
- 1vscode-合并分支代码_vscode 合并代码
- 2前台文本直接取数据库值doFieldSQL插入SQL
- 3OpenVoice——强大的语音克隆与生成技术_openvoice教程
- 4CodeWave系列:6.CodeWave 智能开发平台 扩展依赖库开发_nasl.ide.version
- 5【vim离线升级---vim 缓冲区错误漏洞】_centos离线升级vim
- 6XSS绕过waf
- 7Python+pandas将Excel文件xls批量转换xlsx(代码全注释)_xls批量转换成xlsx 保留格式
- 8手动添加Git Bash Here到右键菜单_git bush here
- 9黑金AX7Z100 FPGA开发板移植LWIP库(一)PS端_黑金ac7z100c 教程
- 10开发个人Ollama-Chat--1 项目介绍_openui 如何本地部署
机器学习初学-简易循环神经网络SimpleRNN和LSTM鉴定商品评价文本_keras 2.1.3
赞
踩
数据集:Product Comments | Kaggle
使用kerasTokenizer工具 One-hot编码分词示例
文本的向量化是机器学习进行进一步数据分析、理解、处理的基础,它的作用是令文本的内容尽可能地结构化。
不同类型的文本,需要用到不同的处理方式。具体来说,分为以下几种处理方式。
■单字符的向量表达。
■词语的向量表达。
■短文本(如评论、留言等)的向量表达。
■长文本(如莎士比亚戏剧集)的向量表达。
最常见的情况,是以“词语”为单位,把文本进行向量化的表达。向量化这个过程,也可以叫作分词,或切词(tokenization)。在前深度学习的特征工程时代,分词是一件烦琐的任务。
- from keras.preprocessing.text import Tokenizer #导入Tokenizer工具
- words = ['Lao Wang has a Wechat account.', 'He is not a nice person.', 'Be careful.']
- tokenizer = Tokenizer(num_words=30) # 词典大小只设定30个词(因为句子数量少)
- tokenizer.fit_on_texts(words) # 根据3个句子编辑词典
- sequences = tokenizer.texts_to_sequences(words) # 为3个句子根据词典里面的索引进行序号编码
- one_hot_matrix = tokenizer.texts_to_matrix(words, mode='binary') #进行One-hot编码
- word_index = tokenizer.word_index # 词典中的单词索引总数
- print('找到了 %s个词' % len(word_index))
- print('这3句话(单词)的序号编码:', sequences)
- print('这3句话(单词)的One-hot编码:', one_hot_matrix)
- # 输出每个索引对应的词
- word_index.items()

1 用Tokenizer给文本分词
- from keras.preprocessing.text import Tokenizer # 导入分词工具
- X_train_lst = df_train["Review Text"].values # 将评论读入张量(训练集)
- y_train = df_train["Rating"].values # 构建标签集
- tokenizer = Tokenizer(num_words=20000) # 初始化词典
- tokenizer.fit_on_texts( X_train_lst ) # 使用训练集创建词典索引
- # 为所有的单词分配索引值,完成分词工作
- X_train_tokenized_lst = tokenizer.texts_to_sequences(X_train_lst)
- word_index = tokenizer.word_index # 词典中的单词索引总数
- print(X_train_lst[0])
- print(X_train_tokenized_lst[0])
- word1 = tokenizer.index_word[253]
- word2 = tokenizer.index_word[532]
- word3 = tokenizer.index_word[917]
- word4 = tokenizer.index_word[3]
- word5 = tokenizer.index_word[68]
- print(word1+' '+word2+' '+word3+' '+word4+' '+word5)




这一步完成了:
✅ 每个句子已经被分解为单词
✅ 每个单词都有唯一对应的单词索引
2 直方图显示各单词个数分布情况
- import matplotlib.pyplot as plt # 导入matplotlib
- word_per_comment = [len(comment) for comment in X_train_tokenized_lst]
- plt.hist(word_per_comment, bins = np.arange(0,150,5)) # 显示评论长度分布
- plt.show()
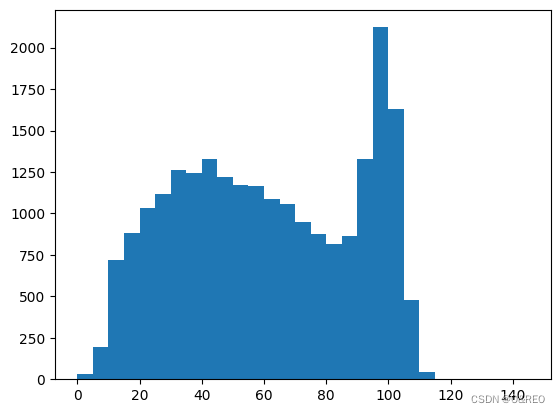
上图中的评论长度分布情况表明多数评论的词数在120以内,所以我们只需要处理前120个词,就能够判定绝大多数评论的类型。如果这个数目太大,那么将来构造出的词嵌入张量就达不到密集矩阵的效果。而且,词数太长的序列,Simple RNN处理起来效果也不好。
3 使用pad_sequences填充数据
keras.preprocessing.sequence.pad_sequences() 函数是一个非常有用的函数,用于对序列数据进行填充。在深度学习任务中,序列数据是一种常见的数据类型,例如文本数据、时间序列数据等。处理序列数据时,往往需要将不同长度的序列对齐到相同的长度上,以便于输入到神经网络模型中进行训练。在过去,一种常见的方法是通过手动编写代码来实现序列的填充操作。这种方法不仅繁琐,还容易出错。为了简化序列数据的填充操作,Keras 开发团队在 Keras 2.1.3 版本中引入了 keras.preprocessing.sequence.pad_sequences() 函数。该函数封装了序列填充的逻辑,使得用户无需手动编写复杂的代码,从而简化了序列数据的预处理流程。
使用pad_sequences将句子数组对齐到同样的长度,为数据不够的的填充0到同样长度,为数据超出的做截断(只保留后侧的)
- from tensorflow.keras.preprocessing.sequence import pad_sequences
-
- max_comment_length = 120 # 设定评论输入长度为120,并填充默认值(如字数少于120)
- X_train = pad_sequences(X_train_tokenized_lst, maxlen=max_comment_length)
- print(X_train_lst[0])
- print(X_train_tokenized_lst[0])
- word1 = tokenizer.index_word[253]
- word2 = tokenizer.index_word[532]
- word3 = tokenizer.index_word[917]
- word4 = tokenizer.index_word[3]
- word5 = tokenizer.index_word[68]
- print(word1+' '+word2+' '+word3+' '+word4+' '+word5)
- print(X_train[0])
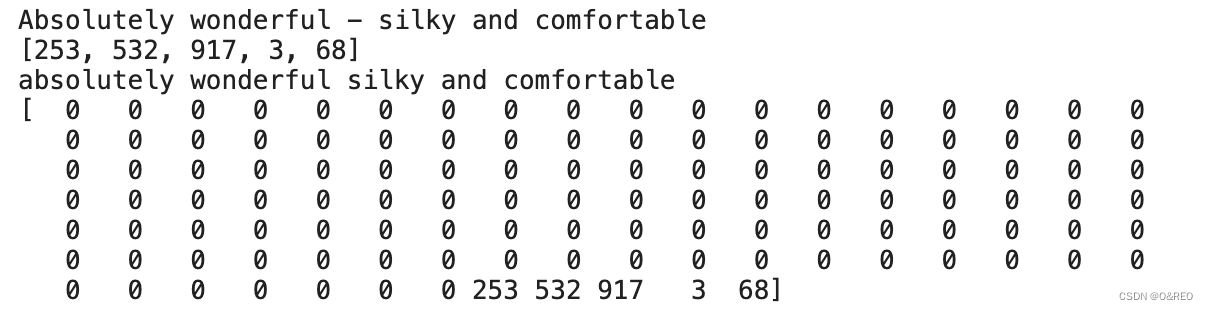
✅ 至此,前期的分词工作已完成。
4 构建SimpleRNN
■先通过Embedding层进行词嵌入的工作,词嵌入之后学到的向量长度为60(密集矩阵),其维度远远小于词典的大小20000(稀疏矩阵)。
■加一个含有100个神经元的Simple RNN层。
■再加一个含有10个神经元的全连接层。
■最后一个全连接层负责输出分类结果。使用Softmax函数激活的原因是我们试图实现的是一个从0到5的多元分类。
■编译网络时,损失函数选择的是sparse_categorical_crossentropy 稀疏分类交叉熵,
sparse_categorical_crossentropy是一个常用的分类问题损失函数,适用于多类别分类任务。在深度学习中,我们通过将类别表示为整数(从0到类别数-1)来进行多类别分类。在使用
sparse_categorical_crossentropy损失函数时,我们不需要将目标变量进行one-hot编码,而是直接使用整数表示类别标签。该损失函数计算预测结果与真实标签之间的交叉熵损失。它对应于为每个样本选择真实类别的概率的最大值。损失越小,模型对真实类别的预测就越准确。
因为这个训练集的标签,是1,2,3,4,5这样的整数,而不是one-hot编码。优化器的选择是adam,评估指标选择acc。
- from keras.models import Sequential # 导入序贯模型
- from tensorflow.python.keras.layers.embeddings import Embedding #导入词嵌入层
- from keras.layers import Dense #导入全连接层
- from keras.layers import SimpleRNN #导入Simple RNN层
- embedding_vecor_length = 60 # 设定词嵌入向量长度为60
- rnn = Sequential() #序贯模型
- rnn.add(Embedding(20000, embedding_vecor_length,
- input_length=max_comment_length)) # 加入词嵌入层
- rnn.add(SimpleRNN(100)) # 加入Simple RNN层
- rnn.add(Dense(10, activation='relu')) # 加入全连接层
- rnn.add(Dense(6, activation='softmax')) # 加入分类输出层
- rnn.compile(loss='sparse_categorical_crossentropy', #损失函数
- optimizer='adam', # 优化器
- metrics=['acc']) # 评估指标
- rnn.build(X_train.shape)
- print(rnn.summary()) #输出网络模型

词嵌入(Word Embedding)的主要目的是将文本数据转换为数字表示,以便计算机能够更好地理解和处理自然语言。它将单词映射到高维向量空间中的向量,其中每个维度代表了某种语义或上下文关系。词嵌入通常通过使用无监督的方法(如Word2Vec、GloVe等)或是基于神经网络的方法(如使用嵌入层)生成。
以下是词嵌入的几个重要原因:
1. 语义关联性:词嵌入可以捕捉到单词之间的语义关联性,因为在向量空间中,语义上相似的单词通常在向量空间中也彼此靠近。这有助于改进自然语言处理任务,如词义相似性计算、文本分类和命名实体识别等。
2. 降维与稠密表示:将文本数据转换为词嵌入向量后,可以将高维稀疏表示(如独热编码)转换为低维稠密表示。这样做有助于减少特征维度、节省内存,并且通常能够捕捉到更丰富的语义信息。
3. 泛化能力:通过词嵌入,模型可以更好地泛化到未见过的单词或短语。即使在训练集中没有出现过的词汇,也可以通过词嵌入将其映射到语义上相似的向量表示。
做词嵌入可以极大地提高自然语言处理任务的效率和准确性。在应用词嵌入之前,模型往往需要先处理和编码文本数据,而且对于高维稀疏表示,模型的训练和推理速度可能会变慢。
如果不使用词嵌入,理论上仍然可以进行训练,但效果可能会受限。缺乏词嵌入表示的模型很难理解单词之间的语义关系和上下文信息,因此可能影响模型的准确性和泛化能力。同时,训练过程可能会更为耗时。
综上所述,词嵌入在自然语言处理任务中扮演着重要的角色。它能够提高模型的效率和性能,并提供更丰富的语义信息。因此,在处理自然语言数据时,使用词嵌入是一个常见的实践。
“这里要介绍一个叫作词嵌入(word embedding)的方法,它通过把One-hot编码压缩成密集矩阵,来降低其维度。而且,每一个维度上的值不再是二维的0,1值,而是一个有意义的数字(如59、68、0.73等),这样的值包含的信息量大。同时,在词嵌入的各个维度的组合过程中还会包含词和词之间的语义关系信息(也可以视为特征向量空间的关系)。
这个词嵌入的形成过程不像One-hot编码那么简单了:词嵌入张量需要机器在对很多文本的处理过程中学习而得,是机器学习的产物。学习过程中,一开始产生的都是随机的词向量,然后通过对这些词向量进行学习,词嵌入张量被不断地完善。这个学习方式与学习神经网络的权重相同,因此词嵌入过程本身就可以视为一个深度学习项目。”摘录来自
零基础学机器学习 黄佳
分词和词嵌入:一个高维稀疏,但信息量小;一个低维密集,但信息量大
✅ 至此,simpleRNN构建工作已完成。
5 训练网络和查验准确率
- history = rnn.fit(X_train, y_train,
- validation_split = 0.3,
- epochs=20,
- batch_size=64)
-
- # 提取训练结果
- train_loss = history.history['loss']
- val_loss = history.history['val_loss']
- train_acc = history.history['acc']
- val_acc = history.history['val_acc']
-
- # 绘制损失图表
- plt.plot(train_loss, color='r', label='Train Loss')
- plt.plot(val_loss, color='g', label='Validation Loss')
- plt.xlabel('Epochs')
- plt.ylabel('Loss')
- plt.legend()
- plt.show()
-
- # 绘制准确率图表
- plt.plot(train_acc, color='r', label='Train Acc')
- plt.plot(val_acc, color='g', label='Validation Acc')
- plt.xlabel('Epochs')
- plt.ylabel('Acc')
- plt.legend()
- plt.show()
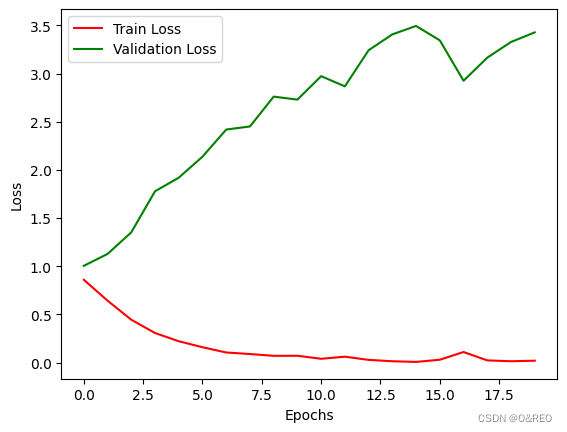
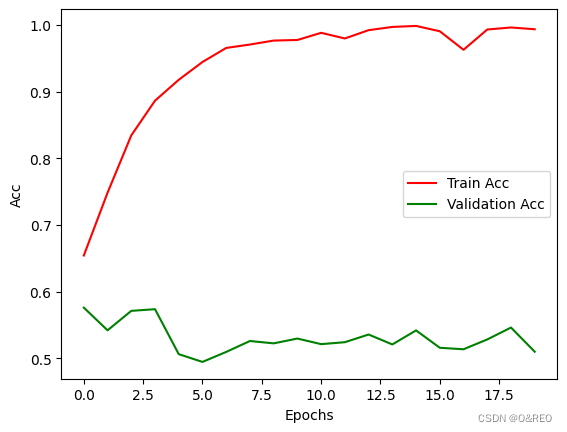
当准确率(accuracy)保持稳定或变化不大,而损失(loss)却越来越高的情况通常发生在某些特定场景中,例如:
类别不平衡:如果训练数据中的类别分布不平衡,即某些类别的样本数量明显多于其他类别,模型可能会倾向于预测这些主导类别,导致准确率较高。然而,损失函数可能会受到那些样本数量较少的类别的影响,而产生较高的损失值。
不适当的损失函数:选择不合适的损失函数可能导致这种情况。例如,对于二元分类问题,使用平均绝对误差(Mean Absolute Error)作为损失函数可能会导致低准确率但较高的损失值。
数据标签错误:如果训练数据中存在错误的标签或噪声,模型在训练中可能尝试拟合这些错误,从而导致高损失值。准确率可能会受到正确标签样本的影响,而保持相对稳定。
模型过拟合:当模型过拟合训练数据时,它可能会记住训练集中的噪声或异常模式,并表现出较低的准确率。然而,这些异常模式对损失函数的贡献可能很大,导致较高的损失值。
交叉熵损失函数在面对此时的过拟合问题时,对离群点更加敏感,损失值在准确率差距不大时逐渐增加 。
如果采用其他类型的前馈神经网络,其效率和RNN的成绩会相距甚远。如何进一步提高验证集准确率呢?
使用LSTM优化
LSTM(长短期记忆网络)和SimpleRNN(简单循环神经网络)两者都是循环神经网络(RNN)的变体,通常用于处理序列数据。以下是它们之间的一些主要区别:
1. 处理长期依赖性:在处理长序列时,SimpleRNN 很难捕捉到远距离时刻的依赖关系。这是因为SimpleRNN 在进行反向传播时,梯度会不断地缩小或放大,导致远距离时刻的输入信息被逐渐遗忘或淹没。而 LSTMs 则采用了门控机制,能够更好地处理长期依赖性。LSTM 中的记忆单元和各种门控单元有助于选择性地保留和遗忘信息。
2. 防止梯度消失:由于 SimpleRNN 的网络结构,梯度在反向传播时容易消失或爆炸,这会影响网络的训练和收敛性能。LSTM 的门控机制有助于缓解这个问题,通过选择性地更新和传递信息,有效地解决了梯度消失问题。
3. 单元结构:SimpleRNN 的基本单元比较简单,只包含一个线性层和一个激活函数。相比之下,LSTM 单元由三个门控单元(输入门、遗忘门和输出门)和一个记忆单元组成,增加了网络的复杂性。这些门控单元允许 LSTM 有更多的灵活性来控制信息的流动和传递。
总而言之,LSTM 相对于 SimpleRNN 具有更好的处理长期依赖性和防止梯度消失的能力。它通过引入记忆单元和门控机制,使得网络能够更好地捕捉序列中的长期依赖关系,并在训练过程中更稳定地传播梯度。对于处理较复杂的序列任务,LSTM 通常比 SimpleRNN 效果更好。
LSTM 的优点:
1. 处理长期依赖性:LSTM 通过门控机制能够更好地捕捉长期依赖关系,适合处理长序列数据。
2. 防止梯度消失:LSTM 的网络结构能够缓解梯度消失问题,有利于网络的训练和收敛性能。
3. 灵活性和记忆能力:LSTM 单元的门控机制赋予网络更大的灵活性,允许选择性地存储和遗忘信息,具备更好的记忆能力。LSTM 的缺点:
1. 复杂性和计算成本:LSTM 比 SimpleRNN 结构更加复杂,包含门控单元和记忆单元,导致计算成本较高。
2. 参数量增加:LSTM 需要更多的参数来管理门控机制,可能会增加模型的复杂度和训练时间。SimpleRNN 的优点:
1. 简单性和计算效率:SimpleRNN 的结构相对简单,只包括一个线性层和一个激活函数,计算效率较高。
2. 适用于短序列:SimpleRNN 在处理短序列数据时表现良好,可以用于一些简单的序列任务。SimpleRNN 的缺点:
1. 处理长期依赖性较差:由于梯度消失问题,SimpleRNN 在处理长序列时不太能有效地捕捉到远距离时刻的依赖关系。
2. 限制模型复杂度:SimpleRNN 较为简单的结构限制了其对复杂序列任务的建模能力。建议:
1. 对于复杂的序列任务,尤其是需要处理长期依赖性的情况,推荐使用LSTM。LSTM具备更好的记忆能力和捕捉长期依赖关系的能力。
2. 如果序列数据较为简单,且对模型的复杂度和计算效率有更高要求,SimpleRNN 是一个可行的选择。
- from tensorflow.python.keras.layers.embeddings import Embedding #导入词嵌入层
- from keras.models import Sequential # 导入序贯模型
- from keras.layers import Dense #导入全连接层
- from keras.layers import LSTM #导入LSTM层
- embedding_vecor_length = 60 # 设定词嵌入向量长度为60
- lstm = Sequential() #序贯模型
- lstm.add(Embedding(20000, embedding_vecor_length,
- input_length=max_comment_length)) # 加入词嵌入层
- lstm.add(LSTM(100)) # 加入LSTM层
- lstm.add(Dense(10, activation='relu')) # 加入全连接层
- lstm.add(Dense(6, activation='softmax')) # 加入分类输出层
- lstm.compile(loss='sparse_categorical_crossentropy', #损失函数
- optimizer = 'adam', # 优化器
- metrics = ['acc']) # 评估指标
- lstm.build(X_train.shape)
- lstm.summary()
- history = lstm.fit(X_train, y_train,
- validation_split = 0.3,
- epochs=20,
- batch_size=64)
-
-
- # 提取训练结果
- train_loss = history.history['loss']
- val_loss = history.history['val_loss']
- train_acc = history.history['acc']
- val_acc = history.history['val_acc']
-
- # 绘制损失图表
- plt.plot(train_loss, color='r', label='Train Loss')
- plt.plot(val_loss, color='g', label='Validation Loss')
- plt.xlabel('Epochs')
- plt.ylabel('Loss')
- plt.legend()
- plt.show()
-
- # 绘制准确率图表
- plt.plot(train_acc, color='r', label='Train Acc')
- plt.plot(val_acc, color='g', label='Validation Acc')
- plt.xlabel('Epochs')
- plt.ylabel('Acc')
- plt.legend()
- plt.show()

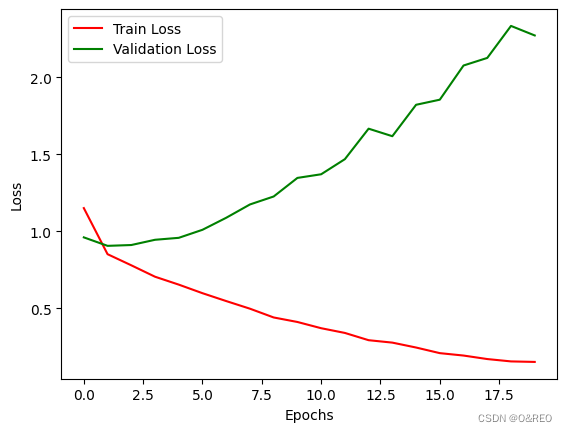
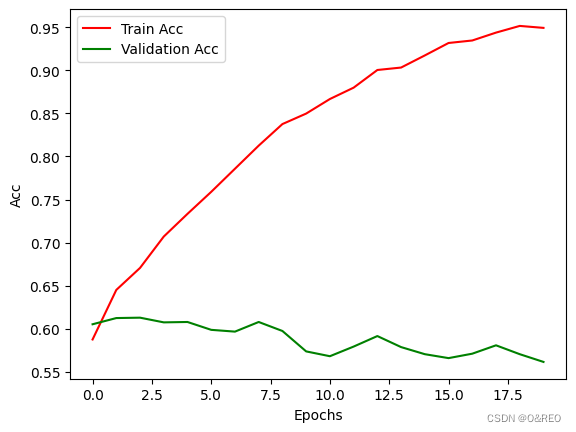
✅ 验证集accuracy提升到0.6左右

