
- 1算法设计与分析_练习三_动态规划算法_有两个数字序列,序列x和序列y,求这两个序列的最长公共子序列。
- 2 前端状态管理请三思
- 3如何在Python中安装TensorFlow_tensorflow怎么安装到python
- 4【文献阅读笔记】M2SNet: Multi-scale in Multi-scale Subtraction Network for Medical Image Segmentation
- 5【强化学习】常用算法之一 “DQN”_dqn公式
- 6nlohmann/json学习使用及示例
- 7什么是0day漏洞,1day漏洞和nday漏洞?
- 8【Java每日面试题】大厂是如何设计秒杀系统的?,2024年最新java开发工程师面试问题汇总
- 9pyside2 环境配置 mac M1_macbook安装pyside2
- 10Mybatis-Plus 3.2.0 版本 MetaObjectHandler 无法进行公共字段全局填充_metaobjecthandler 和 自定义xml 冲突
论文:Look Before You Leap: Learning Landmark Features for One-Stage Visual Grounding_look before you leap: improving text-based person
赞
踩
作者

Abstract
An LBYL (‘Look Before You Leap’) Network is proposed for end-to-end trainable one-stage visual grounding. The idea behind LBYL-Net is intuitive and straightforward: we follow a language’s description to localize the target object based on its relative spatial relation to‘Landmarks’, which is characterized by some spatial positional words and some descriptive words about the object. The core of our LBYL-Net is a landmark feature convolution module that transmits the visual features with the guidance of linguistic description along with different directions. Consequently, such a module encodes the relative spatial positional relations between the current object and its context. Then we combine the contextual information from the landmark feature convolution module with the target’s visual features for grounding. To make this landmark feature convolution light-weight, we introduce a dynamic programming algorithm (termed dynamic max pooling) with low complexity to extract the landmark feature. Thanks to the landmark feature convolution module, we mimic the human behavior of‘Look Before You Leap’ to design an LBYL-Net, which takes full consideration of contextual information. Extensive experiments show our method’s effectiveness in four grounding datasets. Specifically, our LBYL-Net out-performs all state-of-the-art two-stage and one-stage methods on ReferitGame. On RefCOCO and RefCOCO+, Our LBYL-Net also achieves comparable results or even better results than existing one-stage methods. Code is available at https://github.com/svip-lab/LBYLNet.
一个LBYL (’ Look Before You Leap ')网络被提出用于端到端可训练的单阶段视觉接地。LBYL-Net背后的思想是直观和直接的:我们遵循一种语言的描述,根据目标对象与“地标”的相对空间关系来定位目标对象,“地标”的特征是一些空间位置词和一些关于对象的描述性词。我们的LBYL-Net的核心是一个标志性的特征卷积模块,它在语言描述的引导下,将视觉特征沿不同方向进行传输。因此,该模块编码当前对象与其上下文之间的相对空间位置关系。然后将地标特征卷积模块中的背景信息与目标的视觉特征相结合进行接地。为了使该路标特征卷积轻量化,我们引入了一种低复杂度的动态规划算法(称为动态最大池算法)来提取路标特征。借助标志性的特征卷积模块,我们模拟了“look Before You Leap”的人类行为,设计了一个充分考虑上下文信息的LBYL-Net。在4个接地数据集上的大量实验表明了该方法的有效性。具体来说,我们的LBYL-Net在ReferitGame中优于所有最先进的两阶段和一阶段方法。在RefCOCO和RefCOCO+上,我们的LBYL-Net也实现了可比的结果,甚至比现有的单阶段方法更好的结果。代码可以在https://github.com/svip-lab/LBYLNet上找到。
Introduction

人类通常通过描述物体与其他实体的关系来指代图像中的物体。“桌上的笔记本电脑”,理解它们之间的关系对于理解参考性表达至关重要。视觉接地是为了定位引用表达式所描述的实体,它本质上需要上下文信息来接地目标。通过考虑对象的关系,最近的一些研究取得了很有希望的结果[44,24,9,43]。特别是,这些方法通常利用两阶段范式,首先提取区域提议作为候选,然后将区域表达式对作为度量学习的一种方式进行排序。
两阶段方法虽然有效,但存在以下缺陷:(1)两阶段方法时间复杂度大,影响了方法的实时性;(2)由于只考虑预定义类别中的物体,可能无法充分利用整个场景中的语境线索。在单阶段检测成功的激励下[28,19],基于单阶段的视觉接地获得了极大的兴趣,它通过同时检测和匹配范式简化了流水线,加速了推理[39,29]。然而,这些基于检测的单阶段方法仍然可以独立地对网格特征进行定位。整个场景的语境信息,特别是物体之间的关系,还没有被深入研究,不如两阶段的场景。
从这个角度来看,在一个阶段的视觉基础上启用关系建模是理想的,因为对象需要感知语言中提到的关系实体来定位自己,例如。“上面有猫头鹰的椅子”。我们通过引入地标特征Landmark Features和地标特征卷积Landmark Feature Convolution的概念,使网格特征能够捕获丰富的上下文线索,从而更好地进行定位。
首先,在我们的现实生活中,我们通常通过一个容易注意到的建筑来判断我们的位置或其他建筑的位置,这被称为地标。同样,在视觉接地的图像域中,地标可以看作是对目标定位有帮助的位置。图1显示了给定查询语言的图像中地标的可视化。这些地标可能落在背景上,其他物体或物体本身,只要它们有有用的语义线索。该网络可以从这些地标中提取包含全局上下文信息的地标特征。为了充分整合上下文信息以提高定位,这些地标特征从不同方向传播到目标对象,通过一种高效的动态规划算法termedDynamic Max Pooling来描述相对位置。通过标准的卷积运算聚合地标特征,网格特征具有(i)全局接收域(ii)方向感知功能。我们称整个过程为地标特征卷积。
考虑到长期的背景,我们提出了一种新颖的单阶段视觉基础框架。我们的网络首先采用特征金字塔网络(FPN)[15]提取不同尺度下的目标视觉特征,该方法的有效性得到了较好的目标定位。然后利用地标特征卷积从不同方向提取对象的上下文信息,以便更好地描述表达式中提到的对象之间的关系。由于我们在视觉基础上模仿了人类的“三思而后行”行为,我们将我们的方法称为LBYL-Net。
我们的主要贡献总结如下:
- 我们提出了一种基于LBYL-Net的单级视觉接地方法,该方法结合了所述对象的视觉特征以及不同对象之间空间关系的地标特征进行目标定位;
- 提出了一种具有全局接收域但不引入额外参数和复杂度的地标特征卷积。我们展示了它相对于相关卷积模块的优越性。扩张卷积[41],变形卷积[4]和非局部模块[34]。
- 在4个接地数据集上进行了大量的实验,结果表明了该方法的有效性和有效性。特别是,我们的方法在ReferitGame上获得了最先进的性能。
Related Work
Two-Stage Visual Grounding.
可能是有证据表明,感兴趣的区域可以提供更好的个体实体本地化,并容易建立它们的关系联系,两阶段已成为一段时间以来的事实方法。通常,不同的方法在表示上下文的方式上是不同的。Maoet al.[23]和Huet al.[10]使用整个图像作为全局上下文,而Y uet al.[44]直接从附近的物体中提取视觉特征作为建模视觉差异的一种方式,表明关注物体之间的关系可以获得更好的结果。将[24,9]中的上下文作为未标注对象的弱监督信号,采用多实例学习[7],最大限度地提高所有对象对的联合似然。然而,上面的建模可能会将上下文对象的数量简化为一个固定的大小,例如,一个对象作为上下文信息。为此,Zhanget al.[47]利用变分贝叶斯框架,在所有对象上生成一个作为上下文信息的注意图来近似组合上下文配置。对于更详细的视觉语言对齐,注意机制也被广泛应用于分割语言以匹配目标或上下文对象[5,43,48]。与它们不同的是,我们认为情境可以在整个场景中任意呈现,并将它们完全整合成一个单阶段框架。
One-Stage Visual Grounding.
在使用一级目标检测器之前,已经有几种方法尝试直接从整个图像中还原出边界框。然而,这些框架经常遭受对象回收率较低的问题,这使得它们低于两阶段的对应框架。采用基于注意的方法增强目标[8]的局部特征。此外,Y eet al.[40]使用子窗口搜索来找到能量函数最小的位置。受著名的单阶段检测器(如YOLO [28], SSD[19])的鼓励,许多最近的单阶段方法都将提议视为特征图中的网格,并直接从负责检测的网格特征回归边界盒[39,29]。虽然与直接从整个图像回归对象相比有很大的改进,但这种进步可能归功于网格上的鲁棒局部特征表示。另一个改进单阶段视觉基础的方法是应用复杂的语言建模,例如将较长的短语分解为多个部分[38]。在这项工作中,我们没有使用复杂的技术来进行语言建模。我们表明,只要简单地考虑场景中的上下文,我们的网络就可以显示竞争结果。
Landmark Feature Convolution
我们首先总结了最常见的卷积,将其归类为基于点的抽样策略,并讨论了它们的关系、优势和局限性。然后,我们介绍了我们提出的基于区域的采样策略,然后是里程碑特征卷积及其制定和实现
3.1. Point-based Sampling

给定输入特征映射 X = { x v : v ∈ V } X = \{x_v: v∈V\} X={
xv:v∈V},节点特征 x v ∈ R c x_v∈\R^c xv∈Rc,基于点的卷积学习表示向量 y v y_v yv通过:
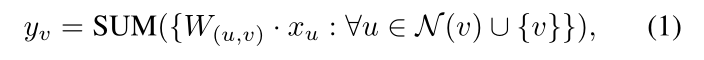
其中 v ∈ V v∈V v∈V表示节点的位置, N ( v ) \mathcal{N }(v) N(v)是节点 v v v的邻域, W ( u , v ) W_{(u,v)} W(u,v)参数化了节点 u u u和节点 v v v的空间关系。在图像特征映射的上下文中,节点与位置相同,因此我们可以交替使用这两种符号。不同的卷积有不同的采样策略 N ( v ) \mathcal{N}(v) N(v),也就是说,我们如何对卷积的节点进行采样来表示输出向量 y v y_v yv。
Standard Convolution.
在3 × 3卷积核中,使用正则网格窗口 R \mathcal{R} R,可以表示为偏移列表。然后取样邻居N (v),或者我们叫感受域,等于

