
热门标签
热门文章
- 1基于小程序的小区物业管理平台开发笔记_微信小程序物业管理系统报告制作总结
- 2如何在以太坊上存一张图片_怎样把图片记录到以太坊区块
- 3基于Springboot宠物领养系统-计算机毕设 附源码241104
- 4构建安全可靠的系统:第一章到第五章
- 5三分钟手把手教你安装fl studio 21.2.2.3914破解版2024年最新图文激活教程_fl studio csdn
- 6Linux系统防火墙firewall-cmd命令_linux firewall-cmd保存到文件
- 7PyTorch框架学习笔记_pytorch学习笔记
- 8java获取MX_从Java中的RuntimeMXBean获取引导路径
- 9使用pytorch完成kaggle猫狗图像识别_kaggle上的简单图像识别程序
- 10基于Hexo和Butterfly创建个人技术博客,(2) 博客站点配置,Hexo框架_config.yml配置文件细说明_hexo的config配置
当前位置: article > 正文
爬虫谷歌学术_谷歌学术爬虫
作者:weixin_40725706 | 2024-04-05 09:30:56
赞
踩
谷歌学术爬虫
一个针对谷歌学术(Google scholar)的爬虫,需要科学上网。
现在每个科研方向的论文太多了,要想把某个领域的论文一网打尽非常麻烦,本文写了个代码来自动实现此功能。支持根据关键词搜索相关的论文,返回指定的前N篇论文的简要信息。
根据关键词搜索
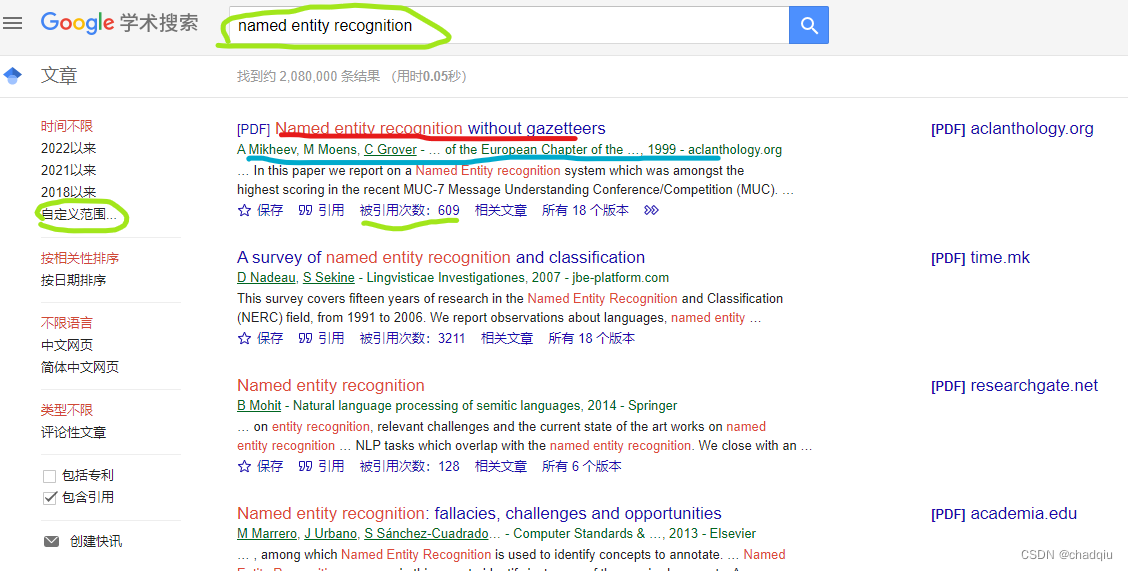
可以指定:关键词、开始时间、结束时间、返回论文的数量(建议不超过200,否则容易被封),爬取的结果包括: [论文标题, 引用数, 发表时间及机构缩写, 论文链接],见上图划线的部分
结果会print出来,也会自动保存到一个excel文件
from bs4 import BeautifulSoup import urllib.request import re import time import traceback import pandas as pd import warnings warnings.filterwarnings("ignore") headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/90.0.4430.93 Safari/537.36'} def get_paper_page(url): req = urllib.request.Request(url=url, headers=headers) res = urllib.request.urlopen(req, timeout=100) html=res.read().decode('utf-8') soup=BeautifulSoup(html) data = [[div.select('.gs_rt > a')[0].text, div.select('.gs_fl > a')[2].string, re.search("- .*?\</div>", str(div.select('.gs_a')[0])).group()[1:-6].replace("\xa0", ""), div.select('.gs_rt > a')[0]["href"]] for div in soup.select('.gs_ri')] data = [[x[0], int(x[1][6:]) if x[1] != None and x[1].startswith("被引用次数") else 0, x[2], x[3]] for x in data] return data def save_paper_list(data, file_name): data = pd.DataFrame(data, columns=['paper title', 'reference', 'publish info', 'url']) writer = pd.ExcelWriter(file_name) data.to_excel(writer, index=False, encoding='utf-8', sheet_name='Sheet1') writer.save() writer.close() def get_paper_list_by_keywork(keyword, start_year = None, end_year = None, max_capacity = 100, debug_mode = False, save_file = "paper_list.xlsx", retry_times = 3): keyword = re.sub(" +", "+", keyword.strip()) url_base = 'https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5' url_base = url_base + '&q=' + keyword if start_year != None: url_base += "&as_ylo=" + str(start_year) if end_year != None: url_base += "&as_yhi=" + str(end_year) start = 0 data = [] while start < max_capacity: url = url_base + "&start=" + str(start) start += 10 print(url) for i in range(retry_times): try: data.extend(get_paper_page(url)) break except Exception as e: if i < retry_times -1: print("error, retrying ... ") else: print("error, fail to get ", url) if debug_mode: traceback.print_exc() time.sleep(20) time.sleep(10) # data: [论文标题, 引用数, 发表时间及机构缩写, 论文链接] print(data) save_paper_list(data, save_file) if __name__ == "__main__": get_paper_list_by_keywork(" named entity recognition ", start_year=2020, max_capacity=100, debug_mode=False, save_file = "paper_list.xlsx") print("end")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
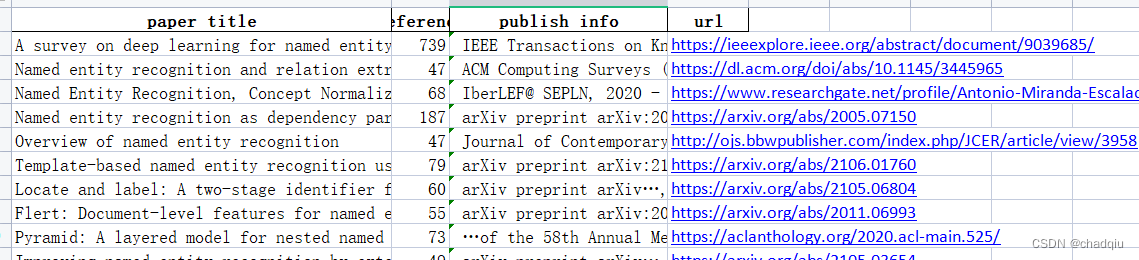
爬取结果excel文件如下图所示:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/364813
推荐阅读
相关标签

