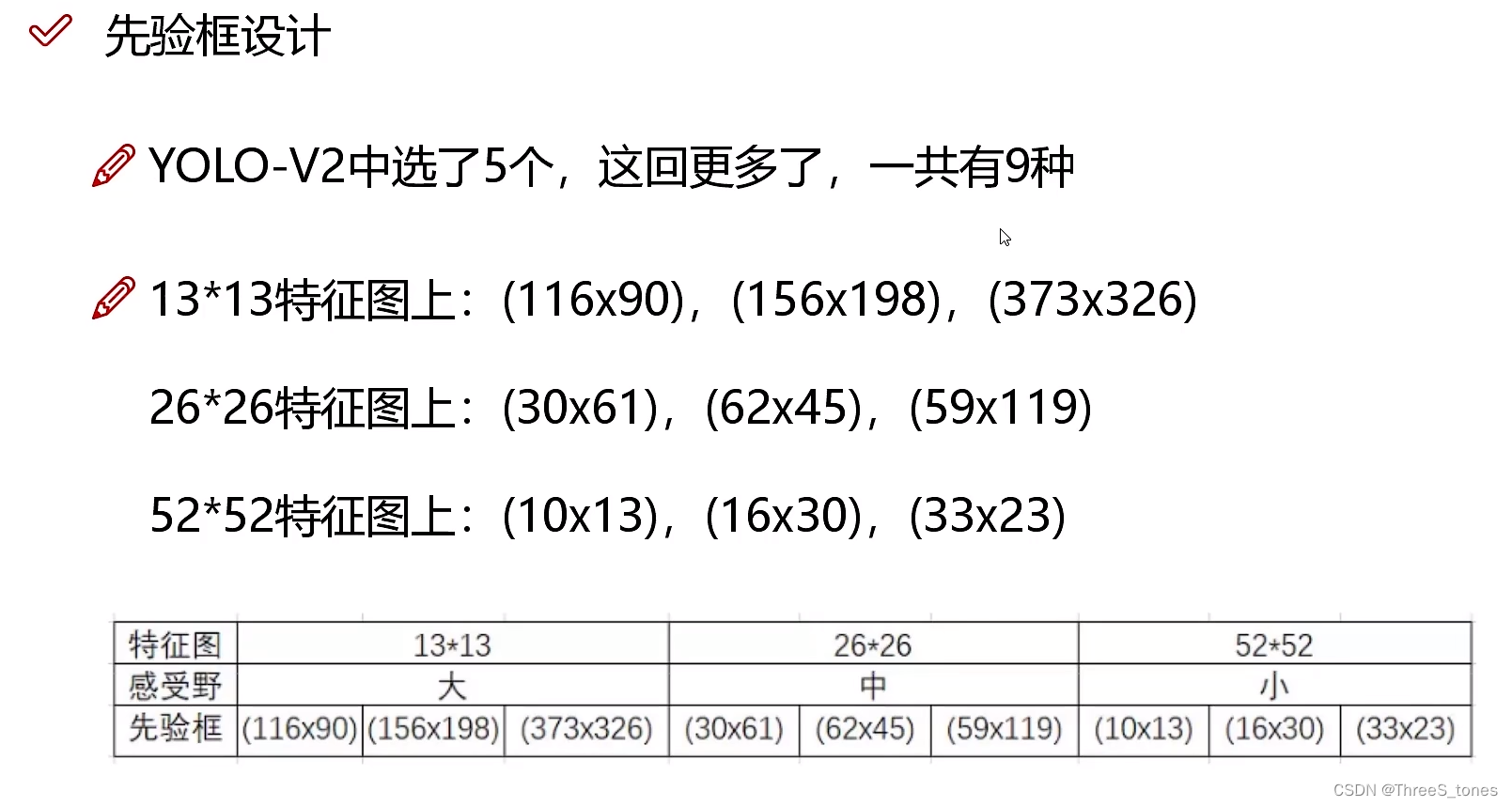
做完聚类之后出来9中常见的规格,但是并不是每个格子都出来9中先验框,而是分了类,不同的先验框交给不同的特征图做。
softmax层改进
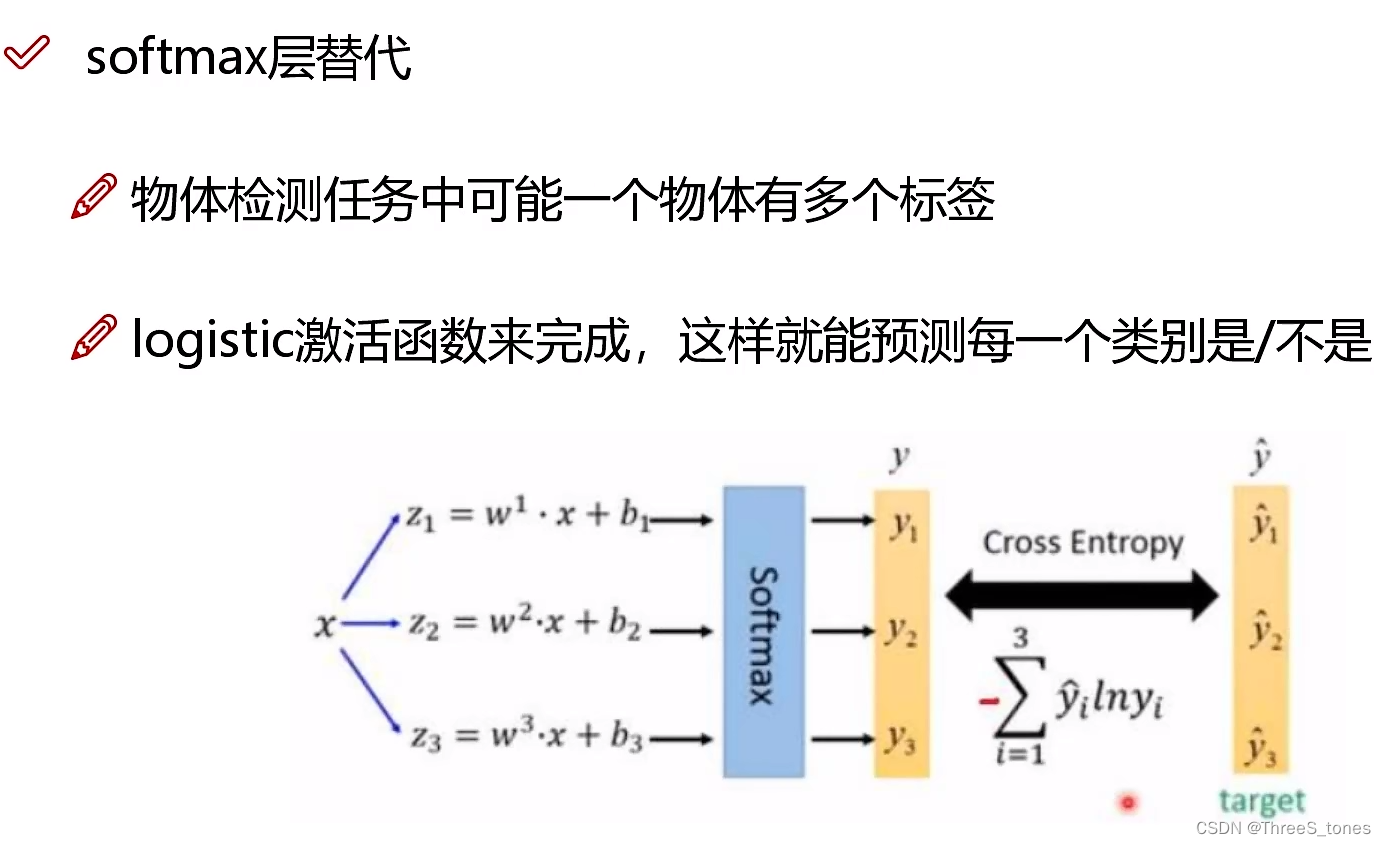
每一个标签都做一个二分类。
很多地方听不明白。

