- 1快速上手Spring Cloud 九:服务间通信与消息队列
- 2linux下golang开发环境配置+liteidex+第三方库的下载和引用_go linux下,怎么根据go.mod下载第3方库
- 3Python自动抓取网页新闻,轻松实现!_python爬取新闻网站内容
- 4回溯算法设计(2):回溯法解决0/1背包问题_0/1背包回溯法算法设计
- 5升级鸿蒙谷歌框架下载,网友Mate 40 Pro+升级鸿蒙2.0:谷歌服务不受影响
- 6Swin-Transformer网络结构详解_swin transformer
- 7DragGAN:简介,安装,使用!
- 8【工作中问题解决实践 三】深入理解RBAC权限模型_rbac1模型
- 9基于差影法实现基于图像的人体姿态行为识别(附带MATLAB代码)_matlab差影法代码
- 10Ubuntu中使用Nginx将静态网页部署到云服务器_网页如何发布到ubuntu服务器上
SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing
赞
踩
- code & pretrained model
- 2022ACL
- Junyi Ao, Rui Wang 南方科技大学& 香港理工
abstract
SpeechT5 将speech和text投射到共享高维空间中,提取通用模态表征。
encoder-decoder的结构,以及six modal-specific (speech/text) pre/post-nets,单独处理text和speech。
在多项下游任务中取得优势,包括ASR、TTS、speech translation,VC,speech identification (SID),speech enhancement (SE)
intro
预训练模型在NLP上有成功,在语音任务上也有wav2vec,HuBERT这样成功的先例。
但是现有的语音预训练模型存在的问题是:(1)大部分通过无标签的speech数据自监督训练,忽略了文本数据的重要性,对于一些语言任务缺乏模态转换的能力;(2)大部分模型仅依靠pretrained speech encoder,然后就对接下游任务。没有预训练的decoder用于seq2seq的生成。
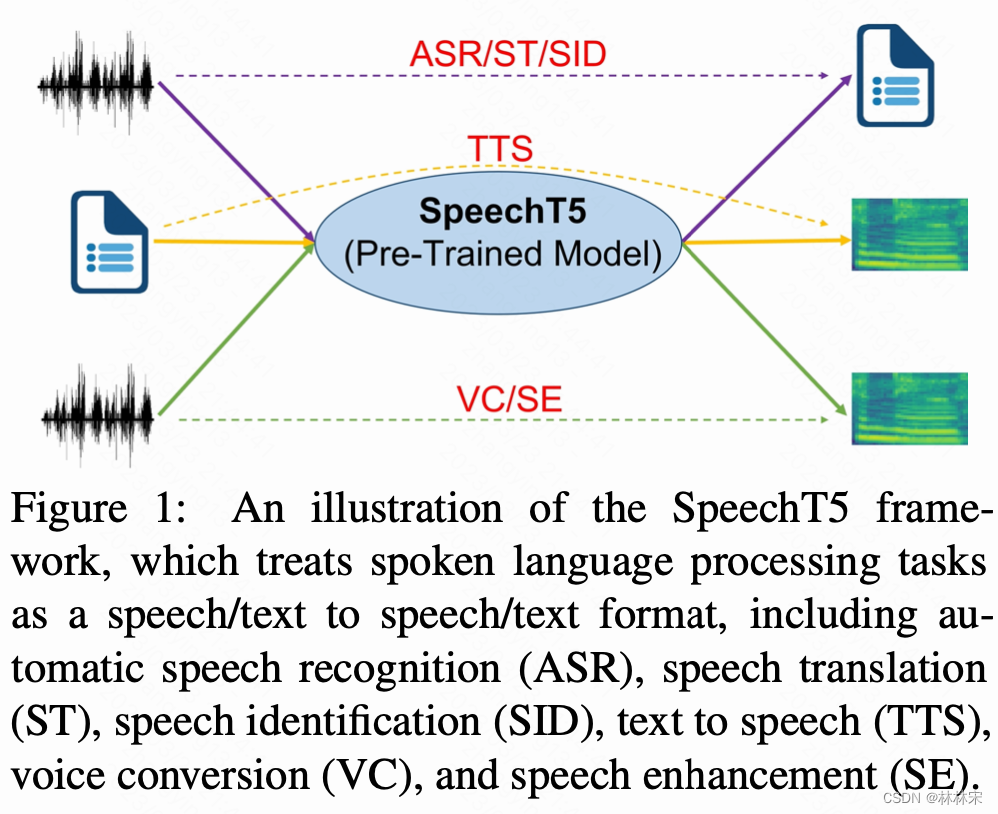
本文提出SpeechT5模型,unified- modal pre-training framework,充分利用无标签的音频和文本数据,完成speech到text之间的转换(多种形式)。不同的prenet分别将speech/text映射到同一共享空间,encoder-decoder的网络完成seq2seq的转换,然后经由单独的postnet生成speech/text。
对于text和speech数据对齐的问题,(1)将speech/text映射到共享的vector quantization space,(2)随机的混合quantized latent representations以及 contextual states, 可以帮助量化器更好的进行跨模态建模。
method
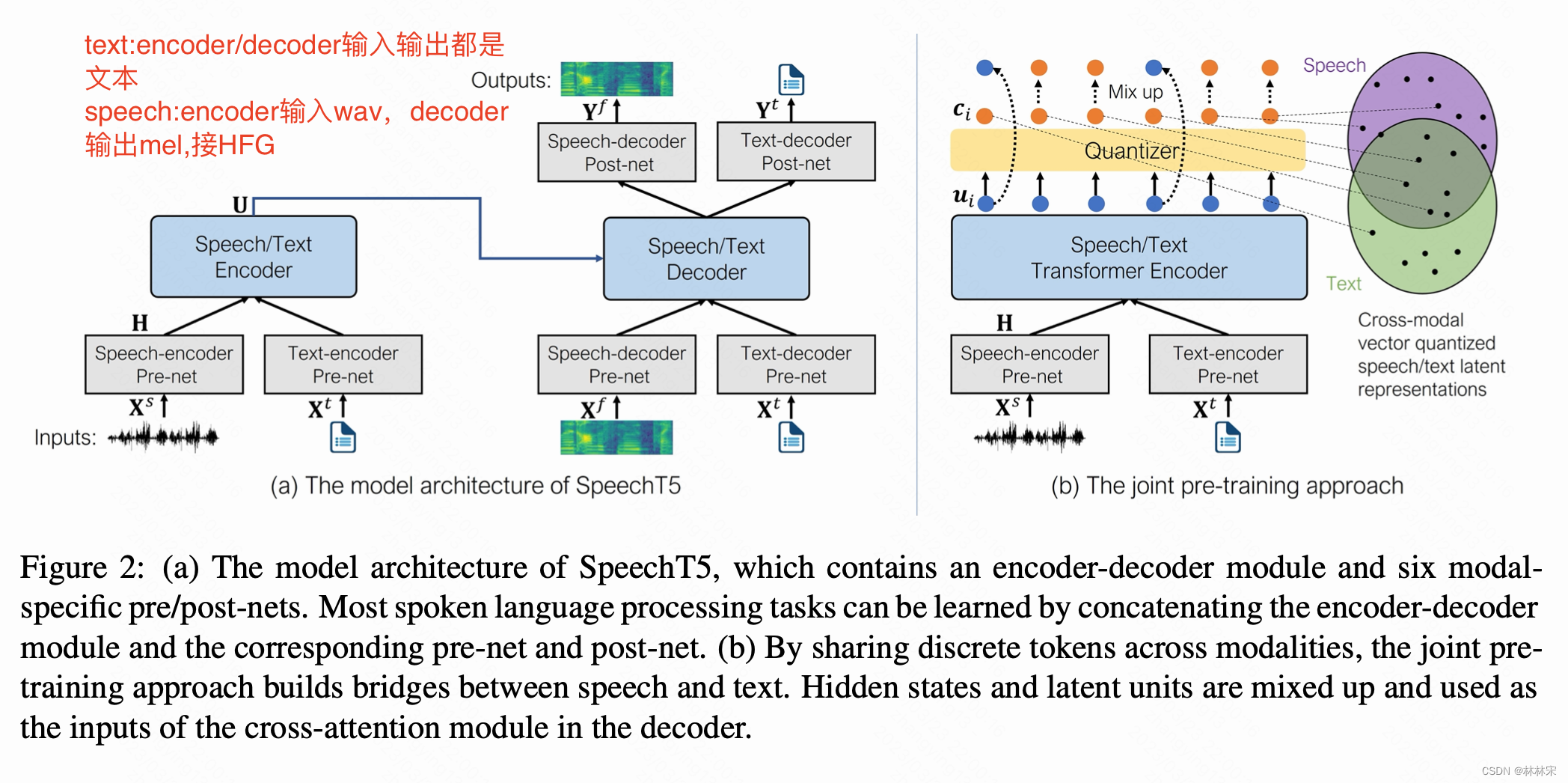
Model Architecture
- Input/Output Representations:
- text:encoder/decoder输入输出都是文本
- speech:encoder输入wav,decoder输出mel,接HFG
- Encoder-Decoder Backbone
- transformer encoder-decodert
- relative position embedding 加在slf-attention的 dot-product weights 中
- Speech Pre/Post-Net
- speech encoder prenet:The convolutional feature extractor of wav2vec 2.0,将波形压缩
- speech decoder prenet:3linearReLU,输入log mel-fbank,拼接x-vector(过一层linear),作为输入,控制多说话人合成。
- speech decoder postnet:(1)linear预测log mel-fbank Y f Y^f Yf+ 5*conv1d 残差预测细节补充;(2)预测mel 的stop token。
- Text Pre/Post-Net:共享embedding矩阵
- pre-net :将token index转成embedding vector
- post-nets:输入embedding,softmax多分类预测所属的最大概率的token,
Pre-Training
- Speech Pre-Training
- 类似HuBERT,使用masked language model ,首先将音频处理成帧级别的信息
Z
Z
Z ,然后随机挑选8% steps作为片段开头mask,mask长度=10, 然后将masked之后的特征输入transformer-encoder,预测高维表征,使用CE Loss约束。
H=speech_erncoder_prenet(audio)
U=transformer_encoder(H)
Z =k-meas(U)
- 类似HuBERT,使用masked language model ,首先将音频处理成帧级别的信息
Z
Z
Z ,然后随机挑选8% steps作为片段开头mask,mask长度=10, 然后将masked之后的特征输入transformer-encoder,预测高维表征,使用CE Loss约束。
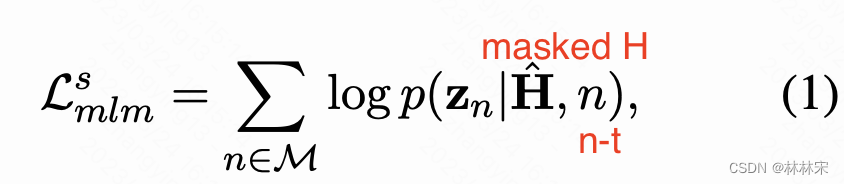
- 重建损失 L1 loss + BCE stop tokens loss
Y
=
s
p
e
e
c
h
−
d
e
c
o
d
e
r
−
p
o
s
t
n
e
t
−
o
u
t
p
u
t
,
X
:
输入
Y= speech-decoder-postnet-output, X:输入
Y=speech−decoder−postnet−output,X:输入
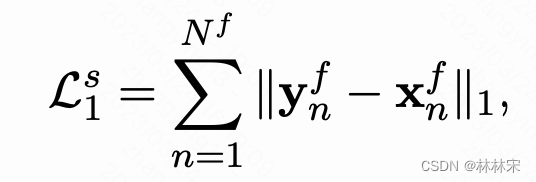
- text pretraining:有损的文本
X
′
X^{'}
X′作为输入,预测输出,对输入采用一定比例的mask,mask的部分单词用mask token代替。参考BART和T5的策略。
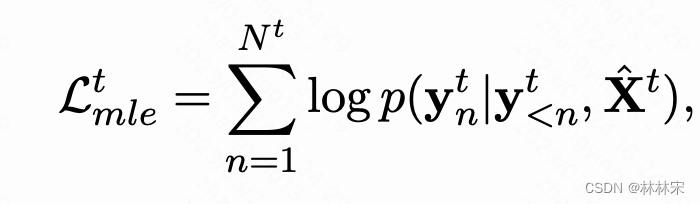
- joint pre-training:上面提到的方法只建模了一个模态,难以应用到跨模态的转换中,本文提出一个跨模态量化的方法,speech和text使用同一个码本,将特征离散,并映射到同一空间。
U , C U,C U,C分别是encoder的输出,和固定的码本特征
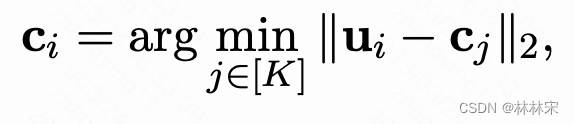
将一部分text representation替换成对应时间步量化后的特征,可以帮助量化器利用跨模态的信息。多样性loss帮助学到更多共享信息。 p k p_k pk是多分类的结果概率结果。
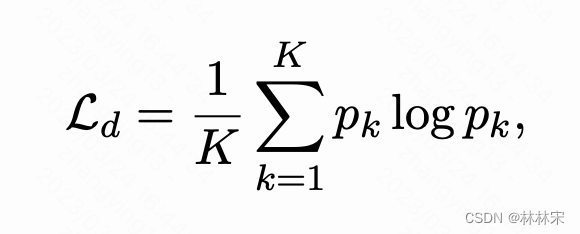
- total loss
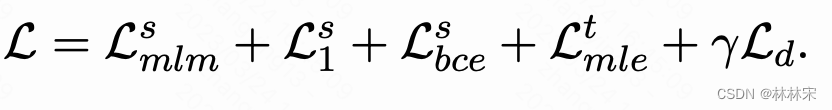
finetuning
- 预训练之后,在下游任务的数据集上进行finetune,这时针对性的选择对应的模块,比如ASR任务,选择speech-encoder prenet, encoder-decoder,text-decoder pre/postnet
experiment
- model arch:12-layer transformer encoder + 6-layer transformer decoder, MHA=12。其中encoder的参数设置和wav2vec以及HuBert是一样的。
- 数据集:speech-LibriSpeech 960h数据,text 400M句子,
- 机器:32*V100,bs=90s speech/12k tokens text perGPU,2 step更新一次,一共500k step
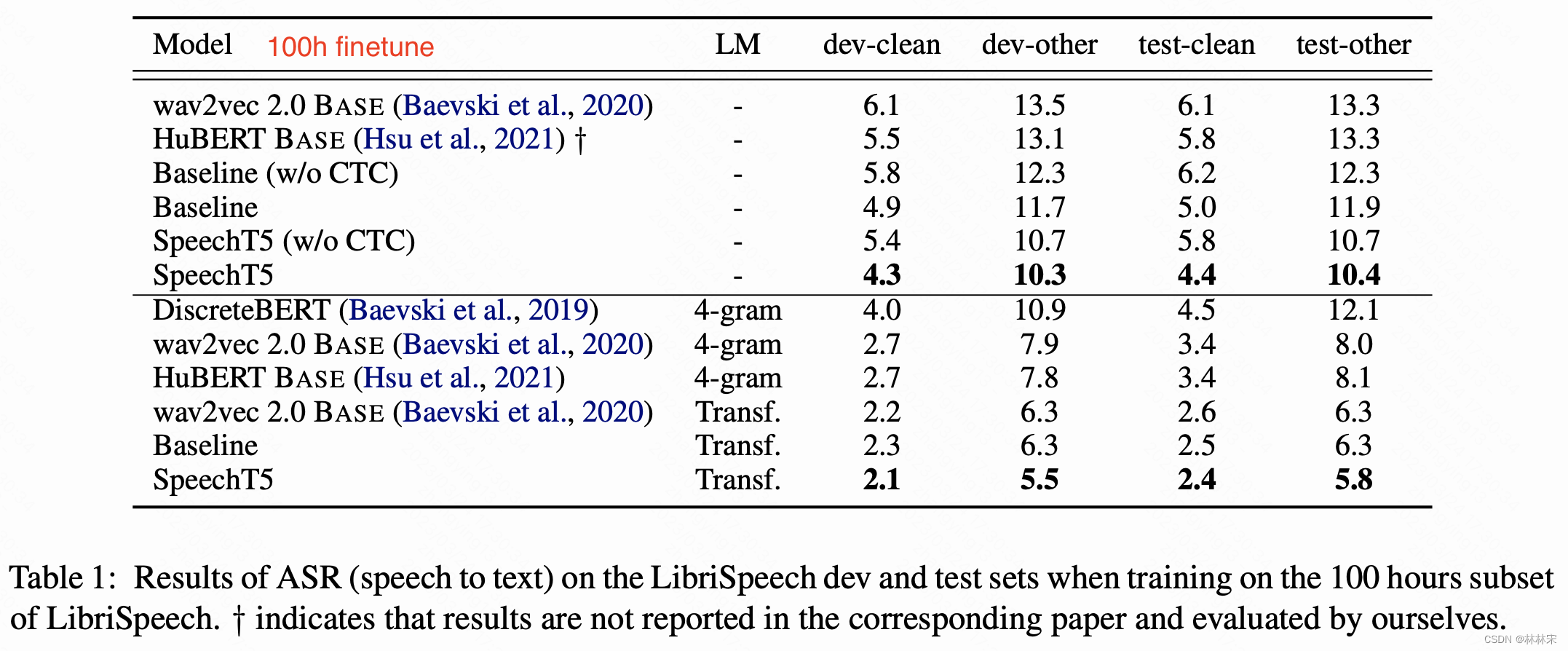
ASR evaluation
TTS evaluation

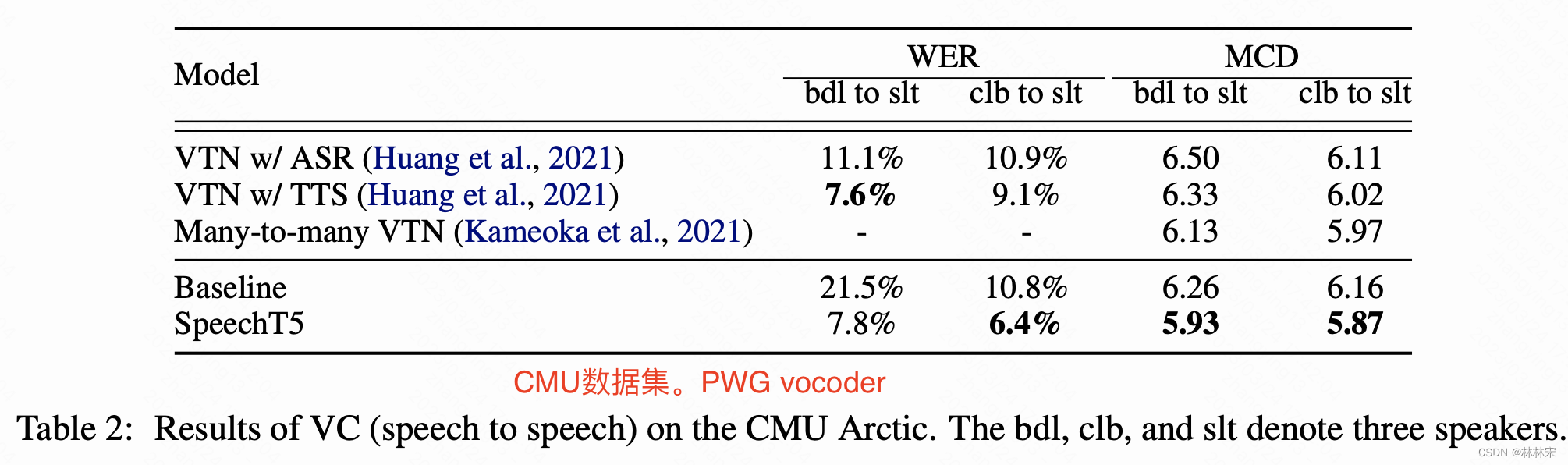
VC evaluation