
- 1小学生计算机课堂实践的重要性,小学《信息技术》有效课堂教学的实践与研究课题方案...
- 2前后端分离开发
- 3开发环境上云,打造五星级开发体验_研发环境上云案例
- 4大模型部署手记(20)Windows+Qwen-VL-Chat-Int4_qianwen大模型本地部署
- 5Rabbit 登录遇到问题:User can only log in via localhost
- 6AI,爱_-ai-愛 博客
- 7深度强化学习(DRL)算法 1 —— REINFORCE_llm drl
- 8Python 霸榜的一周,又有什么新 AI 力作呢?「GitHub 热点速览」
- 9通过selenium框架爬取图片_selenium爬取网页中所有图片
- 10React 之 lazy(延迟加载)(十七)
2021 年云原生技术发展现状及未来趋势
赞
踩
本人有幸担任了 2021 年 GIAC 会议云原生专场的出品人兼讲师,组织了前后四个场子的演讲,在这个过程中个人同时作为听众从这些同行的演讲中学到了很多非常有用的知识。本文算是对 2021 GIAC 云原生专场的侧记,管中窥豹,以观 2021 年云原生技术发展现状及未来一段时间内的趋势。
云原生这个词含义广泛,涉及到资源的高效利用、交付、部署及运维等方方面面。
从系统层次分可以区分出云原生基础设置【如存储、网络、管理平台 K8s】、云原生中间件、云原生应用架构以及云原生交付运维体系,本次专场的四个议题也基本涵盖了这四大方向:
亚马逊的资深技术专家黄帅的《一个云原生服务的爆炸半径治理》
快手基础架构中心服务网格负责人姜涛的《快手中间件 Mesh 化实践》
Tetrate 可观测性工程师柯振旭的《使用 SkyWalking 监控 Kubernetes 事件》
本人以 Dubbogo 社区负责人出品的《Dubbogo 3.0:Dubbo 在云原生时代的基石》
下面根据个人现场笔记以及个人回忆分别记述各个议题的要点。因时间以及本人能力有限,一些错误难免,还请行家多多指正。
1.云原生服务的爆炸半径
个人理解,黄老师的这个议题属于云原生应用架构范畴。
其演讲内容首先从亚马逊 AWS 十年前的一个故障说开:AWS 某服务的配置中心是一个 CP 系统,一次人为的网络变更导致配置中心的冗余备份节点被打垮,当运维人员紧急恢复变更后,由于配置中心不可用【有效副本数少于一半】导致了整个存储系统其他数据节点认为配置数据一致性不正确拒绝服务,最终导致整个系统服务崩溃。
复盘整个事故的直接原因是:CAP 定理对可用性和一致性的定义限定非常严格,并不适合应用于实际的生产系统。因此作为线上控制面的配置中心的数据应该在保证最终一致性的前提下,首先保证可用性。
更进一步,现代分布式系统的人为操作错误、网络异常、软件 Bug、网络/存储/计算资源耗尽等都是不可避免的,分布式时代的设计人员一般都是通过各种冗余【如多存储分区、多服务副本】手段保证系统的可靠性,在不可靠的软硬件体系之上构建可靠的服务。
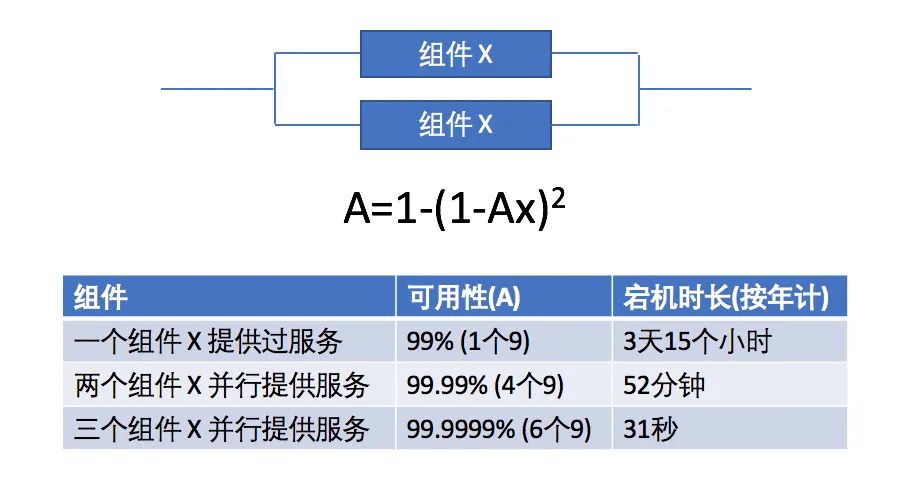
但是这中间有一个误区:有时候一些冗余手段可能因为雪崩效应反而会导致系统的可靠性降低。
如上面的事故,人为的配置错误导致了一连串的软件体系故障,且这些故障之间是高度强相关的,最终导致了雪崩效应,可以称之为“水平扩展的毒药效应”。此时思考的维度就从“在不可靠软硬件体系上提供可靠服务”进一步拓展为“通过各种隔离手段减小事故的爆炸半径”:当不可避免的故障发生时,尽量把故障损失控制到最小,保障在可接受范围内,保证服务可用。
针对这个思路,黄给出了如下故障隔离手段:
服务粒度适中
微服务的服务粒度并不是拆分的越细越好。如果服务粒度过细,会导致服务数量过多,其第一个后果就是导致一个组织内几乎无人能搞清楚服务整体逻辑的来龙去脉,增加维护人员的负担:大家只敢小修小补无人敢做出大幅度的优化改进。
服务粒度过细的第二个后果是造成整体微服务单元体指数级增加,造成容器编排部署成本上升。适中的服务粒度要兼顾架构体系的进化与部署成本的降低。
充分隔离
进行服务编排时,获取数据中心的电源和网络拓扑信息,保证强相关系统之间部署做到“不远”且“不近”。
“不近”是指同一个服务的副本不在使用同一个电源的同一个机柜部署,也不在使用了同一个网络平面的 Azone 内部署。“不远”是指部署距离不能太远,例如多副本可以同城多 IDC 部署。使用这两个原则兼顾性能与系统可靠性。
随机分区
所谓的随机分区这块,其实质就是在混合服务请求,保证某个服务的请求可以走多通道【队列】,保证在某些通道挂掉的情况下不影响某个服务的请求处理,应用随机分区技术,将用户打散在多个 Cell 中,大幅度降低爆炸半径。
与 K8s APF 公平限流算法中的洗牌分片(Shuffle Sharding)颇为相似。
混沌工程
通过持续内化的混沌工程实践,提前踩雷,尽量减少“故障点”,提升系统可靠性。
使用 SkyWalking 监控 Kubernetes 事件
这个议题虽然被安排在第三场演讲,属于云原生交付运维体系,但是与上个议题关联性比较强,所以先在此记述。
如何提升 K8s 系统的可观测性,一直是各大云平台的中心技术难题。K8s 系统可观测性的基础数据是 K8s event,这些事件包含了 Pod 等资源从请求到调度以及资源分配的全链路信息。
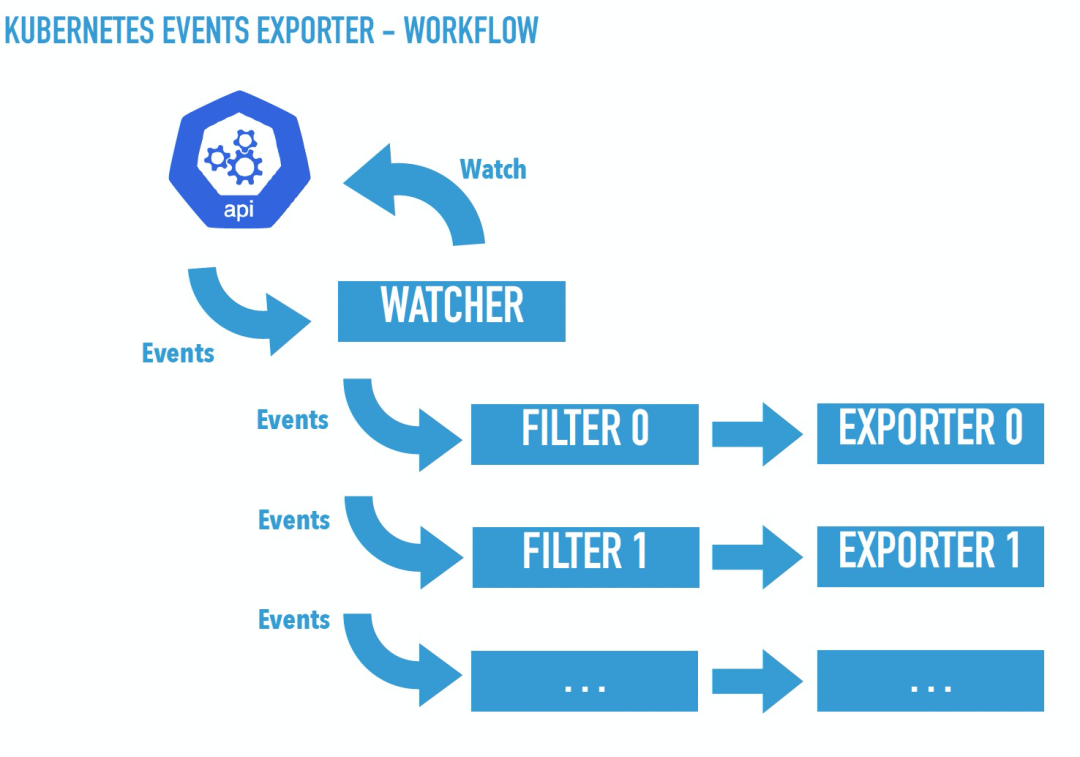
SkyWalking 提供了 logging/metrics/tracing 等多维度可观测性能力,原来只是被用于观测微服务系统,今年提供了 skywalking-kubernetes-event-exporter 接口,专门用于监听 K8s 的 event,对事件进行提纯、收集、发送至 SkyWalking 后端进行分析和存储。

柯同学在演讲过程中花费了相当多的精力演讲整个系统的可视化效果如何丰富,个人感兴趣的点如下图所示:以类似于大数据流式编程的手段对 event 进行过滤分析。

其可视化效果与流式分析手段都是蚂蚁 Kubernetes 平台可借鉴的。
快手中间件 Mesh 化实践
快手的姜涛在这个议题中主要讲解了快手 Service Mesh 技术的实践。
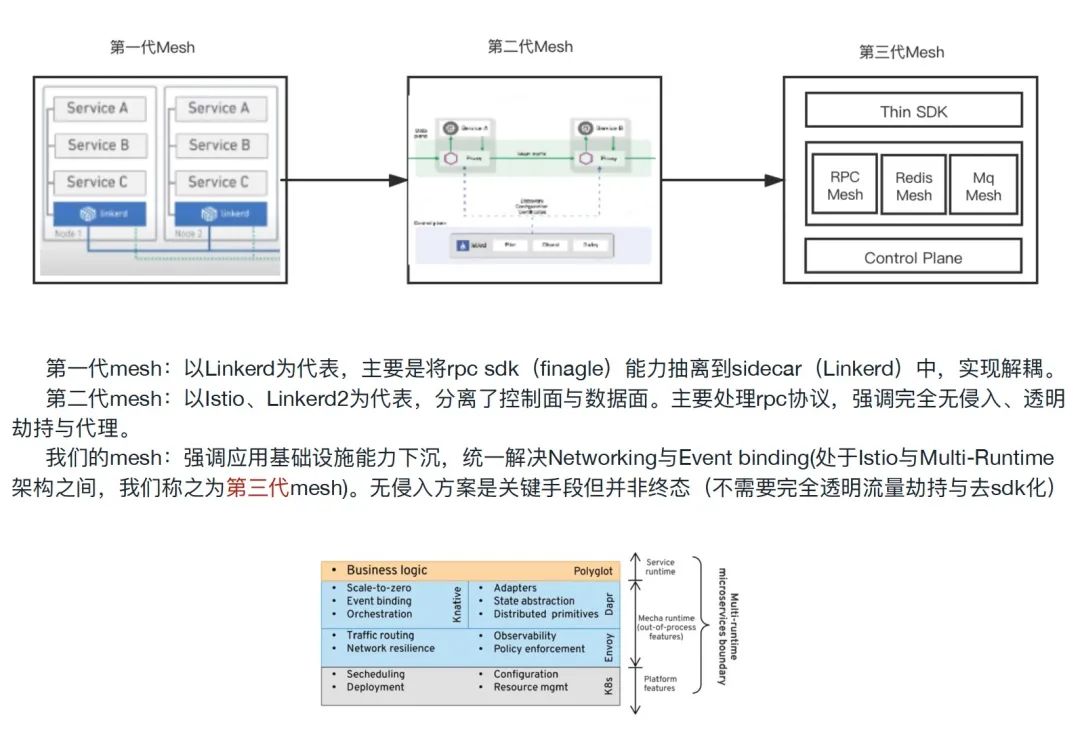
姜老师把 Service Mesh 分为三个世代。其实划分标准有很多,如何划分都有道理。很明显,姜把 Dapr 划入了第三个世代。
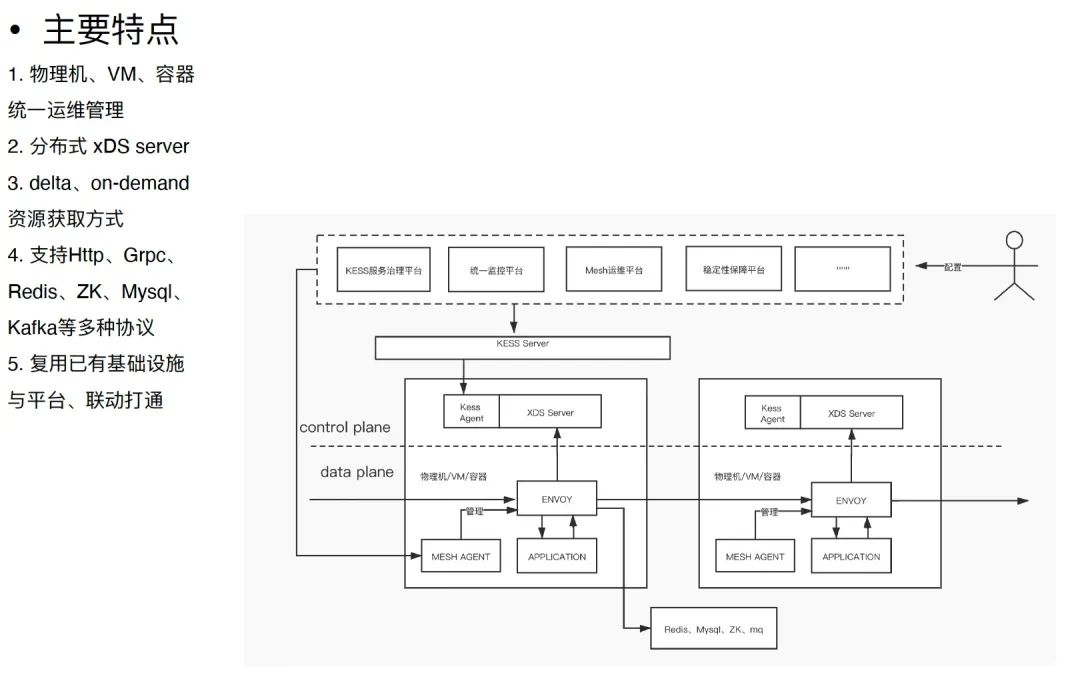
上图是快手的 Service Mesh 架构图,很明显借鉴了 Dapr 的思想:下沉基础组件的能力到数据平面,把请求协议和接口标准化。一些具体的工作有:
统一运维,提高可观测性与稳定性,进行故障注入和流量录制等;
对 Envoy 等做了二次开发,只传输变更的数据、按需获取,解决单实例服务数过多的问题;
对协议栈和序列化协议做了大量的优化;
实施了面向失败设计,Service Mesh 可以 fallback 为直连模式。
个人感兴趣的是姜提到了 Service Mesh 技术在快手落地时面临的三个挑战:
成本问题:复杂环境下的统一部署与运维。
复杂度问题:规模大、性能要求高、策略复杂。
落地推广:对业务来说不是强需求。
特别是第三个挑战,Service Mesh 一般的直接收益方不在业务端,而是基础架构团队,所以对业务不是强需求,而且快手这种实时业务平台对性能非常敏感,Service Mesh 技术又不可避免地带来了延迟的增加。
为了推动 Service Mesh 技术的落地,快手的解决手段是:
首先务必保证系统稳定性,不急于铺开业务量;
搭车公司重大项目,积极参与业务架构升级;
基于 WASM 扩展性,与业务共建;
选取典型落地场景,树立标杆项目。
姜老师在最后给出了快手下半年的 Service Mesh 工作:

很显然这个路线也是深受 Dapr 影响,理论或者架构上创新性不大,更侧重于对开源产品进行标准化并在快手落地。
在演讲中姜提到了 Serivce Mesh 技术落地的两个标杆:蚂蚁集团和字节跳动。其实他们成功的很重要原因之一就是高层对先进技术的重视以及业务侧的大力配合。
Dubbogo 3.0:Dubbo 在云原生时代的基石
作为这个议题的讲师,我在演讲中并没有过多强调 Dubbo 3.0 已有的特性,而是着重演讲了 Service Mesh 的形态以及柔性服务两块内容。
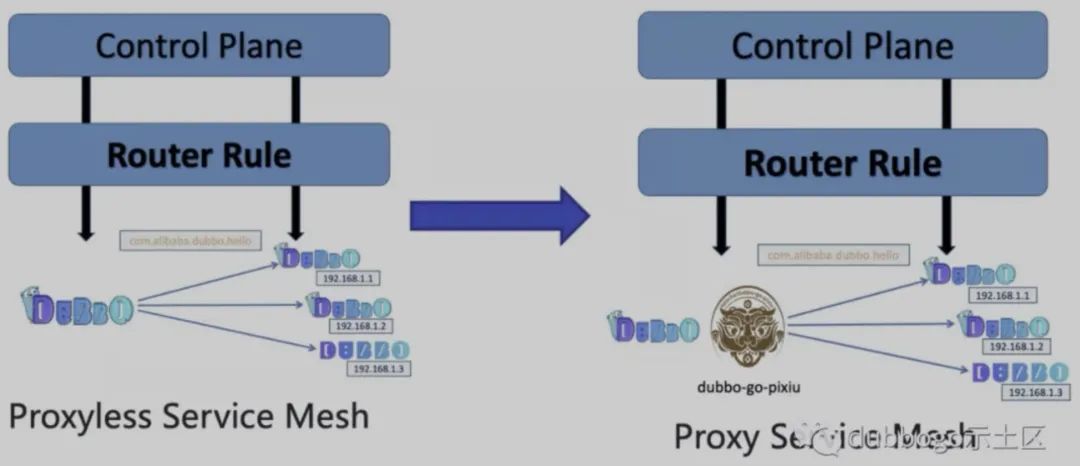
Dubbo 3.0 比较重要的一个点就是 Proxyless Service Mesh,这个概念其实是 gRPC 的滥觞,也是近期 gRPC 生态力推的重点,其优点是性能无损,微服务升级方便。但是 gRPC 自身的多语言生态非常丰富,且 gRPC 鼓吹这个概念的另一个原因作为一个中庸的强调稳定性的框架其性能不甚优秀,如果考虑 Proxy Service Mesh 形态则其性能更加堪忧。
而 Dubbo 生态的最大劣势是除了 Java 和 Go 外,其他多语言能力不甚优秀,个人觉得跟着 gRPC 邯郸学步,完全把其他语言能力屏蔽在外不是什么好主意。Dubbogo 社区出品的 dubbo-go-pixiu 项目在网关与 sidecar 两种形态下解决 Dubbo 生态的多语言能力,把南北流量和东西流量统一到 Pixiu 中。
不管是何种形态的 Service Mesh 技术,其在国内的发展已经渡过第一波高潮,自蚂蚁集团和字节跳动这两个标杆之后走向了寥落,其自身还需要不断进化,更紧密地与业务结合起来让中小厂家看到其业务价值,才会迎来其后续的第二波高潮。
Service Mesh 自身特别适合在 K8s 之上帮助中小厂家把服务迁移到的混合云或多云环境,这些环境大都使用了大量的开源软件体系,能够帮助他们摆脱特定云厂商依赖。
Dubbo 3.0 的柔性服务,基本上可以理解为反压技术。Dubbo 与 Dubbogo 之所以要做柔性服务,其背景是在云原生时代节点异常是常态,服务容量精准评估测不准:
机器规格:大规模服务下机器规格难免异构【如受超卖影响】,即使同规格机器老化速度也不一样;
服务拓扑复杂:分布式服务拓扑结构在不断进化;
服务流量不均衡:有洪峰有波谷;
依赖的上游服务能力不确定性:缓存/db 能力实时变化。
其应对之道在于:在服务端进行自适应限流,在服务调用端【客户端】进行自适应负载均衡。
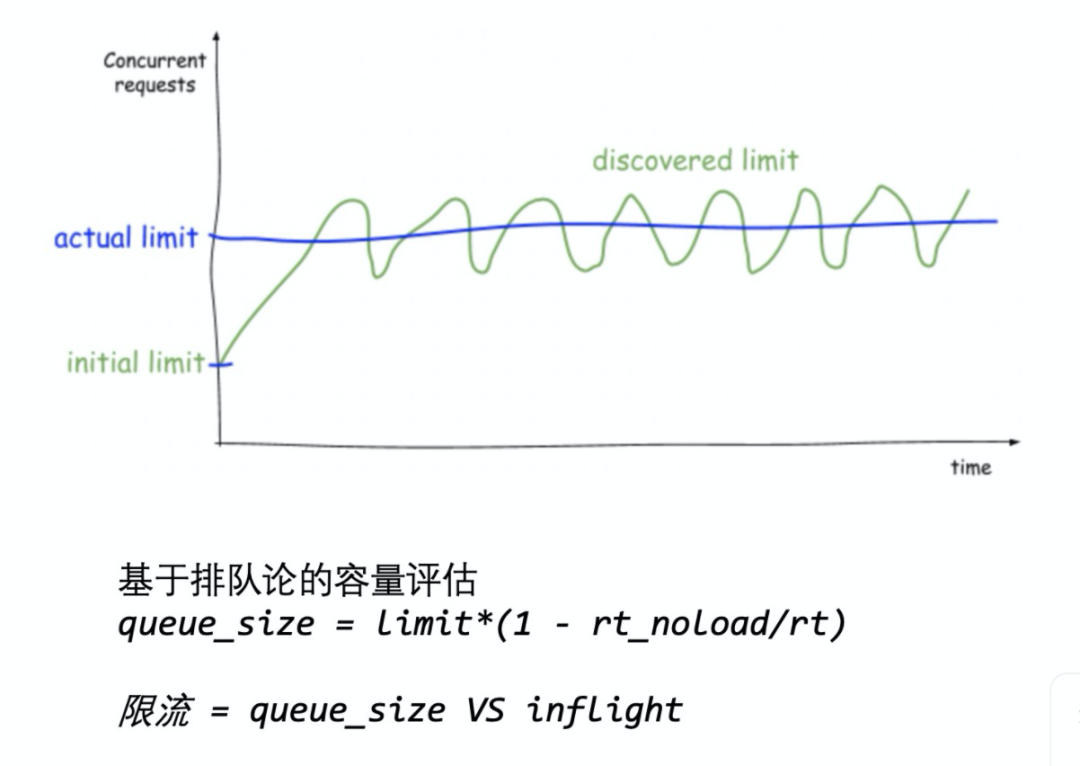
自适应限流的基本思想是基于排队论的 little's law 的改进:queue_size = limit * (1 - rt_noload/rt),各个字段的意义如下:
limit 一段时间内的 qps 上限。
rt_noload 一段时间窗口内的 RT 最小值。
rt 一段时间内的平均 RT,或者可直接取值 P50 RT。
即以两种形态的 RT 来评估 method 级别服务的合适性能。RT 增大反映了整体 load{cpu/memory/network/goroutine} 增大,性能就会下降。反之,RT 减小反映了服务端能够处理更多请求。
自适应限流:服务端是在 method 级别计算 queue_size,同时计算当前 method 的使用的 goroutine 数量 inflight【假设每处理一个客户端请求耗费一个 goroutine】,服务端每次收到某个 method 的新请求后理解实时计算 queue_size,如果 inflight > queue_size,就拒绝当前请求,并把 queue_size - inflight 差值通过 response 包反馈给 client。
自适应负载均衡:客户端通过心跳包或者 response 收到 server 返回的某个 method 的负载 queue_size - inflight,可以采用基于权重的负载均衡算法进行服务调用,当然为了避免羊群效应造成某个服务节点的瞬时压力也可以提供 P2C 算法,Dubbogo 都可以实现出来让用户去选择。
上面整体内容,社区还在讨论中,并非最终实现版本。
场外
从 2017 年到现在,个人参加了大大小小十几次国内各种级别的技术会议,身份兼具出品人和讲师。演讲水平不高,但基本的时间控制能力还可以,做到不拉场。这次主持 GIAC 的云原生分场,听众对本专场的评分是 9.65【所有专场横向评分】,总体表现尚可。
很有幸生活在这个时代,见证了云原生技术大潮的起起伏伏。亦很有幸工作在阿里这个平台,见证了 Dubbogo 3.0 在阿里云钉钉内部的各个场景的逐步落地。
参考阅读:
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式

