
- 1AIGC时代之 - 怎样更好的利用AI助手 - 指令工程
- 2mysql-connector-java和spring-boot-starter-jdbc和mybatis-spring-boot-start
- 3常用的损失函数_lstm损失函数
- 4顺序表的基本操作(完整代码)_顺序表基本操作的实现代码
- 5Git从零开始最详细操作手册_git操作手册
- 6实践数据湖iceberg 第二十六课 checkpoint设置方法_execution.checkpointing.interval
- 7【论文精读】Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement_retinexformer: one-stage retinex-basedtransformer
- 8浏览器工作原理与实践--HTTPS:浏览器如何验证数字证书
- 9文本摘要任务常用数据集介绍
- 10cdh+mysql没创建表_按照CDH时创建 Hive Metastore 数据库表失败。
YOLOV7学习记录之训练过程_yolov7的辅助头训练和生负样本匹配策略
赞
踩
在前面学习YOLOV7的过程中,我们已经学习了其网络结构,然而实际上YOLOV7项目的难点并不在于其网络模型而是在于其损失函数的设计,即如何才能训练出来合适的bbox。
神经网络模型都有训练和测试(推理)过程,在YOLOV7的训练过程中,包含模型构造,标签分配和损失函数计算。其中模型在前面以及讲过了。在测试过程中包含加载模型,损失函数计算,输出值解码,非极大值抑制,MAP计算等,今天我们先讲一下YOLOV7的训练过程。
在训练过程中主要用到这几个文件:

YOLOV7训练过程中的一个重要思想便是正样本匹配策略,其更像是YOLOV5与YOLOX的一个结合体,那么接下来我们结合代码看一下其匹配策略:
YOLOV5,V7正负样本分配策略
yolov5,v7与yolov3、yolov4最大的不同就是v3与v4一个gt只会与一个正样本匹配,而v5,v7一个 gt 可以被分配给多个anchor,还有可能被分配到三个不同的特征图中的两个甚至三个。
匹配策略:这里指的是不带辅助头,论文中,将负责最终输出的Head为lead Head,将用于辅助训练的Head称为auxiliary Head。本博客不重点讨论,原因是论文中后面的结构实验实现提升比较有限(0.3个点)
主要是参考了YOLOV5 和YOLOV6使用的当下比较火的simOTA.
S1.训练前,会基于训练集中gt框,通过k-means聚类算法,先验获得9个从小到大排列的anchor框。(可选)
S2.将每个gt与9个anchor匹配:Yolov5为分别计算它与9种anchor的宽与宽的比值(较大的宽除以较小的宽,比值大于1,下面的高同样操作)、高与高的比值,在宽比值、高比值这2个比值中,取最大的一个比值,若这个比值小于设定的比值阈值,这个anchor的预测框就被称为正样本。一个gt可能与几个anchor均能匹配上(此时最大9个)。所以一个gt可能在不同的网络层上做预测训练,大大增加了正样本的数量,当然也会出现gt与所有anchor都匹配不上的情况,这样gt就会被当成背景,不参与训练,说明anchor框尺寸设计的不好。
S3.扩充正样本。根据gt框的中心位置,将最近的2个邻域网格也作为预测网格,也即一个groundtruth框可以由3个网格来预测;可以发现粗略估计正样本数相比前yolo系列,增加了三倍(此时最大27个匹配)。图下图浅黄色区域,其中实线是YOLO的真实网格,虚线是将一个网格四等分,如这个例子中,GT的中心在右下虚线网格,则扩充右和下真实网格也作为正样本。
S4.获取与当前gt有top10最大iou的prediction结果。将这top10 (5-15之间均可,并不敏感)iou进行sum,就为当前gt的k。k最小取1。
S5.根据损失函数计算每个GT和候选anchor损失(前期会加大分类损失权重,后面减低分类损失权重,如1:5->1:3),并保留损失最小的前K个。
S6.去掉同一个anchor被分配到多个GT的情况。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
正负样本分配
正负样本分配的函数build_targets(yolo_training.py),将其分为以下结构:
├── 数据准备
└── 遍历每个特征图
├── ①anchors和gt匹配,看哪些gt是当前特征图的正样本(find_3_positive)初筛
└── ②将当前特征图的正样本分配给对应的grid(完成复筛:iou,类别)
- 1
- 2
- 3
- 4
步骤1:anchors和gt匹配,看哪些gt是当前特征图的正样本**(find_3_positive)**
这里要做的是从gt的上下左右分别偏移0.5来获取周边的单元格来进行预测,通过计算anchor的长宽比例是否合适(比例位于1/4与4之间)则认为符合,那么当前gt就能与当前特征图匹配。
如图所示:这是lead head的正样本匹配策略
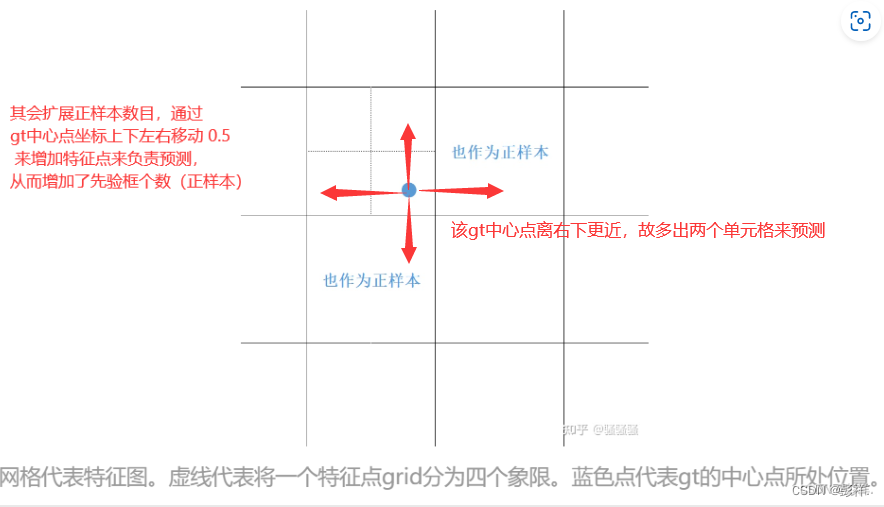
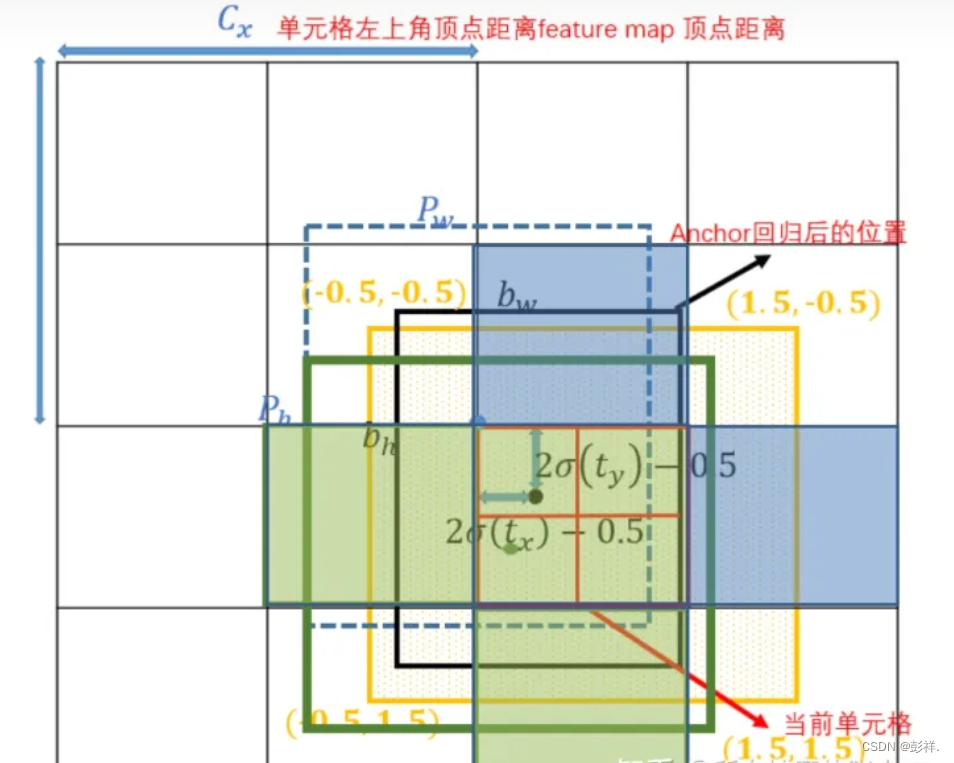
YOLOV7中引入了辅助头,其正样本为:
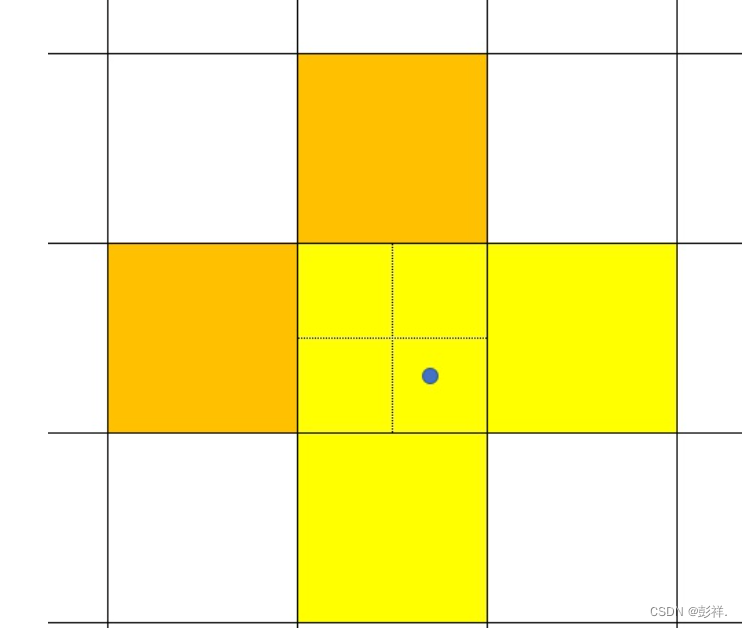
如图:训练时,lead head和aux head中正样本分配图示(蓝色点代表着gt所处的位置,实线组成的网格代表着特征图grid,虚线代表着一个grid分成了4个象限以进行正负样本分配。如果一个gt位于蓝点位置,那么在lead head中,黄色grid将成为正样本。在aux head中,黄色+橙色grid将成为正样本)
初筛(find_3_positive)
设置偏移方向与偏移大小
g = 0.5 # offsets 漂移的距离,为获取更多正样本
off = torch.tensor([#漂移方向
[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g
- 1
- 2
- 3
- 4
- 5
- 6
在yolov5,v7中,会将一个特征点分为四个象限,针对步骤1中匹配的gt,会计算该gt(上图中蓝色点)处于四个象限中的哪一个,并将邻近的两个特征点也作为正样本。以上图举例,若gt偏向于右下角的象限,就会将gt所在grid的右边、下边特征点也作为正样本。
# 分别对应中心点、左、上、右、下
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
], device=targets.device).float() * g
# gain = [1, 1, 特征图w, 特征图_h, 特征图w, 特征图_h]
gxy = t[:, 2:4] # 以特征图左上角为原点,gt的xy坐标
gxi = gain[[2, 3]] - gxy # 以特征图左上角为原点,gt的xy坐标
# jklm就分别代表左、上、右、下是否能作为正样本。g=0.5
# j和l, k和m是互斥的,(x,y)%1会得到两个值所以其最终可以组成四个方位
j, k = ((gxy % 1 < g) & (gxy > 1)).T
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))#组成五维
# 原本一个gt只会存储一份,现在复制成3份 拼接函数
t = t.repeat((5, 1, 1))[j]
# 偏移量
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
关于上面的代码语法上理解如下
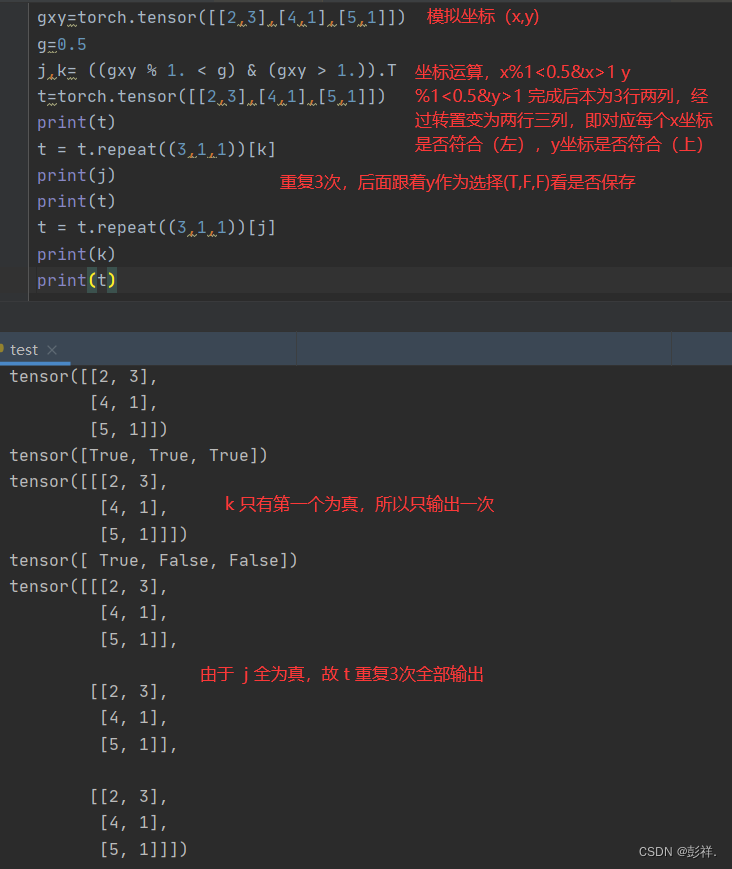
这里可以看出V5和V7是很类似的,相比较yolov3和v4一个gt只会匹配一个正样本的方式,该种方法能够分配更多的正样本,有助于训练加速,正负样本平衡。
完成增加正样本后(找到了t个先验框(正样本),我们需要判断这些框是属于哪张图片,其属于哪个类别,负责该样本预测的单元格的左上坐标为多少,以及该坐标的w,h的缩放比例
# -------------------------------------------#
# b 代表属于第几个图片,即每个t属于的图片
# gxy 代表该真实框所处的x、y中心坐标
# gwh 代表该真实框的wh坐标
# gij 代表真实框所属的特征点坐标
# -------------------------------------------#
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()#.long是取值,不要小数部分,如gxy(2.3,2.2)左移-0.5则为(1.8,2.2)取值(1,2)即由(1,2)的anchor来进行匹配,获得偏移后负责预测的单元格
gi, gj = gij.T # grid xy indices
# -------------------------------------------#
# gj、gi不能超出特征层范围
# a代表属于该特征点的第几个先验框
# -------------------------------------------#
a = t[:, 6].long() # anchor indices
indices.append(
(b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid indices
anchors.append(anchors_i[a]) # anchors比例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
而且由于每一个特征图中,都会将所有的gt与当前特征图的anchor计算能否分配正样本,也就说明一个gt可能会在多个特征图中都分配到正样本。
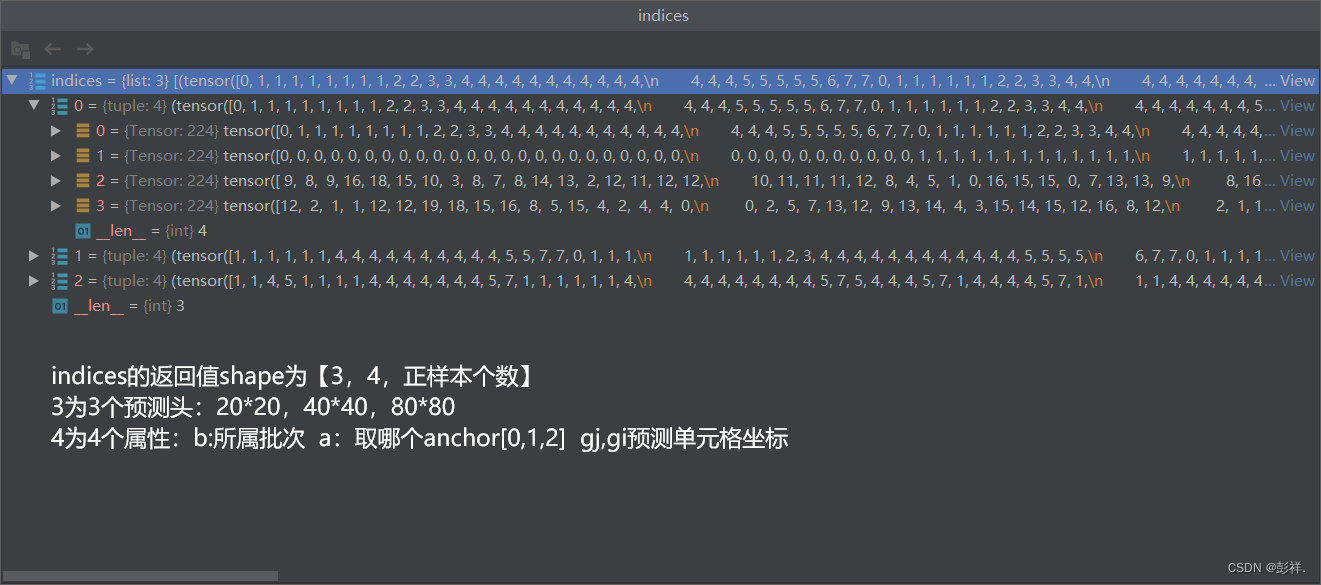
find_3_positive的返回结果为:
indices 的shape为:【3,4,正样本个数】
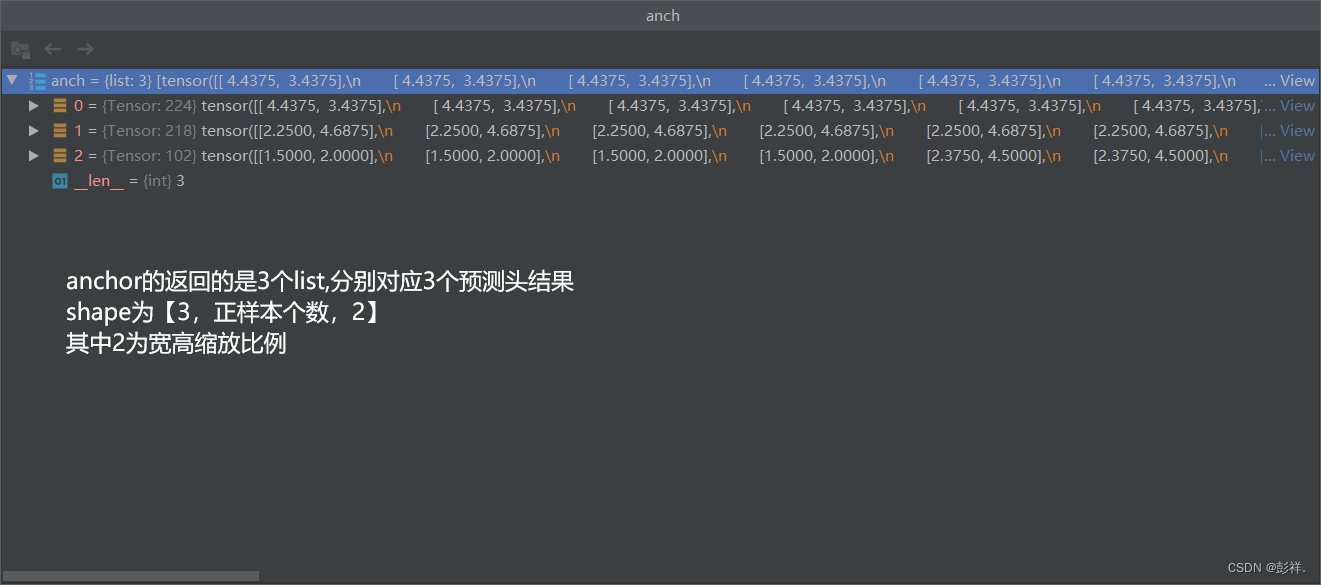
anchor的shape为:
复筛get_target()
至此,我们便完成了正样本的匹配即初筛工作,紧接着我们要对初筛得到的先验框进行复筛,此时便是要根据predictions的预测先验框与真实框计算IOU与类别进行复筛。
# 取出这个真实框对应的预测结果
# -------------------------------------------#
fg_pred = prediction[b, a, gj, gi]
#判断是否是物体与类别符合
p_obj.append(fg_pred[:, 4:5])
p_cls.append(fg_pred[:, 5:])
# -------------------------------------------#
# 获得网格后,进行解码,这里需要按照步长进行恢复,并得到我们的预测恢复结果
# -------------------------------------------#
grid = torch.stack([gi, gj], dim=1).type_as(fg_pred)
pxy = (fg_pred[:, :2].sigmoid() * 2. - 0.5 + grid) * self.stride[i]
pwh = (fg_pred[:, 2:4].sigmoid() * 2) ** 2 * anch[i][idx] * self.stride[i]
pxywh = torch.cat([pxy, pwh], dim=-1)
pxyxy = self.xywh2xyxy(pxywh)#该函数将xywh转化为左上,右下坐标形式
pxyxys.append(pxyxy)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
计算当前图片中,真实框与预测框的重合程度
ou的范围为0-1,取-log后为0~inf
重合程度越大,取-log后越小
因此,真实框与预测框重合度越大,pair_wise_iou_loss越小,所得为(真实框个数*候选框个数)
pair_wise_iou = self.box_iou(txyxy, pxyxys)
pair_wise_iou_loss = -torch.log(pair_wise_iou + 1e-8)
- 1
- 2
通过计算IOU后,选择前20,若没有20,则有多少选多少
top_k, _ = torch.topk(pair_wise_iou, min(20, pair_wise_iou.shape[1]), dim=1)
dynamic_ks = torch.clamp(top_k.sum(1).int(), min=1)
# gt_cls_per_image 种类的真实信息,转换为one -hot格式,复制操作
gt_cls_per_image = F.one_hot(this_target[:, 1].to(torch.int64), self.num_classes).float().unsqueeze(
1).repeat(1, pxyxys.shape[0], 1)
- 1
- 2
- 3
- 4
- 5
预测类别并计算交叉熵
cls_preds_ = p_cls.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * p_obj.unsqueeze(0).repeat(num_gt,
1, 1).sigmoid_()
y = cls_preds_.sqrt_()
pair_wise_cls_loss = F.binary_cross_entropy_with_logits(torch.log(y / (1 - y)), gt_cls_per_image,
reduction="none").sum(-1)
- 1
- 2
- 3
- 4
- 5
求cost损失总和,topk函数:找前k个最大值
cost = ( pair_wise_cls_loss+ 3.0 * pair_wise_iou_loss)
matching_matrix = torch.zeros_like(cost)
for gt_idx in range(num_gt):#从真实框中去找这里面损失最小的k个
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item())
matching_matrix[gt_idx][pos_idx] = 1.0
- 1
- 2
- 3
- 4
- 5
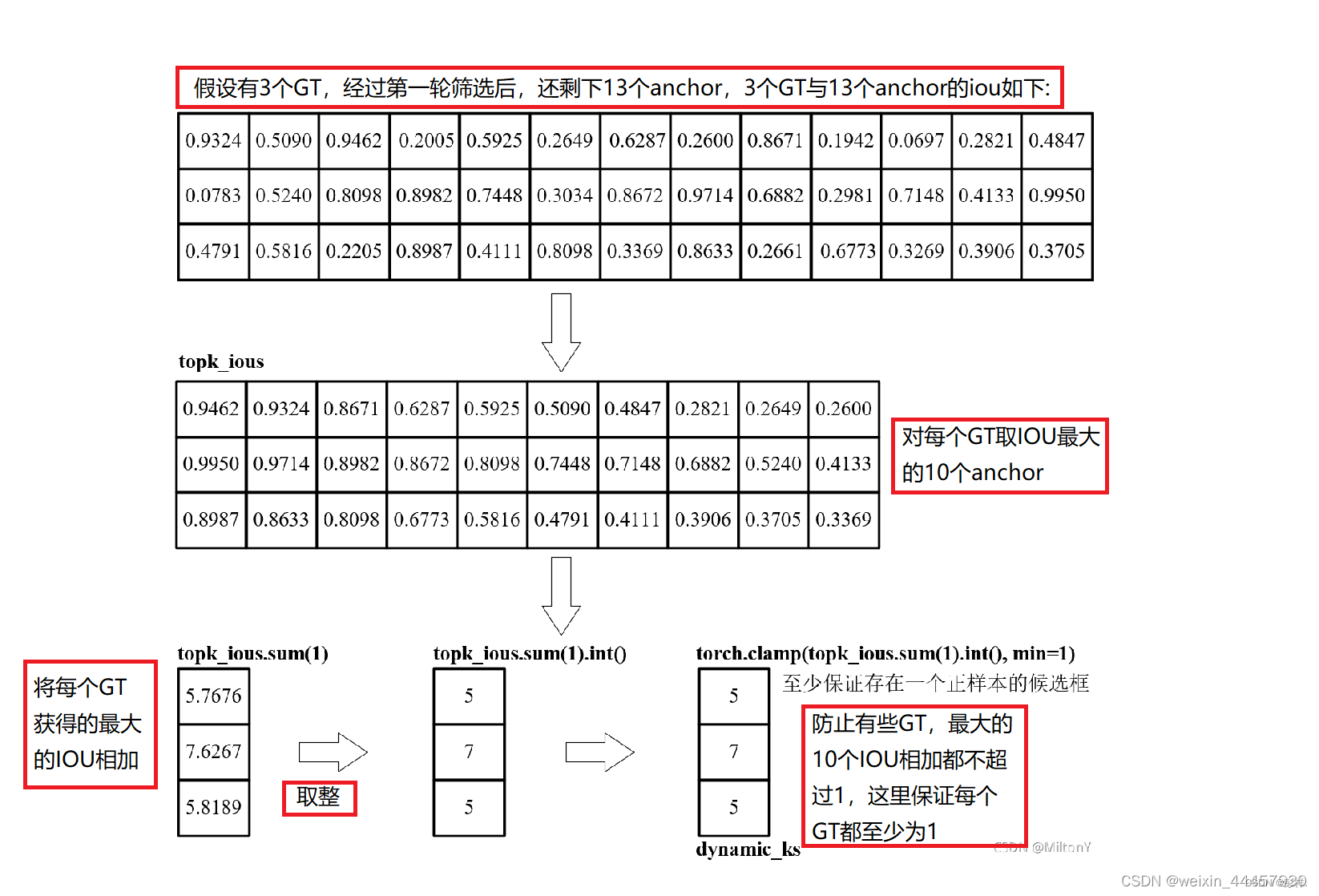
为防止一个anchor预测多个gt,还需要将其转换一下取出最小的iou作为y预测
anchor_matching_gt = matching_matrix.sum(0)#sum(0)求数组每一列的和
if (anchor_matching_gt > 1).sum() > 0:#找出哪些sum>0,说明一个anchor正样本匹配到了多个gt
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)#找到最小的
matching_matrix[:, anchor_matching_gt > 1] *= 0.0#其余赋值0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0#最小的赋值1
fg_mask_inboxes = matching_matrix.sum(0) > 0.0
fg_mask_inboxes = fg_mask_inboxes.to(torch.device(device))#哪些是正样本
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)#正样本对应的真实框索引
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
最终我们将匹配的批次,我们得到的值为:
matching_bs, matching_as, matching_gjs, matching_gis, matching_targets, matching_anchs
下面来讲解其值含义:
matching_bs:匹配上的批次

matching_as:匹配上的anchor id [0,1,2]

matching_gjs, matching_gis:匹配上的单元格xy坐标(负责正样本预测)


matching_targets:匹配上的标签,通过标签中批次,xywh(真实框)可以与前面匹配上的anchor进行计算。在find-3-positive中其加上了anchorid,但在这里没有用到被删除了。

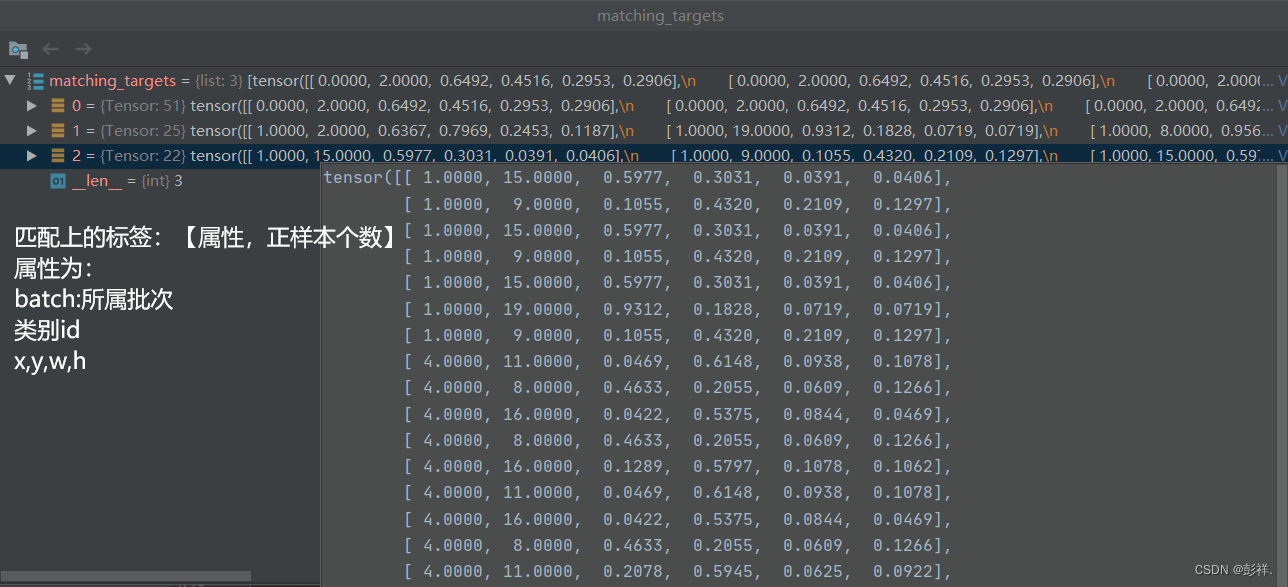
matching_anchs:匹配上的anchor缩放比例

计算损失
完成build-targe函数后获得上面提到的匹配的正样本信息:call函数中
bs, as_, gjs, gis, targets, anchors = self.build_targets(predictions, targets, imgs)
- 1
开始计算损失:
for i, prediction in enumerate(predictions):
# -------------------------------------------#
# image, anchor, gridy, gridx
# -------------------------------------------#
b, a, gj, gi = bs[i], as_[i], gjs[i], gis[i]
tobj = torch.zeros_like(prediction[..., 0], device=device) # target obj
# -------------------------------------------#
# 获得目标数量,如果目标大于0
# 则开始计算种类损失和回归损失
# -------------------------------------------#
n = b.shape[0]
if n:
prediction_pos = prediction[b, a, gj, gi] # prediction subset corresponding to targets
# -------------------------------------------#
# 计算匹配上的正样本的回归损失
# -------------------------------------------#
# -------------------------------------------#
# grid 获得正样本的x、y轴坐标
# -------------------------------------------#
grid = torch.stack([gi, gj], dim=1)
# -------------------------------------------#
# 进行解码,获得预测结果,这里可以看到与build_target中是遥相呼应的是相同的计算方式
# -------------------------------------------#
xy = prediction_pos[:, :2].sigmoid() * 2. - 0.5
wh = (prediction_pos[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
box = torch.cat((xy, wh), 1)
# -------------------------------------------#
# 对真实框进行处理,映射到特征层上
# -------------------------------------------#
selected_tbox = targets[i][:, 2:6] * feature_map_sizes[i]
selected_tbox[:, :2] -= grid.type_as(prediction)
# -------------------------------------------#
# 计算预测框和真实框的回归损失
# -------------------------------------------#
iou = self.bbox_iou(box.T, selected_tbox, x1y1x2y2=False, CIoU=True)
box_loss += (1.0 - iou).mean()
# -------------------------------------------#
# 根据预测结果的iou获得置信度损失的gt,使用iou来代替置信度
# -------------------------------------------#
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
# -------------------------------------------#
# 计算匹配上的正样本的分类损失
# -------------------------------------------#
selected_tcls = targets[i][:, 1].long()
t = torch.full_like(prediction_pos[:, 5:], self.cn, device=device) # targets
t[range(n), selected_tcls] = self.cp
cls_loss += self.BCEcls(prediction_pos[:, 5:], t) # BCE
# -------------------------------------------#
# 计算目标是否存在的置信度损失
# 并且乘上每个特征层的比例
# -------------------------------------------#
obj_loss += self.BCEobj(prediction[..., 4], tobj) * self.balance[i] # obj loss
# -------------------------------------------#
# 将各个部分的损失乘上比例
# 全加起来后,乘上batch_size
# -------------------------------------------#
box_loss *= self.box_ratio
obj_loss *= self.obj_ratio
cls_loss *= self.cls_ratio
bs = tobj.shape[0]
loss = box_loss + obj_loss + cls_loss
return loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
根据模型预测结果计算回归值,回归值计算公式
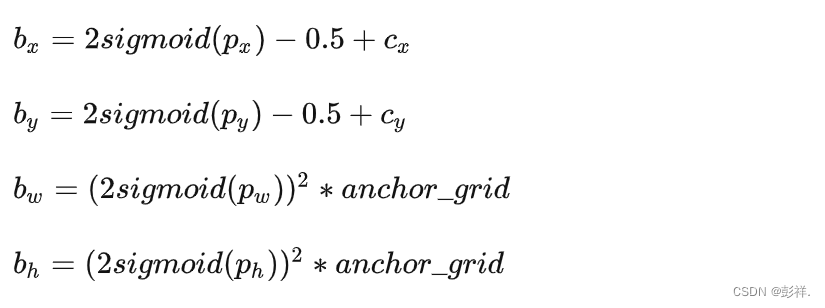
至此,YOLOV7的正样本匹配与损失函数计算过程便完成了。

