
- 1Stable Diffusion使用样例实践(二)_realisticvisionv60b1
- 2多线程面试题_怎么控制同一时间只有 3 个线程运行?
- 3VSCode 中使用GO语言_vscode运行go语言
- 4python-flask项目的服务器线上部署
- 5Krpano:打造全景漫游体验—Layer详解_krpano坐标轴
- 6MySQL8.0.33二进制包安装与部署_mysql-8.0.33
- 7【图像处理与机器学习】贝叶斯决策_贝叶斯最小风险决策
- 8ssh: connect to host github.com port 22: Connection refused_connection refused could not read
- 9RabbitMQ在CentOS下的安装_centos 安装rabbitmq
- 10Langchain-chatchat本地部署_langchain-chatchat 本地 部署
利用python、tensorflow、opencv实现人脸识别(包会)!_tensorflow识别人
赞
踩
一,前言
本人是机械专业在读硕士,在完成暑假实践的时候接触到了人脸识别,对这一实现很感兴趣,所以花了大概十天时间做出了自己的人脸识别。这篇文章应该是很详细的了所以帮你实现人脸识别应该没什么问题。
先说本博文的最终要达到的效果:通过一系列操作,在摄像头的视频流中识别特定人的人脸,并且予以标记。
本人通过网上资料的查询发现这类人脸识别,大多参考了一位日本程序员小哥的文章。
链接:https://github.com/Hironsan/BossSensor
关于这个思路的人脸识别网上资料很多,但是有很多细节没有提到,我在实践的过程中菜过了无数的坑,希望我这篇文章能够对你提供更加清晰的思路和操作。先看结果(人丑勿怪)!这个是识别我的脸,别人的脸不会识别到

其实,这已经涉及到了一些机器学习的内容,对于像入门机器学习的同学来说是一个不错的练手的项目。
二、前期准备工作
首先说,我在刚开始接触的时候,主要是在各种数据包的安装上以及环境的配置上花费了巨大的时间,有些数据包升级版本之后与一些功能不兼容,出了很多问题,所以。我在这里说一下我的数据包的版本和python版本。现在可以用anaconda来下载python和各种数据包,但是最新的版本是用python3.6.X,在后面的实践中可能会出现不同的问题,所以为了安全起见python最好选择3.5.X的,不要安装2.X的,与3.X的版本不兼容,会出现很多问题。另外再安装一个tensorflow,pip,keras,sklearn,PIL,numpy,opencv等。其中keras要安装2.0版本的,opencv安装3.3.1版本的。tensorflow有CPU版本的和GPU版本的,你可以看一下你适合哪一种,这里贴出来一些供你参考:
您必须从以下 TensorFlow 类型中选择其一来进行安装:
仅支持 CPU 的 TensorFlow。如果您的系统没有 NVIDIA® GPU,则必须安装此版本。请注意,此版本的 TensorFlow 通常更容易安装(用时通常在 5 或 10 分钟内),所以即使您拥有 NVIDIA GPU,我们也建议先安 装此版本。预编译的二进制文件将使用 AVX 指令。
支持 GPU 的 TensorFlow。TensorFlow 程序在 GPU 上的运行速度通常要比在 CPU 上快得多。因此,如果您 的系统配有满足以下所示先决条件的 NVIDIA® GPU,并且您需要运行性能至关重要的应用,则最终应安装此 版本。
另外我在安装的过程中发现了几篇比较不错的博文供你参考:
1.https://blog.csdn.net/Eppley/article/details/79297503
2.https://blog.csdn.net/WJ_MeiMei/article/details/79684627
3.https://zhuanlan.zhihu.com/p/24055668
在几篇博文里你也会看到验证安装正确的方法,如果可以的话,说明你安装成功了,这里我就不多说了。后面的话你可能还会遇到别的什么问题,如果还需要安装什么模块的话,在安装也可以。
在硬件方面,你还需要一个USB摄像头。
总结:
-
USB摄像头一个;
-
python -- 3.5.X
-
tensorflow
-
opencv -- 3.3.1
-
keras -- 2.0.X
-
sklearn -- 0.19.0
三、正式开始
1,识别人脸
实现人脸识别简单程序没几行,但是我们要实现的是识别这个是谁的脸。首先我们让系统识别人脸,这是opencv的工作,我们只需要调用其中的API函数就可以了。下面是调用opencv实现对于人脸的识别。咱们在程序下面对程序进行一些解释:
-
-
- import cv2
- import sys
- from PIL import Image
-
- def CatchUsbVideo(window_name, camera_idx):
- cv2.namedWindow(window_name)
-
- #视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
- cap = cv2.VideoCapture(camera_idx)
-
- #告诉OpenCV使用人脸识别分类器
- classfier = cv2.CascadeClassifier("H:\\OpenCV\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml")
-
- #识别出人脸后要画的边框的颜色,RGB格式
- color = (0, 255, 0)
-
- while cap.isOpened():
- ok, frame = cap.read() #读取一帧数据
- if not ok:
- break
-
- #将当前帧转换成灰度图像
- grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
-
- #人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
- faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
- if len(faceRects) > 0: #大于0则检测到人脸
- for faceRect in faceRects: #单独框出每一张人脸
- x, y, w, h = faceRect
- cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
-
- #显示图像
- cv2.imshow(window_name, frame)
- c = cv2.waitKey(10)
- if c & 0xFF == ord('q'):
- break
-
- #释放摄像头并销毁所有窗口
- cap.release()
- cv2.destroyAllWindows()
-
- if __name__ == '__main__':
- if len(sys.argv) != 1:
- print("Usage:%s camera_id\r\n" % (sys.argv[0]))
- else:
- CatchUsbVideo("识别人脸区域", 0)

首先,第一行import cv2,实际上,”cv2”中的”2”并不表示OpenCV的版本号。我们知道,OpenCV是基于C/C++的,”cv”和”cv2”表示的是底层CAPI和C++API的区别,”cv2”表示使用的是C++API。这主要是一个历史遗留问题,是为了保持向后兼容性。PIL是一个模块,如果运行的过程中提示你缺少模块的时候你就要安装一个模块了,其余同理,就不再说了。另外在函数Catchusbvideo中,第二个参数指的是你电脑的摄像头的编号,例如是0,1,2等,如果0不行的话,试一下1。在下边的人脸识别分类器中是我自己下载的opencv,下载网站是:https://opencv.org/releases.html,如果你是windows选择对应版本就好,还有就是“H:\\OpenCV\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml”这是我安装的一个路径,你也要找到这个路径并且复制到程序中,这个东西的作用主要是实现对人脸识别的功能,在安装中还有其他的功能,我也一并列在下面:
人脸检测器(默认):haarcascade_frontalface_default.xml
人脸检测器(快速Harr):haarcascade_frontalface_alt2.xml
人脸检测器(侧视):haarcascade_profileface.xml
眼部检测器(左眼):haarcascade_lefteye_2splits.xml
眼部检测器(右眼):haarcascade_righteye_2splits.xml
嘴部检测器:haarcascade_mcs_mouth.xml
鼻子检测器:haarcascade_mcs_nose.xml
身体检测器:haarcascade_fullbody.xml
人脸检测器(快速LBP):lbpcascade_frontalface.xml
另外,如果我们想构建自己的分类器,比如识别火焰、汽车,数,花等,我们依然可以使用OpenCV训练构建。

对同一个画面有可能出现多张人脸,因此,我们需要用一个for循环将所有检测到的人脸都读取出来,然后逐个用矩形框框出来,这就是接下来的for语句的作用。Opencv会给出每张人脸在图像中的起始坐标(左上角,x、y)以及长、宽(h、w),我们据此就可以截取出人脸。其中,cv2.rectangle()完成画框的工作,在这里外扩了10个像素以框出比人脸稍大一点的区域。cv2.rectangle()函数的最后两个参数一个用于指定矩形边框的颜色,一个用于指定矩形边框线条的粗细程度。
运行结果:
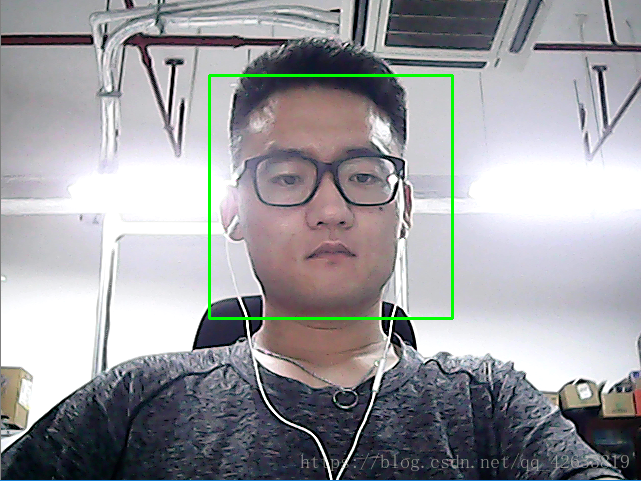
好,看来可以顺利的识别出视频中的脸,搞定!但是我们想做的是识别这个人脸是谁的,这仅仅能识别这是谁的脸,完全不能满足我们的渴望,接下来我们进行下一步!
2.模型训练
模型训练的目的是让电脑知道,这个脸的特征是什么,从而可以在视频流中识别。在训练之前必须先准备足够的脸部照片作为机器学习的资料。
2.1准备机器学习的资料
所谓机器学习就是给程序投喂足够多的资料,资料越多,准确度和效率也会越高。要想识别出这张人脸属于谁,我们肯定需要大量的自己的脸和别人的脸,这样才能区别开。然后将这些数据输入到Tensorflow中建立我们自己脸的模型。
1.keras简介
上面提到的日本小哥利用深度学习库keras来训练自己的人脸识别模型。 我这里找到一篇keras的中文文档可能对你有些帮助。另外关于Keras, Keras是由纯python编写的基于theano/tensorflow的深度学习框架。Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结果,如果有如下需求,可以优先选择Keras:
a)简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
b)支持CNN和RNN,或二者的结合
c)无缝CPU和GPU切换
Keras的模块结构:
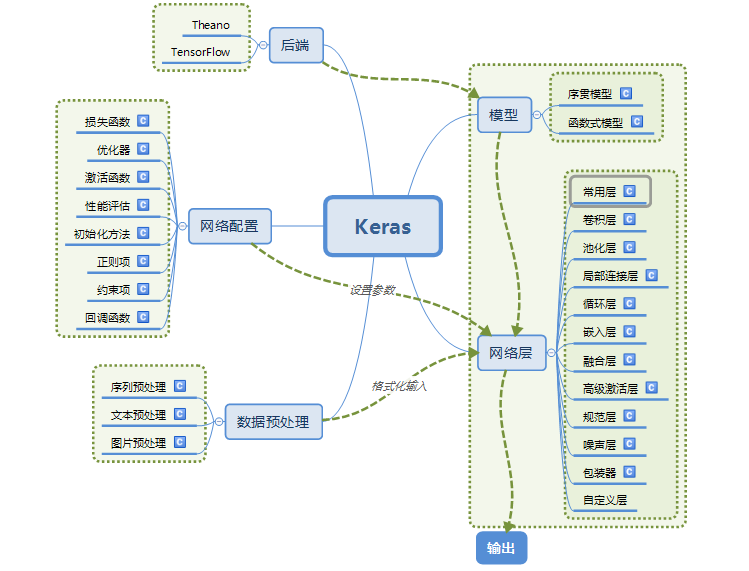
使用Keras搭建一个神经网络:
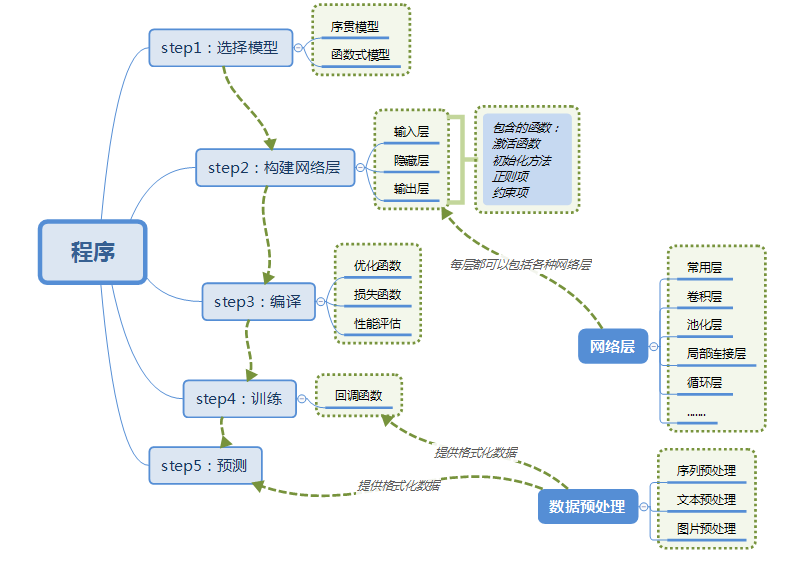
数据格式(data_format):
目前主要有两种方式来表示张量:
a) th模式或channels_first模式,Theano和caffe使用此模式。
b)tf模式或channels_last模式,TensorFlow使用此模式。
因为我装的是tensorflow因此我直接使用了keras的Tensorflow版,同时,为了验证其它深度学习库的效率和准确率,我还使用了Theano,利用CNN——卷积神经网络来训练我的人脸识别模型。本节专注把训练数据准备好。
完整代码如下:
-
-
- import cv2
- import sys
-
- from PIL import Image
-
- def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):
- cv2.namedWindow(window_name)
-
- #视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
- cap = cv2.VideoCapture(camera_idx)
-
- #告诉OpenCV使用人脸识别分类器
- classfier = cv2.CascadeClassifier("H:\\OpenCV\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml")
-
- #识别出人脸后要画的边框的颜色,RGB格式
- color = (0, 255, 0)
-
- num = 0
- while cap.isOpened():
- ok, frame = cap.read() #读取一帧数据
- if not ok:
- break
-
- grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #将当前桢图像转换成灰度图像
-
- #人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
- faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
- if len(faceRects) > 0: #大于0则检测到人脸
- for faceRect in faceRects: #单独框出每一张人脸
- x, y, w, h = faceRect
-
- #将当前帧保存为图片
- img_name = '%s/%d.jpg'%(path_name, num)
- image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
- cv2.imwrite(img_name, image)
-
- num += 1
- if num > (catch_pic_num): #如果超过指定最大保存数量退出循环
- break
-
- #画出矩形框
- cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
-
- #显示当前捕捉到了多少人脸图片了,这样站在那里被拍摄时心里有个数,不用两眼一抹黑傻等着
- font = cv2.FONT_HERSHEY_SIMPLEX
- cv2.putText(frame,'num:%d' % (num),(x + 30, y + 30), font, 1, (255,0,255),4)
-
- #超过指定最大保存数量结束程序
- if num > (catch_pic_num): break
-
- #显示图像
- cv2.imshow(window_name, frame)
- c = cv2.waitKey(10)
- if c & 0xFF == ord('q'):
- break
-
- #释放摄像头并销毁所有窗口
- cap.release()
- cv2.destroyAllWindows()
-
- if __name__ == '__main__':
- if len(sys.argv) != 1:
- print("Usage:%s camera_id face_num_max path_name\r\n" % (sys.argv[0]))
- else:
- CatchPICFromVideo("截取人脸", 0, 1000, 'C:\\Users\\Administrator\\Desktop\\Python\\data\\liziqiang')
这段代码我们只是在前面代码的基础上增加脸部图像存储功能,比较简单。
def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):在函数定义中,几个参数,反别是窗口名字,摄像头系列号,捕捉照片数量,以及存储路径。根据自己需要进行修改,咱们这里为了精度高一点,选择捕捉1000张脸部照片。在你捕捉的时候由于精度的问题,会捕捉许多非脸部的照片,这时候需要你将不是脸部的照片清洗掉,使数据更加准确。另外,我们还需要捕捉另一个人的图片来提高模型的准确度。然后存储到另一个文件夹下,注意,一个人的照片存储到一个文件夹下,不可弄混。截图完成,就像下图这样。
好了,经过前面的数据搜集,咱们已经差不多准备了2000张照片,准备工作已经做好,下面我们将进行数据模型的训练!
2.模型训练
训练程序建立了一个包含4个卷积层的神经网络(CNN),程序利用这个网络训练我的人脸识别模型,并将最终训练结果保存到硬盘上。在我们实际动手操练之前我们必须先弄明白一个问题——什么是卷积神经网络(CNN)?
想知道你可以谷歌,另外有关神经网络我会另外写一篇博客。这里就不多做介绍了。
首先建立一个python文件,命名load_dataset。代码如下:
-
- import os
- import sys
- import numpy as np
- import cv2
-
- IMAGE_SIZE = 64
-
- #按照指定图像大小调整尺寸
- def resize_image(image, height = IMAGE_SIZE, width = IMAGE_SIZE):
- top, bottom, left, right = (0, 0, 0, 0)
-
- #获取图像尺寸
- h, w, _ = image.shape
-
- #对于长宽不相等的图片,找到最长的一边
- longest_edge = max(h, w)
-
- #计算短边需要增加多上像素宽度使其与长边等长
- if h < longest_edge:
- dh = longest_edge - h
- top = dh // 2
- bottom = dh - top
- elif w < longest_edge:
- dw = longest_edge - w
- left = dw // 2
- right = dw - left
- else:
- pass
-
- #RGB颜色
- BLACK = [0, 0, 0]
-
- #给图像增加边界,是图片长、宽等长,cv2.BORDER_CONSTANT指定边界颜色由value指定
- constant = cv2.copyMakeBorder(image, top , bottom, left, right, cv2.BORDER_CONSTANT, value = BLACK)
-
- #调整图像大小并返回
- return cv2.resize(constant, (height, width))
-
- #读取训练数据
- images = []
- labels = []
- def read_path(path_name):
- for dir_item in os.listdir(path_name):
- #从初始路径开始叠加,合并成可识别的操作路径
- full_path = os.path.abspath(os.path.join(path_name, dir_item))
-
- if os.path.isdir(full_path): #如果是文件夹,继续递归调用
- read_path(full_path)
- else: #文件
- if dir_item.endswith('.jpg'):
- image = cv2.imread(full_path)
- image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE)
-
- #放开这个代码,可以看到resize_image()函数的实际调用效果
- #cv2.imwrite('1.jpg', image)
-
- images.append(image)
- labels.append(path_name)
-
- return images,labels
-
-
- #从指定路径读取训练数据
- def load_dataset(path_name):
- images,labels = read_path(path_name)
-
- #将输入的所有图片转成四维数组,尺寸为(图片数量*IMAGE_SIZE*IMAGE_SIZE*3)
- #我和闺女两个人共1200张图片,IMAGE_SIZE为64,故对我来说尺寸为1200 * 64 * 64 * 3
- #图片为64 * 64像素,一个像素3个颜色值(RGB)
- images = np.array(images)
- print(images.shape)
-
- #标注数据,'liziqiang'文件夹下都是我的脸部图像,全部指定为0,另外一个文件夹下是同学的,全部指定为1
- labels = np.array([0 if label.endswith('liziqiang') else 1 for label in labels])
-
- return images, labels
-
- if __name__ == '__main__':
- if len(sys.argv) != 1:
- print("Usage:%s path_name\r\n" % (sys.argv[0]))
- else:
- images, labels = load_dataset("C:\\Users\\Administrator\\Desktop\\Python\\data")
稍微解释一下resize_image()函数。这个函数的功能是判断图片是不是正方形,如果不是则增加短边的长度使之变成正方形。这样再调用cv2.resize()函数就可以实现等比例缩放了。因为我们指定缩放的比例就是64 x 64,只有缩放之前图像为正方形才能确保图像不失真。例如:

这样明显不是正方形。经过程序运行之后要达到这样的目的。

大概是这么个意思。
将你捕捉到的照片放在俩个不同的文件夹里,我在这里一块放在了data文件夹里。

然后再新建一个python文件,命名为:face_train。添加如下代码。
-
- import random
-
- import numpy as np
- from sklearn.cross_validation import train_test_split
- from keras.preprocessing.image import ImageDataGenerator
- from keras.models import Sequential
- from keras.layers import Dense, Dropout, Activation, Flatten
- from keras.layers import Convolution2D, MaxPooling2D
- from keras.optimizers import SGD
- from keras.utils import np_utils
- from keras.models import load_model
- from keras import backend as K
-
- from load_data import load_dataset, resize_image, IMAGE_SIZE
-
-
-
- class Dataset:
- def __init__(self, path_name):
- #训练集
- self.train_images = None
- self.train_labels = None
-
- #验证集
- self.valid_images = None
- self.valid_labels = None
-
- #测试集
- self.test_images = None
- self.test_labels = None
-
- #数据集加载路径
- self.path_name = path_name
-
- #当前库采用的维度顺序
- self.input_shape = None
-
- #加载数据集并按照交叉验证的原则划分数据集并进行相关预处理工作
- def load(self, img_rows = IMAGE_SIZE, img_cols = IMAGE_SIZE,
- img_channels = 3, nb_classes = 2):
- #加载数据集到内存
- images, labels = load_dataset(self.path_name)
-
- train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size = 0.3, random_state = random.randint(0, 100))
- _, test_images, _, test_labels = train_test_split(images, labels, test_size = 0.5, random_state = random.randint(0, 100))
-
- #当前的维度顺序如果为'th',则输入图片数据时的顺序为:channels,rows,cols,否则:rows,cols,channels
- #这部分代码就是根据keras库要求的维度顺序重组训练数据集
- if K.image_dim_ordering() == 'th':
- train_images = train_images.reshape(train_images.shape[0], img_channels, img_rows, img_cols)
- valid_images = valid_images.reshape(valid_images.shape[0], img_channels, img_rows, img_cols)
- test_images = test_images.reshape(test_images.shape[0], img_channels, img_rows, img_cols)
- self.input_shape = (img_channels, img_rows, img_cols)
- else:
- train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels)
- valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels)
- test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels)
- self.input_shape = (img_rows, img_cols, img_channels)
-
- #输出训练集、验证集、测试集的数量
- print(train_images.shape[0], 'train samples')
- print(valid_images.shape[0], 'valid samples')
- print(test_images.shape[0], 'test samples')
-
- #我们的模型使用categorical_crossentropy作为损失函数,因此需要根据类别数量nb_classes将
- #类别标签进行one-hot编码使其向量化,在这里我们的类别只有两种,经过转化后标签数据变为二维
- train_labels = np_utils.to_categorical(train_labels, nb_classes)
- valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
- test_labels = np_utils.to_categorical(test_labels, nb_classes)
-
- #像素数据浮点化以便归一化
- train_images = train_images.astype('float32')
- valid_images = valid_images.astype('float32')
- test_images = test_images.astype('float32')
-
- #将其归一化,图像的各像素值归一化到0~1区间
- train_images /= 255
- valid_images /= 255
- test_images /= 255
-
- self.train_images = train_images
- self.valid_images = valid_images
- self.test_images = test_images
- self.train_labels = train_labels
- self.valid_labels = valid_labels
- self.test_labels = test_labels
-
- #CNN网络模型类
- class Model:
- def __init__(self):
- self.model = None
-
- #建立模型
- def build_model(self, dataset, nb_classes = 2):
- #构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
- self.model = Sequential()
-
- #以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
- self.model.add(Convolution2D(32, 3, 3, border_mode='same',
- input_shape = dataset.input_shape)) #1 2维卷积层
- self.model.add(Activation('relu')) #2 激活函数层
-
- self.model.add(Convolution2D(32, 3, 3)) #3 2维卷积层
- self.model.add(Activation('relu')) #4 激活函数层
-
- self.model.add(MaxPooling2D(pool_size=(2, 2))) #5 池化层
- self.model.add(Dropout(0.25)) #6 Dropout层
-
- self.model.add(Convolution2D(64, 3, 3, border_mode='same')) #7 2维卷积层
- self.model.add(Activation('relu')) #8 激活函数层
-
- self.model.add(Convolution2D(64, 3, 3)) #9 2维卷积层
- self.model.add(Activation('relu')) #10 激活函数层
-
- self.model.add(MaxPooling2D(pool_size=(2, 2))) #11 池化层
- self.model.add(Dropout(0.25)) #12 Dropout层
-
- self.model.add(Flatten()) #13 Flatten层
- self.model.add(Dense(512)) #14 Dense层,又被称作全连接层
- self.model.add(Activation('relu')) #15 激活函数层
- self.model.add(Dropout(0.5)) #16 Dropout层
- self.model.add(Dense(nb_classes)) #17 Dense层
- self.model.add(Activation('softmax')) #18 分类层,输出最终结果
-
- #输出模型概况
- self.model.summary()
-
- #训练模型
- def train(self, dataset, batch_size = 20, nb_epoch = 10, data_augmentation = True):
- sgd = SGD(lr = 0.01, decay = 1e-6,
- momentum = 0.9, nesterov = True) #采用SGD+momentum的优化器进行训练,首先生成一个优化器对象
- self.model.compile(loss='categorical_crossentropy',
- optimizer=sgd,
- metrics=['accuracy']) #完成实际的模型配置工作
-
- #不使用数据提升,所谓的提升就是从我们提供的训练数据中利用旋转、翻转、加噪声等方法创造新的
- #训练数据,有意识的提升训练数据规模,增加模型训练量
- if not data_augmentation:
- self.model.fit(dataset.train_images,
- dataset.train_labels,
- batch_size = batch_size,
- nb_epoch = nb_epoch,
- validation_data = (dataset.valid_images, dataset.valid_labels),
- shuffle = True)
- #使用实时数据提升
- else:
- #定义数据生成器用于数据提升,其返回一个生成器对象datagen,datagen每被调用一
- #次其生成一组数据(顺序生成),节省内存,其实就是python的数据生成器
- datagen = ImageDataGenerator(
- featurewise_center = False, #是否使输入数据去中心化(均值为0),
- samplewise_center = False, #是否使输入数据的每个样本均值为0
- featurewise_std_normalization = False, #是否数据标准化(输入数据除以数据集的标准差)
- samplewise_std_normalization = False, #是否将每个样本数据除以自身的标准差
- zca_whitening = False, #是否对输入数据施以ZCA白化
- rotation_range = 20, #数据提升时图片随机转动的角度(范围为0~180)
- width_shift_range = 0.2, #数据提升时图片水平偏移的幅度(单位为图片宽度的占比,0~1之间的浮点数)
- height_shift_range = 0.2, #同上,只不过这里是垂直
- horizontal_flip = True, #是否进行随机水平翻转
- vertical_flip = False) #是否进行随机垂直翻转
-
- #计算整个训练样本集的数量以用于特征值归一化、ZCA白化等处理
- datagen.fit(dataset.train_images)
-
- #利用生成器开始训练模型
- self.model.fit_generator(datagen.flow(dataset.train_images, dataset.train_labels,
- batch_size = batch_size),
- samples_per_epoch = dataset.train_images.shape[0],
- nb_epoch = nb_epoch,
- validation_data = (dataset.valid_images, dataset.valid_labels))
-
- MODEL_PATH = './liziqiang.face.model.h5'
- def save_model(self, file_path = MODEL_PATH):
- self.model.save(file_path)
-
- def load_model(self, file_path = MODEL_PATH):
- self.model = load_model(file_path)
-
- def evaluate(self, dataset):
- score = self.model.evaluate(dataset.test_images, dataset.test_labels, verbose = 1)
- print("%s: %.2f%%" % (self.model.metrics_names[1], score[1] * 100))
-
- #识别人脸
- def face_predict(self, image):
- #依然是根据后端系统确定维度顺序
- if K.image_dim_ordering() == 'th' and image.shape != (1, 3, IMAGE_SIZE, IMAGE_SIZE):
- image = resize_image(image) #尺寸必须与训练集一致都应该是IMAGE_SIZE x IMAGE_SIZE
- image = image.reshape((1, 3, IMAGE_SIZE, IMAGE_SIZE)) #与模型训练不同,这次只是针对1张图片进行预测
- elif K.image_dim_ordering() == 'tf' and image.shape != (1, IMAGE_SIZE, IMAGE_SIZE, 3):
- image = resize_image(image)
- image = image.reshape((1, IMAGE_SIZE, IMAGE_SIZE, 3))
-
- #浮点并归一化
- image = image.astype('float32')
- image /= 255
-
- #给出输入属于各个类别的概率,我们是二值类别,则该函数会给出输入图像属于0和1的概率各为多少
- result = self.model.predict_proba(image)
- print('result:', result)
-
- #给出类别预测:0或者1
- result = self.model.predict_classes(image)
-
- #返回类别预测结果
- return result[0]
-
-
-
-
-
-
-
-
- if __name__ == '__main__':
- dataset = Dataset('./data/')
- dataset.load()
-
- model = Model()
- model.build_model(dataset)
-
- #先前添加的测试build_model()函数的代码
- model.build_model(dataset)
-
- #测试训练函数的代码
- model.train(dataset)
-
-
- if __name__ == '__main__':
- dataset = Dataset('./data/')
- dataset.load()
-
- model = Model()
- model.build_model(dataset)
- model.train(dataset)
- model.save_model(file_path = './model/liziqiang.face.model.h5')
-
-
- if __name__ == '__main__':
- dataset = Dataset('./data/')
- dataset.load()
-
-
- #评估模型
- model = Model()
- model.load_model(file_path = './model/liziqiang.face.model.h5')
- model.evaluate(dataset)
-
-
-
-
运行程序结果:
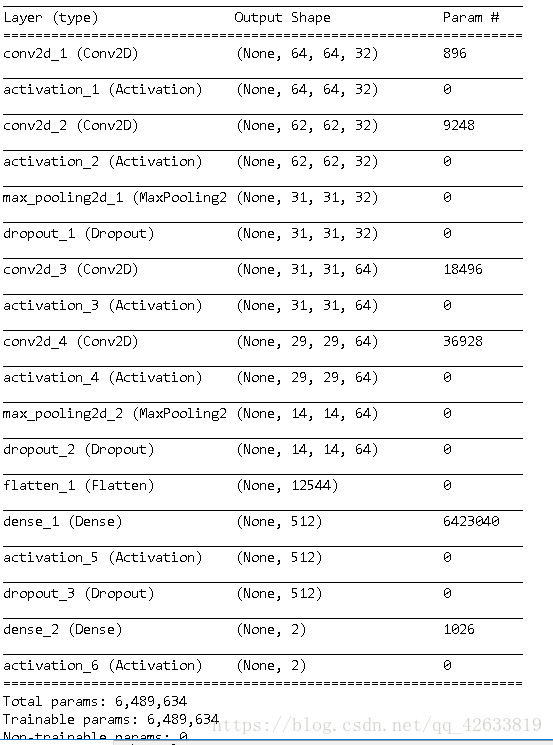
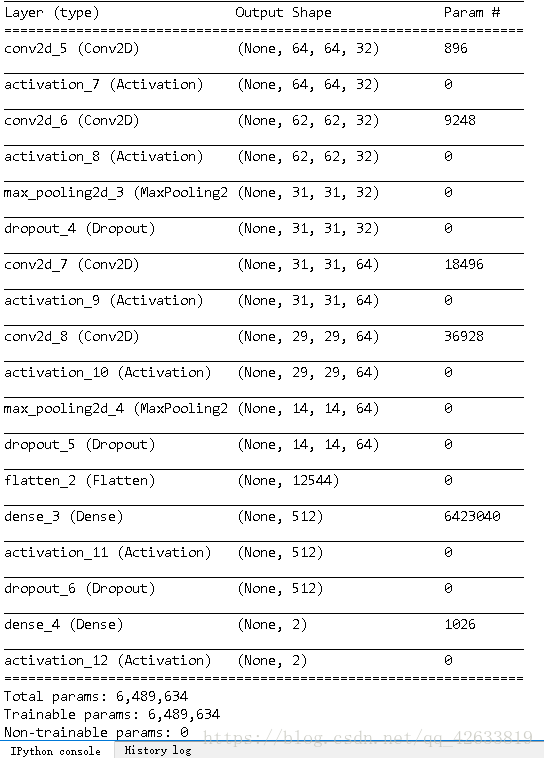

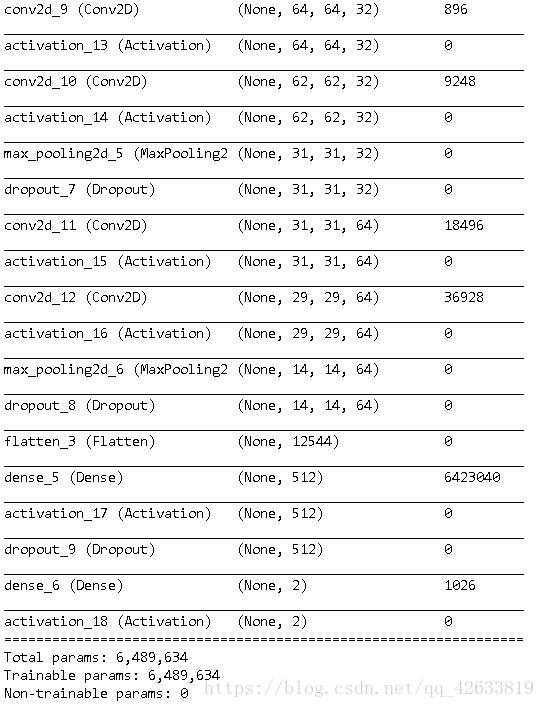

可以看到,最后我们对数据进行了验证,准确率达到了99.83%。结果较为理想,并且在model下面也得到了我i们的训练数据。

由此,我们最重要的训练数据也完成了,加下来就是验证我们训练数据的效果的时候了。
3、识别人脸
新建python文件,命名:Face_recognition。代码如下:
- #-*- coding: utf-8 -*-
-
- import cv2
- import sys
- import gc
- from face_train import Model
-
- if __name__ == '__main__':
- if len(sys.argv) != 1:
- print("Usage:%s camera_id\r\n" % (sys.argv[0]))
- sys.exit(0)
-
- #加载模型
- model = Model()
- model.load_model(file_path = './model/liziqiang.face.model.h5')
-
- #框住人脸的矩形边框颜色
- color = (0, 255, 0)
-
- #捕获指定摄像头的实时视频流
- cap = cv2.VideoCapture(0)
-
- #人脸识别分类器本地存储路径
- cascade_path = "H:\\opencv\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml"
-
- #循环检测识别人脸
- while True:
- ret, frame = cap.read() #读取一帧视频
-
- if ret is True:
-
- #图像灰化,降低计算复杂度
- frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
- else:
- continue
- #使用人脸识别分类器,读入分类器
- cascade = cv2.CascadeClassifier(cascade_path)
-
- #利用分类器识别出哪个区域为人脸
- faceRects = cascade.detectMultiScale(frame_gray, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
- if len(faceRects) > 0:
- for faceRect in faceRects:
- x, y, w, h = faceRect
-
- #截取脸部图像提交给模型识别这是谁
- image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
- faceID = model.face_predict(image)
-
- #如果是“我”
- if faceID == 0:
- cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 2)
-
- #文字提示是谁
- cv2.putText(frame,'liziqiang',
- (x + 30, y + 30), #坐标
- cv2.FONT_HERSHEY_SIMPLEX, #字体
- 1, #字号
- (255,0,255), #颜色
- 2) #字的线宽
- else:
- pass
-
- cv2.imshow("识别朕", frame)
-
- #等待10毫秒看是否有按键输入
- k = cv2.waitKey(10)
- #如果输入q则退出循环
- if k & 0xFF == ord('q'):
- break
-
- #释放摄像头并销毁所有窗口
- cap.release()
- cv2.destroyAllWindows()
好,最终实现的结果就是文章开头的时候的效果。希望能帮到你!
有什么问题我会尽量回答!

