
- 1人脸表情识别相关研究_大学开展表情识别技术的相关研究工作
- 2当YOLOv5碰上PyQt5_yolov5加入pyqt5
- 3centos系列:【 全网最详细的安装配置Nginx,亲测可用,解决各种报错】_centos 安装nginx
- 4Python从入门到自闭(基础篇)
- 5EVO轨迹评估工具学习笔记_evo轨迹对准怎么从轨迹最开始对准
- 6学术英语视听说2听力原文_每天一套 | 高中英语听力专项训练(2)(录音+原文+答案)...
- 7深度解析:六个维度透视Claude3的潜能与局限_claude技术剖析
- 8git revert是个好东西_git revert 某个文件
- 9Jetson orin部署大模型示例教程_jetson部署
- 10YOLOv9:目标检测的新里程碑
全面解析 LLM 推理性能的关键因素_llm 事实性 问题 发散性 问题
赞
踩
一、背景介绍
自 OpenAI 一年前发布 ChatGPT 以来,大型语言模型(LLM)领域经历了前所未有的快速发展。在短短一年时间内,涌现出了数以百计的 LLM 模型,包括开源模型如 LLaMA、Mistral、Yi、Baichuan、Qwen,以及闭源模型如 Claude、Gemini 等。这些模型的出现不仅丰富了人工智能的应用领域,也对模型推理框架提出了新的挑战。
与传统的 AI 模型不同,LLM 的推理过程具有其独特性,简单套用传统 AI 模型的推理框架往往难以满足效率和性能的需求。因此,针对 LLM 的特点,业内出现了一系列专门的推理框架,如vLLM、Huggingface TGI、DeepSpeed-MII、NVIDIA 的 TensorRT-LLM,以及国内的 LMdeploy 等,这些框架旨在优化和加速 LLM 推理,简化部署流程。
然而,在目前的工业界和学术界,尚未形成一个统一且完善的 LLM 推理性能基准测试(Benchmark)工具。这意味着在进行 LLM 的私有化推理部署时,往往缺乏有效的参考基准,需要进行重复的性能评估,以在不同的条件和方案中做出最优选择。造成这一状况的主要原因是影响LLM 推理性能的因素众多且复杂,包括但不限于硬件类型、模型配置、数据分布以及采用的优化策略等。
本文旨在全面总结这些因素,通过对各种影响因素的分析和探讨,提供一个全景式的视角来指导LLM 的推理部署。我们的目标是帮助读者在面对多样化的部署选项时,能够以最小的代价做出充分且明智的评估,从而优化 LLM 应用。
二、LLM 推理介绍
2.1 LLM 推理过程
当前的主流 LLM 基本都是 Decoder Only 的 Transformer 模型,其推理过程可以分为两个阶段:
-
Prefill:根据输入 Tokens(Recite, the, first, law, of, robotics) 生成第一个输出 Token(A),通过一次 Forward 就可以完成,在 Forward 中,输入 Tokens 间可以并行执行(类似 Bert 这些 Encoder 模型),因此执行效率很高。
-
Decoding:从生成第一个 Token(A) 之后开始,采用自回归方式一次生成一个 Token,直到生成一个特殊的 Stop Token(或者满足用户的某个条件,比如超过特定长度) 才会结束,假设输出总共有 N 个 Token,则 Decoding 阶段需要执行 N-1 次 Forward,这 N-1 次 Forward 只能串行执行,效率很低。另外,在生成过程中,需要关注的 Token 越来越多(每个 Token 的生成都需要 Attention 之前的 Token),计算量也会适当增大。

2.2 KV Cache
如下图所示,在 LLM 推理中最关键的就是下图中的 Multi-Head Attention,其主要的计算集中在左图中灰色的 Linear(矩阵乘)和 Scaled Dot-Product Attention 中的 MatMul 矩阵乘法:
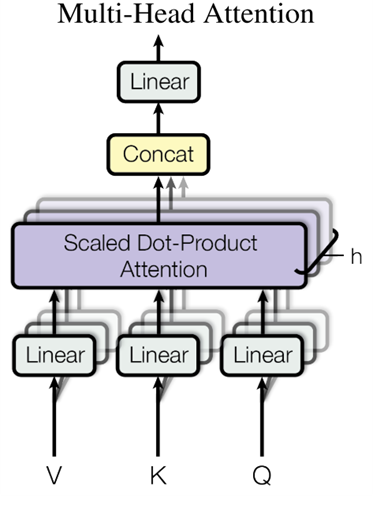
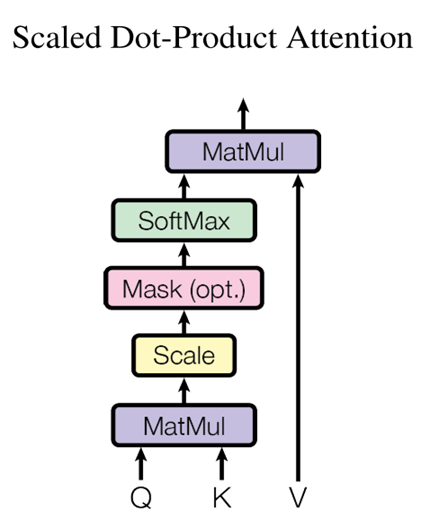
如上右图中的 Mask 是一个下三角矩阵,也是因为这个下三角矩阵实现了 LLM Decoder 的主要特性,每个 Token 都只能看到当前位置及之前的 Token。
如下图所示,其中的 QKT 可以理解为一个相关性矩阵,如动图所示,4 个 Token 对应 4 个 Step,其中:
-
Step 2 依赖 Step 1 的结果,相关性矩阵的第 1 行不用重复计算
-
Step 3 依赖 Step 1 和 Step 2 的结果,相关性矩阵的第 1 行和第 2 行不用重复计算
-
Step 4 依赖 Step 1、Step 2 和 Step 3 的结果,相关性矩阵的第 1 行、第 2 行和第 3 行不用重复计算
在 Decoding 阶段 Token 是逐个生成的,上述的计算过程中每次都会依赖之前的结果,此时最简单的思路就是 Cache 之前计算过的中间结果,在计算当前 Token 时直接从 Cache 中读取而不是重新计算,如下图所示,上面是没有 Cache 的情况,下面是有 Cache 的情况:
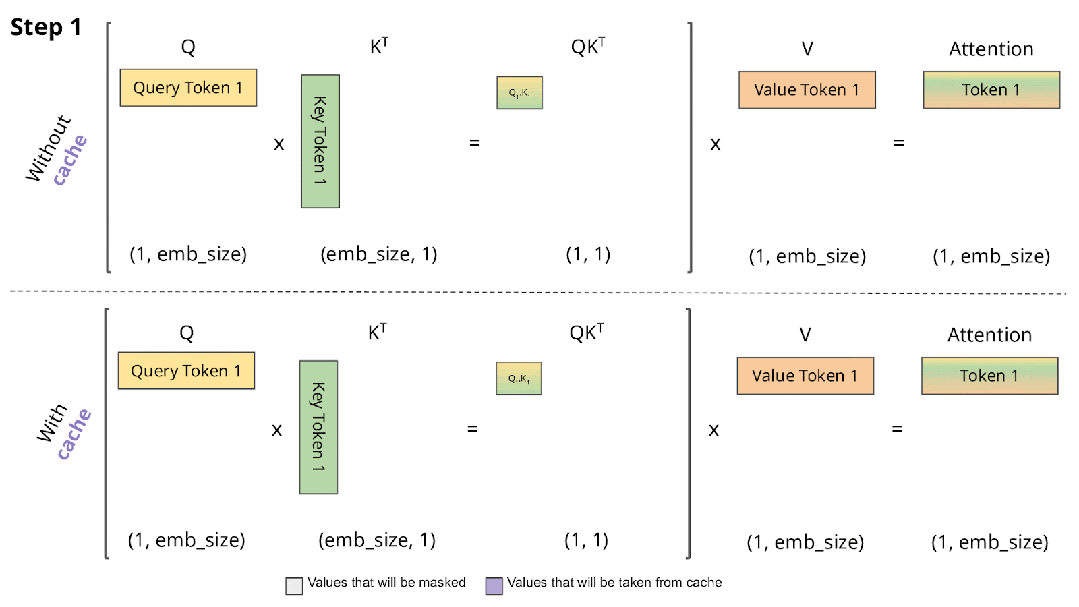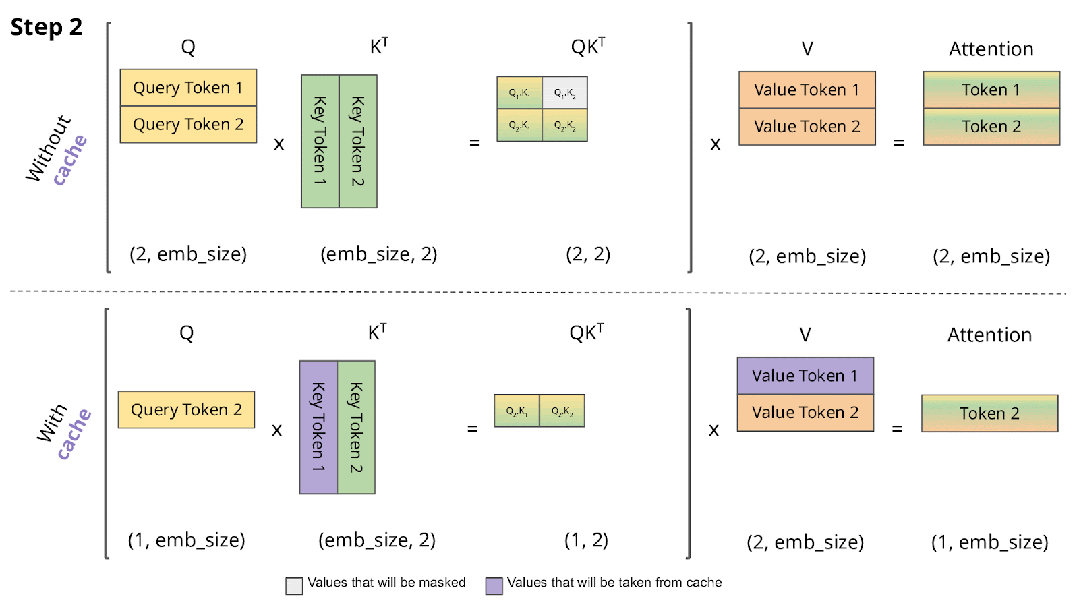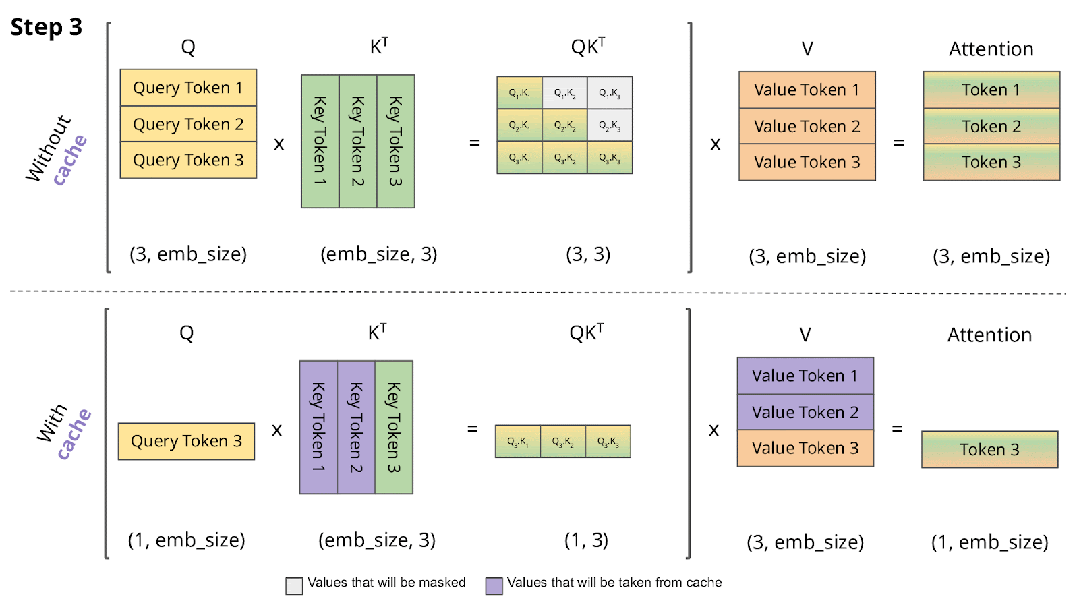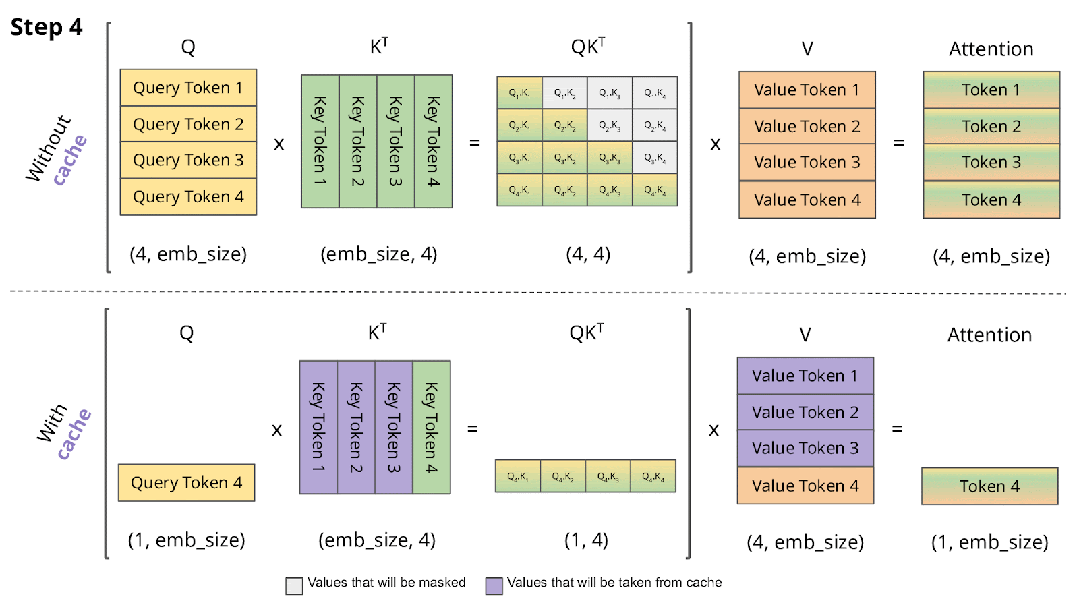
如下表所示,在 T4 GPU 上以 GPT2 模型为例验证有无 Cache 对推理时延的影响,其加速效果非常明显,因此也成为 LLM 推理的标配:
| GPT2/T4 |
无 KV Cache |
有 KV Cache |
加速比 |
| Output Token 1000 |
52.53s |
9.12s |
5.76x |
当然,KV Cache 也有一定不足,其相当于使用空间换时间,占用的显存会大幅增加,尤其是对于参数规模较大的模型。比如,对于 Vicuna-13B 模型(FP16 推理,其 Transformer layer num=40, embedding size=5120)来说,在 Sequence Length=1024,batch size=8 下,KV 缓存所占显存大小为 2 * 2 * 40 * 5120 * 1024 * 8 = 6.7G。
2.3 访存瓶颈
因为 Decoding 阶段 Token 逐个处理,使用 KV Cache 之后,上面介绍的 Multi-Head Attention 里的矩阵乘矩阵操作全部降级为矩阵乘向量。
除此之外,Transformer 模型中的另一个关键组件 FFN 中主要也包含两个矩阵乘法操作,但是 Token 之间不会交叉融合,也就是任何一个 Token 都可以独立计算,因此在 Decoding 阶段不用 Cache 之前的结果,但同样会出现矩阵乘矩阵操作降级为矩阵乘向量。
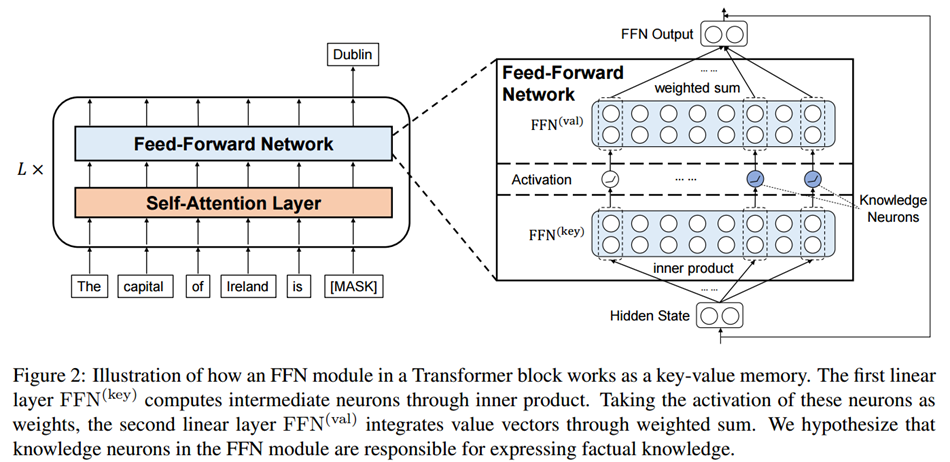
矩阵乘向量操作是明显的访存 bound,而以上操作是 LLM 推理中最主要的部分,这也就导致 LLM 推理是访存 bound 类型。
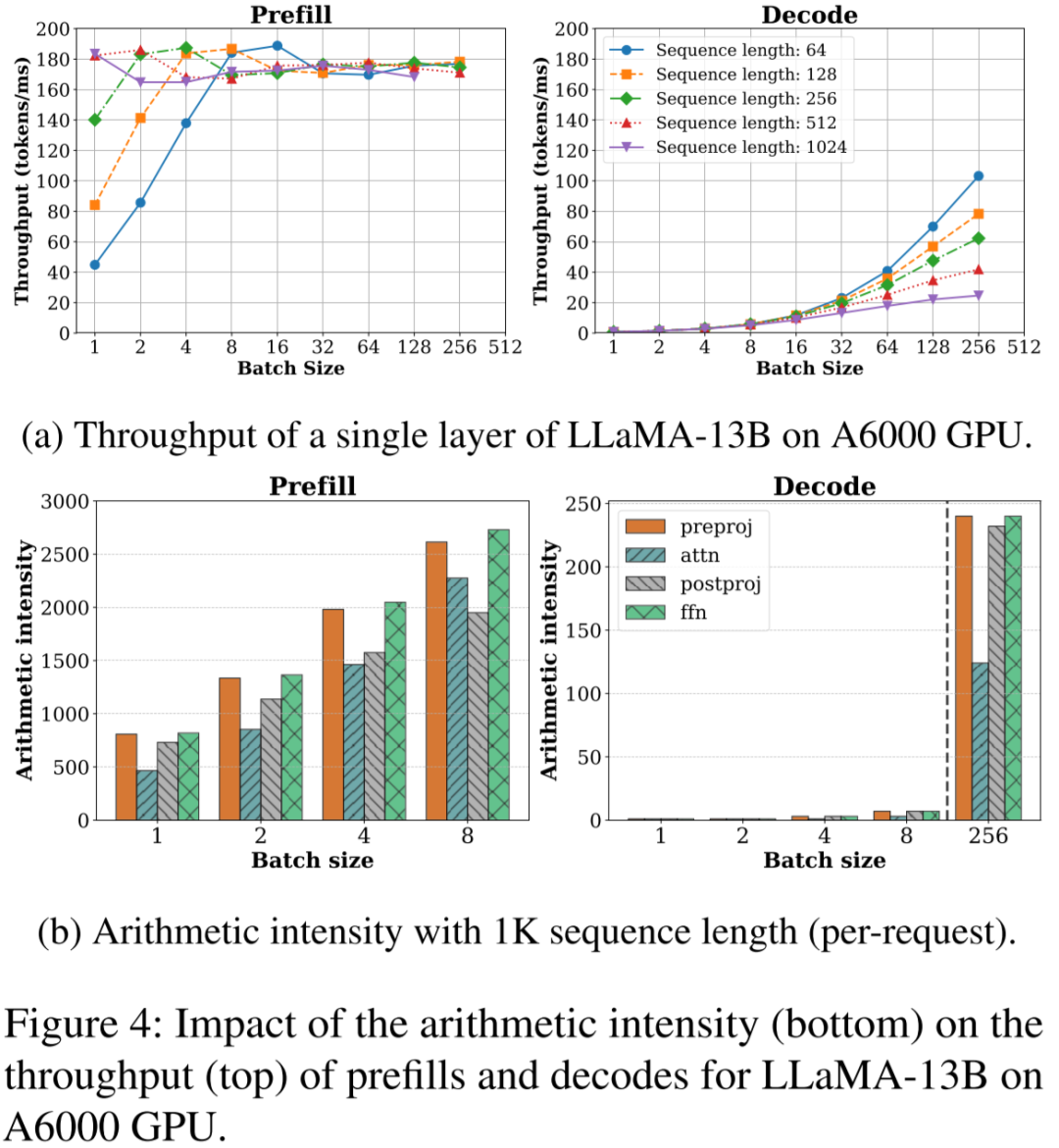
基于 V100 GPU,FP16 精度,LLM 推理 Prefill 阶段和 Decoding 阶段的 Roofline Model 可以近似表示如下(理论上限),其中
-
三角表示 Prefill 阶段:假设 Batch size 为 1,Sequence Length 越大,计算强度越大,通常都会位于 Compute Bound 区域。
-
圆表示 Decoding 阶段:Batch size 越大,计算强度越大,理论性能峰值越大,通常都会位于 Memory Bound 区域。
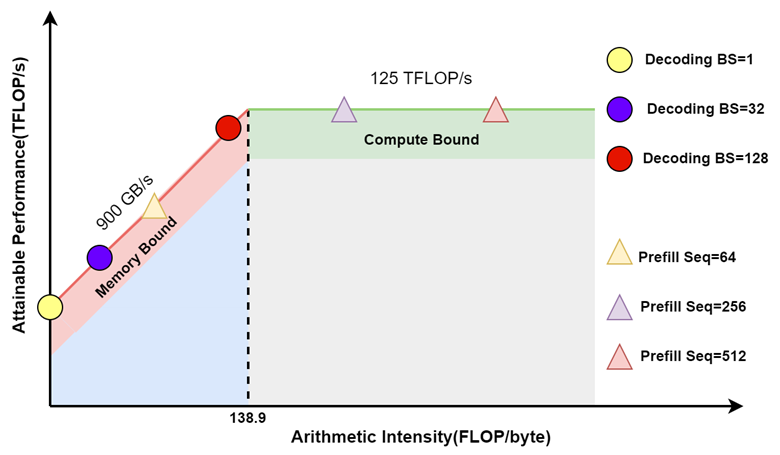
如下图所示,Prefill 阶段在比较小 Batch Size 下就可以获得比较大的计算强度,相应的吞吐也很高;而 Decoding 阶段需要比较大的 Batch Size 才能获得相对高的计算强度及吞吐(图片来自 [2308.16369] SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills ):
2.4 LLM 评估指标
针对 LLM 推理服务通常有两种调用模式,一种是传统的请求方式,一次请求获得所有的生成 Token,这种方式的好处是请求链路比较简单,但 LLM 推理的时间往往比较长,可能需要数秒,这也导致用户体验很不好;另一种是像 ChatGPT 一样的 Streaming 方式,其不是一次返回所有 Token,而是一边生成一边返回,只要生成速度大于人的阅读速度就能获得很好的用户体验。
针对上述的两种方式,也就引申出不同的评估指标。对于非 Streaming 模式,通常需要评估其整个请求的延迟(Latency),请求粒度的 QPS(Throughput);针对 Streaming 模式,通常需要评估第一个 Token 生成的时延(Time To First Token,TTFT)和后续每个 Token 的时延(Time Per Output Token,TPOT,也就对应每秒能生成的 Token 数目)。除此之外,在评估时延时通常也需要按照不同的维度评估,比如平均时延、P90 时延、P99 时延等。
除了以上的服务指标外,服务的成本也是需要考虑的重要因素,比如 V100、A100 和 H100 哪种硬件更适合 LLaMA 13B 模型的推理部署,成本更低?
2.5 影响 LLM 输出结果的因素
在进行 LLM 推理优化、性能评估时首先要保证生成结果的对齐,然而这并不总能保证,主要有以下几个影响因素:
-
低精度量化(KV Cache INT8、GPTQ INT4、AWQ INT4):必然会影响模型的输出结果。
-
采样参数:LLM 生成时会加上一些采样策略,以保证生成结果的丰富度,然而这些采样策略都会引入随机性,每次请求的结果会变,因此通常会首先会采用 Greedy Search 来去除随机性,等结果对齐之后再进一步打开引入随机性的采样策略。
-
Batching:LLM 推理中提升吞吐最主要的手段就是通过 Batching 充分发挥 GPU 算力,然而不同的 Batch Size 会导致 LLM 推理时采用不同的 CUDA Kernel(不同的算法),进而导致出现误差,而且 LLM 这种逐个 Token 生成的方式会导致误差累积,结果差异会进一步放大。
在 LLM 推理中,要想保证生成结果的严格对齐通常是很困难的,此时往往需要进一步地全面评估来验证效果。
三、LLM 推理影响因素
3.1 硬件环境
与常规的 AI 模型推理一样,LLM 也可以选择使用 GPU 推理或使用 CPU 推理,与传统 AI 模型不同的是,LLM 模型往往很大,需要大量的存储空间,单个推理实例比常规的 AI 模型大得多。比如一个常见的 13B LLM 为例,使用 FP16 精度,其仅模型参数就需要 13B * 2 = 26GB 的存储空间,甚至很多 GPU 显存(比如 T4 GPU 只有 15GB 可用显存)都不足以装下模型参数,更不用说 KV Cache 等临时存储。此时往往需要采用分布式多卡推理,而一个 T4 GPU 却足以容纳多个 ResNet50 或 Bert Base 模型实例。
此外,LLM 的两阶段推理特性(Prefill 和 Decoding)也为硬件选型带来了很大的挑战和可能,可以从一个 LLM 推理集群的角度去考虑,也可以从 LLM 推理服务或单个 LLM 推理实例的角度去考量硬件配置。
3.1.1 推理集群
微软和华盛顿大学在 [2311.18677] Splitwise: Efficient generative LLM inference using phase splitting 中提出了 Splitwise,作者专门构建了 LLM 推理集群,为 LLM 推理不同阶段选择不同的 GPU 类型,Prefill 阶段为计算密集型,可以选择高算力 GPU,而 Decoding 阶段为访存密集型,相应的可以使用算力不是特别强而访存带宽比较大的 GPU。同时为了两个阶段 KV cache 的共享,需要在 GPU 间有高速的 IB 网络互联。
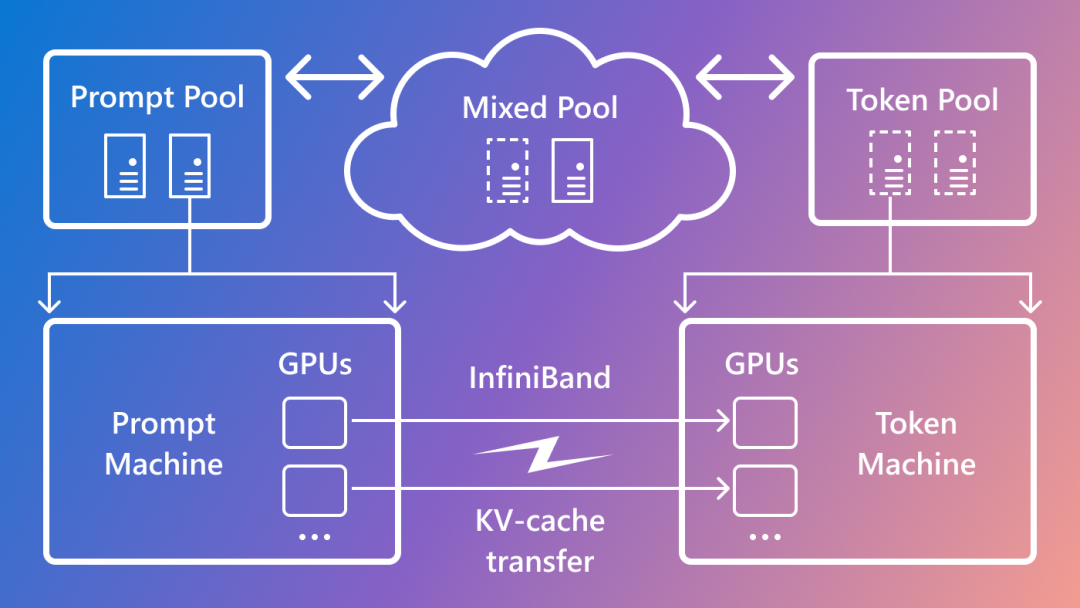
如下图 Figure 2 所示,在 [2310.18547] Punica: Multi-Tenant LoRA Serving 中,作者针对多租户、多 LoRA LLM 推理场景构建了 LLM 推理集群,以便降低 LLM 推理的成本。
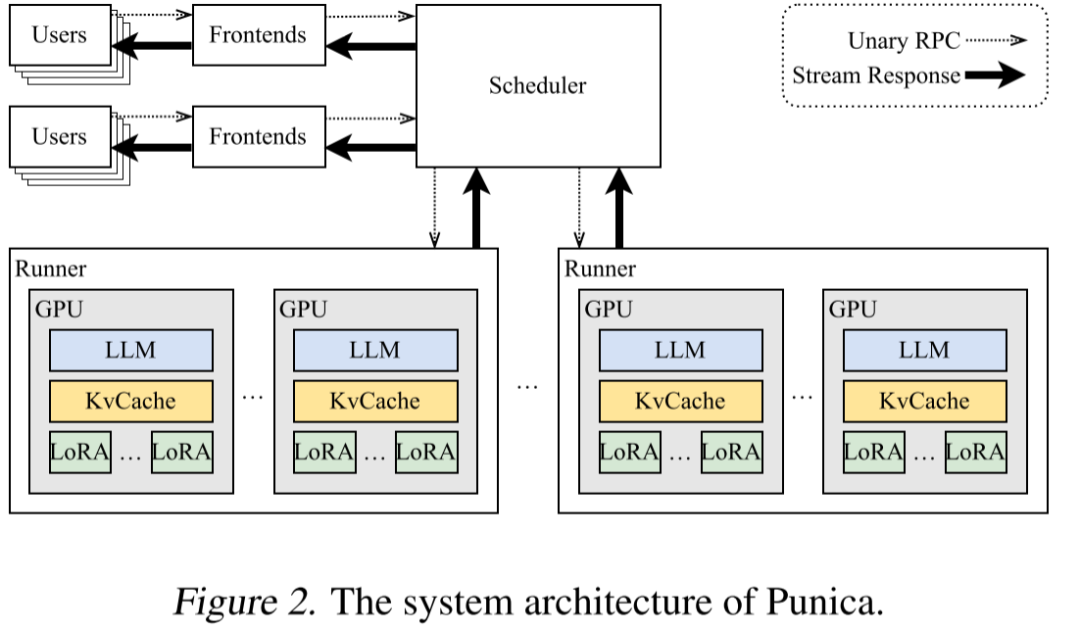
如下图 Figure 3 所示,在 [2311.15566] SpotServe: Servi

