
热门标签
热门文章
- 1[python]飞桨python小白逆袭课程day5——大作业来啦_百度飞浆用python调整图片清晰度
- 2作为前端技术人,体验刚开源的鸿蒙OS_鸿蒙专用前端库
- 3经典算法精讲精练之回溯法求解0-1背包问题_用回溯法求解0-1背包问题,假如3件物品(按照价值密度排序)的重量与价值分别是:
- 4让你的win10/win11系统变得不再卡顿,优雅草伊凡整理-长期更新-如何让windows操作系统不用老是重装在不断的更新中依然保持流畅运行
- 5无监督学习,生成模型:自编码器(AE,VAE),GAN_ae神经网络
- 6常用logcat命令_logcat 指定关键字
- 7Spring Boot 服务优雅关闭/下线方式汇总, Spring Boot 打包排除指定文件_springboot actuator shutdown
- 8想系统学习GO语言(Golang),能推荐几本靠谱的书吗?_golang教程 知乎
- 9FreeFileSync 文件备份_disksync freefilesync 数据库离线备份
- 10解决ElementPlus中的Menu菜单背景设为透明后导航栏文字下方出现一条细白线_el-menu透明
当前位置: article > 正文
深度学习:权重衰减_no bias declay
作者:weixin_40725706 | 2024-04-01 18:09:58
赞
踩
no bias declay
转载:深度学习优化策略
L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化。
L2正则化与权重衰减系数
L2正则化就是在代价函数后面再加上一个正则化项:
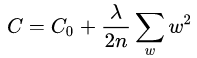
其中C0代表原始的代价函数,后面那一项就是L2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。λ就是正则项系数,权衡正则项与C0项的比重。另外还有一个系数1/2,1/2 1/211经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好凑整为1。系数λ就是权重衰减系数。
为什么可以给权重带来衰减

权重衰减(L2正则化)的作用
作用:权重衰减(L2正则化)可以避免模型过拟合问题。
思考:L2正则化项有让w变小的效果,但是为什么w变小可以防止过拟合呢?
原理:(1)从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀),而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。(2)从数学方面的解释:过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
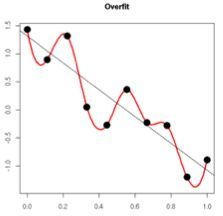
No bias decay:
一般来说,权重衰减会用到网络中所有需要学习的参数上面。然而仅仅将权重衰减用到卷积层和全连接层,不对biases,BN层的 \gamma, \beta 做权重衰减,效果会更好。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/349761
推荐阅读
相关标签

