
- 1基于Springboot框架北京某大学图书馆座位预约系统设计与实现 研究背景和意义、国内外现状_图书馆预约系统国内外研究现状
- 2去除el-tabs的底部灰色横线_el-tabs 去除灰色横线
- 3Python 报错 unicodedecodeerror: ‘utf-8‘ codec can‘t decode byte 0x8c_代码从windows转到mac时pycharm下报unicodedecodeerror: 'utf-
- 4CloudFlare免费内网穿透
- 5关于APP广告变现的介绍_日活一万的app广告费
- 6内网环境使用docker部署微服务系统记录_docker内网部署
- 7Linux CentOS 本地yum配置
- 8MySQL 8.0.30 新新特性 不可见主键_mysql8.0隐式主键
- 9RuntimeError错误的几个可能原因记录和解决方法_runtimeerror: [enforce fail at c:\actions-runner\_
- 10二叉树C语言基本定义+操作代码+注释详解(二叉树的递归/非递归遍历方法)_二叉树与递归c语言基础
【新手】自然语言处理新手入门知识【NLP】_自然语言处理入门
赞
踩
该文章适用于刚开始接触自然语言这门课的小伙伴,略微简介,感兴趣可以观看哦!
前言
自然语言(Natural language)通常是指一种自然地随文化演化的语言。例如,汉语、英语都是自然语言的例子。自然语言是人类交流和思维的主要工具。 自然语言是人类智慧的结晶,自然语言处理是人工智能中最为困难的问题之一,而对自然语言处理的研究也是充满魅力和挑战的,也是各国人表达的方法其中之一。
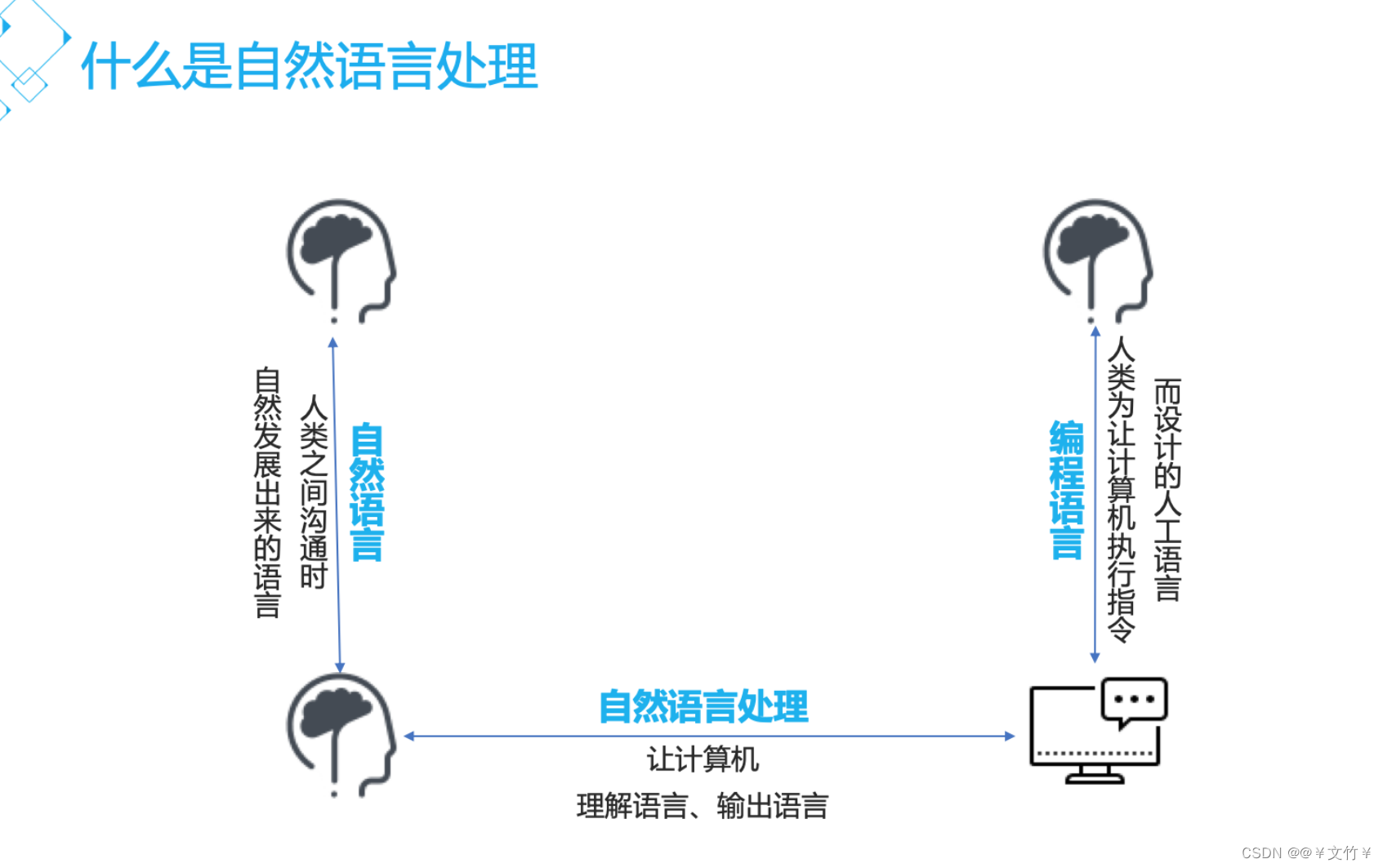
一、自然语言处理是什么?
自然语言处理(Natural Language Processing, 简称NLP)是计算机科学与语言学中关注于计算机与人类语言间转换的领域, 被誉为人工智能的皇冠明珠,是计算机科学和人工智能领域的一个重要的分支,其主要研究人与计算机之间,使用自然语言进行有效通信的各种理论和方法,简单来说:
计算机以用户的自然语言形式作为输入,在其内部通过定义算法进行加工,计算等系列操作后(用以模拟人类对自然语言的理解)在返回用户所期望的结果。
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。
为了让小伙伴们能更加通俗易懂地明白什么是自然语言处理,可观看下列视频:
https://www.bilibili.com/video/BV1BQ4y1178t/?spm_id_from=333.337.search-card.all.click&vd_source=a79b6ff630b5d04c396e68528362d5a8
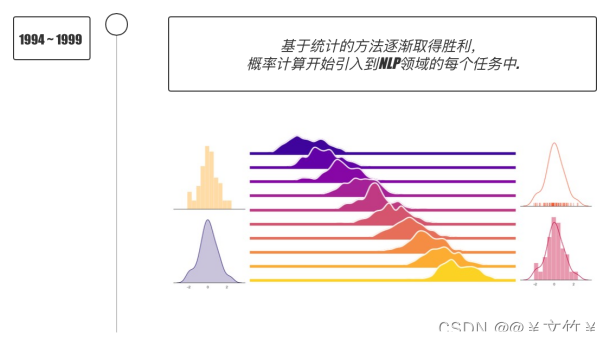
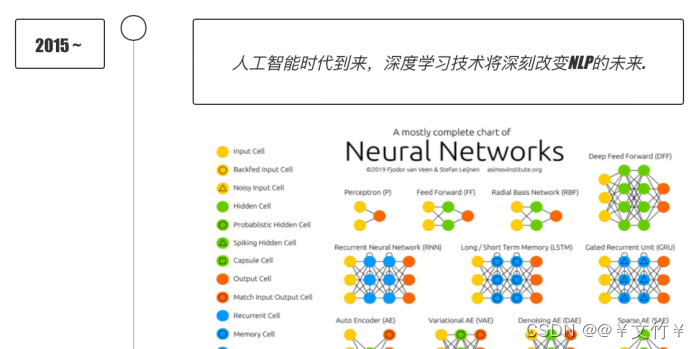
二、自然语言的发展历程
自然语言处理的发展历程主要有以下四个阶段:分别有兴起、符号主义、连接主义、深度学习四个阶段,如下图所示: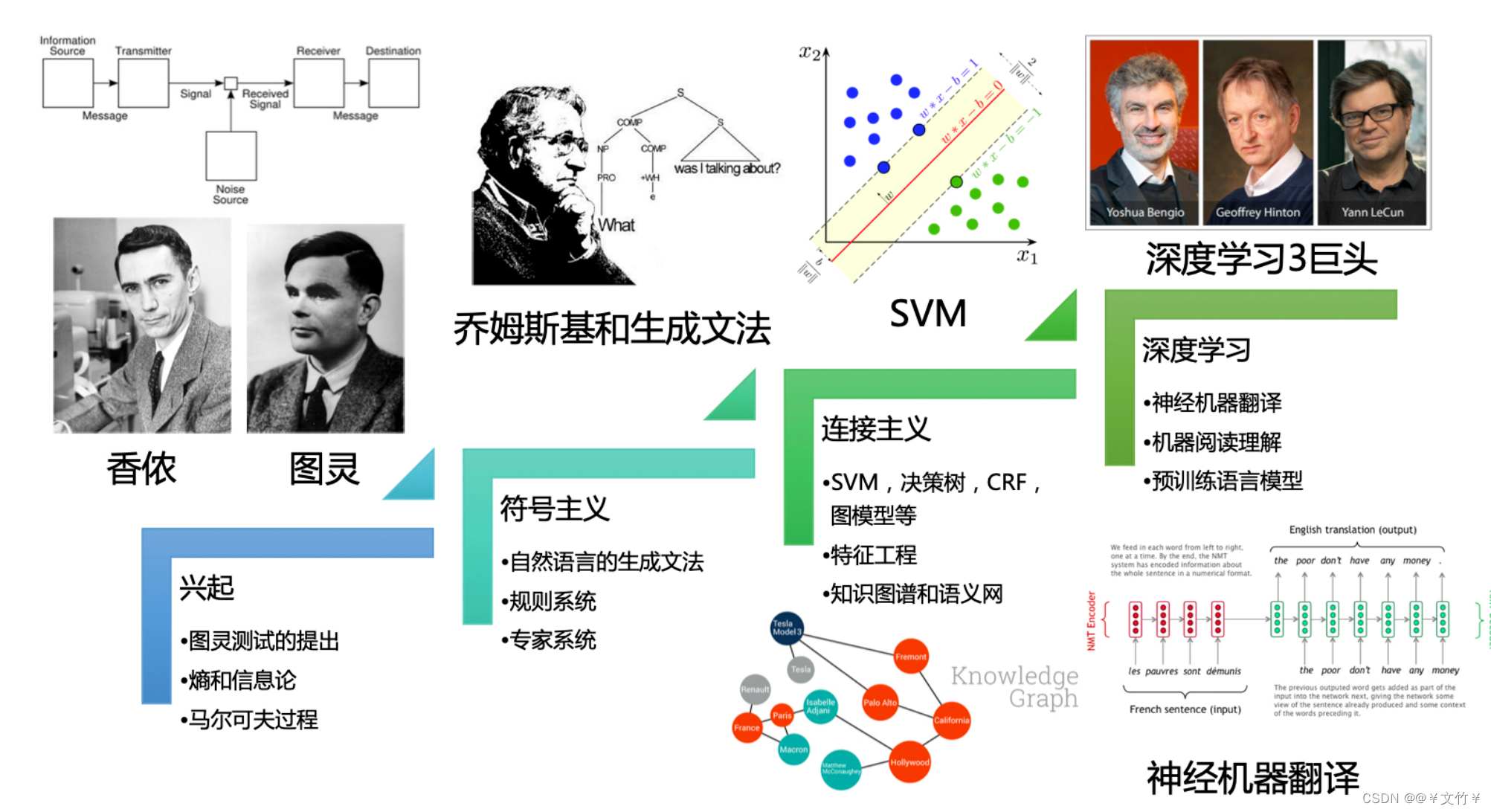
我大概看了一下资料,发现有一些大佬阐述关于自然语言处理的相关发展历程还是非常详细的,我觉得小伙伴们可以借鉴看一下,这里我就不过多阐述了:
https://zhuanlan.zhihu.com/p/559022300
主要的简单历程大概就是(小编只是简单概括一下哦,有不明白的可以留言):



或者小伙伴们可以看以下视频,或许能更加深刻的明白,自然语言处理的发展历程:
https://www.bilibili.com/video/BV1of4y1h7dQ/?spm_id_from=333.337.search-card.all.click&vd_source=a79b6ff630b5d04c396e68528362d5a8
三、自然语言的应用场景
生活中自然语言应用场景还是很多的,例如有:
1.机器翻译
2.语音识别
3.情感分析
4.问答系统
5.自动摘要
6.聊天机器人
7.市场预测
8.文本分类
…
等等一些应用场景
其实对于机器来说理解人类的自然语言有时候还是比较有歧义的,例如以下案例就表明机器有时候并不能很好的理解人类表达的意思:
对于表达听赵雷的成都这首歌,可能的说法有:
我要听赵雷的成都
给我播赵雷的成都
我想听歌赵雷的成都
放首赵雷的成都
给唱一首赵雷的成都
放音乐赵雷的成都
放首歌赵雷的成都
放赵雷的成都这首歌
给爷放个赵雷的成都
以上列举的还是相对规范的说法,实际中还存在很多长尾的不太规范的说法,比如“最近有首歌叫成都,那个好像是赵雷唱的,还挺火的,播放一下”。规则的方法对规范的说法都有些力不从心,对于大量的不太规范的说法,就几乎无能为力了。
试想一下,您对着像语音助手聊天,一旦有句话不能正确理解,心底就会情不自禁的骂一句,“好傻。。”。如果想得到高精度的结果,规则方法需要撰写的句式量则成指数级增长,但是即使撰写了足够多的规则,准确率也不一定能够提升。因为每条规则都有其适用条件,当数量到了一定程度之后,就会不可避免的存在大量的冲突。最后冲突的带来的准确率的损失,已经抵消规则数量带来的准确率的提升了。
相反的,以深度学习为代表的统计学习方法,理论上讲只要有更多的数据,就能得到更高的性能。而且统计的方法具有一定的泛化性能,对于未见过的长尾的case,也是可以得到正确的结果的。这也是为什么规则方法要转向统计方法的最主要原因。
总结
以上就是对于刚接触自然语言的小伙伴介绍的关于自然语言处理的一些知识,相对来说还是比较简洁明了的,如果有什么不清晰或者不明白的地方,欢迎留言或私信哦!

