
- 1基于STM32F103单片机的老人防跌倒报警装置GSM短信蜂鸣器报警方案原理图程序设计_单片机蜂鸣器报警电路
- 2软考 系统架构设计师系列知识点之杂项集萃(46)
- 3qml 实现展示本地文件系统_qml实现系统
- 4数据库分库分表_根据uid分2表和4表的区别
- 5Qt:24---QFileSystemModel、QDirModel数据模型_使用qfilesystemmodel和qtreeview显示指定后缀名的文件
- 6【共词聚类分析】基于CNKI和WOS的小样本稳健性检验_知网 聚类分析
- 7动手学深度学习(Pytorch版)代码实践 -卷积神经网络-15参数管理
- 8windows下Qt安装教程_qt windows 安装
- 9多模态大模型:打开人工智能新视界_多模态大模型 可成大纲
- 10java继承练习题-PTA_7-2 jmu-java-03面向对象-06-继承覆盖综合练习-person、student、emp
Python据框和序列的访问、切片及运算(中国大学数据集)_中国大学数据集.scv
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
1.导入pandas numpy模块并读取文件 中国大学数据集.csv , 显示前topn行
9.从data中删除索引为1024的学校,形成一个新的数据框data_no_1024, 并显示
10.从data中删除掉 地址 列,形成一个新的数据框data_no_addr, 并显示
13.每个省份,不同类型学校 数量的交叉分析,并将结果保存到 各省份学校类型统计表.xlsx
一、实验要求:
本次实验主要目的如下:
- 熟悉Python编程,基础结构流程;
- 数据框和序列的访问、切片及运算;
- pandas导入外部数据文件;
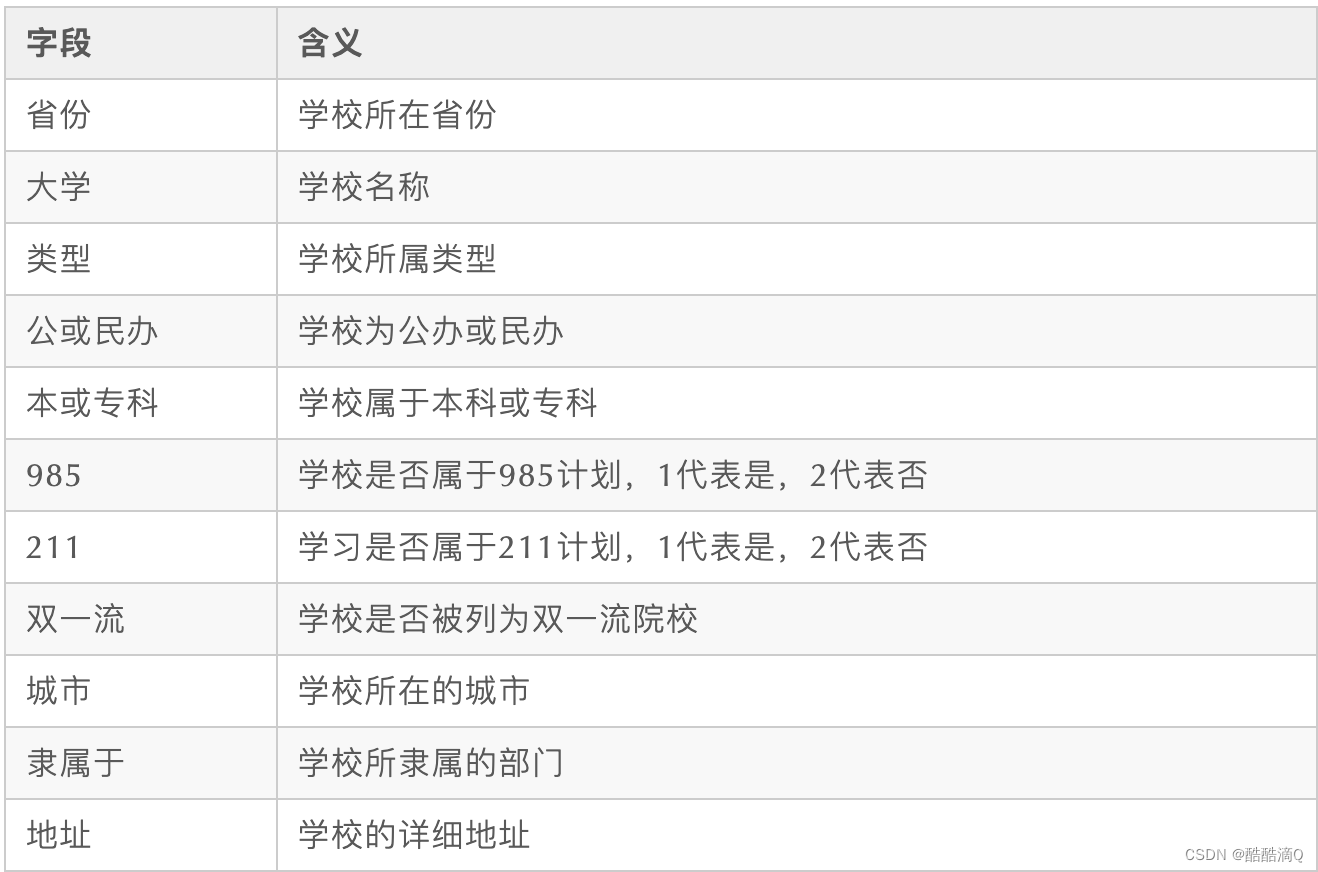
- 本次实验使用的数据集为 中国大学数据集, 该数据集每条数据字段含义如下:
二、相关文件
链接:https://pan.baidu.com/s/16N45wcmtoRKBHLtt_ZwRNg
提取码:kkdq
三、使用 Jupyter工具导入项目步骤
1.菜单栏中找到Anaconda Prompt (Anaconda3),点击运行
2.输入: cd 指定项目的文件夹路径
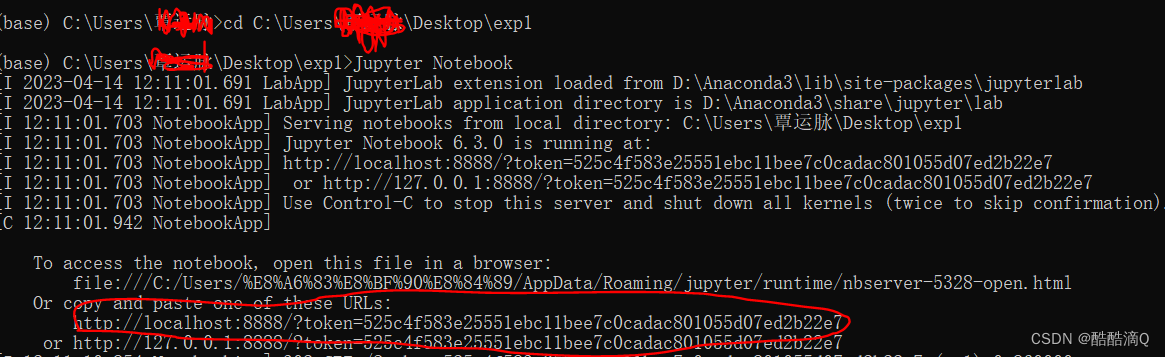
3.启动项目: Jupyter Notebook
4.复制倒数第一个链接到网页访问。
三、实验内容
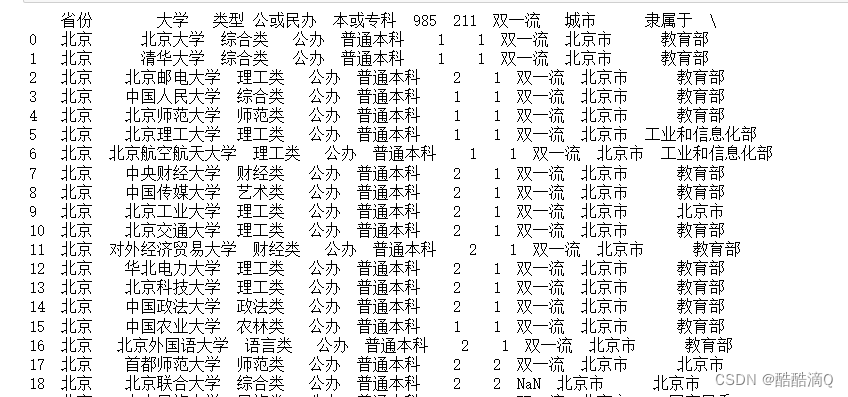
1.导入pandas numpy模块并读取文件 中国大学数据集.csv , 显示前topn行
- # 导入pandas numpy模块并读取文件 中国大学数据集.csv , 显示前topn行
- # todo
-
- import pandas as pd
- import numpy as np
- path='中国大学数据集.csv'
- whc_id = 629
- topn = whc_id % 43
-
- data = pd.read_csv(path,sep=',')
- h=data.head(topn)
- print(h)
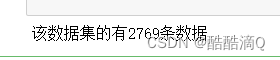
2.查看该数据集的基本情况
- # 查看该数据集的基本情况
- #print(data.shape)
- #print(data.info())
- print("该数据集的有{0}条数据".format(data.shape[0])) # 请在{}中填写表示行数的正确表达式
3.查看每一列空值数量
- # 查看每一列空值数量
- # todo
- data.isnull().sum()

4.对于双一流这一列的替换
# 将字段里的双一流字符串 替换为数值1, 原地替换(即inplace=True)
# 将字段里的空值替换为 2
# 提示可以使用Series.replace()
- data.replace('双一流', 1, inplace=True)
-
- # 将整个 DataFrame 中的空值替换为 2,原地替换
- df.fillna(2, inplace=True)
- print(df)

5.请输出每个省份高校数量列表,按照降序排序并输出
提示: 可以使用groupby
- # 请输出每个省份高校数量列表, 提示: 可以使用groupby
- counts = data.groupby("省份")["大学"].count()
-
- # 按照降序排序并输出
- sorted_counts = counts.sort_values(ascending=False)
- print(sorted_counts)
- # 并且按照降序进行排序 输出
- # todo

6.计算当前数据集中大学分布于多少个省份中
- # 计算当前数据集中大学分布于多少个省份中
- num_provinces = len(data["省份"].unique())
-
- print(f"当前数据集中大学分布于{num_provinces}个省份中。")

7.计算双一流学校数量
- # 计算双一流学校数量
- #print(data)
- #注,根据上面的题,已经把双一流这一列中的字符串“双一流"改为了 1
- #num_top_universities = data["双一流"].sum()
- num_top_universities = (data["双一流"]==1).sum()
- print(f"双一流学校数量为{num_top_universities}所。")
![]()
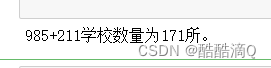
8.计算985+211学校的数量
注意:有的学校既是985也是211, 所以有可能重复
- # 计算985+211学校的数量。 注意有的学校既是985也是211, 所以有可能重复
- num_985_universities = len(data[data["985"]==1])
- num_211_universities = len(data[data["211"]==1])
- print(f"985+211学校数量为{num_985_universities+num_211_universities}所。")
9.从data中删除索引为1024的学校,形成一个新的数据框data_no_1024, 并显示
- # 从data中删除索引为1024的学校,形成一个新的数据框data_no_1024, 并显示
- data_no_1024 = data.drop(index=1024)
-
- # 显示新的数据框
- print(data_no_1024)

10.从data中删除掉 地址 列,形成一个新的数据框data_no_addr, 并显示
- # 从data中删除掉 地址 列,形成一个新的数据框data_no_addr, 并显示
- # todo
- data_no_addr = None # edit this line
- # 删除地址列,形成新的数据框
- data_no_addr = data.drop(columns=['地址'])
-
- # 显示新的数据框
- print(data_no_addr)

11.从 data 中选择所有北京、湖北、广东的学校
形成三个数据框 data_bj, data_hb, data_gd
并按照湖北、北京、广东的顺序将这三个学校从上到下拼接在一起形成一个新的数据框 data_cat.并显示data_cat
- # edit lines below
- # 选择所有北京学校,形成新的数据框 data_bj
- data_bj = data[data['省份'] == '北京']
- # 选择所有湖北学校,形成新的数据框 data_hb
- data_hb = data[data['省份'] == '湖北']
- # 选择所有广东学校,形成新的数据框 data_gd
- data_gd = data[data['省份'] == '广东']
- # 将三个数据框按照湖北、北京、广东的顺序拼接在一起,形成新的数据框 data_cat
- data_cat = pd.concat([data_hb, data_bj, data_gd], axis=0)
- # 显示新的数据框 data_cat
- print(data_cat)

交叉分析
交叉分析通常用于分析两个或两个以上分组变量之间的关系,以交叉表形式进行变量间关系的对比分析;
从数据的不同维度,综合进行分组细分,进一步了解数据的构成、分布特征。交叉分析有数据透视表和交叉表两种:
透视表 pd.pivot_table(data,values,index,columns,agg,func,fill_value,margins)
data:要应用透视表的数据框。values:待聚合的列名,默认聚合所有数值列。index:用于分组的列名或其他分组键,出现在结果透视表的行。columns:用于分组的列名或其他分组键,出现在结果透视表的列。aggfunc:聚合函数或函数列表,默认为'mean',可以是任何对groupby有效的函数。fill_value:用于替换结果表中的缺失值。margins:添加行/列小计和总计,默认为False。
pivot_table()函数返回值是数据透视表的结果,该函数相当于Excel中的数据透视表功能。
12.每个省份公或民办学校数量的交叉分析
- # 每个省份公或民办学校数量的交叉分析
- pd.pivot_table(data, values=['大学'], index=['省份'], columns=['公或民办'], aggfunc=[np.size], margins=True)
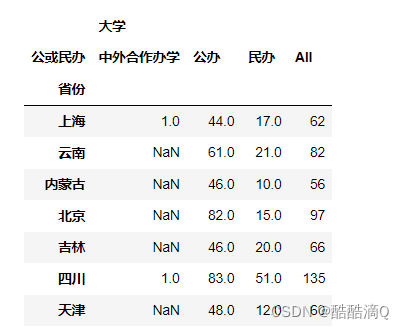
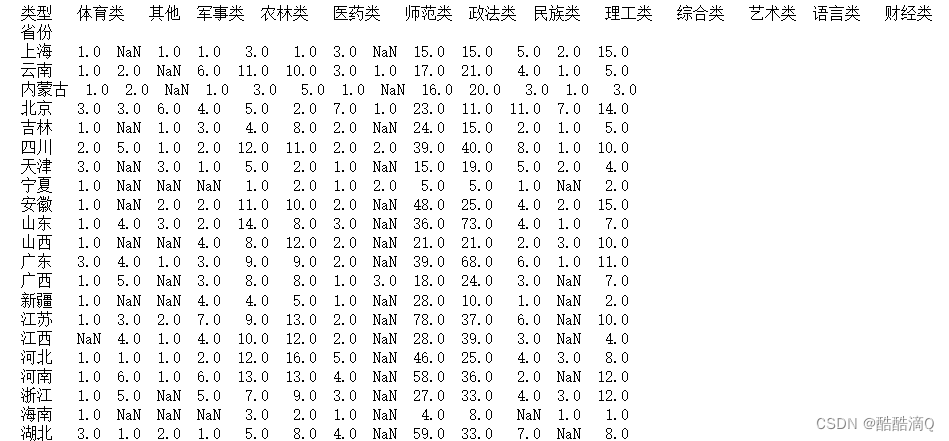
13.每个省份,不同类型学校 数量的交叉分析。 并将结果保存到 各省份学校类型统计表.xlsx
- # 每个省份,不同类型学校 数量的交叉分析。 并将结果保存到 各省份学校类型统计表.xlsx
- from pandas import ExcelWriter
- #print(data)
- # 对每个省份和学校类型进行分组,统计数量
- grouped = data.groupby(['省份', '类型'])['大学'].count()
- # 将分组结果转换为数据框,按照省份和学校类型进行重塑
- result = pd.DataFrame(grouped).reset_index().pivot(index='省份', columns='类型', values='大学')
- # 将结果保存到Excel文件
- with ExcelWriter('各省份学校类型统计表.xlsx') as writer:
- result.to_excel(writer)
- # 显示结果
- print(result)
- # todo
四、总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了Python据框和序列的访问、切片及运算,以及讲解了使用jupyter工具导入项目。

