
热门标签
热门文章
- 1Python机器学习、数据统计分析在医疗中的应用_python在医学上的应用
- 2集成学习之Bagging_集成学习bagging
- 3git和github的关系_git和github 什么关系
- 4人脸检测(勿喷)_人脸检测如何判断是否为完整人脸
- 5以太坊常用网址_imtoken官方正版官网入口
- 6Python 异步编程(Async/Await)_async def python
- 7创建一个javascript公共方法的npm包,js-tool-big-box,发布到npm上,一劳永逸_npm 组件库里添加公共方法工具
- 8最佳路径搜索(一):盲目搜索(深度优先,广度优先,深度限制,迭代加深)_盲目搜索算法 第一关广度优先搜索头歌
- 9小红书笔记api_万维易源-小红书单个笔记详细数据
- 10python获取excel部分数据_#python读取excel莫个页签sheets()行数,并且获取里边的内容。#python读取excel表格的部分数据...
当前位置: article > 正文
随机森林算法详解_随机森林的算法概述
作者:weixin_40725706 | 2024-06-24 19:58:08
赞
踩
随机森林的算法概述
随机森林算法详解
随机森林(Random Forest)是一种集成学习方法,通过构建多个决策树并将它们的预测结果结合起来,来提高模型的准确性和稳定性。随机森林在分类和回归任务中都表现出色,广泛应用于各类机器学习问题。本文将详细介绍随机森林的原理、特点、优缺点、常见应用场景以及示例代码。
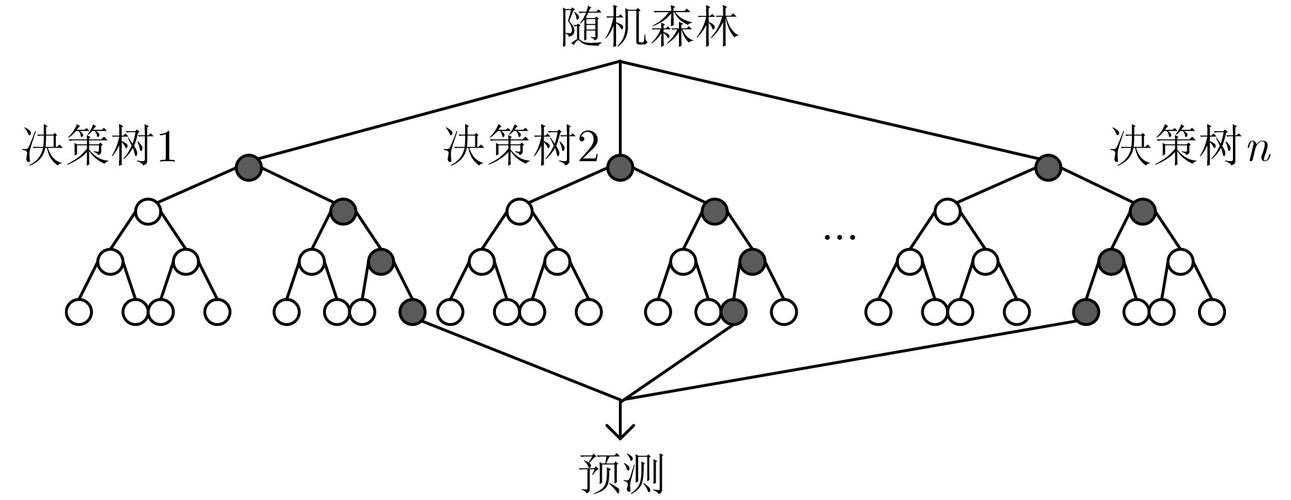
随机森林原理
随机森林的核心思想是通过构建多个决策树并将它们的预测结果结合起来,从而减少单个模型的过拟合,提高模型的泛化能力。其基本步骤如下:
- 样本采样:通过Bootstrap抽样方法,从原始训练集中有放回地随机抽取多个子集,每个子集用于训练一个决策树。
- 特征采样:在构建每个决策树时,对于每次分裂,只随机选择部分特征进行分裂选择,增加模型的多样性。
- 决策树训练:对于每个子集,构建一棵决策树。决策树的深度通常较大,不进行剪枝。
- 结果融合:对于分类问题,采用多数投票法将所有树的预测结果进行投票;对于回归问题,取所有树的预测平均值。
核心机制
- Bootstrap抽样:通过从原始数据集中有放回地抽样,生成多个不同的训练子集,确保每个决策树的训练数据不同。
- 随机特征选择:在每次分裂时随机选择部分特征,增加了树的差异性,降低了过拟合的风险。
- 多数投票与平均值:通过将多个决策树的结果进行融合,平滑了单个树的噪声,提高了模型的稳定性和准确性。
随机森林特点
优点
- 抗过拟合能力强:通过构建多个决策树并进行结果融合,随机森林有效降低了过拟合的风险。
- 处理高维数据:随机特征选择机制使得随机森林能够处理高维数据,尤其在特征数量远大于样本数量的情况下表现优异。
- 稳定性强:对训练数据的噪声和异常值不敏感,具有较高的鲁棒性。
- 易于并行化:每棵树可以独立训练,天然适合并行计算,训练速度较快。
- 特征重要性评估:能够评估各个特征的重要性,提供有用的特征选择信息。
缺点
- 计算资源消耗大:训练和预测过程中需要构建和存储大量决策树,对内存和计算资源要求较高。
- 模型解释性差:相比单棵决策树,随机森林的结果较难解释,不容易理解每个特征对结果的具体影响。
- 高维稀疏数据处理较差:在处理高维稀疏数据时,随机森林的表现可能不如线性模型和基于梯度的模型。
常见应用场景
随机森林适用于各种需要高准确性和稳定性的任务,包括但不限于:
- 分类任务:如文本分类、图像分类、医学诊断等。
- 回归任务:如房价预测、销售额预测、天气预报等。
- 特征选择:通过评估特征的重要性,帮助选择最有价值的特征,提高其他模型的性能。
- 异常检测:在金融、网络安全等领域,用于检测异常行为。
随机森林的参数详解
使用随机森林时,了解和调优其参数非常重要。以下是一些关键参数的详细介绍:
| 参数名称 | 含义 | 默认值 |
|---|---|---|
n_estimators | 森林中树的数量 | 100 |
max_features | 每次分裂时考虑的最大特征数 | ‘auto’ |
max_depth | 每棵树的最大深度 | None |
min_samples_split | 内部节点再划分所需最小样本数 | 2 |
min_samples_leaf | 叶子节点最少样本数 | 1 |
bootstrap | 是否使用Bootstrap抽样法 | True |
oob_score | 是否使用袋外样本评估模型 | False |
n_jobs | 并行运行任务的个数 | 1 |
random_state | 随机数种子,用于保证结果可重复 | None |
verbose | 控制树构建过程的详细程度 | 0 |
主要参数解释
- n_estimators:决定了森林中树的数量,树越多模型的效果通常越好,但训练和预测的时间也会增加。
- max_features:控制每棵树分裂时考虑的最大特征数,较小的值通常能增加树的差异性,防止过拟合。
- max_depth:限制树的最大深度,防止单棵树过于复杂导致过拟合。
- min_samples_split 和 min_samples_leaf:控制节点分裂和叶子节点的最小样本数,防止模型过拟合。
- bootstrap:决定是否使用Bootstrap抽样法,通常设置为True。
- oob_score:使用袋外样本(Out-of-Bag)来评估模型性能,无需额外的验证集。
- n_jobs:指定并行运行的任务数,可以加速训练过程。
- random_state:设置随机种子,确保实验的可重复性。
如何选择和调优随机森林
在实际应用中选择和调优随机森林模型,需要根据具体任务和数据情况进行调整。以下是一些调优建议:
- 树的数量(n_estimators):通常树的数量越多,模型的效果越好,但要平衡训练时间和计算资源。
- 最大特征数(max_features):可以尝试设置为特征总数的平方根或对数,找到一个平衡点。
- 最大深度(max_depth):控制树的最大深度,防止树过深导致过拟合,可以通过交叉验证选择合适的深度。
- 最小样本数(min_samples_split, min_samples_leaf):设置较大的最小样本数,可以减少过拟合,提高模型的泛化能力。
- 使用袋外样本(oob_score):启用袋外样本评估,可以在不使用验证集的情况下评估模型性能。
- 并行计算(n_jobs):在计算资源允许的情况下,使用并行计算加速训练过程。
示例代码
为了更好地理解随机森林的应用,以下是一个使用随机森林进行分类和回归任务的示例代码。
分类任务示例
我们将使用自生成的数据集来演示如何使用随机森林进行分类。
import numpy as np from sklearn.datasets import make_classification from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report # 生成分类数据集 X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=42) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 创建随机森林分类器 clf = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42) # 训练模型 clf.fit(X_train, y_train) # 预测 y_pred = clf.predict(X_test) # 评估模型 print(f'Accuracy: {accuracy_score(y_test, y_pred)}') print(classification_report(y_test, y_pred))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
回归任务示例
我们将使用自生成的数据集来演示如何使用随机森林进行回归。
import numpy as np from sklearn.datasets import make_regression from sklearn.ensemble import RandomForestRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score # 生成回归数据集 X, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=42) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 创建随机森林回归器 reg = RandomForestRegressor(n_estimators=100, max _depth=10, random_state=42) # 训练模型 reg.fit(X_train, y_train) # 预测 y_pred = reg.predict(X_test) # 评估模型 print(f'Mean Squared Error: {mean_squared_error(y_test, y_pred)}') print(f'R^2 Score: {r2_score(y_test, y_pred)}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
结论
随机森林作为一种强大的集成学习方法,通过集成多个决策树,有效提高了模型的准确性和稳定性。本文详细介绍了随机森林的原理、特点、优缺点以及参数调优方法,并通过示例代码展示了随机森林在分类和回归任务中的应用。在实际应用中,选择和调优随机森林需要根据具体任务和数据情况进行调整,通过合理的参数设置,可以充分发挥随机森林的优势,解决复杂的机器学习问题。
我的其他同系列博客
支持向量机(SVM算法详解)
knn算法详解
GBDT算法详解
XGBOOST算法详解
CATBOOST算法详解
随机森林算法详解
lightGBM算法详解
对比分析:GBDT、XGBoost、CatBoost和LightGBM
机器学习参数寻优:方法、实例与分析
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/753838
推荐阅读
相关标签

