
热门标签
热门文章
- 1首起针对国内金融企业的开源组件投毒攻击事件_组件投毒 数据库
- 2项目体检(Health Check)升级上线
- 3Mac系统安装及配置python_macbook如何安装python2
- 4python读程序写结果-31.Python:文件读写
- 5Git+TortoiseGit详细安装教程(HTTP方式)_tortoisegit http
- 6Python的日志输出_python日志输出到文件
- 7Springboot+Vue项目-基于Java+MySQL的图书馆管理系统(附源码+演示视频+LW)
- 8阅读小车循迹论文笔记:灰度传感器、仿生处理器、路径跟踪机制()_灰度传感器原理图
- 9SIDE:开启研发新的颠覆式的开发体验
- 10Flask-SQLAlchemy的使用(详解)_flask sqlalchemy options
当前位置: article > 正文
理解神经网络的注意力机制(Attention)及PyTorch 实现_pytorch 卷积+attention
作者:羊村懒王 | 2024-04-30 19:41:06
赞
踩
pytorch 卷积+attention
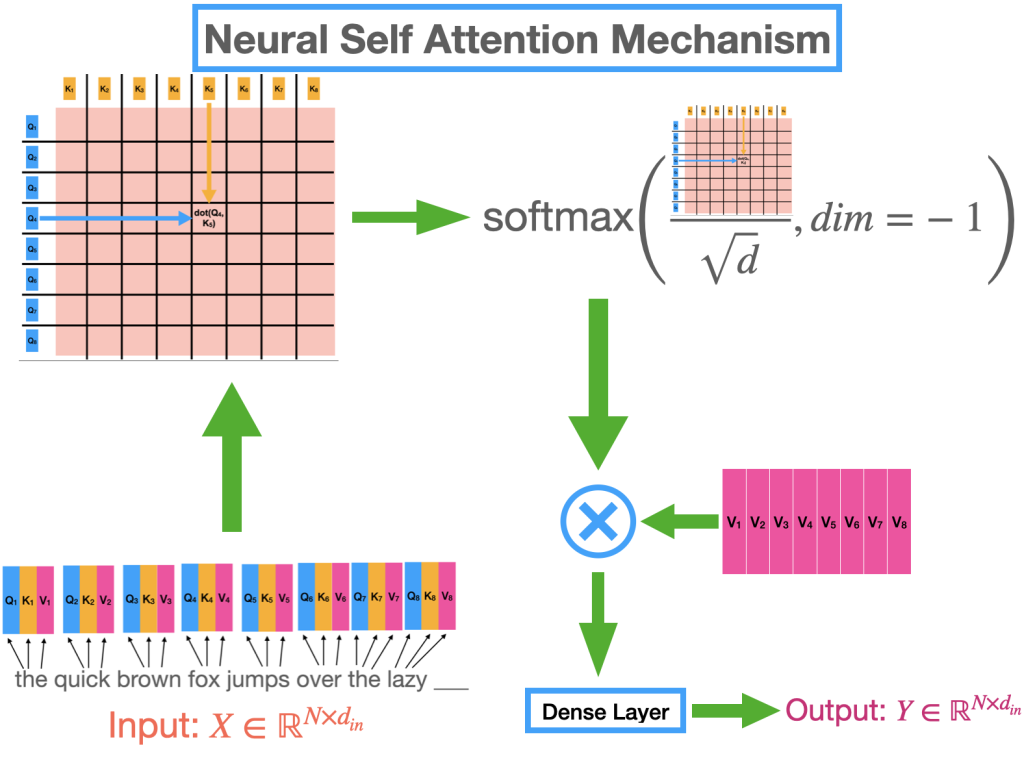
刚刚结束的 2022 年对于人工智能的许多进步来说是不可思议的一年。最近 AI 中的大多数著名地标都是由称为变形金刚的特定类别模型驱动的,无论是 chatGPT 的令人难以置信的进步,它席卷了世界,还是稳定的扩散,它为您的智能手机带来了类似科幻小说的功能。即使是 Tesla 的自动驾驶软件堆栈,也许是世界上部署最广泛的深度学习系统,也在引擎盖下使用变压器模型(双关语意)。“神经注意机制”是让 Transformer 在各种任务和数据集上如此成功的秘诀。
这是关于视觉转换器 (ViT) 的系列文章中的第一篇。在本文中,我们将了解注意力机制并回顾导致它的思想演变。接下来,我们就直观的了解一下。我们将从头开始在 PyTorch 框架中实现注意力机制,将直观的理解与数学细节结合起来,最终将这种理解转化为代码。尽管我们将在文章结尾专门讨论视觉转换器,但大部分讨论同样适用于大型语言模型 (LLM),例如 GPT-3 和最近发布的 chatG
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/514879
推荐阅读
相关标签

