
- 1Gitee的使用_gitee仓库怎么用
- 2【数据结构】二叉树(定义、性质、存储、遍历、构造)解析+完整代码
- 3Vue3搭建后台管理系统模板_vue3.0 后台模板
- 4Jmeter中http请求时加HTTP Cookie管理器,cookie不生效问题
- 5JSP日志系统之登录界面的实现一_jsp怎么弄一个登录日志出来
- 6Redis十六种常见使用场景_redis你觉得应用场景有哪些
- 7CVE-2022-30190:Microsoft office MSDT 代码执行漏洞_cve-2022-30190那个版本的office
- 8媒体专访怎么做?媒体采访指南_进行对话,询问并说明您对其中一种媒体来源的偏好
- 9百度CTO王海峰当选中国软件产业40年功勋人物
- 10第二章:AI大模型的基础知识2.2 关键技术解析2.2.3 预训练与微调_ai大模型如何做预训练
Attention机制全流程详解与细节学习笔记_attention 如何处理 padding
赞
踩
回顾
上一篇笔记里,我们的初学笔记里,我们已经对Attention机制的主要内容作了全面的介绍,这篇笔记,主要是补充我在第二次学习Attention机制时对一些细节的理解与记录。下面我会把整个Attention机制的主要流程通过另外一种方式再过一遍,对其中的一些关键参数的维度,这里也会有所标注。温故而知新,挺好。
Attention的全流程
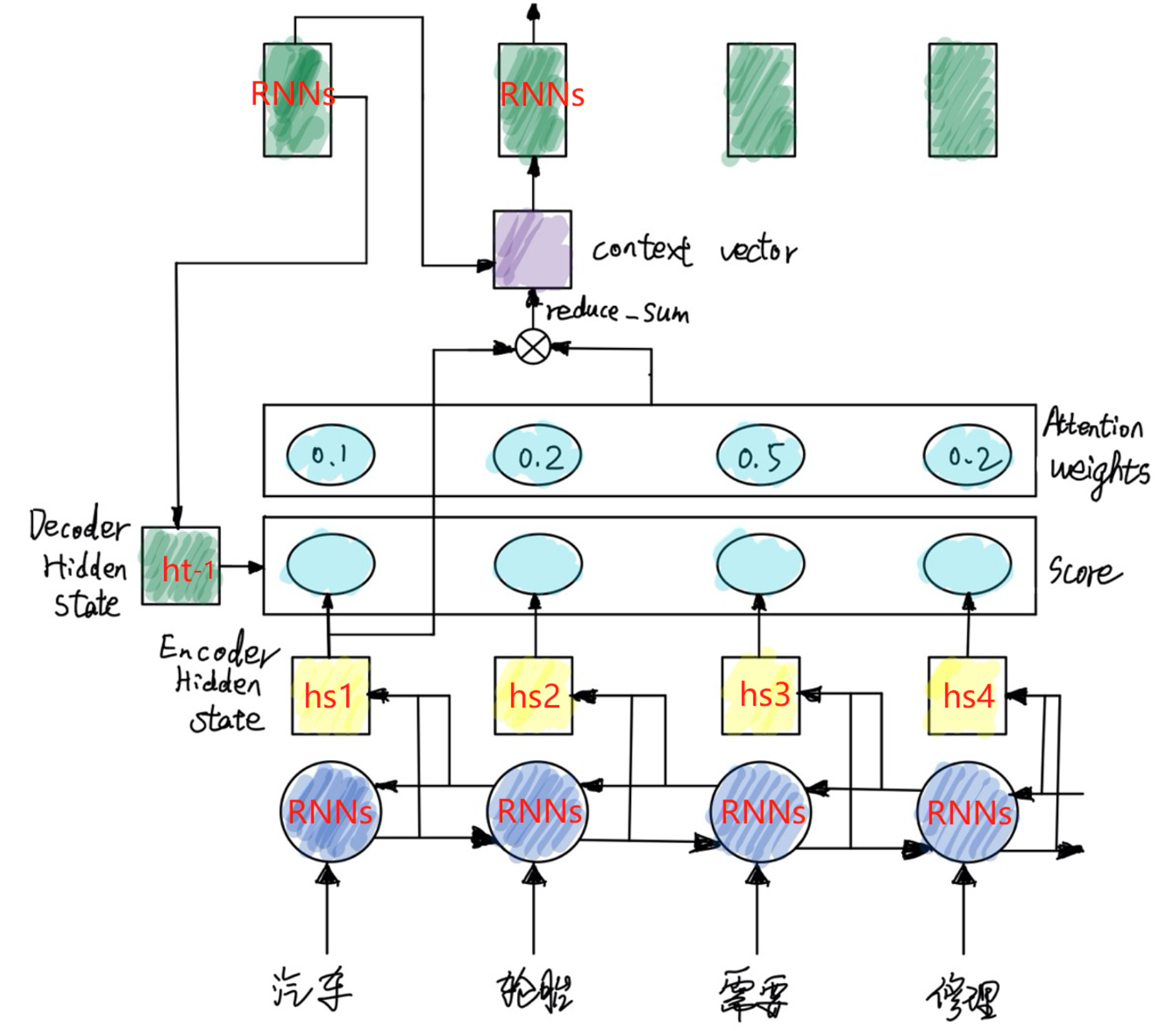
我们用上面的图来说明Attention机制的整个工作流程。
首先,是Decoder部分:
原始输入是语料分词后的token_id,分批次传入Embedding层得到词向量,再将词向量传入Encoder中的特征提取器进行特征提取,这里使用的是RNN系列的模型(RNN、LSTM、GRU),用RNNs代称,为了更好的捕捉一个句子前后的语义特征,我们这里使用双向的RNNs。两个方向的RNNs所产生的两部分隐藏层状态拼接成一个状态hs进行输出。这是后面Attention所需要用到的重要状态值,它包含了各个输入词的语义,在普通的Seq2Seq模型中,它就是生成的语义编码c。

再看Decoder部分:
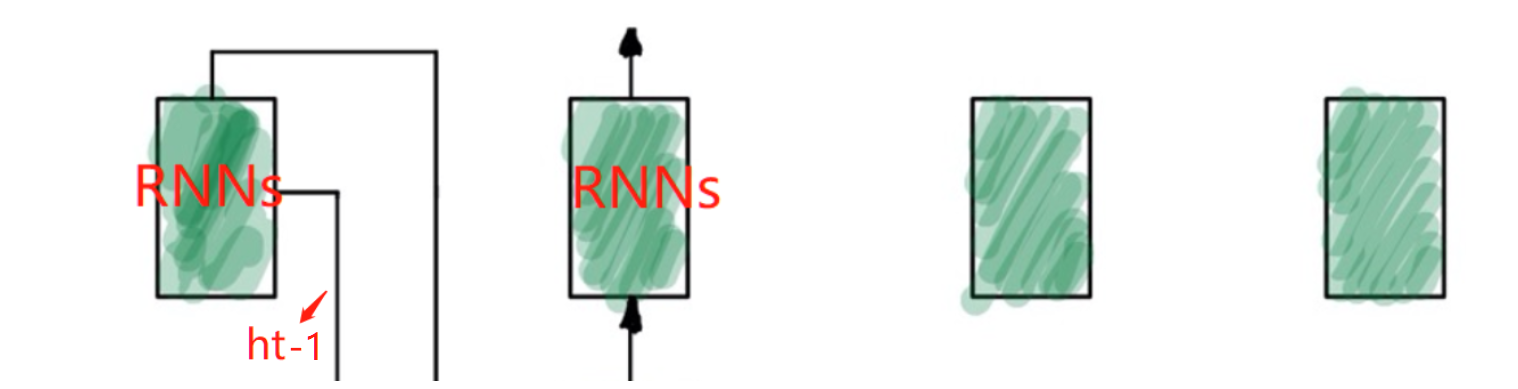
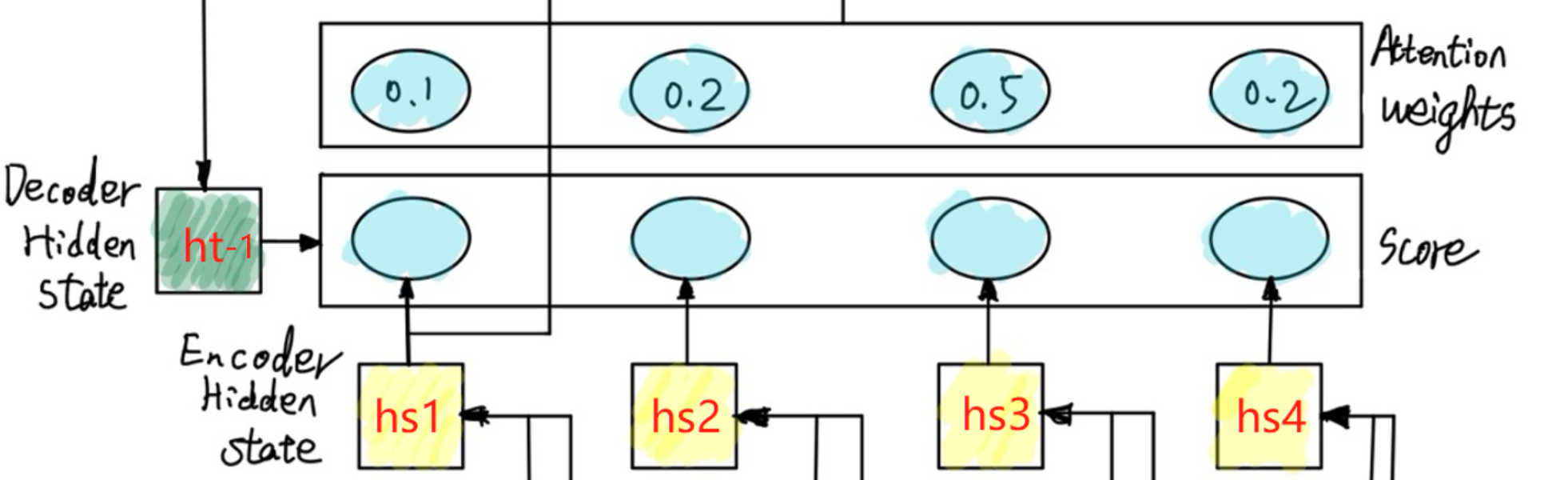
解码部分与编码部分类似,t-1时刻RNNs输出一个隐藏状态h_(t-1),该隐藏状态在图中要传下去,与编码产生的h_s进行计算,得到一个Score:
注意,当前时刻用到的Decoder的隐藏态h_t-1代表是上一时刻Decoder单元输出的,因为在RNN中,当前时刻的输入来自于上一时刻的输出。
这个Score怎么计算的呢,一般我们常用的两个方法如下:
方法一:
两个向量h_t与h_s直接进行点乘得到Score。中间也可以加一个神经网络参数去学习。点乘其实是求了两个向量的相似度,这看起来也很合理,越相似的权重越大。
方法二:
感知机的方式。可以写作:v^T tanh(W_h h_i + W_s s_t + b_attn)。
下一步,将Score进行softmax归一化,得到权重Attention Weight。
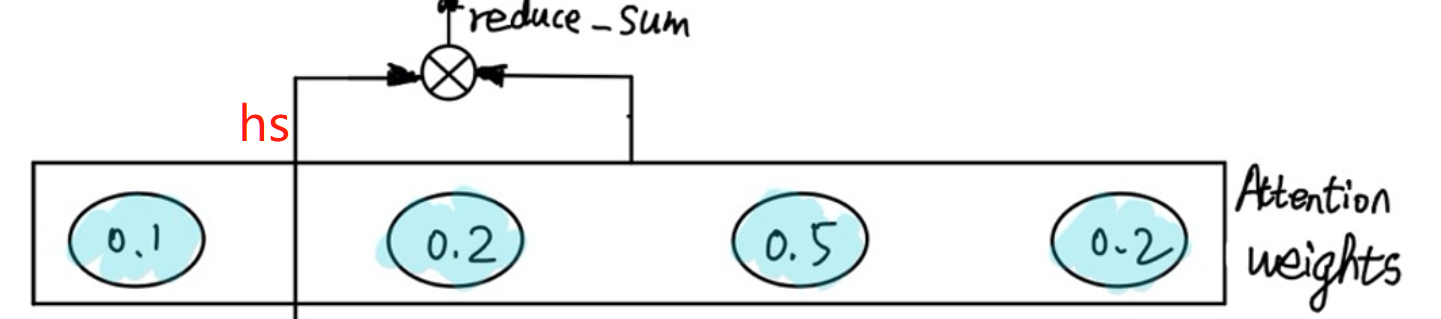
再将Attention Weight与h_s作reduce_sum,其实也就是加权求和得到context vector。形如图中的0.1h_s1+0.2h_s2+0.5h_s3+0.2h_s4。如下图:
接下来,再将context vector与Decoder中上一时刻的输出进行concat,拼接成新的向量作为这一时刻Decoder的输入:
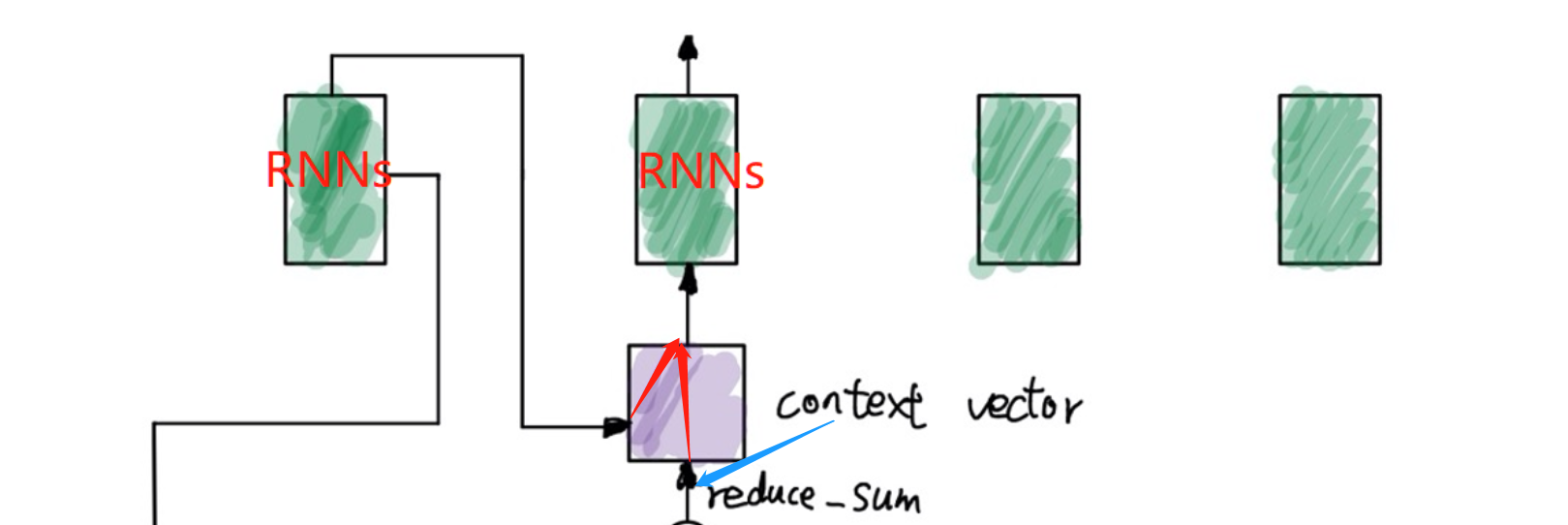
至此Attention的主要流程就描述完了,Decoder的输出就可以去接一个全连接层再过一个softmax就可以拿到词表大小的概率分布了,这也就得到了我们的预测值,再将预测值跟标签值算损失函数作反向梯度更新,再更新网络参数,如此往复,也就是神经网络的常规操作了。
代码实现中的各个关键tensor的维度
这里记录一下一般在代码实现整个Seq2Seq Attention时,各个环节各个关键tensor的维度,先对各个变量做一下定义说明:
batch_size:数据分批时一批数据的大小;
embedding_dim:输入对应的embedding的维度,默认Encoder与Decoder一致;
enc_max_len:encoder时输入的最大长度,一般是数据预处理是,阶段或padding之后规范化的长度;
dec_max_len:decoder时输入的最大长度;
enc_hidden_size:encoder中隐藏层的维度;
dec_hidden_size:decoder中隐藏层的维度;
vocab_size:词表大小。
各个关键tensor维度:
Encoder部分:
Encoder的输入:enc_input.shape=(batch_size,enc_max_len)
输入因为是token_id,所以得过一个Embedding层,过完Embedding的输入:enc_input_embedding.shape=(batch_size,enc_max_len,embedding_dim)【每一个词都变成了对应的词向量】
过完Encoder的输出:enc_output.shape=(batch_size,enc_max_len,enc_hidden_size);对应隐藏层的维度:enc_hidden.shape=(batch_size,enc_hidden_size)
Decoder部分:
原始Decoder的输入:dec_input.shape=(batch_size,dec_max_len)
第一个Encoder的输入过Embedding层:dec_input_embedding.shape=(batch_size,1,embedding_dim)
隐藏层:dec_hidden.shape=(batch_size,dec_hidden_size)
Attention中间过程及输出:
score.shape=(batch_size,enc_max_len,1) = Attention_Weight.shape
Attention_Weight与enc_output作reduce_sum,其实是在中间维度上进行的加权求和,得到的context_vextor维度:context_vextor.shape=(batch_size,enc_hidden_size)
将context_vextor升维后与dec_input_embedding进行concat,得到最终每个RNNs的输入:RNNs_input.shape=(batch_size,1,embedding_dim+enc_hidden_size)
输出:dec_output.shape=(batch_size,dec_hidden_size)
如果输出再过一个FC层,则输出维度(batch_size,vocab_size)
小结
没什么特殊小结,纸上得来终觉浅,绝知此事要躬行。代码撸一遍就知道了。改天放上代码链接。晚安嘞您。
参考文章:
没有参考文章,感谢HCT张楠老师的讲解。

