
- 1软件测试的定义、目的及原则_软件测试的原则和意义。
- 2【使用 BERT 的问答系统】第 6 章 :BERT 模型应用:其他任务_bert问答模型
- 3C#毕业设计——基于C#+asp.net+sqlserver的房屋出租管理系统设计与实现(毕业论文+程序源码)——房屋出租管理系统_c#房屋出租系统
- 4Android兼容之鸿蒙系统使用Profiler分析系统时Crash_android studio profiler使用崩溃
- 5CClientDC CDC CPaintDC CWindowDC 的区别_cclientdc 字体
- 6HarmonyOS开发(三):ArkTS基础_arkts image引入
- 7Mac下解决AS出现Failed to open zip file. Gradle‘s dependency cache may be corrupt问题_mac gradle's dependency cache seems to be corrupt
- 8Android日常(03) Caused by: java.lang.IllegalStateException: Fragment xxxxFragment{2f4a09} not attached_java.lang.illegalstateexception: fragment not atta
- 9用Homebrew安装的东西都在哪_homebrew下载的软件没有出现在应用程序栏
- 10在阿里云平台部署ChatGLM2-6B模型、langchain-ChatGLM2知识库_langchain-chatchat 阿里云人工只能平台
产生和防御对抗样本的新方法 | 分享总结
赞
踩

来源:AI研习社
作者:杨文
在线上公开课上,来自清华大学的在读博士生廖方舟分享了他们团队在 NIPS 2017 上一个对抗样本攻防大赛中提到的两个新方法,这两个方法在大赛中分别获得了攻击方和防守方的第一名。在此可看视频回放:http://www.mooc.ai/open/course/383
廖方舟,清华大学化学系学士,生医系在读博士。研究方向为计算神经学,神经网络和计算机视觉。参加多次 Kaggle 竞赛,是 Data Science Bowl 2017 冠军,NIPS 2017 对抗样本比赛冠军。Kaggle 最高排名世界第 10。
分享主题:
动量迭代攻击和高层引导去噪:产生和防御对抗样本的新方法

分享内容:
大家好,我是廖方舟,今天分享的主题是对抗样本的攻和防。对抗样本的存在会使得深度学习在安全敏感性领域的应用收到威胁,如何对其进行有效的防御是很重要的研究课题。 我将从以下几方面做分享。
什么是对抗样本
传统的攻击方法
传统的防守方法
动量迭代攻击
去噪方法
高层引导去噪方法
什么是对抗样本
对抗样本的性质不仅仅是图片所拥有的性质,也不仅仅是深度学习神经网络独有的性质。因此它是把机器学习模型应用到一些安全敏感性领域里的一个障碍。
当时,机器学习大牛 Good fellow 找了些船、车图片,他想逐渐加入一些特征,让模型对这些船,车的识别逐渐变成飞机,到最后发现人眼观测到的图片依然是船、车,但模型已经把船、车当做飞机。

我们之前的工作发现样本不仅仅是对最后的预测产生误导,对特征的提取也产生误导。这是一个可视化的过程。
当把一个正常样本放到神经网络后,神经元会专门观察鸟的头部,但我们给它一些对抗样本,这些对抗样本也都全部设计为鸟,就发现神经网络提取出来的特征都是乱七八糟,和鸟头没有太大的关系。也就是说欺骗不是从最后才发生的,欺骗在从模型的中间就开始产生的。

下图是最简单的攻击方法——Fast Gradient Sign Method

除了 FGSM 单步攻击的方法,它的一个延伸就是多步攻击,即重复使用 FGSM。由于有一个最大值的限制,所以单步的步长也会相应缩小。比如这里有一个攻击三步迭代,每一步迭代的攻击步长也会相应缩小。
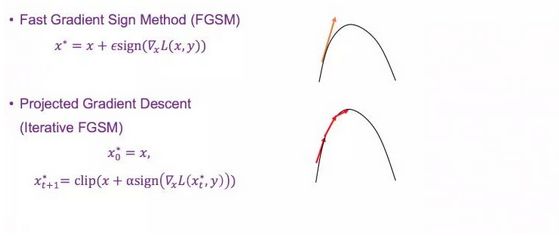
产生图片所用的 CNN 和需要攻击的 CNN 是同一个,我们称为白盒攻击。与之相反的攻击类型称为黑盒攻击,也就是对需要攻击的模型一无所知。

以上所说的都是 Non Targeted, 只要最后得到的目标预测不正确就可以了。另一种攻击 Targeted FGSM,目标是不仅要分的不正确,而且还要分到指定的类型。

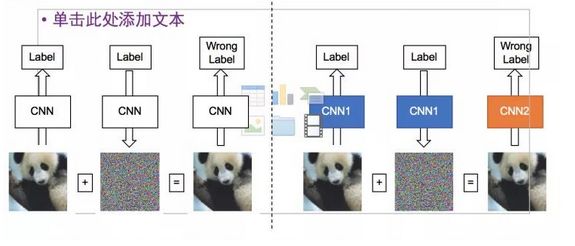
一个提高黑盒攻击成功率行之有效的办法,是攻击一个集合。

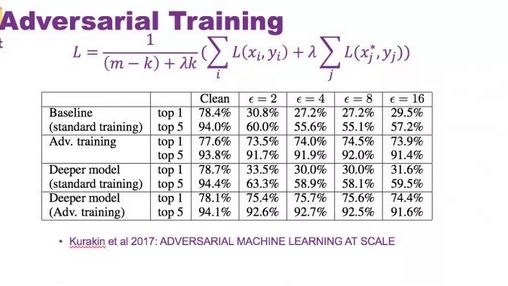
而目前为止一个行之有效的防守策略就是对抗训练。在模型训练过程中,训练样本不仅仅是干净样本,而是干净样本加上对抗样本。随着模型训练越来越多,一方面干净图片的准确率会增加,另一方面,对对抗样本的鲁棒性也会增加。
下面简单介绍一下 NIPS 2017 上的这个比赛规则
比赛结构
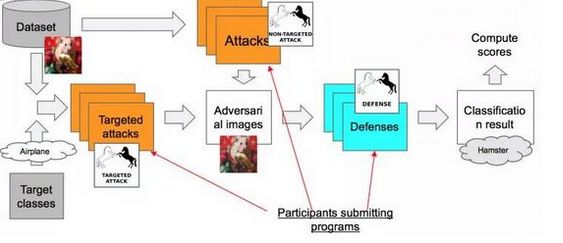
两个限制条件:容忍范围不能太大;不能花太长时间产生一个对抗样本,或者防守一个对抗样本

FGSM 算法结果

图中绿色模型为攻击范围,最后两栏灰色是黑盒模型,随着迭代数量的增加, 攻击成功率反而上升。这就给攻击造成了难题。
我们解决的办法就是在迭代与迭代中间加入动量

加入动量之后,白盒攻击变强了,而且对黑盒模型攻击的成功率也大大提升了。

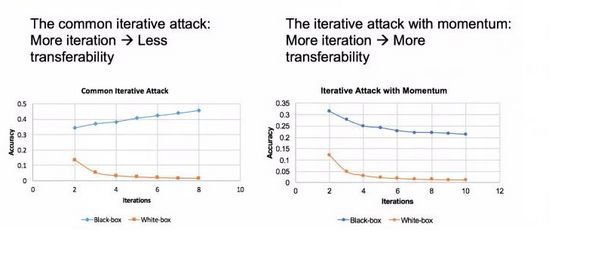
总结
以前方法(iterative attack)的弱点是在迭代数量增多的情况下,它们的迁移性,也就是黑盒攻击性会减弱,在我们提出加入动量之后,这个问题得到了解决,可以很放心使用非常多的迭代数量进行攻击。
在 NIPS 2017 比赛上得到最高的分数
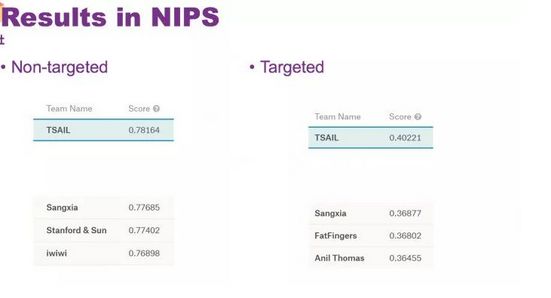
需要提到的一点,上面提到的都是 Non-targeted , 在 Targeted 攻击里面,这个策略有所不同。在 Targeted 攻击里面,基本没有观察到迁移性,也就是黑盒成功率一直很差,即便是加入动量,它的迁移程度也非常差。
下面讲一下防守
首先想到的就是去噪声,我们尝试用了一些传统的去噪方法(median filter 、BM3D)效果都不好。之后我们尝试使用了两个不同架构的神经网络去噪。一个是 Denoising Autoencoder,另一个是 Denoising Additive U-Net。

我们的训练样本是从 ImageNet 数据集中取了三万张图片 ,使用了七个不同的攻击方法对三万张图片攻击,得到 21 万张对抗样本图片以及三万张对应的原始图片。除了训练集,我们还做了两个测试集。一个白盒攻击测试集和一个黑盒攻击测试集。

训练效果

我们发现经过去噪以后,正确率反而有点下降。我们分析了一下原因,输入一个干净图片,再输入一个对抗图片,然后计算每一层网络在这两张图片上表示的差距,我们发现这个差距是逐层放大的。
图中蓝线发现放大的幅度非常大,图中红线是去噪过后的图片,仍然在放大,导致最后还是被分错。

为了解决这个问题,我们提出了经过改良后的网络 HGD
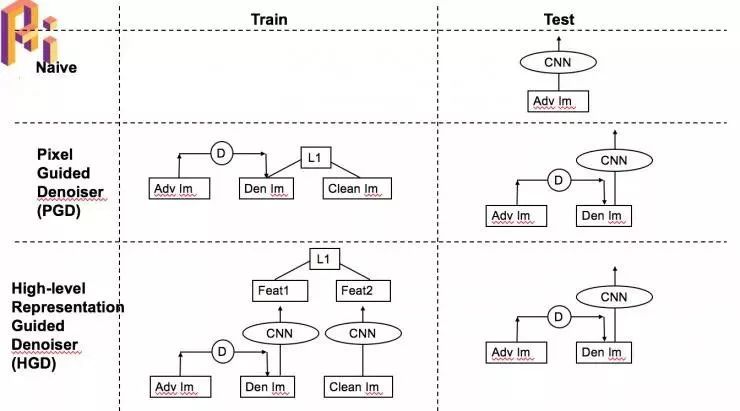
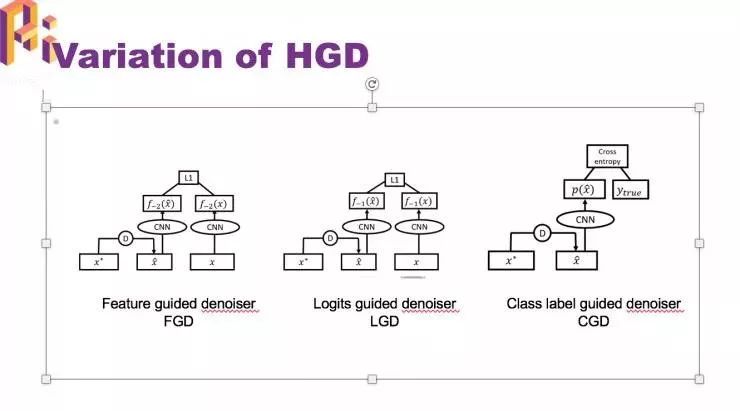
HGD 的几个变种
和之前的方法相比,改良后的网络 HGD 防守准确率得到很大的提升
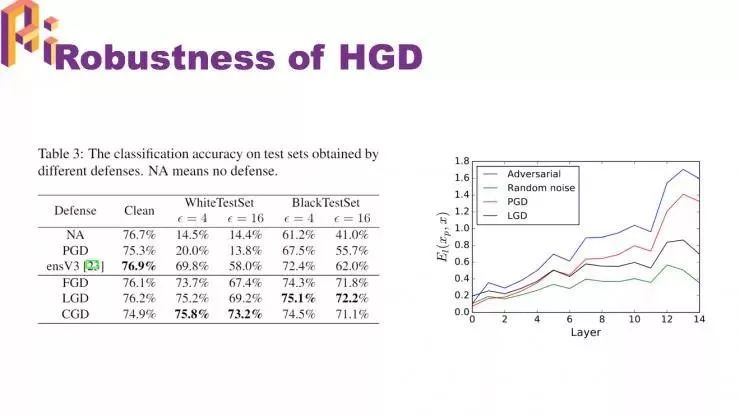
HGD 有很好的迁移性

最后比赛中,我们集成了四个不同的模型,以及训练了他们各自的去噪, ,最终把它们合并起来提交了上去。
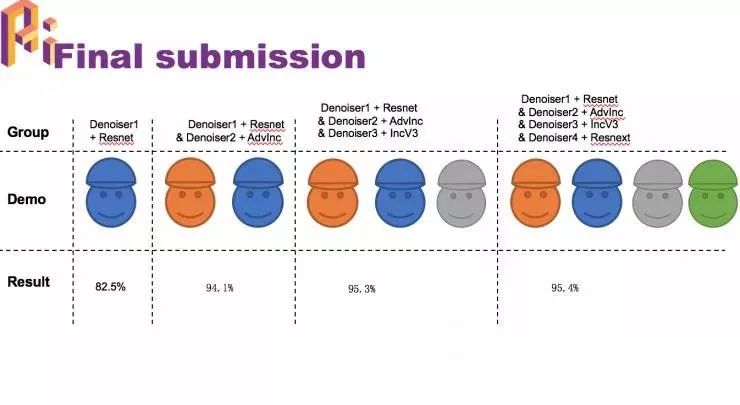
HGD 网络总结
优点:
效果显著比其他队伍的模型好。
比前人的方法使用更少的训练图片和更少的训练时间。
可迁移。
缺点:
还依赖于微小变化的可测量
问题并没有完全解决
仍然会受到白盒攻击,除非假设对手不知道 HGD 的存在
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


