
- 1springboot+mysql高校教学管理系统-计算机毕业设计源码32780
- 2手写一个RPC框架,我(小白)行,你(大佬)肯定行_手撸一个rpc框架
- 3python-jwt的生成和解析_python createjwt
- 4【位段】位段和结构体的区别
- 5VScode+esp-idf:安信可esp32-cam开发板测试sd卡_esp32cam sd卡
- 6Web SQL 学习笔记_could not prepare statement (1 not an error)
- 7easy connect for Mac 详细安装教程
- 82022-06-04 关于aliyun-java-vod-upload.jar包在maven中引入失败问题
- 9Stable Diffusion 黑白老照片上色修复_controlnet 修复老照片
- 1020 Debian如何配置DNS服务(2)主从服务器
CNN的具体架构VGG
赞
踩
VGG Net的背景
VGGNet由牛津大学计算机视觉组合和Google DeepMind公司研究员一起研发的深度卷积神经网络。它探索了卷积神经网络的深度和其性能之间的关系,通过反复的堆叠33的小型卷积核和22的最大池化层,成功的构建了16~19层深的卷积神经网络。VGGNet获得了ILSVRC 2014年比赛的亚军和定位项目的冠军,在top5上的错误率为7.5%。目前为止,VGGNet依然被用来提取图像的特征。
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
在VGG中使用了2个3x3卷积核来代替5x5卷积核,使用了3个3x3卷积核来代替7x7卷积核,这样在相同感受野的条件下,提升了网络的深度,同时也减少了参数。下面给出一幅图来加深理解:
使用VGG的优点

1.参数数量的减少: 使用三个3x3的卷积核代替一个7x7的卷积核可以显著减少参数的数量,一个7x7的卷积核包含49个参数,但是一个3x3的卷积核包含9个参数,三个则是27个参数,所以,通过使用三个3x3的卷积核,你减少了参数数量(49 vs 27),这意味着模型的训练需要的计算资源更少,同时也能加速前向传播和反向传播的过程。
2.捕获更复杂的特征: 通过层叠多个3x3卷积层,网络能够学习更复杂的特征表示。每通过一层3x3卷积核,输入的特征图(feature map)会经历一次非线性变换,通过增加卷积层的深度,模型能够捕获到更加复杂和抽象的特征,这对于处理高级视觉任务来说是非常有用的。
3.为什么每通过一次卷积层,经历非线性变换模型能够捕捉到更加复杂和抽象的特征? 每个卷积层后面通常会跟一个非线性激活函数(如ReLU)。当使用多个3x3卷积层代替单个7x7卷积层时,输入数据会经过更多的非线性激活函数,这有助于增加网络的非线性,并使得网络能够学习更加复杂的函数。
原因: 通过层叠多个卷积层,并在它们之间应用非线性激活函数,模型能够逐渐合成并提炼特征。第一层卷积可能捕捉到简单的边缘和纹理信息;随着更多层的叠加,通过前一层提取的特征可以结合成更复杂的模式,如物体的部分和结构。每经过一层非线性变换,网络就能进一步组合并丰富这些特征,捕捉到更高层次、更抽象的信息。
另外: 每次非线性变换后,特征的表达能够更加精细化,这有助于区分那些在低层次特征中无法区分的细微差异。例如,简单的边缘和角落特征经过多层处理后,可以变成对物体形状和纹理的具体描述,这为分类或检测任务提供了更加丰富的信息。
4.更有效的感受野管理: 感受野是卷积网络中的一个重要概念,指的是输出特征图中的每个元素对输入数据的覆盖区域大小。三个连续的3x3卷积层具有与一个7x7卷积层相同的感受野大小(即7x7)。这样,虽然感受野大小相同,但通过分解为更多层,网络可以更灵活地学习数据的层次性结构。
VGG16-D的背景
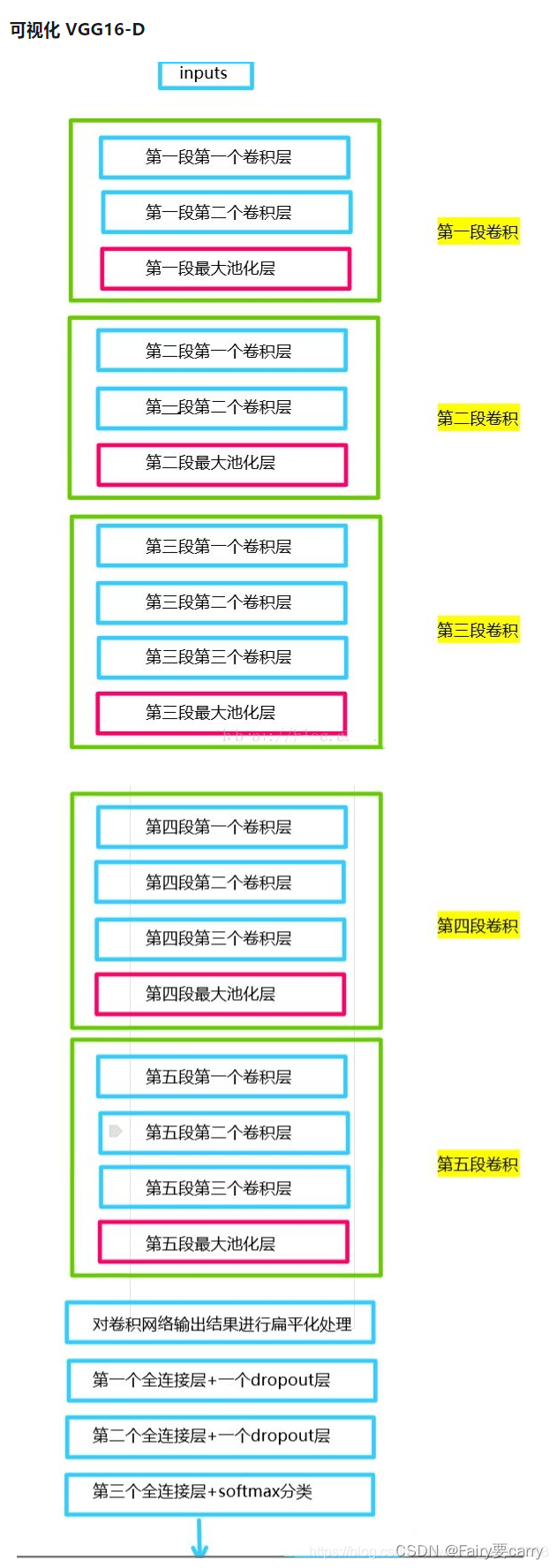
1.CNN和VGG概念上的区别
CNN是一种泛称,指的是使用卷积层、池化层和全连接层等结构的神经网络。它可以包含多种结构和设计,例如LeNet、AlexNet、VGG、ResNet等,每种结构都有其独特的特点和设计思路。而VGG是CNN的其中一种具体实现,是由Visual Geometry Group(牛津大学的研究团队)提出的一个具体的深度卷积神经网络架构。
2.网络结构的区别
CNN的结构比较灵活,可以根据任务和需求自定义卷积核大小、卷积层的数量、池化层的类型等。而VGG则是一种具体的网络结构,它使用了固定大小的3x3卷积核和2x2的最大池化层,并且在每个卷积块中卷积层的数量逐渐增加,这种设计使得VGG具有较深的网络结构。
3.网络深度
VGG相对于一些早期的CNN结构来说更深,例如LeNet和AlexNet。VGG-16和VGG-19分别包含16个和19个卷积层和全连接层,而一些其他的CNN结构可能层数较少。

