
热门标签
热门文章
- 1GPT、Claude、Gemini全系列模型免费白嫖方法_chatgpt镜像
- 2谷粒商城笔记+踩坑(8)——仓库管理_谷粒商城获取spu规格
- 3用于文本去重(相似度计算)的Simhash算法学习及python实现(持续学习中)_simhash算法实例
- 4【leetcode面试经典150题】32.串联所有单词的子串(C++)
- 5【定时同步系列5】Farrow内插器结构原理和MATLAB实现_定时同步内插
- 62024年前端面试真题汇总-3月持续更新中 先收藏慢慢看!(Vue 小程序 css ES6 React 校招大厂真题、高级前端进阶等)_小程序面试题2023
- 7linux mysql dengl_mysql 高性能压力测试
- 8python绘制热力图
- 9探秘Unity ML-StableDiffusion:将AI艺术带入游戏开发的新篇章
- 10各行业都爱用什么编程语言开发?
当前位置: article > 正文
【文本表征】2018年自然语言理解最火的三种方法
作者:weixin_40725706 | 2024-04-25 02:49:02
赞
踩
【文本表征】2018年自然语言理解最火的三种方法
众所皆知的分布式词向量方法CBOM, skip-gram, Glove等已经成为NLP任务的标配,但致命的缺点是无法区别同一个词在不同语境下的含义,如“bank"无论是银行还是河岸的意思,词向量都是同一个,让人脑壳疼。本文要介绍的是2018年很火的三个方法:Elmo, GPT, BERT。它们能够处理多义词、反应不同的语境,从而更好地理解自然语言,并且在下游NLP任务中有突出表现。
1 ELMO
来自论文:“Deep contextualized word representation(2018.3)”
机构:Allen Institute for Artificial Intelligence
概述:文章提出ELMO模型,在大量的语料上训练一个深层双向语言模型,输入为一个完整的句子,句子中的词向量的表征由该模型隐层的函数表示。
1.1 基础:双向语言模型
前向语言模型是用前面的词去预测下一个词:
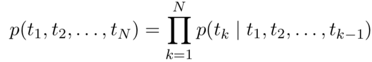
句子中的词被映射到词向量之后,依次输入L层RNN,将该词在第L层输出的隐藏向量输入softmax去预测下一个词。
后向语言模型是用后面的词去预测前�一个词:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/482860
推荐阅读
相关标签

