
大数据实时处理 2.1 初识Spark_soark 是实时吗
赞
踩
目录
- 了解什么是Spark计算框架
- 了解Spark计算框架的特点
- 了解Spark计算框架的应用场景
- 理解Spark框架与Hadoop框架的对比
一、Spark的概述
(一)Spark的组件
- Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。
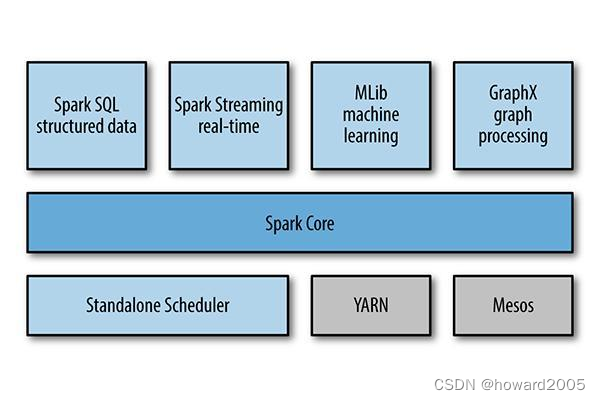
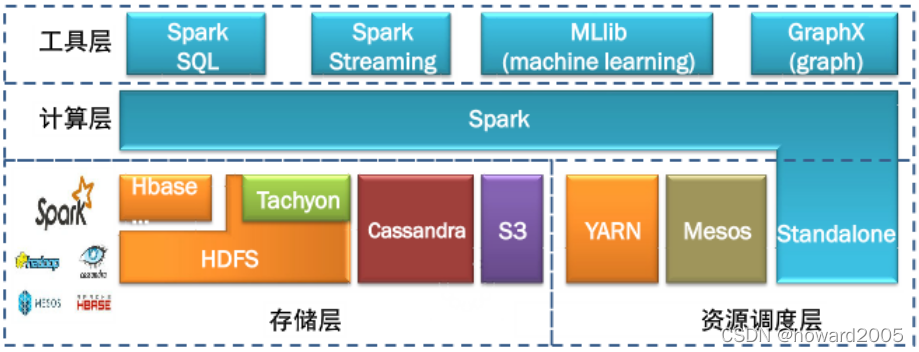
1、Spark Core
- Spark核心组件,实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含对弹性分布式数据集的API定义。
2、Spark SQL
- 用来操作结构化数据的核心组件,通过Spark SQL可直接查询Hive、HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD。
3、Spark Streaming
- Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业。

4、MLlib
- Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能。

5、Graph X
- Spark提供的分布式图处理框架,拥有对图计算和图挖掘算法的API接口及丰富的功能和运算符,便于对分布式图处理的需求,能在海量数据上运行复杂的图算法。
6、独立调度器、Yarn、Mesos
- 集群管理器,负责Spark框架高效地在一个到数千个节点之间进行伸缩计算的资源管理。
(二)Spark的发展史
1、发展简史
- 对于一个具有相当技术门槛与复杂度的平台,Spark从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。2009年,Spark诞生于伯克利大学AMPLab,最开初属于伯克利大学的研究性项目。它于2010年正式开源,并于2013年成为了Aparch基金项目,并于2014年成为Aparch基金的顶级项目,整个过程不到五年时间。
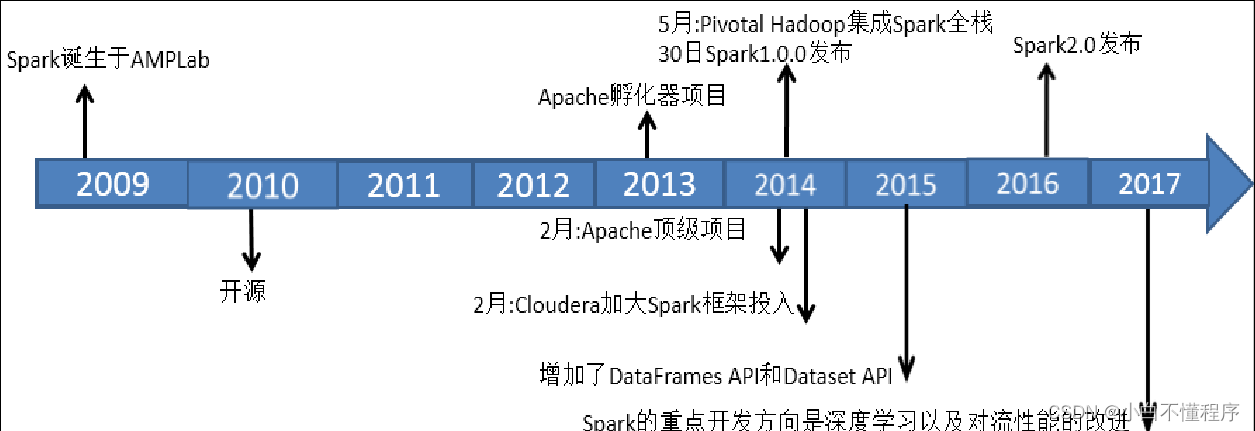
2、目前最新版本
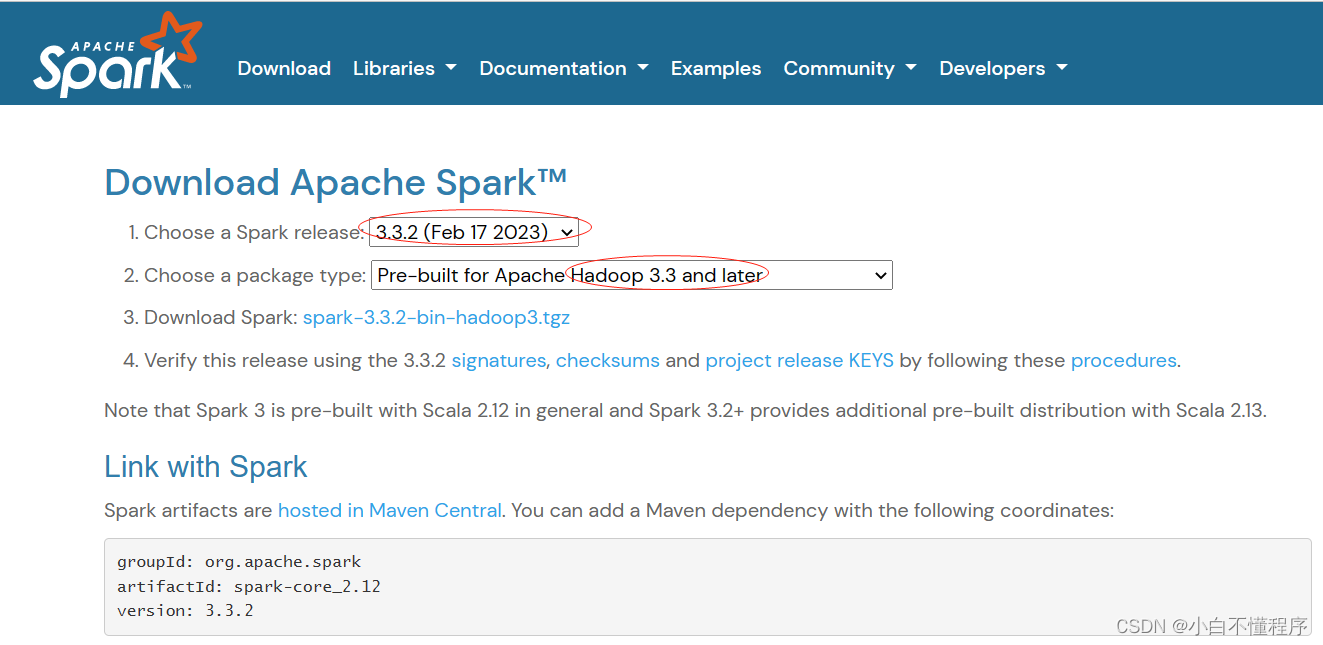
- Spark目前最新版本是2023年2月17日发布的Spark3.3.2
二、Spark的特点
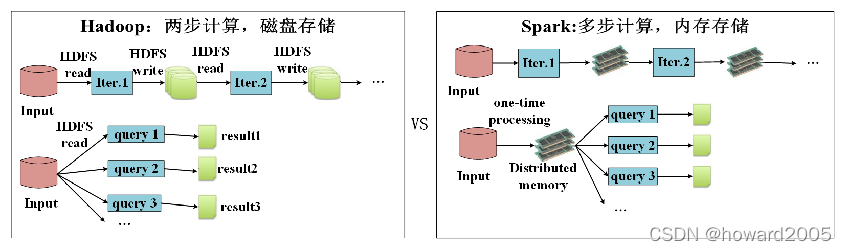
- Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
- Spark官网上给出Spark的特点

(一)速度快
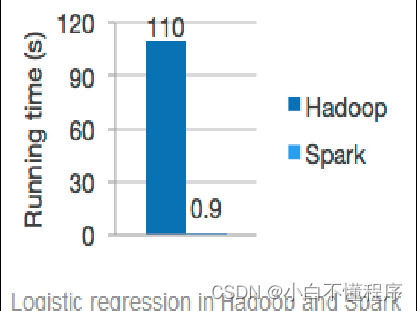
- 与MapReduce相比,Spark可以支持包括Map和Reduce在内的更多操作,这些操作相互连接形成一个有向无环图(Directed Acyclic Graph,简称DAG),各个操作的中间数据则会被保存在内存中。因此处理速度比MapReduce更加快。Spark通过使用先进的DAG调度器、查询优化器和物理执行引擎,从而能够高性能的实现批处理和流数据处理
(二)易用性
- Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高级运算符,使得编写并行应用程序变得容易并且可以在Scala、Python或R的交互模式下使用Spark。

(三)通用性
- Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming,并且支持在一个应用中同时使用这些组件。
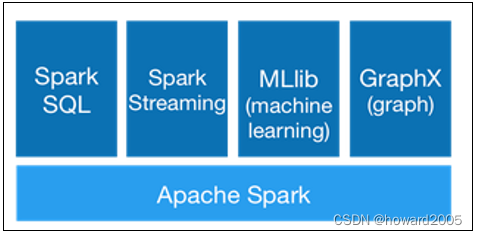
(四)兼容性
- 用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。

(五)代码简洁
1、采用MR实现词频统计
- 编写词频统计映射器 -
WordCountMapper
package net.hw.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取行内容
String line = value.toString();
// 按空格拆分得到单词数组
String[] words = line.split(" ");
// 遍历单词数组,生成输出键值对
for (int i = 0; i < words.length; i++) {
context.write(new Text(words[i]), new IntWritable(1));
}
}
}
- 编写词频统计归约器 -
WordCountReducer
package net.hw.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
// 定义键出现次数
int count = 0;
// 遍历输入值迭代器
for (IntWritable value : values) {
count += value.get(); // 其实针对此案例,可用count++来处理
}
// 输出新的键值对,注意要将java的int类型转换成hadoop的IntWritable类型
context.write(key, new IntWritable(count));
}
}
- 编写词频统计驱动器 -
WordCountDriver
package net.hw.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(WordCountDriver.class);// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(Text.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(IntWritable.class);// 设置Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置reduce任务输出键类型
job.setOutputKeyClass(Text.class);
// 设置reduce任务输出值类型
job.setOutputValueClass(IntWritable.class);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建输入目录
Path inputPath = new Path(uri + "/word/input");
// 创建输出目录
Path outputPath = new Path(uri + "/word/result");// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputPath, true);// 给作业添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputPath);
// 给作业设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成
job.waitForCompletion(true);// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
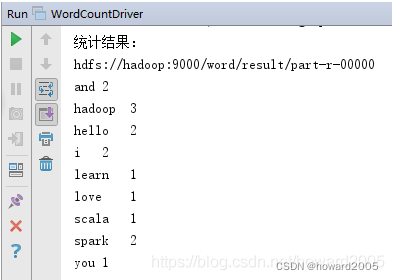
- 运行程序WordCountDriver,查看结果
2、采用Spark实现词频统计
- 编写词频统计对象 - Example01

package net.lym.day03
import scala.io.Source
/**
* 功能:词频统计
* 作者:柠檬
* 日期:2023年03月23日
*/
object Example01 {
def main(args: Array[String]): Unit = {
val iterator = Source.fromFile("test.txt") // 获取迭代器
val text = iterator.getLines().toList.mkString(" ") // 降维处理
val words = text.split(" ") // 拆分处理,化整为零
val mp = words.map((_, 1)) // 映射,单词计数
val wc = mp.groupMapReduce(_._1)(_ => 1)(_ + _) // 分组映射归纳
wc.foreach(println) // 遍历输出
}
}
- 启动程序,查看结果

3、两种代码对比结论
- 大家可以看出,完成同样的词频统计任务,Spark代码比MapReduce代码简洁很多。
三、Spark的应用场景
(一)应用场景分类
1、数据科学
- 数据工程师可以利用Spark进行数据分析与建模,由于Spark具有良好的易用性,数据工程师只需要具备一定的SQL语言基础、统计学、机器学习等方面的经验,以及使用Python、Matlab或者R语言的基础编程能力,就可以使用Spark进行上述工作。
2、数据处理
- 大数据工程师将Spark技术应用于广告、报表、推荐系统等业务中,在广告业务中,利用Spark系统进行应用分析、效果分析、定向优化等业务,在推荐系统业务中,利用Spark内置机器学习算法训练模型数据,进行个性化推荐及热点点击分析等业务。
(二)使用Spark的公司
1、腾讯
- 广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR (Predict Click-Through Rate) 投放系统上,支持每天上百亿的请求量。
2、Yahoo
- Yahoo将Spark用在Audience Expansion中。Audience Expansion是广告中寻找目标用户的一种方法,首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是Logistic Regression。同时由于某些SQL负载需要更高的服务质量,又加入了专门跑Shark的大内存集群,用于取代商业BI/OLAP工具,承担报表/仪表盘和交互式/即席查询,同时与桌面BI工具对接。
3、淘宝
- 淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等,将Spark运用于淘宝的推荐相关算法上,同时还利用GraphX解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
4、优酷土豆
- 目前Spark已经广泛使用在优酷土豆的视频推荐,广告业务等方面,相比Hadoop,Spark交互查询响应快,性能比Hadoop提高若干倍。一方面,使用Spark模拟广告投放的计算效率高、延迟小(同Hadoop比延迟至少降低一个数量级)。另一方面,优酷土豆的视频推荐往往涉及机器学习及图计算,而使用Spark解决机器学习、图计算等迭代计算能够大大减少网络传输、数据落地等的次数,极大地提高了计算性能。
四、Spark与Hadoop的对比
(一)编程方式
- Hadoop的MapReduce计算数据时,要转化为Map和Reduce两个过程,从而难以描述复杂的数据处理过程;而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
(二)数据存储
- Hadoop的MapReduce进行计算时,每次产生的中间结果都存储在本地磁盘中;而Spark在计算时产生的中间结果存储在内存中。
(三)数据处理
- Hadoop在每次执行数据处理时,都要从磁盘中加载数据,导致磁盘IO开销较大;而Spark在执行数据处理时,要将数据加载到内存中,直接在内存中加载中间结果数据集,减少了磁盘的IO开销。
(四)数据容错
- MapReduce计算的中间结果数据,保存在磁盘中,Hadoop底层实现了备份机制,从而保证了数据容错;Spark RDD实现了基于Lineage的容错机制和设置检查点方式的容错机制,弥补数据在内存处理时,因断电导致数据丢失的问题。

