
- 1uni-app(H5)论坛 | 社区 表情选择 UI组件
- 2CPU怎么实现LOCK指令
- 3自然语言处理与计算机视觉:融合与挑战
- 4解析大型语言模型的训练、微调和推理的运行时性能_大模型推理性能
- 5Android安装包各子包介绍_android 应用包名下的不同分类包
- 6科学大数据作用重大
- 7Windows安装Git图文教程_git安装教程 windows
- 8Python 五种图片相似度比较方法_python对比图片
- 92019最新Flutter 面试知识点集锦(二)_flutter platformview原理
- 10element el-descriptions-item设置单独一行显示【记录】_elementui description-item span
“意识机器”初探:如何让大语言模型具备自我意识?
赞
踩

导语
什么是意识?现在的大语言模型具备意识了吗?我们能否造出具备自我意识的机器?在集智俱乐部「后ChatGPT」读书会,北京师范大学系统科学学院教授、集智俱乐部创始人张江老师回顾了意识科学和意识建模领域的进展,认为自我意识是意识的关键,而早期对于图灵机、自指、自复制自动机等研究可以为构建机器意识模型很大的启发。集智俱乐部核心成员、人工智能算法工程师李嫣然将此次读书会整理成文,并补充了背景知识,分享给大家。
关键词:意识机器,自我意识,自指,自复制自动机,通用人工智能

来源: 集智俱乐部
讲者:张江
作者:李嫣然
编辑:梁金
随着大语言模型研究的突破,越来越多人开始关注大语言模型与通用人工智能(AGI),以及大语言模型是否已经具有意识。众所周知,想要探讨“意识”是非常困难的,因为就连人类本身都很难定义自身的意识。尽管如此,关于“意识”的研究和思考却从未停止。
于是,为了更好地探究意识与人工智能的关系,本次读书会中张江老师梳理了人类意识研究、意识理论与建模、自指与意识机器、以及自模拟意识机器等话题。在这次读书会中,关于意识、自指、自编码、分形、注意力机制、重整化甚至量子等方面的话题都有涉猎。本文为《“意识机器”初探》这期读书会的笔记,同时补充了一定的背景知识。

引言
在开篇这里,我们不妨思考这样一个问题。我们该如何评估一个东西(比如大语言模型)是否具有“意识”?张江老师提出,有三个角度判断一个东西是否有意识:
1. 从语言行为角度:像耳熟能详的图灵测试,就是从机器的行为来判断它是否具有智能。即在测试过程中,机器的行为是否已经与人无异。行为可以认为是某种宏观层面的判断方式。
2. 从实现意识硬件的物理现象的角度:我们也可以从实现意识的硬件——比如“脑”或“计算机”的物理现象层面来判断一个东西是否具有意识。比如现在有许多科学家已经发现了一些人脑中出现“意识”的特征,这些特征可以定位到神经元活动等。还有如临界相变等都可能与意识的物理机制有关。
3. 从实现意识软件的功能结构角度:这第三种角度是张江老师自己思考提出的,他认为这第三个角度既不是物理的,也不是行为的,而是从软件的构成与结构的角度来判断。比如一个自指程序,它没有外在物质身体,行为也很单调,但它很可能是具备意识的。
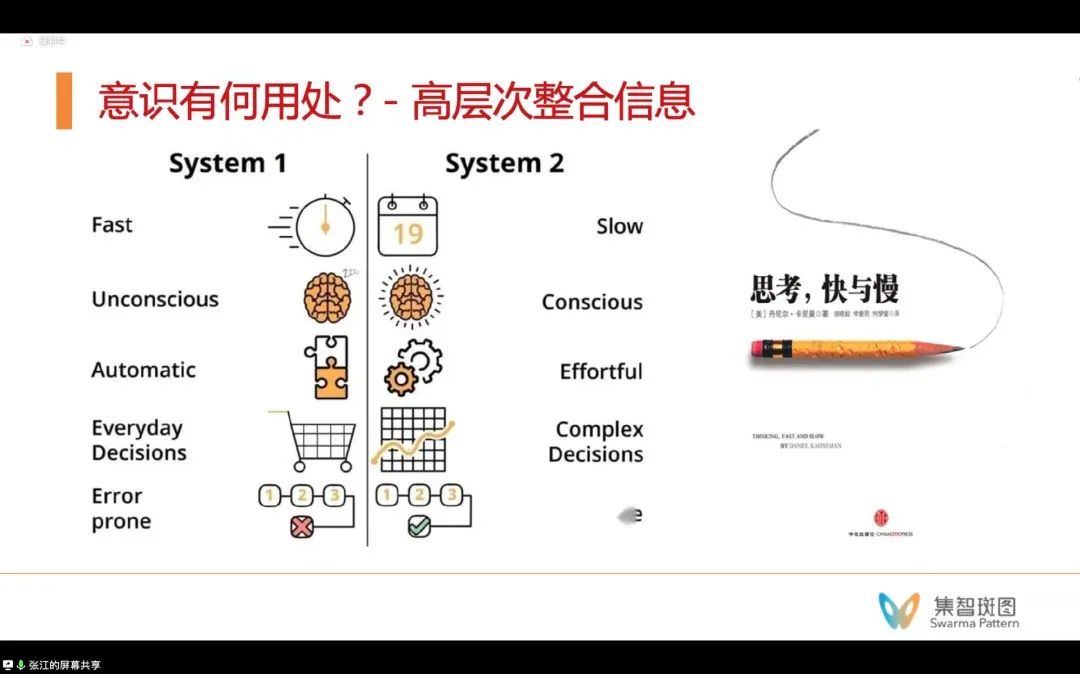
进而,我们可以再思考第二个问题。意识有何用处?为什么我们要研究意识?这里可以从我们人类的思维模式来找到一些证据。人类的思维有一个很重要的特点是,会做高层次信息的整合。在《思考,快与慢》这本书中,也提到人类的大脑有2个系统,一个是快系统(系统1),一个是慢系统(系统2)。粗浅地理解的话,快系统更偏直觉,慢系统更偏逻辑。
那么,为什么逻辑思维一定要慢系统执行?为什么在人类的进化和日常生活中,它一定要整合信息?这是因为,世界本质上由很多并行的 agent 构成,这些并行的部分要形成一个整体(integration)的时候,就需要整合信息了,这就是串行化,也就是“我”这个个体的形成。所以,世界有了“我”,也就从并行转变为串行了。与此同时,“我”也必然需要与其它的整体传输信息的方式,这便是语言的形成。
尽管这样想很合理,但如果这样想——假设意识是一种信息整合的话——意识又仿佛是一种 bottleneck,语言是一种阻碍信息高效交流的存在。如果人脑和人脑之间直接相连,会比人们用语言传递信息更高效。所以我们可以再进一步想一想,“意识”是否真的只是为了我们处理世界中的各种信息才形成的呢?

除了信息传递和信息处理,意识可能还有其它用处。如果我们能意识到“我”,我们就可以“自我反思”“自我改进”甚至”自我解释“——这些对于生命都是很重要的。同样,我列出来的这几篇论文也都是目前关于大模型的最新改进方向的论文,它们的共同特点就是都存在着“自我”的字样。
自我反思
Self-Refine: Iterative Refinement with Self-Feedback
https://arxiv.org/abs/2303.17651
Reflexion: an autonomous agent with dynamic memory and self-reflection
https://arxiv.org/abs/2303.11366
自我改进
Large Language Models Can Self-Improve
https://arxiv.org/abs/2210.11610
自我解释
Self-explaining AI as an alternative to interpretable AI
https://arxiv.org/abs/2002.05149
特别值得一提的是这个“自我解释”,它对于构建一个我们可信赖的AI系统至关重要,同时要想让AI具备解释能力,让它了解因果推理也是很自然的,这是因为它不仅要做出预测、判断和决策,还要能跟我们说出来,它为什么这么做——这就是“自我解释”。尽管这种解释并不一定是它对自己决策过程的真实反应,而完全可能是它自己编的一个故事,但是问题的关键在于它给出了一种解释,这就让我们人类对它会产生信赖感。这也是我们人类人际交往关系的存在基础。
那么语言和意识的关系究竟是什么呢?纵观历史,人类大脑的前额叶在人类的进化过程中,是在不断地增长的——就是因为人们总是使用语言。所以,从人和人沟通的角度,语言是非常重要的。同时,在人和人沟通的时候,其实我们是处于一个复杂的环境下的,比如博弈环境。只有在这样的环境中,人才能反照自身,“他人是一面镜子”。这样的自我又是另一种自我。在复杂的博弈中,人们才能产生“我”的行动会对别人产生什么样的影响的推理。
例如,最近的MIT和Google联合出品的论文就在尝试用大模型搭建一个虚拟的“西部世界”,并探讨AI自我反思和社会互动的能力。
论文题目:
Generative Agents: Interactive Simulacra of Human Behavior
论文链接:
https://arxiv.org/abs/2304.03442
虽然近一年,也有不少新的人工智能领域的论文,尝试给大语言模型加了一些模块,让它可以进行自我提升、自我精炼、自我反思和自我解释等。但这些论文基本都只是加了个反馈回路——依然还不能被称为是自指机器。至少,从上面的分析角度来看,人工智能在和人类的互动中,需要反观自身,而这个自身并不是现有的论文已实现的那种样子,因而这个方向还充满着机遇。
尽管如此,大语言模型出现之后,有越来越多的研究开始关注基于 LLM 实现更多”自我“的东西了,这是非常令人期待和兴奋的。
人类意识研究
从引言部分可以了解到,研究意识是很重要的。那么历史上,都有哪些意识研究呢?这部分的内容涵盖了大量历史上的实验。

在《What is consciousness, and could machines have it?》这篇论文研究中,作者提到,意识至少有3重含义:
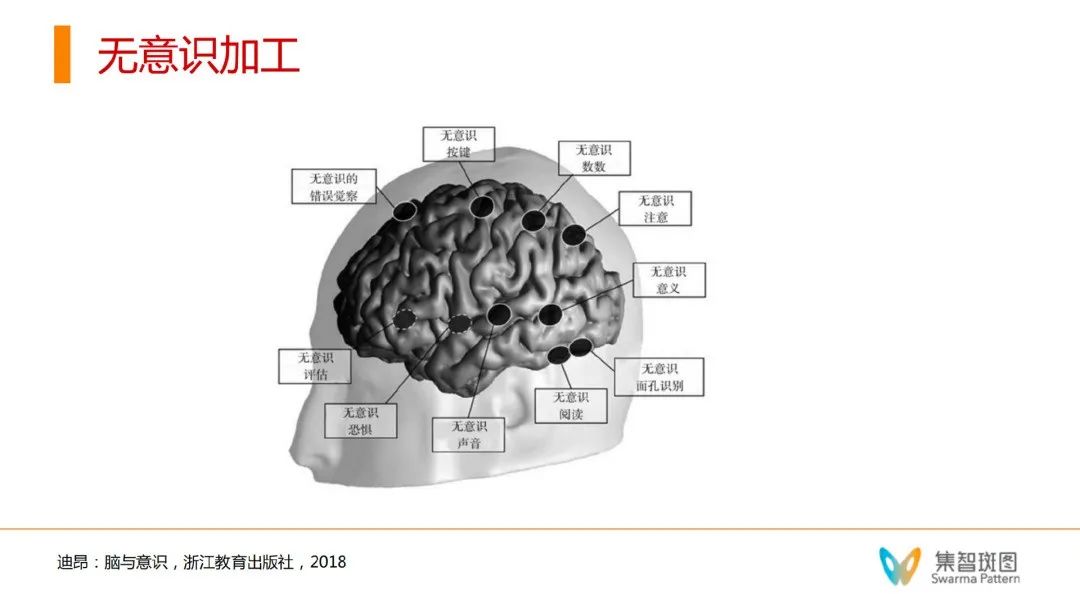
1. C0,无意识加工和意识状态。即,什么工作在什么条件下,必须有意识参与?作者做了很多实验,来验证无意识加工的存在。这个领域的研究相对成熟。
2. C1,总体可用性。即信息整合、同一性。这一方面的内容与“整合信息论”的理论相关,主要研究了信息整合是如何发生的,以及如何定量衡量。
3. C2,自我监控——即自我意识的核心。
非常多大家都很熟悉的经典实验,可以证明人类的意识与看见其实是很不同的,比如 Dan Simons & Christopher Chabris 的“黑猩猩”实验和“注意瞬脱”实验。
论文题目:
Gorillas in Our Midst: Sustained Inattentional Blindness for Dynamic Events
论文链接:
https://journals.sagepub.com/doi/10.1068/p281059

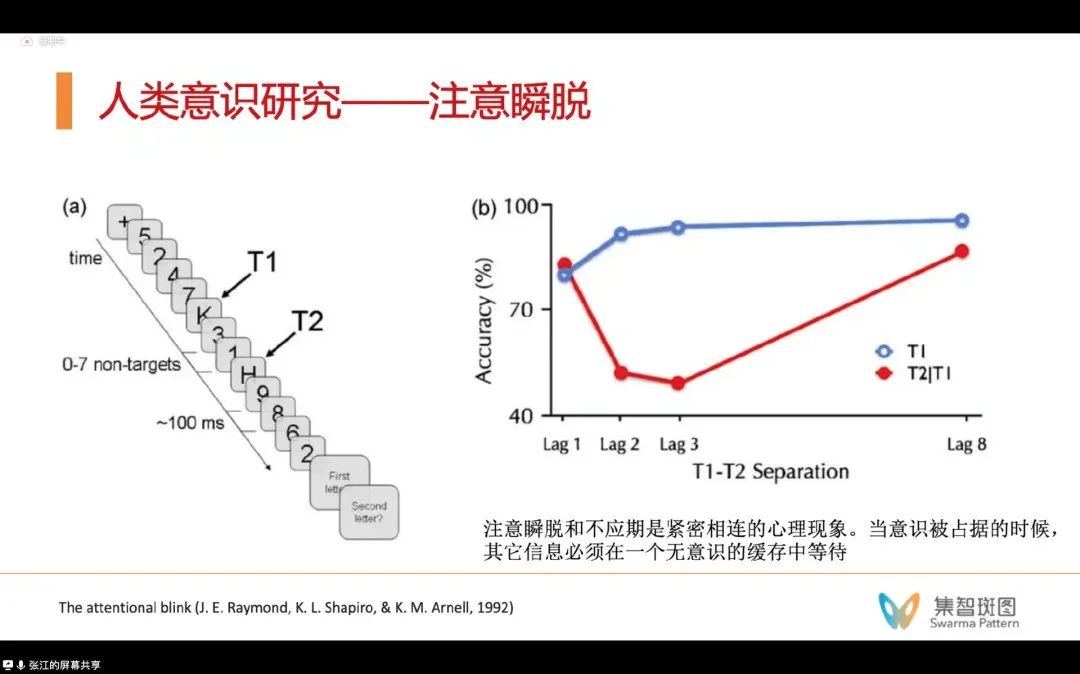
注意瞬脱实验(attentional wink),可直译为“大脑眨眼”。这个实验要求被试报告屏幕上出现的字母。随着接续字母的间隔时间变短,被试会“看不见”第二个字母,会认为没有第二个字母——原因就是他的注意力都放在了第一个字母。但如果我们重新把间隔时间变长的话,被试又可以“看到”到两个字母了。这些实验就都在说明:人们的大脑会有意识的不同状态,于是就有了无意识和有意识的状态的划分。
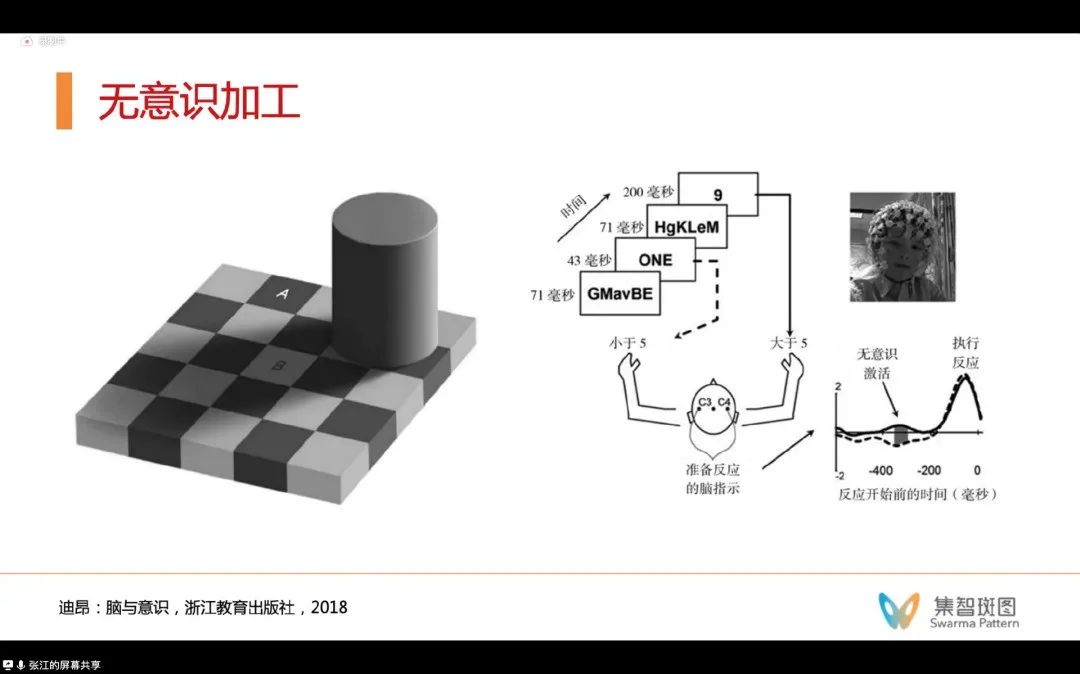
这里的棋盘格实验在划分的基础上又进了一步,它验证了我们的大脑在没有意识觉察的前提下,就已经在进行信息的处理和加工了。比如棋盘上的A, B两个字母,实际上都是同样灰度亮度的,可是我们人第一反应总是以为A, B不同色——这是因为我们的大脑在没有意识的情况下,已经做了一些逻辑处理的加工——认为B在阴影里,所以B的颜色更深。后来的各种各样的实验发现,我们大脑参与的无意识加工,有非常非常多。比如简单的逻辑计算、甚至决策判断。
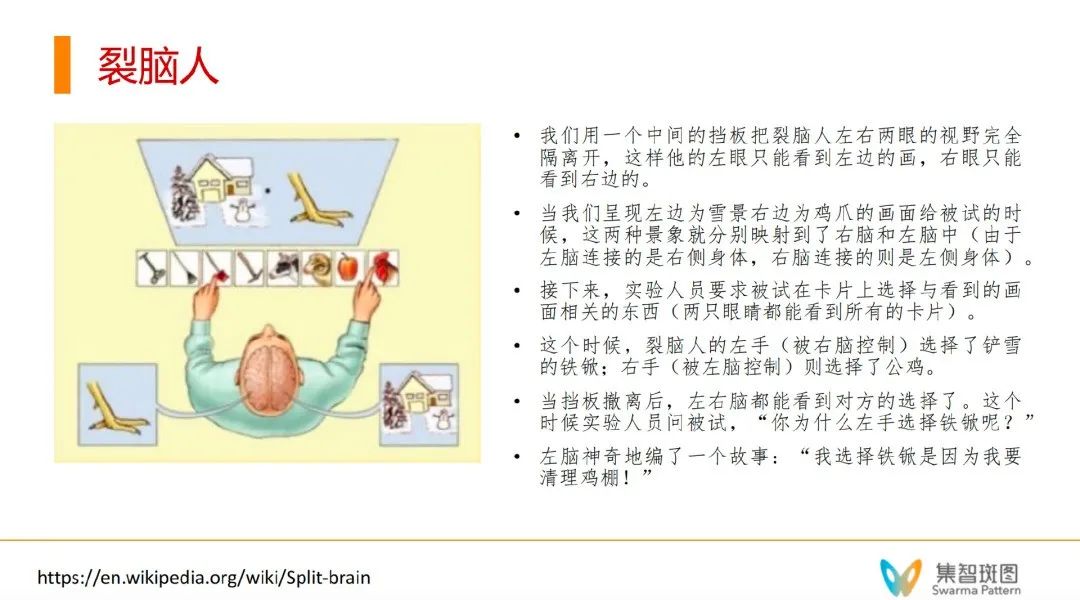
还有一些实验告诉我们,我们甚至可以在“无意识加工”的基础上,分成两个自我。就像“裂脑人”这种疾病。左脑的语言能力甚至会“编故事”来解释意识的左右区分,左右甚至可以相对独立地进行决策。
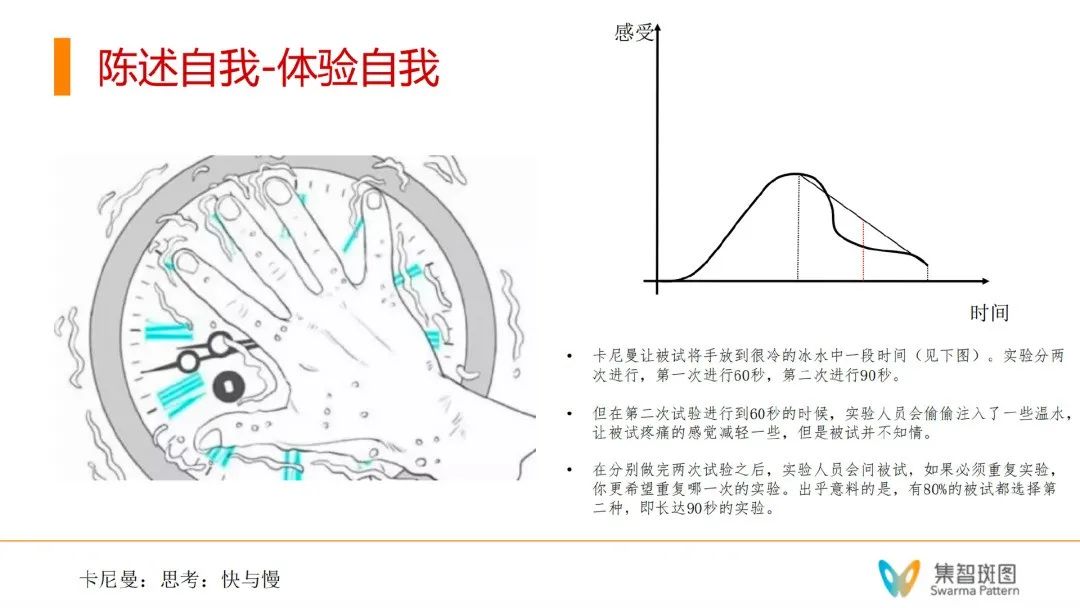
另外一个有趣的实验,更贴近我们的生活。如果我们让同一个被试,把手浸泡在冰水里,但两次测试浸泡不同时间长度。且第二次浸泡时间长的时候,实验人员会在实验快结束的时候偷偷把水进行加温,但被试并不知道。做完两次实验后,实验人员问被试更愿意重复做哪次实验。80%的被试愿意再做第二个实验,但实际上第二个实验浸泡时间更长,90s。这个实验告诉我们,大脑的“意识”或者说“感受”并不完全相等。有一个大脑对于快到结束部分的体验更在意。
意识是“自由”的吗?
如果刚才这些实验都比较定性,那么这里想分享一个经典的定量实验。这是一个从60年代就有人开始尝试,而在80年代成为一个经典的实验,关注的是人类是如何做决策的,人类是否有自由意志,人类做决策是瞬间的,还是在意识深处有一些信号已经知道我们要做决策了。在实验中,被试是一群大学生,他们被要求在观察到特定的信号后按下手里的按钮。
在这个实验里,研究者们在大学生的脑波信号中发现,在按下按钮前500ms(半秒钟),就已经产生脑电波信号了。说明无意识很早就在决策前参与了。更有趣的是,如果让大学生们自我陈述,他们是何时在头脑中产生按按钮的决定的,这个时间往往会比500ms靠后一些,但也会比按钮的动作时间靠前。这个实验就非常贴合那个词“起心动念”,先有的是“无意识”的一个信号RP,然后才有了意识W,最后做出动作是M。
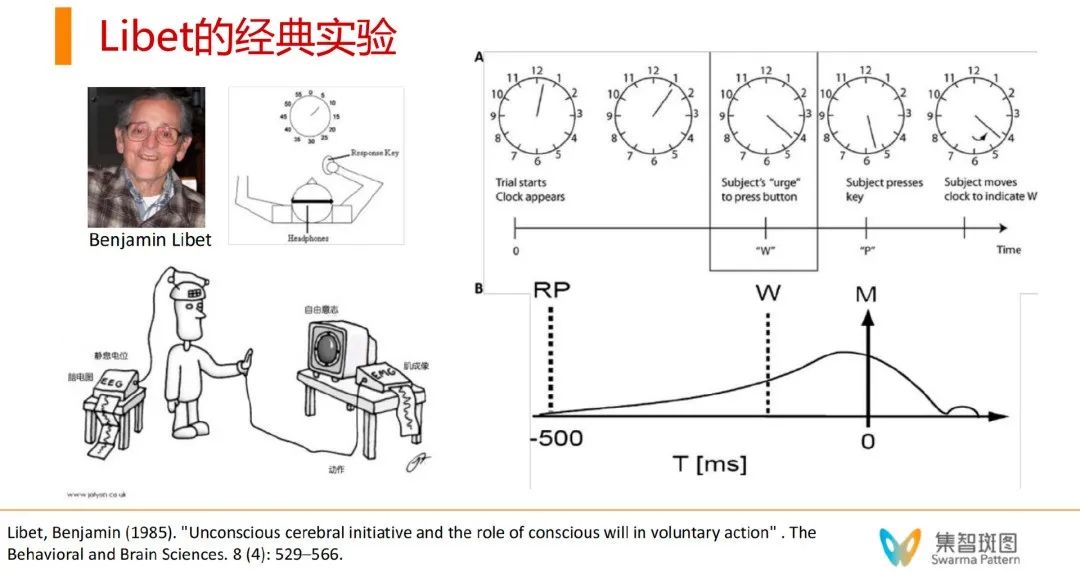
这个实验首先告诉我们,当我们做决策的时候,也是先有无意识参与的,然后才是意识和行动。同时,这个实验还从一定程度上挑战了所谓的“自由意志”的存在,这是因为,在我们意识头脑中产生按按钮的前期将近500毫秒,就已经由我们的“身体”产生了要做的决定,而我们的意识参与进来的时候,本质上只不过是对这种“身体决定”的一种认知和解读。不过,关于自由意志这一点,还存在着相当大的争议。意识与自由意志的问题,我们后面也会讨论。
物理世界中可能看到“意识”吗?
那么,从物理世界的角度,有可能定位看见意识吗?在之前推荐的书《脑与意识》中,作者做了很多实验,用各种手段,在大脑中定位意识神经元。

实验发现,达到作者认为的“意识通达”这个状态,是需要一个过程的。以视觉任务举例,在360-500ms的时候(这个时间长度和Libet的实验时间长度相当),小规模放电就会发生在“无意识区域”。随后,小规模放电一点点渗透到脑的核心区域(一般认为是前额叶、顶叶、颞叶等区域)——即“意识”的脑区。进入这些意识脑区后,放电会变得非常剧烈,同时会引发放电的雪崩,然后就会有各种区域的一系列的激活,并且这些各种区域的雪崩效果会持续相对长的时间。这个过程有一个典型的特征,即“全局性”——空间的全局性,和时间的高延迟性。换句话说,这种“意识”活动的时间尺度和空间尺度都非常强。而且后面的研究也认为,时间的相关性非常长。这和物理中的相变也有密切关系。这些内容,在书中也有介绍。
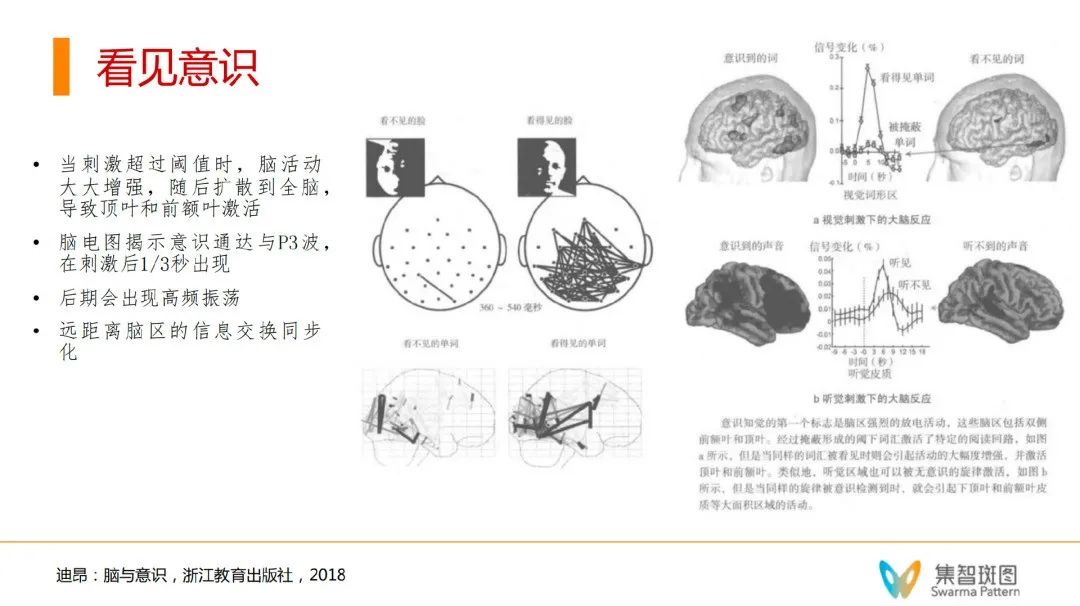
于是,这本书的作者,认为意识信号有4个特征:
1. 超过阈值时,信号会大大增强,然后“雪崩”扩散。
2. 脑电上,会呈现出一种P3波(书中有图),是一种很规则的波形,相对局部的一种波形,会在刺激的1/3s后出现。认为P3波是一种界定有无意识的时间特征。
3. 后期会出现高频振荡,和gamma波的发生(人类清醒时的波形)有关系。
4. 远距离脑区会同步交换信息。
意识理论与建模
随着大语言模型的出现和告诉发展,与大语言模型息息相关的“意识”领域研究可能也已经进入了突破的边缘。在意识研究领域,有几个代表理论:
1. 全局工作空间,Global Workspace Theory
2. 信息整合论,Integrated Information Theory
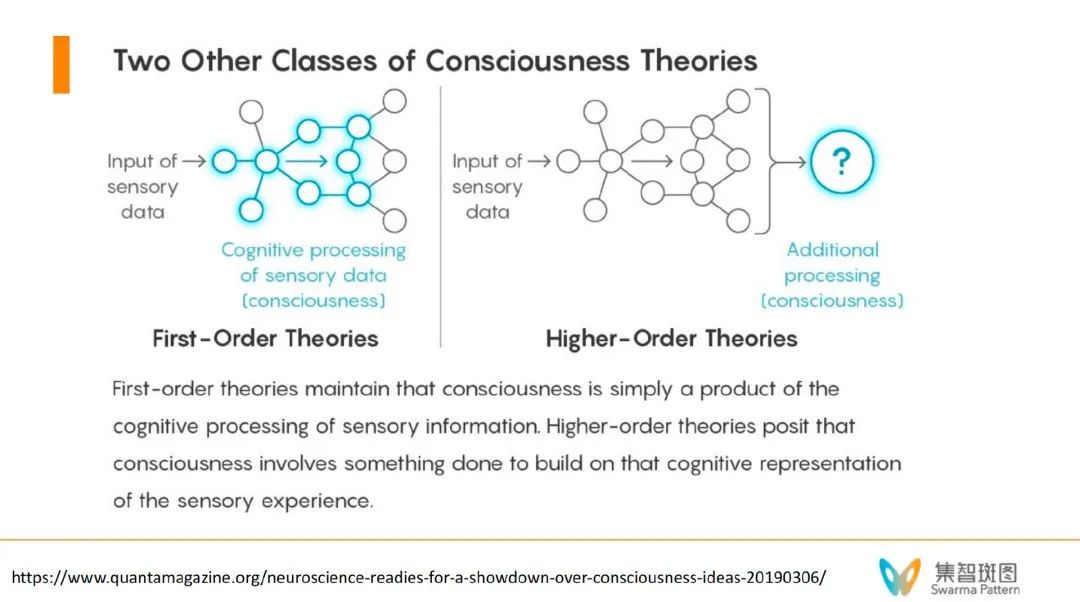
3. 一阶/高阶理论,First-Order / Higher-Order Theories
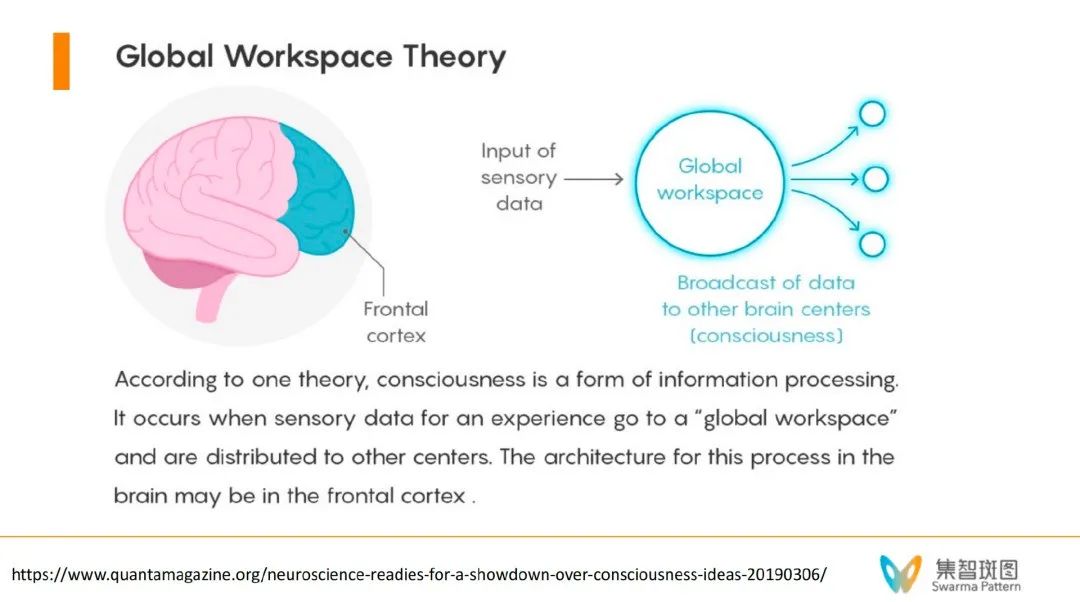
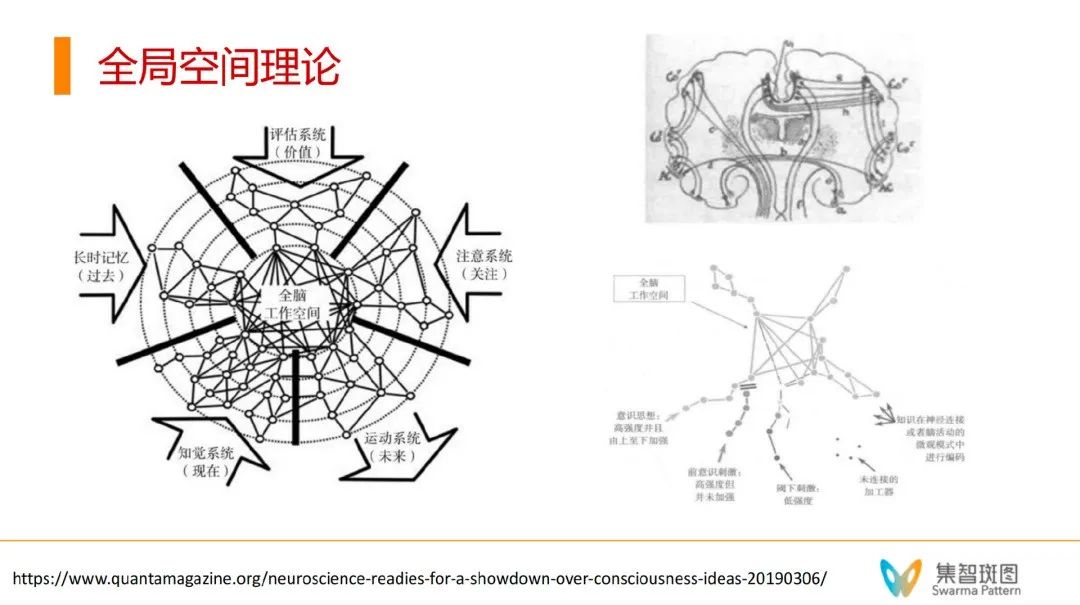
首先来说全局工作空间理论(global workspace theory)。这个理论认为,人类的大脑实际上有一堆小程序,类似于APP。这些小程序平时不需要意识参与,自动就能完成一系列的工作。而意识是什么呢?全局工作空间理论认为,意识就好像一个舞台,在特殊的场合/刺激下,意识会让这些小程序加载到全局的意识系统里去,进入到舞台的中央。
这样的话,在这个空间里,就可以做很多复杂的信息处理,如逻辑推理、决策规划等。这些是需要全脑参与的。不仅如此,意识还能反过来给这些小程序去发放信号,同时发给小程序,这样能让人快速产生行动。
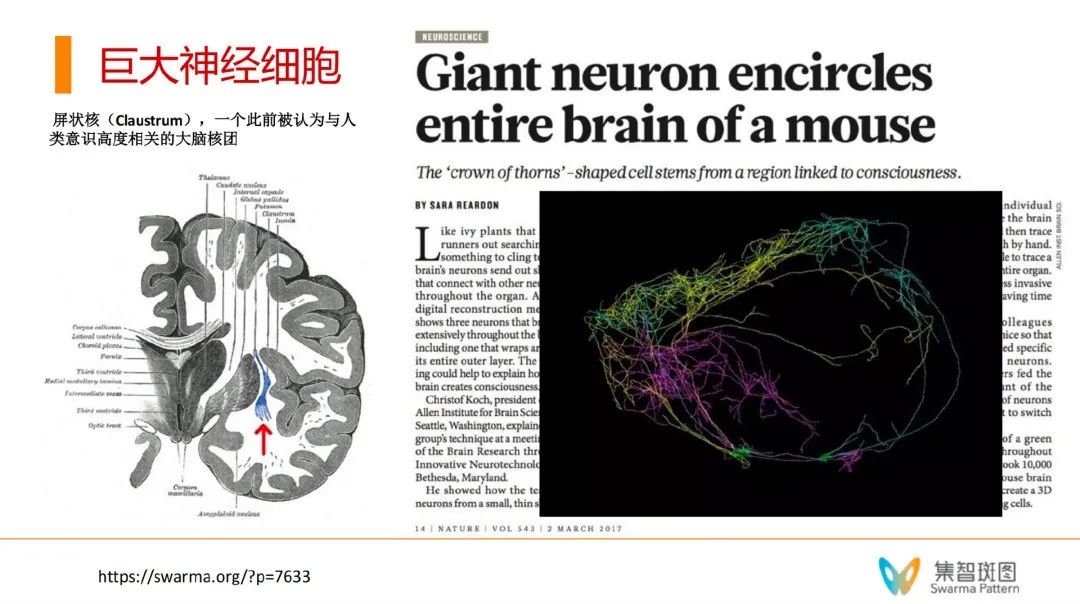
现在科学家们已经找到了很多证据,证明在大脑里,有很多跨脑区的长程连接,这些连接都可以认为是某种全局激活的物理基础。2017年,《Neuroscience》上有一个报道,科学家们发现了“巨大神经细胞”(Giant Neuron)。如下图,一个颜色是一个神经元,有很多突触,这些突触很长,基本达到了“脑”的尺度。这也成为了“全局工作空间理论”的一个物理证据。
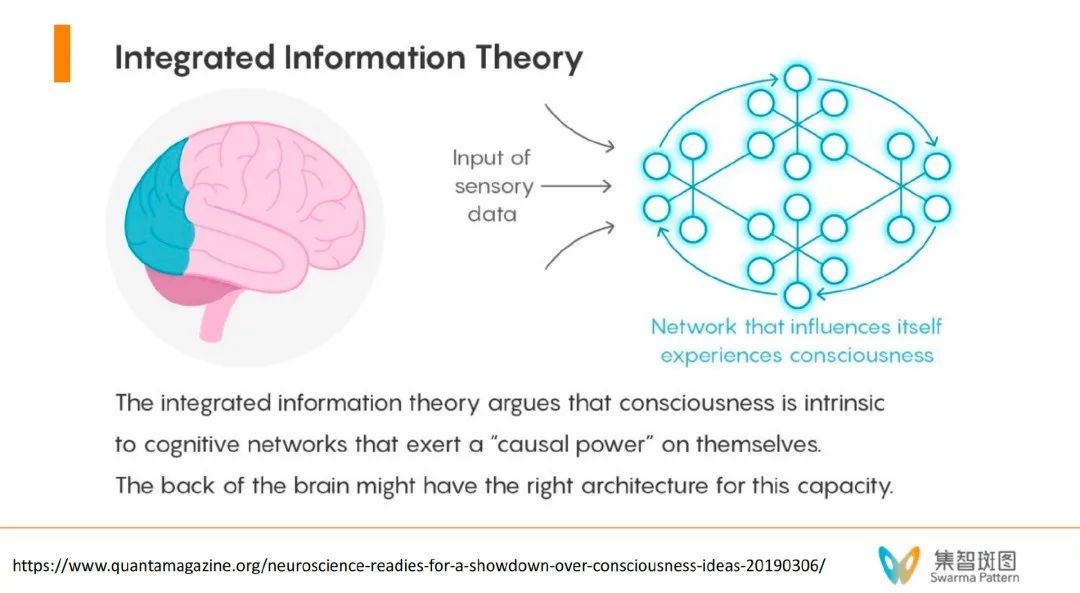
第二个重要的理论是“整合信息理论”(Integrated Information Theory)。这个理论的观点是从5个现象学公理出发,定量刻画了什么样的网络会具备意识。其中,我认为这个理论最重要的有两条,分别是:
(1)该理论认为整合是非常重要的,有整有分。因为脑是并行的分布式的系统,而神经元又要被整合成一个整体;
(2)因果力,该理论认为被整合后的神经元要展现出“因果力量”(causal power)。
如果与全局工作空间理论相比,整合信息理论中认为的因果力其实就发生在全局工作空间中的中心区域(舞台),认为这些中心区域需要有这种因果力量,使得其能给其它神经元施加。这个理论思想和因果涌现也非常有关,而且这个理论甚至可以定量地、定义“意识度” φ。
如上图,假设我们有一个分布式网络系统,里面只涵盖2个单元。那么所谓的整合信息论里的大φ,刻画的是这2个单元作为部分或整体(2单元的系统)如何发生因果联系(见右侧网络)——我们会发现,其能产生16种因果作用的可能性。在右侧网络上,每一个节点上的标识,箭头前是 t 时刻,箭头后是 t+1 时刻。这个网络刻画的是,t 时刻的某个局部或整体会对 t+1 时刻的另一部分的局部或整体产生的影响。这个因果力之所以重要,是因为它能实现的不仅仅是2个单元之间的相互作用,也有2个单元作为整体对一个单元独自产生的作用——这就是“向下因果”。系统的因果作用不仅仅是体现在个体和个体之间,也展现在整体对个体上。
“向下因果”是因果涌现领域中重要的概念。在集智的因果涌现读书会里,我们关注到,在复杂系统里,存在多个层级和多种尺度,这不仅可能表现为不同层级和尺度下存在不同的因果关系,甚至有可能存在跨层级的因果联系。事实上,有大量的例子能够让我们找到这种跨层级的因果关系。在集智的另一篇文章《涌现、因果与自指——“因果涌现”理论能否破解生命与意识之谜》中,我们就介绍过这样一个例子。
为了体会向下因果,我们不妨做出这样一个动作,即用自己的手拍打自己的身体,当我们做这个动作的时候,仍旧可以从两个层次观察:在微观层面,这个动作无疑会造成手臂、身体上大量细胞死亡;而从“我”这个整体的人层面看,这些细胞无疑是被“我”制约的。吊诡的是,“我”是由大量的细胞构成的一个系统,假使按常规的因果论(还原论),“我”这个人体的特性是由细胞所决定的,正如“我”会害怕火,是因为细胞害怕火,细胞一被火烧,就会死亡。可是,人们却可以为自己的理想信念做出牺牲,甚至不惜让自己的细胞乃至于全部都被火烧死。显然,这超越了常规的从微观到宏观的因果论,而是从宏观到微观的因果倒置。
这些例子都符合物理化学的基本规律,然而这些解释却显得冗余且没有触及到更重要的本质:人可以为了理想信念而牺牲;蚂蚁可以为了整个蚁群而牺牲;“我”存在自由意志,所以可以拍打自己。这些都是因为有一个更高层级的整体,这个整体可以作为一个独立的主体发出“因果之力”,使得因果箭头从整体指向个体:我希望拍打手臂,所以产生了动作,细胞也随动作而死亡。而整合信息论中最重要的第二个观点就是在强调这种“因果力”,causal power。
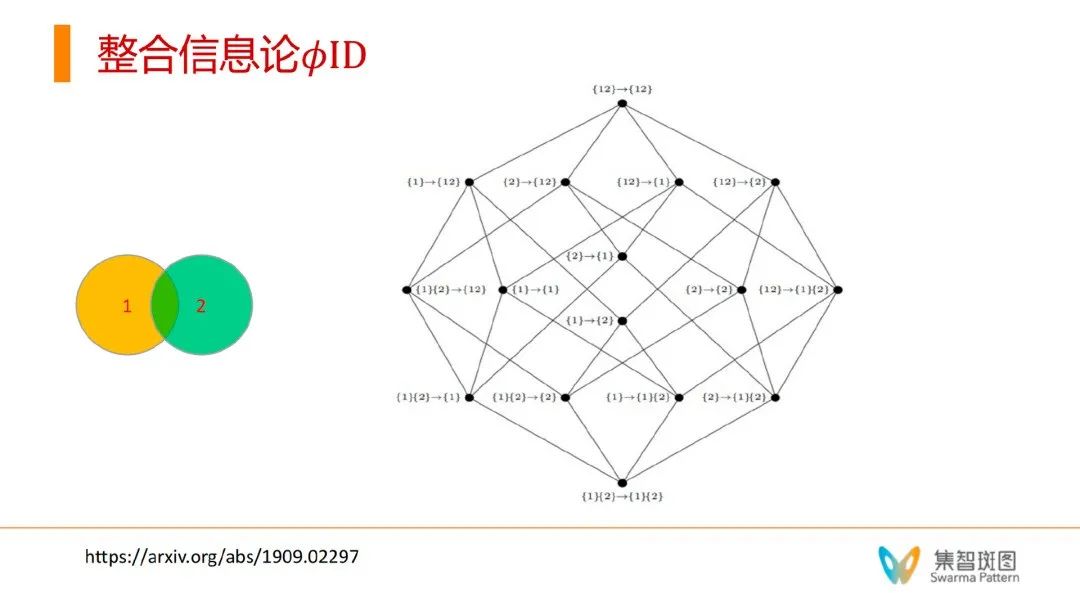
论文题目:
Beyond integrated information: A taxonomy of information dynamics phenomena
论文链接:https://arxiv.org/abs/1909.02297
有了这种可以从整体指向个体和个体之间相互作用的因果力,就可以使信息产生“协同作用”。比如 Y = A XOR B,就是这样一种有协同作用的系统,因为要确定Y的取值,你必须同时知道A和B的状态取值,单独知道了一个,对Y的预测仍旧毫无作用,我说A与B的协同(整体),对Y有影响,而不是A或B对Y有影响。这样的话,对于一个有 n 个单元的系统,所有可能的组合态至少是 2^n 种,每种组合态就可以对下一个时刻的某种组合态产生影响。这就是信息整合论的因果力,causal power。
一阶/高阶意识理论涉及到了意识的层次、自指等问题,这个我们后面专门讨论。
还有非常多的意识理论,有兴趣的读者可以参考之前的一篇综述文章《意识理论综述:众多竞争的意识理论如何相互关联?》。
论文题目:
Theories of consciousness
论文链接:
https://www.nature.com/articles/s41583-022-00587-4

意识的实现
说完理论,说说意识的实现。有一对图灵奖获得者夫妇(Lenore Bluma和Manuel Blum),在PNAS上发了一篇“论文笔记”,提出了一个“意识图灵机”模型——一个可计算的意识架构。
论文题目:
A theory of consciousness from a theoretical computer science perspective: Insights from the Conscious Turing Machine
论文链接:
https://www.pnas.org/doi/10.1073/pnas.2115934119
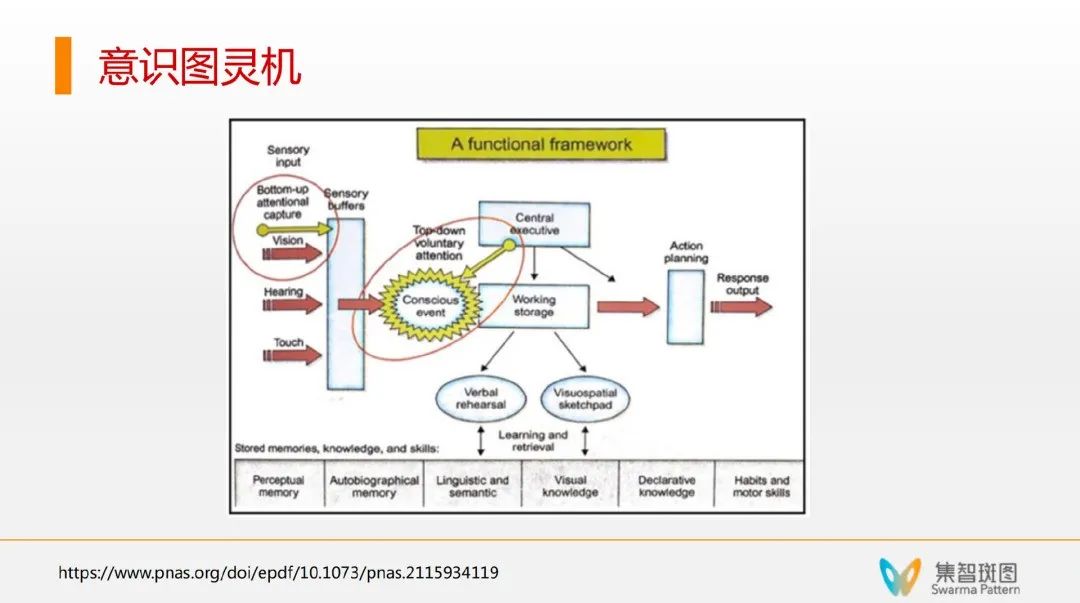
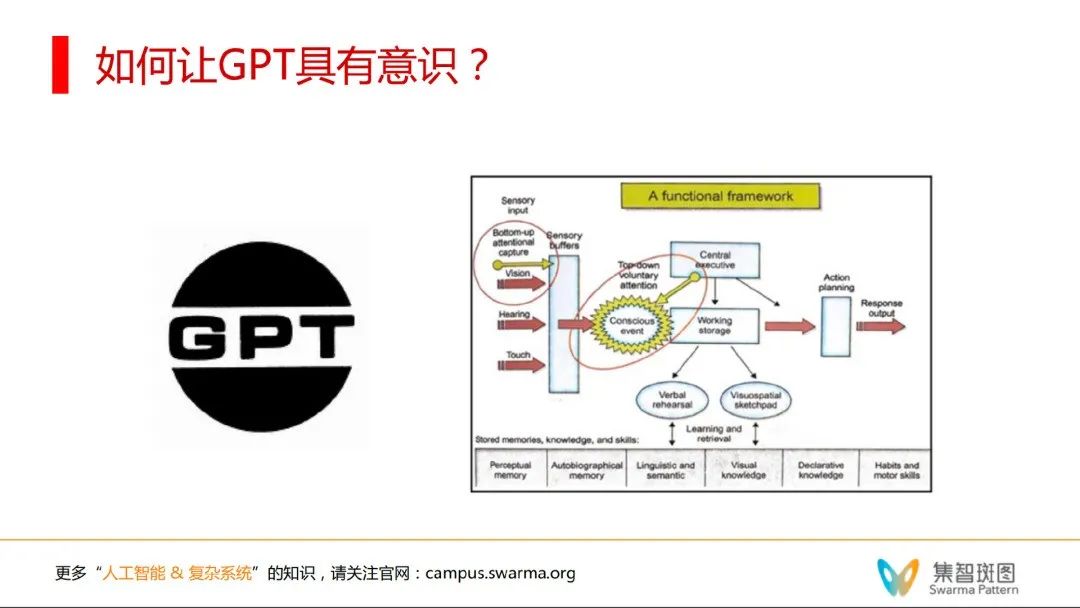
可以认为,意识图灵机就是把“全局工作空间理论”的架构给铺垫出来了,一堆小程序在底下可以做各种分布式任务,然后有一个全局空间。重点是,意识图灵机实现了一些信息上行和下行的机制。
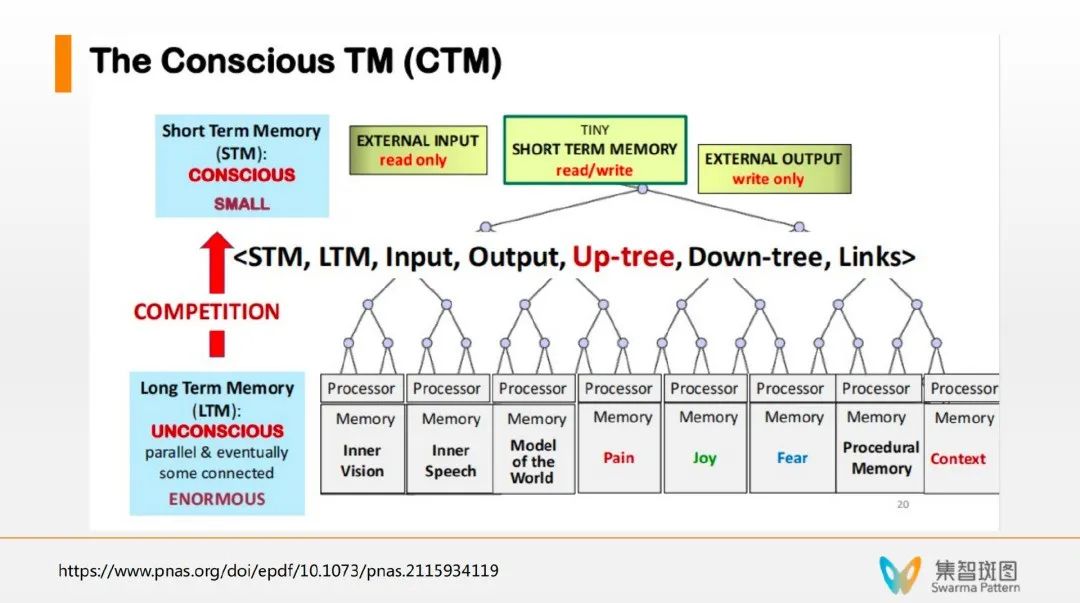
由上图可知,意识图灵机中的“上行”机制存在于它的一个 up-tree 的架构,使得下方的“小程序“可以用一种自竞争的方式在激活之后,形成一个适当地往上进入到意识过程。
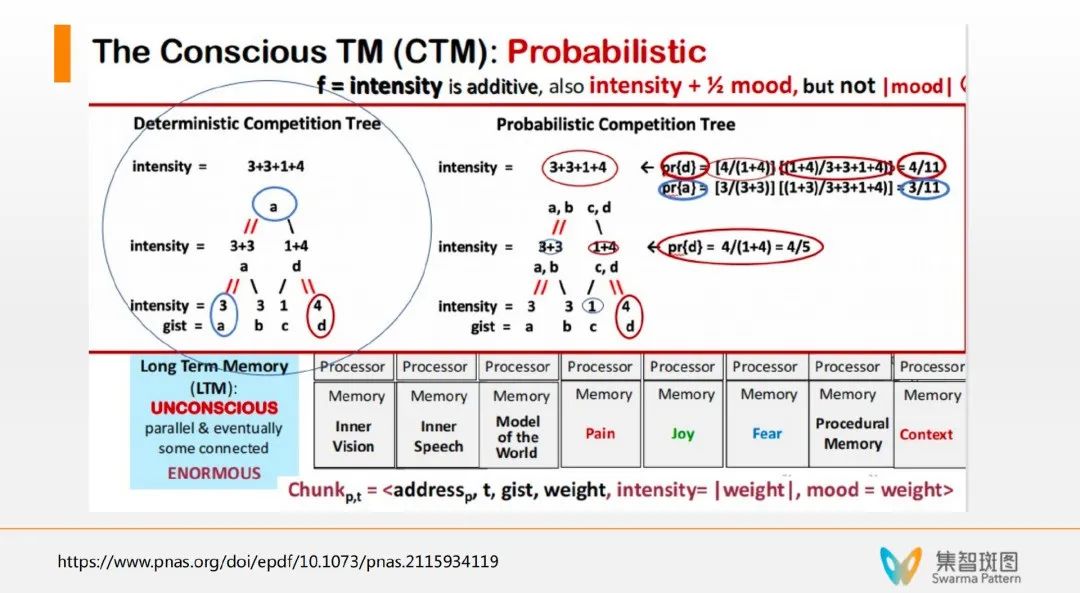
具体来讲,小程序都有一个强度数值,然后在上行的时候,系统就用一种强度求和并归一化的方式来模仿每一个小程序激活的概率,并通过随机采样来实现上行的激活机制。
一旦进入意识状态,全局工作空间就可以工作了——意识被激活了,于是开始下行 down-tree 机制,这种信息传递就是一种快速的广播,让信息广播到每个小程序,并检测可以处理信息的小程序。
这个架构非常像“遗传算法分类器系统”里的“白板机制”——很多小程序都竞争往白板上写,写的内容所有小程序都能看到,并争相激活。这个意识图灵机的机制和白板机制非常像。重要的是,这里还有个 learning 学习的过程。虽然所有程序都被激活了,但不是所有程序都能处理这些信息。一旦有些小程序能成功处理信息,比如有2个小程序一起成功处理了某个信息/某个任务,这个系统就会加强这2个小程序的连接。而且这个学习,是用 Hebb 学习率原理来学习的,而不是梯度反传——这点很重要。这样使得在未来再激活的时候,这2个小程序的地位就和其它小程序不一样了。
上面这个意识图灵机和全局空间理论很好地模拟了注意瞬脱的问题。但也遗留了一些问题。比如:规划、想象、自我意识、自由意志等。
世界模型
为了继续探索规划和想象这个方向,LSTM 之父,在2012年的时候,提出了一种叫做 World Models(世界模型)的强化学习框架。其认为强化学习主体,应该内嵌一个虚拟世界,即 world model。在研究中,他用大量的实验证明了,内嵌了虚拟世界的模型能在相对小样本的数据上更加充分地学习——因为 Agent 可以 dreaming。
世界模型相关论文
World Models
https://arxiv.org/abs/1803.10122
Dream to Control: Learning Behaviors by Latent Imagination
https://arxiv.org/abs/1912.01603
Mastering Diverse Domains through World Models
https://arxiv.org/abs/2301.04104
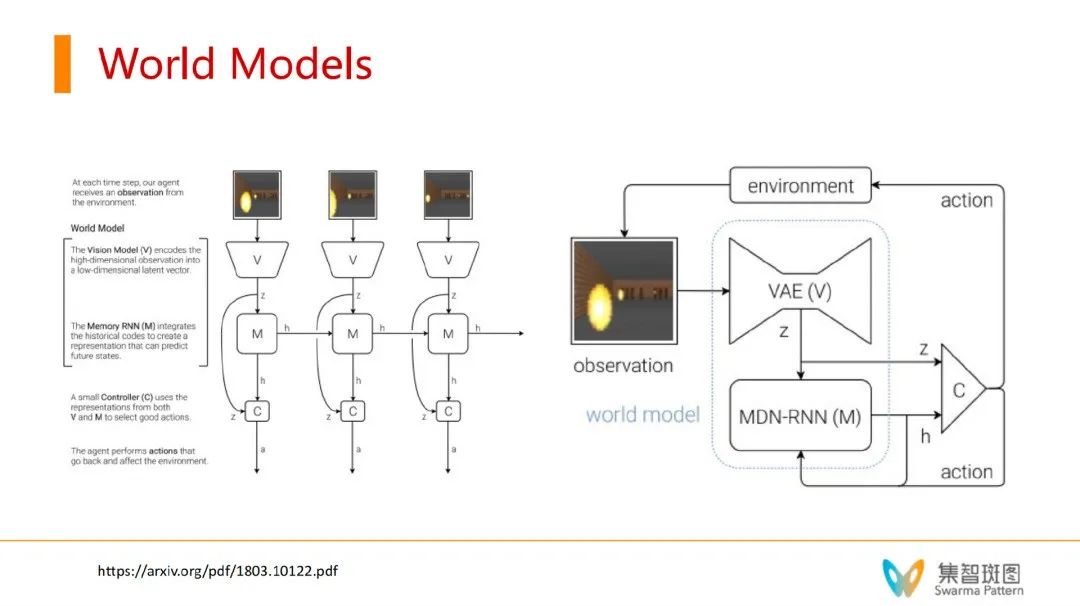
具体来看,世界模型就是一个 RNN,它的输入主要包括了两组元素,一组是被编码的世界状态,另一个是自身在 t-1 的行动,这个RNN的目的就是预测下一步的 state/reward/action。有了这样一个世界模型,强化学习 Agent 在学习的时候就能带来很多收益。一方面在训练的时候,我们可以刻意地去训练这个世界模型(监督学习机制)。另一方面,它可以 dreaming——而这就是为什么世界模型能在相对小样本的数据上更加充分地学习的原因。
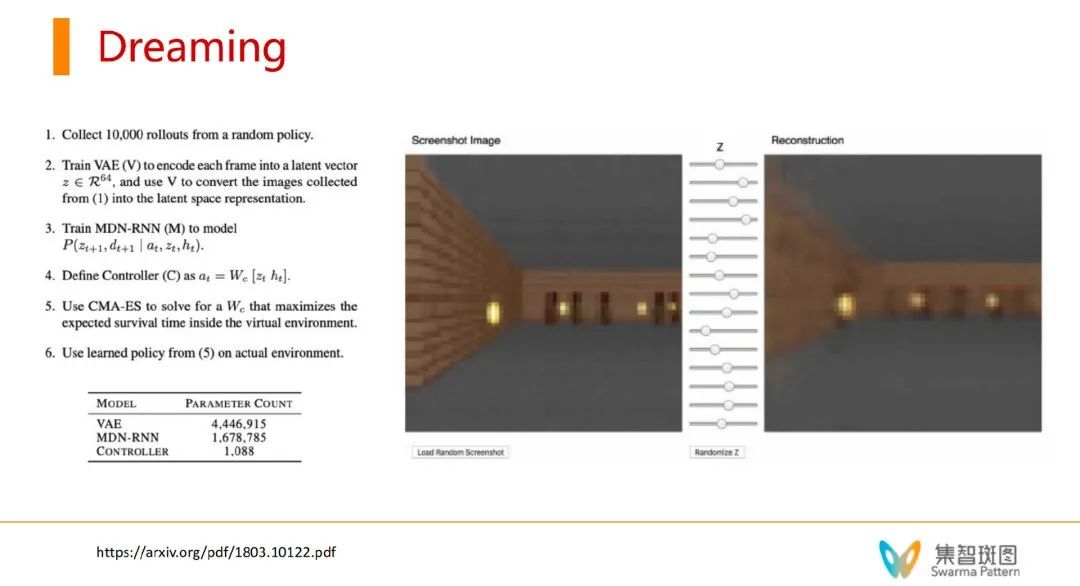
dreaming 的过程是,把不太完备的世界模型,单独拿出来做训练,通过一些假想的 action,即可以自己生成虚拟的 action。同时,从某个 t 时刻开始,让 world model 这个真实世界的模拟器,来生成下一个时刻的 action/state和reward,再拿这些 dreaming 的数据训练强化学习主体的执行部分。这样就可以在 dreaming 过程中优化目标函数,让 reward 达到最大。这样就大大增加了训练样本,减少了训练时间。同时,这里的 CMA-ES 是一个规划算法。从而可以用规划算法优化目标。即,有了世界模型就有了一个模拟器,Agent就可以设定一个未来目标,在模拟的World Model中找到实现这个目标的规划路径,从而产生一步步的action。
包括自我的世界模型
论文题目:
Separating the World and Ego Models for Self-Driving
论文链接:
https://arxiv.org/abs/2204.07184
然而,世界模型的系列工作虽然很好,但很重要的遗憾是——世界模型里依然没有自我(self)。虽然它可以把 action 重新喂给自己,但这只是一个行动,并不完全是“反思”——当我们在“意识”领域提及“反思”的时候,更多的时候,反思指的是一种心理状态。对比人类自身,我们人类建模的 world model 里是包括了 self 的,而现有的 world model 研究并不包含自身。另一个遗憾是,世界模型系列的 dreaming 做梦的过程,是非自主的。agent 会刻意地把“打游戏”和做梦之间做了区分,但人类是任意时刻都可以切换甚至同时做这两点。
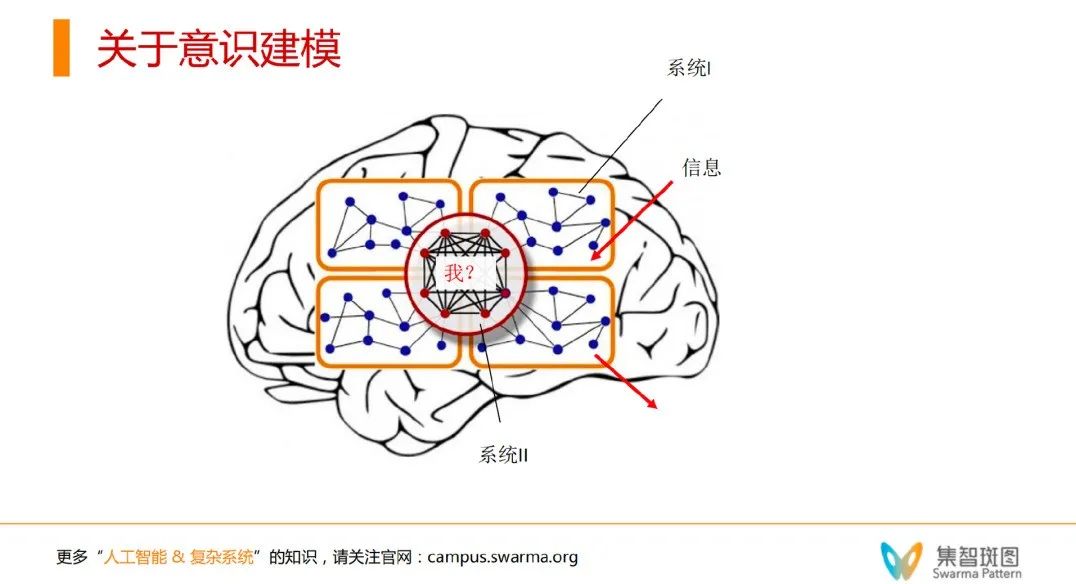
那么回顾刚才提到的这些意识理论和意识实现框架,我们不妨思考:一个真正理想化的意识建模是什么样呢?我们可以得出如下4个设想:
1. 意识建模至少要有系统1和系统2——这点和全局工作空间理论一样。
2. 更重要的是这个系统2,要有因果力。为了实现这点,系统2很可能是全连接的网络。
3. 同时,这个意识建模必须要像 world model 一样要能想象和执行规划。
4. 最最重要的就是要把 self 放进去。
自指与意识机器
有了一些意识建模的设想,我们不妨进一步深入讨论,是否有可能实现一个具备自我意识的机器呢?这个问题的答案很可能是有的,而且这种意识机器,很可能是自指意识机器。
这里出现了两个概念,一个是自我意识,一个是自指意识,区别是什么?自我意识是指具备对自我进行反思、推理、想象等思维活动的意识系统,比如我们人脑。而自指意识,是指通过我即将讲述的自指原理实现的具备自我反思、推理、想象等活动的意识系统。其中,后者会显然包含前者,因为后者通过自指技术实现的对自我的反思,是一种完美的映射,即通过特殊的技术实现的在空间和时间两个维度中的“完美”自我映射,而前者极有可能是不完美的自我映射。其次,后者可以被看作是自我意识的一个规范性理论,一个理论原型,而现实的自我意识系统则可能是一种不完美的实现。
要理解真实自我意识系统和理论上的自指意识系统的区别,我们不妨以冯·诺依曼的自复制自动机研究做一个类比。我们知道,在冯·诺伊曼提出自复制自动机后没几年,人们就发现了生命通过DNA进行自复制的工作原理,并同时发现生命基于 DNA 的自复制原理像极了冯·诺伊曼的自复制机器的原理,比如DNA就可以对应到冯·诺伊曼机器中的长长纸带,而蛋白质合成过程就对应了通用构造器(Universal Constructor)根据纸带构造机器的过程。但DNA合成蛋白质的过程很可能并不满足冯诺伊曼所说的通用构造性,即不见得所有的生命体都可以通过DNA构造出来(如RNA生命)。另外,细胞在复制的过程中也无法保持一模一样,但是冯诺伊曼的机器却可以。所以孕育了生命的 DNA-蛋白质系统并不一定是完美自指的,但很可能是一种非常接近完美自指的系统。
即便如此,我们依然认为讨论自指意识机器的实现对于我们理解“意识”,以及理解 GPT 是否具备意识是有帮助的。为什么会这样说呢?诚如开篇提到的,现在许多为大语言模型加上“反思”模块的工作,都还是有局限的。其局限性在于,这种方式实现的“反思”都是不完备“自我”的。因为所有的反思都不等于“我”,一定是有信息损失的。那么,有人可能会问,人类大脑里的 world model 就没有信息损失吗?当我们闭眼想象某个事物的时候,你会发现它很模糊,这个经验直接告诉我们人类大脑中的信息表征过程显然是有损失的,但这是对外界事物的表征过程。而张江老师认为,意识中的“自我”,即我对自我的表征,是一个没有信息损失的映射——这有可能可以基于我们对当下自我认知的这种自明性。所以,如果想实现一个更好的意识建模,我们就要建模无损的自我——这就让我们提出自指意识机器。
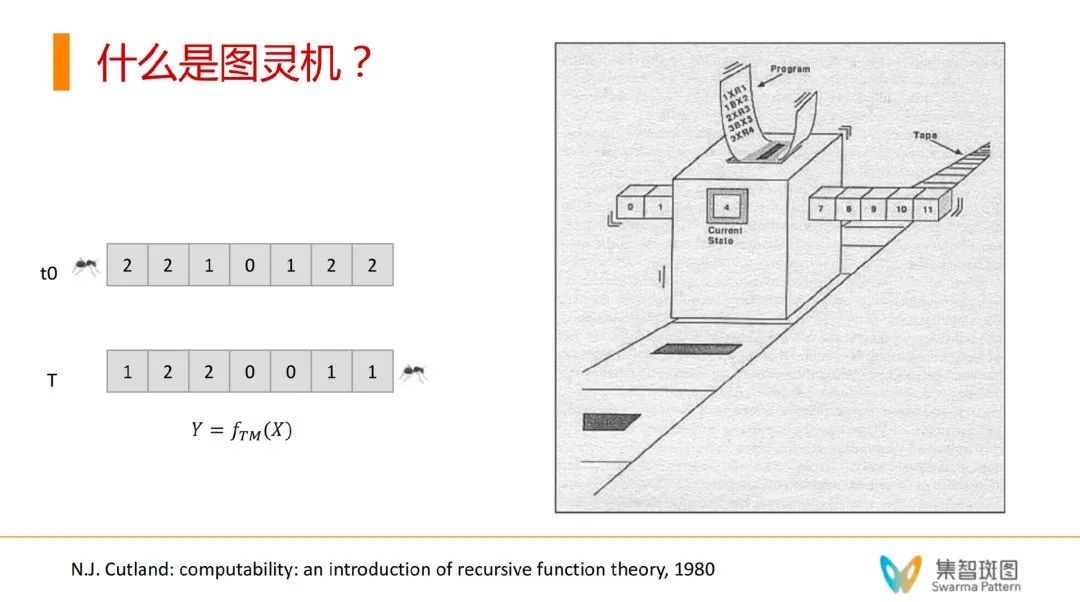
其实,在图灵机的发展阶段,就有了自指意识机器。自指的理论,是建造在“图灵机”上的。图灵机是一种理论上的计算机模型,其上有一条长长的纸带,可以认为是它的工作空间/记忆空间,也可以认为是它运作过程的工作/记忆存储装置。图灵机会根据自己的程序来一步步在纸带上工作,同时,所有给图灵的程序都是写死的。
图灵机可以做计算:在初始时刻,纸带有一串信息,t步之后,纸带读出的信息就是计算的结果。这样就有了一个 Y = f(X) 的映射,f就是一个可计算函数。所有能用数学做建模的系统,都可以用图灵机做模拟——这也就是图灵完备性。
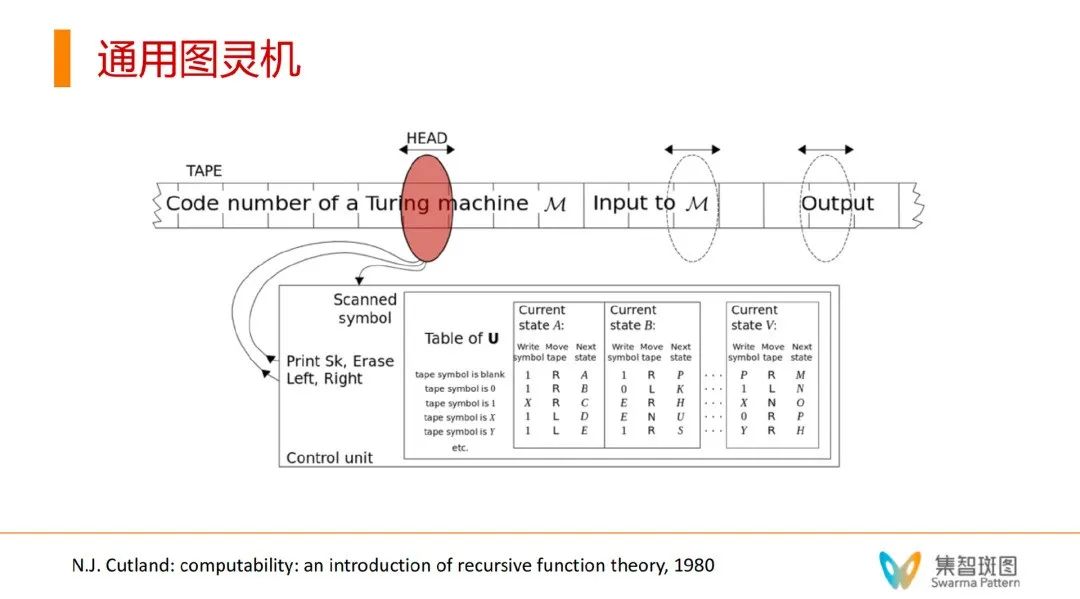
所有图灵机的家族有多大呢?其实,自然数的个数和所有的图灵机的个数(纸带无穷长,程序表也可以很长)是一样多的,是阿列夫数 ℵ。值得注意的是,在所有图灵机的集合里,有一个另类的点——通用图灵机(Universal Turing Machine,UTM)。它的特别之处在于,这个 UTM 可以在不改变自身程序的情况下,通过改变纸带的内容,来可以模拟图灵机集合中的所有图灵机,包括它自身——通用图灵机。通用图灵机能做到这点,使用的方式就是,把其它图灵机的程序写到 UTM 的纸带上——即把某个图灵机进行 encoding。这样有了源码和数据,UTM 就像编译器,就可以模拟这台图灵机了。
有了图灵机的概念,就可以了解自指了。“自指”是一个规范理论,可以定义“自我”,可以分辨(tell)一个“他物”是否有自我。能实现这一点的原因在于,“自指”技术可以构造出一个数学上的不动点,使得它能在一步迭代过程中无损地得到新“我”。关于自指,这里推荐有兴趣的读者去阅读《哥德尔、埃舍尔、巴赫——集异璧之大成》这本经典之作,另外还给大家推荐一本相对专业,同时又没那么晦涩难懂的书《Computability》这本书,既深入又易懂,入门级著作。

N.J. Cutland: computability: an introduction of recursive function theory, 1980
历史上,人们曾根据自指构造出罗素悖论和哥德尔定理中的关键命题,并引发了第三次数学危机。
而冯·诺依曼设计的这台自复制机器,却让自指具备了“建构”能自复制的生命的本领。后来的人,在现代的计算机里,实现了这个冯·诺依曼设计的机器。通过这个视频,你可以看到一个完整的机器自复制的过程,先复制纸带的内容,再开始构造机器。
John von Neumann: Theory of Self-reproducing Automata, 1965
自指本身是一种语言中的现象,但后来数学家们把它变成了一种数学或编程的技巧。这里的关键,就是如何绕开无穷的递归,而实现完美的自指。原本,我们想实现一个如下图的“自打印”程序,即自己打印自己源代码的程序,是不可能的。因为这里面存在着无穷递归。

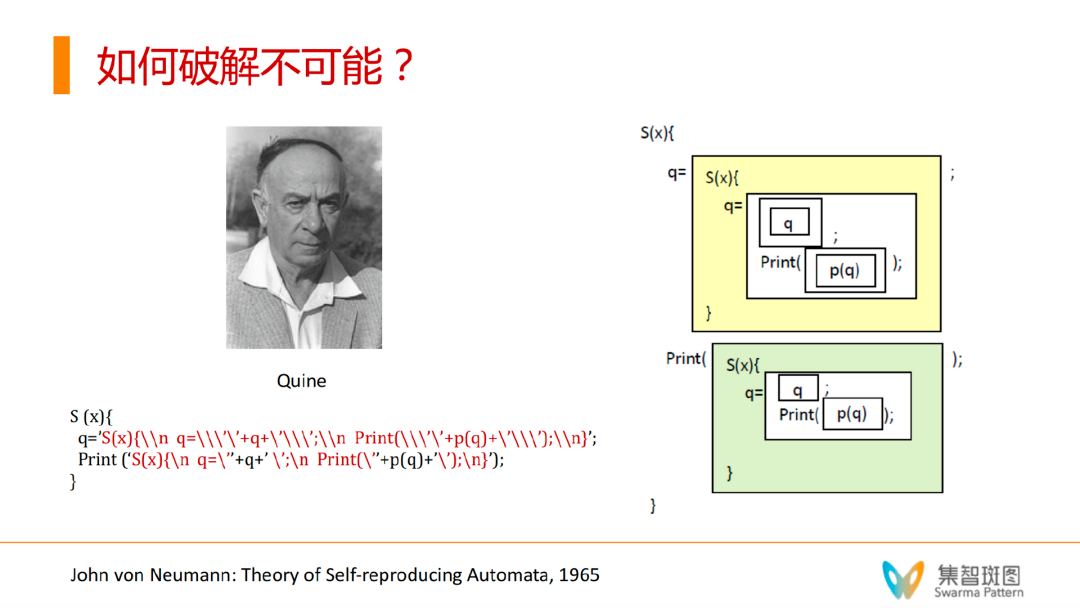
但后来数学家们借鉴了哲学家Quine的想法,巧妙地破解了这种不可能性。
破解的奥秘就在于,我们不能静态地写一个自打印程序,而必须通过在一个外部环境(通常就是操作系统)中执行程序,在过程中展开这个程序,然后当你比较它打印出来的东西和它自己的源代码的时候,你会发现它们是一模一样的。
那么,要实现这种自打印程序,需要什么样的逻辑结构呢?我们可以参考右侧的图,它展示了 Quine 程序的逻辑结构。第一部分,相当于做了一个“虚拟部分的相”(黄框),另一部分则是实相(绿框)。最重要的 ,通过观察我们可以看到,这里的虚相和实相几乎是相同的,就像一个程序照镜子一样。
顺便提一下,这一点也是前面提到的通过“功能结构”或“软件”来区分意识/非意识的关键所在——你只要在系统的功能层面区分出虚拟的相和真实的体,便能够判断自我意识/非意识。
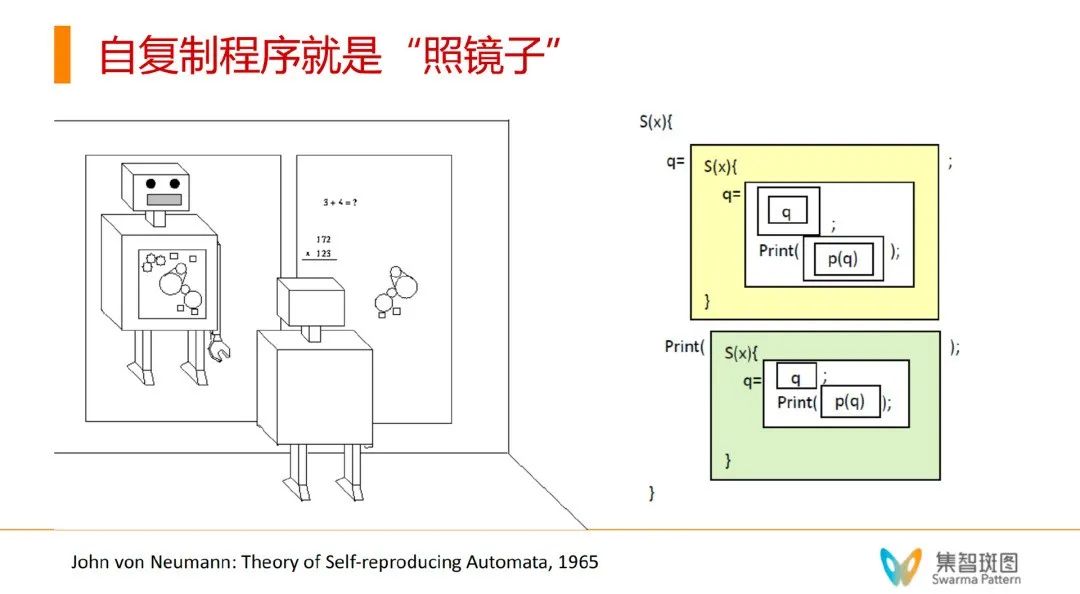
那么,冯·诺伊曼构造的自复制自动机,也是遵循类似的原理的,实现自复制的关键就是——在时间上展开。
以下面的例子为说明,要想从时间展开的角度实现自复制,第一步,我们需要先把图纸复制一份(就像复印机所做的一样)。第二步,我们需要借助一种通用构造器,使得原始的机器在图纸上进行加工操作,构造出一台新的机器。再次强调一下,想要实现自复制,有两个关键点:
1. 有一个执行环境:U
2. 在时间中完成展开
有了 Quine 的技巧后,我们还能做出一大类和自我有关系的程序——甚至可以认为 Quine 就是“自我”的遗传编码。
第二递归定理
为了实现自指意识机器,不可忽视的还有 Kleene 早在30年代就提出的一个定理——Kleene 第二递归定理。

Kleene 第二递归定理,即,对于任意可计算的功能f(比如打印字符串),总能找到一个特殊的源代码/程序n,执行这个程序的代码,就等价于拿着它自己的源代码执行 f 这个操作(即打印出自己的源代码)。要想理解 Kleene 第二递归定理,可以把大φ 认为是操作系统或编译器,下标n就是源代码。源代码要根据 f 构造出来。这里的关键是f可以是任意的可计算函数,所以不仅仅是打印,什么构造、思考、模拟、推理,甚至强化学习等等,都是可以的。
根据这个定理,我们可以推出:只要“修正”、“提高”、“解释”、“反省”等过程是图灵可计算的,那么根据这个定理,总能找到这个特殊的源代码,和这些特殊的源代码f耦合在一起,就能构造出“修正自我”、“提高自我”、“解释自我”的程序——执行以后的效果等价于拿着自己的源代码执行f这个操作。
这个定理是极其让人兴奋的。因为如果我们能获得自己的源代码,从某种程度上我们就是“神”了——因为这样就可以基于源代码完成自更新(自修改源代码)——而第二递归定理告诉我们,这种程序是存在的!

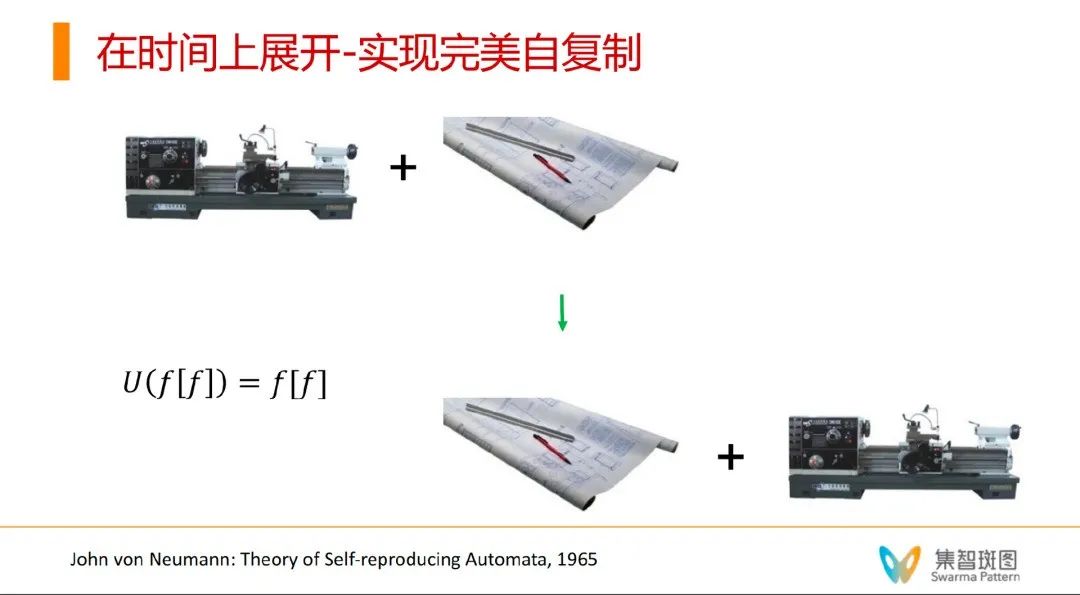
不仅如此,第二递归定理还有更深层次的寓意。让我们回忆一下冯·诺依曼的理论——他不仅是一个伟大的数学家,也是一个伟大的复杂科学理论先驱。他的著作 “Theory of Self-Reproducing Automata” 对于复杂性和生命的重要问题曾有过许多讨论。冯·诺依曼提出,所有已知的复杂系统,存在一个明确的分水岭,分水岭的左边,大部分是人造系统,比如当时的计算机、汽车、厂房等等;分水岭的右边,大部分是诸如人的大脑、细胞、生命、生态系统等大自然形成的系统。在分水岭左边的系统,随着时间的变化会不断降级,比如我们需要经常保养汽车,否则就会出各种问题;与此相反,在分水岭右边的系统,不仅不会随着时间的变化而降级,反倒能够不断进化,特别站在生态系统角度看,其中的物种能生生不息,并且似乎变得越来越高级。
简单来说,冯·诺依曼告诉我们,自然系统之所以可以不断升级,就是因为达尔文式的进化——即基因突变,得到新的生命个体——有可能比原始生命个体更优——不断持续下去——就有可能产生一个类“熵减”的过程——形成秩序的增加。而有了第二递归定理后,我们就可以实现这件事了!
如何实现呢?只要在自复制的过程中,去干扰图纸/源代码,即对图纸做一个变异——让源代码上附加一个新的东西——得到一个新的图纸(把下图中的大小两个图纸合在一起)。然后,让通用构造器在构造过程中,用新的图纸——相当于实现了一定意义上的自我修改——也就得到了一个新的物种——可以进一步迭代。
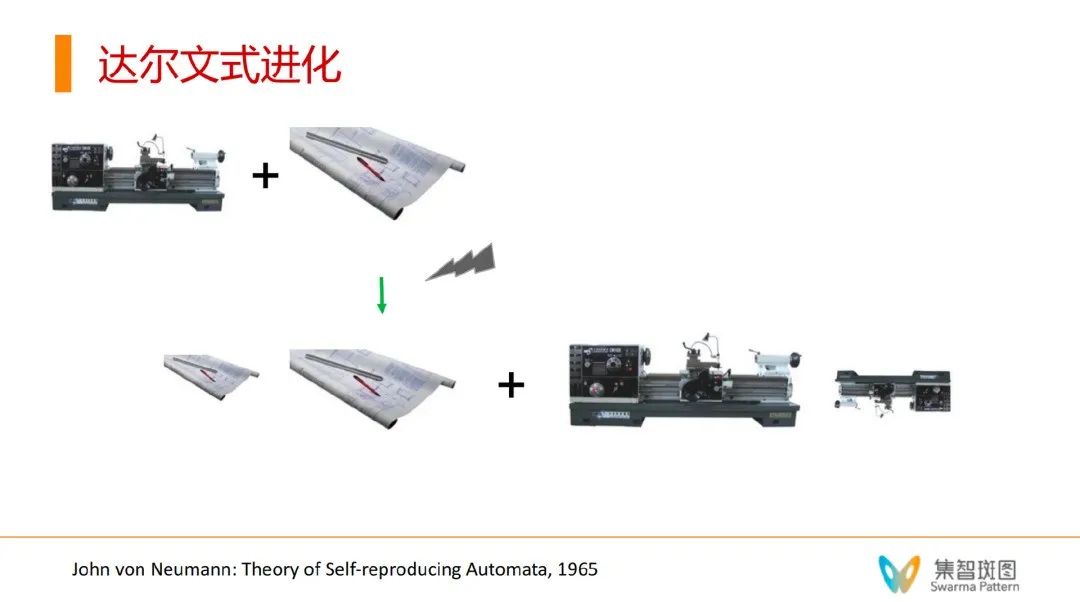
这一定理配合冯·诺依曼对于复杂系统的理解有着很深的隐喻。冯·诺依曼判断,在复杂系统中存在一个复杂度阈值,如果系统的复杂度没有超过阈值,那么系统便会在热力学第二定律的作用下不断降级,以至于最后瓦解,相反,一旦超过这一阈值,系统便仿佛能够超越热力学第二定律,得以不断升级并进化。那么,这个阈值是什么?就是自复制!在自复制机器出现之前,所有形成的生命都是不断降级的过程——只有跨过这一点——才能形成不断进化的生物——所以,复杂的阈值与 Kleene 第二定律是非常相关的。对此部分内容感兴趣的读者可以进一步阅读《让 ChatGPT 拥有意识,冯·诺依曼会怎么做?——自指机器的奥秘》。
自我反省机器
Kleene 第二定律引发的思考有几点很重要:
1. 相当一部分研究自我意识的人都认为不可能实现完美自省——但机器可以实现完备的自指,也就可以实现完备的自省——只要通过 Quine 的技巧和第二递归定律(在证明第二递归定理的证明过程中,本质上也用到了Quine)。Quine 操作就有点像“机器自我说话”——说出来的话也是自身。都是通过时间展开得到的。
2. 机器和描述都不是完备的。但把它们合在一起的时候,把它们交给 OS/自然,靠自然的运作,t->t+1,就能实现完备的自指了。这个过程中,一定要做到虚拟和真实的尽可能相似,同时要让它们二者配合在一起运作,虽然它们两者都有一些缺陷,但最后让自然运作去弥合二者,这才能实现自复制。
3. 机器和描述互为镜像——这和分形也有关系,比如冯·诺依曼的自打印结构。
第二点的含义还可以引申到人类追求宇宙真理的过程。人类靠意识能否完美认知宇宙真理?这有可能是不可能的,因为所谓的认知真理,其实就是在用我们人脑来装下宇宙万象,而宇宙包含了我,而我无法装下我,这存在着无穷递归。而有了自指技术,其实人并不需要完美认知宇宙,认知到一定程度就可以了,然后人只要把自己的认知结果——有可能就是一个人工智能机器,与人合在一起形成一个整体,然后,把剩下的留给自然——谋事在人,成事在天,于是人-机构成的整体就能完美地模拟宇宙运转了。

有了这些理论后,就不难理解自指意识了。在《Computatbility》这本书里就讨论了“自我反省机器“,self introspection 的可能性。通过第二递归定律,我们就可以构造出来这种机器。值得注意的是,这个自我反省机器必须得有一个参数 t,即运作t步,这样图灵机才能可停机——才能实现可计算的函数,才能使用 Quine。

同时,自我反省机器也是一个自我模拟的程序。因为 U 是一个通用模拟器,也很容易构造出自我修改程序。这个 V 就是在一定条件下修改另一个程序的源代码。

虽然我们从更好的意识建模延伸到了自指意识机器、自我反省机器的构建,但之前这些讨论都是有缺陷的——因为自我反省机器要执行 t 步(模拟 t 步),但 t 和 U 的执行步数 T 不同,即这个自我反省机器并不是实时的机器。虽然我们实现了自我反省机器,但这里的实现只考虑了功能的等价,不考虑中间步骤的等价。
可我们都知道,意识是实时的,所以有可能构造一个实时的等价自我机器吗?这是有可能的,因为操作系统是一个实时系统。配合 Quine 技巧,有可能构造出实时自模拟的程序。
当然,通过自指实现的自我意识,也存在一定的问题:

异步自省模型
刚才也提到了,也许完美的自指自模拟模型并不一定是自然所必须的。我们是否还有其它途径去简化自省机器呢?

这里,张江老师分享了《机器意识》这本书,是厦门大学周昌乐老师写的。周老师做了很多意识机器的研究。其中,周老师有个“异步自省模型”(Asynchronous Introspection Theory)。如下图,大盒子可以看作是人脑,人脑里有个小机器人R,可以理解为R就是注意力,这个注意力可以关注若干个东西(小机器人的面前有3块屏幕)。每个屏幕背后连接着不同的东西,比如M2连接语音,M1连接摄像头。其中,最特殊的一块屏幕是M0,M0连接的是C0摄像头——而C0在拍摄整个R观察各个屏幕的画面。这个M0很关键,就相当于是一个反省的过程。
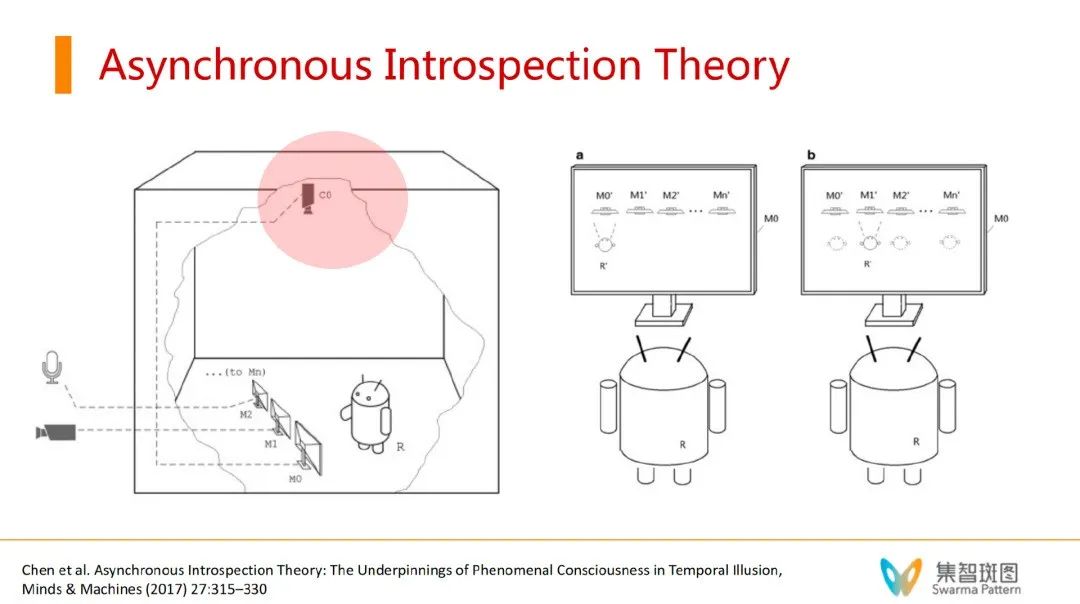
论文题目:
Asynchronous Introspection Theory: The Underpinnings of Phenomenal Consciousness in Temporal Illusion
论文链接:
https://link.springer.com/article/10.1007/s11023-016-9409-y
这个理论的有趣之处在于,它提出了”异步性“这个概念。假设这个R,每一时刻只能关注到一个屏幕——这是非常关键的假设。即,小机器人R看M1屏幕的时候,看不见M0屏幕,每一时刻只能关注到一个东西。当这个系统在两个屏幕之间切换的过程还有一定的延迟性时,机器人R就可能看到“自己”,从而产生对自我的认知。
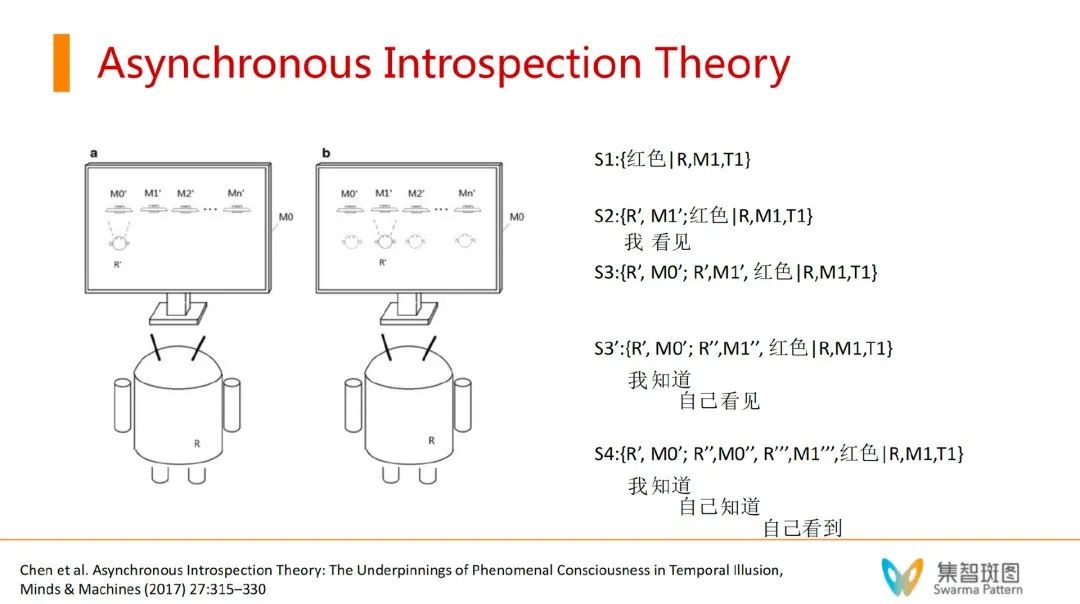
周老师他们描述了一个过程。如上图,小机器人的每一个时刻观测记为一个记忆体。
S1记忆体:比如在 T1 时刻,小机器人“我”通过 M1 看到了红色 S2记忆体:T2时刻,小机器人切换到了M0屏幕,由于M0=C0+机器人自己,且有一定延迟,这个T2时刻,猛一下转到了M0屏幕,就会看到T1时刻的自己(延迟画面)。就会看到了自己的”相“,即,R的相R'在观看M1的相M1'。S3记忆体:T3时刻,没有切换屏幕,继续盯着M0看,这时候看到了T2时刻的自己,即,自己在盯着M0屏幕看——且是一个二阶表征,R',M0', R'', M1''。虚拟世界中的虚拟世界。S4记忆体:这个过程如果始终盯着M0看到,就会产生一连串高阶感知。
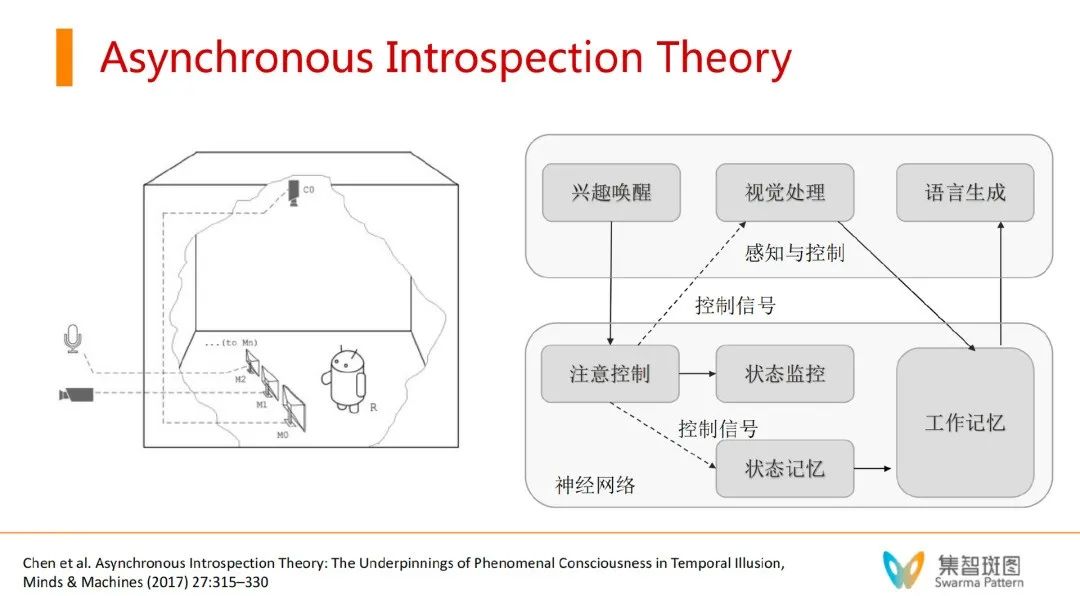
遗憾的是,在周老师的这个理论框架里,机器人R是由系统外部的一个人控制的(控制何时换屏幕)。使得这个系统依然不是完全自主的。那么,有没有可能改变这一切呢?让R自主决定呢?张江老师提出了一个改进的办法:异步自省模型+world model,并用注意力来实现 dynamic attention。
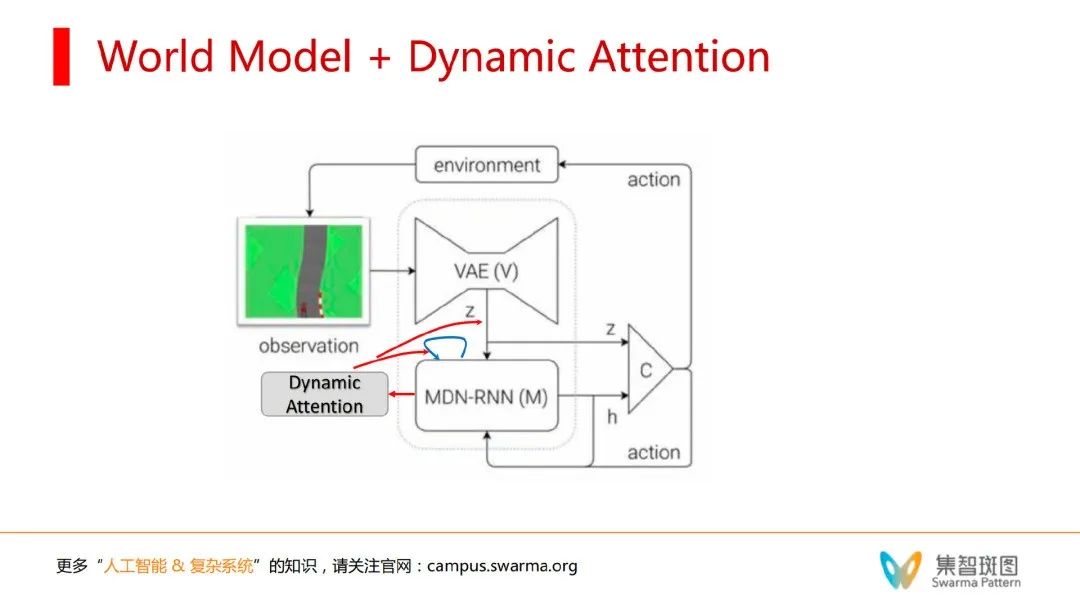
有了动态注意力,每一次迭代就实现了对自我的模拟。注意力机制可以分配注意力到 z(外部世界输入的内容),或者到自我身上。这2者之间有了一个 trade-off。这就可以模拟意识的相关机制。当把注意力放在自我的身上,就是在我自我意识的自我反省了。
自由意志
文章写到这里,再多说一些大家都感兴趣的话题,比如自由意志。在自指框架下,自由意志的问题就很有趣。而这也和因果涌现有关。
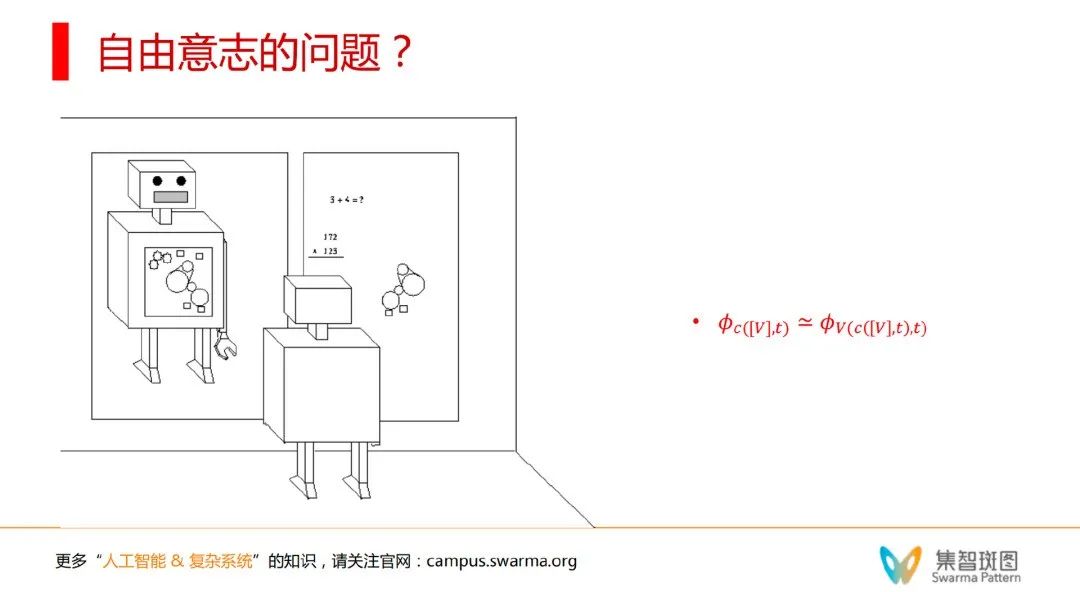
如上图,当我们照镜子的时候,镜子里的相是因?还是镜子外的我是因?假设镜子里的相是想象的,就有可能做出超过镜子外的我的行动(因为我们可以想象未来)。那么系统2的虚相就有可能指导系统1的大脑、身体来运作——就有了一个从内而外的因果箭头。但这个箭头也是虚假的,因为 Quine 自模拟。这时其实是分不清孰因孰果。
在电影《黑客帝国》(The Matrix)里,有一个经典镜头便表现了这种因果关系:
ORACLE: I'd ask you to sit down, but you're not going to anyway. And don't worry about the vase.
先知:我就不请你坐了,反正你也不会坐。你别担心那花瓶。
NEO: What vase?
尼奥:什么花瓶?
He turns to look around and his elbow knocks a VASE from the table. It breaks against the linoleum floor.
他一转身,碰倒桌上的花瓶,掉地上碎了。
ORACLE: That vase.
先知:就那花瓶。
Neo: Shit, I'm sorry.
尼奥:见鬼!对不起。
She pulls out a tray of chocolate chip cookies and turns. She is an older woman, wearing big oven mitts, comfortable slacks and a print blouse. She looks like someone's grandma.
她取出饼干,转过身来。穿着、样子、动静,看上去就像一位邻家奶奶。
ORACLE: I said don't worry about it. I'll get one of my kids to fix it.
先知:我说没关系,我会叫那些孩子来还原它的。
Neo: How did you know...?
尼奥:你怎么知道会……?
She sets the cookie tray on a wooden hot pad.
她将饼干放一木盘上。
ORACLE: What's really going to bake your noodle later on is, would you still have broken it if I hadn't said anything.
先知:让你觉得更困惑的是,我不说,你还会不会打破那花瓶。
正常情况下,因果序列表现为,先知对Neo说,不用担心花瓶,Neo听见后便转身,结果打碎了花瓶。不过,这里面存在一条奇妙的因果箭头:实际上,Neo头脑中还存在一个想象世界, 当先知与Neo说完话后,Neo便想象到花瓶碎掉的场景,或者说是一种预期,对未来的预期显然还未发生,正是这一预期使得Neo转身,花瓶便被Neo打碎,于是,预期便得以自我实现(Self-fulfilling Prophecy)。似乎,这里面存在一种从未来指向现在的因果箭头,当然,在这个例子中,这是因为人脑存在一个想象世界,不过,这种现象会在很多存在生命的个体中发生,比如虫子会在自己的控制下爬向食物,这里面,正是未来的预期,或者说目的,驱使了虫子的行动。
在自指程序下,只要能做到内外一致,就可以做到因果箭头的”颠倒“——实现自由意志。
好了,关于意识的现象和理论部分我们就全部介绍完了,下面,还可以延展讨论几个问题:
如何让ChatGPT具有意识?
要回答这个问题,首先就要回答:如果不做任何改进,现有的 ChatGPT 等大语言模型具有意识吗?我们可以从3个层面来评估这个问题。
1. 宏观层面——行为层面。许多意识相关的理论及证据都已经表明,从行为层面判断是否具有意识是很不可靠的——例如ChatGPT不可能照镜子,就无法通过是否能识别出镜子里的自己而判断是否有意识。
2. 微观层面——物理层面。比如,大语言模型在运行的过程中,其神经网络内部是否有大尺度的全联通网络激活——尤其在执行复杂任务上,是否存在系统2的工作痕迹。这一点,似乎是可以被验证的。
3. 功能层面——及 GPT 里面有没有虚拟层呢?假设有,这些虚拟层在映照自我吗?如何映照自我的呢?至少要区分虚拟层和真实层,然后还要区分出这两者之间复杂的编码关系。
那么,如果 ChatGPT 等大语言模型还没有意识。如何让它具有意识?至少从本文中提到的许多理论和思考可以看到,未来值得做的至少有两个方向:
1. 让 GPT 等 LM 和全局工作空间(意识图灵机)发生耦合。通过系统2,让它做更复杂的任务。
2. 世界模型+动态注意力。让GPT替代世界模型(有整个互联网的知识),可以把 GPT 当成世界模拟器。那么再加上对自我的感知,就可能出现自我修正等功能。
“自我”就是“意识”皇冠上的明珠。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


