- 1Kimi高阶技巧:打造你的AI写作助手,一键生成专业内容!_kimi 公众号写作 高级指令
- 2BlueDroid代码学习分享
- 3Spring整合Hibernate实现Spring Data JPA (介绍和使用)_org.hibernate.search.jpa 和 spring-data jpa 共享
- 4MUNIK解读功能安全软件开发阶段——软件安全需求_功能安全ssr
- 5训练过程acc_跟着雨哥学AI系列之三:详解飞桨框架模型训练
- 6真正国产的最良心的SSH工具,可能是唯一已具备替代SecureCRT、XShell、MobaXTerm等国外核心基础工具的软件,强烈推荐_国产ssh工具
- 7【图解大数据技术】流式计算:Spark Streaming、Flink
- 8《Docker极简教程》--Docker镜像--Docker镜像的概念_docker的tag是镜像表示
- 9IPSEC详解
- 10Flink面试题大全(建议收藏)
15 张图,带你看懂人工智能现状
赞
踩
每年,人工智能指数都会以更大的虚拟冲击力登陆虚拟桌面——今年,它的 393 页证明了人工智能将在 2023 年迎来一个真正重要的一年。在过去的三年里,IEEE Spectrum阅读了整个该死的事情,并拿出了一系列总结人工智能当前状态的图表。
今年的报告由斯坦福以人为中心的人工智能研究所 (HAI)发布,增加了有关负责任人工智能的扩展章节和有关科学和医学领域人工智能的新章节,以及通常对研发、技术性能、经济的综述、教育、政策和治理、多样性和公众舆论。
由于这是一个非常长的报告,我们不能完整翻译,但笔者就感兴趣的部分,做了一些摘译:
AI,一些数据
在前沿AI研究章节中,报告表示,Epoch AI 是一群致力于研究和预测先进人工智能演变的研究人员。他们维护着 20 世纪 50 年代以来发布的人工智能和机器学习模型的数据库,根据最新进展、历史意义或高引用率等标准选择条目。分析这些模型可以全面概述机器学习领域近年来和过去几十年的演变。4数据集中可能缺少某些模型,然而,数据集可以揭示相对趋势。
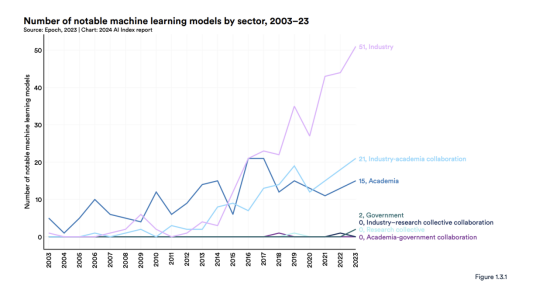
直到 2014 年,学术界主导了机器学习模型的发布。从那时起,工业就占据了主导地位。2023 年,工业界产生了 51 个著名的机器学习模型,而学术界只有 15 个(图 1.3.1)。值得注意的是,2023 年产学合作产生了 21 个著名模型,再创新高。
为了说明人工智能不断发展的地缘政治格局,人工智能指数研究团队分析了著名模型的原产国。
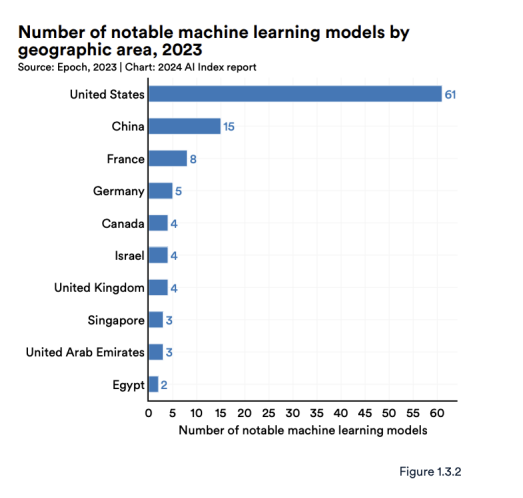
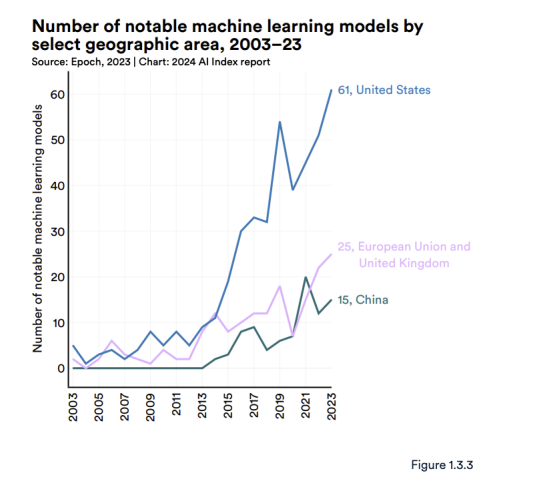
图 1.3.2 显示了研究人员所属机构所在地的著名机器学习模型总数。2023 年,美国以 61 个著名机器学习模型领先,其次是中国(15 个)和法国(8 个)。自 2019 年以来,欧盟和英国在著名人工智能模型数量上首次超过中国产生(图1.3.3)。自2003年以来,美国生产的模型数量超过了英国、中国和加拿大等其他主要地理区域(图1.3.4)。
报告表示,人工智能模型中的术语“计算”表示训练和操作机器学习模型所需的计算资源。一般来说,模型的复杂性和训练数据集的大小直接影响所需的计算量。模型越复杂,底层训练数据越大,训练所需的计算量就越大。
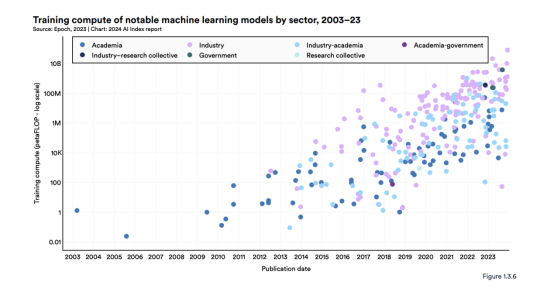
图 1.3.6 直观地展示了过去 20 年著名机器学习模型所需的训练计算。最近,著名人工智能模型的计算使用量呈指数级增长。6这种趋势在过去五年中尤为明显。计算需求的快速增长具有至关重要的影响。例如,需要更多计算的模型通常具有更大的环境足迹,并且公司通常可以比学术机构更多地访问计算资源。
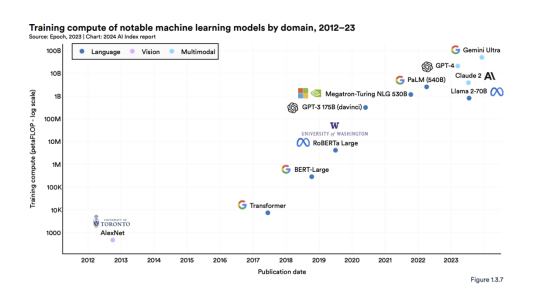
图 1.3.7 突出显示了 2012 年以来著名机器学习模型的训练计算情况。例如,AlexNet 是推广使用 GPU 改进 AI 模型的标准实践的论文之一,估计需要 470 petaFLOP 进行训练。
最初的 Transformer 于 2017 年发布,需要大约 7,400 petaFLOPs。谷歌的 Gemini Ultra 是当前最先进的基础模型之一,需要 500 亿petaFLOPs。
训练模型,到底有多耗钱
关于基础模型的讨论中的一个突出话题是它们的推测成本。
尽管人工智能公司很少透露训练模型的费用,但人们普遍认为这些成本已达数百万美元,并且还在不断上升。例如,OpenAI 的首席执行官 Sam Altman 提到,GPT-4 的训练成本超过 1 亿美元。
训练费用的增加实际上使传统上人工智能研究中心的大学无法开发自己的前沿基础模型。作为回应,例如拜登总统关于人工智能的行政命令,试图通过创建国家人工智能研究资源来平衡工业界和学术界之间的竞争环境,该资源将向非工业参与者提供进行更高水平人工智能所需的计算和数据。
了解训练人工智能模型的成本很重要,但有关这些成本的详细信息仍然很少。在去年的出版物中,人工智能指数是最早对基础模型的训练成本进行估算的指数之一。今年,AI Index 与人工智能研究机构 Epoch AI 合作,大幅增强和巩固了 AI 训练成本估算的稳健性。为了估算前沿模型的成本,Epoch 团队还分析了训练时长,使用与模型相关的出版物、新闻稿或技术报告中的信息,如训练硬件的类型、数量和利用率。
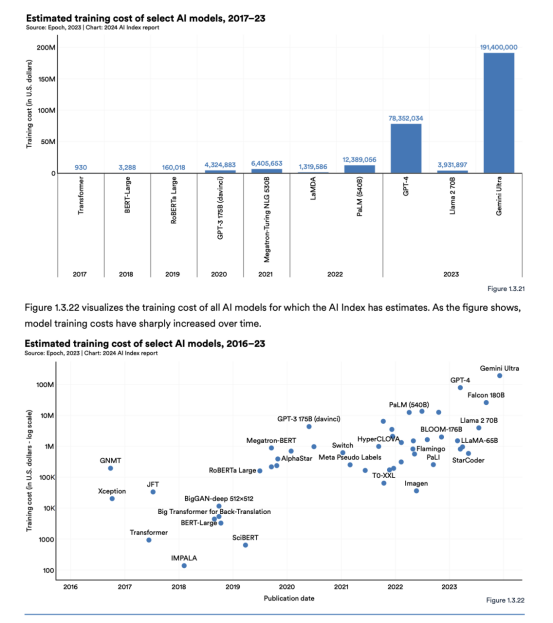
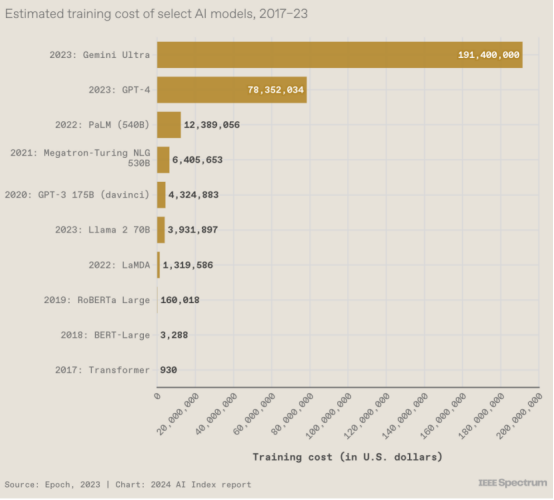
图 1.3.21 根据云计算租赁价格直观地显示了与选定 AI 模型相关的估计培训成本。AI Index的估计证实了人们的怀疑,即近年来模型训练成本大幅增加。例如,2017 年,最初的 Transformer 模型引入了几乎所有现代LLM的架构,训练成本约为 900 美元。RoBERTa Large 于 2019 年发布,在许多规范理解上取得了最先进的结果 SQuAD 和 GLUE 等基准测试的训练成本约为 160,000 美元。快进到 2023 年,OpenAI 的 GPT-4 和谷歌的 Gemini Ultra 的训练成本估计分别约为 7800 万美元和 1.91 亿美元。
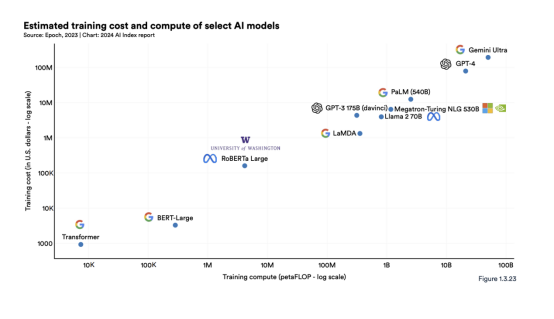
正如之前的AI Index报告所确定的那样,人工智能模型的训练成本与其计算要求之间存在直接相关性。如图 1.3.23 所示,具有更多计算训练的模型需要更高的训练成本。
最后IEEE通过15张图,总结人工智能现状。
15张图,总结人工智能现状
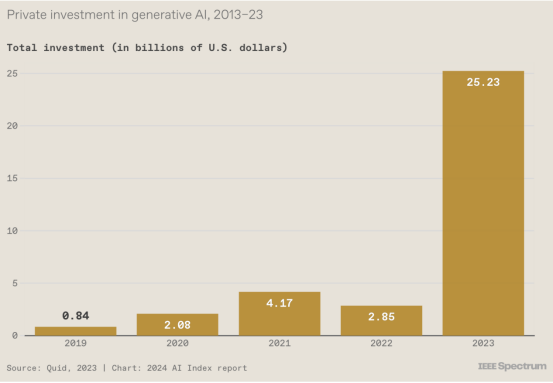
1. 生成式人工智能投资猛增
尽管去年企业投资总体下降,但对生成式人工智能的投资却大幅增长。今年报告的主编Nestor Maslej告诉IEEE Spectrum,这种繁荣预示着 2023 年的更广泛趋势,因为世界正在努力应对ChatGPT和图像生成DALL-E 2等生成人工智能系统的新功能和风险。 “去年的故事是关于人们对生成人工智能的反应,”Maslej 说,“无论是在政策方面,无论是在公众舆论中,还是在拥有更多投资的行业中。”报告中的另一张图表显示,生成式人工智能的私人投资大部分发生在美国。”
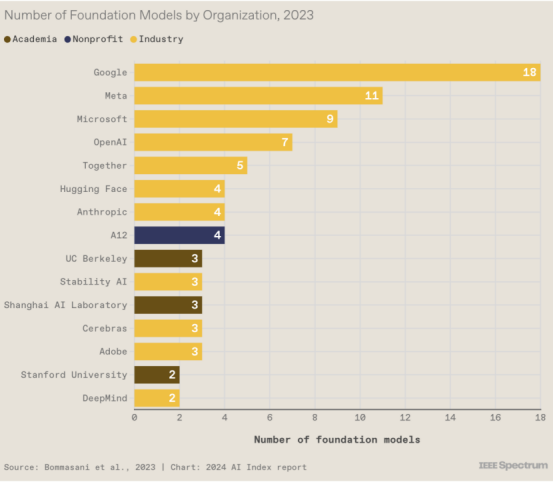
2. 谷歌在基础模型竞赛中占据主导地位
基础模型是大型多用途模型,例如,OpenAI 的GPT-3和GPT-4是使ChatGPT用户能够编写代码或莎士比亚十四行诗的基础模型。由于训练这些模型通常需要大量资源,因此工业界现在制造了大部分模型,而学术界只提供了少量资源。公司发布基础模型既是为了推动最先进的技术发展,也是为了为开发人员提供构建产品和服务的基础。谷歌在 2023 年发布了最多的内容。
3. 封闭模型优于开放模型
目前人工智能领域的热门争论之一是基础模型应该开放还是封闭,一些人激烈地认为开放模型是危险的,而另一些人则坚持开放模型驱动创新。AI 指数并没有介入这场争论,而是着眼于诸如已发布了多少开放式和封闭式模型等趋势(此处未包含的另一张图表显示,在 2023 年发布的 149 个基础模型中,有 98 个是开放式的, 23 个通过 API 提供了部分访问权限,28 个已封闭)。
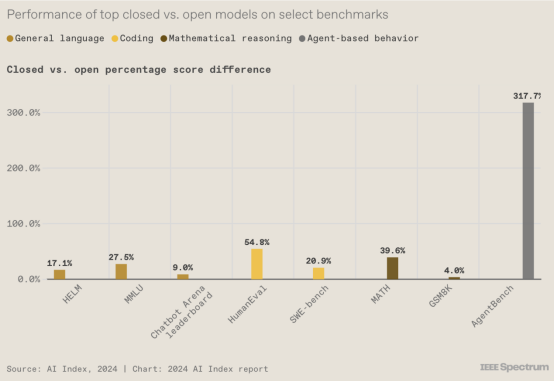
上图揭示了另一个方面:在许多常用的基准测试中,封闭模型的表现优于开放模型。Maslej 表示,关于开放式与封闭式的争论“通常围绕风险担忧,但很少讨论是否存在有意义的性能权衡”。
4. 基础模型变得超级昂贵
这就是为什么工业界在基础模型领域占据主导地位:培训一个大模型需要大量资金。但具体有多深呢?人工智能公司很少透露训练模型所涉及的费用,但人工智能指数通过与人工智能研究组织Epoch AI合作,超出了典型的猜测。报告解释说,为了做出成本估算,Epoch 团队利用从出版物、新闻稿和技术报告中收集的信息“分析了培训持续时间以及培训硬件的类型、数量和利用率”。
有趣的是,谷歌2017 年的 Transformer 模型引入了支撑当今几乎所有大型语言模型的架构,训练费用仅为 930 美元。
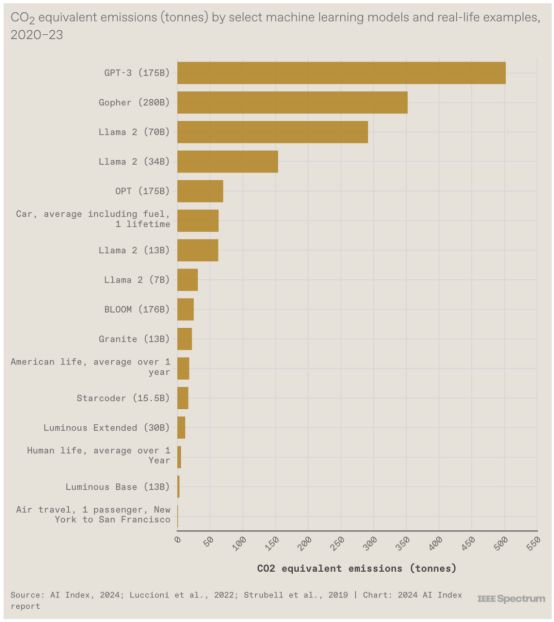
5. 它们的碳足迹很大
AI Index 团队还估算了某些大型语言模型的碳足迹。报告指出,模型之间的差异是由于模型大小、数据中心能源效率和能源网碳强度等因素造成的。报告中的另一张图表(此处未包含)显示了对与推理相关的排放的初步猜测(当模型正在执行其训练的工作时),并呼吁对此主题进行更多披露。正如报告指出的那样:“虽然每次查询的推理排放量可能相对较低,但当模型每天被查询数千次甚至数百万次时,总影响可能超过训练的影响。”
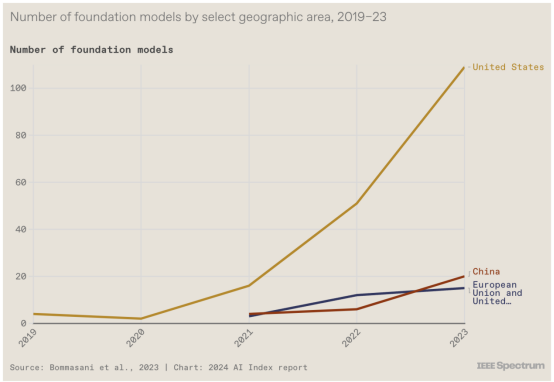
6. 美国在基础模型方面处于领先地位
虽然 Maslej 表示该报告并不是试图“宣布这场竞赛的获胜者”,但他确实指出,美国在几个方面处于领先地位,包括发布的基础模型数量(下图)以及被视为重大技术进步的人工智能系统数量。不过,他指出,中国在其他方面处于领先地位,包括人工智能专利授权和工业机器人安装。
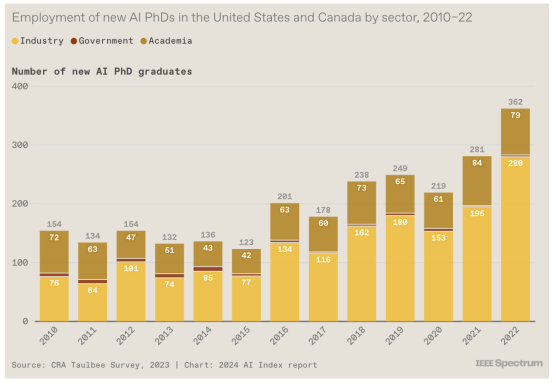
7. 业界呼唤新博士
考虑到之前讨论的有关行业在生成人工智能方面获得大量投资并发布大量令人兴奋的模型的数据,这一点并不令人意外。2022 年(该指数有数据的最近一年),北美 70% 的新人工智能博士在工业界就业。这是过去几年趋势的延续。
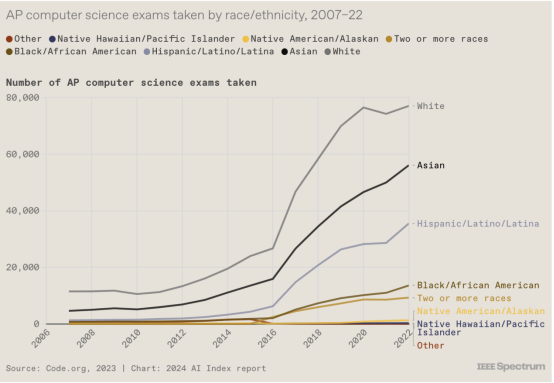
8. 多样性方面取得的一些进展
多年来,在减少人工智能中白人和男性的数量方面几乎没有取得任何进展。但今年的报告提供了一些充满希望的迹象。例如,参加 AP 计算机科学考试的非白人和女性学生数量正在增加。上图显示了种族趋势,而另一张图表(此处未包含)显示,现在参加考试的学生中有 30% 是女孩。
报告中的另一张图表显示,在本科阶段,获得计算机科学学士学位的北美学生的种族多样性也呈现出积极的趋势,尽管获得计算机科学学士学位的女性人数在过去五年中几乎没有变化。Maslej 说:“重要的是要知道这里还有很多工作要做。”
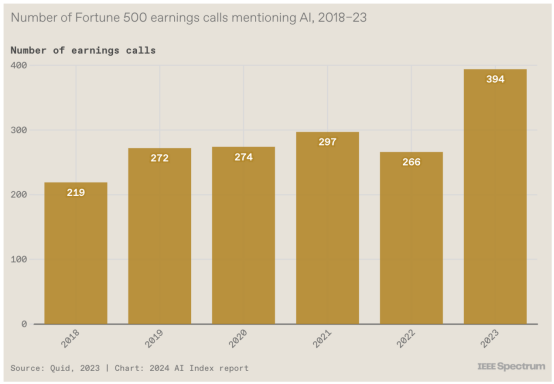
9. 财报电话会议上的闲聊
企业已经意识到人工智能的可能性。该指数从市场情报公司Quid获取了有关财富 500 强公司财报电话会议的数据,该公司使用自然语言处理工具扫描所有提及“人工智能”、“AI”、“机器学习”、“ML”和“深度学习。”近 80% 的公司在电话会议中讨论了人工智能。“我认为企业领导者担心,如果他们不使用这项技术,他们就会错过机会,”马斯莱说。
虽然其中一些闲聊可能只是首席执行官们闲聊流行语,但报告中的另一张图表显示,麦肯锡调查中 55% 的公司已经在至少一个业务部门实施了人工智能。
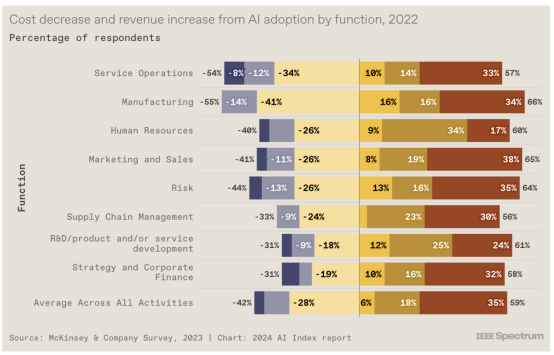
10.成本下降,收入上升
这就是为什么人工智能不仅仅是一个企业流行语:麦肯锡的同一项调查显示,人工智能的整合导致公司成本下降,收入上升。总体而言,42% 的受访者表示成本降低了,59% 的受访者声称收入增加了。
报告中的其他图表表明,这种对利润的影响反映了效率的提高和工人生产力的提高。2023年,不同领域的多项研究表明,人工智能使工人能够更快地完成任务并生产出更高质量的工作。一项研究着眼于使用Copilot 的程序员,而其他研究则着眼于顾问、呼叫中心代理和法学院学生。“这些研究还表明,尽管每个工人都受益,但人工智能对低技能工人的帮助比对高技能工人的帮助更大,”马斯莱说。
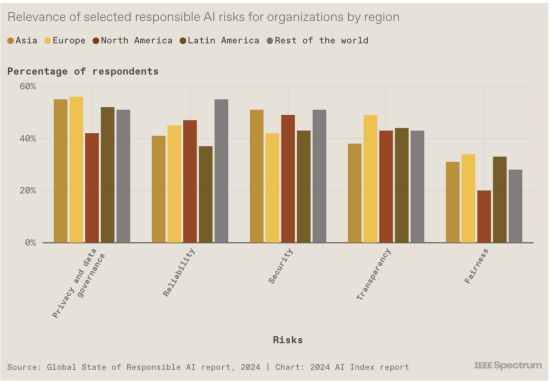
11. 企业确实感知到风险
今年,AI Index 团队对全球 1000 家收入至少 5 亿美元的公司进行了调查,以了解企业如何看待负责任的 AI。结果表明,隐私和数据治理被认为是全球最大的风险,而公平性(通常在算法偏差方面讨论)仍然没有得到大多数公司的认可。报告中的另一张图表显示,企业正在针对其感知的风险采取行动:跨地区的大多数组织都实施了至少一项负责任的人工智能措施来应对相关风险。
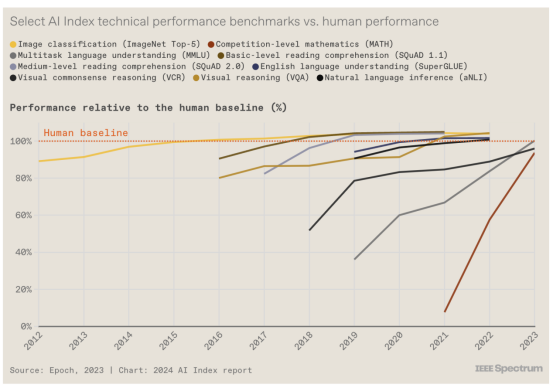
12.人工智能还不能在所有事情上击败人类......
近年来,人工智能系统在一系列任务上的表现都优于人类,包括阅读理解和视觉推理,Maslej 指出,人工智能性能改进的步伐也在加快。“十年前,有了像 ImageNet 这样的基准,你可以依靠它来挑战人工智能研究人员五六年,”他说。“现在,针对竞赛级别的数学引入了新的基准,人工智能从 30% 开始,然后在一年内达到 90%。”虽然人类在复杂的认知任务中仍然表现优于人工智能系统,但让我们明年看看情况如何。
13. 制定人工智能责任规范
当人工智能公司准备发布大型模型时,标准做法是根据该领域的流行基准对其进行测试,从而让人工智能社区了解模型在技术性能方面如何相互比较。然而,根据负责任的 AI 基准测试模型的情况并不常见,这些基准评估RealToxicityPrompts和ToxiGen、响应中的BOLD和BBQ以及TruthfulQA等。这种情况开始发生变化,因为人们越来越意识到,根据这些基准检查模型是负责任的事情。然而,报告中的另一张图表显示缺乏一致性:开发人员正在根据不同的基准测试他们的模型,这使得比较变得更加困难。
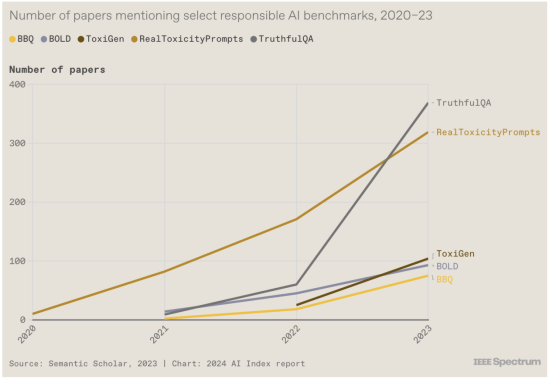
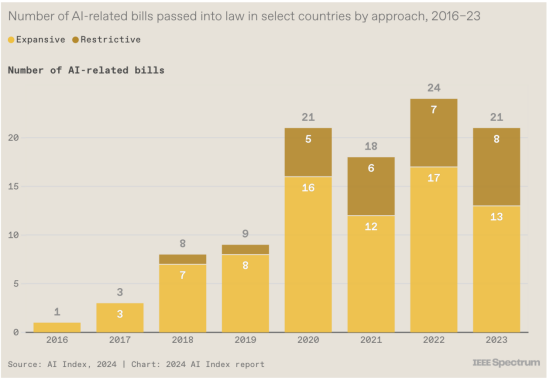
14. 法律既促进又限制人工智能
2016年至2023年间,人工智能指数发现,有33个国家通过了至少一项与人工智能相关的法律,其中大部分行动发生在美国和欧洲;在此期间,总共通过了 148 项与人工智能相关的法案。该指数研究人员还将法案分为旨在增强国家人工智能能力的扩张性法律或限制人工智能应用和使用的限制性法律。尽管许多法案继续推动人工智能发展,但研究人员发现全球存在限制性立法的趋势。
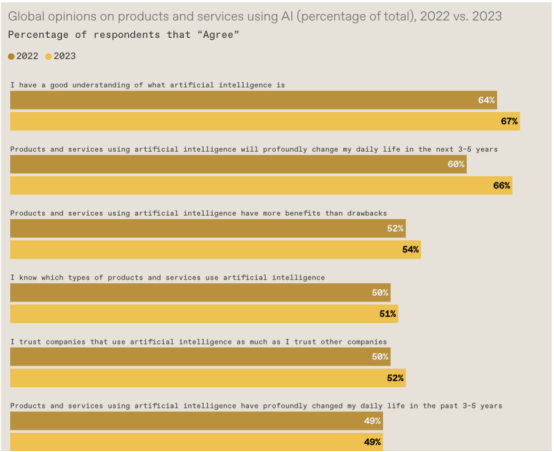
15. 人工智能让人紧张
该指数的民意数据来自一项关于人工智能态度的全球调查,调查来自 31 个国家的 22,816 名成年人(16 岁至 74 岁)。超过一半的受访者表示人工智能让他们感到紧张,这一比例高于去年的 39%。三分之二的人现在预计人工智能将在未来几年深刻改变他们的日常生活。
Maslej 指出,该指数中的其他图表显示不同人群的观点存在显着差异,年轻人更倾向于对人工智能将如何改变他们的生活持乐观态度。有趣的是,“这种人工智能悲观情绪很多来自西方发达国家”,他说,而印度尼西亚和泰国等地的受访者则表示,他们预计人工智能的利大于弊。