
- 1springboot获取resources下的文件失败解决记录_springboot java.io.filenotfoundexception: class pa
- 2关键节点与邻居搜索:K-Core算法对比K-Hop算法的效能较量_。 关节点检索算法
- 3FlowUs息流打造AI赋能下的知识库,信息深度挖掘与智能创作!FlowUs让你的数据资产更有价值
- 4javascript开发技巧训练_学好这些小技巧,帮你写出更好地JavaScript
- 5docker mysql8使用SSL及使用openssl生成自定义证书_mysql 8 cert生成
- 6mac系统 SSH配置_mac ssh配置
- 7自然语言处理 (NLP) 入门教程_nlp入门教程
- 835.MySQL导出数据的几种方式_mysql 导出表数据
- 9vs+qt5.0 使用poppler-qt5 操作库获取pdf所有文本输出到txt操作
- 10超级详细的GitLab安装 与使用 【Gitlab添加组、创建用户和项目、权限管理】_gitlab群组_gitlab创建账号,分配权限
Python进行文本处理分析与词云生成——以三国演义为例(含代码讲解)_参考压缩包中的词云案例,根据提供的素材,制作三国演义第一章内容的带蒙版的词云(
赞
踩
前景:
在Python中处理文本数据是一种常见的任务,这需要使用到多种字符串操作和数据结构。本文将详细解读如何调用jieba、wordcloud以及matplotlib这些库进行文本处理分析与词云制作。
在pycharm中下载并安装库
在我们导入所需要的库之前我们需要先在pycharm中下载并安装库,步骤如下:
-
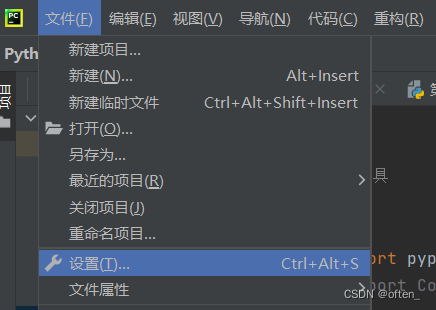
在PyCharm的顶部的菜单中选择 "File"(文件) -> "Settings"(设计)(在Mac上是 "PyCharm" -> "Preferences")。
-
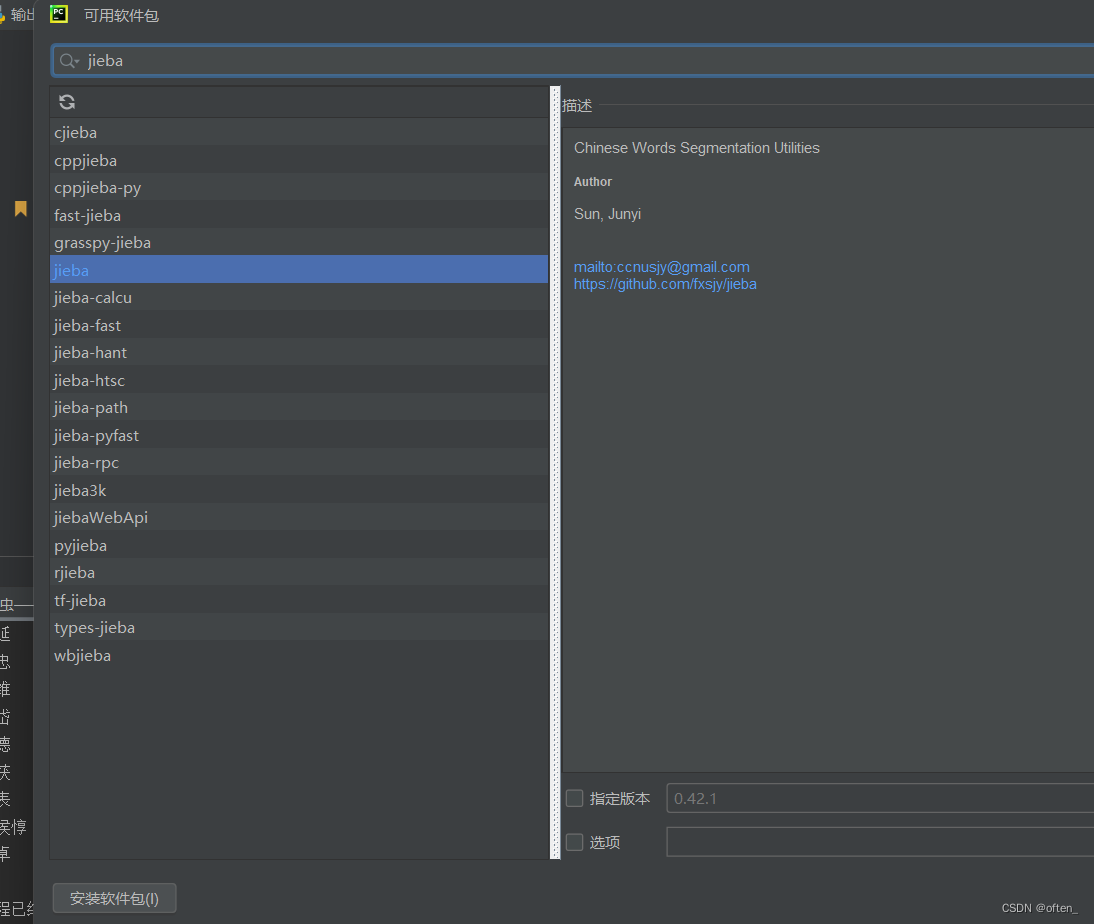
在设置窗口中,选择 "Project: [Your Project Name]" -> "Python Interpreter"。
-
在 Python Interpreter 页面的左上角,你会看到一个加号(+)按钮,点击它。
-
在弹出的窗口中,你可以搜索要安装的库的名称,然后选择并点击 "Install Package"。
-
等待安装完成后,你就可以在您的项目中使用这个库了。
这样,您就可以在PyCharm中方便地下载并安装您需要的库了

操作步骤
1.导入库
2. 打开并读取文件
3. 构建停用词表
4. 分词
5. 统计词频
6.删除无意义的停用词
7. 查看高频词
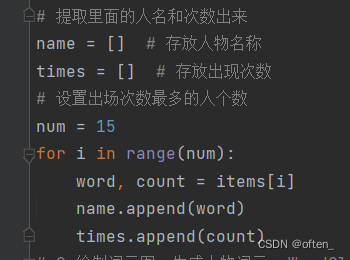
8.提取人名和出场次数
9. 构建词云图
10. 绘制词云图
具体代码实施
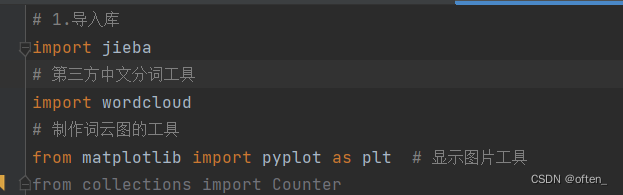
第一步导入库:我们首先使用import函数导入我们后面文本分析和制作词云所需要使用的库,包括jieba(中文分词第三方库)、wordcloud(词云生成库)和matplotlib(绘图库)。这些库分别用于中文分词、词云生成和数据可视化。
第二部打开并读取文件:我们使用open函数打开了一个文本文件,并使用read函数读取了文件内容。这样我们就可以对文件中的文本进行分析。

第三步构建停用词表:我们创建了一个停用词表,用于过滤掉一些无意义的词语,例如人名、地名等。这有助于提高文本分析的准确性。三国演义的停用词表如下

第四步分词:使用jieba库进行中文分词,将文本内容进行分词处理,为后续的词频统计做准备

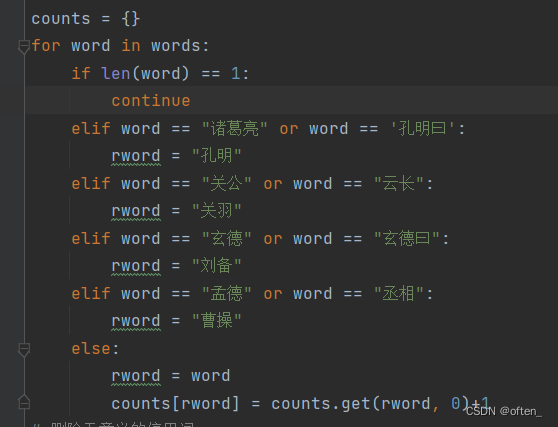
第五步统计词频:我们首先初始化一个空字典counts然后再使用get函数对分词后的结果进行词频统计,得到每个词语出现的次数,将名字放入字典的键中,将出现的次数放在字典的值中。要注意的是在三国演义中有许多人物有不同的叫法。列如:关公,云长都是指关羽,所以我们需要循环遍历加if语句将其变为同一个名字。
第六步删除无意义的停用词:减少后面我们遍历的内容,减少代码运行时间,再将我们刚刚所得到的字典列表化,方便我们后边使用sort()函数对其进行降序排序。("sort()" 函数是 Python 中的一个内置函数,用于对列表(list)进行排序。该函数会修改原始列表,将其元素按照升序排列。如果需要降序排列,则可以设置 reverse=True 参数。)

第七步查看高频词:这一步我们使用for循环统计并输出了词频统计结果中出现次数最多的前20个词语,以便对文本内容有一个整体的了解("format" 函数通常是在各种编程语言中用来格式化字符串的函数。它可以将变量或表达式的值插入到字符串中,并按照特定的格式显示。)

第八步提取人名和次数:在这一步中,我们定义一个空列表name和times分别用来存储人物的名称和出场次数,然后使用for循环将降序的名字和出现的次数分别赋值给word和count,并用append()函数将其分别赋值给列表name和times,使用wordcloud库构建了词云对象,并将高频词语及其出现次数用于生成词云图。
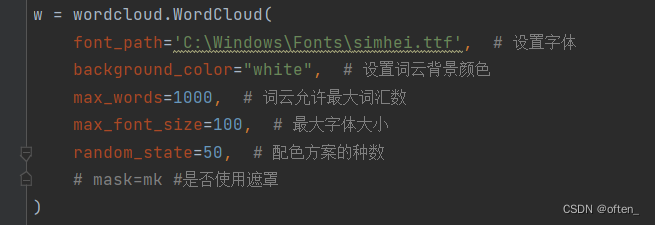
第九步构建词云图:我们使用wordcloud库构建了词云对象w,并设置词云属性:
1.font_path='C:\Windows\Fonts\simhei.ttf': 这行代码指定了字体路径,使用的是宋体字体(simhei)。这通常用于确保中文能够正确显示,因为默认的字体可能不支持中文。
2.background_color="white": 设置词云的背景颜色为白色。
3.max_words=1000: 在生成的词云中,最多显示1000个词汇。
4.max_font_size=100: 设置词云中字体的最大大小为100。
5.random_state=50: 设置随机数生成器的种子为50,确保每次生成的词云颜色配置是一样的
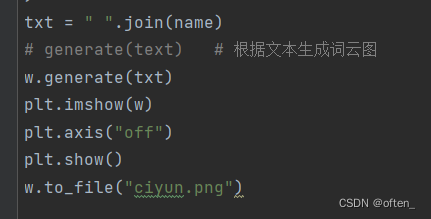
第十步绘制词云:定义一个txt 并赋值 " ".join(name): 将 name 列表中的所有元素连接成一个字符串,元素之间用空格分隔。(假设 name 是一个包含多个词汇的列表,这个操作就是将这些词汇连接成一个句子)
w.generate(txt): 使用上面生成的字符串 txt(从 name 转换得来)来生成词云。
显示和保存词云:
plt.imshow(w): 使用 matplotlib 显示生成的词云。
plt.axis("off"): 关闭坐标轴。
plt.show(): 显示图像。
w.to_file("ciyun.png"): 将生成的词云保存为名为 "ciyun.png" 的PNG图像文件。
到此我们的词云就制作完成了,感谢你的阅读!!!

