
热门标签
热门文章
- 1kafka知识点_kafka broker
- 2网络安全之渗透实战学习_渗透 csdn
- 3Java基础学习大全(一)_java学习
- 4ai绘画|Stable Diffusion 整合包下载链接来了_stable diffusion ai 下载
- 5WPF GridLength折叠动画+ GridSplitter 拖拽布局_wpf树形导航菜单
- 6使用APK进行Frida注入,免电脑联机麻烦,批量解决更新脚本或frida麻烦_frida-inject
- 72023.12.30subprocess.CalledProcessError: Command ‘(‘lsb_release‘, ‘-a‘)‘ returned non-zero exit stat_subprocess.calledprocesserror: command '('lsb_rele
- 8探秘MP-SPDZ:高性能安全多方计算框架
- 9第二章 编译程序基本原理 — 编译过程概述_编译过程包括哪些阶段?各阶段的主要功能是什么?
- 10不容错过,前端 Code Review 的最佳实践方案来了
当前位置: article > 正文
Image-Text Interaction Network(CCF B)_跨模态注意力机制
作者:weixin_40725706 | 2024-05-16 18:17:45
赞
踩
跨模态注意力机制
Zhu T, Li L, Yang J, et al. Multimodal sentiment analysis with image-text interaction network[J]. IEEE Transactions on Multimedia, pages 1–1, 2022(CCF B类)
目录
(1)Cross-modal Alignment Module
(4)Multimodal Sentiment Classification
一、本文贡献
- 提出一种新的针对于多模态情感分析的图像文本交互网络。该方法通过对齐情感图像区域和文本词用于分析图像文本交互。
- 基于跨模态的注意力机制提出了一种跨模态的对齐模块,用来捕获图像区域和文本单词之间的细粒度对应关系;为抑制错位对齐的区域单词对所产生的消极影响,提出一个自适应的跨模态门模块融合多模态特征。
- 大量的实验验证了本文方法的优点。进行消融实验,验证方法的合理性。
二、本文所提出的方法
1.模型框架
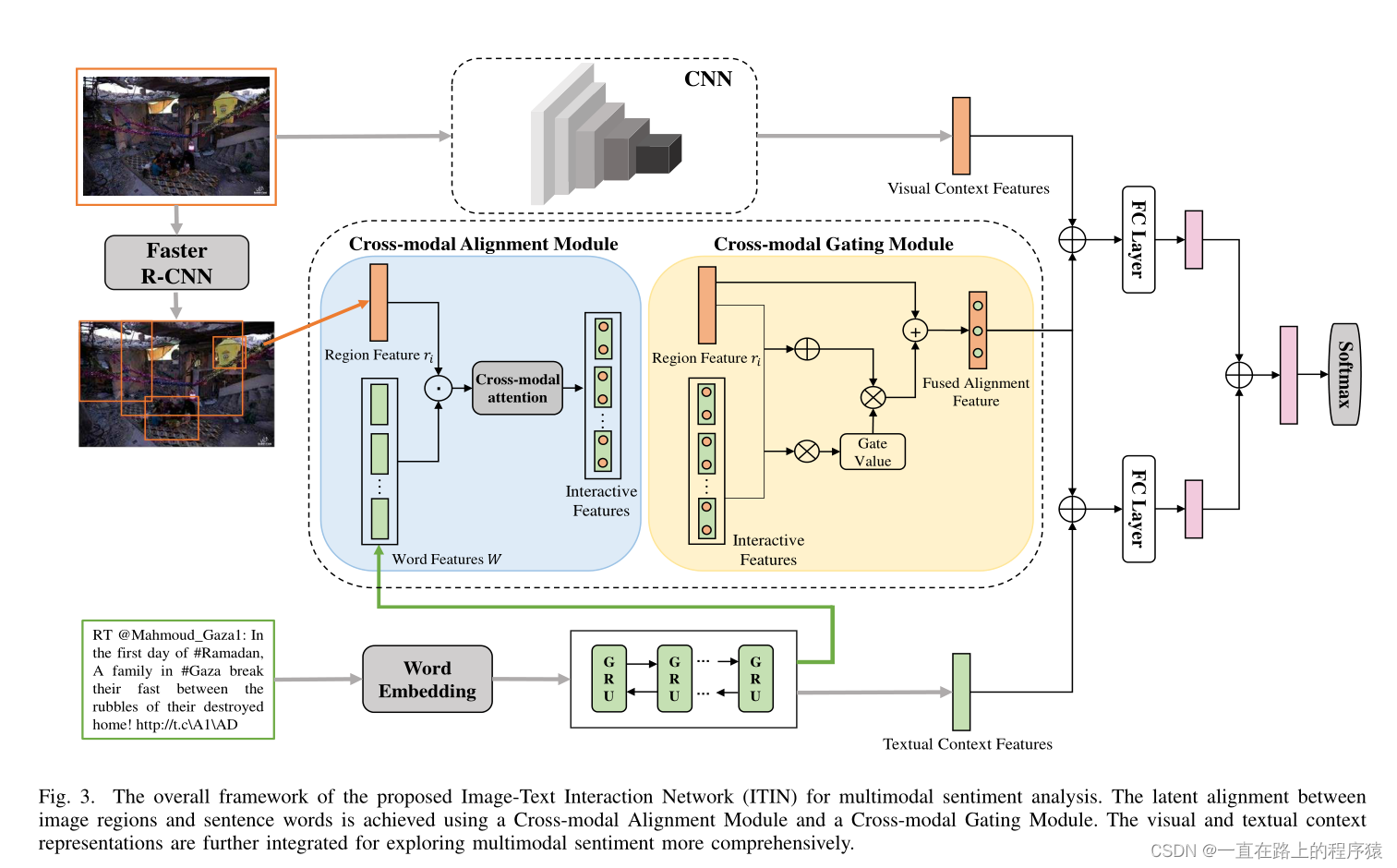
2.图像文本交互
(1)Cross-modal Alignment Module
跨模态对齐模块目的是在嵌入空间中对齐图像区域和句子中的单词。
图像区域特征提取:对于输入的图像I,使用在Visual Genomes数据集上预训练的Faster R-CNN检测图像区域以及相关的表示。取每个图像的前m个区域提示框,每个区域是一个2048维的向量,定义为
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/579979
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

