
- 1hadoop3.x支持LZO压缩配置_hadoop lzo
- 2iOS_MethodSwizzling_黑魔法坑点与解决方案_ios怎么避免方法交换造成的污染
- 3Prometheus 监控 Mysql_prometheus servicemonitor 监控mysql容器
- 4视觉语言模型详解
- 5【训练】Codeforces Round #877 (Div. 2) ABC题解_codeforces887中的a题怎么做
- 6BarTender 9.10 与Seagull License Server 9.10 通用的注册机_bartender注册码
- 7你适合考PMP还是软考?两者的区别是否清楚,分别能给你带来什么价值_软考和pmp 哪个有用?考哪个比较好?
- 8编码器—解码器和注意力机制_编码器与解码器之间的注意力机制的作用
- 9两种服务器机柜的冷却解决方案_服务器机柜散热
- 10Python - 深度学习系列31 - ollama的搭建与使用_ollama安装
hive建表并load数据小结_hive load data 分隔符
赞
踩
一、建表的时候要指明分隔符
hive建表时默认的分隔符是'\001',若在建表的时候没有指明分隔符,load文件的时候文件的分隔符需要是'\001'的,
若文件分隔符不是'\001',程序不会报错,但表查询的结果会全部为'NULL',
如何制作分隔符为'\001'的测试文件
用vi编辑器Ctrl+v然后Ctrl+a就可以通过键盘输入'\001'
也可以在建表的时候指明分隔符为制表符,然后测试文件用excel制表符制作,
例如:
create table pokes(foo INT,bar STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
LOAD DATA local inpath '/root/pokes.txt' INTO TABLE pokes;其中 pokes.txt文件需要用excel制作制表符为分隔符,否则程序不会报错,但表查询的结果会全部为'NULL'
二、替换分隔符
若待导入的文件的分隔符与表的分隔符不一致,或者需要替换hive导出文件字段默认分隔符:
Hive建表的时候虽然可以指定字段分隔符,不过用insert overwrite local directory这种方式导出文件时,字段的分割符会被默认置为\001,一般都需要将字段分隔符转换为其它字符,可以使用下面的命令:
sed -e 's/\x01/|/g' file
可以将|替换成自己需要的分隔符,file为hive导出的文件。
例如:
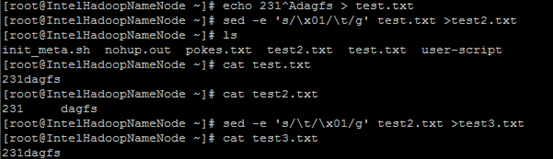
三 复杂类型的数据表,这里列之间以'\t'分割,数组元素之间以','分割
#数据文件内容如下
1 huangfengxiao beijing,shanghai,tianjin,hangzhou
2 linan changchu,chengdu,wuhan
hive> create table complex(name string,work_locations array)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> COLLECTION ITEMS TERMINATED BY ',';
hive> describe complex;
OK
name string
work_locations array
hive> LOAD DATA LOCAL INPATH '/home/hadoop/hfxdoc/complex.txt' OVERWRITE INTO TABLE complex
hive> select * from complex;
OK
huangfengxiao ["beijing","shanghai","tianjin","hangzhou"]
linan ["changchu","chengdu","wuhan"]
Time taken: 0.125 seconds
hive> select name, work_locations[0] from complex;
MapReduce Total cumulative CPU time: 790 msec
Ended Job = job_201301211420_0012
MapReduce Jobs Launched:
Job 0: Map: 1 Cumulative CPU: 0.79 sec HDFS Read: 296 HDFS Write: 37 SUCCESS
Total MapReduce CPU Time Spent: 790 msec
OK
huangfengxiao beijing
linan changchu
Time taken: 20.703 seconds
四如何分区?
表class(teacher sting,student string,age int)
Mis li huangfengxiao 20
Mis li lijie 21
Mis li dongdong 21
Mis li liqiang 21
Mis li hemeng 21
Mr xu dingding 19
Mr xu wangqiang 19
Mr xu lidong 19
Mr xu hexing 19
如果我们将这个班级成员的数据按teacher来分区
create table classmem(student string,age int) partitioned by(teacher string)
分区文件
classmem_Misli.txt
huangfengxiao 20
lijie 21
dongdong 21
liqiang 21
hemeng 21
classmem_MrXu.txt
dingding 19
wangqiang 19
lidong 19
hexing 19
LOAD DATA LOCAL INPATH '/home/hadoop/hfxdoc/classmem_Misli.txt' INTO TABLE classmem partition (teacher = 'Mis.li')
LOAD DATA LOCAL INPATH '/home/hadoop/hfxdoc/classmem_MrXu.txt' INTO TABLE classmem partition (teacher = 'Mis.Xu')
#分区列被默认到最后一列
hive> select * from classmem where teacher = 'Mr.Xu';
OK
dingding 19 NULL Mr.Xu
wangqiang 19 NULL Mr.Xu
lidong 19 NULL Mr.Xu
hexing 19 NULL Mr.Xu
Time taken: 0.196 seconds
#直接从分区检索,加速;如果where子句的条件不是分区列,那么,这个sql将被编译成mapreduce程序,延时很大。
#所以,我们建立分区,是为了一些常用的筛选查询字段而用的。
五桶的使用?更高效!可取样!主要用于大数据集的取样
桶的原理是对一个表(或者分区)进行切片,选择被切片的字段,设定桶的个数,用字段与个数的hash值进行入桶。
比如bucket.txt数据文件内容如下:
id name age
1 huang 11
2 li 11
3 xu 12
4 zhong 14
5 hu 15
6 liqiang 17
7 zhonghua 19
如果我们想将这个数据表切成3个桶,切片字段为id
那么用id字段hash后,3个桶的内容如下:
桶id hash 3 =0
3 xu 12
6 liqiang 17
桶id hash 3 =1
1 huang 11
4 zhong 14
7 zhonghua 19
桶id hash 3 =2
2 li 11
5 hu 15
这个过程的创建表语句如下:
create table bucketmem (id int,name string,age int) CLUSTERED BY (id) sorted by (id asc) into 3 buckets
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH '/home/hadoop/hfxdoc/bucketmem.txt' INTO TABLE bucketmem;
select * from bucketmem tablesample(bucket 1 out of 4)
六其他操作参考,更完整的请参考官网: https://cwiki.apache.org/confluence/display/Hive/Home
1) 创建与已知表相同结构的表Like:
只复制表的结构,而不复制表的内容。
create table test_like_table like test_bucket;
2) 对表进行重命名 rename to:
ALTER TABLE table_name RENAME TO new_table_name
3) 增加分区 Add Partitions:
ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1' ]partition_spec [ LOCATION 'location2' ]
4) 对表中的某一列进行修改,包括列的名称/列的数据类型/列的位置/列的注释
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type[COMMENT col_comment] [FIRST|AFTER column_name]
5) 添加/替换列Add/ReplaceColumns
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENTcol_comment], ...)
ADD COLUMNS 允许用户在当前列的末尾增加新的列,但是在分区列之前。

