
- 1解决主机有网络但虚拟机没网络连接问题----记录
- 2Linux安装hadoop
- 3Python中selenium库的用法详解_python selenium
- 4Git 打patch (打补丁)的使用_git patch怎么用
- 5android基础知识12:android自动化测试03—基于junit的android测试框架02
- 6Matlab生成随机数的一些命令_matlab随机生成数 并输出
- 7《Python自然语言处理》第二章 习题解答 练习6
- 8借助PLC-Recorder,西门子PLC S7-200SMART实现2ms周期采集的方法(带时间戳采集)_200smart时间超过一天怎么比较
- 9无人机在水利行业的应用
- 10VRay Next (4.0) for SketchUp之AO通道的设置与输出_su渲染ao图参数设置
一文读懂「RAG,Retrieval-Augmented Generation」检索增强生成
赞
踩
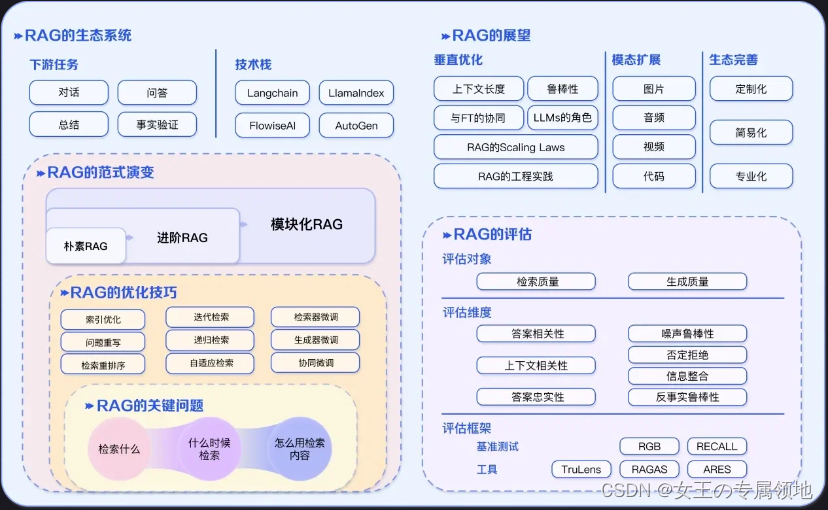
Retrieval-Augmented Generation(RAG)作为机器学习和自然语言处理领域的一大创新,不仅代表了技术的进步,更在实际应用中展示了其惊人的潜力。
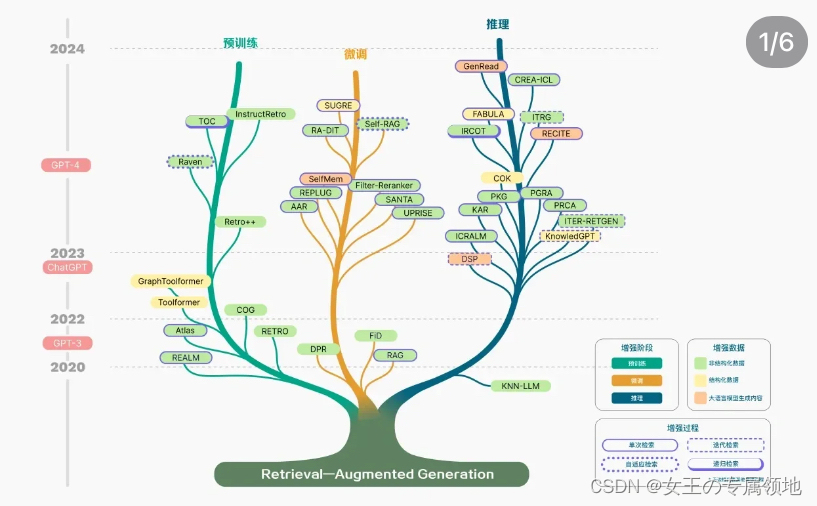
RAG结合了检索(Retrieval)和生成(Generation)两大核心技术,通过这种独特的混合机制,能够在处理复杂的查询和生成任务时,提供更加准确、丰富的信息。无论是在回答复杂的问题,还是在创作引人入胜的故事,RAG都展现了其不可小觑的能力。
一 、什么是RAG?
检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。它是一个为大模型提供外部知识源的概念,这使它们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。
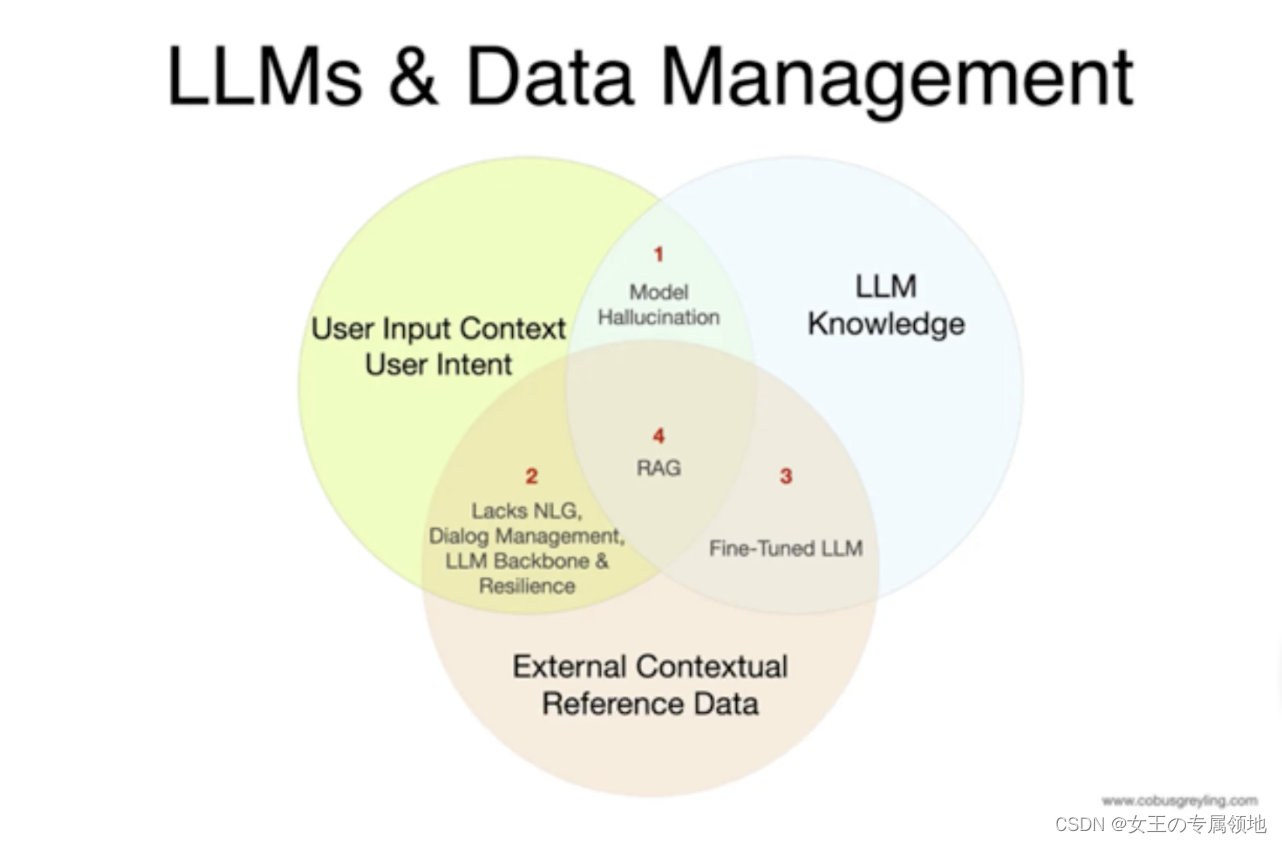
但是大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
- 知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
- 幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
而RAG是解决上述问题的一套有效方案。

二、RAG结构
简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
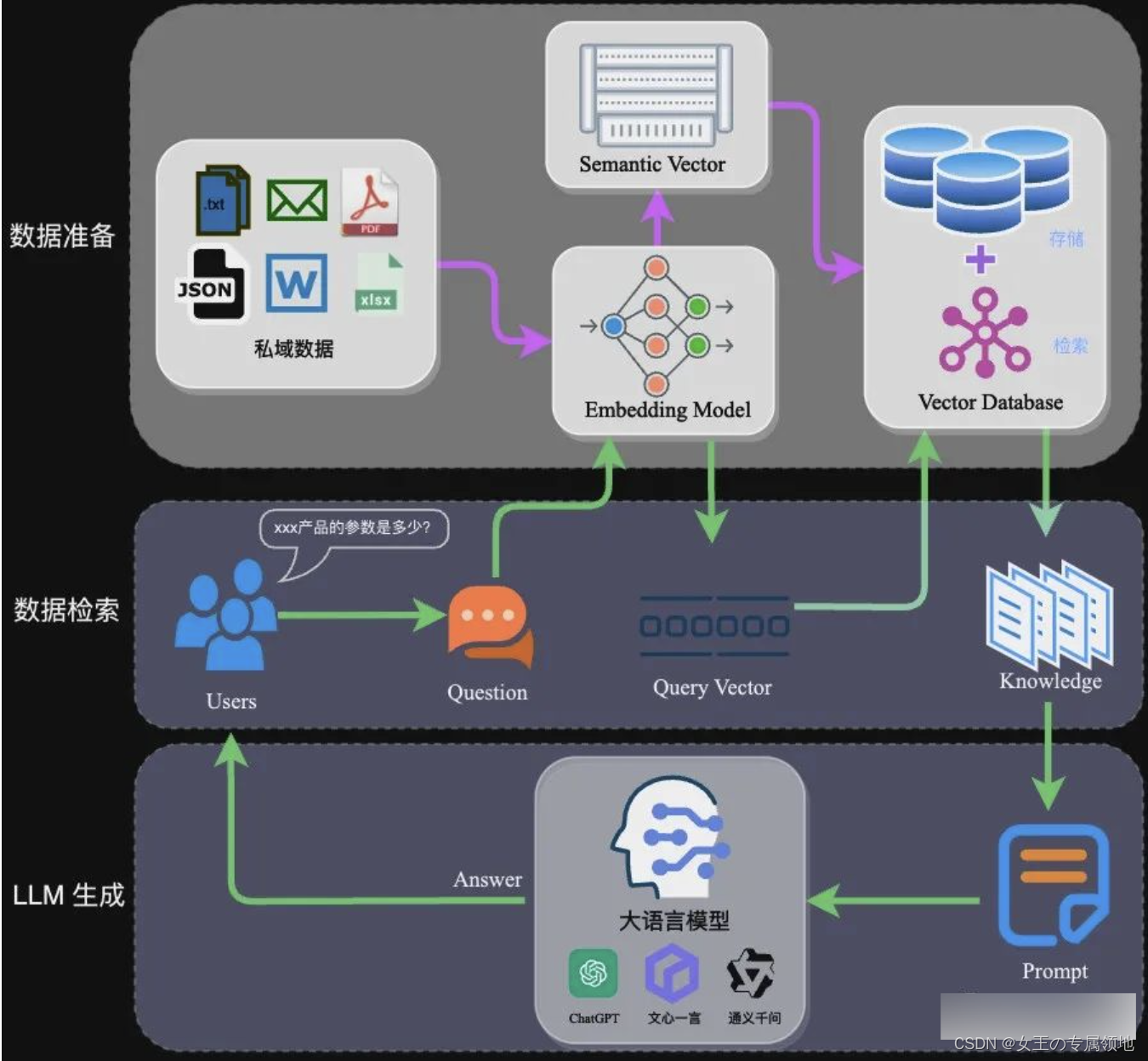
完整的RAG应用流程主要包含两个阶段:
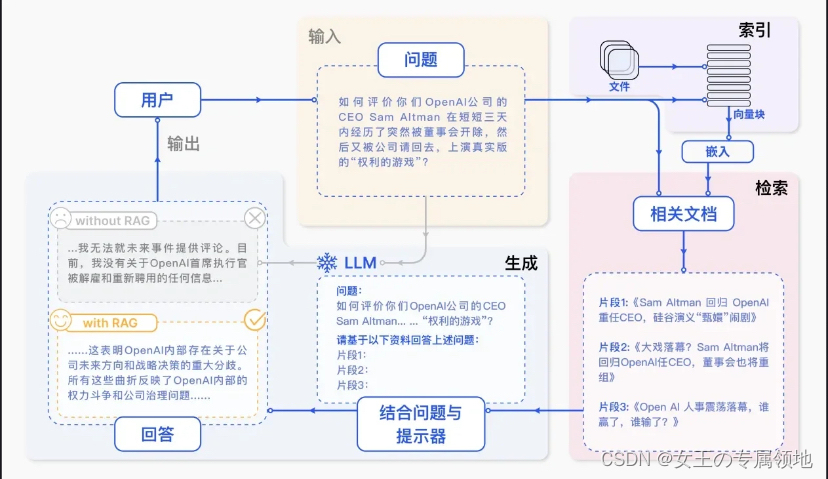
- 数据准备阶段:数据提取 >> 文本分割 >> 向量化(embedding) >> 数据入库
- 应用阶段:用户提问 >> 数据检索(召回) >> 注入Prompt >> LLM生成答案
2.1 数据准备阶段
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
数据提取
-
数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
-
数据处理:包括数据过滤、压缩、格式化等。
-
元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
文本分割
文本分割主要考虑两个因素:
- 1)embedding模型的Tokens限制情况;
- 2)语义完整性对整体的检索效果的影响。
一些常见的文本分割方式如下:
-
句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
-
固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
向量化(embedding)
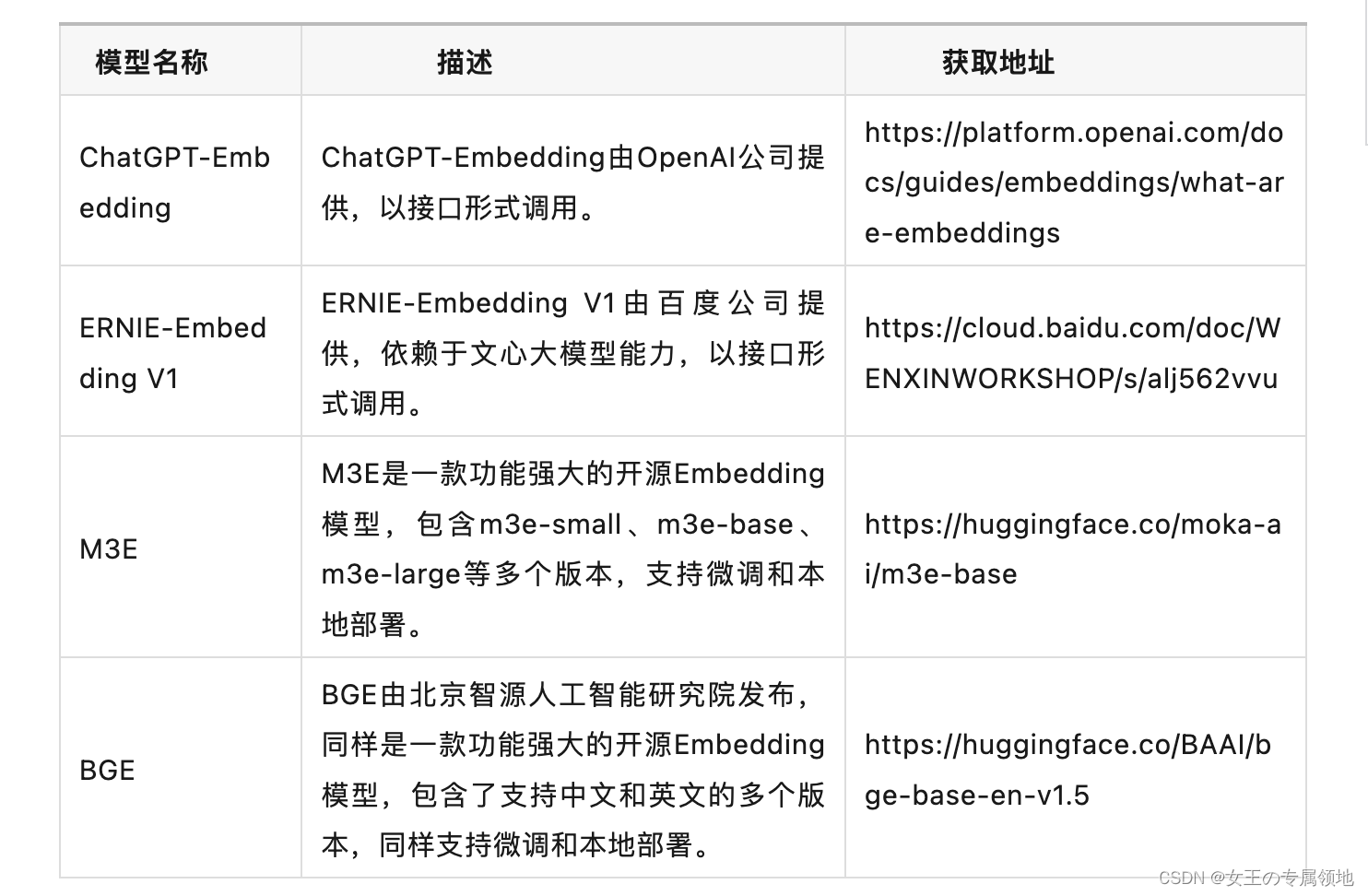
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如表中所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
数据入库
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
2.2 应用阶段
在应用阶段,我们根据用户的提问,通过高效的检索方法,召回与提问最相关的知识,并融入Prompt,大模型参考当前提问和相关知识,生成相应的答案。关键环节包括:数据检索、注入Prompt等。
数据检索
常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
-
相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
-
全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
注入Prompt
Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。一个简单知识问答场景的Prompt如下所示:
【任务描述】 假如你是一个专业的客服机器人,请参考【背景知识】,回 【背景知识】 {content} // 数据检索得到的相关文本 【问题】
石头扫地机器人P10的续航时间是多久?
Prompt的设计只有方法、没有语法,比较依赖于个人经验,在实际应用过程中,往往需要根据大模型的实际输出进行针对性的Prompt调优。

