- 1深入理解 Java 虚拟机(第一弹) - Java 内存区域透彻分析_java元数据空间并不在虚拟机中,而是使用本地内存。
- 2LDAP认证-ldap介绍_ldap认证是什么意思
- 3rk3588网络部署_rk3588 模型部署
- 4毕业设计——java web大作业,通过jsp+servlet实现宿舍管理系统_javaweb jsp期末大作业简单项目
- 5微信小程序点击事件(bindtap)传递参数_微信小程序bindtap传递参数
- 6【论文精读】【DETR】End-to-End Object Detection with Transformers
- 7uni-app的基本使用_uniapp自定义全局loading
- 8linux搭建面板端我的世界服务器_mcsm安装java
- 9Flutter的Windows中文超详细安装教程集锦,前端配置开发 Flutter 踩坑记,以及相关基础语法_flutter中文教程
- 10100天精通鸿蒙从入门到跳槽——第13天:ArkTS声明式UI 使用教程_鸿蒙开发教程
ElasticSearch
赞
踩
链接:https://pan.baidu.com/s/1WCaI25ZQLAwrCOmyh1pZow
提取码:bg1i
--来自百度网盘超级会员V5的分享
简称ES,是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时存储,检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB(大数据级)的数据.ES使用Java开发,内部使用Lucene(Java开发)做为器核心来实现所有索引和搜索功能.通过简单的RestFul API来隐藏其内部Lucene的复杂性,让全文搜索变得简单.
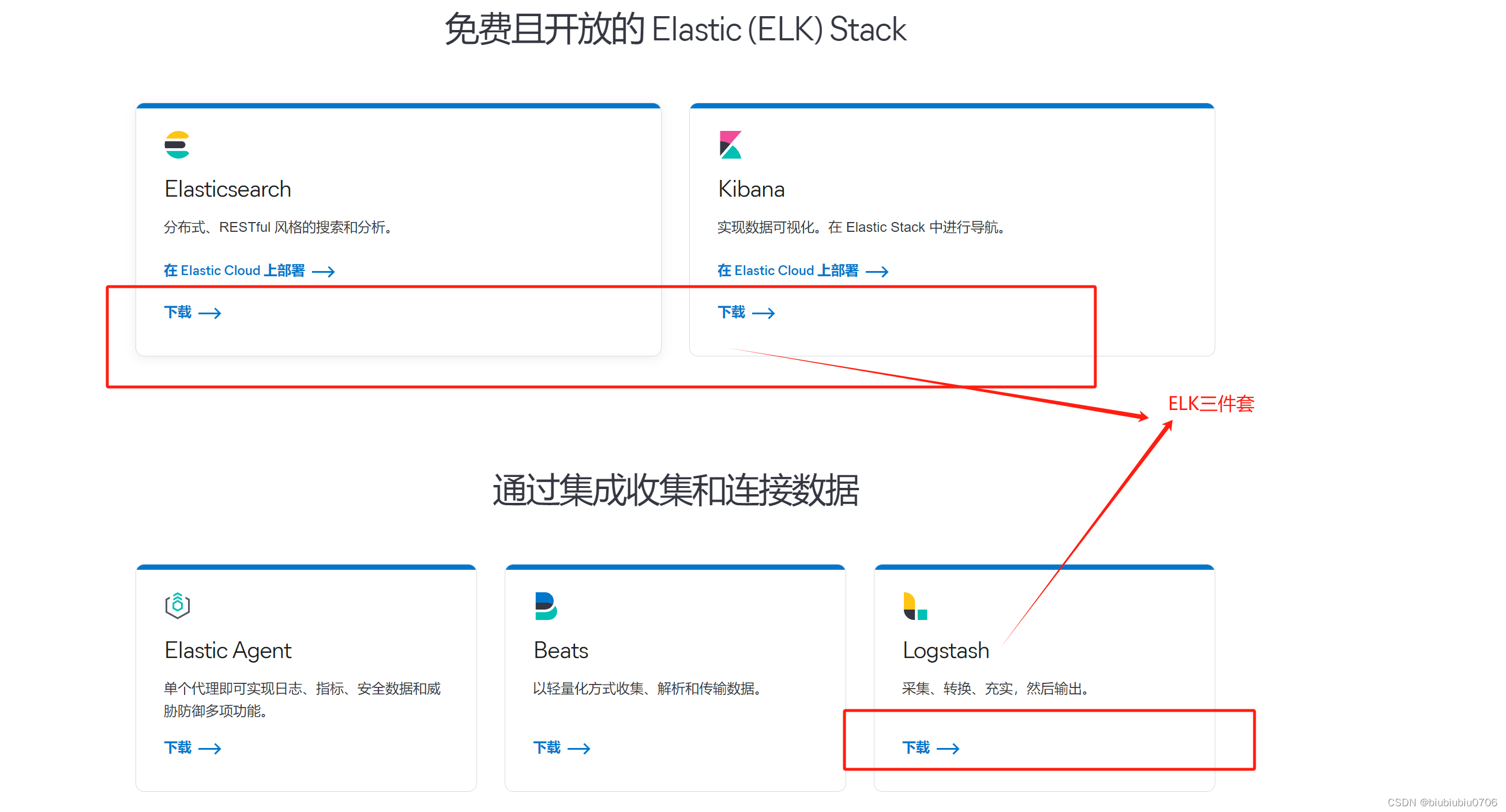
ELK技术:Elastic Search+Logstash+Kibana(了解下) 处理可视化大规模日志

哪些地方用到了ElasticSearch 维基百科等等
ElasticSearch和Solr
都是通过Lucene实现的.
1.单纯对已有数据进行搜索时,Solr更快
2.当实时建立索引时,Solr会产生IO阻塞,查询性能较差,ElasticSearch有明显优势
3.随着数据量的增加,Solr的搜索效率会变得低而ElasticSearch却没有明显的变化
4.Solr利用Zooker进行分布式管理,而ElasticSearch自身带有分布式协调管理功能
5.Solr支持更多数据格式.如:JSON,XML,CSV,而ElasticSearch仅支持JSON格式
成年人不做选择 可以不用,不能不会
ElasticSearch安装(这里全在WINDOWS上):
JDK版本8或以上. ElasticSearch客户端界面工具(Kibana)
中文官网:简体中文 | Elastic
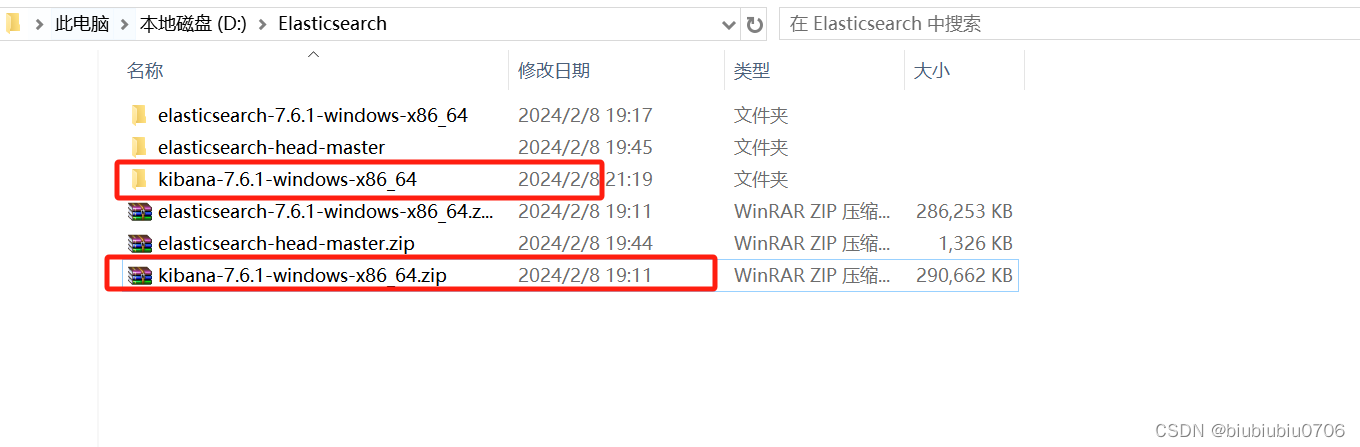
这里用7.6.1版本 注意Kibana版本要和ElasticSearch一致
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.1-windows-x86_64.zip
https://artifacts.elastic.co/downloads/kibana/kibana-7.6.1-windows-x86_64.zip
这里需要前端环境:Nodejs python
解压即用
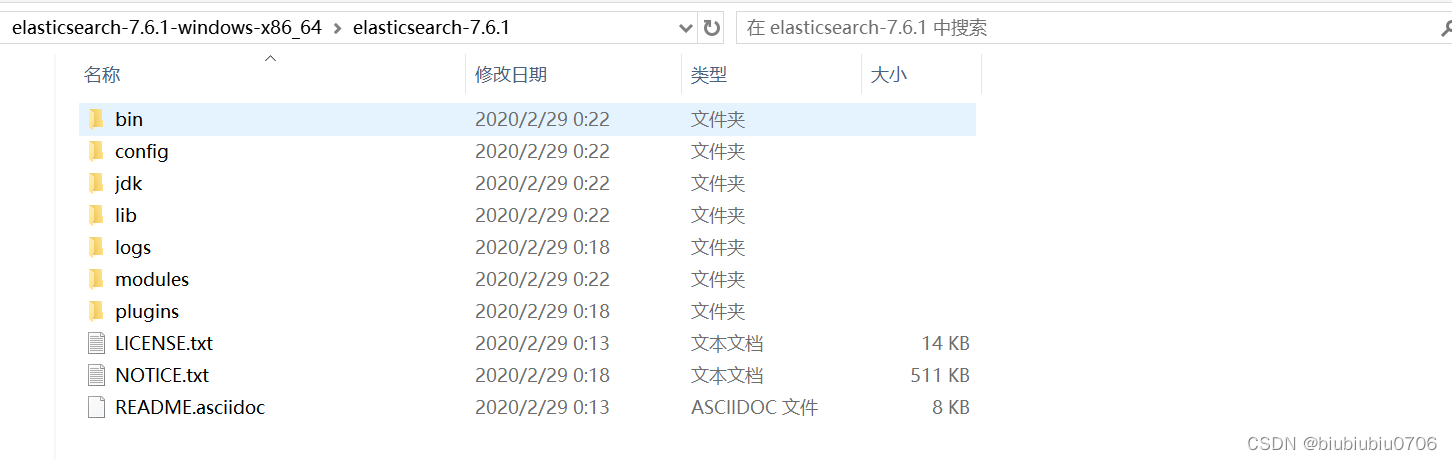
目录介绍
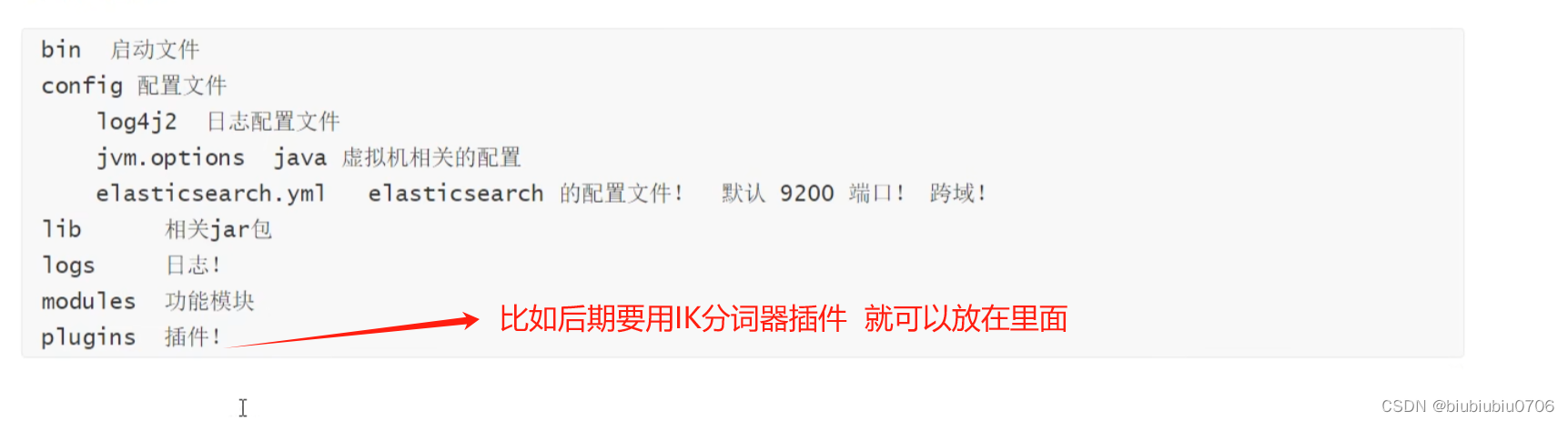 默认Elastic启动用1G内存 如果内存比较小 可以在jvm.options文件设置
默认Elastic启动用1G内存 如果内存比较小 可以在jvm.options文件设置
启动ES
双击


默认公开端口是9200(就是你通过RestFull API去调用的端口) 内部Elastic通信端口是9300
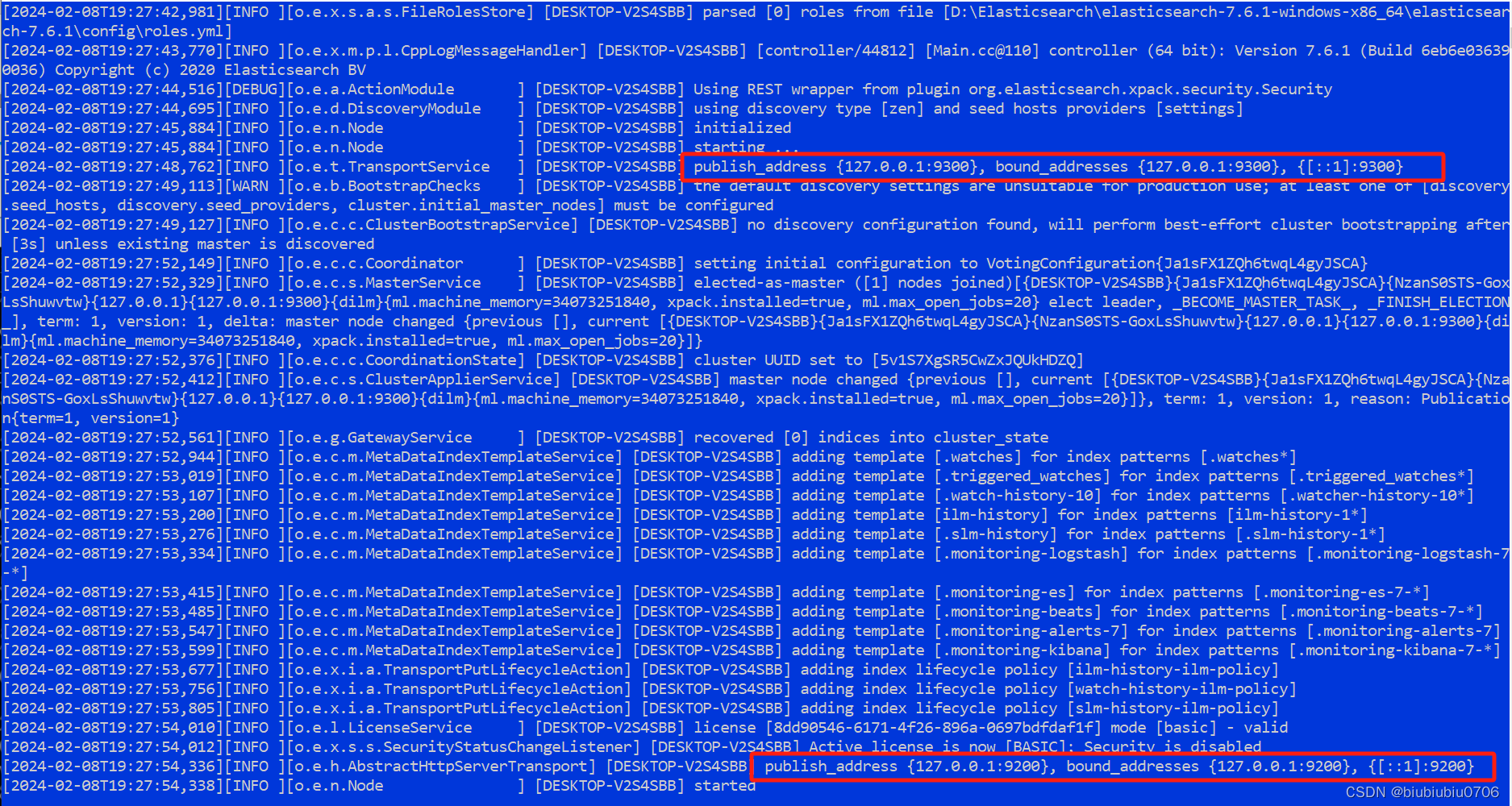
访问测试
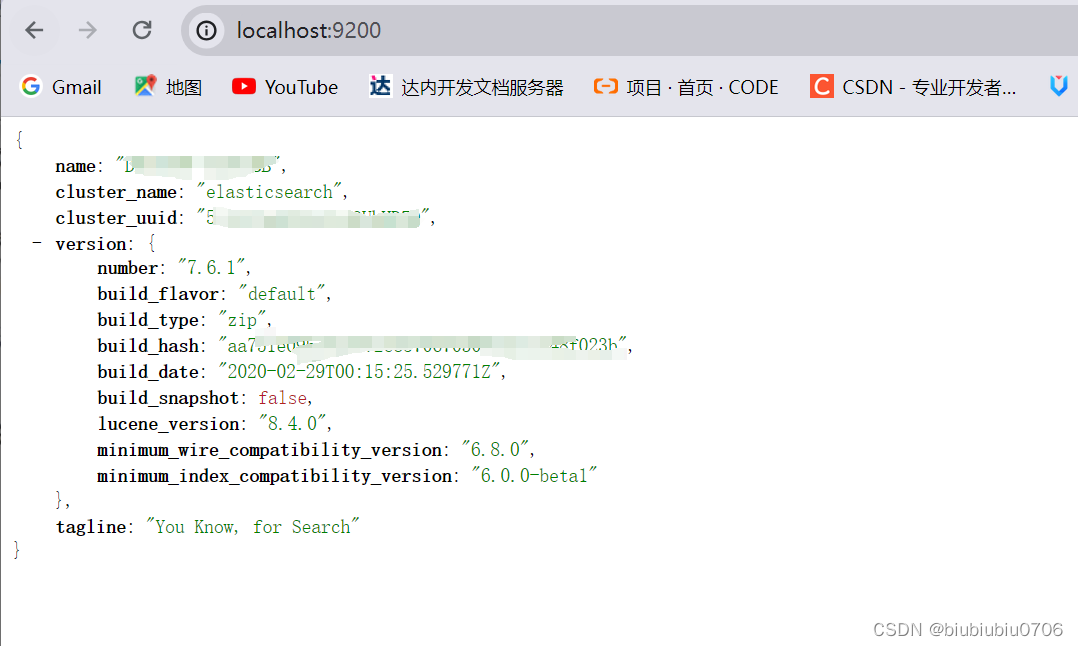
访问本机 localhost:9200端口试下
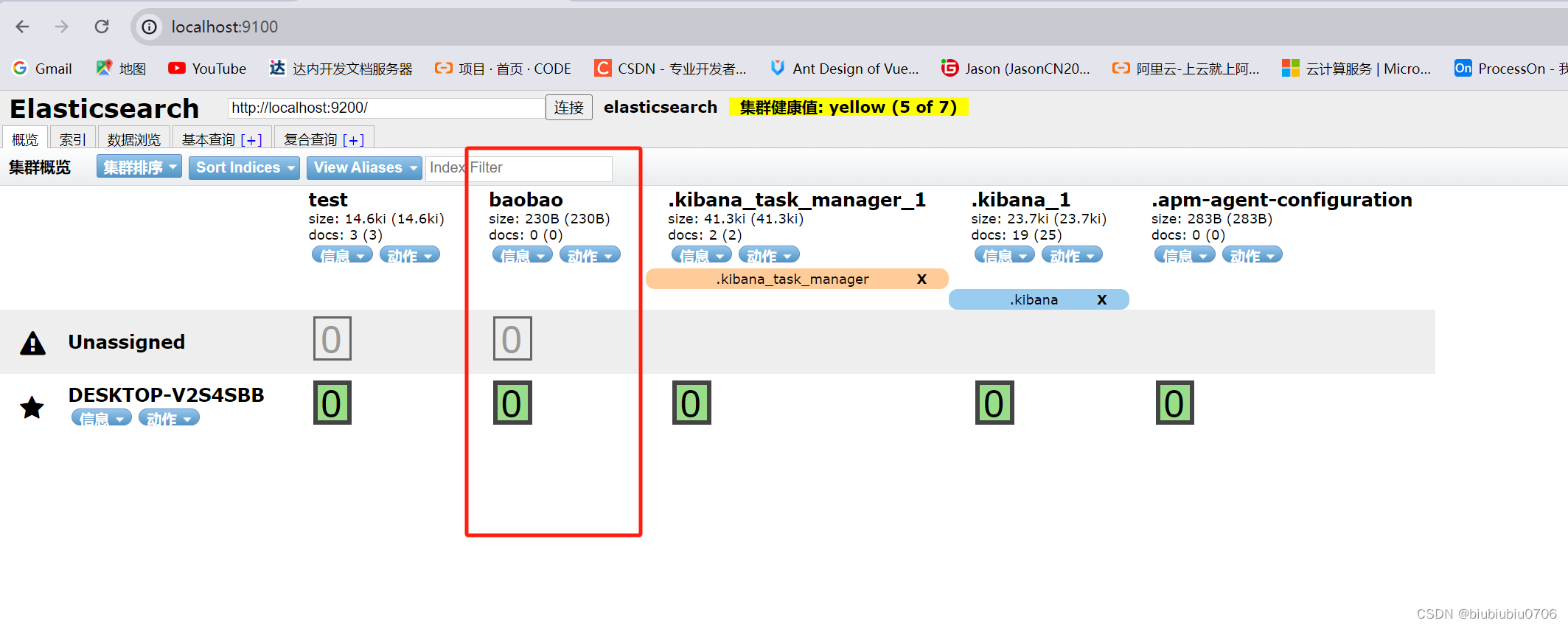
安装可视化界面 现在使用最多的是 elasticserach-head插件(此插件依赖Nodejs)
elasticserach-head是一款开源的可视化的elasticsearch可视化工具
github地址 这是个前端项目 一次要有nodejs环境
GitHub - mobz/elasticsearch-head: A web front end for an elastic search cluster
解压
 解压之后
解压之后
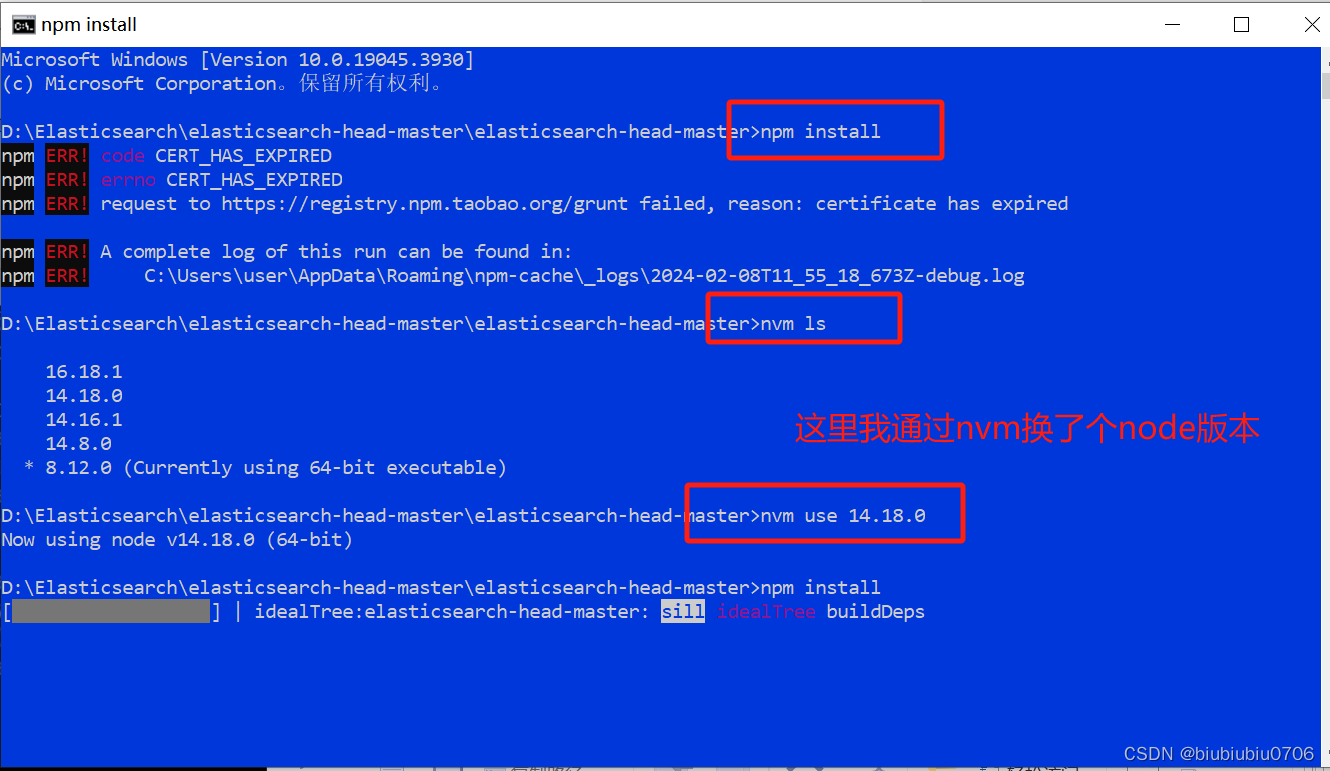
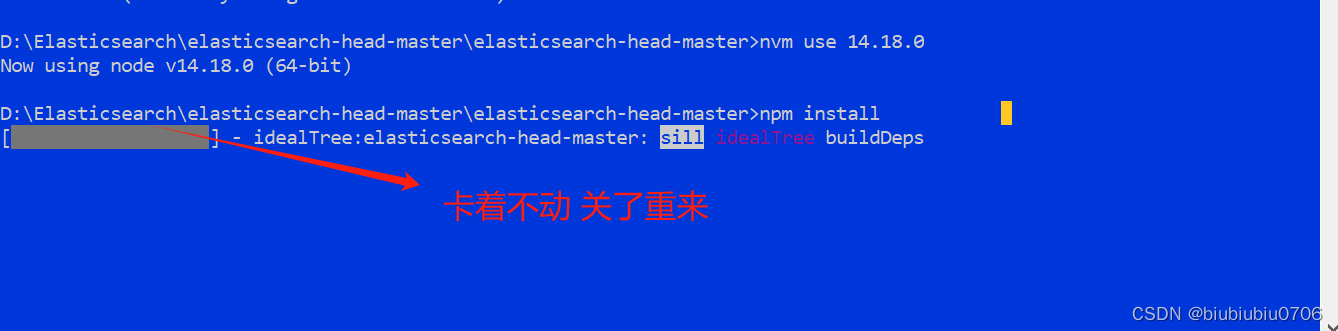
是淘宝镜像过期了
npm config set registry https://registry.npmmirror.com

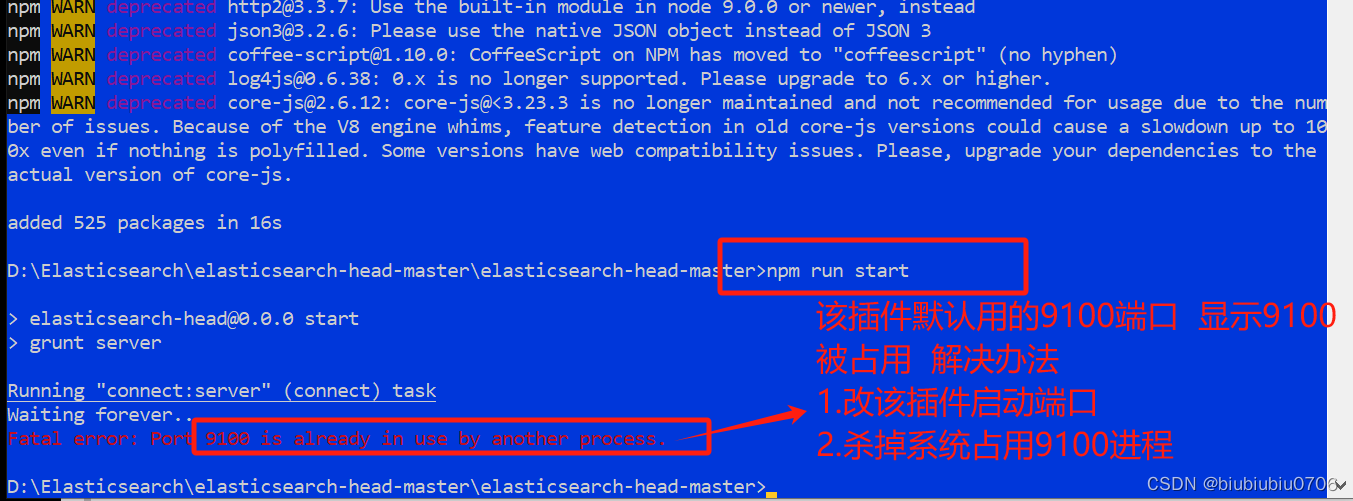
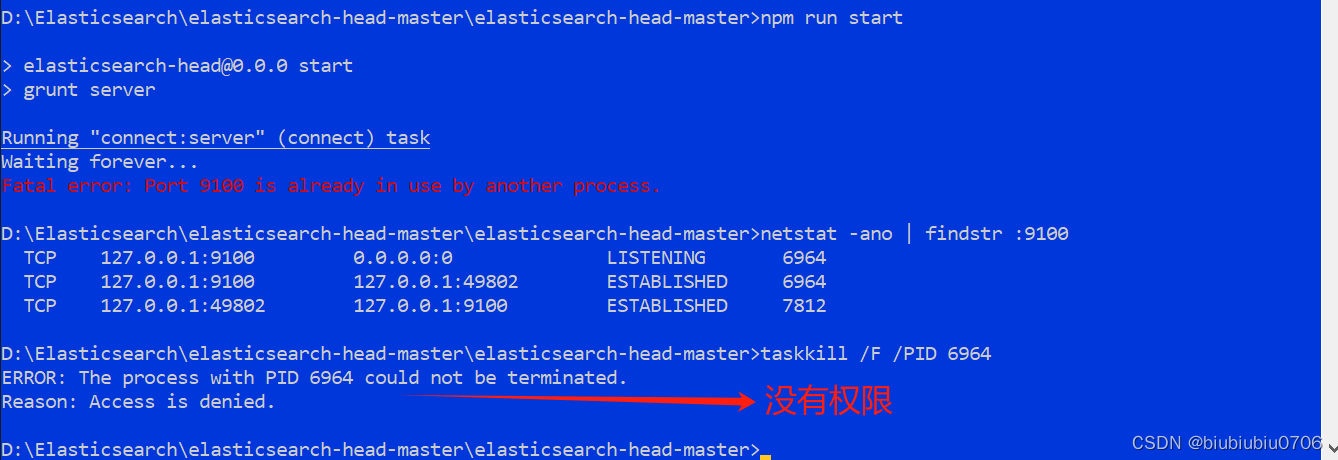
查看端口情况
netstat -ano | findstr :9100
杀掉指定PID进程
taskkill /F /PID 6964
看了下 是鼠标跟新占用了
启动
npm run start

访问
localhost:9100
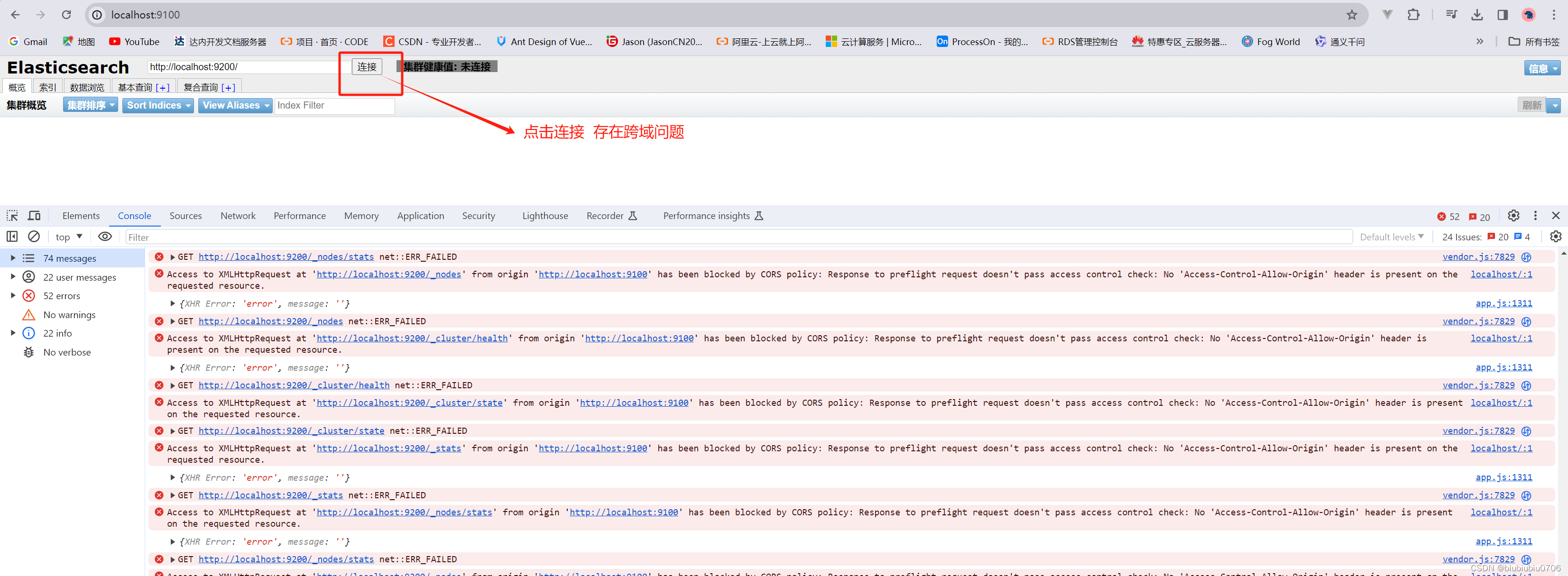
先关闭ElasticSearch
在ElasticSearch的config目录里的elasticsearch.yml文件中配置
http.cors.enabled: true
http.cors.allow-origin: "*"
注意空格

重启ElasticSearch

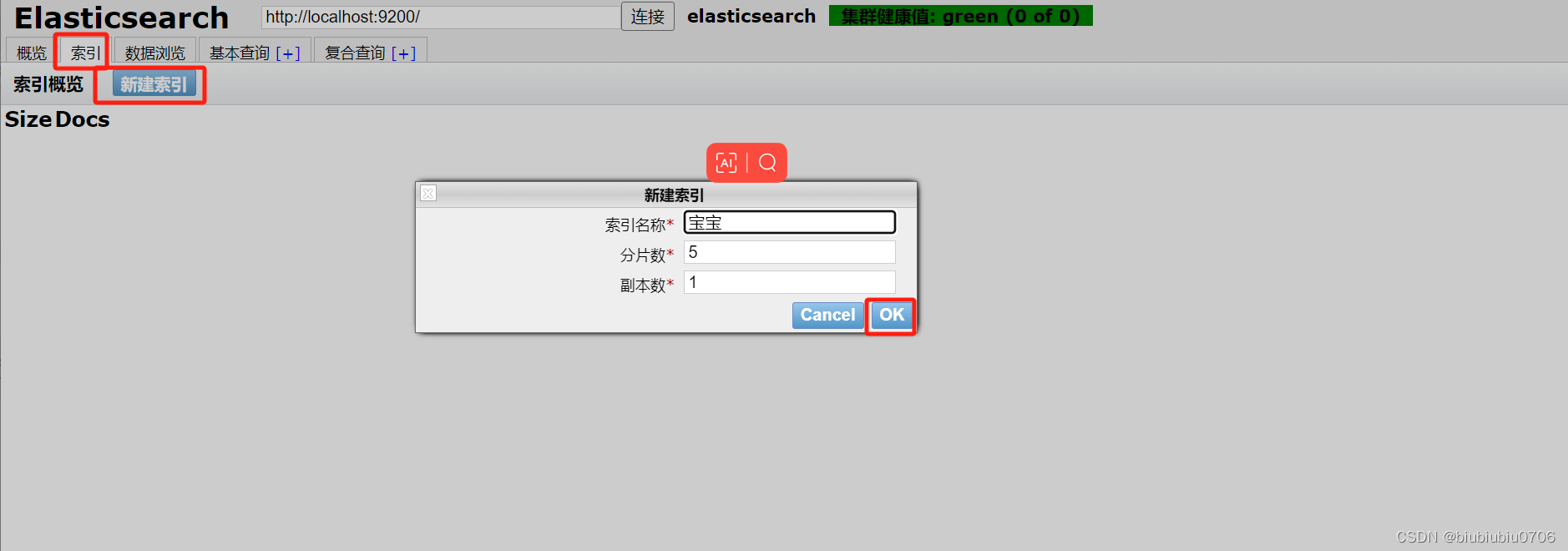
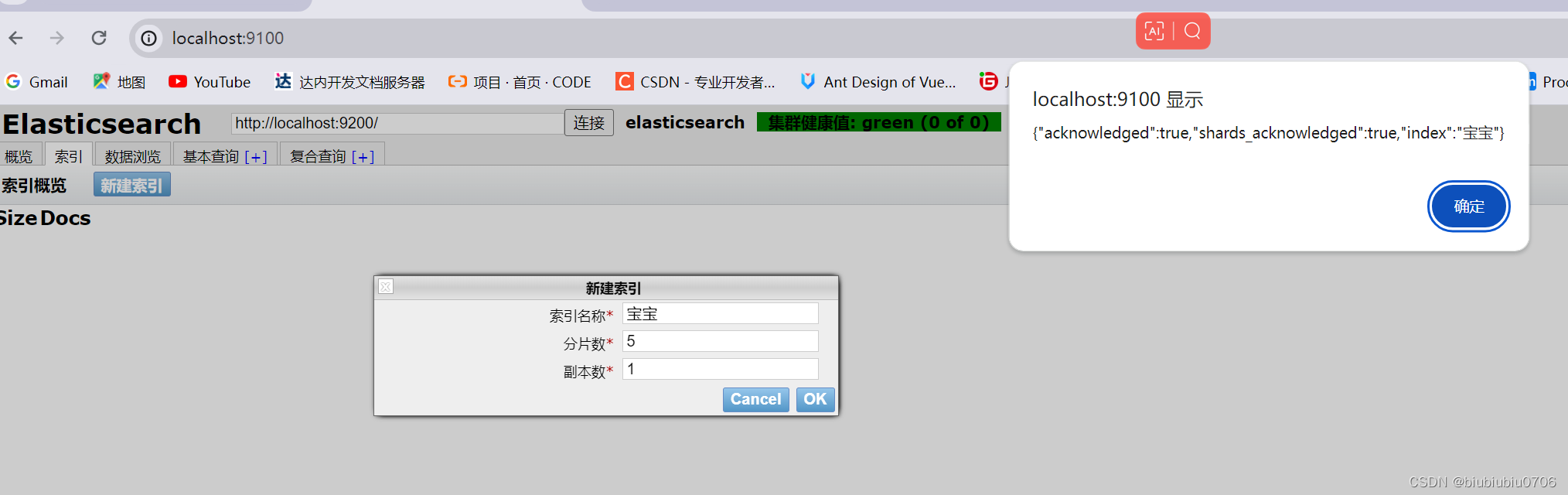
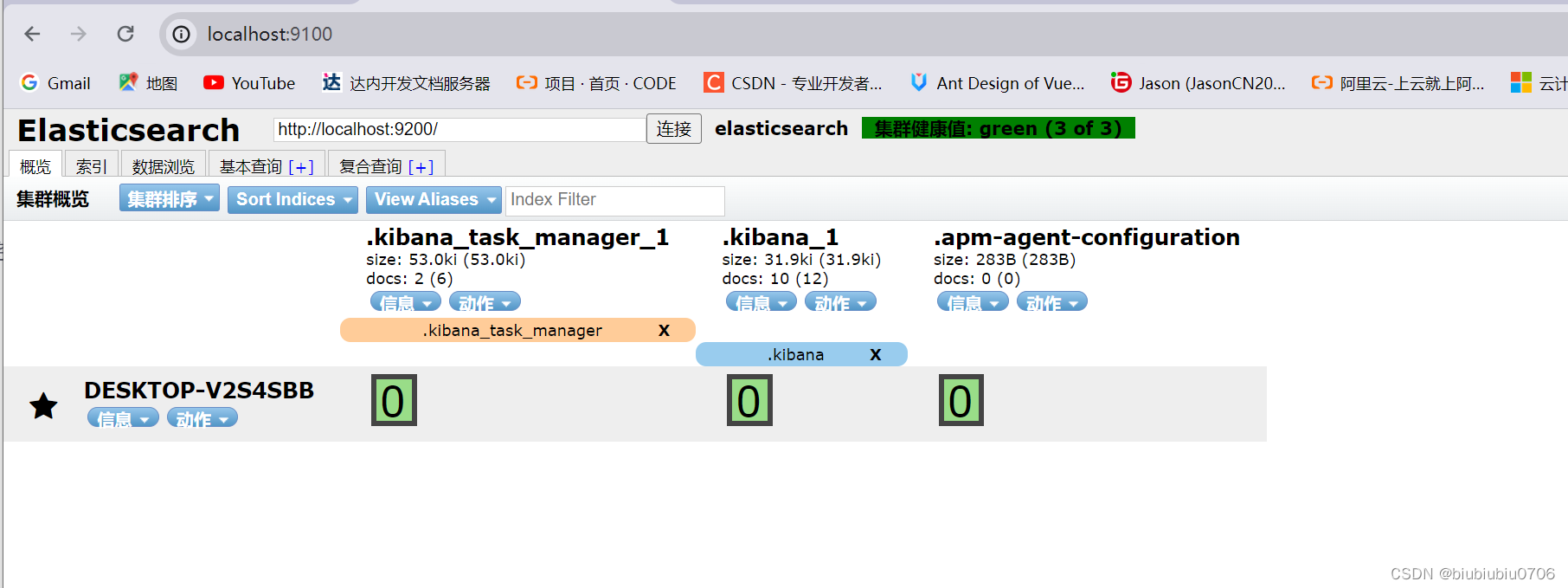
这里可以创建索引(暂时可以理解成建立数据库 文档是库中的数据)
暂时把elasticsearch-head当成一个创建索引(创建数据库) 数据展示工具
关于查询 后期会放到kibana中去做
Kibana安装
先了解下ELK->ElasticSearch+Logstash+Kibana
ElasticSearch:是一个基于Lucene,分布式,通过RestFul方式进行交互的近实时搜索平台框架.像百度,谷歌这种大数据全文搜索引擎的场景都可以使用ElasticSearch做为底层支持框架.
Logstash:是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/Redis/ElasticSearch/Kafka等)
Kibana:可以将Elasticsearch的数据通过友好的页面展示出来,提供实时分析功能
注意:很多人认为ELK它是一个日志分析架构技术栈.实际上ELK支持任何数据分析和收集.只不过日志分析和收集更具有代表性.但非唯一性
总的来讲就是 Logstash(收集清洗数据)->ES(存储分析数据)->Kibana(可视化展示数据)
Kibana也是解压即可以用解压比较慢(内容很多)
双击启动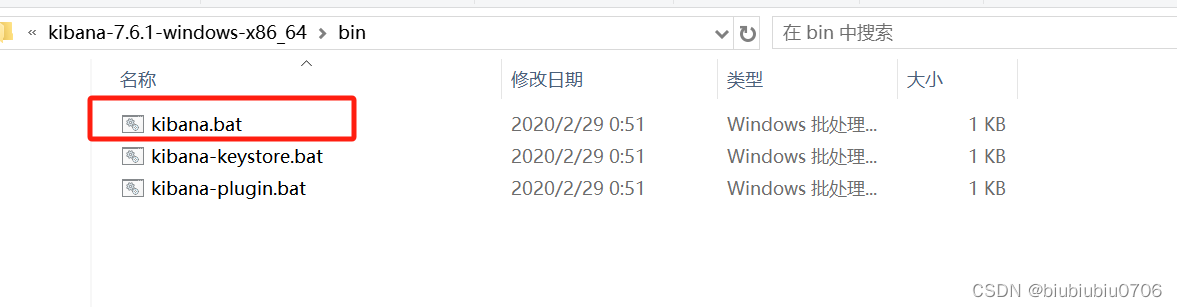
默认启动端口5601
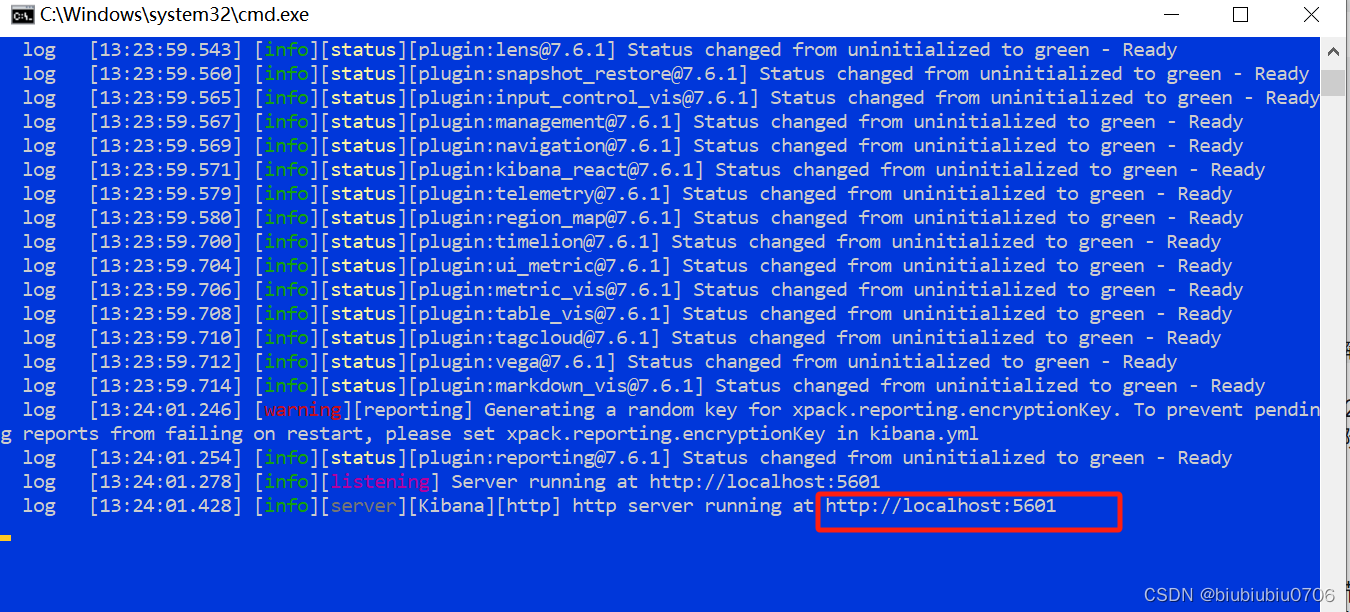
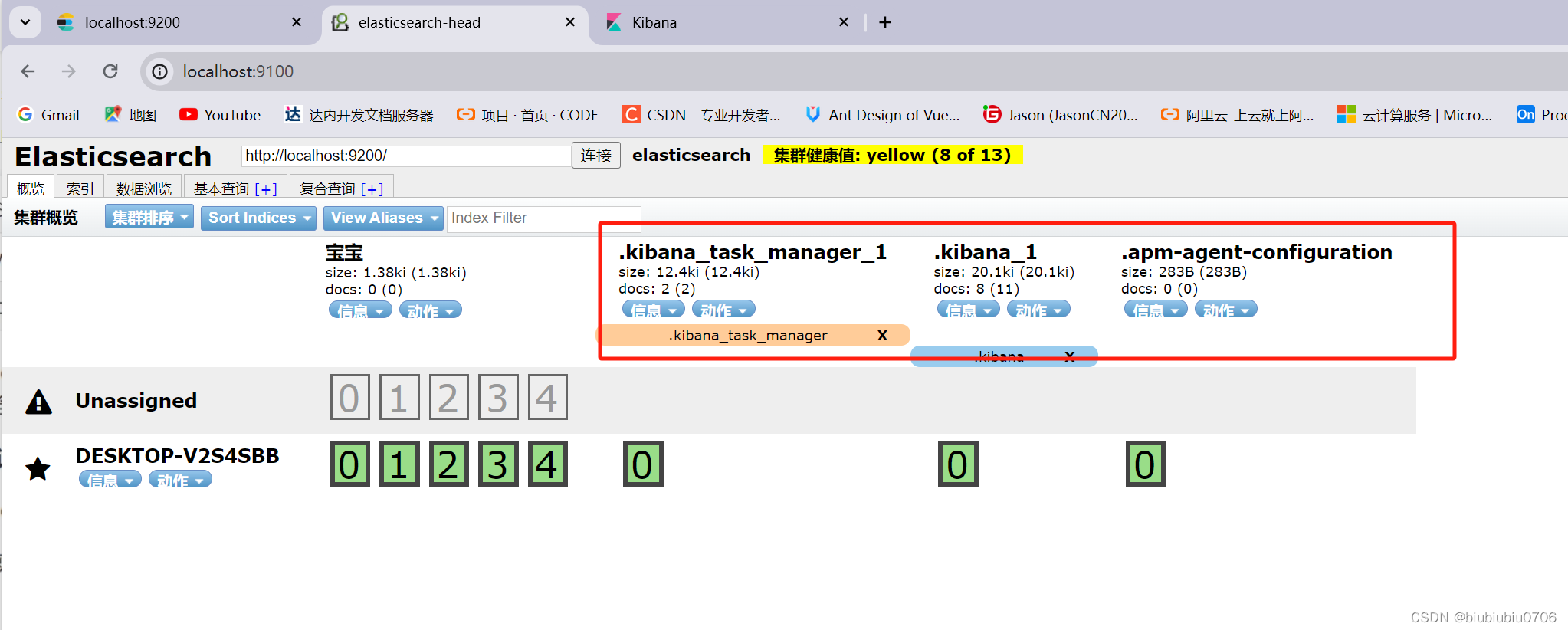
注意:Kibana启动后 在elasticsearch-head中多了这三个
访问
localhost:5601
Kibana汉化 打开config里的kibana.yml 然后重启Kibana
ES核心概念:
ElasticSearch是面向文档的

物理设计:ElasticSearch在后台把每个索引划分成多个分片.每个分片可以在集群中不同服务器迁移
逻辑设计:一个索引类型中,包含多个文档.当我们搜索一个文档时,通过索引->类型->文档ID的顺序搜索到某个具体的文档.ID不必是整数,实际是一个字符串.

Lucene用的是倒排索引
一个索引就好比一个数据库
ElasticSearch的索引和Lucene索引对比
ElasticSearch中索引被分为多个分片,每个分片是一个Lucene索引.所以一个ElasticSearch索引是由多个Lucene索引组成的.
IK分词器插件:
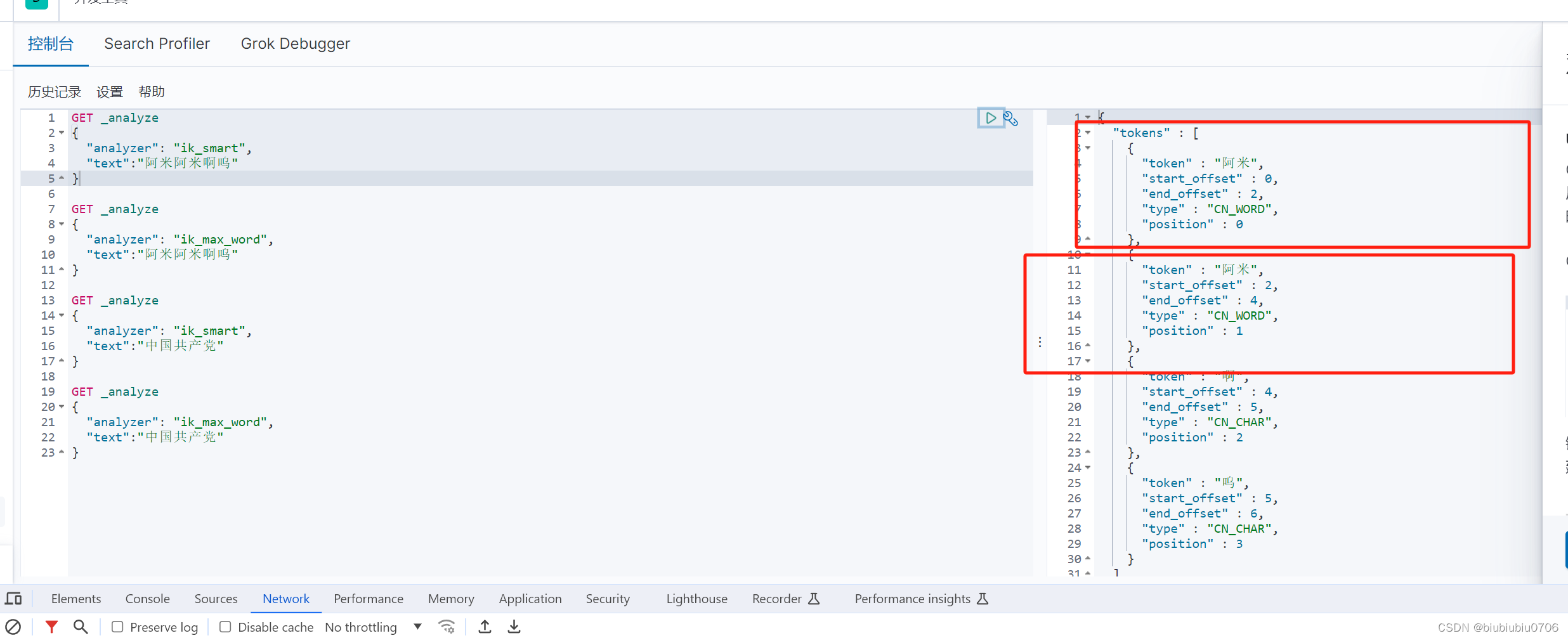
分词:即把一段中文或者别的划分为一个个的关键字,搜索时候会把信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个个匹配操作.默认的中文分词是将每个字看成一个词.比如"阿米阿米啊呜"会被分为"阿","米","阿","米","啊","呜".这样可能不符合我们要求.所以需要安装分词器来解决这个问题
IK分词器主要解决中文
IK分词器提供了两种分词算法:
ik_start:最少切分
ik_max_word:最细粒度划分
Github地址:
Release v7.6.1 · medcl/elasticsearch-analysis-ik · GitHub
选择和ElasticSearch版本相同的
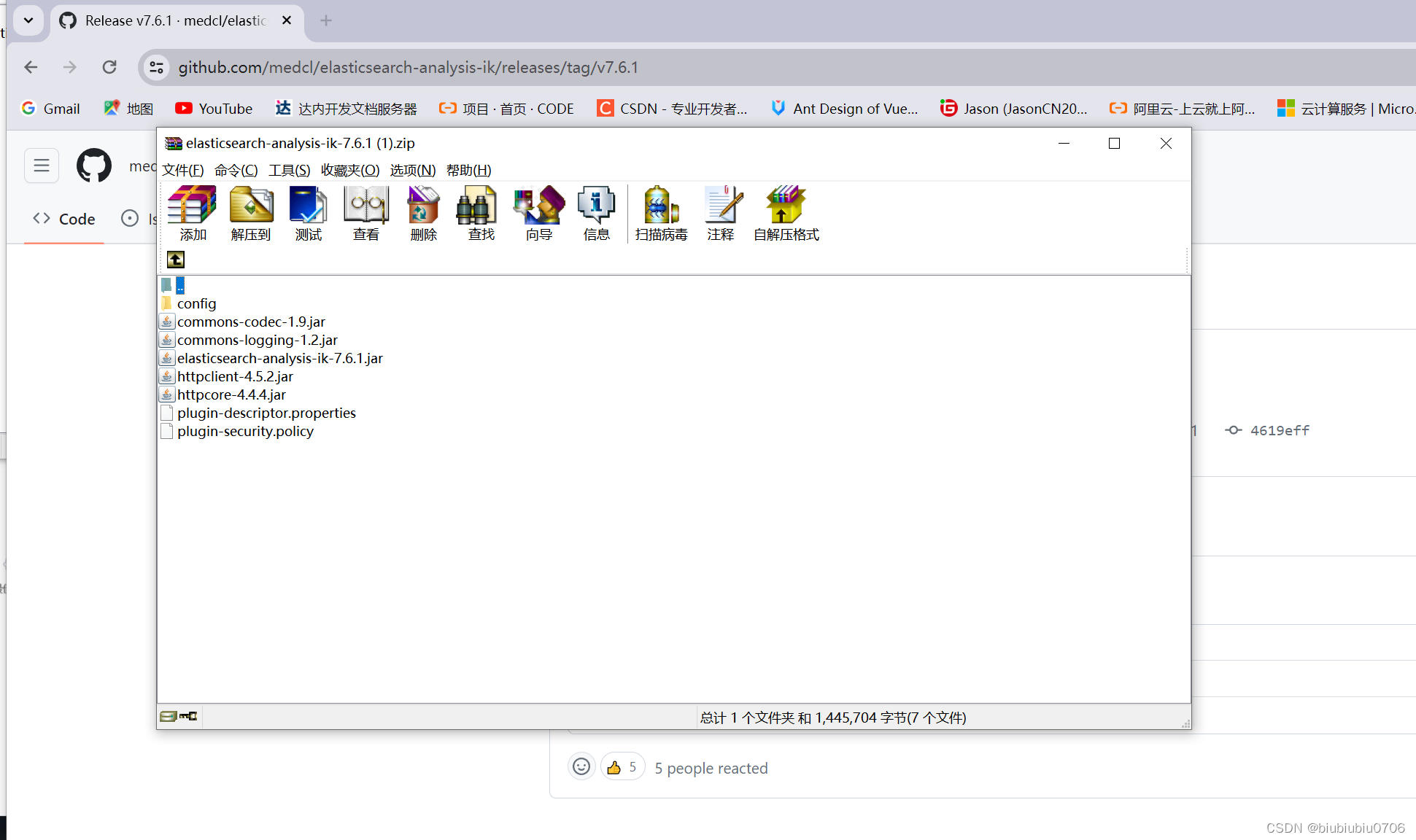
在ElasticSearch的plugins目录新建ik文件夹 将文件加压到ik文件
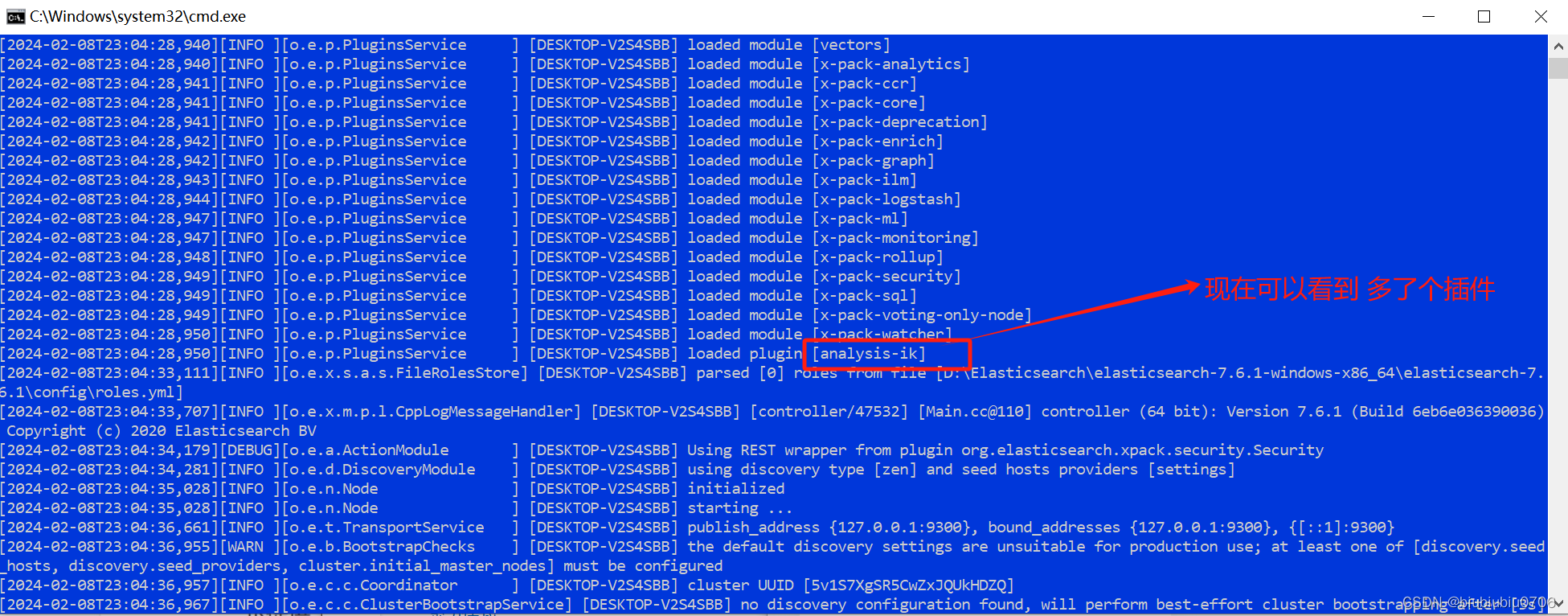
关了所有
一个个重启
ElastisSearch启动时候多了个插件
启动Kibana
你也可以用postMan 专业的事让专业工具做 Kibana本身就是干这个的
IK分词器提供了两种分词算法:
ik_start:最少切分
ik_max_word:最细粒度划分
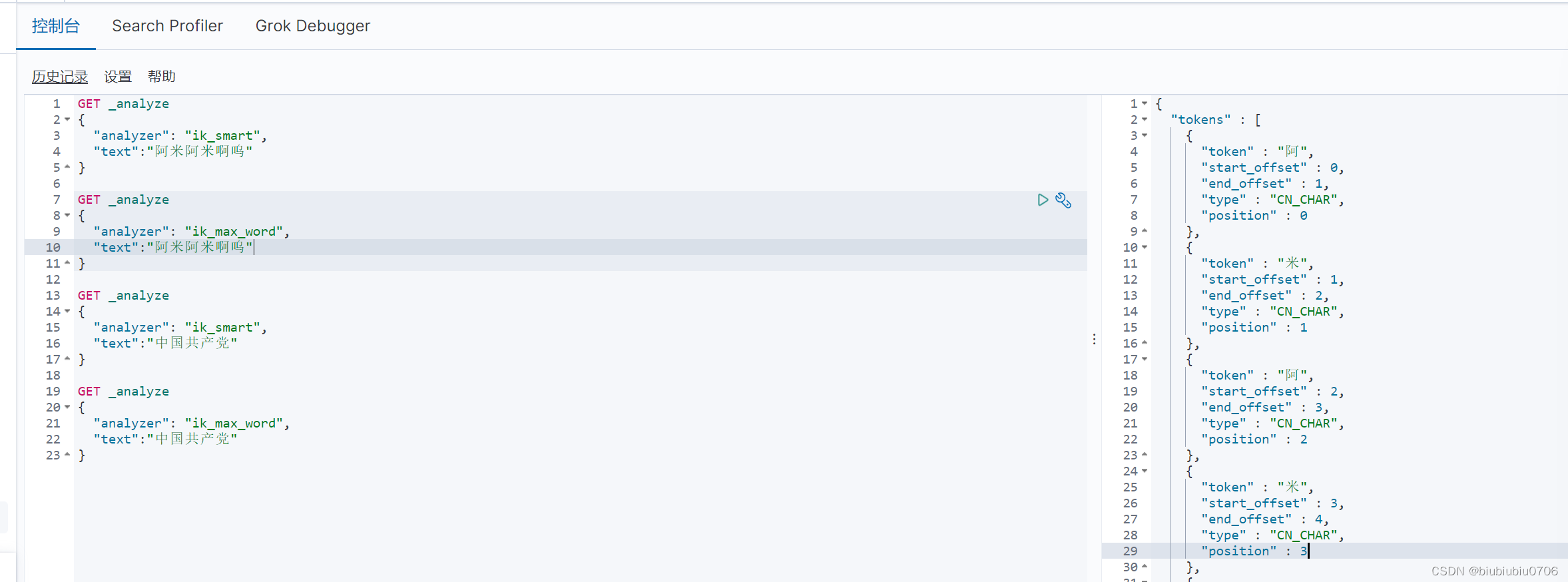
IK分词器设置数据字典
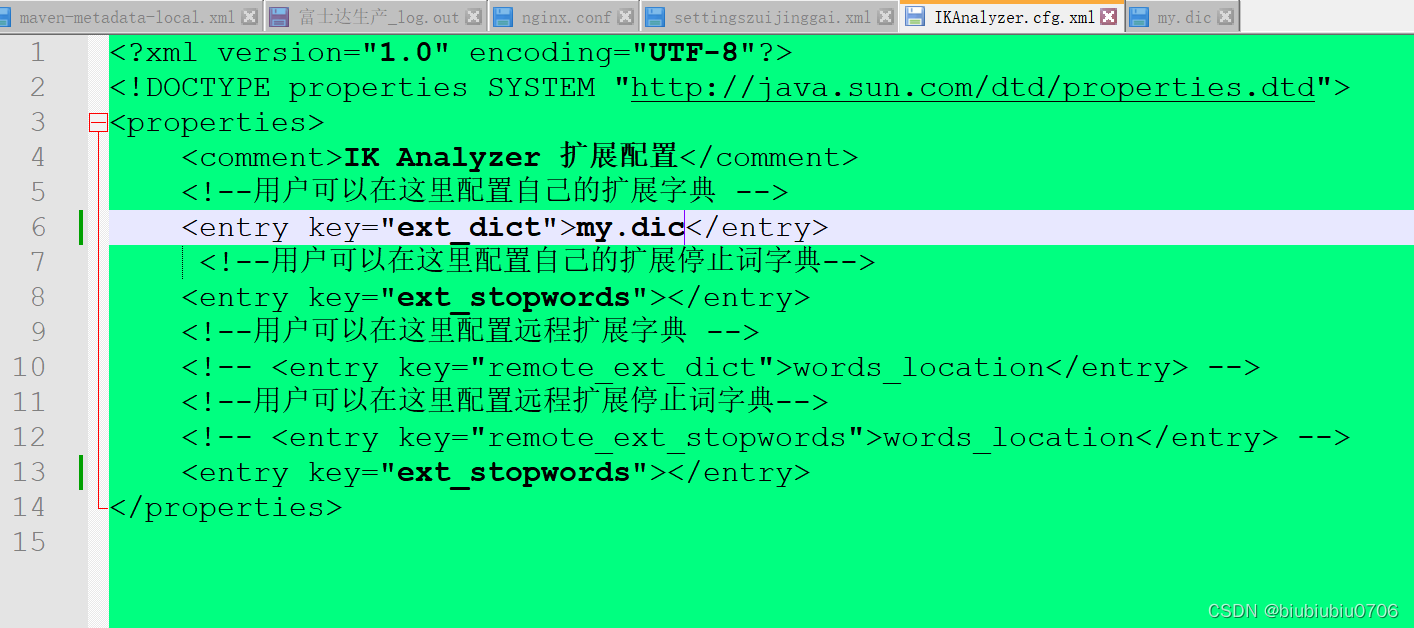
重启ElasticSearch
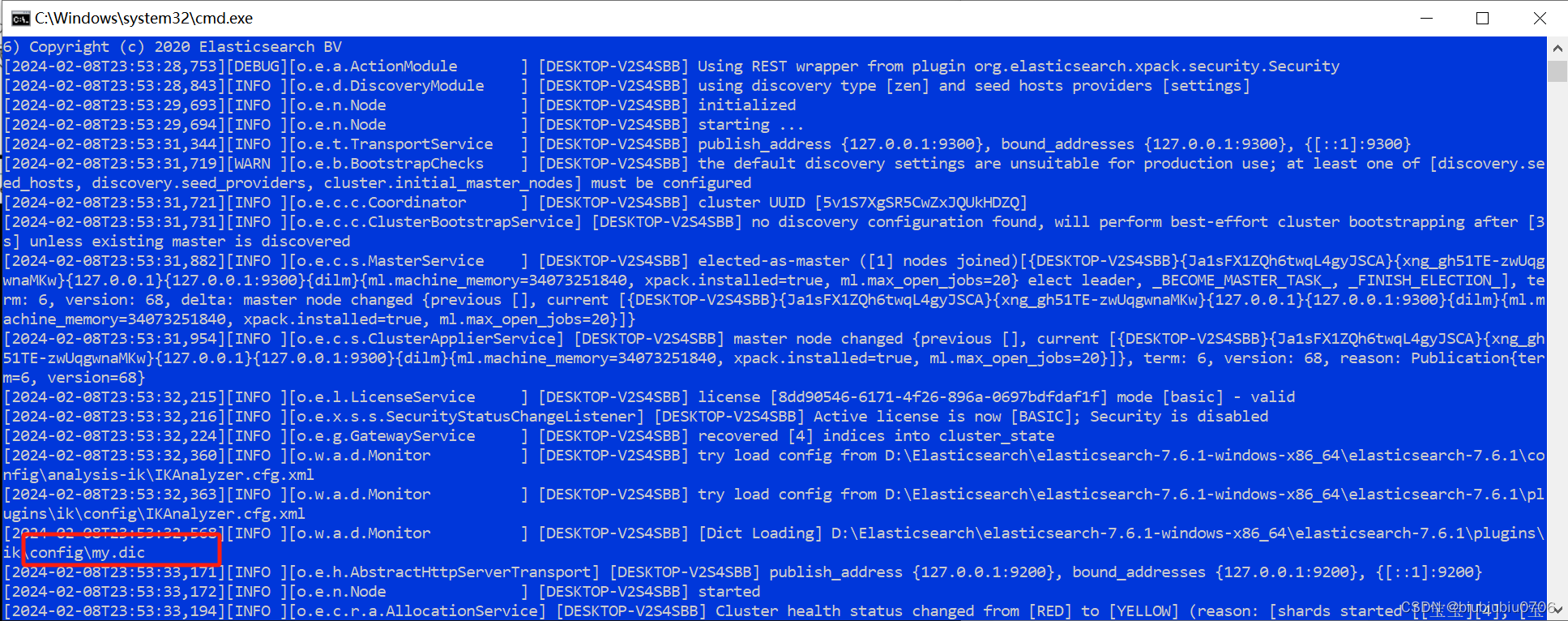
重启Kibana
再测试
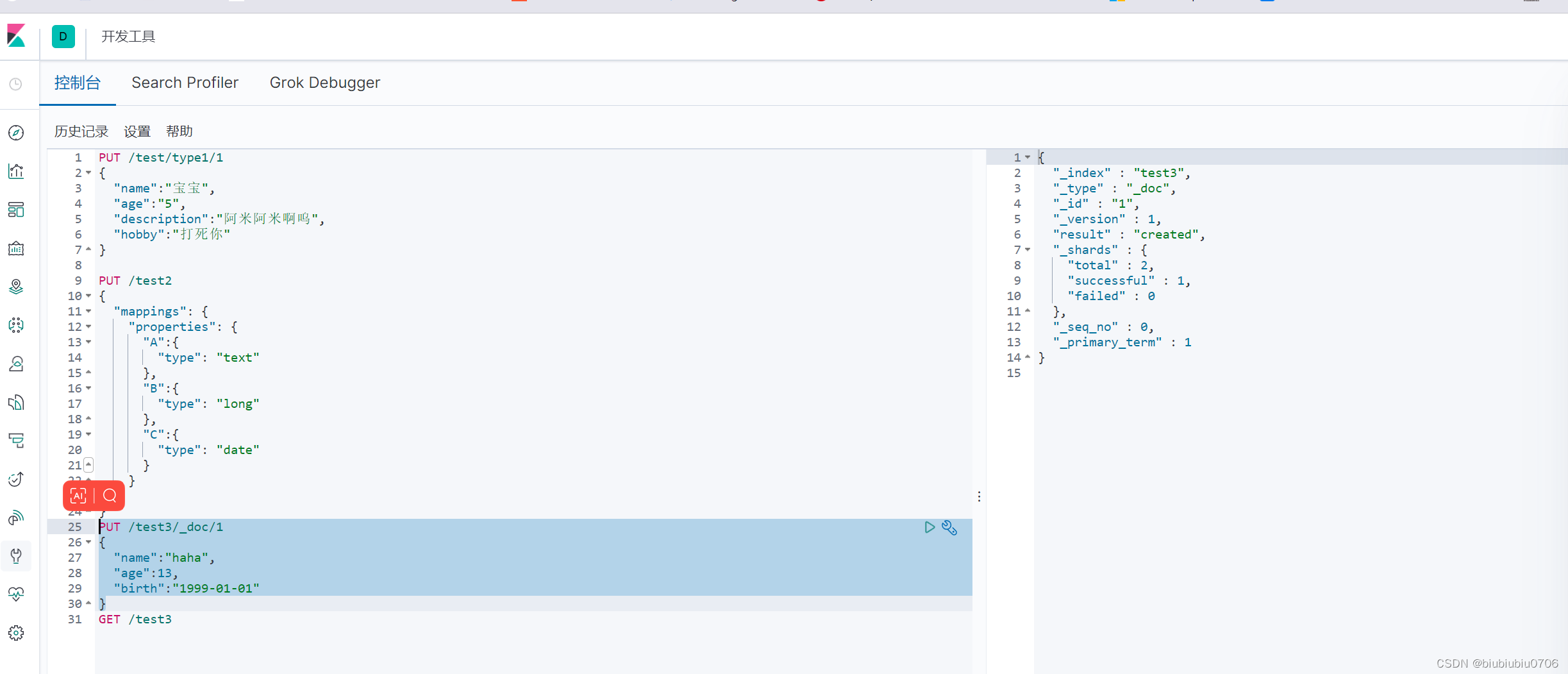
创建索引
启动elasticsearch-head
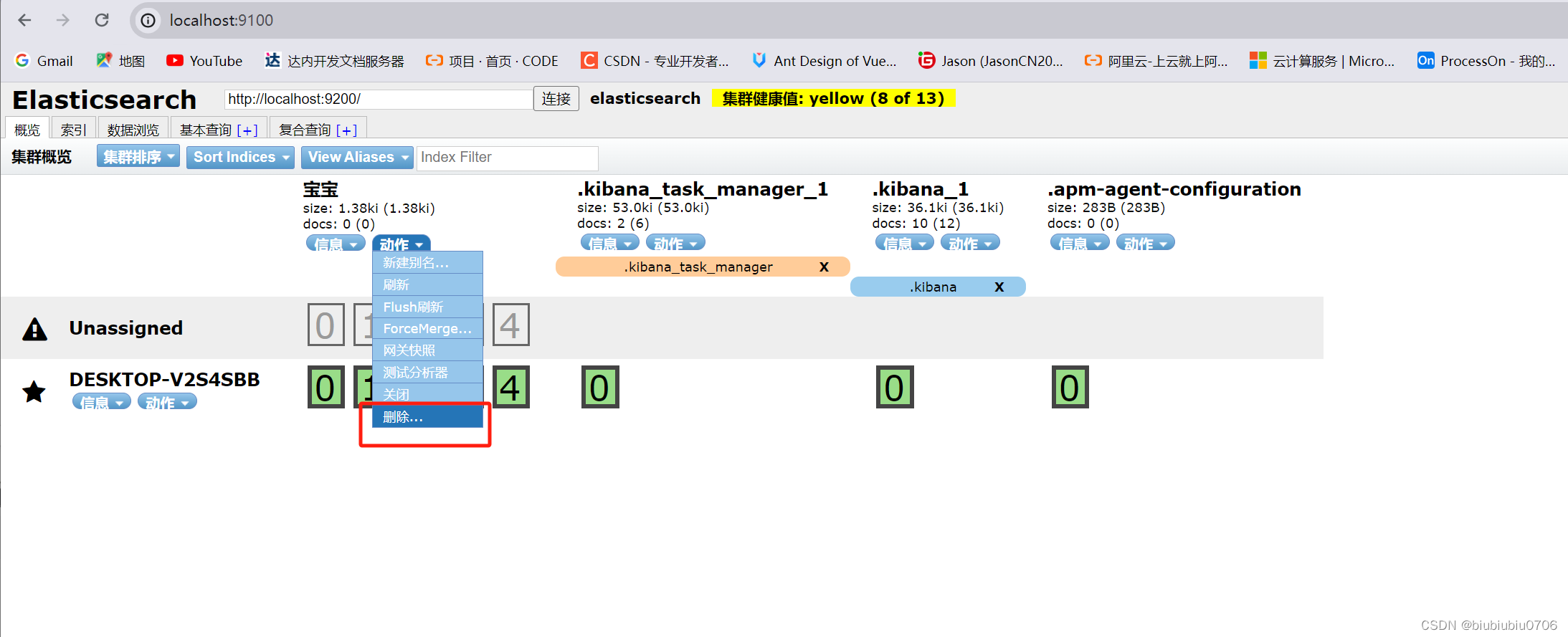
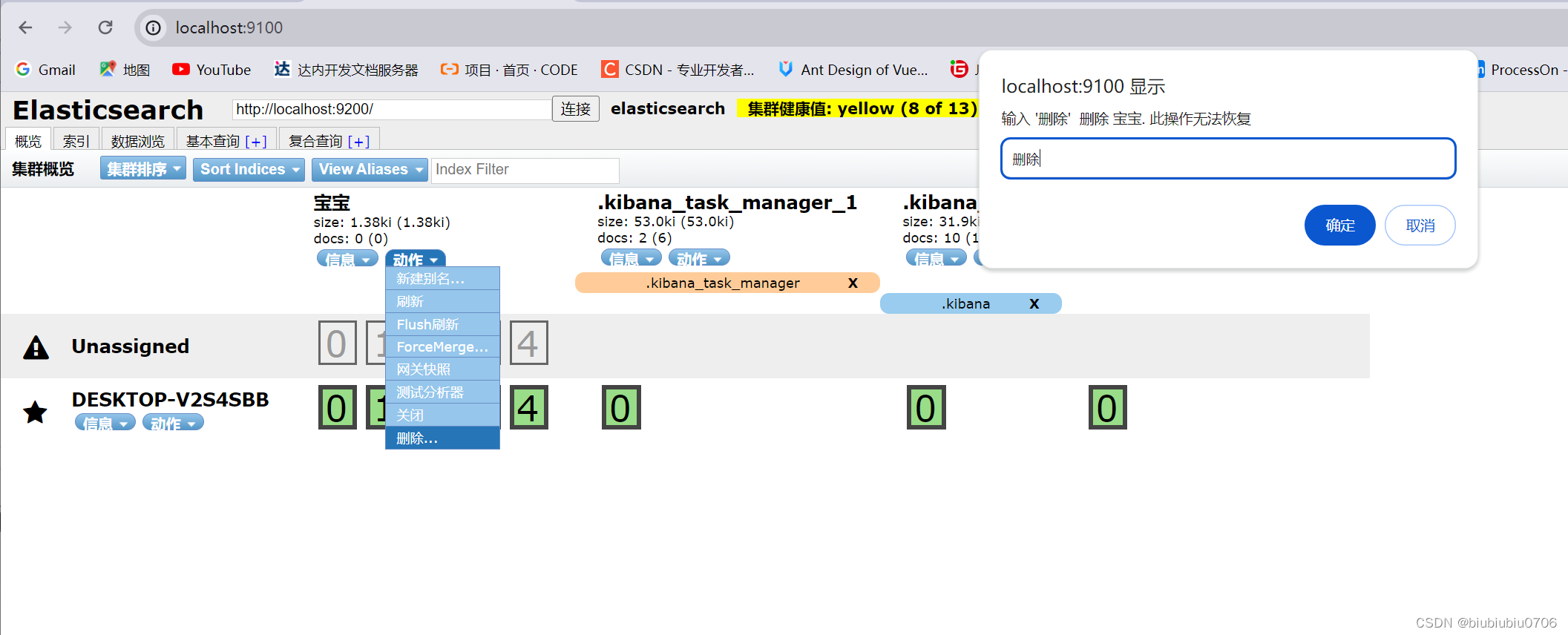
剩下三个库是Kibana自带的
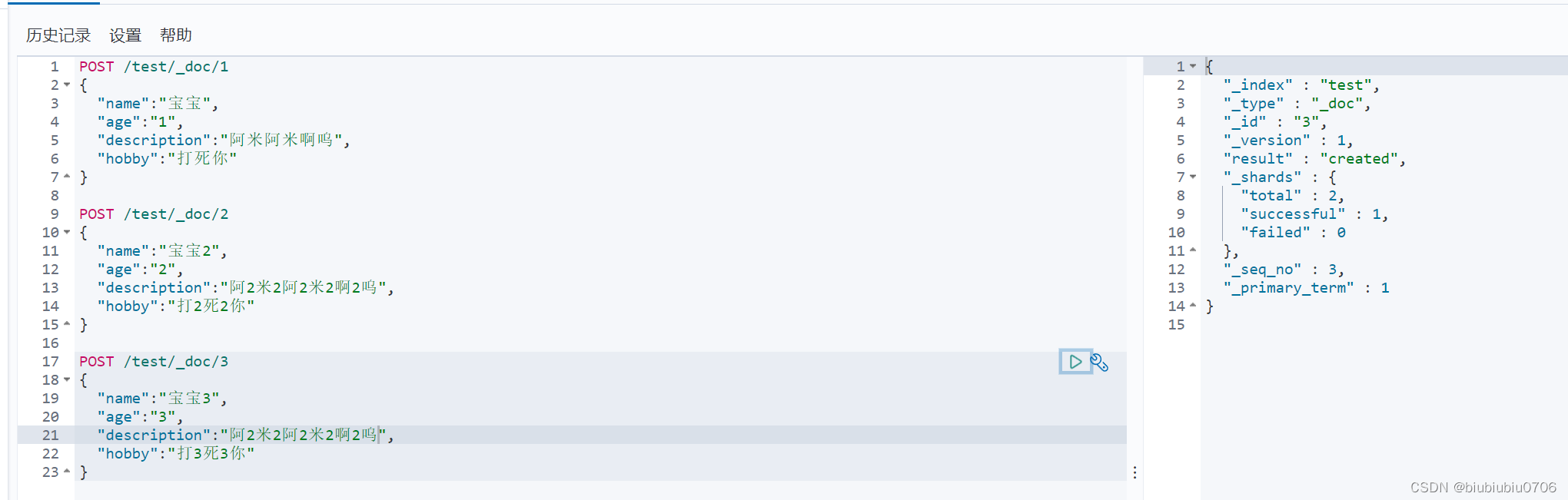
创建索引
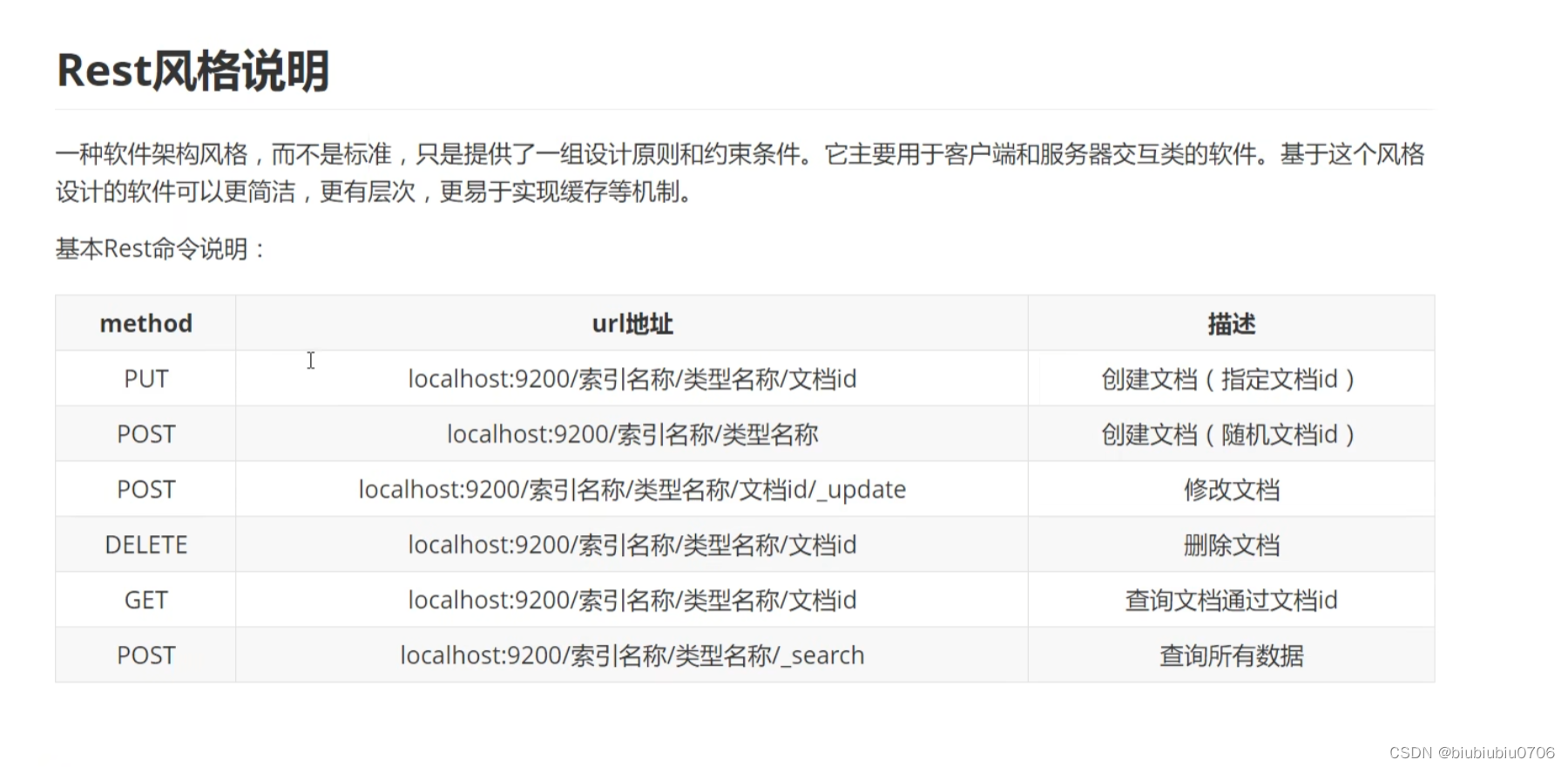
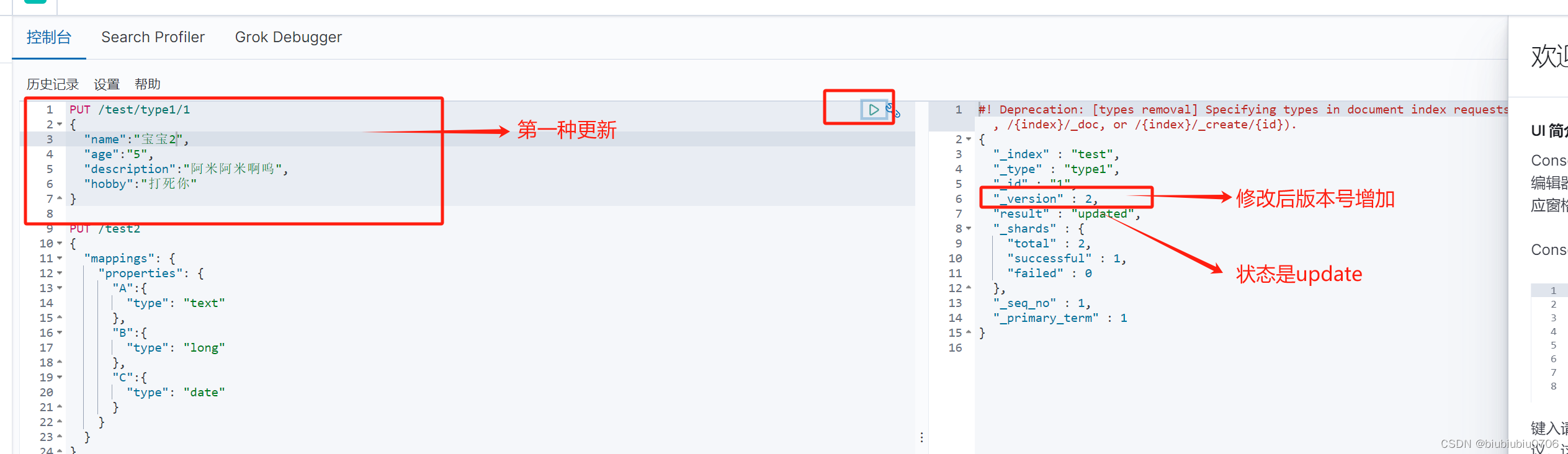
PUT /索引名/类型名/文档id PUT /test/type1/1 (POST /test/type1/1 也可以 )
POST /test/type1 就是随机文档ID
{请求体}
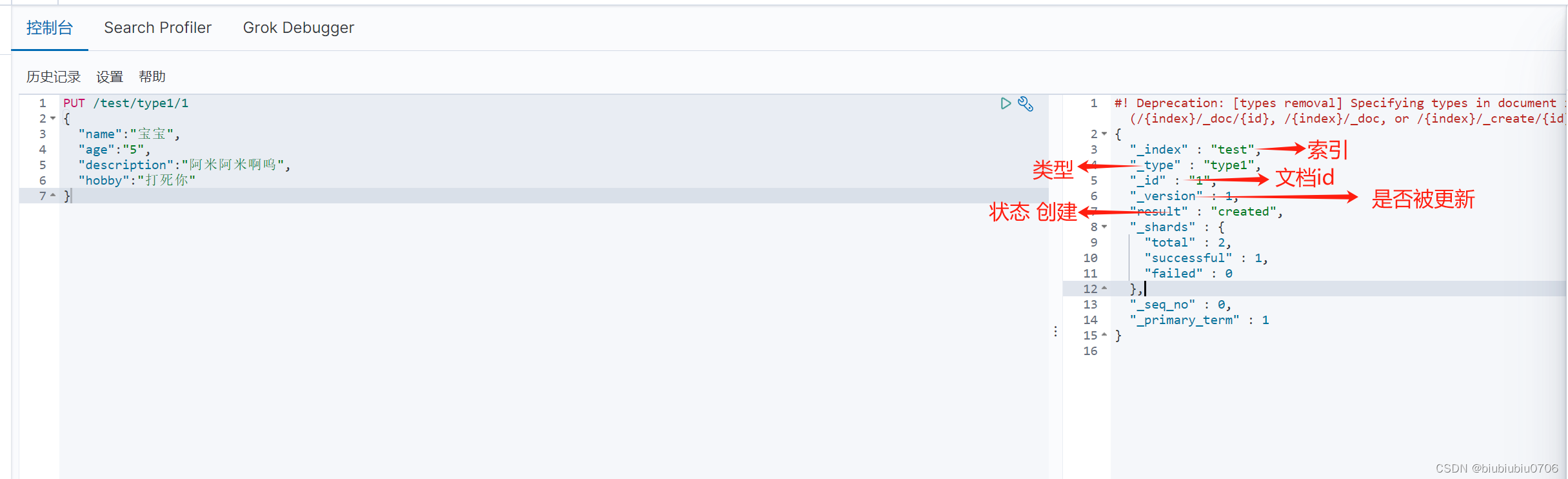
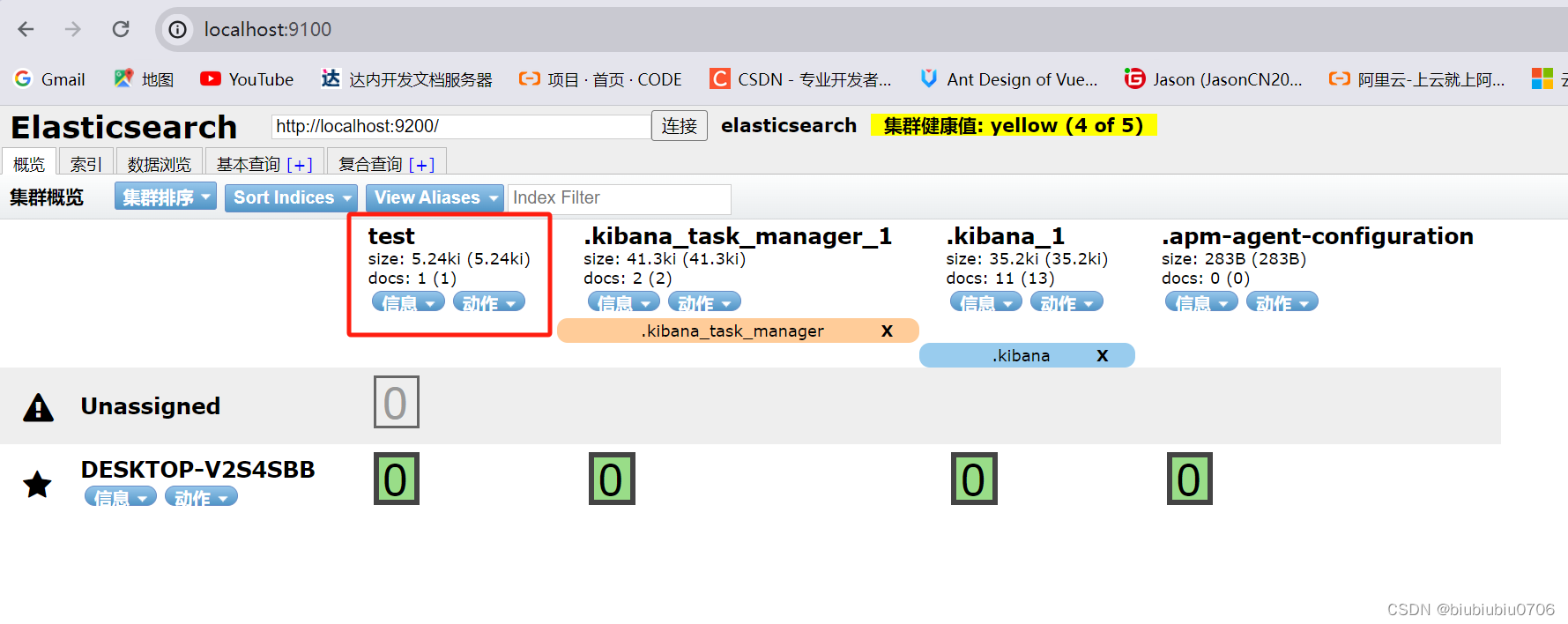
完成了自动增加索引 数据也成功添加 初期将索引当成数据库
那么可以有个想法,把所有数据放进去 以后在查出来

关于字段类型

如何指定字段类型 上面我们指定了字段名并没有指定字段类型
创建索引并给索引加字段名和字段类型

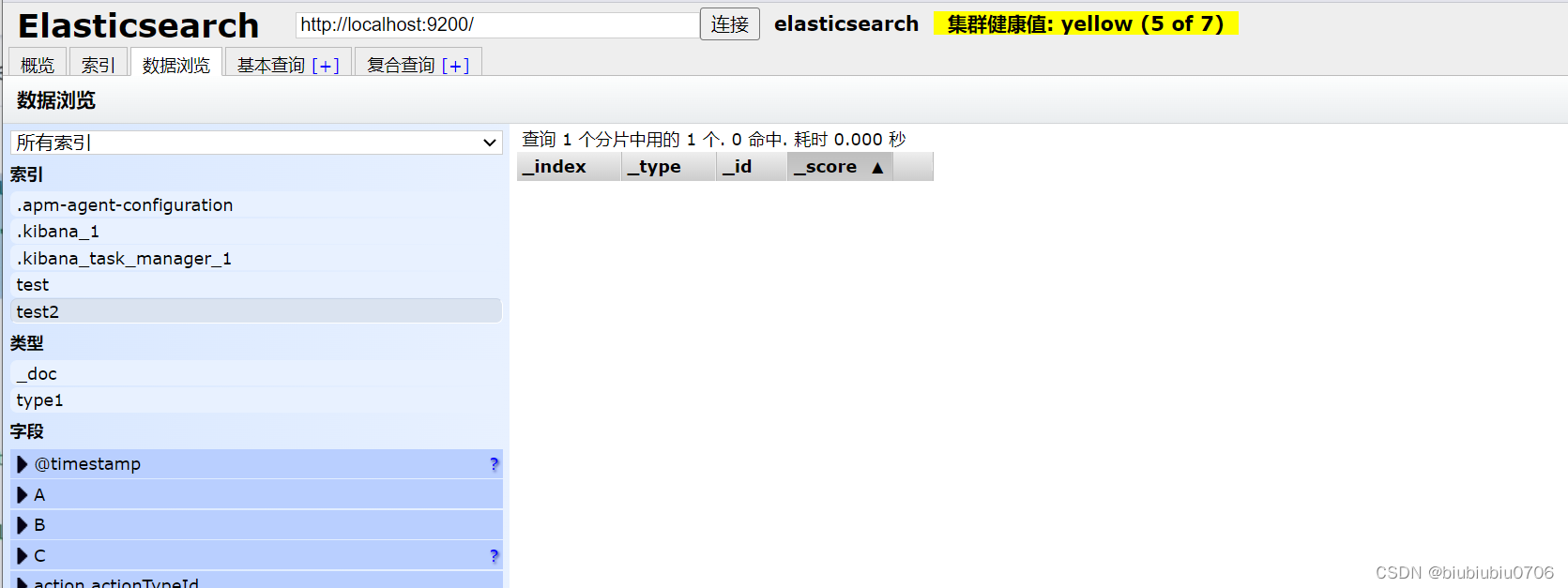
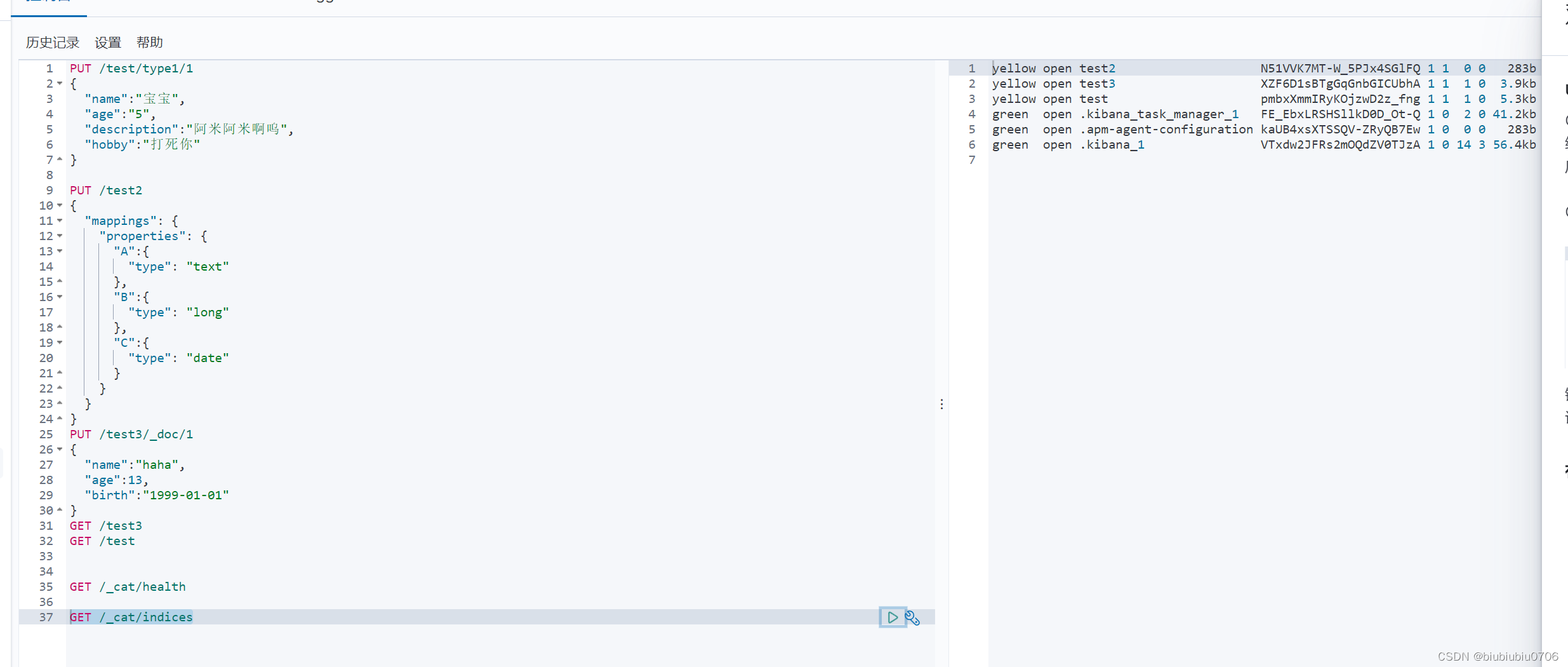
获取索引信息(数据库信息)
GET /test2
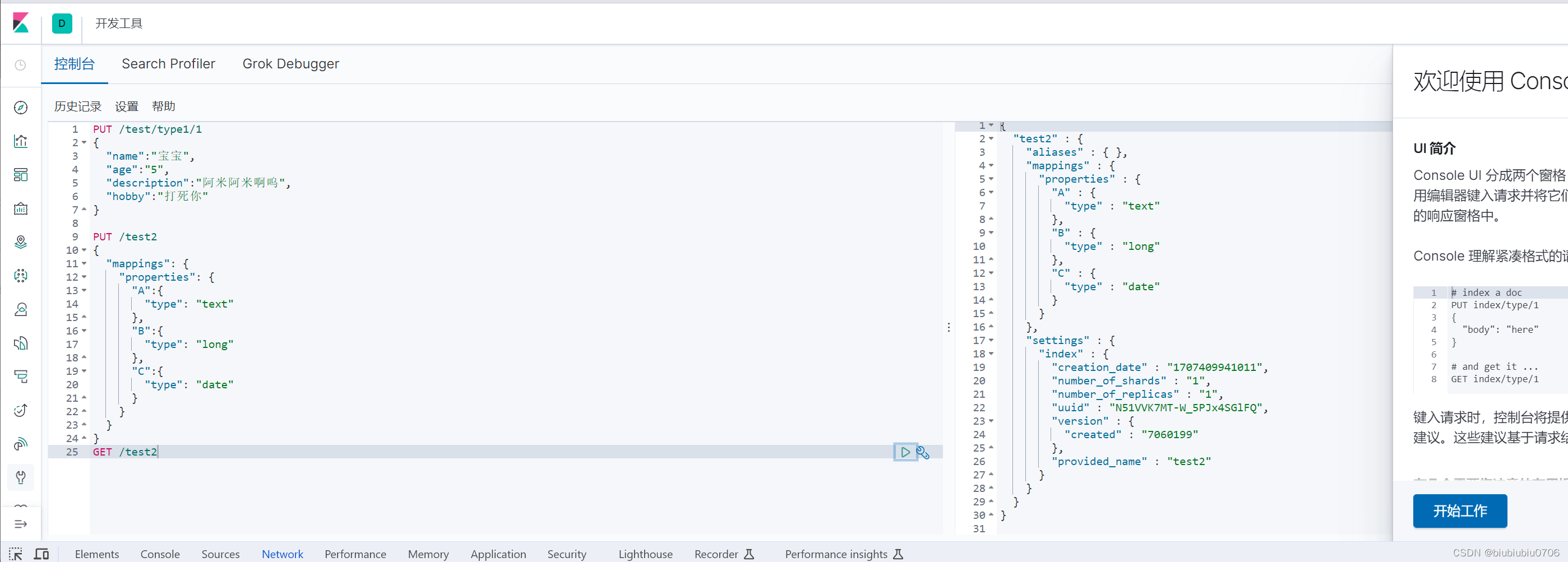
查看默认信息
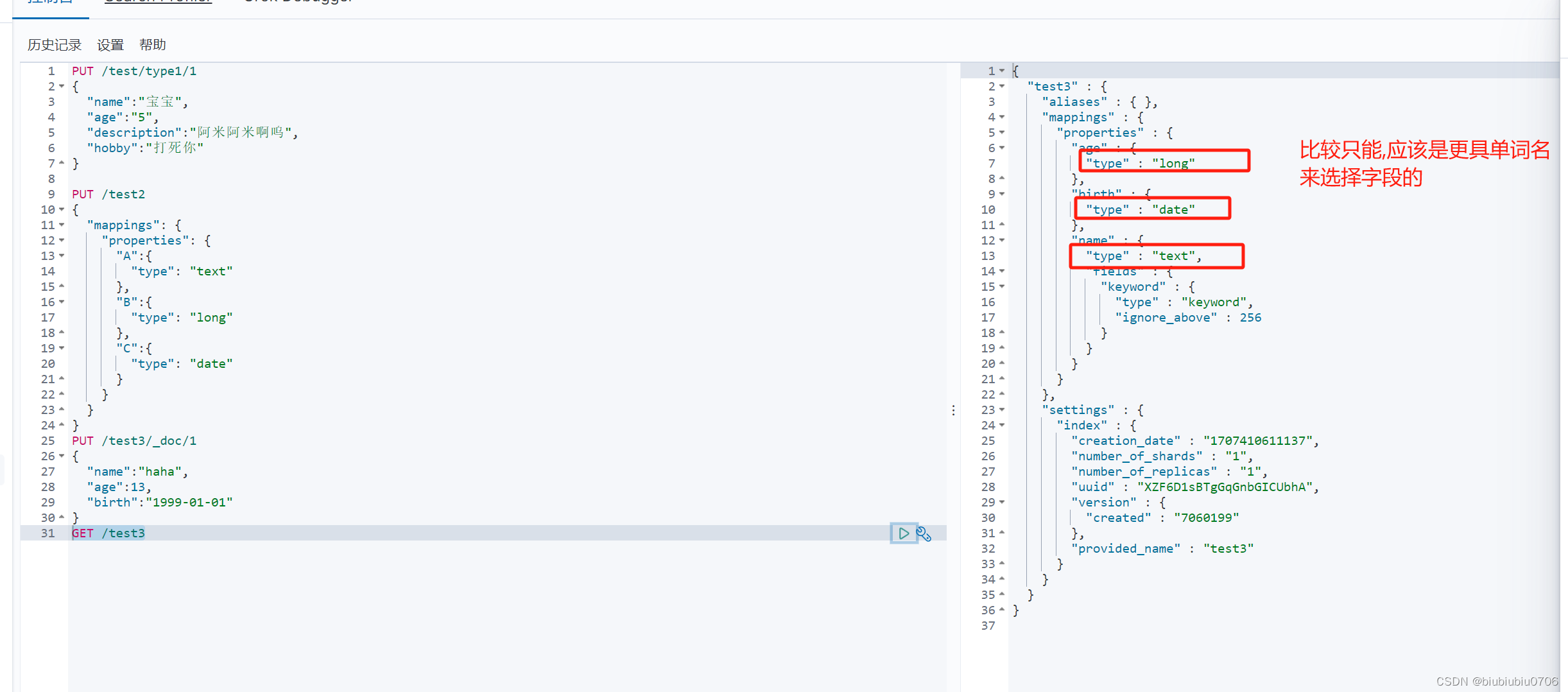
注意 keyword 表示不能分割 分词器也不能分割

GET /_cat/health
GET /_cat/indices
修改索引
方式1
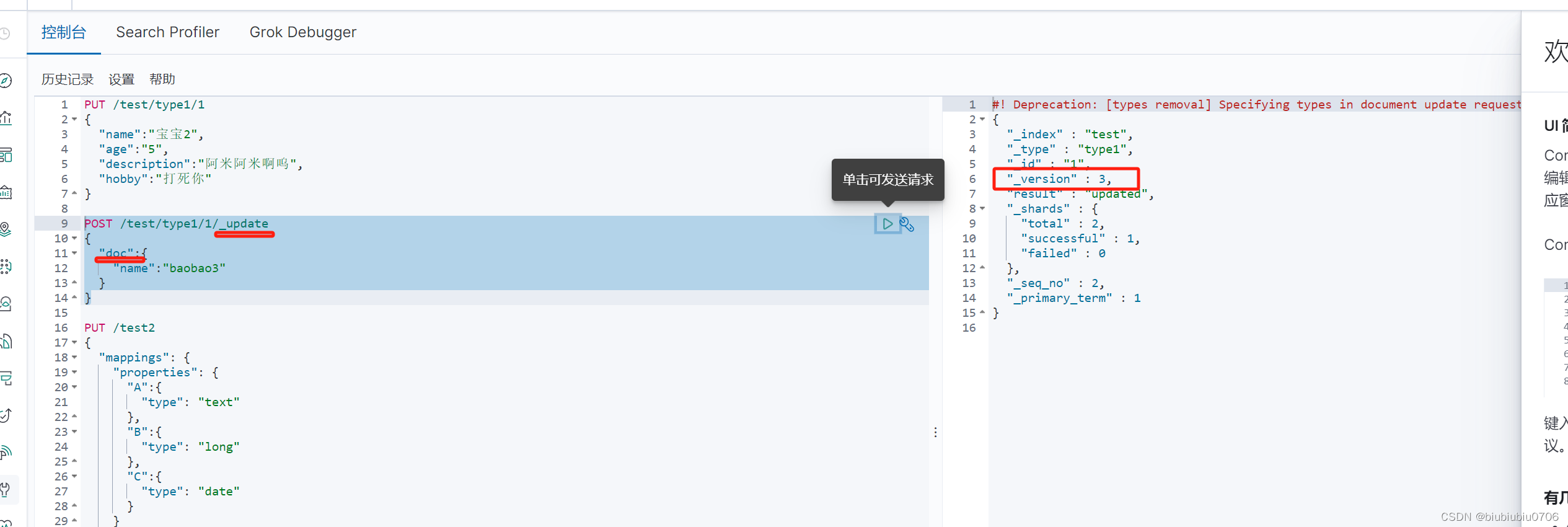
方式2
如果用POST /test/type1/1
{
"doc":{
"name":"ddddd"
}
}
这样的话 其他数据就都没了.只有name
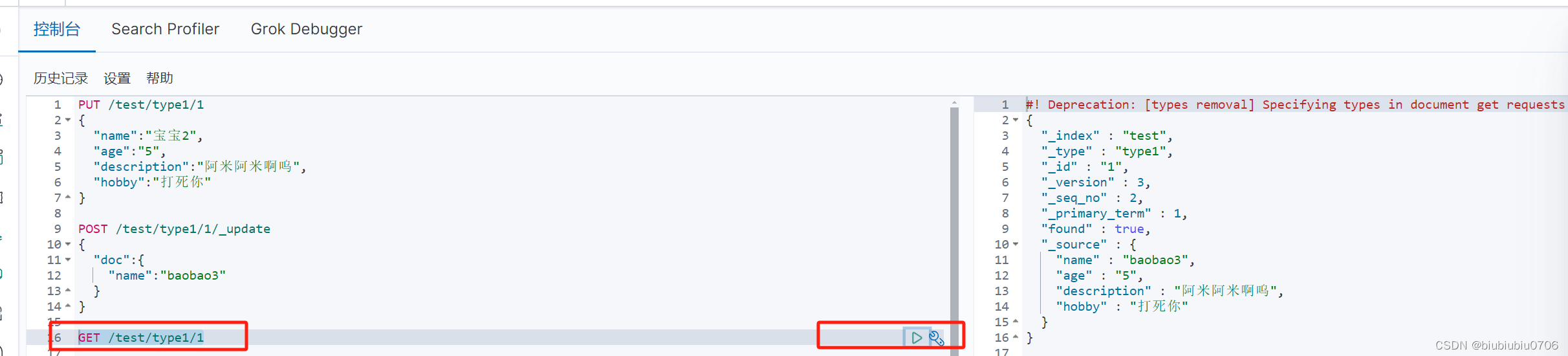
需要加上_update
POST /test/type1/1/_update (这种方式效率更高)
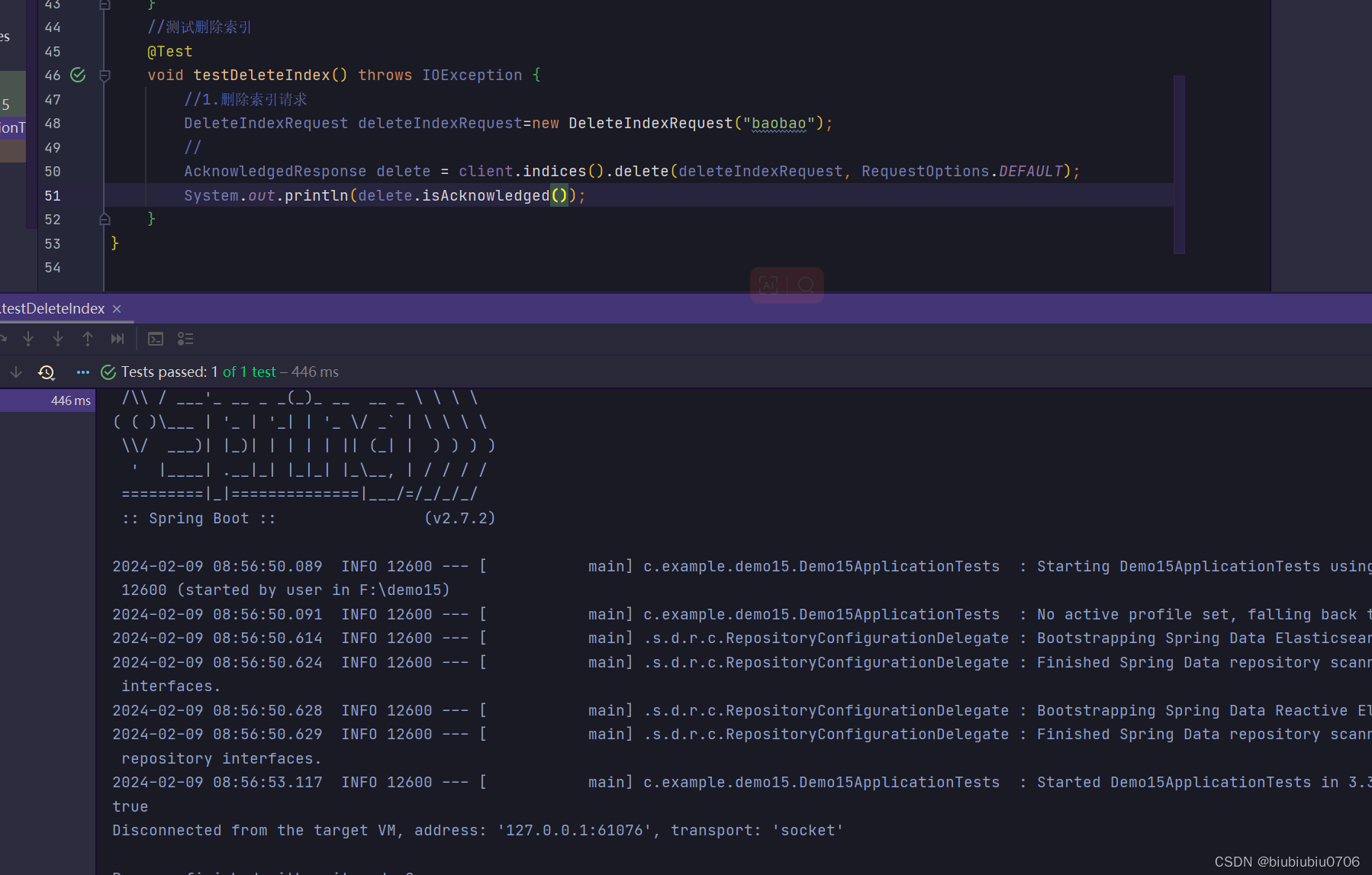
删除索引 (好比删除库,自然数据也没了)
DELETE /xxxx
上面已经清空了所有
下面放些数据进去
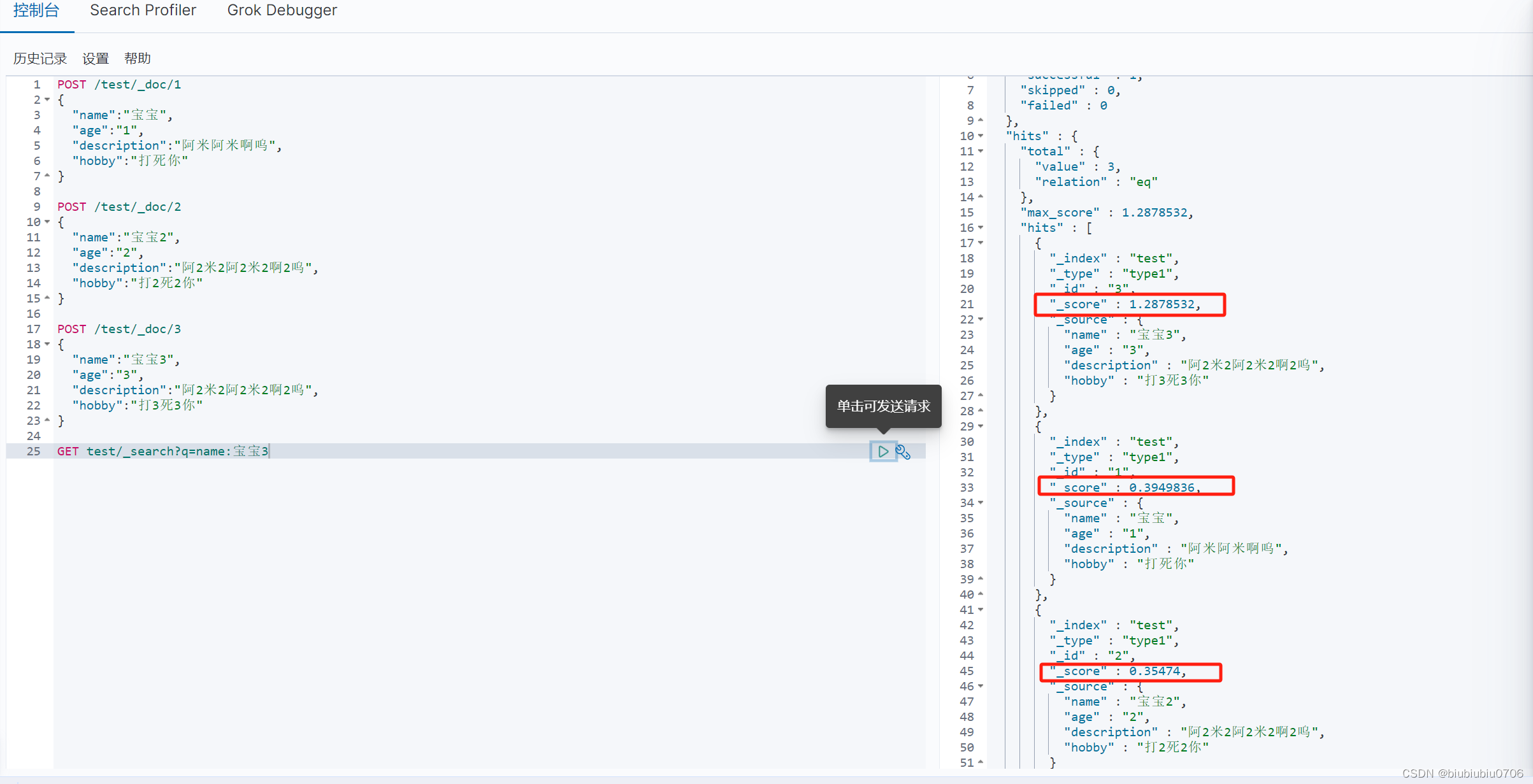
简单的条件查询

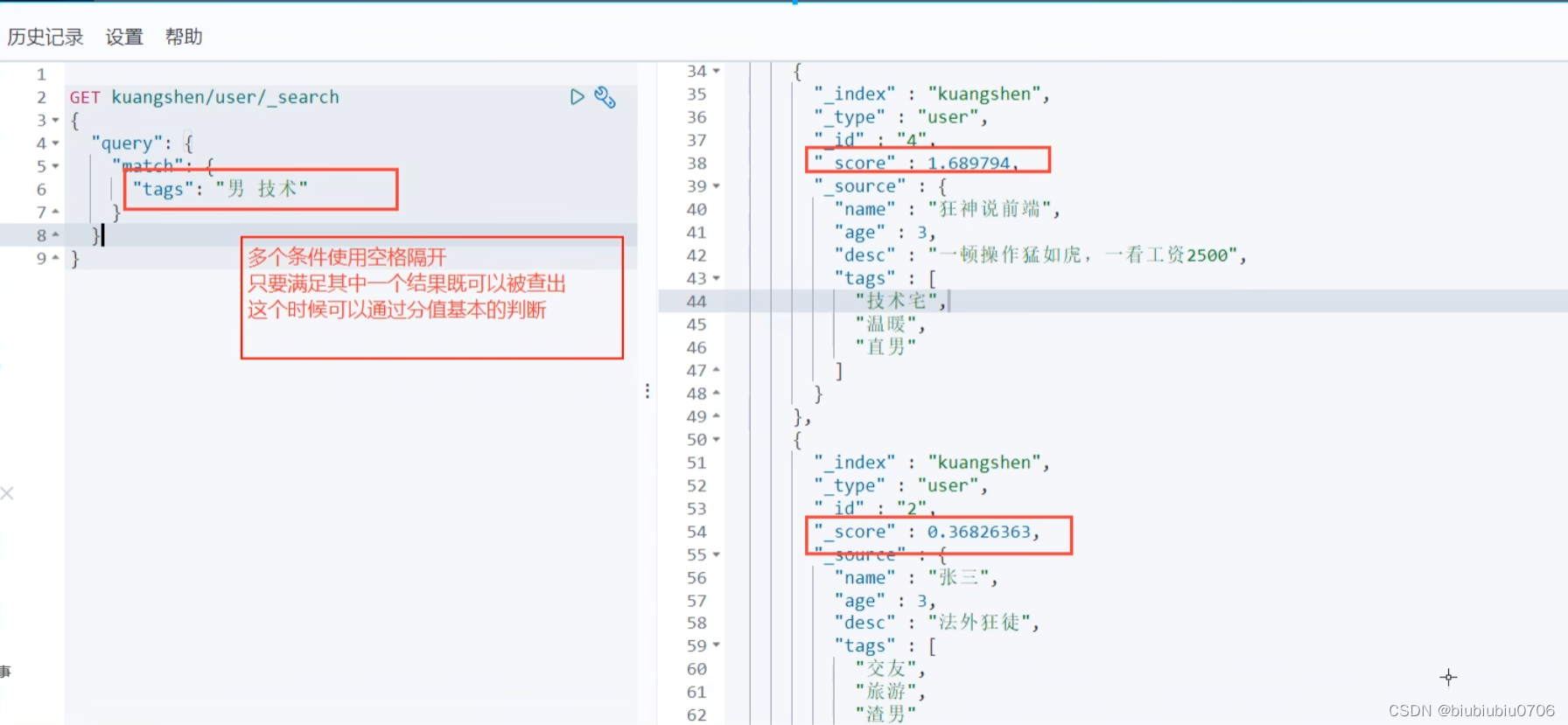
"_score" : 是匹配度
复杂查询条件
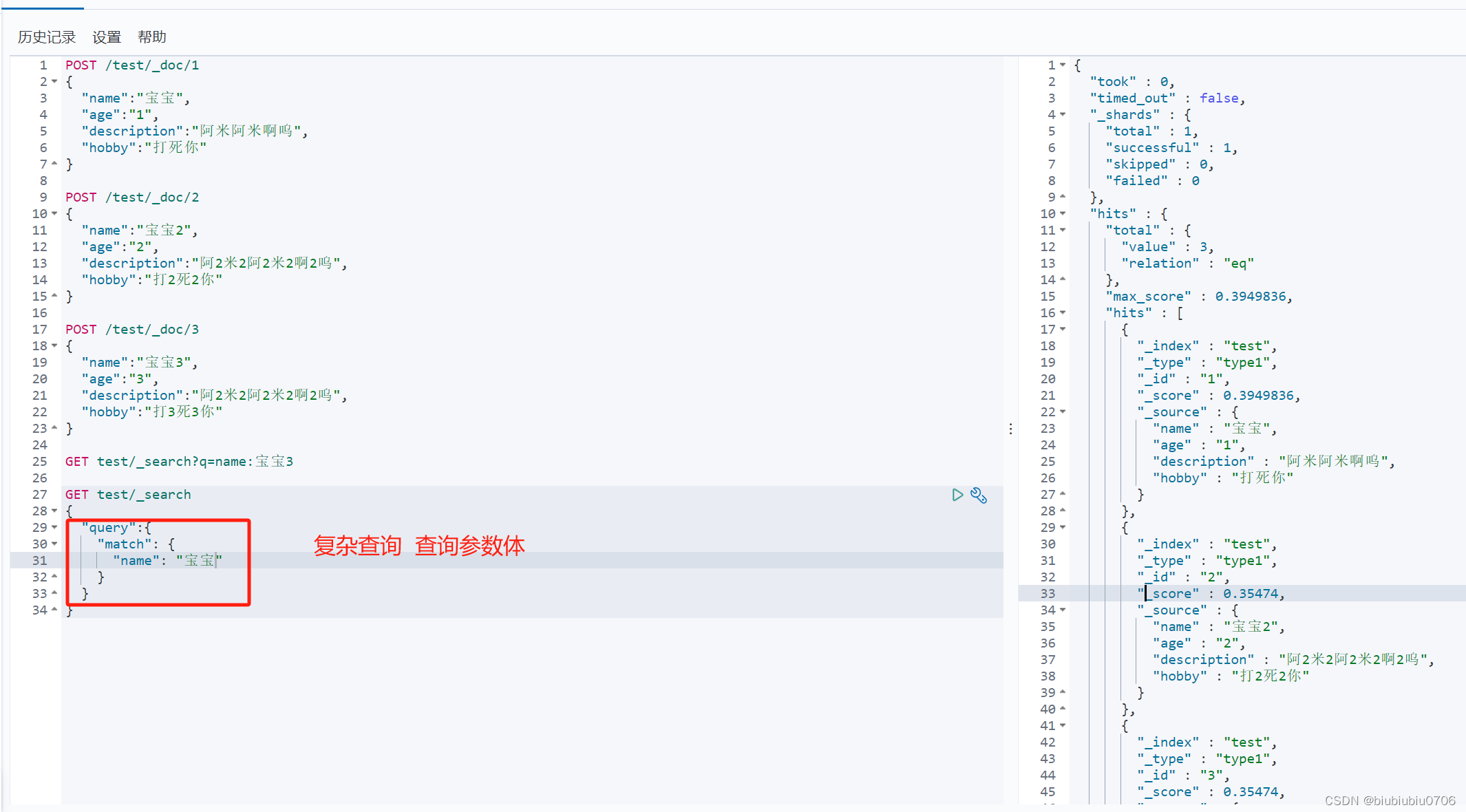
输出结果不想太多 java中可以根据_score去做匹配
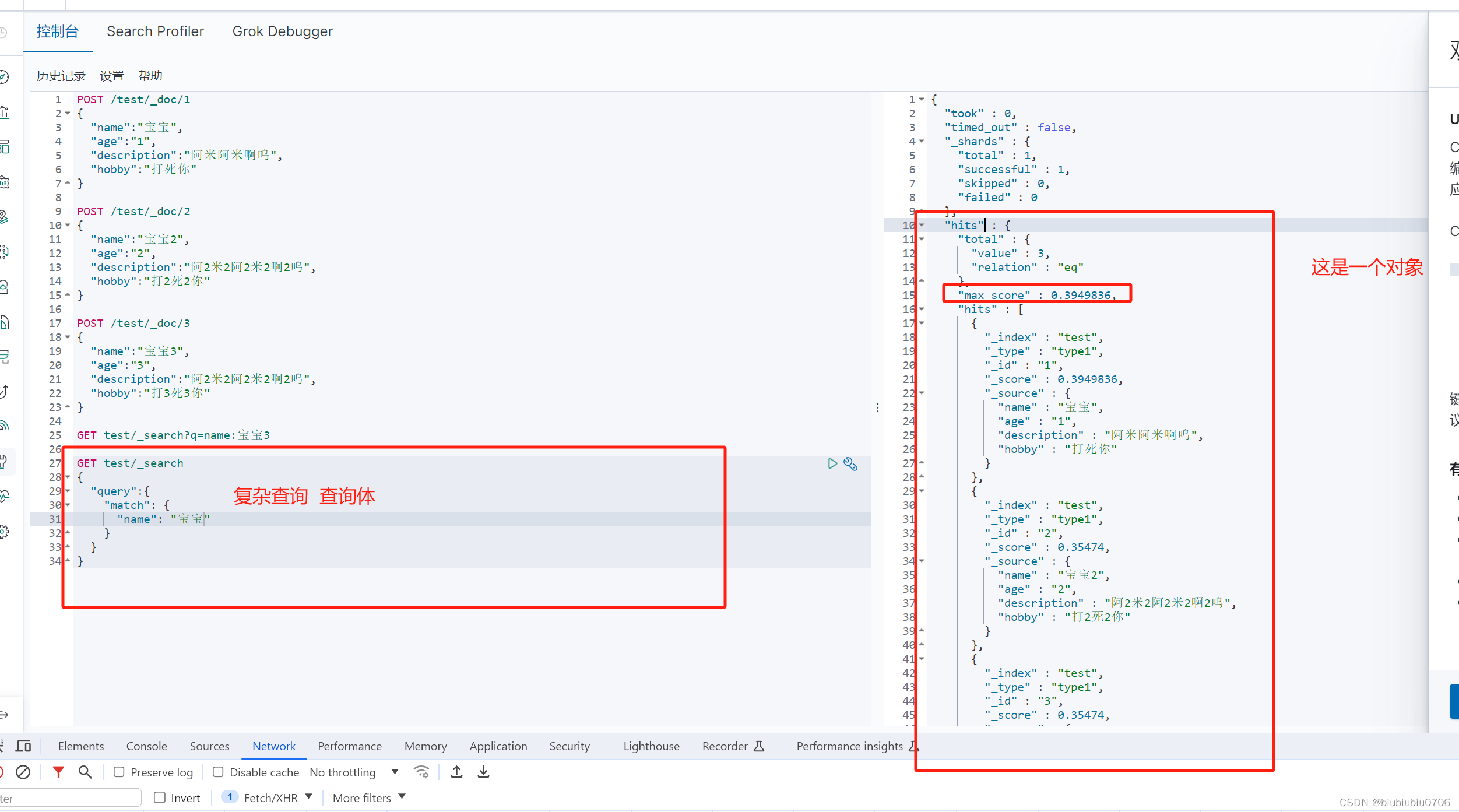
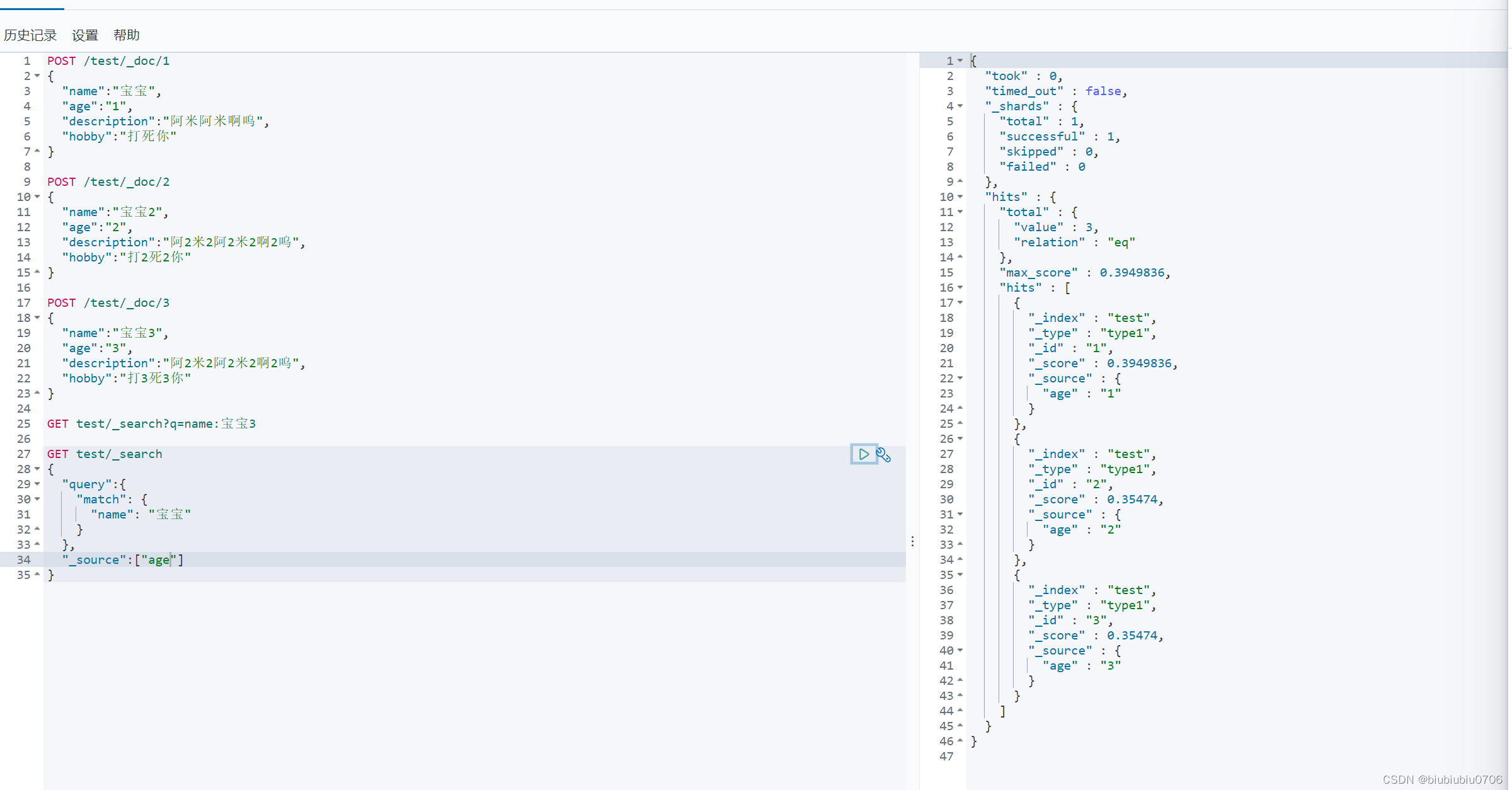
_source指定要查的字段是什么 结果过滤
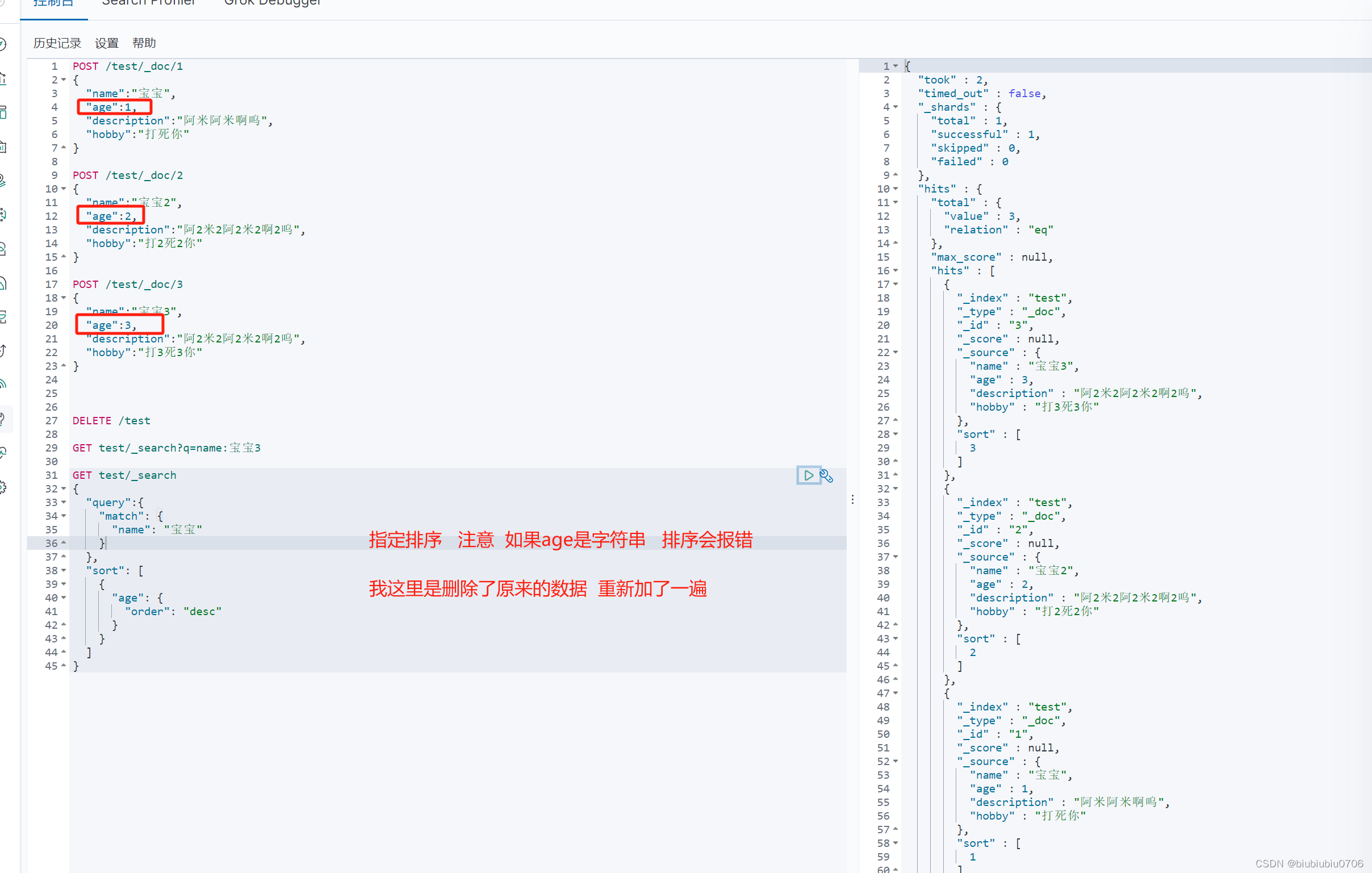
排序 desc asc
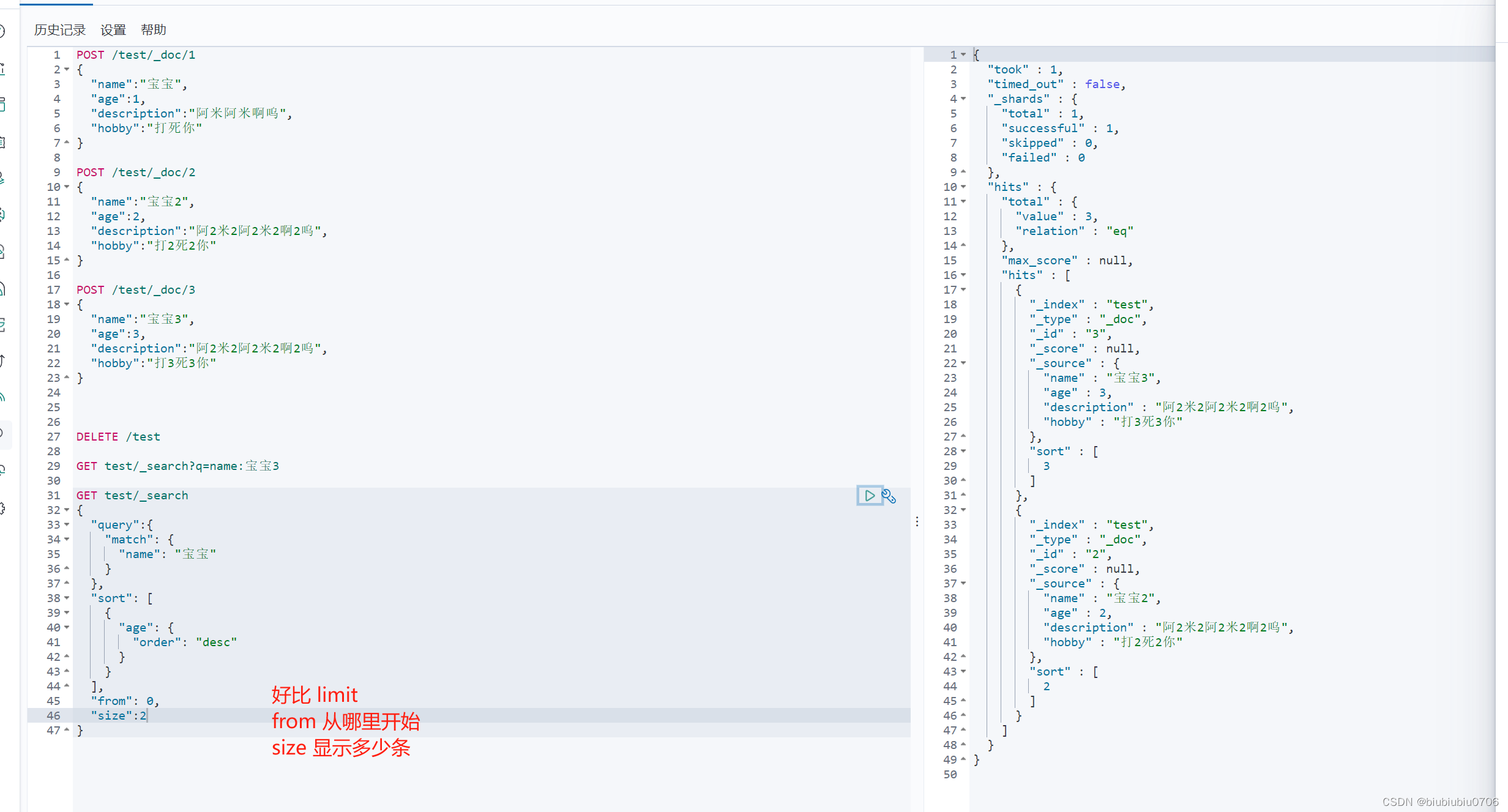
分页
多条件查询 must 好比mysql里的and 多条件匹配

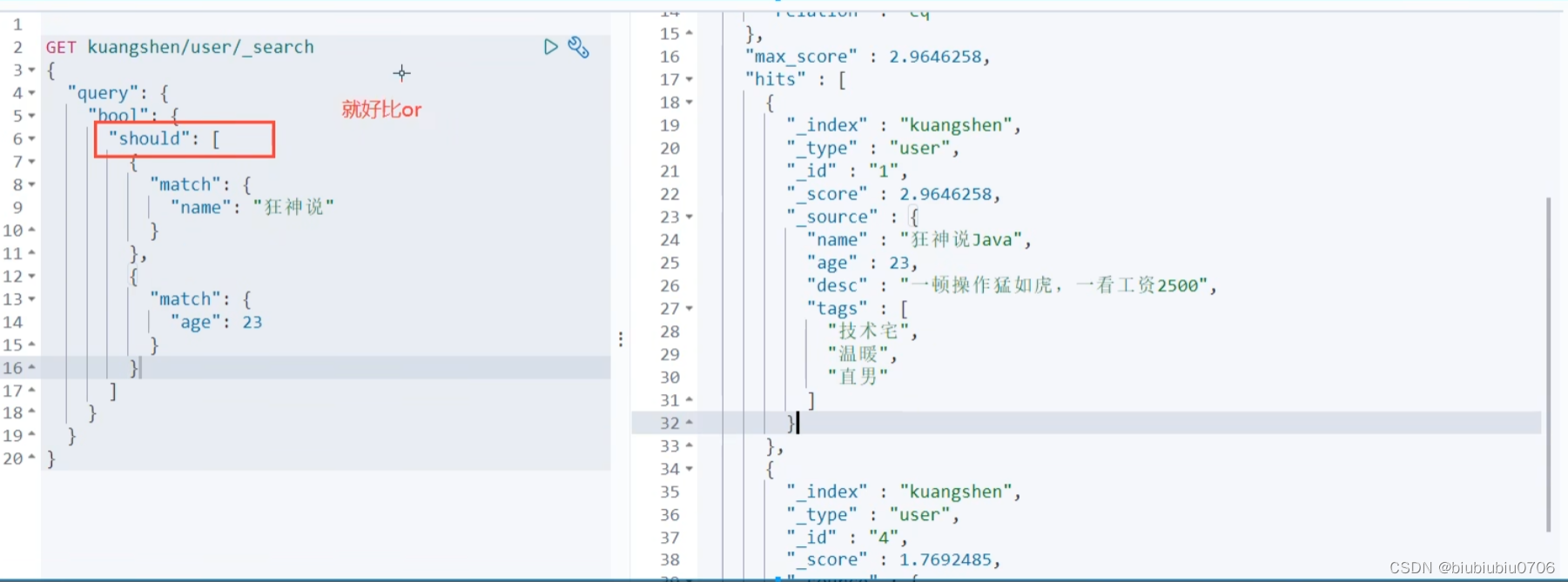
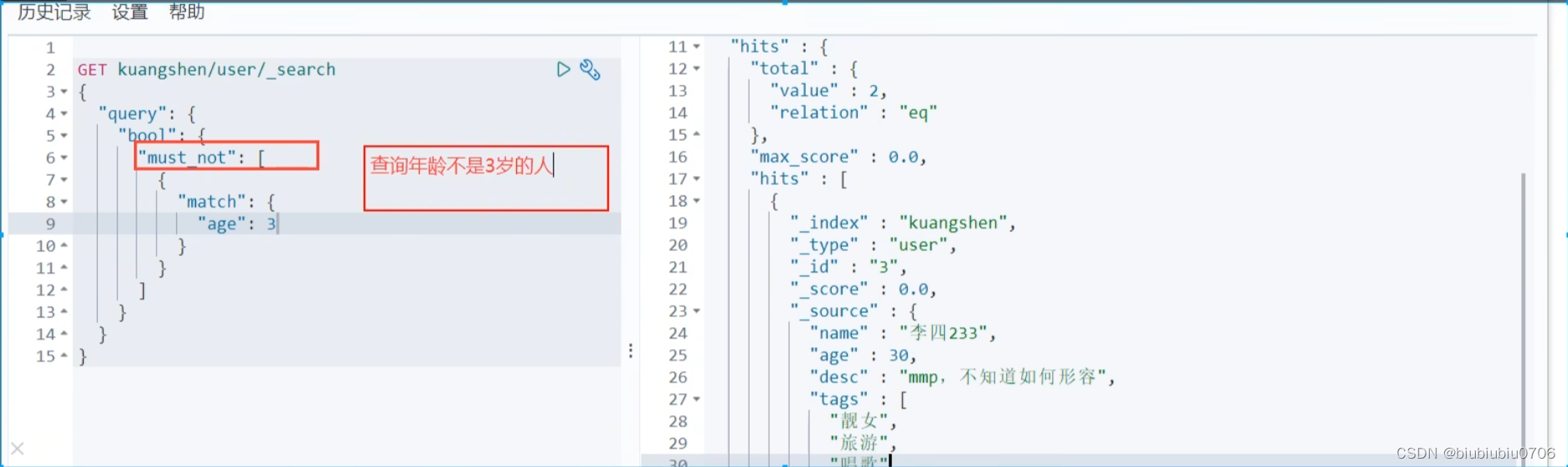
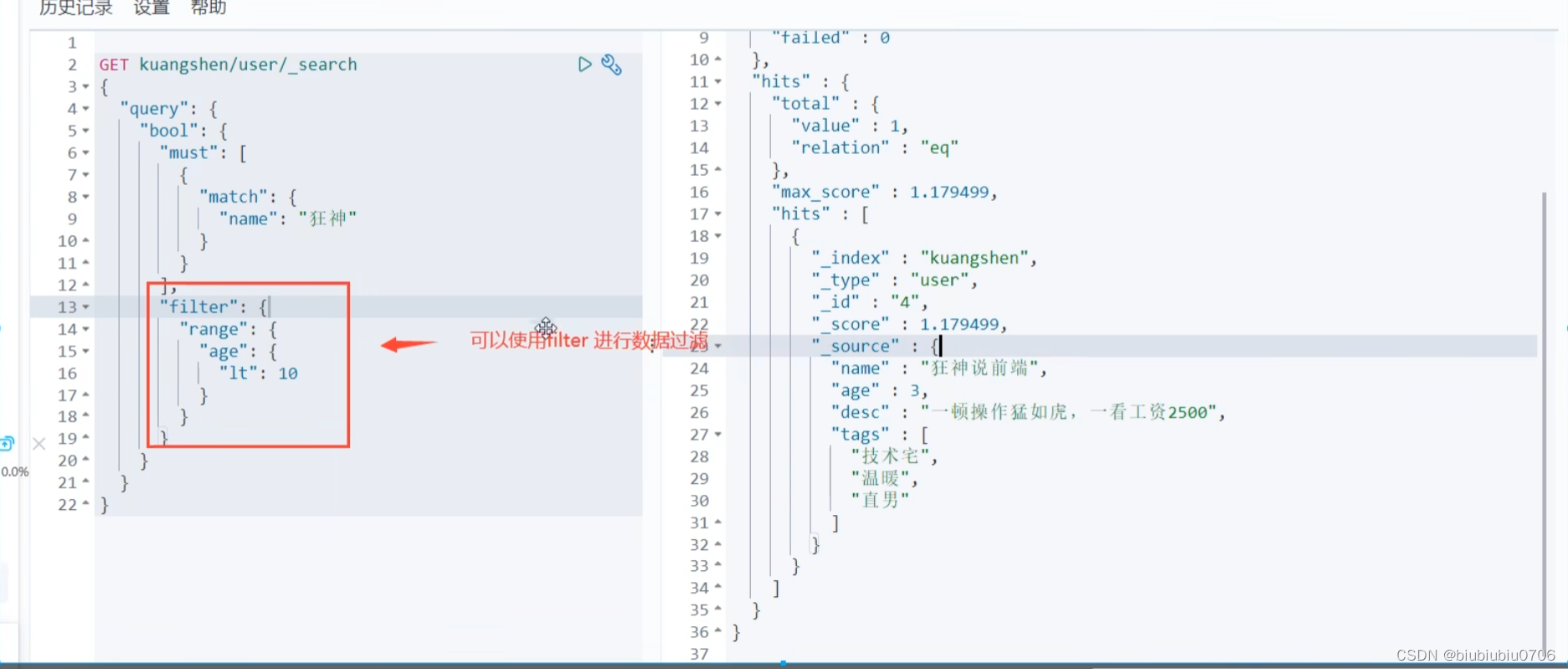
过滤器 filter gt:大于 gle:大于等于 lt:<小于 lte:小于等于
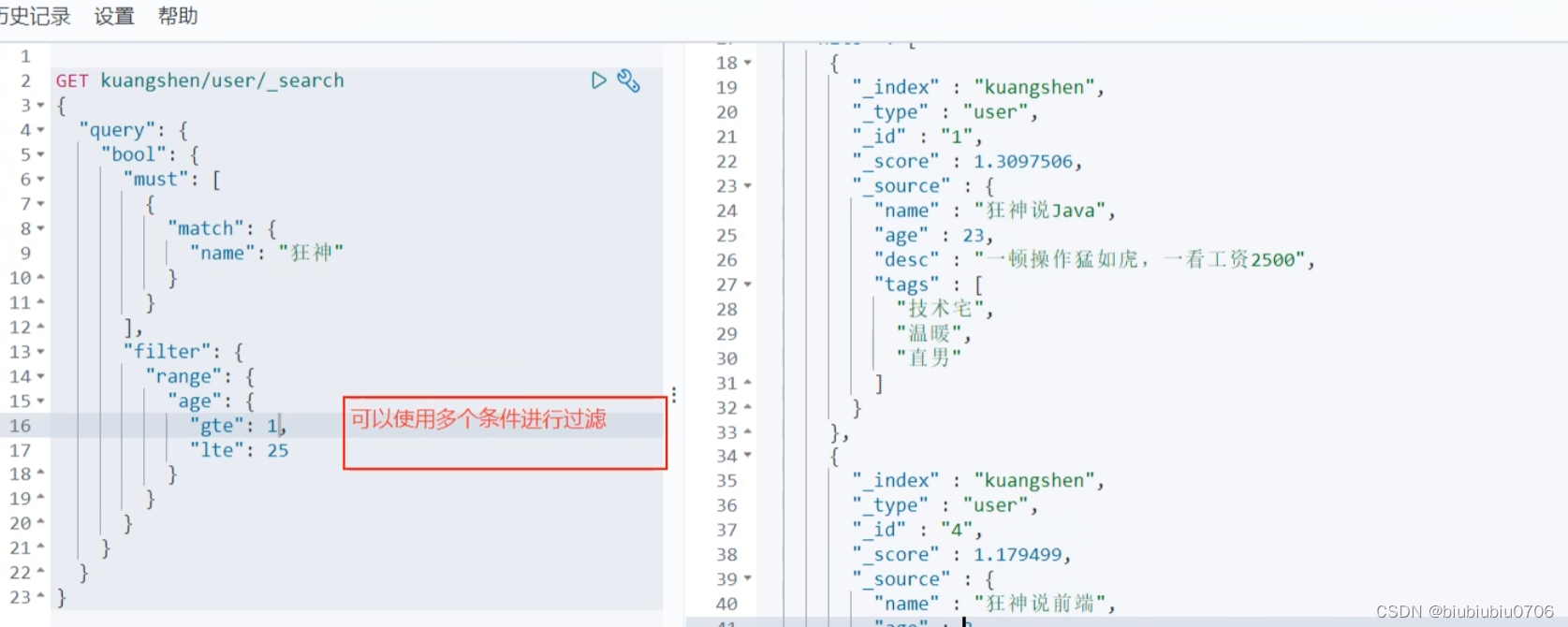
匹配多个条件
SpringBoot整合ElasticSearch
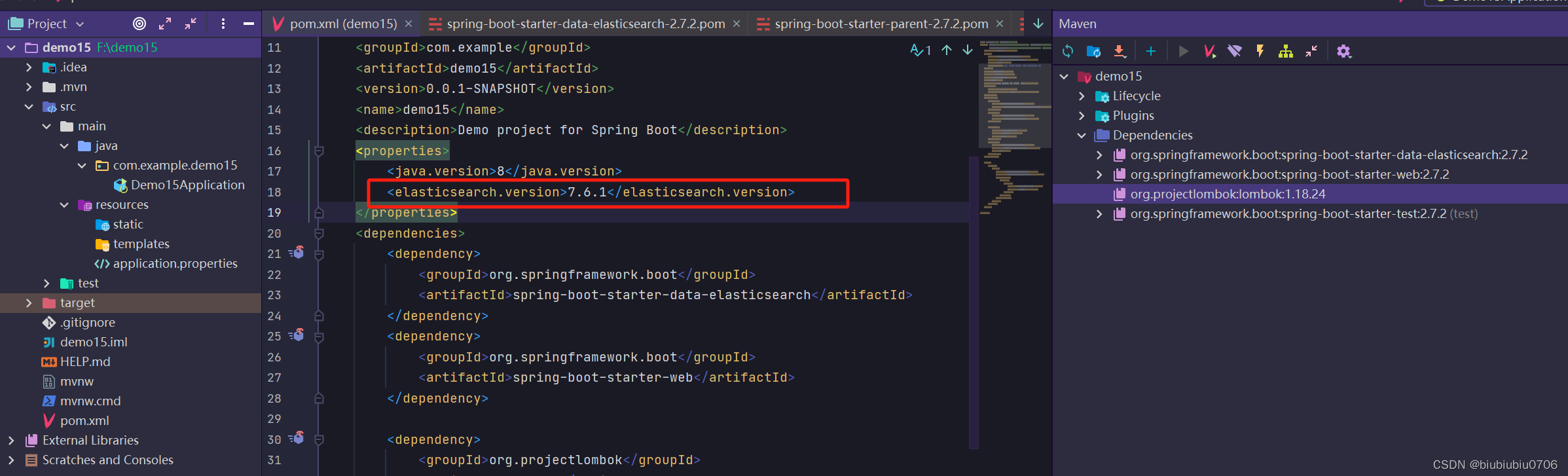
创建一个SpringBoot项目 我这里导入了lombok elasticsearch springweb依赖
由于本机用的ElasticSearch是7.6.1版本 所以修改了下
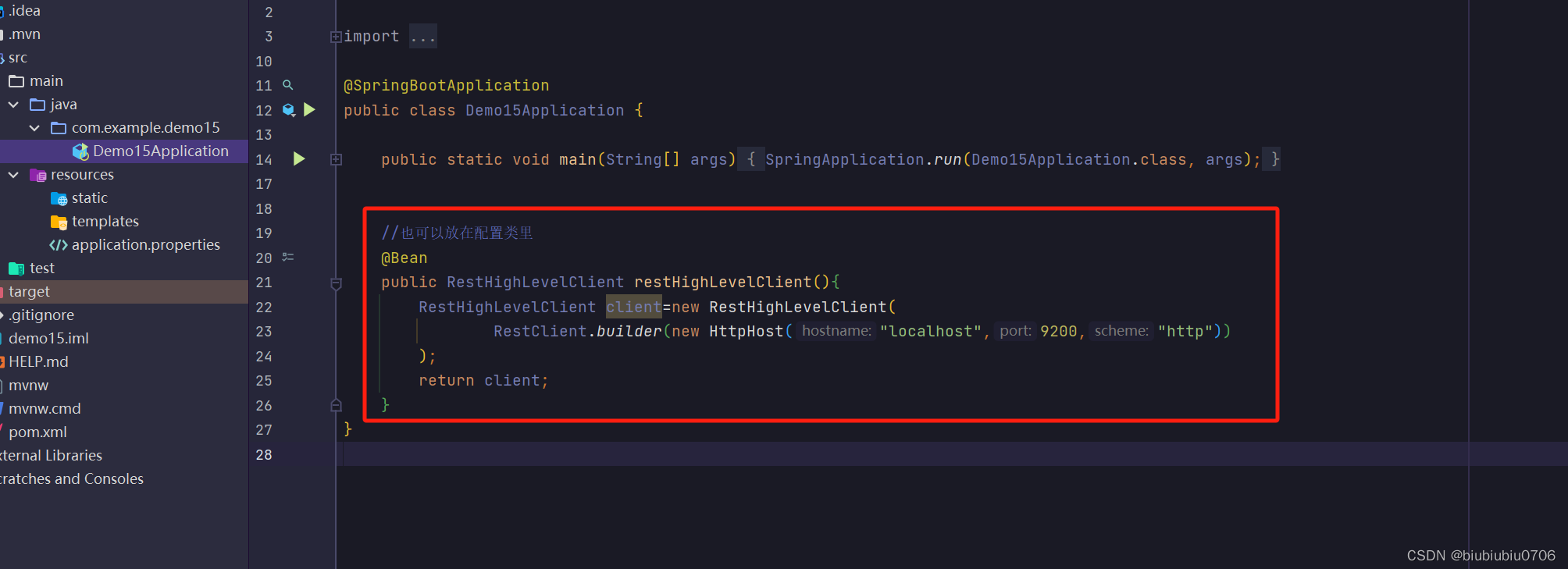
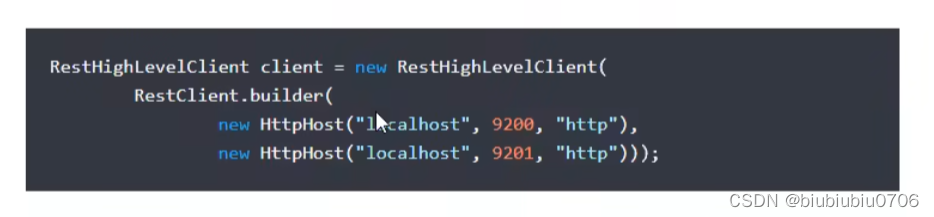
如果是集群就配置多个
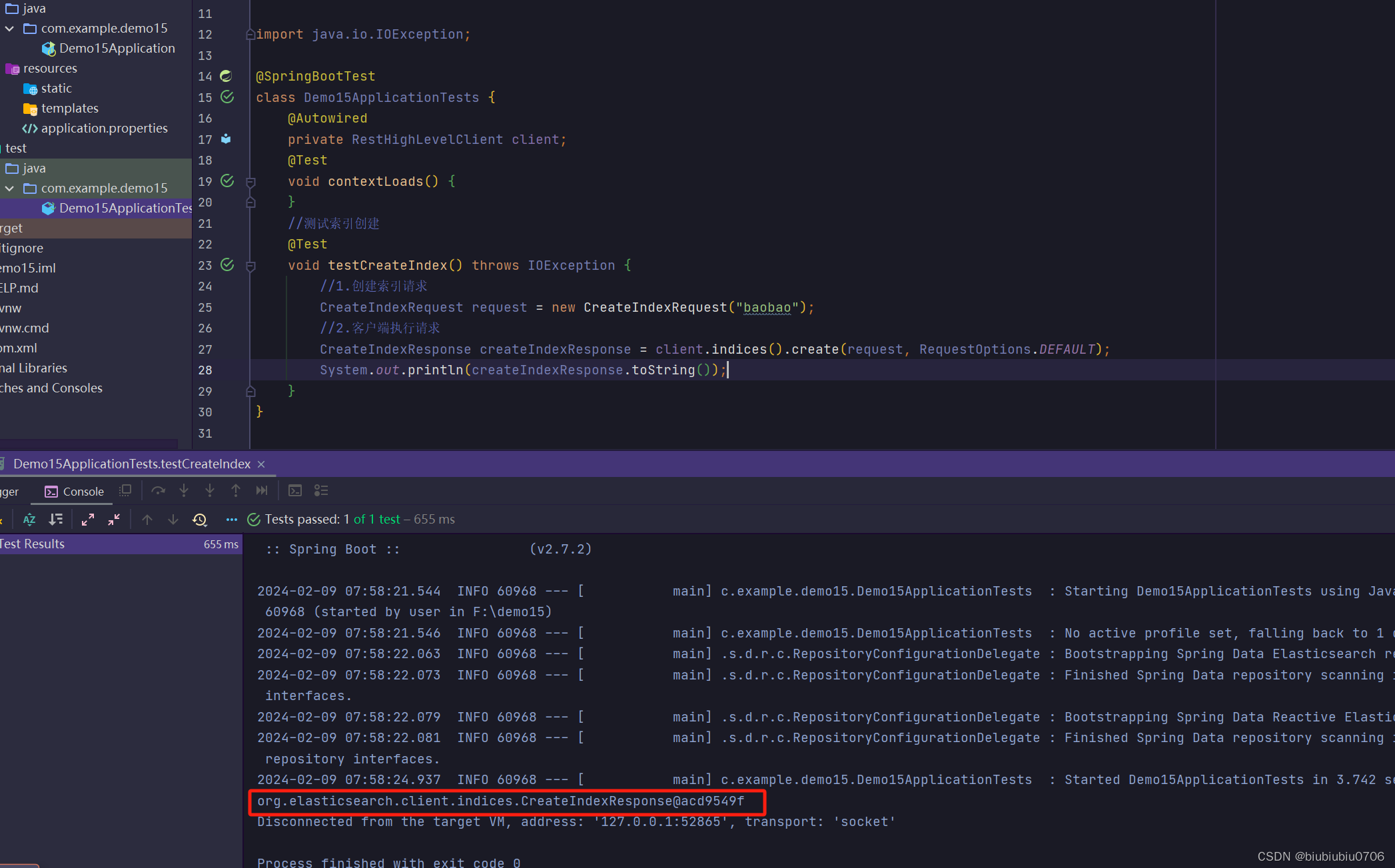
只能判断存不存在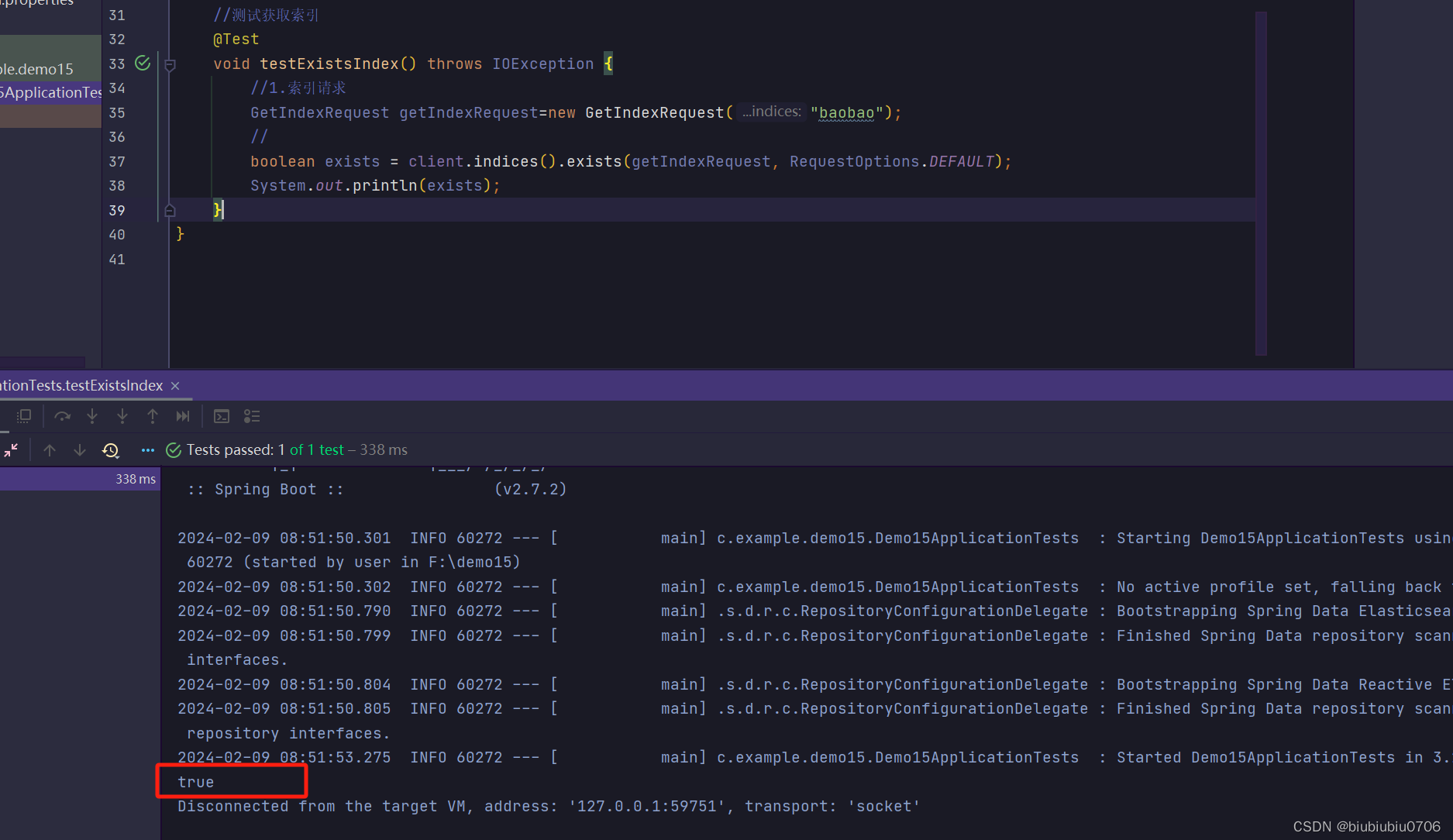
对比下API设计
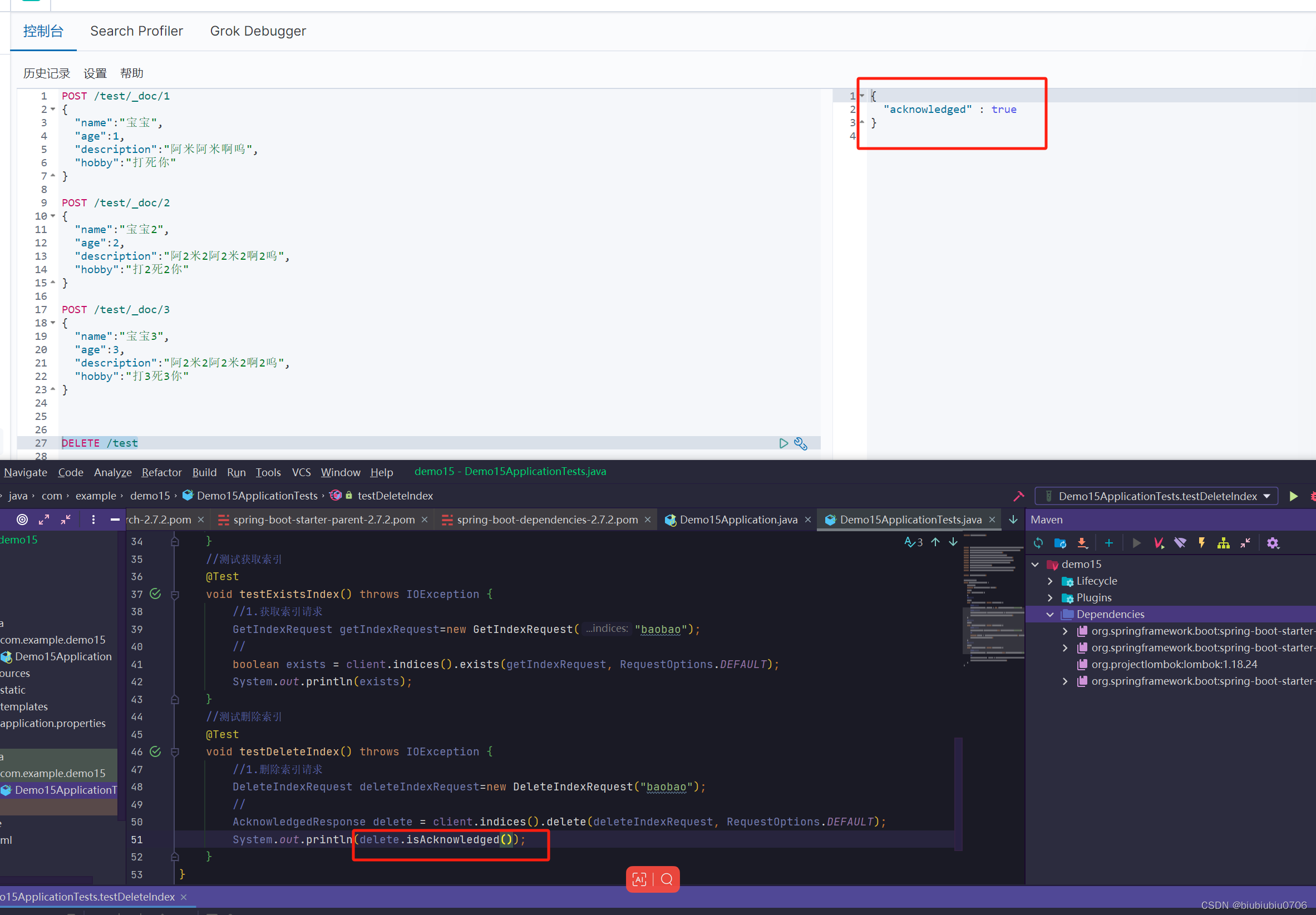
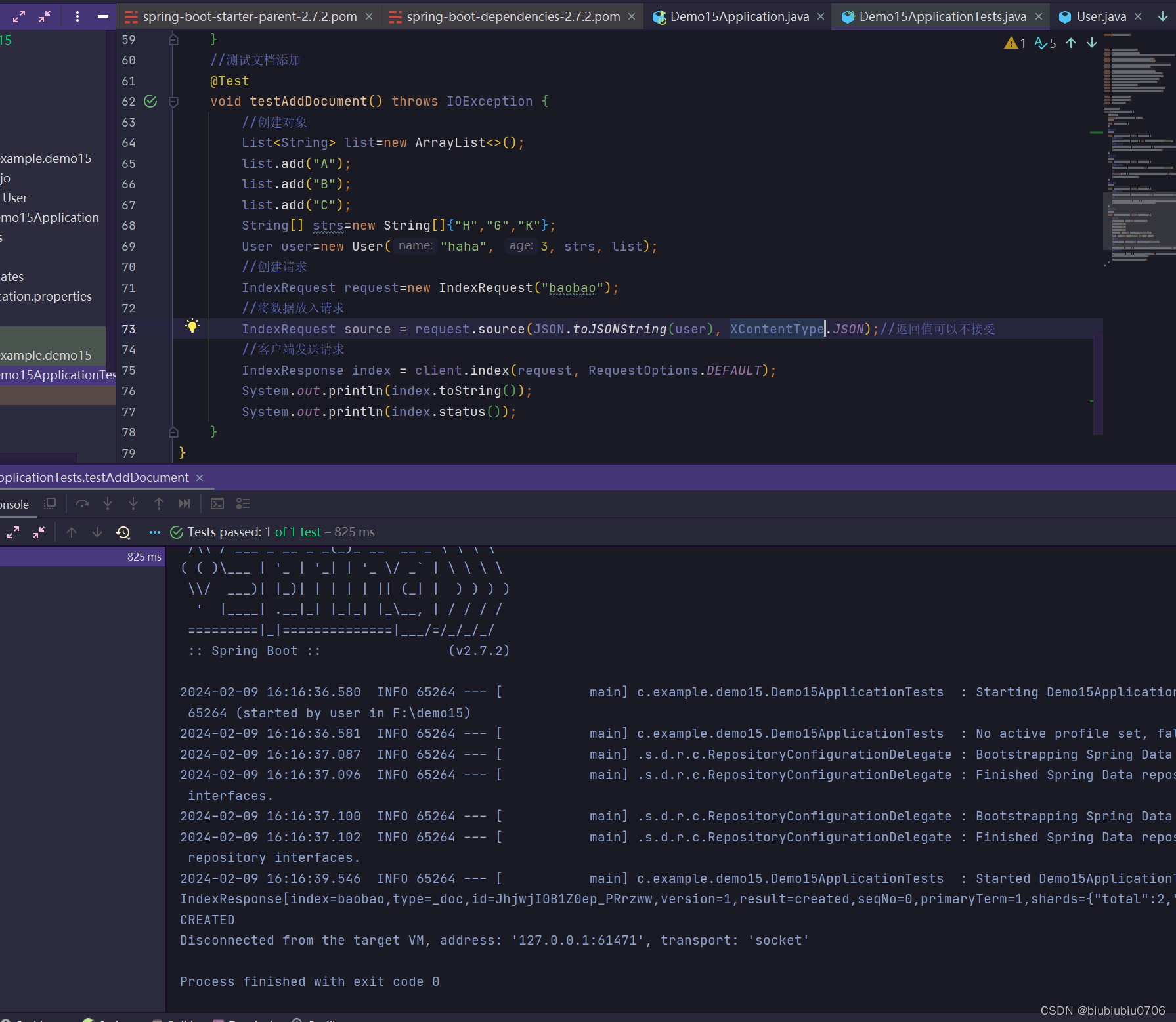
下面是对文档的CRUD 需要发送JSON数据 创建实体类
引入fastJson

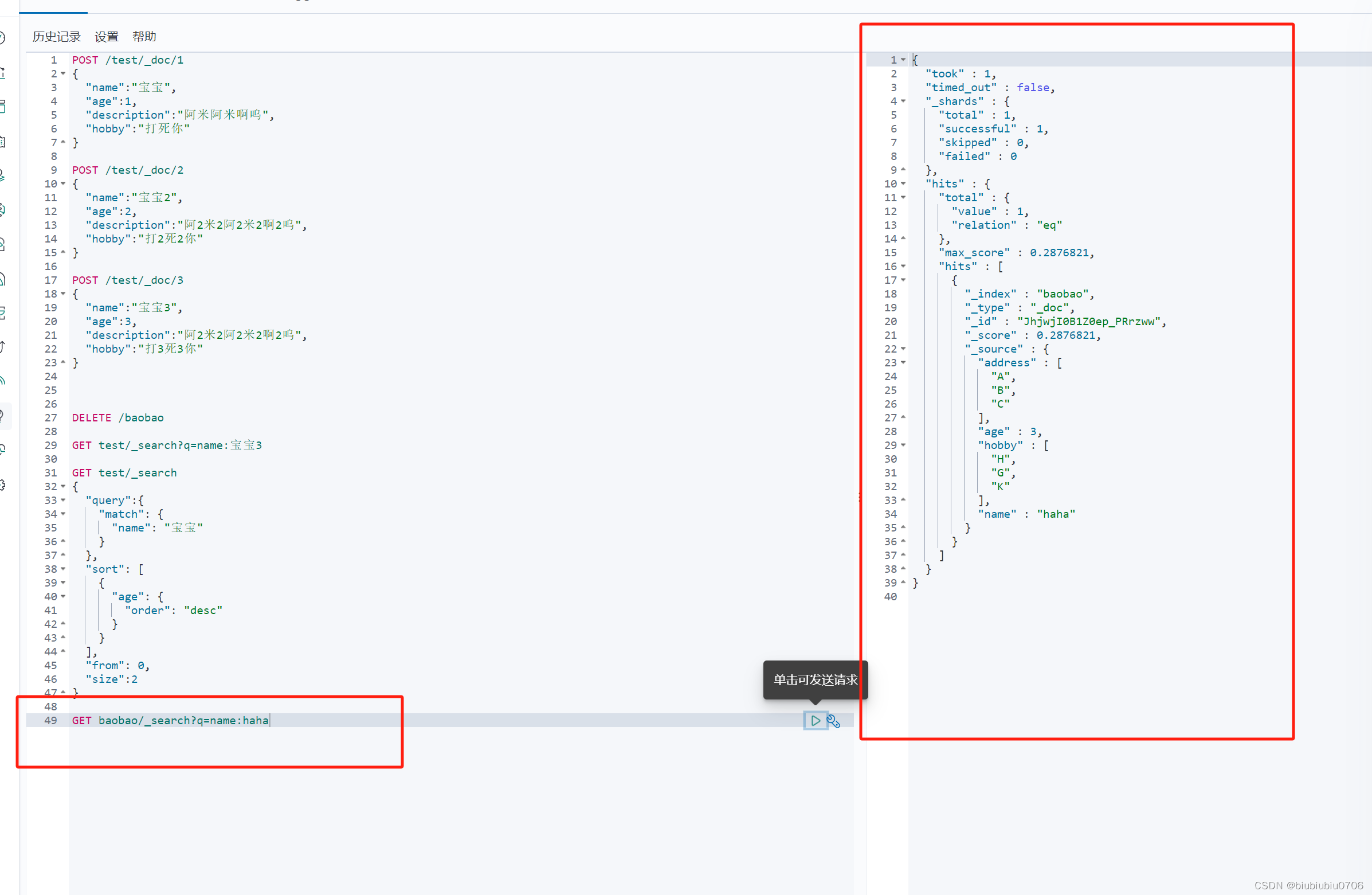
java爬取数据:解析网页jsoup依赖 获取请求返回的页面信息,赛选出我们想要的数据