
- 1Homestead切换PHP版本_php 无法将“update-alternatives”项识
- 2使用matlab训练卷积神经网络_matlab卷积神经网络
- 3Java装箱拆箱和重载重写(五)_integer i1 = 40;integer i2 = 40;相等吗
- 4python中常用的序列化模块_Python中的序列化和反序列化
- 5应用(接口)被刷的解决方案(接口防止机器刷数据的处理方案)
- 6SpringBoot 面试题(六)
- 7用python实现SM2数字证书的坑
- 8Python爬虫天津景点数据可视化和景点推荐系统
- 9基于Hadoop的网上购物行为大数据分析及预测系统【flask+echarts+机器学习】前后端交互_基于hadoop的购物行为分析系统
- 10算法工程师的日常工作内容?你想知道的可能都在这里
搭建hadoop、SPARK,安装PySpark和notebook,实现简单实例文件分别在local、standalone、yarn和k8s上的运行_pyspark安装notebook
赞
踩
搭建hadoop、SPARK,安装PySpark和notebook,实现简单实例文件分别在local、standalone、yarn和k8s上的运行
准备
准备了三台虚拟机,配置网络(cd etc/sysconfig/network-scripts),添加域名和ip映射关系(vi /etc/hosts),以及在windows系统的hosts下添加虚拟机域名映射关系,保证虚拟机之间能够ping通。
vi /etc/hosts:
192.168.1.66 datanode01
192.168.1.67 datanode02
192.168.1.68 datanode03
- 1
- 2
- 3
添加hadoop用户,useradd hadoop,修改权限。
cd /etc/sudoers
visudo
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
一、安装jdk
下载jdk,并通过xftp上传到 /usr/java路径下解压。并 vi /etc/profile 配置环境。配置完以后,通过source /etc/profile启动生效。
通过which java和java -version查看配置结果如下:
[root@datanode01 ~]# which java
/usr/java/jdk1.8.0_291/bin/java
[root@datanode01 ~]# java -version
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
- 1
- 2
- 3
- 4
- 5
- 6
二、安装hadoop集群
1.设置SSH免密钥
[hadoop@datanode01 ~]$ssh-keygen -t rsa
[hadoop@datanode01 ~]$ssh-copy-id datanode01
[hadoop@datanode01 ~]$ssh-copy-id datanode02
[hadoop@datanode01 ~]$ssh-copy-id datanode03
- 1
- 2
- 3
- 4
在datanode02和datanode03上也是如此操作,保证彼此之间实现免密登录。
2.hadoop下载及环境配置
在hadoop官网下载hadoop3.1.4,并通过xftp上传到 /usr/local/路径下,解压,并重命名文件为hadoop。vi /etc/profile 配置hadoop环境。配置完以后,通过source /etc/profile启动生效。/etc/profile文件示例(下面包含了zookeeper的配置):
export JAVA_HOME=/usr/java/jdk1.8.0_291
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/hadoop
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/sbin
- 1
- 2
- 3
- 4
- 5
- 6
3.hadoop配置相关文件
在/usr/local/hadoop/etc/hadoop路径下配置hadoop-env.sh 设置JAVA_HOME:
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/java/jdk1.8.0_291
- 1
- 2
- 3
修改core-site.xml:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://datanode01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/tmp</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property> <property> <name>dfs.datanode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在三台虚拟机的/opt/data下创建tmp、namenode和datanode目录。
修改hdfs-site.xml,将datanode02设置为secondary name node:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>datanode02:50090</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
编辑slaves,设置datanode。
[hadoop@datanode01 hadoop]$ cat slaves
datanode01
datanode02
datanode03
- 1
- 2
- 3
- 4
编辑yarn-site.xml,将datanode02设置为resource manager。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>datanode02</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
编辑mapred-site.xml。将datanode03设置为job history server。
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>datanode03:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>datanode03:19888</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.分发和启动Hadoop
将datanode01安装目录下文件拷贝到datanode02、datanode03。
[root@datanode01 ~]# scp -r ${HADOOP_HOME}/ datanode02:/usr/local/hadoop
- 1
切换到root账户,关闭3台机器的防火墙。第一次启动集群,要格式化namenode。
[hadoop@datanode01 hadoop]# hdfs namenode -format
- 1
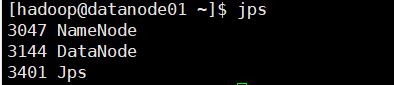
启动hdfs,并通过jps查看启动后的结果:
[hadoop@datanode01 hadoop]# start-dfs.sh
- 1
[hadoop@datanode01 hadoop]# jps
- 1
启动yarn(Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn):
[hadoop@datanode01 hadoop]# start-yarn.sh
- 1
在本地机器上通过web页面查看:

三、安装zookeeper
1.zookeeper分布式集群搭建
从官网上下载apache-zookeeper-3.5.8-bin.tar.gz, 将文件解压到/usr/local/zookeeper,复制zoo_sample.cfg到同一目录,命名为zoo.cfg.然后在文件里配置:
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
dataDir=/usr/local/zookeeper/data
server.1=datanode01:2888:3888
server.2=datanode02:2888:3888
server.3=datanode03:2888:3888
- 1
- 2
- 3
- 4
- 5
- 6
分别在三台虚拟机上的/usr/local/zookepper/data/路径下创建myid文件,并分别写入相应的id(1 2 3)
2.修改相应的配置文件
和hadoop的配置相似,分别配置环境、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml以及修改/usr/local/hadoop/etc/hadoop/workers文件。
yarn-site.xml修改后示例:
[root@datanode01 hadoop]# cat yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>datanode02</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>datanode02:8088</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>datanode02</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>datanode02:8088</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>hadoop.zk.address</name> <value>datanode01:2181,datanode02:2181,datanode03:2181</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
workers修改后示例:
[root@datanode01 hadoop]# cat workers
datanode01
datanode02
datanode03
- 1
- 2
- 3
- 4
启动Hadoop:
在三台虚拟机执行/usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode命令,启动journalnode。
[hadoop@datanode01 ~]$ jps
1907 Jps
1893 JournalNode
- 1
- 2
- 3
[hadoop@datanode02 ~]$ jps
1575 Jps
1561 JournalNode
- 1
- 2
- 3
[hadoop@datanode03 ~]$ jps
1576 Jps
1562 JournalNode
- 1
- 2
- 3
在datanote1上执行/usr/local/hadoop/sbin/hadoop-daemon.sh start namenode。
[hadoop@datanode01 ~]$ /usr/local/hadoop/sbin/hadoop-daemon.sh start namenode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
[hadoop@datanode01 ~]$ jps
2000 NameNode
1893 JournalNode
2029 Jps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在datanode02上执行/usr/local/hadoop/bin/hadoop namenode -bootstrapStandby同步datanote01的信息。
在datanote01上执行/usr/local/hadoop/bin/hdfs zkfc -formatZK格式化zkfc
[hadoop@datanode01 ~]$ /usr/local/hadoop/bin/hdfs zkfc -formatZK
- 1
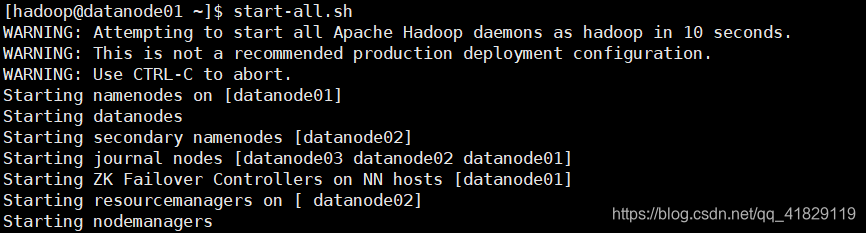
之后在datanode01上执行/usr/local/hadoop/sbin/stop-all.sh,把相关的服务全部停掉。
在datanode01上执行start-all.sh,启动集群。

四、安装spark
1.下载安装scala
下载scala 2.12.8,上传解压到/usr/local/scala目录下。
vi /etc/profile,配置环境变量。
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
- 1
- 2
执行命令:source /etc/profile,使环境配置生效
2.搭建spark集群
下载spark 2.4.3,上传到/usr/local/下,解压重命名为spark。
vi /etc/profile,配置环境变量。
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin
- 1
- 2
cd /usr/local/spark/conf,进入spark配置目录,执行命令复制配置文件:
cp spark-env.sh.template spark-env.sh
配置spark-env.sh,配置jdk、scala、hadoop、ip、master等信息,SPARK_MASTER_IP和 SPARK_MASTER_HOST配置master服务器域名,SPARK_LOCAL_IP为对应spark节点的IP地址,配置如下:
export JAVA_HOME=/usr/java/jdk1.8.0_291
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=datanote01
export SPARK_MASTER_HOST=datanote01
export SPARK_LOCAL_IP=192.168.1.66
export SPARK_WORKER_MEMORY=2g
export SPARK_WORKER_CORES=1
export SPARK_HOME=/usr/local/spark
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
cd /usr/local/spark/conf,配置从节点
datanode02
datanode03
- 1
- 2
拷贝spark到在datanode02和datanode03。
3.启动spark集群
在datanode01上进入cd /usr/local/spark/sbin
执行命令:./start-all.sh,即可启动Spark集群,在哪个服务器上执行该命令,该服务器将成为主节点,其余服务器都是从节点。
示例截图如下:

启动结果:
[root@datanode01 sbin]# spark-shell 2021-05-06 19:22:32,993 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://datanode01:4040 Spark context available as 'sc' (master = local[*], app id = local-1620300209753). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.3 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_291) Type in expressions to have them evaluated. Type :help for more information.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
web界面

spark自带pyspark,启动pyspark如下:
[root@datanode01 sbin]# pyspark [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux2 Type "help", "copyright", "credits" or "license" for more information. 2021-05-06 19:31:10,949 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 2021-05-06 19:31:17,215 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.4.3 /_/ Using Python version 2.7.5 (default, Oct 14 2020 14:45:30) SparkSession available as 'spark'. >>>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
4.安装notebook
下载安装anaconda,Anaconda3-4.0.0-Linux-x86_64.sh,通过bash Anaconda3-4.0.0-Linux-x86_64.sh,安装在root/anaconda3下。
在/etc/profile里添加配置:
export ANACONDA_HOME=/root/anaconda3
export PYSPARK_PYTHON=$ANACONDA_HOME/bin/python
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$ANACONDA_HOME/bin
- 1
- 2
- 3
接下来设置openssl
openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout mycert.pem -out mycert.pem
打开ipython , 设置密码。通过jupyter-notebook --generate-config生成配置文件,在/root/.jupyter/ 下修改config 文件: jupyter_notebook_config.py
vim /root/.jupyter/jupyter_notebook_config.py
c.NotebookApp.password = u'sha1:自己前面生成的秘钥'
c.NotebookApp.ip = '192.168.1.66' #本机IP
c.NotebookApp.port=8888 #端口
- 1
- 2
- 3
- 4
启动notebook
jupyter notebook --ip=10.177.33.45 --no-browser
- 1
结果:
[root@datanode01 .jupyter]# jupyter notebook --ip=192.168.1.66 --no-browser
[I 21:03:02.240 NotebookApp] Serving notebooks from local directory: /root/.jupyter
[I 21:03:02.241 NotebookApp] 0 active kernels
[I 21:03:02.241 NotebookApp] The Jupyter Notebook is running at: http://192.168.1.66:8888/
[I 21:03:02.241 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[I 21:03:52.523 NotebookApp] 302 GET / (192.168.1.1) 3.69ms
[I 21:03:52.564 NotebookApp] 302 GET /tree (192.168.1.1) 38.38ms
[I 21:04:09.340 NotebookApp] 302 POST /login?next=%2Ftree (192.168.1.1) 5.18ms
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
web界面结果:

5.实现简单实例
3.py中的程序
from pyspark import SparkContext
from pyspark import SparkConf
conf=SparkConf().setAppName('appName').setMaster('Local[*]')
sc=SparkContext(conf=conf)
text_file=sc.textFile("/usr/1")
counts=text_file.flatMap(lambda line: line.split(" ")).map(lambda word:(word,1)).reduceByKey(lambda a,b:a+b)
counts.saveAsTexFile("/usr/2")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
local上提交命令执行程序
[root@datanode01 sbin]# spark-submit --driver-memory 2g --master local[*] 3.py
- 1
standlone上提交命令执行程序
[root@datanode01 sbin]# spark-submit --master spark://master:7077 --deploy-mode client executor-memory 512m --total-executor-cores 2 3.py
- 1
yarn上提交命令执行程序
[root@datanode01 sbin]# spark-submit --driver-memory 512m --executor-cores 2 --master yarn --deploy-mode client 3.py
- 1

