
- 1基于STM32出租车计费器设计
- 2同居的童话_第一次进去丫头的身体怎么办
- 3HMACMD5加密方法的简要过程
- 4Github复现-测试基于transformer的变化检测模型BIT_CD
- 5阿里为啥把MySQL晾一边,抢用ClickHouse+Doris,秒级实现有多爽?
- 6Vue项目部署到Tomcat踩坑记录_vue3 tomcat部署
- 7vue3项目学习记录<一>---配置tsconfig.json文件_tsconfig.app.json:3:27 3 "include": ["env.d.ts", "
- 8搜索系统【处理流程,意图识别,实体识别,属性对齐】_实体识别和意图识别
- 9python-pygame小游戏之球球大作战_pygame球球大作战
- 10全方位AI工具集成,免费使用_ai工具集里面工具免费吗?
中boxplot函数的参数设置_如何在Python中生成图形和图表
赞
踩

在本章中,我们将学习如何在Python中生成图形和图表,同时将使用函数和面向对象的方法来可视化数据。
Python中常用的一些可视化数据包括以下几种。
- Matplotlib。
- Seaborn。
- ggplot。
- Geoplotlib。
- Bokeh。
- Plotly。
在本章中将使用Matplotlib可视化数据包。此外,还将学习其他有用库的编码。
1 折线图
折线图(Line Chart)是将一系列数据点通过直线连接起来的图表,它提供了一个参数对另一个参数的简单行为,常用于显示随着时间推移的趋势。可以使用折线图来比较相关的特征。
在Jupyter Notebook中生成第一张图表。
首先导入所需要的库。
import matplotlib.pyplot as plt默认情况下, Matplotlib打开新的窗口以显示结果。如果想在当前Notebook页面看到结果,可以使用如下所示的命令。
%matplotlib inline其次需要设置两个轴的数据。在x
轴上获取1~15的数据, y
轴选取平均值为50且标准差为10的随机数据。
# 1~15的一维数 a = range(1,16) #使用均值和标准差生成另一数据上的随机整数mean = 50 sigma = 10 b = numpy.random.normal(mean, sigma, 15).astype(int)现在,只需运行下方的绘图命令,折线图就会出现,结果如图1所示。
plt.plot(a,b)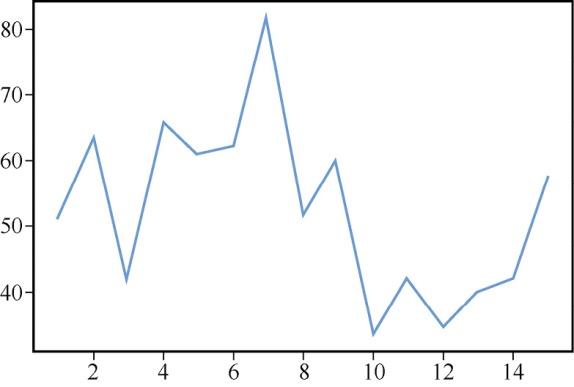
图1
也可以使用下面的代码改变线条的颜色,结果如图2所示。
#定义颜色plt.plot(a,b,color='Red')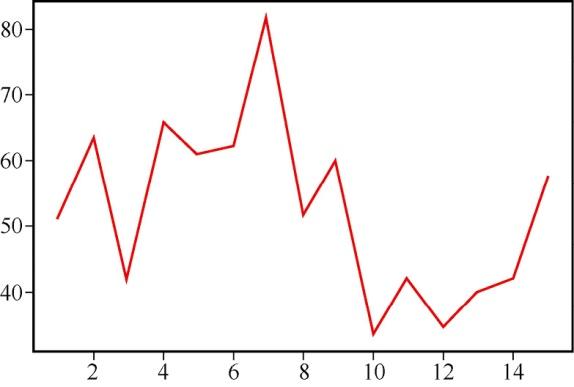
图2
通过ls和lw变量可以改变线的类型及其宽度,结果如图3所示。
#改变线的类型和宽度plt.plot(a,b,ls='--',lw=4)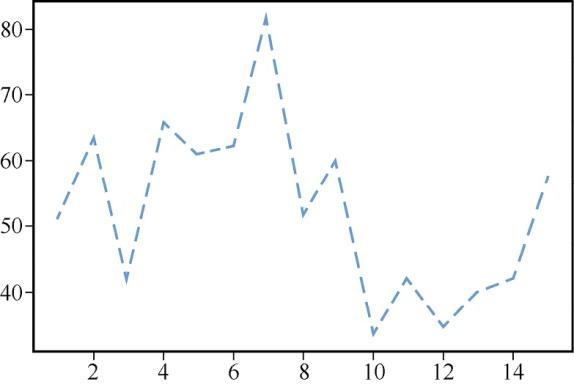
图3
通过下面的命令可以在每个数据点上添加标记,结果如图4所示。
#定义标记和标记宽度plt.plot(a,b,marker='3',mew=10)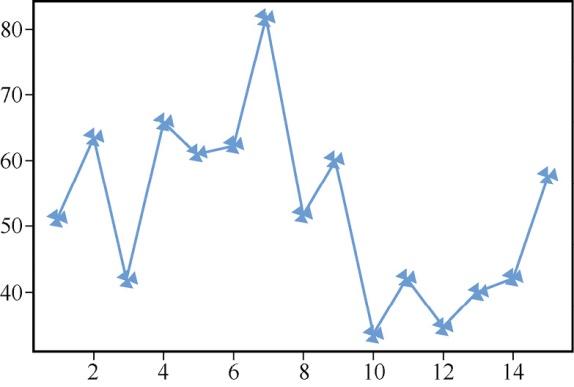
图4
也可以绘制Pandas DataFrame中的折线图。
sales_in_Delhi = [34,45,33,45,49] sales_in_Pune = [12,13,6,14,10] sales_in_Mumbai = [67,78,90,75,85] sales =pandas.DataFrame({'Delhi':sales_in_Delhi,'Pune':sales_in_Pune,'Mumbai':sales_in_Mumbai})为了绘制折线图,可以使用以下命令。 xticks和yticks用于设置数轴上的有效范围,结果如图5所示。
sales.plot(xticks=range(1,5),yticks=range(0,100,20))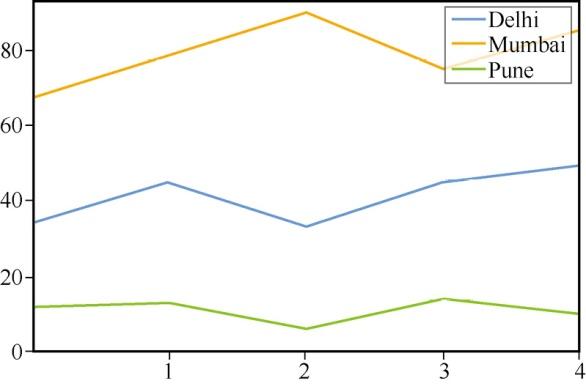
图5
为不同的线条定义颜色,结果如图6所示。
#定义颜色选项colors = ['Red','Green','Black'] sales.plot(xticks=range(1,5),yticks=range(0,100,20),color=colors)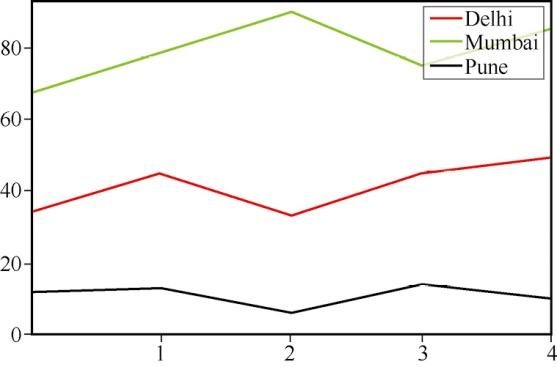
图6
2 条形图
条形图(Bar Chart)常用于分析分组数据,它一般与分类数据一起使用,用来可视化其他变量对每一类别的影响。条形图为每个类别创建一个矩形。例如,有3个类别的城市,我们希望了解这些城市中的车辆数量。通过使用条形图,可以生成3个矩形(每个矩形代表一个城市),同时高度表示车辆数量。条形图显示了在每个类别的观察次数。
使用下面的代码绘制条形图,结果如图7所示。
plt.bar(a,b)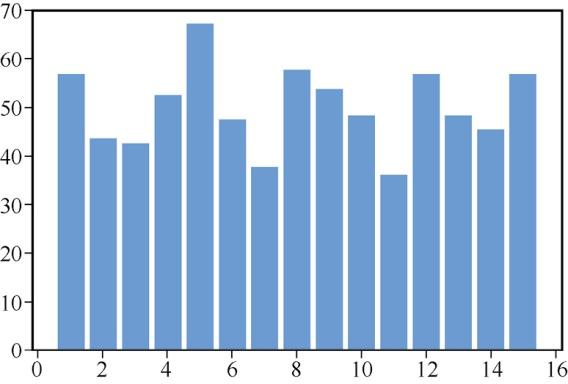
图7
也可以从Pandas中生成条形图。默认情况下, plot函数生成折线图。可以指示函数生成条形图,结果如图8所示。
sales.plot(kind='bar')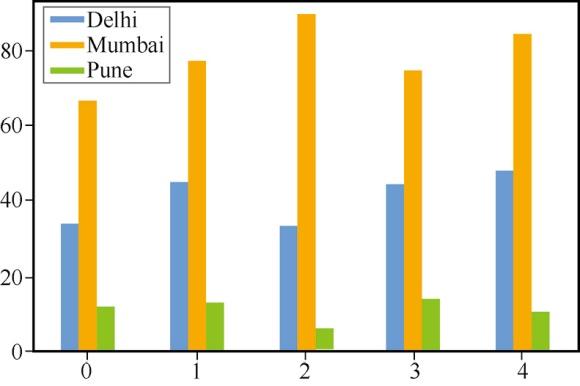
图8
3 饼图
饼图(Pie Chart)将整个数据表示为一个圆。根据不同类别的比例沿圆圈制作切片。例如,对3个城市的车辆进行分析,饼图中展示了一个城市相比于其他城市的车辆比例。如果想在一个统一的规模下比较每个类别,饼图是非常合适的。
通过使用以下命令生成饼图,结果如图9所示。
a = [3,4,5,7,12] plt.pie(a,labels=['AA','BB','CC','DD','EE'])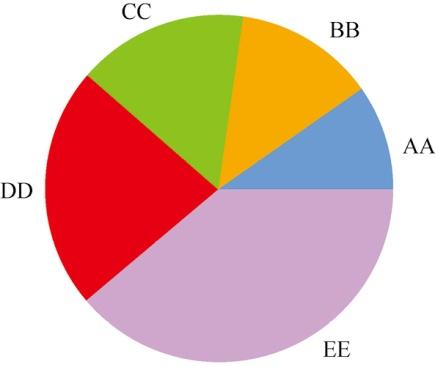
图9
定义每个切片的颜色,结果如图10所示。
#为每个类别定义颜色color_list = ['Red','Green','Blue','Yellow','Grey'] plt.pie(a,labels=['AA','BB','CC','DD','EE'],colors=color_list)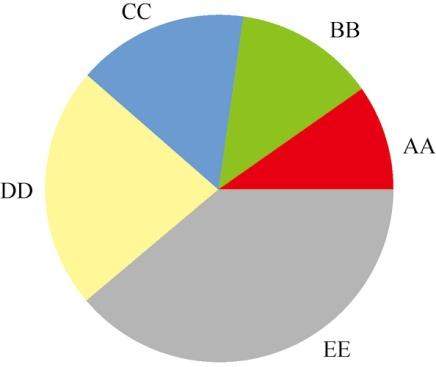
图10
4 直方图
直方图(Histograms)是统计学中广泛应用的图形之一,它能使我们确定连续数据的形状。通过直方图可以检测数据的分布、数据中的离群值和其他有用的属性。
要通过连续数据构造直方图,首先需要创建箱子(bin)并将数据放入适当的箱子中。这不同于与分类变量一起使用的条形图。
例如,有以下数据。
Data = [23, 12, 34, 56, 43, 26, 13, 39, 58, 32, 44 ]
可以按照表1这样定义箱子。
表1
箱子(bin)
数据点
数据点数
>20
12、13
2
20~40
23、34、26、39、32
5
40~60
56、43、58、44
4
使用matplotlib创建直方图。
#用均值和标准差生成随机整数mean = 20 sigma = 5 hist_data = numpy.random.normal(mean, sigma, 500).astype(int) plt.hist(hist_data)这将产生以下直方图,结果如图11所示。
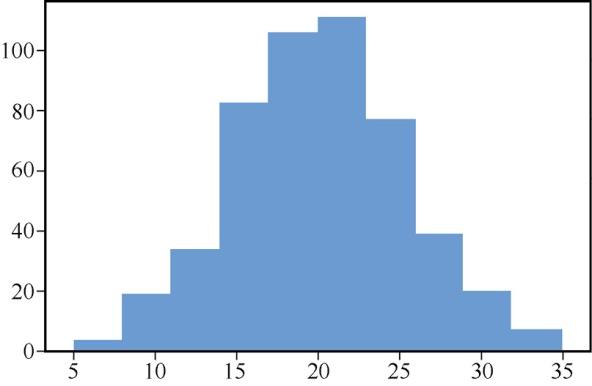
图11
5 散点图
散点图(Scatter Plot)能够表示两组数据点之间的关系。例如,任何人的体重和身高、交通强度和汽车数量、发表的论文数和多年的论文查看量等均可以通过散点图来呈现。
使用下面的代码生成散点图,结果如图12所示。
#用均值和标准差生成随机整数mean = 20 sigma = 5 #生成数据并对其排序scatter_data_1 = numpy.sort(numpy.random.normal(mean, sigma,50).astype(int)) scatter_data_2 = numpy.sort(numpy.random.normal(mean, sigma,50).astype(int)) #散点图plt.scatter(scatter_data_1,scatter_data_2)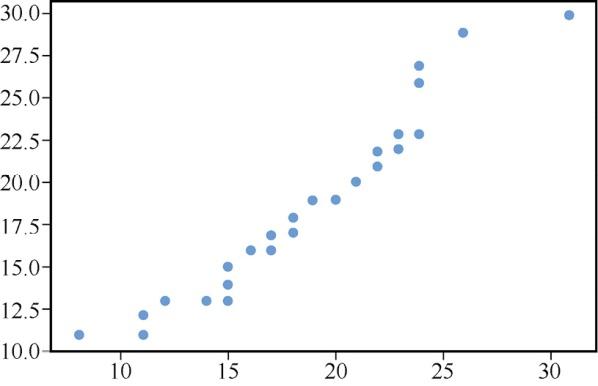
图12
6 箱线图
箱线图(Box Plot)可以用来理解变量的扩展传播。在箱线图中,矩形顶部边界代表上四分位数(third quantile),底部边界代表下四分位数(first quantile),而盒子中的直线表示中位数(median)。
顶部的垂直线表示最大值,底部的垂直线表示最小值。
通过下面的代码生成方框图,结果如图13所示。
box_data = numpy.random.normal(56, 10, 50).astype(int) plt.boxplot(scatter_data_1)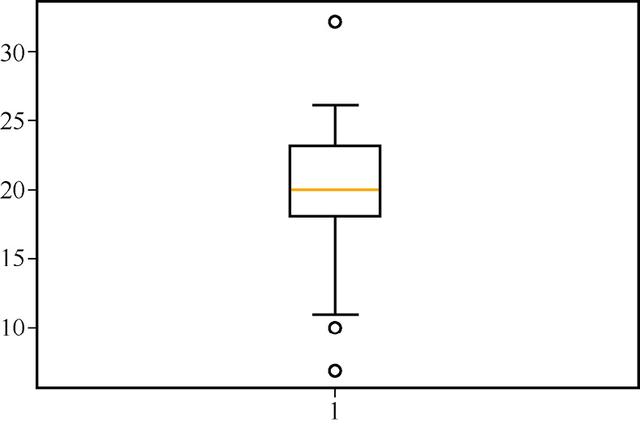
图13
7 采用面向对象的方式绘图
除了使用函数生成图形之外,还可以使用面向对象的方法来生成这种图形。我们定义一个图形对象并不断地添加图元素来丰富它。
首先,创建一个空白图形对象并向其添加轴。然后,在对象内生成绘图并为其指定参数,结果如图14所示。
下面是该方法的代码。
#一个数轴上获取1~15的数字a = range (1,16) #用均值和标准差生成另一数轴上的随机整数mean = 50 sigma = 10 b = numpy.random.normal(mean, sigma, 15).astype(int) #首先,定义图形对象figure_object = plt.figure() #添加轴axes = figure_object.add_axes([.1,.1,1,1]) #添加网格axes.grid() #设置轴标签axes.set_xlabel('X') axes.set_ylabel('Y') #设置坐标轴显示axes.set_xticks(range(1,15)) axes.set_yticks(range(20,100,10)) #设定轴极限axes.set_xlim([1,15]) axes.set_ylim([20,80]) #生成图axes.plot(a,b)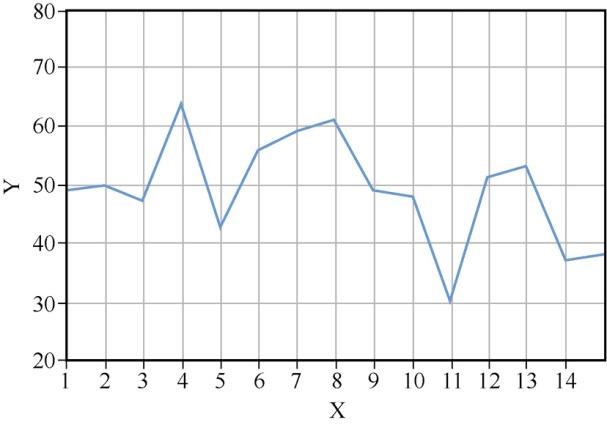
图14
在上面的代码中进行了如下的操作。
(1)使用plt.figure()创建了图形对象。
(2)使用add_axes定义数轴。
(3)使用grid()启用网格。
(4)定义了数轴标签。
(5)定义数轴上的值axes (xticks, yticks)。
(6)添加了数轴的下限和上限。
(7)使用plot生成绘图。
也可以创建子图,通过子图对其进行比较。
mean = 20 sigma = 5 c = numpy.random.normal(mean, sigma, 15).astype(int) #创建图形对象fig_sub_object = plt.figure() #图形对象中的两个轴number_of_rows= 1 number_of_cols = 2 fig_sub_object, (axes1,axes2) = plt.subplots(number_of_rows,number_of_cols) axes1.plot(a,b) axes2.plot(a,c)生成图15所示的图形。
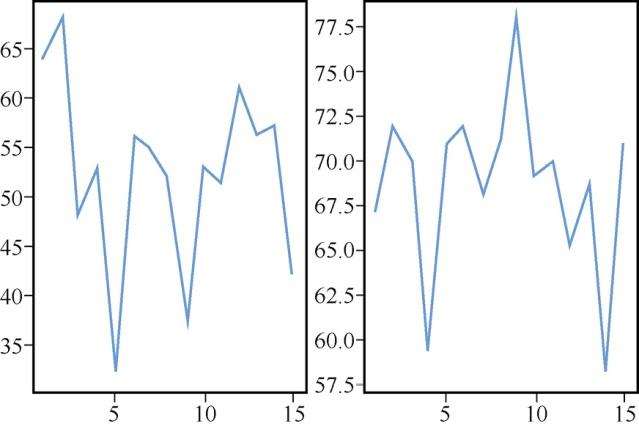
图15
8 Seaborn
Seaborn是基于Matplotlib的Python程序包,它提供了一些高层次的统计图形方法。下面会介绍到一些Seaborn中常用的绘图。
首先导入Seaborn。
import seaborn然后创建一些随机数据。
#用均值和标准差生成随机整数mean = 25 sigma = 10 dist_data_1 = numpy.random.normal ( mean, sigma, 500).astype(int) dist_data_2 = numpy.random.normal(mean+5, sigma-4, 500).astype(int) dist_data_3 = numpy.random.normal(mean-5, sigma+2, 500).astype(int) dist_data = pandas.DataFrame({"A":dist_data_1,"B":dist_data_2,"C":dist_data_3}) #首先,创建分类数据data = ["Delhi

