
- 1Scikit-learn 数据挖掘和数据分析工具的使用指南
- 2使用遗忘因子最小二乘法(FFRLS)的锂离子电池二阶RC参数辨识
- 3论文笔记:Cross -Scale Self-Attention Module(CSSA):跨尺度自注意力模块
- 4图片/视频等效果质量评测指标
- 5Python基础篇(二)-- 数据类型和运算符_print(str[0:7:2])的结果为
- 6【AI大模型应用开发】【LangChain系列】1. 全面学习LangChain输入输出I/O模块:理论介绍+实战示例+细节注释_langchain+openai构建module i/o
- 7100天精通Python(可视化篇)——第100天:Pyecharts绘制多种炫酷漏斗图参数说明+代码实战_phtyon漏斗图
- 810亿数据要存要查,选Mongodb还是Elalsticsearch?_manticoresearch和es比较
- 9上采样、下采样、过采样、欠采样是什么?_欠采样和过采样 谢邀
- 10Vue官网下载Vue.js和Vue.min.js_vue.js官网
浅析分布式数据库
赞
踩
前言
随着信息技术的迅猛发展,各行各业产生的数据量呈爆炸式增长,传统集中式数据库的局限性在面对大规模数据处理中逐渐显露,从而分布式数据库应运而生。分布式数据库是在集中式数据库的基础上发展起来的,是分布式系统与传统数据库技术结合的产物,具有透明性、数据冗余性、易于扩展性等特点,还具 备高可靠、高可用、低成本等方面的优势,能够突破传统数据库的瓶颈。应用对数据库的要求越来越高,新的应用要求数据库不仅具有良好的ACID属性,还要具有良好的扩展性。
数据库发展历程
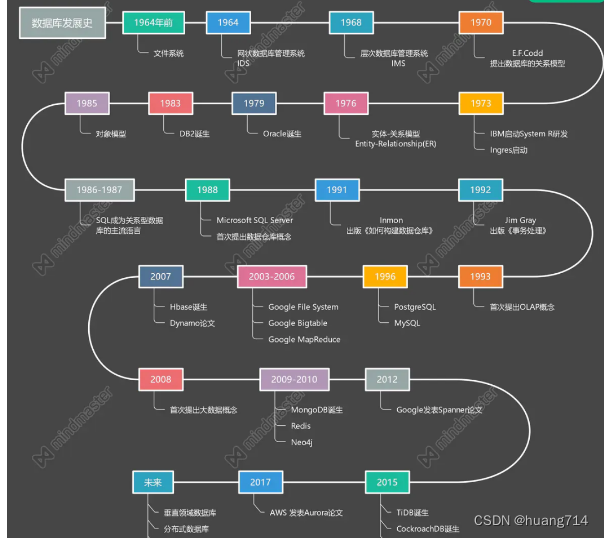
简单一句话总结,整体数据库的发展经历了SQL、NoSQL、NewSQL、Distributed SQL。
具体SQL、NoSQL、NewSQL类型有如下分类:
SQL
SQL是关系型数据库管理系统(RDBMS),顾名思义,它是围绕关系代数和元组关系演算构建的。70年代以来,它一直是主要的数据库解决方案,只是最近才有了其他产品的空间。不管有些人说什么,这意味着它一直能出色地执行广泛的任务。其主要优点如下:
- 不同的角色(开发者,用户,数据库管理员)使用相同的语言。
- 不同的RDBMS使用统一标准的语言。
- SQL使用一种高级的非结构化查询语言。.
- 它坚持 ACID 准则 (原子性,一致性,隔离性,持久性),,这些准则保证了数据库尤其是每个事务的稳定性,安全性和可预测性。
如你所见,许多SQL的好处来源于它的统一性,舒适性和易用性。即使你只有非常有限的SQL知识(或完全没有,如果需要),你可以在像 online SQL Query Builder 这样的特殊工具帮助下使用它。
然而,它的缺点使得它非常不适合某些类型的项目。SQL的主要问题是它难以扩展,因为它的性能随着数据库的变大而快速下降。分布式也是有问题的。
NoSQL和NewSQL出现的原因之一是,以前的RDBMS的设计不能满足现代数据库每秒处理的事务数量。像亚马逊或阿里巴巴等需要处理惊人数据量的巨头,以前的RDBMS会在几分钟内出现问题。
NoSQL (Not Only SQL)
NoSQL越来越受欢迎,其中最重要的实现是Apache Cassandra,MongoDB等产品。它主要用于解决SQL的可扩展性问题。因此,它是没有架构的并且建立在分布式系统上,这使得它易于扩展和分片。
然而,这些好处是以放宽ACID原则为代价的:NoSQL采取最终一致性原则,而不是所有四个参数在每个事务中保持一致。这意味着如果在特定时间段内没有特定数据项的更新,则最终对其所有的访问都将返回最后更新的值。这就是这样的系统通常被描述为提供基本保证的原因(基本可用,软状态,最终一致性) — 而不是ACID。
虽然这个方案极大地增加了可用时间和伸缩性,它也会导致数据丢失----这个问题的严重程度取决于数据库服务器的支持情况和应用代码质量.在某些情况下,这个问题十分严重。
另一个NoSQL出现的问题是现在有很多类型的NoSQL系统,但它们之间却几乎没有一致性.诸如灵活性,性能,复杂性,伸缩性等等特性在不同系统间差别巨大,这使得甚至是专家在他们之间都很难选择。不过,当你根据项目特点作出了合适的选择,NoSQL可以在不显著丢失稳定性的情况下提供一个远比SQL系统更高效的解决方案。
NewSQL
人们常常批评 NoSQL“为了倒掉洗澡水,却把婴儿一起冲进了下水道”(Throwing the baby out with the bathwater)。SQL 类数据库应用如此广泛,为了分布式特性就需要抛弃 SQL 显得非常得不偿失。
因此一些组织开始构建基于 SQL 的分布式数据库,从表面看它们都支持 SQL,但是根据实现方式,其发展出了两种路线:NewSQL 和 Distributed SQL。这一讲我先介绍前者。
NewSQL 是基于 NoSQL 模式构建的分布式数据库,它通常采用现有的 SQL 类关系型数据库为底层存储或自研引擎,并在此之上加入分布式系统,从而对终端用户屏蔽了分布式管理的细节。Citus 和 Vitess 就是此种类型的两个著名案例,在后面的第四个模块中,我会具体介绍。
此外,一些数据库中间件,如 MyCAT、Apache ShardingShpere,由于其完全暴露了底层的关系型数据库,因此不能将它们称为 NewSQL 数据库,不过可以作为此种模式的另类代表。
大概在 2010 年年初的时候,人们尝试构建此类数据库。而后,451 ResEArch 的 Matthew Aslett 于 2011 年创造了“NewSQL”这个术语,用于对这些新的“可扩展” SQL 数据库进行定义。
NewSQL 数据库一般有两种。
第一种是在一个个独立运行的 SQL 数据库实例之上提供了一个自动数据分片管理层。例如,Vitess 使用了 MySQL,而 Citus 使用 PostgreSQL。由于每个独立实例仍然是单机关系型数据库,因此一些关键特性无法得到完美支持,如本地故障转移 / 修复,以及跨越分片的分布式事务等。更糟糕的是,甚至一些单机数据库的功能也无法进行使用,如 Vitess 只能支持子查询的一个“子集”。
第二种包括 NuoDB、VoltDB 和 Clustrix 等,它们构建了新的分布式存储引擎,虽然仍有或多或少的功能阉割,但可以给用户一个完整的 SQL 数据库体验。
NewSQL 数据库最初构建的目的是解决分布式场景下,写入 SQL 数据库所面临的挑战。它可以使用多个传统单机 SQL 数据库作为其存储节点,在此基础上构建起可扩展的分布式数据库。在它产生的年代,云技术还处于起步阶段,因此这类 NewSQL 得到了一定程度的发展。但是,随着多可用区、多区域和多云的云部署成为现代应用程序的标准,这些数据库也开始力不从心起来。
与此同时,像 Google Spanner 和 TiDB 这样的 Distributed SQL 数据库的崛起,NewSQL 数据库的地位就受到了进一步挑战。因为后者是被设计利用云组价的特性,并适应在不可靠基础设施中稳定运行的“云原生”数据库。
可以看到 NewSQL 回归了以 SQL 为核心的状态,这次回归展示了 SQL 的魅力,即可以穿越数十年时光。但这次革命是不彻底的,我们可以看到传统单机数据库的身影,还有对 SQL 功能的阉割。而革命者本身也往往来自应用领域,而不是专业数据库机构。所以NewSQL 更像是用户侧的狂欢,它可以解决一类问题,但并不完备,需要小心地评估和使用。
Distributed SQL
上面我也提到过 Distributed SQL 数据库,此种使用的是特殊的底层存储引擎,来构建水平可伸缩的数据库。它在 NewSQL 的功能基础上,往往提供的是“地理分布”功能,用户可以跨可用区、区域甚至在全球范围内分布数据。CockroachDB、Google的Spanner、OceanBase 和 PingCAP 的 TiDB 就是很好的例子,这些引擎通常比 NewSQL 的目标更高。
但需要强调的是,NoSQL 和 NewSQL 是建立在一个假设上,即构建一个完备功能的分布式数据库代价是高昂的,需要进行某种妥协。而商用 Distributed SQL 数据库的目标恰恰是要以合理的成本构建这样一种数据库,可以看到它们的理念是针锋相对的。
相比于典型的 NewSQL,一个 Distributed SQL 数据库看起来更像一个完整的解决方案。它的功能一般包括可扩展性、数据一致性、高可用性、地理级分布和 SQL 支持,它们并非一些工具的组合。一个合格的 Distributed SQL 数据库应该不需要额外工具的支持,就可以实现上述功能。
此外,由于 Distributed SQL 天然适合与云计算相结合,因此一些云原生数据库也可以归为此门类,如 AWS 的 Aurora 等。不论是云还是非云数据库,Distributed SQL 几乎都是商业数据库,而 NewSQL 由于其工具的本质,其中开源类型的数据库占有不小的比重。
这一方面反映了 Distributed SQL 非常有潜力且具有商业价值,同时也从一个侧面说明了它才是黄金年代 SQL 关系型数据库最为正统的传承者。
新一代的 SQL 已经冉冉升起,它来自旧时代。但除了 SQL 这一个面孔外,其内部依然发生了翻天覆地的改变。不过这正是 SQL 的魅力:穿越时光,依然为数据库的核心,也是数据库经典理论为数不多的遗产。
分布式数据库发展历程
2006年,Google发布了三篇论文,也是公认的大数据的三驾马车:分布式文件系统GFS、分布式KV存储数据库Big Table以及处理和生成超大数据集的算法模型MapReduce。
此后,虽然分布式开始成为大家讨论的对象,但由于分布式事务的性能以及分布式系统的复杂性,使得分布式数据库仅在数据量非常大的联机分析处理(OLAP)场景得到了一些应用。在传统数据库领域,仍以Oracle为代表的的集中式数据库独霸天下,更是独领国际市场,阿里便是其在中国最大的客户。
此后的十年,是分布式数据库被“冷落”的十年。与其说是被“冷落”,不如说是技术上难以突破,以及培育成本高,当时集中式数据库的商业化之路越走越顺,能够停下来从头开始的厂商少之又少。
不过,随着互联网时代的加速发展和科技的进步,集中式数据库的功能开始捉襟见肘。越来越多的企业进行数字化转型,对业务系统也更加高频的并发访问,当产生庞大的数据处理量,集中式数据库昂贵的成本和存储、计算极为有限的扩展能力开始暴露,企业不得不寻求性价比更高、存储和计算扩展能力更强的数据库。
2010年,阳振坤在阿里的招募下,开始研发国内第一款全自研式分布式数据库OceanBase。彼时的分布式技术是真正的无人区,直至2015年,腾讯云、阿里云、PingCap等公司才开始在初步探索。
分布式数据库被“冷落”的10年,正是OceanBase在蚂蚁内部打磨的十年。从仅用在淘宝收藏夹一个细小的场景,到支撑了9年的淘宝双十一,并打破了TPC-C测试的世界纪录,直至2020年独立,到目前已经累计了400+客户。
简单总结一下,分布式数据库发展大概经历了三个阶段:
第一代是分布式存储系统,也称为 NoSQL,2013 年之前比较流行,基本思路是牺牲 SQL,牺牲事务、一致性和企业级功能,只支持简单的 KV 操作从而做到可扩展;
第二代是分布式数据库,以 Google Spanner 系统为代表,支持可扩展的 SQL,在第一代 NoSQL 系统的基础之上引入了 SQL 和分布式事务,保证强一致性,但是不太注重 SQL 兼容性和性价比,单机性能往往比较差;
第三代是透明扩展的企业级数据库,也就是我说的“下一代企业级分布式数据库”。以 OceanBase、TiDB 为代表。分布式架构对业务透明,支持完备的兼容 MySQL 和 Oracle 的企业级功能,支持 HTAP 混合负载,单机性能很高,且系统架构的性能天花板很高,可以基于该架构追求极致性能。
什么是分布式数据库
首先看下百度百科对于分布式数据库系统的定义:
分布式数据库系统 (DDBS)包含分布式数据库管理系统(DDBMS)和分布式数据库(DDB)。在分布式数据库系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据分别在不同的局部数据库中存储、由不同的 DBMS进行管理、在不同的机器上运行、由不同的操作系统支持、被不同的通信网络连接在一起。
百度百科
分布式数据库最早于 20 世纪 80 年代提出,受限于当时 的计算机软硬件及网络发展水平,数据库专家 M.Tamer Özsu 和 Patrick Valduriez 在经典著作《分布式数据库系统原理(第 3 版)》中,把分布式数据库定义为一群分布在计算机网络上、 逻辑上相互关联的数据库。
随着信息技术的发展,集中式数 据库也正向基于网络的共享集群路线发展,而市场上的分布 式数据库也不仅限于网络分布、逻辑关联等特性,经典的分 布式数据库定义显然已不能体现分布式数据库当前技术特 点,难以满足数据库种类区分要求。
根据目前我国分布式数据库技术现状,我们认为分布式 数据库是具备分布式事务处理能力、可平滑扩展、分布于计 算机网络且逻辑上统一的数据库。主要特征如下:
- 分布式事务处理
分布式数据库与集中式数据库的 主要区别就是是否具备分布式事务的处理能力。通过对数据 库各种操作的并行计算、全局事务管理等机制,实现真正的 分布式事务处理,并实现与集中式数据库一致的 ACID 特性。
- 平滑扩展
分布式数据库可根据业务的增长需要, 动态扩展物理节点,以提升整体处理能力,且扩展过程不需 停机,不影响在线业务。理论上可以进行无限扩展,扩展之 后在逻辑上仍然是一个统一的数据库。
- 物理分布、逻辑统一
分布式数据库的数据不是存 储在一个物理节点中,而是存储在计算机网络上的多个节点 上,且通过网络实现了真正的物理分布。而逻辑上仍是一个 数据库,为用户提供统一的访问入口,实现对分布在网络节 点上的数据的统一操作,即用户可以像使用传统集中式数据 库一样使用分布式数据库,而不是分别操作多个数据库。
分布式数据库架构设计
经典数据库包含存储、事务、SQL 这几个核心引擎,以及基于这些核心引擎之上的数据库功能和性能、成本、安全、可靠等企业级特性。企业级分布式数据库在经典数据库的基础之上引入了分布式,实现了高可用和可扩展。虽然分布式数据库在原生分布式架构上产生了很多创新技术,但在数据库的功能、性能、精细化程度上还有一段很长的路要走。
企业级分布式数据库除了做好分布式,更要坚守数据库的初心:提升功能兼容性和单机性能。经典数据库的关键技术经受住了时间的考验,例如 SQL 标准、事务模型,企业级分布式数据库需要向经典数据库学习 SQL 兼容性。今天,分布式领域很热门的一些技术,例如存储计算分离、HTAP,最早也出自经典数据库,且经典数据库在精细化程度上往往做得更好。
存储设计
数据库常用的存储架构设计模型有三种:
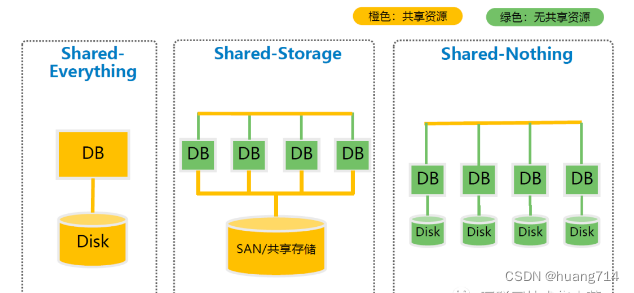
shared-Everything
一般针对于单机而言,完全透明的共享 CPU、内存和IO等资源,并行能力是三种结构中最差的。
shared-Disk
shared-disk也可以成为shared-storage,每个单元的CPU和内存是独立的,共享磁盘系统,典型产品有Oracle RAC,它是数据共享,可以通过增加节点来提高并行处理能力,扩展能力较好。当存储器接口达到饱和时,增加节点并不能获得更高的性能。
aurora采用了share storage, shared-storage同样可以解决 ha 和快速恢复(甚至比选举还快),特别是对于云厂商可以一个大 storage 给多个租户,对用户便宜对自己省钱。
shared-Nothing
每个处理单元所拥有的资源都是独立的,不存在共享资源。单元之间通过协议通信,并行处理和扩展能力更好。各个节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或者节点间流转。
目前包括国内OceanBase、TiDB都采用了Shared-Nothing架构。
Shared-Nothing架构的优势:
- 易于扩展
- 内部自动并行处理,无需人工分区或优化
- 最优化的IO处理
- 增加节点实现存储、查询及加载性能的线性扩展
存储计算分离
相信今天很多人都听过存储计算分离,但不同系统的做法差别很大。业界有三种存储计算分离方案:
中间件分库分表
基于中间件分库分表,后端的数据库表示存储,中间件表示计算,这种方案是真正的存储计算分离吗?显然不是,我也把这种方案叫做“伪存储计算分离”,主要有以下两种模式:
客户端程序库方式
该方式在客户端安装程序库,通过客户端程序库直接访问数据,该方式的优点是性能高,缺点是对应用有侵入。访问示意图如下:
典型客户端程序库中间件如阿里的TDDL,本文以TDDL为例,介绍客户端程序库方式的数据库访问中间件的工作原理。
TDDL采用了客户端库(即Java.jar包)形式,在Jar包中封装了分库分表的逻辑,部署在ibatis、mybatis或者其他ORM框架之下、JDBC Driver之上,是JDBC或持久框架层与底层JDBC Driver之间的交互桥梁。
TDDL的逻辑架构分为三层:Matrix 、Group、Atom。Matrix层负责分库分表路由,SQL语句的解释、优化和执行,事务的管理规则的管理,各个子表查询出来结果集的Merge等;Group层负责数据库读写分离、主备切换、权重的选择、数据保护等功能;Atom层是真正和物理数据库交互,提供数据库配置动态修改能力,包括动态创建,添加,减少数据源等。
当client向数据库发送一条SQL的执行语句时,会优先传递给Matrix层。由Martix 解释 SQL语句、优化,并根据查询条件将SQL路由到各个group;各个group根据权重选择其中一个Atom进行查询;各个Atom再将结果返回给Matrix,Matrix将结果合并返回给client。:
数据库代理服务中间件
数据库代理服务中间件部署在客户端与数据库服务器之间,对于客户端而言,它就像数据库服务器,而对于数据库服务器而言,它就像客户端。因所有数据库服务请求都需要经过数据库代理服务中间件,所以,中间件不仅可以记录所有的数据库操作,修改客户端发过来的语句,还可以对数据库的操作进行优化,实现其他如读写分离之类的能力

该方式应用程序不需要任何修改,只需把链接指向代理服务器,由代理服务器访问数据库,该方式的优点对应用没有侵入,缺点是性能低。
典型的数据库代理服务中间件有MySQL代理、Cobar、MyCAT、TDSQL等,本文以MySQL代理为例,介绍客户端程序库方式的数据库访问中间件的工作原理。
MySQL代理是MySQL官方提供的MySQL数据库代理服务中间件,其数据查询过程如下:
1、 数据库代理服务中间件收到客户端发送的SQL查询语句;
2、 代理服务中间件对SQL语句进行解析,得到要查询的相关信息,如表名CUSTOMER;
3、 代理服务中间件查询配置信息,获得表CUSTOMER的存储位置信息,如数据库A、B、C;
4、 同时根据解析的情况进行判断,如数据库A、B、C上都可能存在需要查询的数据,则将语句同时发送给数据库A、B、C。此时,如有必要,还可以对SQL语句进行修改。
5、 数据库A、B、C执行收到的SQL语句,然后将查询结果发送给数据库中间件。
6、 中间件收到数据库A、B、C的结果后,将所有的结果汇总起来,根据查询语句的要求,将结果进行合并。
7、 中间件将最后的结果返回给客户端
不同的数据库代理服务中间件,根据其支持的协议,可代理的数据库不同,如Cobar只能代理MySQL数据库,而MyCAT除了可代理MySQL外,还可代理其他关系型数据库吗,如Oracle、SQL Server等。
划分为 SQL、事务和分布式 KV 层
分布式 KV 表示存储,SQL 和事务表示计算,存储和计算采用松耦合设计,这种方案能够解决可扩展的 SQL 处理问题,但每次操作都涉及到计算和存储之间的远程访问,且事务相关元数据存储到分布式 KV 表格中,增加了事务处理的额外开销,牺牲了性能。
第二种最经典的代表是开源的TiDB数据库。下面是开源的TiKV,上面是SQL层,存储用KV,这样一来scale out的解决方案就会很方便。同样经典的就是TiDB模仿的对象,谷歌的Spanner,下面用的是BigTable上面再构建起Spanner层。
这种做法最大的好处就是scale out做起来很好。最大的坏处,就是单节点性能不行。客户是不是愿意牺牲单节点性能,从而获得更好的scale out,我想这个问题见仁见智。每个人可能会有不同的观点。
以TiDB为例简单介绍一下这种架构:
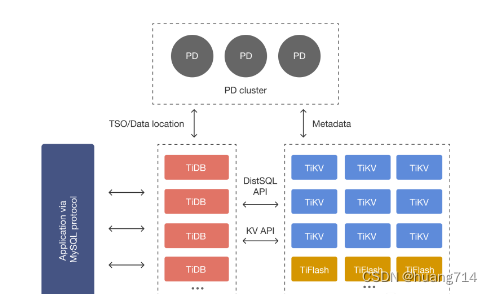
- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
- 存储节点
-
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
紧耦合设计
SQL、事务和 KV 表示计算,KV 层数据块依赖的分布式文件系统表示存储。这种方案来自于经典数据库的 IOE 架构,SQL、事务和 KV 层表示计算,底层依赖 EMC 的 SAN 存储。Amazon Aurora 借鉴了经典数据库的存储计算分离架构,并在云原生环境下发扬光大,成为最终的事实标准。
为了追求极致性能,我认为,企业级分布式数据库应该向经典数据库学习原生存储计算分离技术,我推荐这种方案。
但是最开始的Aurora版,底下是一个大磁盘,上面是计算层。这个大磁盘同时具备了Log merge的能力,这样的做法性能是不是可以做到单节点极致其实也存疑。
至于阿里巴巴另外一个数据库PolarDB,下面一个大磁盘接上单机MySQL,根本就没办法谈Scale out的事情了。PolarDB-X倒是更可能Scale out。但是早年的PolarDB-X上面三节点备份,下面文件系统再做三备份,一个记录写9份的骚操作,我没有在第二个数据库里见过。至于现在PolarDB-X演化的怎么样了,我也不好判断。
OceanBase 数据库采用 Shared-Nothing 架构,各个节点之间完全对等,每个节点都有自己的 SQL 引擎、存储引擎、事务引擎,运行在普通PC服务器组成的集群之上,具备高可扩展性、高可用性、高性能、低成本、与主流数据库高兼容等核心特性。
下图是OceanBase的整体架构:
OceanBase 数据库的一个集群由若干个节点组成。这些节点分属于若干个可用区(Zone),每个节点属于一个可用区。可用区是一个逻辑概念,表示集群内具有相似硬件可用性的一组节点,它在不同的部署模式下代表不同的含义。例如,当整个集群部署在同一个数据中心(IDC)内的时候,一个可用区的节点可以属于同一个机架,同一个交换机等。当集群分布在多个数据中心的时候,每个可用区可以对应于一个数据中心。每个可用区具有 IDC 和地域(Region)两个属性,描述该可用区所在的 IDC 及 IDC 所属的地域。一般地,地域指 IDC 所在的城市。可用区的 IDC 和 Region 属性需要反映部署时候的实际情况,以便集群内的自动容灾处理和优化策略能更好地工作。
在 OceanBase 数据库中,一个表的数据可以按照某种划分规则水平拆分为多个分片,每个分片叫做一个表分区,简称分区(Partition)。某行数据属于且只属于一个分区。分区的规则由用户在建表的时候指定,包括hash、range、list等类型的分区,还支持二级分区。例如,交易库中的订单表,可以先按照用户 ID 划分为若干一级分区,再按照月份把每个一级分区划分为若干二级分区。对于二级分区表,第二级的每个子分区是一个物理分区,而第一级分区只是逻辑概念。一个表的若干个分区可以分布在一个可用区内的多个节点上。每个物理分区有一个用于存储数据的存储层对象,叫做 Tablet ,用于存储有序的数据记录。
当用户对 tablet 中记录进行修改的时候,为了保证数据持久化,需要记录重做日志(REDO)到 Tablet 对应的日志流(Log Stream)里。每个日志流服务了其所在节点上的多个 tablet。为了能够保护数据,并在节点发生故障的时候不中断服务,每个日志流及其所属的 Tablet 有多个副本。一般来说,多个副本分散在多个不同的可用区里。多个副本中有且只有一个副本接受修改操作,叫做主副本(Leader),其他副本叫做从副本(Follower)。主从副本之间通过基于 Multi-Paxos 的分布式共识协议实现了副本之间数据的一致性。当主副本所在节点发生故障的时候,一个从副本会被选举为新的主副本并继续提供服务。
在集群的每个节点上会运行一个叫做 observer 的服务进程,它内部包含多个操作系统线程。节点的功能都是对等的。每个服务负责自己所在节点上分区数据的存取,也负责路由到本机的 SQL 语句的解析和执行。这些服务进程之间通过 TCP/IP 协议进行通信。同时,每个服务会监听来自外部应用的连接请求,建立连接和数据库会话,并提供数据库服务。
为了简化大规模部署多个业务数据库的管理并降低资源成本,OceanBase 数据库提供了独特的多租户特性。在一个 OceanBase 集群内,可以创建很多个互相之间隔离的数据库"实例",叫做一个租户。从应用程序的视角来看,每个租户是一个独立的数据库。不仅如此,每个租户可以选择 MySQL 或 Oracle 兼容模式。应用连接到 MySQL 租户后,可以在租户下创建用户、database,与一个独立的 MySQL 库的使用体验是一样的。同样的,应用连接到 Oracle 租户后,可以在租户下创建 schema、管理角色等,与一个独立的 Oracle 库的使用体验是一样的。一个新的集群初始化之后,就会存在一个特殊的名为 sys 的租户,叫做系统租户。系统租户中保存了集群的元数据,是一个 MySQL 兼容模式的租户。
为了隔离租户的资源,每个 observer 进程内可以有多个属于不同租户的虚拟容器,叫做资源单元(UNIT)。每个租户在多个节点上的资源单元组成一个资源池。资源单元包括 CPU 和内存资源。
为了使 OceanBase 数据库对应用程序屏蔽内部分区和副本分布等细节,使应用访问分布式数据库像访问单机数据库一样简单,我们提供了 obproxy 代理服务。应用程序并不会直接与 OBServer 建立连接,而是连接obproxy,然后由 obproxy 转发 SQL 请求到合适的 OBServer 节点。obproxy 是无状态的服务,多个 obproxy 节点通过网络负载均衡(SLB)对应用提供统一的网络地址。
HTAP
HTAP并不是什么新概念,自从2014年,Gartner提出 HTAP(Hybrid Transaction / Analytical Processing,混合事务分析处理)概念之后,HTAP就一直被热炒,因为确实有场景支持,所以,也备受关注,因此,号称HTAP的数据库产品也越来越多。
但什么才是真正的HTAP?是近年来特别火的话题,并不是具有同时处理TP 和AP的能力,就是HTAP数据库。
目前,比较主流的观点是,真正的HTAP,是高度融合的一个系统。这里需要注意,高度融合的一个系统,不是把两个不同的系统拼接在一起形成所谓的一个系统。这并不符合“一份数据”的要求,本质上还是使用两个系统,成本必然大幅上升,并且系统后续的开发和运维,也会有各种问题。另外,这种系统是无法保证对事务的支持能力、数据实效性的。
真正的HTAP,一定是基于一体化架构。当然,这种架构在技术上实现难度更大。但对事务的支持能力和数据的实效性等方面都能提供更好的保证。
HTAP 实现通常有如下两种做法:
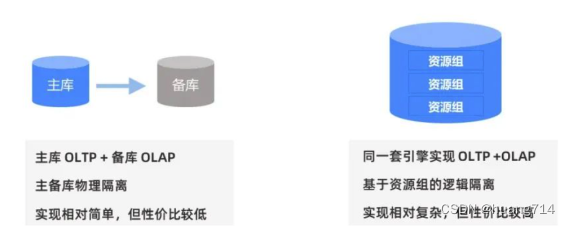
第一种是主备库物理隔离,主库做 OLTP,备库做 OLAP,主备之间通过 redo 日志做同步,备库与主库之间有一定的延迟。第二种是在同一套引擎实现 OLTP 和 OLAP 混合负载,区分 OLTP 和 OLAP 请求所在的资源组,对资源组进行逻辑隔离。
第一种方案实现相对简单,但由于产生了更多数据冗余,性价比较低;第二种方案实现相对复杂,但采用一体化设计,性价比更高。第二种方案来自经典数据库,例如 Oracle、SQL Server。
我认为,企业级分布式数据库应该学习 HTAP 技术,采用第二种方案。
经典数据库
经典数据库,例如 Oracle 数据库或者 SQL Server 数据库,其实都是在一套引擎下支持 HTAP 混合负载,这种方式做得更精细,性价比更高,且经典数据库通过类似 Cgroup 等技术已经解决了 TP(Transactional Processing) 和 AP(Analytical Processing)隔离的问题。OceanBase 数据库在技术上可以更多地借鉴发展了五十多年的经典关系数据库。
TiDB
在早先版本的TiDB里面,Raft增加了单纯的listener,作为备库,备库是列式的存储。有别于基于KV的OLTP workload的存储。
TiDB早期的AP引擎是魔改ClickHouse得来的。主要利用列存进行AP处理。但是也可以在有必要的时候从行存中读取。总体来说,还是两套引擎。TiDB 5.0版本,据说引入了类似GreenPlum的MPP架构,使得其对OLAP的处理更上一层楼。TiDB 是计算和存储分离的架构,底层的存储是多副本机制,可以把其中一些副本转换成列式存储的副本。OLAP 的请求可以直接打到列式的副本上,也就是 TiFlash 的副本来提供高性能列式的分析服务,做到了同一份数据既可以做实时的交易又做实时的分析,这是 TiDB 在架构层面的巨大创新和突破。
TiDB 的理论基础来源于 2013 年 Google 发布的 Spanner / F1 论文 ,以及 2014 年 Stanford 工业级分布式一致性协议算法 Raft 论文。在架构上,TiDB 将计算和存储层进行高度的抽象和分离,对混合负载的场景通过 IO 优先级队列、智能副本调度、行列混合存储等技术,使 HTAP 变为可能。
参考 Google Spanner / F1 的设计,TiDB 整体架构分为上下两层:负责计算的 TiDB Server 和 负责存储的 TiKV Server,二者由集群管理模块 PD Server 调度和管理。
TiDB Server 对应于 Google F1, 是一层无状态的 SQL Layer ,其本身并不存储数据,只负责计算。在接收到 SQL 请求后,该计算层会通过 PD Server 找到存储计算所需数据的 TiKV 地址,然后与 TiKV Server 交互获取数据,最终返回结果。在水平扩展方面,随着业务的增长,用户可以简单地添加 TiDB Server 节点,提高数据库整体的处理能力和吞吐。
作为整个集群的管理模块,PD(Placement Driver ) 主要工作有三类:一是存储集群的元信息;二是对 TiKV 集群进行调度和负载均衡,如数据的迁移、Raft group leader 的迁移等;三是分配全局唯一且递增的事务 ID。
TiKV Server 是一个分布式 Key Value 数据库,对应于 Google Spanner ,支持弹性水平扩展。不同于 HBase 或者 BigTable 那样依赖底层的分布式文件系统,TiKV Server 在性能和灵活性上更好,这对于在线业务来说非常重要。随着数据量的增长,用户可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 模块则会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。
OceanBase
真正的 HTAP 是在 OLTP 数据库的基础上扩展 OLAP 的能力。经典的 OLTP 数据库,无论是开源的 MySQL,还是商业数据库 Oracle/SQL Server,都采用集中式架构,底层存储引擎是面向磁盘设计的 B+ 树。这种方案是为小数据量的实时事务处理量身定制的,读写性能很好但相比 LSM Tree 等新型数据结构存储成本更高。以 OceanBase 为例,底层采用优化过的 LSM Tree 存储引擎,在支付宝所有业务完全替换 Oracle/MySQL,存储成本只有原来 B+ 树方案的 1/3 左右。
经典数据库,比如 Oracle 或者 SQL Server,其实都是在一套引擎下支持 HTAP 混合负载,这种方式做得更精细,性价比更高,且经典数据库通过类似 cgroup 等技术已经解决了 TP 和 AP 隔离的问题。OceanBase 技术上可以更多借鉴发展了五十多年的经典关系数据库。
OceanBase 的HTAP采用的是无共享 MPP 架构,OceanBase 数据库自创的分布式计算引擎,能够让系统中多个计算节点同时运行 OLTP 类型的应用和复杂的 OLAP 类型的应用,真正实现了用一套计算引擎同时支持混合负载的能力,让用户通过一套系统解决 80% 的问题,充分利用客户的计算资源,节省客户购买额外的硬件资源、软件授权带来的成本。
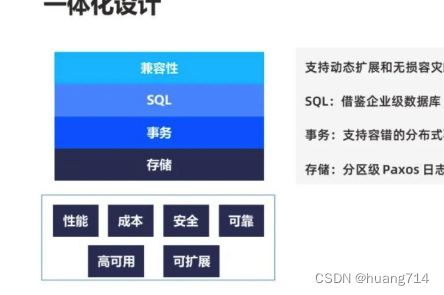
在 SQL 层,借鉴企业级数据库,例如 Oracle 的 HTAP 设计,在同一套引擎同时支持 OLTP 和 OLAP 混合负载;在事务层,实现了支持自动容错的分布式事务和多版本并发控制,保证与经典集中式数据库对标的强一致 ACID;在存储层,通过分区级 Paxos 日志同步实现高可用和自动扩展,支持灵活的存储架构,包括本地存储,以及存储计算分离。
OceanBase的AP 主要采用行列混合存储、编译执行、向量引擎、基于代价的查询改写和优化等技术,再加上 OceanBase 的可扩展性很好,OceanBase 在 AP 领域里面的实时分析部分是业界领先的。当然,对于离线大数据处理,Spark 等大数据方案可能是更合适的选择。
经典数据库通过行列混合存储支持 HTAP 混合负载,将一个表格划分为行组(row group),每个行组内按列存储,在行存和列存之间寻找一个平衡点。
每个行组都是一个压缩单位,支持智能索引和高效压缩,例如在行组内存储 count、sum 等索引元数据。另外,Oracle 和 SQL Server 都支持 In Memory 列存,OLTP 查询访问磁盘中的行存表,并在内存中额外存储一份列存表专门用于 OLAP 查询。HTAP 往往指的是同时支持 OLTP 业务和实时 OLAP 业务,这里需要避免走极端。
由于 HTAP 采用行列混合存储,对于纯粹的离线 OLAP 业务,性能可能不如更加专用的 OLAP 和大数据系统。HTAP 的价值在于更加简单通用,对于绝大部分中等规模的客户,数据量不会特别大,只需要一套系统即可。当然,对于超大型互联网企业,一套系统肯定是不够的,需要部署多套系统。我们既要不断探寻更加通用的 HTAP 方案,又要避免 one size fit all,最终的方案很可能是 one size fit a bunch。
HTAP 的另外一个技术挑战是资源隔离。
偷懒的做法是多副本做物理隔离,主副本做 OLTP 查询,备副本做 OLAP 查询。另外一种是经典数据库中采用的资源组方案,无论是 Oracle 还是 SQL Server,都支持定义不同的资源组,并限制每个资源组可以使用的物理资源。资源组的隔离可以通过类似 SQL Server 数据库内的 SQLVM 来实现,也可以通过操作系统底层的 cgroup 机制来实现。
数据库业务往往有三类用户:OLTP 用户做在线交易,Batch 用户做批处理,DSS 用户做报表,通过资源组限制每类用户可使用的 CPU、IO、网络资源,从而避免 OLTP 业务受影响。Oracle 最新版本的多租户隔离就是采用cgroup 机制,OceanBase 也采用了类似的机制,实际效果都很不错。
相比 MySQL 等开源数据库,经典商业数据库的最大价值在于能够处理复杂查询和混合负载,企业级分布式数据库应该向经典数据库学习 SQL 优化和 SQL 执行技术。

经典数据库采用基于代价的优化,且支持基于代价的改写,很多分布式数据库的优化器依赖开源的 Calcite 框架,由于通用框架的限制,很难做到基于代价的改写,复杂查询的支持能力有限。Oracle 优化器分成两个阶段:第一个阶段串行优化,第二个阶段并行优化,对分布式和并行场景的考虑相对较少,企业级分布式数据库可以在 Oracle 优化器的基础上做创新,增强分布式和并行能力,支持一阶段优化,在代价模型中同时考虑单机和分布式代价。
经典数据库的 SQL 执行能力也非常出色,无论是 TPC-H、TPC-DS 等 benchmark,还是真实的业务场景,单核执行性能都非常好。企业级分布式数据库应该学习经典数据库的 SQL 执行技术,包括编译执行、向量执行、 push 模型,SIMD 处理、基于结构化数据的强类型系统等等。
PolarDB
PolarDB本身的AP能力很一般。PolarDB-X的最新版本,搞的有点像GreenPlum那样的MPP架构,但是从已经知道的细节来看,我也无法分辨这OLTP/OLAP是一套引擎还是两套引擎,对于PolarDB的HTAP实现不是很清楚。
Paxos or Raft
Paxos
所谓的 Paxos 算法,是为了解决来自客户端的值被发送到集群中的任意一点,而后集群中的所有节点为该值达成共识的一种协调算法。同时这个值伴随一个版本号,可以保证消息是有顺序的,该顺序在集群中任何一点都是一致的。
基本的 Paxos 算法非常简单,它由三个角色组成。
- Proposer:Proposer 可以有多个,Proposer 提出议案(value)。所谓 value,可以是任何操作,比如“设置某个变量的值为 value”。不同的 Proposer 可以提出不同的 value。但对同一轮 Paxos 过程,最多只有一个 value 被批准。
- Acceptor:Acceptor 有 N 个,Proposer 提出的 value 必须获得 Quorum 的 Acceptor 批准后才能通过。Acceptor 之间完全对等独立。
- Learner:上面提到只要 Quorum 的 Accpetor 通过即可获得通过,那么 Learner 角色的目的就是把通过的确定性取值同步给其他未确定的 Acceptor。
这三个角色其实已经描述了一个值被提交的整个过程。其实基本的 Paxos 只是理论模型,因为在真实场景下,我们需要处理许多连续的值,并且这些值都是并发的。如果完全执行上面描述的过程,那性能消耗是任何生产系统都无法承受的,因此我们一般使用的是 Multi-Paxos。
Multi-Paxos 可以并发执行多个 Paxos 协议,它优化的重点是把 Propose 阶段进行了合并,这就引入了一个 Leader 的角色,也就是领导节点。而后读写全部由 Leader 处理,同时这里与 ZAB 类似,Leader 也有任期的概念,Leader 与其他节点之间也用心跳进行互相探活。是不是感觉有那个味道了?后面我就会比较两者的异同。
另外 Multi-Paxos 引入了两个重要的概念:replicated log 和 state snapshot。
- replicated log:值被提交后写入到日志中。这种日志结构除了提供持久化存储外,更重要的是保证了消息保存的顺序性。而 Paxos 算法的目标是保证每个节点该日志内容的强一致性。
- state snapshot:由于日志结构保存了所有值,随着时间推移,日志会越来越大。故算法实现了一种状态快照,可以保存最新的日志消息。当快照生成后,我们就可以安全删除快照之前的日志了。
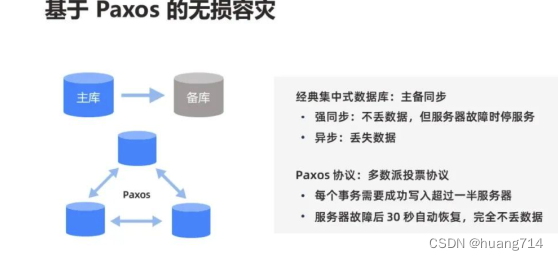
2014 年,OceanBase 将 Paxos 协议引入到数据库,首次在金融核心系统做到 RPO=0,也正是依靠这项技术,成为支付宝的最终选择。基于 Paxos 协议,OceanBase 继续研发了同城三机房、两地三中心、三地五中心等多种灵活的容灾部署方案。
经典集中式数据库往往采用主备同步方案,有两种同步模式:第一种是强同步,每个事务操作都需要强同步到备机才可以应答用户,这种方式能够做到服务器故障不丢数据,但必须停服务,无法保证可用性;另外一种是异步,每个事务操作只需要在主机成功就可以应答用户,这种方式能够做到高可用,但主库和备库之间数据不一致,备库切换为主库之后会丢数据。
强一致和高可用作为数据库最重要的两个特性,在主备同步模式下,鱼和熊掌不可兼得。Paxos 是一种基于多数派的分布式投票协议,每个事务需要成功写入超过一半服务器才可以应答用户。俗话说得好,“三个臭皮匠顶过一个诸葛亮”,假设总共有 3 台服务器,每个事务操作要求至少在 2 台服务器上成功,无论任何一台服务器发生故障,系统中还有 1 台包含了全部数据的服务器能够正常工作,从而做到完全不丢数据,并在 30 秒之内选出新的主库恢复服务,RPO 等于 0,RTO 小于 30 秒。所有保证 RPO=0 的协议都是 Paxos 协议或者 Paxos 协议的变种,Raft 协议就是其中之一。
Raft
Raft 可以看成是 Multi-Paxos 的改进算法,因为其作者曾在斯坦福大学做过关于 Raft 与 Multi-Paxos 的比较演讲,因此我们可以将它们看作一类算法。
Raft 算法可以说是目前非常不错的的分布式共识算法,包括 TiDB、FaunaDB、Redis 等都使用了这种技术。原因是 Multi-Paxos 没有具体的实现细节,虽然它给了开发者想象空间,但共识算法一般居于核心位置,一旦存在潜在问题必然带给系统灾难性的后果。而 Raft 算法给出了大量的实现细节,且处理方式相比于 Multi-Paxos 有两点优势。
- 发送的请求的是连续的,也就是说 Raft 的写日志操作必须是连续的;而 Multi-Paxos 可以并发修改日志,这也体现了“Multi”的特点。
- 选主必须是最新、最全的日志节点才可以当选,这一点与 ZAB 算法有相同的原则;而 Multi-Paxo 是随机的。因此 Raft 可以看成是简化版本的 Multi-Paxos,正是这个简化,造就了 Raft 的流行。
Multi-Paxos 随机性使得没有一个节点有完整的最新的数据,因此其恢复流程非常复杂,需要同步节点间的历史记录;而 Raft 可以很容易地找到最新节点,从而加快恢复速度。当然乱序提交和日志的不连续也有好处,那就是写入并发性能会大大提高,从而提高吞吐量。所以这两个特性并不是缺点,而是权衡利弊的结果。当然 TiKV 在使用 Raft 的时候采用了多 RaftGroup 的模式,提高了单 Raft 结构的并发度,这可以被看作是向 Multi-Paxos 的一种借鉴。
同时 Raft 和 Multi-Paxos 都使用了任期形式的 Leader。好处是性能很高,缺点是在切主的时候会拒绝服务,造成可用性下降。因此一般我们认为共识服务是 CP 类服务(CAP 理论)。但是有些团队为了提高可用性 ,转而采用基础的 Paxos 算法,比如微信的 PaxosStore 都是用了每轮一个单独的 Paxos 这种策略。
以上两点改进使 Raft 更好地落地,可以说目前最新数据库几乎都在使用该算法。想了解算法更多细节,请参考https://raft.github.io/。你从中不仅能学习到算法细节,更重要的是可以看到很多已经完成的实现,结合代码学习能为你带来更深刻的印象。
如何选择
Raft 协议是 Paxos 协议的一种简化,原理是在 Paxos 协议基础上增加了一个限制,要求按顺序投票,也就意味着数据库 redo 日志顺序同步。Raft 协议的好处是实现简单,但每个分区只能顺序同步,并发同步性能较差,在弱网环境下事务卡顿现象概率较高;Paxos 协议支持乱序同步,虽然实现更加复杂,但并发同步性能好,在弱网环境下事务卡顿现象概率较低。Raft 类系统发明了一个概念叫:Multi-Raft,指的是每个分片运行一个 Raft 协议。这个概念和经典的 Multi-Paxos 是不对等的,Multi-Paxos 指的是一个分片内做并发,Multi-Raft 指的是多个分片之间做并发,如果单个分片写入量很大,仍然是会产生性能瓶颈的。
Paxos 和 Raft 两种协议都是合理的做法,据悉目前国内有两个数据库产品使用了Raft,一个是阿里云的PolarDB。它用了自己改进的Paralle Raft协议。另外一个是TiDB。Paxos也是顶尖互联网公司在大规模分布式存储系统的主流做法,包括 Google Spanner,Microsoft Azure,Amazon DynamoDB,OceanBase 等等。
这当然有历史原因,Raft出来的比较晚。但是也有现实的原因,单从性能方面来说Paxos是领先Raft的,Paxos协议的实现有很多很难的地方,一不小心就栽坑。我自己亲自经历的就看到过几个大Bug,导致数据丢失,都是Paxos协议实现细节上不对导致的。要实现一个好的Raft,估计难度上会相对容易一些。这当然也会成为某些项目的选择。
存储引擎
存储引擎的特点千差万别,各具特色。但总体上我们可以通过三个变量来描述它们的行为:缓存的使用方式,数据是可变的还是不可变的,存储的数据是有顺序的还是没有顺序的。
缓存形式
缓存是说存储引擎在数据写入的时候,首先将它们写入到内存的一个片段,目的是进行数据汇聚,而后再写入磁盘中。这个小片段由一系列块组成,块是写入磁盘的最小单位。理想状态是写入磁盘的块是满块,这样的效率最高。
大部分存储引擎都会使用到缓存。但使用它的方式却很不相同,比如我将要介绍的 WiredTiger 缓存 B 树节点,用内存来抵消随机读写的性能问题。而我们介绍的 LSM 树是用缓存构建一个有顺序的不可变结构。故使用缓存的模式是衡量存储引擎的一个重要指标。
可变/不可变数据
存储的数据是可变的还是不可变的,这是判断存储引擎特点的另一个维度。不可变性一般都是以追加日志的形式存在的,其特点是写入高效;而可变数据,以经典 B 树为代表,强调的是读取性能。故一般认为可变性是区分 B 树与 LSM 树的重要指标。但 BW-Tree 这种 B 树的变种结构虽然结构上吸收了 B 树的特点,但数据文件是不可变的。
当然不可变数据并不是说数据一直是不变的,而是强调了是否在最影响性能的写入场景中是否可变。LSM 树的合并操作,就是在不阻塞读写的情况下,进行数据文件的合并与分割操作,在此过程中一些数据会被删除。
排序
最后一个变量就是数据存储的时候是否进行排序。排序的好处是对范围扫描非常友好,可以实现 between 类的数据操作。同时范围扫描也是实现二级索引、数据分类等特性的有效武器。如本模块介绍的 LSM 树和 B+ 树都是支持数据排序的。
而不排序一般是一种对于写入的优化。可以想到,如果数据是按照写入的顺序直接存储在磁盘上,不需要进行重排序,那么其写入性能会很好,下面我们要介绍的 WiscKey 和 Bitcask 的写入都是直接追加到文件末尾,而不进行排序的。
以上就是评估存储引擎特点的三个变量,我这里将它们称为黄金三角。因为它们是互相独立的,彼此并不重叠,故可以方便地评估存储引擎的特点。下面我们就试着使用这组黄金三角来评估目前流行的存储引擎的特点。
B 树类
上文我们提到过评估存储引擎的一个重要指标就是数据是否可以被修改,而 B 树就是可以修改类存储引擎比较典型的一个代表。它是目前的分布式数据库,乃至于一般数据库最常采用的数据结构。它是为了解决搜索树(BST)等结构在 HDD 磁盘上性能差而产生的,结构特点是高度很低,宽度很宽。检索的时候从上到下查找次数较少,甚至如 B+ 树那样,可以完全把非叶子节点加载到内存中,从而使查找最多只进行一次磁盘操作。
下面让我介绍几种典型的 B 树结构的存储引擎。
InnoDB
InnoDB 是目前 MySQL 的默认存储引擎,同时也是 MariaDB 10.2 之后的默认存储引擎。
根据上文的评估指标看,它的 B+ 树节点是可变的,且叶子节点保存的数据是经过排序的。同时由于数据的持续写入,在高度不变的情况下,这个 B+ 树一定会横向发展,从而使原有的一个节点分裂为多个节点。而 InnoDB 使用缓存的模式就是:为这种分裂预留一部分内存页面,用来容纳可能的节点分裂。
这种预留的空间其实就是一种浪费,是空间放大的一种表现。用 RUM 假设来解释,InnoDB 这种结构是牺牲了空间来获取对于读写的优化。
在事务层面,InnoDB 实现了完整的隔离级别,通过 MVCC 机制配合各种悲观锁机制来实现不同级别的隔离性。
WiredTiger
WiredTiger 是 MongoDB 默认的存储引擎。它解决了原有 MongoDB 必须将大部分数据放在内存中,当内存出现压力后,数据库性能急剧下降的问题。
它采用的是 B 树结构,而不是 InnoDB 的 B+ 树结构。这个原因主要是 MongoDB 是文档型数据库,采用内聚的形式存储数据(你可以理解为在关系型数据库上增加了扩展列)。故这种数据库很少进行 join 操作,不需要范围扫描且一次访问就可以获得全部数据。而 B 树每个层级上都有数据,虽然查询性能不稳定,但总体平均性能是要好于 B+ 树的。
故 WiredTiger 首先是可变数据结构,同时由于不进行顺序扫描操作,数据也不是排序的。那么它是如何运用缓存的呢?这个部分与 InnoDB 就有区别了。
在缓存中每个树节点上,都配合一个更新缓冲,是用跳表实现的。当进行插入和更新操作时,这些数据写入缓冲内,而不直接修改节点。这样做的好处是,跳表这种结构不需要预留额外的空间,且并发性能较好。在刷盘时,跳表内的数据和节点页面一起被合并到磁盘上。
由此可见,WiredTiger 牺牲了一定的查询性能来换取空间利用率和写入性能。因为查询的时候出来读取页面数据外,还要合并跳表内的数据后才能获取最新的数据。
BW-Tree
BW-Tree 是微软的 Azure Cosmos DB 背后的主要技术栈。它其实通过软件与硬件结合来实现高性能的类 B 树结构,硬件部分的优化使用 Llama 存储系统,有兴趣的话你可以自行搜索学习。我们重点关注数据结构方面的优化。
BW-Tree 为每个节点配置了一个页面 ID,而后该节点的所有操作被转换为如 LSM 树那样的顺序写过程,也就是写入和删除操作都是通过日志操作来完成的。采用这种结构很好地解决了 B 树的写放大和空间放大问题。同时由于存在多个小的日志,并发性也得到了改善。
刷盘时,从日志刷入磁盘,将随机写变为了顺序写,同样提高了刷盘效率。我们会发现,BW-Tree 也如 LSM 树一样存在读放大问题,即查询时需要将基础数据与日志数据进行合并。而且如果日志太长,会导致读取缓慢。而此时 Cosmos 采用了一种硬件的解决方案,它会感知同一个日志文件中需要进行合并的部分,将它们安排在同一个处理节点,从而加快日志的收敛过程。
以上就是典型的三种 B 树类的存储引擎,它们各具特色,对于同一个问题的优化方式也带给我们很多启发。
LSM 类
LSM是典型的不可变数据结构,使用缓存也是通过将随机写转为顺序写来实现的。
我们在说 LSM 树时介绍了它存储的数据是有顺序的,其实目前有两种无顺序的结构也越来越受到重视。
经典存储
经典的 LSM 实现有 LeveledDB,和在其基础之上发展出来的 RocksDB。它们的特点我们之前有介绍过,也就是使用缓存来将随机写转换为顺序写,而后生成排序且不可变的数据。它对写入和空间友好,但是牺牲了读取性能。
Bitcask
Bitcask 是分布式键值数据库 Riak 的一种存储引擎,它也是一种典型的无顺序存储结构。与前面介绍的典型 LSM 树有本质上的不同,它没有内存表结构,也就是它根本不进行缓存而是直接将数据写到数据文件之中。
可以看到,其写入是非常高效的,内存占用也很小。但是如何查询这种“堆”结构的数据呢?答案是在内存中有一个叫作 Keydir 的结构保存了指向数据最新版本的引用,旧数据依然在数据文件中,但是没有被 Keydir 引用,最终就会被垃圾收集器删除掉。Keydir 实际上是一个哈希表,在数据库启动时,从数据文件中构建出来。
这种查询很明显改善了 LSM 树的读放大问题,因为每条数据只有一个磁盘文件引用,且没有缓存数据,故只需要查询一个位置就可以将数据查询出来。但其缺陷同样明显:不支持范围查找,且启动时,如果数据量很大,启动时间会比较长。
此种结构优化了写入、空间以及对单条数据的查找,但牺牲了范围查找的功能。
RocksDB
RocksDB 是由 Facebook 基于 LevelDB 开发的一款提供键值存储与读写功能的 LSM-tree 架构引擎。用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),然后再写入内存中的跳表(SkipList,这部分结构又被称作 MemTable)。LSM-tree 引擎由于将用户的随机修改(插入)转化为了对 WAL 文件的顺序写,因此具有比 B 树类存储引擎更高的写吞吐。
内存中的数据达到一定阈值后,会刷到磁盘上生成 SST 文件 (Sorted String Table),SST 又分为多层(默认至多 6 层),每一层的数据达到一定阈值后会挑选一部分 SST 合并到下一层,每一层的数据是上一层的 10 倍(因此 90% 的数据存储在最后一层)。
RocksDB 允许用户创建多个 ColumnFamily ,这些 ColumnFamily 各自拥有独立的内存跳表以及 SST 文件,但是共享同一个 WAL 文件,这样的好处是可以根据应用特点为不同的 ColumnFamily 选择不同的配置,但是又没有增加对 WAL 的写次数。
MPP
MPP (Massively Parallel Processing) 大规模并行处理,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
MPP架构具有如下特征:
- 任务并行执行
- 数据分布式存储(本地化)
- 分布式计算
- 私有资源
- 横向扩展
- Shared Nothing架构
MPP并行处理的关键点在于将数据均匀的分布到每一块磁盘上,从而发挥每一块磁盘性能,从根本上解决IO瓶颈问题。数据的均匀分布可以充分的利用物理硬件资源,因此它也是性能调优的基础。数据的均匀分布很大程度上依赖于分布键和具体分布方式的选择,常用的分布方式有哈希和循环等。

MPP采用shared-Nothing的架构模型,理论上可以做到线性扩展来提升数据仓库的性能。但生产实践中,通常受限于网络收敛比、成本等因素,往往最多只能扩展几百节点。
MPP在具体架构实现上,通常有无Master和Master-Slave两种方式,无共享Master的结构方式中,所有节点是对等的,客户端可以通过任意的节点来加载数据,不存在性能瓶颈和单点故障风险。
基于MPP架构的数据库(MPPDB)是一种 Shared-Nothing架构的分布式并行结构化数据库集群,具备高性能、高可用、高扩展特性,可以为超大规模数据管理提供高性价比的通用计算平台,并广泛地用于支撑各类数据仓库系统、BI 系统和决策支持系统。
对于一张表中的多条记录来说,客户端的数据通过解析器进行解析后,将数据分发给各个处理单元进行处理,每个处理单元将接收到的记录存储到自己的逻辑盘中。GaussDB中解析器对应协调节点CN,处理单元对应数据节点DN。
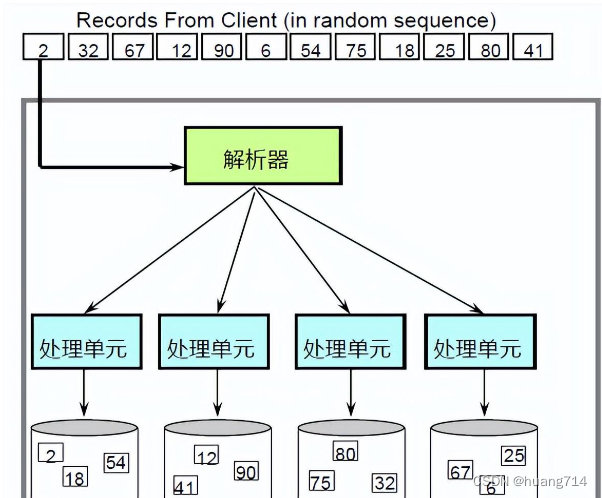
当客户端发出查询请求时,解析器同样将查询命令分发给各个处理单元,各个处理单元并行的定位到查询的记录并返回给解析器,解析器将各个处理单元的查询结果合并后返回给客户端。
对于多张表来说,每个表的记录都会分布在各个处理单元上,每个处理单元都会有各个表的记录。理想情况下,记录会均匀的分布到各个处理单元上。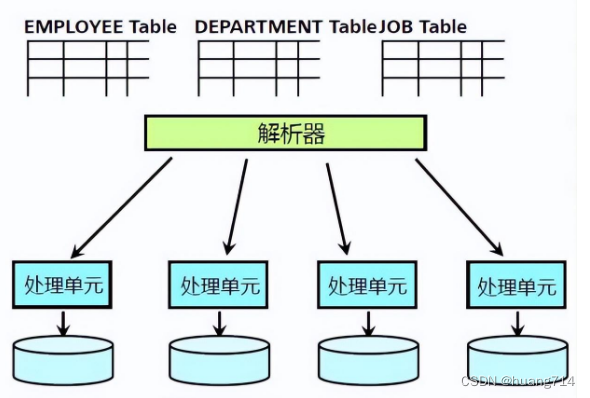
如果采用的是根据分布键的哈希值来确定记录的分布节点,那么分布键一般在建表时指定,如果没有指定,系统会根据一定的规则选择默认字段作为分布键。
MPP架构下数据库执行排序操作时,每个处理单元会先进行内部的数据排序,然后再将各处理单元数据进行多路归并排序。
MPP架构下数据库执行关联操作时,如果关联字段是分布键,那么关联的字段必然分布在相同的节点上,则在每个节点分别进行关联,然后将结果集合并;如果关联字段不是分布键,则需要数据在节点间进行流动再进行关联、合并。
MPP架构下数据库进行聚合操作,每个处理单元会进行节点内部的数据聚合,之后再将各处理单元数据进行汇总。如果聚合字段不是分布键,也会有数据流动。
MPP数据库有对SQL的完整兼容和一些事务的处理能力,对于用户来说,在实际的使用场景中,如果数据扩展需求不是特别大,需要的处理节点不多,数据都是结构化的数据,习惯使用传统的RDBMS的很多特性的场景,可以考虑MPP,例如Greenplum/Gbase等。
如何选择分布式数据库
如何选择一款分布式数据库,可以考虑如下几点:
1. 要兼容MySQL,因为本人就是MySQL重度研究与使用者,高度认可MySQL这个数据库的架构及使用方式等(中毒已深)。兼容MySQL这个要求,其实是非常高的,我们每个人都知道。只是MySQL的语法比较乱(说到代码实现,可能更多的是骂了),很松散,如果说做到了90%的兼容度,那是不够的,最好要做到100%,这能做到吗?我想是可以的。目前像国内的OceanBase、TiDB、PolarDB都能够兼容MySQL。
2. 存储率高,使用分布式数据库的业务,大部分应该是存储分析型,如果使用了分布式数据库,还需要占用太多的硬件资源,且存储不了太多数据的话,那这个在成本上就非常高了,得不偿失。比如OceanBase,基于LSM存储引擎,底层有一定的压缩机制,比传统MySQL存储能够降低30%。
3. 有健全的圈子,使用中难免会碰到问题,碰到问题的时候,现在处于分布式发展的初级阶段,所以社区的人比较少,而只能去求助官方,如果官方不能提供帮助(也许是没给钱),那这样的数据库,可能就不具有诱惑力了,风险太大。目前国内的OceanBase、TiDB、PolarDB都已经开源,且有一定的售后支持。
4. 性能够用,在使用了分布式数据库之后,其实已经默认接受了降低性能要求的条件,所以我们的要求只是说,性能够用即可,不会去和单点MySQL去比,因为没有意义。够用就好,当然在这方面如果足够好,那是再好不过了。性能这块目前国内的OceanBase、TiDB、PolarDB都不错,尤其是OceanBase参与全球顶级的TPC-C 测试,位列全球第一,远超第二名Oracle(OceanBase天然具备分布式,很自然可以分多个片,手动分片无限堆机器自然分数比较高,纯单机的测试和Oracle比的话结果不好说)。
5. 少技术栈,这样的需求是非常高的,因为技术栈太长,会加重运维人员的成本,并且在现在这样人才难找更难招的情况下,这样的愿望是更迫切的。
分布式数据库发展趋势
企业级分布式数据库除了做好分布式,更要坚守数据库的初心,在功能兼容性、性价比上下功夫。今天,分布式数据库领域流行的一些技术,包括存储计算分离、HTAP,最早都出自经典数据库,且经典数据库经过五十多年的实践,通过应用驱动技术创新做得更加精细。
我认为企业级分布式数据库是未来的大趋势,最终能不能走到那一步,取决于我们能否站在经典数据库这一巨人的肩膀上,深挖经典数据库的核心技术和理念,在消化理解的基础上做创新。企业级分布式数据库在分布式架构上做了很多创新,包括分区级 Paxos 日志同步实现高可用和可扩展,支持容错的分布式事务和多版本并发控制,但对经典数据库的核心技术理解还需要加强,例如深入理解 Oracle 和 SQL Server 等企业级数据库的 HTAP 和存储计算分离技术。
结合《2022 分布式数据库发展趋势研究报告》,分布式数据库有如下九大发展趋势
- 分布式数据库走向原生设计
- 分布式数据库架构的设计走向一体化
- 分布式数据库的能力将向混合负载发展
- 分布式数据库的场景将向云化发展
- 分布式数据库的高可用能力不断在提升
- 分布式数据库对数据一致性的支持将日臻完善
- 分布式数据库的生态建设亟需推动
- 分布式数据库需要支持异构芯片的混合部署
- 分布式数据库应支持数据透明加密

